







1. 二分查找算法(非递归)
1.1 介绍
- 二分查找算法只适用于从有序的数列种进行查找,将数列排序后再进行查找
- 二分查找法的运行时间为对数时间O(log2 n),即查找到需要的目标位置最多只需要log2 n步
1.2 代码实现
public class BinarySearch {
public static void main(String[] args) {
int[] arr = {
1, 3, 8, 10, 11, 67, 100};
int index = binarySearch(arr, -7);
System.out.println(index);
}
//二分查找的非递归实现
public static int binarySearch(int[] arr, int target) {
int left = 0;
int right = arr.length - 1;
while (left <= right) {
int mid = (left + right) / 2;
if (arr[mid] == target) {
return mid;
} else if (arr[mid] > target) {
right = mid - 1;//向左边查找
} else {
left = mid + 1;//向右边查找
}
}
return -1;
}
}
2. 分治算法
2.1 介绍
- 就是把一个复制的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的问题,直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并,分治算法可以求解的一些境点问题
- 二分查找
- 大整数乘法
- 棋盘覆盖
- 合并排序
- 快速排序
- 线性时间选择
- 最接近点对问题
- 循环赛日程表
- 汉诺塔
2.2 基本步骤
- 分解:将原问题分解成若干个规模较小,相互独立,与原问题形式相同的子问题
- 解决:若子问题规模较小而容易被解决则直接解决,否则递归各个子问题
- 合并:将各个子问题的解合并为原问题的解
2.3 汉诺塔问题
2.3.1 思路
- 如果仅有一个盘,A->C
- 有>=2个盘,总是可以看做是两个盘1.最下面的盘;2.上面的盘
- 先把最上面的盘A->B
- 最下面的盘A->C
- B塔的所有盘B->C
2.3.2 代码实现
public class Hanoitower {
public static void main(String[] args) {
hanoiTower(10, 'A', 'B', 'C');
}
//使用分治算法,汉诺塔的移动方法
public static void hanoiTower(int num, char a, char b, char c) {
//只有一个盘
if (num == 1) {
System.out.println("第1个盘从" + a + "->" + c);
} else {
hanoiTower(num - 1, a, c, b);
System.out.println("第" + num + "个盘从" + a + "->" + c);
hanoiTower(num - 1, b, a, c);
}
}
}
3. 动态规划算法
3.1 介绍
- 动态规划(Dynamic Programming)算法的核心思想是:将大问题划分为小问题进行解决,从而一步步获取最优解的处理算法
- 与分治相似,也是将待求解问题分解成若干个子问题,先求子问题,然后从这些子问题的解得到原问题的解
- 与分治不同的是,适用于用动态规划求解的问题,经分解得到子问题不是互相独立的,下一个子阶段的求解是建立在上一个子阶段解的基础上进行进一步求解
- 动态规划可以通过填表的方式来逐步推进,得到最优解
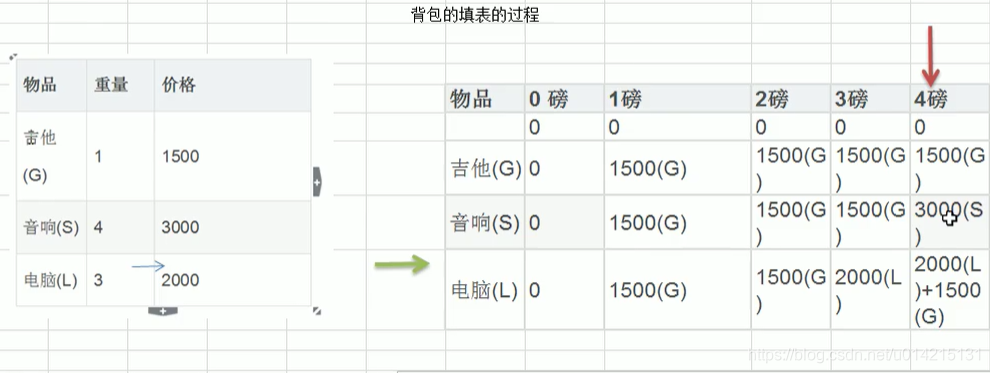
3.2 背包问题
3.2.1 思想
- 总价值最大,重量不能超出
- 装入物品不能重复
| 物品 | 重量w | 价格v |
|---|---|---|
| 吉他 | 1 | 1500 |
| 音响 | 4 | 3000 |
| 电脑 | 3 | 2000 |
每次遍历到第i个物品,根据w[i]和v[i]来确定是否需要将该物品放入背包中,即对于给定的n个物品,C为背包容量,令v[i]·[j]表示再前i个物品总能够装入容量为j的背包中的最大价值
- v[i]·[0]=v[0]·[j]=0
- 当w[i]>j时,v[i]·[j]=v[i-1]·[j]
- 当j>=w[i]时,v[i]·[j]=max{v[i-1]·[j],v[i]+v[i-1]·[j-w[i]}
3.2.2 代码实现
public class KnapsackProblem {
public static void main(String[] args) {
int[] w = {
1, 4, 3};//物品的重量
int[] val = {
1500, 3000, 2000};//物品的价值
int m = 4;//背包的容量
int n = val.length;//物品的个数
int[][] v = new int[n + 1][m + 1];//v[i][j]表示在前i个物品中能装入容量为j的背包中的最大价值
int[][] path = new int[n + 1][m + 1];
for (int i = 1; i < v.length; i++) {
for (int j = 0; j < v[0].length; j++) {
if (w[i - 1] > j) {
v[i][j] = v[i - 1][j];
} else {
//v[i][j] = Math.max(v[i - 1][j], val[i - 1] + v[i - 1][j - w[i - 1]]);
if (v[i - 1][j] < val[i - 1] + v[i - 1][j - w[i - 1]]) {
v[i][j] = val[i - 1] + v[i - 1][j - w[i - 1]];
path[i][j] = 1;
} else {
v[i][j] = v[i - 1][j];
}
}
}
}
for (int i = 0; i < v.length; i++) {
v[i][0] = 0;
}
for (int i = 0; i < v[0].length; i++) {
v[0][i] = 0;
}
for (int i = 0; i < v.length; i++) {
for (int j = 0; j < v[i].length; j++) {
System.out.print(v[i][j] + " ");
}
System.out.println();
}
int i = path.length - 1;
int j = path[0].length - 1;
while (i > 0 && j > 0) {
if (path[i][j] == 1) {
System.out.printf("第%d个商品放入到背包\n", i);
j -= w[i - 1];
}
i--;
}
}
}
4. KMP算法
4.1 暴力匹配算法
- 有一个字符串str1="中国你中你国你国中国你好"和一个子串str2=“中国你好”,判断str1是否含有str2,如果存在返回第一次出现的位置。如果没有,返回-1
- 假设现在str1匹配到i位置,字串str2匹配到j位置,则
- 如果当前字符匹配成功(str1[i]==str2[j]),则i++,j++,继续匹配下一个字符
- 如果str1[i]!=str2[j],令i=i(j-1),j=0。相当于每次匹配失败时,i回溯,j置为0
- 有大量回溯,效率很低
4.1.1 代码实现
public class ViolenceMatch {
public static void main(String[] args) {
String s1 = "中国你中你国你国中国你好";
String s2 = "中国你好-";
int i = violenceMatch(s1, s2);
System.out.println(i);
}
public static int violenceMatch(String str1, String str2) {
char[] s1 = str1.toCharArray();
char[] s2 = str2.toCharArray();
int s1Len = s1.length;
int s2Len = s2.length;
int i = 0;//指向s1
int j = 0;//指向s2
while (i < s1Len && j < s2Len) {
if (s1[i] == s2[j]) {
//匹配成功
i++;
j++;
} else {
i = i - (j - 1);
j = 0;
}
}
if (j == s2Len) {
return i - j;
} else {
return -1;
}
}
}
4.2 KMP算法
- KMP算法常用于在一个文本串S内查找一个模式串P出现的位置
- KMP通过一个next数组,保存模式串中前后最长公共子序的长度,每次回溯时,通过next数组找到,前面匹配过的位置,省去了大量的计算时间
- str1 = “BBC ABCDAB ABCDABCDABDE”,str2="ABCDABD "
public class KMPAlgorithm {
public static void main(String[] args) {
String str1 = "BBC ABCDAB ABCDABCDABDE";
String str2 = "ABCDABD";< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1505
1505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









