







字符串的模式匹配在计算机应用中十分广泛,也是Microsoft,Intel,BAT等知名企业经常出现的面试题,关于字符串的模式匹配,最常见的方法有很多种,如朴素字符串匹配算法,Rabin-Karp算法,有限自动机算法,以及Knuth-Morris-Pratt算法(简称KMP),本文是对《算法导论》第三版第32章节的一个札记,旨在让几种算法更加直观易于理解,字符串匹配问题,我们可以描述如下:
有一个目标字符串target,记为T[0,1,2,3,...,(n-1)],即它的长度为n;
有一个模式字符串pattern,记为P[0,1,2,3,...,(m-1)],即它的长度为m;
已知模式串长度必须不能大于目标字符串长度,即m≤n。
我们所要做的工作就是找到模式串在目标串中的所有有效偏移,将有效偏移记为s。有效偏移s定义为T[s+0, s+1, s+2, ..., s+(m-1)] = P[0,1,2,..., (m-1)]。说的直白点,有效偏移s就是模式串P在目标串T中出现匹配时第一个字符所在的位置,举个例子如下图:

上图中有效偏移s=3,有时候模式串P在目标串T中根本不会出现,此时的有效偏移s就没有意义,我们可以定义模式串P在目标串T中不存在的情形时s=-1。
下文我们重点介绍朴素字符串匹配算法,Rabin-Karp算法这两种字符串算法。
1. 朴素字符串匹配算法
朴素字符串匹配算法是通过一个循环找到所有有效偏移,该循环对(n-m+1)个可能s值进行检测,看是否满足T[s+0, s+1, s+2, ..., s+(m-1)] = P[0,1,2,..., (m-1)]。 s的取值可以是0,1,2,3,4,..., (n-m),共(n-m+1)种情况。
#include <iostream>
using namespace std;
/*!
* 朴素字符串匹配算法
* 参数值:
* T: 目标字符串
* P: 模式串
*
* 算法复杂度是O((n-m+1)*m) n为目标串的长度,m为模式串长度。
*/
void naive_string_matcher(const char *T, const char *P){
int n = strlen(T);
int m = strlen(P);
for(int s = 0; s <= n-m; ++s){ //s的取值可以是0,1,2,3,4,..., (n-m),共(n-m+1)种情况
/*!
* 对(n-m+1)个可能s值进行检测,看是否满足
* T[s+0, s+1, s+2, ..., s+(m-1)] = P[0,1,2,..., (m-1)]
*/
int i;
for(i = 0; i < m; ++i){
if(T[s+i] != P[i])
break;
}
/*!
* 如果i==m说明此时T[s+0, s+1, s+2, ..., s+(m-1)]与
* P[0,1,2,..., (m-1)]完全相等,否则i在里层for循环没有增至m时
* 就已经break出来了,所以如果i和m相等则说明此时的s为有效偏移
*/
if(i == m)
cout << "Pattern occurs with shift: " << s << endl;
}
}
int main(){
const char *T = "abcabaabcadac";
const char *P = "abaa";
naive_string_matcher(T,P);
return 0;
}在最坏情况下,朴素字符串匹配的算法运行时间为O((n-m+1)*m),如目标串是一个由n个字符‘a'组成的串,模式串是一个由m个字符’a'组成的串,此时对于偏移s共有(n-m+1)种可能,里层for循环也必须要比较m次才能知道是否匹配,故最坏情况下运行时间为O((n-m+1)*m)。
2. Rabin-Karp字符串匹配算法
上述的第一种方法称为朴素字符串匹配算法,或者称之为暴力搜索方法,也是最直观最容易想到的方法,其算法对于每一种可能出现的有效偏移s都要执行里层for循环来一个字符一个字符的依次判断模式串P[0,1,2,..., (m-1)]与T[s+0, s+1, s+2, ..., s+(m-1)] 是否相等,因此速度比较慢,那么我们可以给出一种更快的比较方法:对于每一种可能出现的有效偏移s情形下的T[s+0, s+1, s+2, ..., s+(m-1)] 与P[0,1,2,..., (m-1)]我们尝试一次性判断两者是都相等,这便是Rabin-Karp算法的核心,这种尝试一次性判断两者是否相等方法就是计算出目标串T的所有可能的子串T[s+0, s+1, s+2, ..., s+(m-1)] 与P[0,1,2,..., (m-1)]两者的hash值,再判断是否相等。若两者hash值不相等,则说明T[s+0, s+1, s+2, ..., s+(m-1)] 与P[0,1,2,..., (m-1)]肯定不相等;反之,若两者hash值相等,则如果hash值不冲突的情况下我们可以认为T[s+0, s+1, s+2, ..., s+(m-1)] 与P[0,1,2,..., (m-1)]两者完全相等。然而,我们知道,我们一般不能保证hash函数的值不出现冲突,因此当两者hash值相同的情况下,我们需要进一步依次一个字符一个字符的判断模式串P[0,1,2,..., (m-1)]与T[s+0, s+1, s+2, ..., s+(m-1)] 是否真的相同。Rabin-Karp算法中用到的hash函数是对一个素数取余。
下面介绍Rabin-Karp算法的数学知识与步骤:
我们假设模式串和目标字符串中所有可能出现的不同种字符数目为d(计算机中的输入不同符号的数目最大也就是256,即d=256)。我们可以认为d就是我们输入的模式串和目标串的进制或者称之为基数,这里的d好比十进制里面的10,我们可以将任何一个字符串都进行hash映射成一个整数。
第一步我们需要做的就是对输入的模式串P进行预处理,也就是计算出模式串P的hash值,记为hash(P[0,1,2,..., (m-1)])。给定的目标串T长度为n,其可能出现的有效偏移s=0,1,2,3,4,...,(n-m)。我们用T[s+0, s+1, s+2, ..., s+(m-1)] 表示每一种可能与模式串P[0,1,2,..., (m-1)]相等的情形,其hash值我们记为hash(T[s+0, s+1, s+2, ..., s+(m-1)])。在第一步里面我们同时也计算出T[0, 1, 2, ..., (m-1)] 的hash值,记为hash(T[0, 1, 2, ..., (m-1)] )。
第二步我们需要做的就是对于s=0,1,2,3,4,...,(n-m)这共(n-m+1)中情形:分别判断hash(T[s+0, s+1, s+2, ..., s+(m-1)] )与hash(P[0,1,2,..., (m-1)])是否相等。若不相等,则说明T[s+0, s+1, s+2, ..., s+(m-1)] 与P[0,1,2,..., (m-1)]肯定不相等;若相等,则需要进一步判断T[s+0, s+1, s+2, ..., s+(m-1)] 与P[0,1,2,..., (m-1)]是否真的相等,还是仅仅是两者hash值相同造成的冲突而已。
上述步骤简单分明,然而有一个计算不同有效偏移s下的hash(T[s+0, s+1, s+2, ..., s+(m-1)] )值的方法却比较有讲究,如果对于s=0,1,2,3,4,...,(n-m)这共(n-m+1)中情形,每次都计算一下hash(T[s+0, s+1, s+2, ..., s+(m-1)] )将是非常浪费时间的,我们需要常数时间内计算出该值,我们的已知条件是最初的hash(T[0, 1, 2, ..., (m-1)] ),这在第一步就已经计算出来了。这其实是一个简单的数学问题,我们只需要弄明白如何从hash(T[s+0, s+1, s+2, ..., s+(m-1)] )值计算出hash(T[(s+1)+0, (s+1)+1, (s+1)+2, ..., (s+1)+(m-1)] )即可。因为Rabin-Karp算法中用到的hash函数是对一个素数取余,
T[(s+1)+0, (s+1)+1, (s+1)+2, ..., (s+1)+(m-1)] = d*(T[s+0, s+1, s+2, ..., s+(m-1)] - T[s+0]*d^(m-1)) + T[s+m]
因此,我们有:
hash(T[(s+1)+0, (s+1)+1, (s+1)+2, ..., (s+1)+(m-1)]) =
(d*(hash(T[s+0, s+1, s+2, ..., s+(m-1)]) - T[s+0]*h) + T[s+m]) mod q (公式1)
其中h = d^(m-1) mod q.
因此每次只需要用公式(1)来迭代即可计算出每次的hash(T[(s+1)+0, (s+1)+1, (s+1)+2, ..., (s+1)+(m-1)] )。
下面是Rabin-Karp算法的源码及其注释:
#include <iostream>
using namespace std;
/*!
* 定义d为256,也是字符表中所有不同字符的数量
* 定义q为素数,即hash函数对其取余
*/
#define d 256
#define q 137
/*!
* Rabin-Karp字符串匹配算法
* 参数值:
* T: 目标字符串
* P: 模式串
* n为目标串的长度,m为模式串长度。
*/
void RabinKarp_string_matcher(const char *T, const char *P){
int n = strlen(T);
int m = strlen(P);
int h = 1;
int i;
// h = d^(m-1) % q
for(i = 0; i < m-1; i++)
h = (h * d) % q;
/*!
* 预处理:首先的计算出 hash(P[0,1,2,..., (m-1)]) 和 hash(T[0, 1, 2, ..., (m-1)])
* 将两者分别存储在变量 p 和 t 中。
*/
int p, t;
p = t = 0;
for(i = 0; i < m; ++i){
p = (d*p+P[i])%q;
t = (d*t+T[i])%q;
}
for(int s = 0; s <= n-m; ++s){ //s的取值可以是0,1,2,3,4,..., (n-m),共(n-m+1)种情况
/*!
* 首先进行hash值 p 和 t 的判断,若相等则需要进一步
* 一个字符一个字符的依次比较
*/
if(p == t){
int index;
for(index = 0; index < m; ++index){
if(T[s+index] != P[index])
break;
}
/*!
* 如果index==m说明此时T[s+0, s+1, s+2, ..., s+(m-1)]与
* P[0,1,2,..., (m-1)]完全相等,否则i在里层for循环没有增至m时
* 就已经break出来了,所以如果i和m相等则说明此时的s为有效偏移
*/
if(index == m)
cout << "Pattern occurs with shift: " << s << endl;
}
/*!
* 更新t,因为T[s+0, s+1, s+2, ..., s+(m-1)]在下一次变成了
* T[(s+1)+0, (s+1)+1, (s+1)+2, ..., (s+1)+(m-1)],根据公式
* hash(T[(s+1)+0, (s+1)+1, (s+1)+2, ..., (s+1)+(m-1)]) =
(d*(hash(T[s+0, s+1, s+2, ..., s+(m-1)]) - T[s+0]*h) + T[s+m]) mod q
* 即为:
* t_new = (d*(t_old - T[s+0]*h) + T[s+m]) mod q
*/
if(s < n-m){
t = (d*(t-T[s]*h) + T[s+m]) % q;
if(t < 0)
t = t+q;
}
}
}
int main(){
const char *T = "abcabaabcadac";
const char *P = "abaa";
RabinKarp_string_matcher(T,P);
return 0;
}上述代码执行的流程如下图所示:
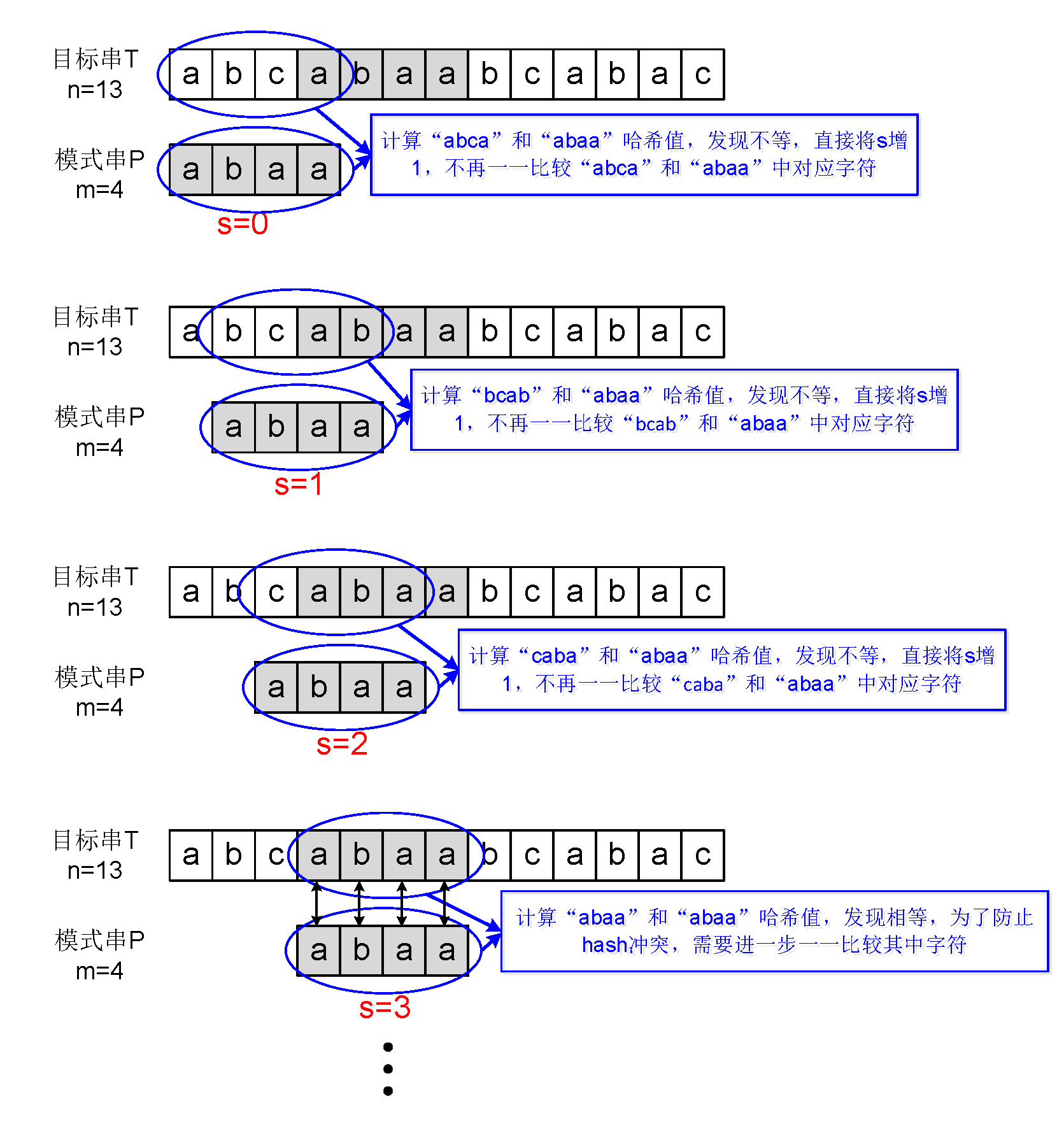
下面分析Rabin-Karp算法的时间复杂度,Rabin-Karp算法需要Θ(m)的预处理时间来计算出最初的模式串P[0,1,2,..., (m-1)]和目标串子串T[0, 1, 2, ..., (m-1)]的hash值,在匹配阶段需要耗费时间Θ((n-m+1)*m),其最坏情况下为O((n-m+1)*m),最快情形与朴素字符串匹配相同,即每次都hash一致,需要进一步一一比对对应位置字符,且判断到最后一个才能知道是否出现匹配。不过每次都出现hash一致但最终的字符串却不相同的情形其实也是比较少见的,虽然理论上分析Rabin-Karp算法的最坏情况下时间开销与朴素匹配算法比起来没啥优势,但是在平均情况下,Rabin-Karp算法还是比朴素匹配快的,它的期望匹配时间是O(n+m)。
参考文献:http://www.ituring.com.cn/article/1759















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









