






目录
一、我们要解决什么问题?
1、流程标准化;
2、提高复用性(组件能力);
3、可视化配置(流程编排、ABTest实验变量、召回数据比例、混排比例);
4、可调试的流程和在线调试功能,可协助排查问题(如L4混排逻辑,可直接观察每个排序步骤对结果的影响)。
二、LiteFlow 可以解决哪些问题?不能解决哪些?
| 功能 | 是否支持 | 解释 |
|---|---|---|
| 功能 | 是否支持 | 解释 |
| 规则配置的灵活性 | ✅ | 简单的规则配置,灵活配置; |
| 高性能 | ✅ | 官方压测数据:几乎没有损耗; |
| 平滑热更新 | ✅ | 支持多种平滑热更新方式,也可支持自定义方式; |
| 改造成本 | ✅ | 只需要封装成对应组件就可以,数据传递通过上下文传递。 |
| 可视化 | ❌ | 官方未支持可视化,需要考虑可视化实现的难度 |
| 灰度 | ❌ |
官方未支持,可自实现,采用Apollo配置的方式切换版本。 |
三、业务架构
四、技术架构
我们希望通过轻舟可视化的展示流程编排的细节,以及支持动态调整流程,我们需要将规则文件的编排规则从分发服务中解耦,采用配置中心进行管理,以数据库的方式进行存储。分发服务则会通过接口访问读取规则,并以代码构造规则。
注意
采用了数据库的方式进行存储规则的话,就相当于没有平滑热更新,需要自己实现,LiteFlow也有提供对应的API能力。具体该如何实现,我们后面在进行探讨。
因为LiteFlow并未提供可视化的能力,所以我们需要自己实现,考虑到过度的可视化会带来开发难度与复杂性,所以,我的设想是以树结构进行设计。
|
设想1
|
设想2
|
|---|---|
|
树的节点分为两种:
上面两种种节点,都是通过开发手动注册到配置中心,在流程编排的时候,树节点都是通过选项框来进行选择对应的组件。各类组件会有对应的属性值,用来定制组件在不同场景下的动态调整。 
|
树的节点分为三~四种:
|

4.0、架构图

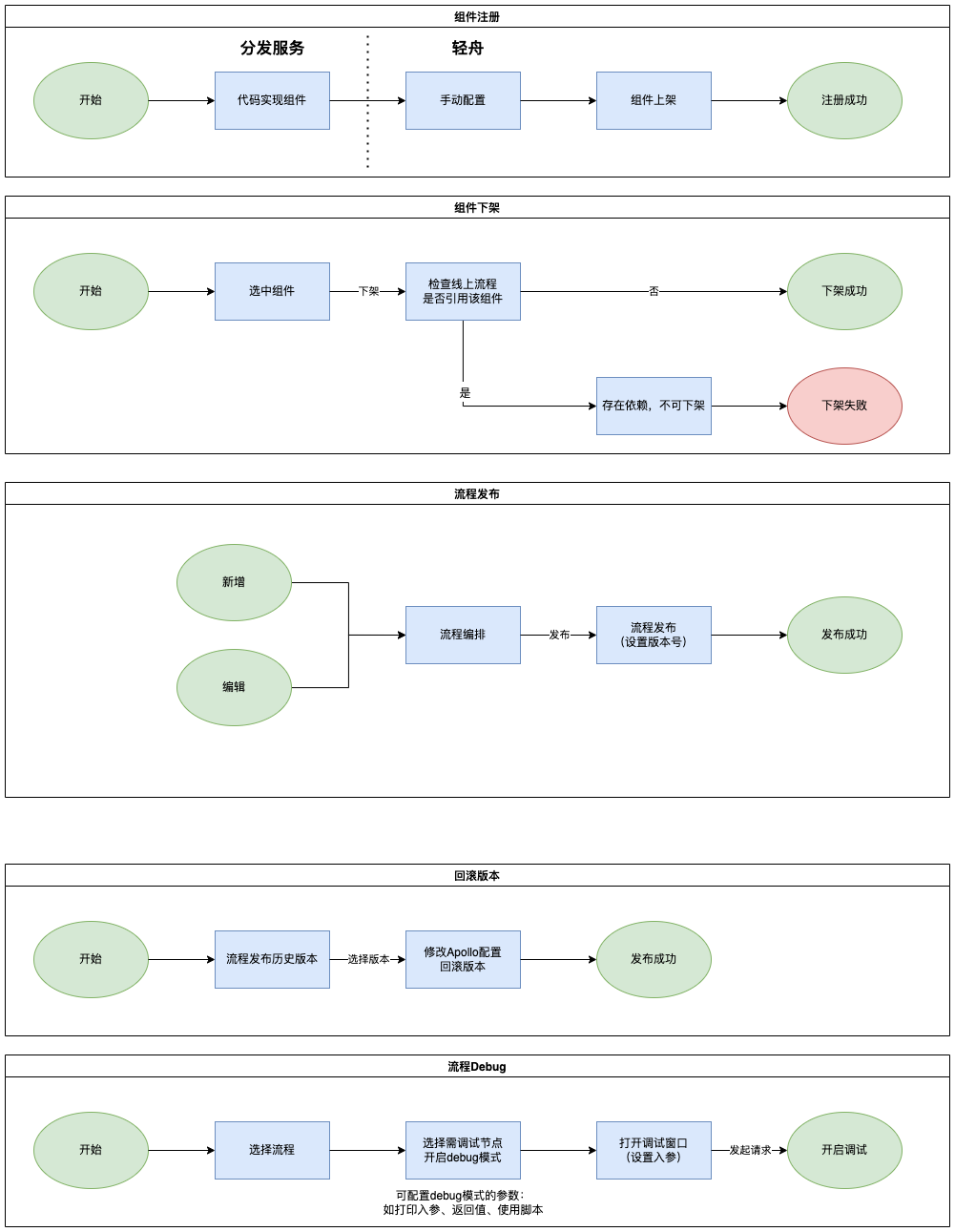
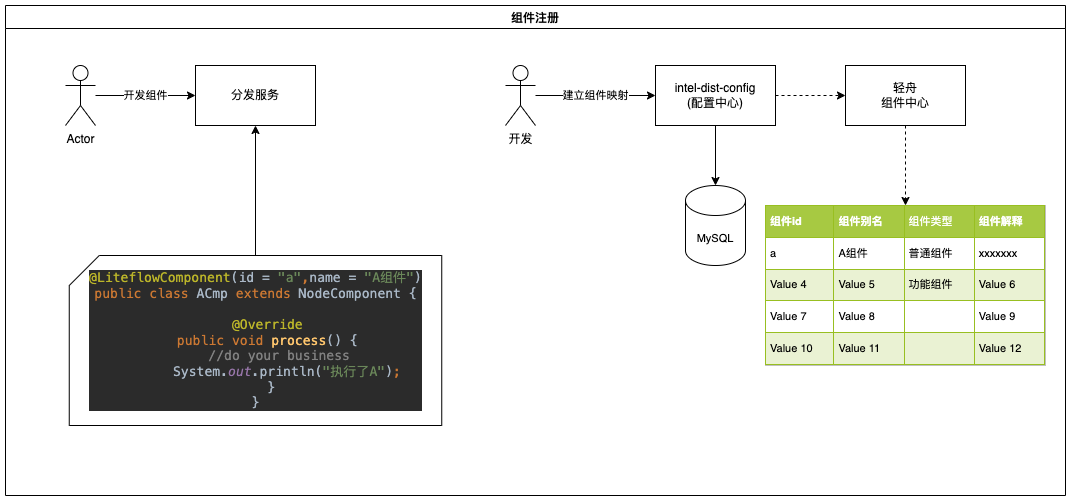
4.1、 组件注册(必要)
组件的具体实现逻辑还是在分发服务,为了配置中心在进行可视化编辑的时候,可以关联到该组件实现,我们需要将代码中的组件手动的在配置中心进行注册,主要包含四项数据:
- 组件ID
- 组件别名
- 组件类型
- 组件解释
- 组件依赖上下文:组件是依赖上下文来进行数据传递的,需要明确定义好,组件依赖的上下文。防止流程设计后,流程走不通。
如下图中例子,分发服务的组件实现 @LiteflowComponent(id="a",name="xxx") 会有组件ID、组件名两个属性,我们要在轻舟那边创建一条的组件映射,并添加上类型以及解释。
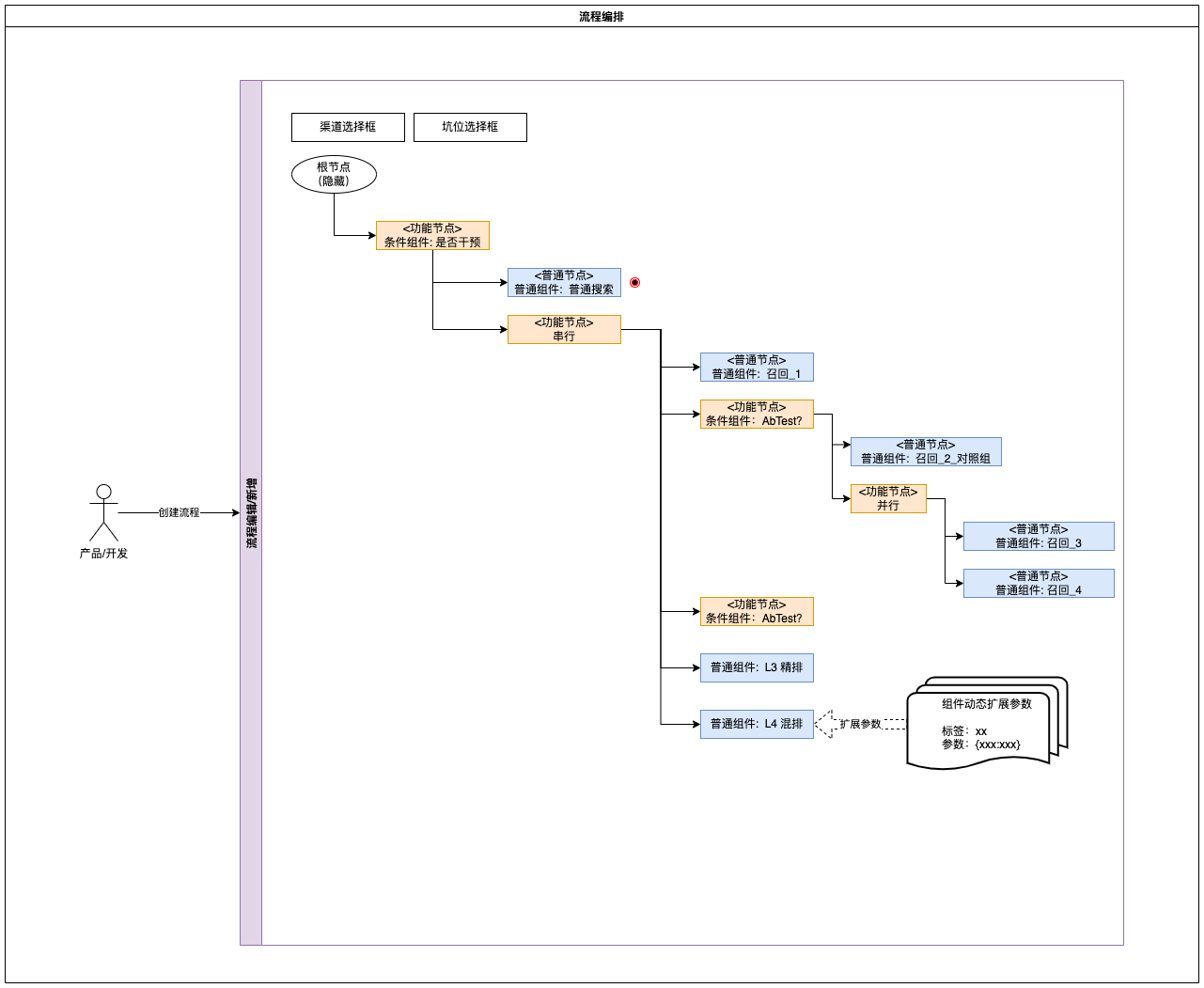
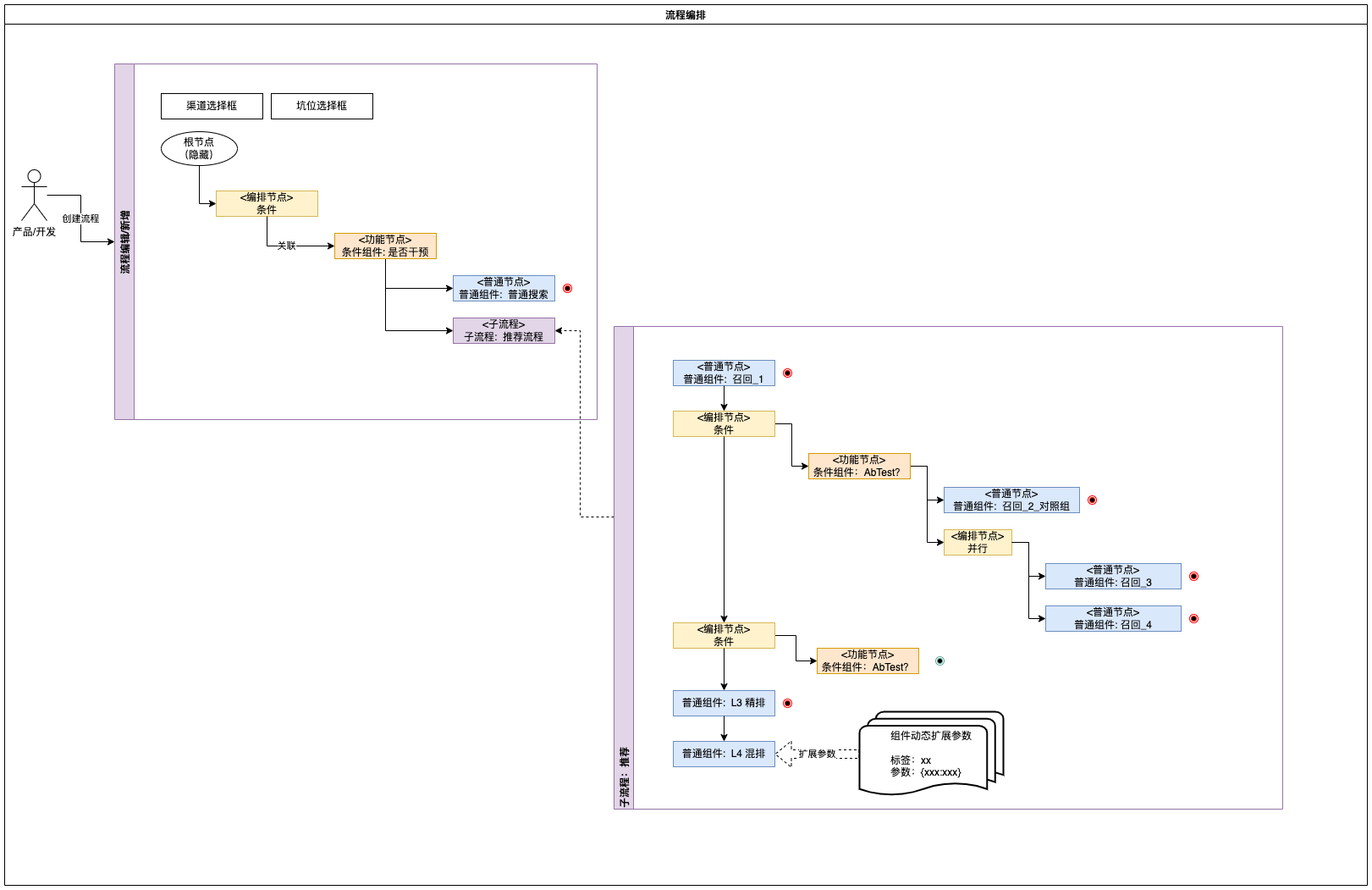
4.2、流程编排(必要)
流程编排通过渠道+坑位表示对应的接口,默认有个根节点,没有任何属性(其实就是串行功能组件),添加子节点时,通过选项选择不同类型的组件进行组装,并且可对选中的组件添加该流程中的自定义入参。
| 设想1 | |
|---|---|
|
|
|
4.3、流程版本发布(必要)
流程发布增加了版本的概念,主要是考虑流程发布后该如何快速回滚的问题,采用版本的概念后,可以选择任意版本进行发布、回滚,对线上环境的可用性多一层保障。
多版本也是对环境隔离的条件,像分发服务的stage环境与prod环境是公用同个数据库,如果未进行版本隔离,那么stage进行验收调整流程时将会影响到prod环境。

4.4、数据热更新 (必要)
上面的流程编排后,我们将会解析得到LiteFlow的EL规则配置,该配置会被存在配置中心的数据库中,该EL规则配置是每次访问接口都要获取的,我们不可能每次都查询数据库,所以我们会引入缓存。
但是,如果用Redis缓存的话,每次访问接口都取读取的话,也会增加一些请求网络带宽,以及耗时问题。所以,我打算将该数据存到服务本地缓存,使用全局变量Map直接存储、以及通过Apollo来通知缓存进行热更新。
Apollo主要配置对应的接口与流程版本的映射,服务的本地缓存会自己维护流程版本与EL规则配置。当Apollo发起更新时,将会触发监听事件,本地缓存需要将不在Apollo配置的流程版本进行移除,对未进行缓存的版本调用接口进行读取并缓存,并调用LiteFlowApi进行热更新。
提示
LiteFlow:既然是指定刷新,那么必须你要获取到改动的EL内容,然后再利用动态代码构建重新build下就可以了,这种方式会自动替换缓存中已有的规则。这种方式不用在build之前销毁流程。
4.5、流程调试、线上排查 (扩展)
4.5.1 流程调试
当我们流程编排后,该如何进行验证我们的流程是否正确呢?是否符合我们的预期呢?总不能把本就有问题的流程设计直接扔到服务跑跑看吧。
针对上面的设想,我们还需要一个可以前置进行流程语法检查、以及流程执行过程调试的过程。
- 流程语法检查:LiteFlow是已经提供了API能力,所以完全可以支持。
- 流程执行过程调试:LiteFlow有提供流程实际执行的步骤信息以及组件耗时,我计划在流程编排的详情页面上增加一个接口调试窗口,我们可以预设一些入参,当产品或者开发想要进行TestCase时,可以直接在这里快速执行。将执行结果会高亮在流程图上,更具有可观测性。(主要服务的对象是产品同学,给他们一个可以直接执行的入口,而不需要走版本发布流程。)
4.5.2 线上排查
当我们的流程进行拆分成一个个组件后,我们该如何排查线上问题呢?
比如,我们L4的重排逻辑,会夹杂很多干预、重排的逻辑,任何一个规则都会影响到最终排序,这将导致我们排查问题的难度。
线上排查能力,计划分成两部分实现:
- 日志打印开关:对每个组件增加了日志开关,可自定义进行开关,当请求头带有x-debug:true时会把开启日志打印的组件,将输入输出进行打印。(是否有必要增加开关?还是直接根据x-debug来判断就行?)
- 注入脚本:LiteFlow支持我们构建脚本组件,我们可以借用脚本进行协助排查问题(该方法比较灵活,只限制在debug模式下进行)。
建议
Debug时,也要创建一个新版本,保证不会影响线上数据。
4.6、UML

五、可视化方案
流程编排可视化主要分成两块,一块是流程图渲染,一个是针对该流程节点之间的关联关系、以及属性的编辑操作。
拆成两块后,流程图渲染就只是简单把数据渲染成图,可参考:CSS 流程图 。
而节点关系的交互操作改成了侧边栏弹窗的方式进行编辑,这样可以大大降低可视化方案的成本。
5.1、效果示意图:
| 设想1 | 设想2 |
|---|---|
|
| 参考:设想2流程编排图 |

5.2、效果代码展示:
| 设想1 | 设想2 | ||
|---|---|---|---|
|
|
六、最佳实践
6.1、组件之间数据传递
LiteFlow 支持多个上下文,组件之间的数据传递依赖上下文进行传递。
建议将上下文分成两类:
- 业务相关
- 非业务相关
不管是业务还是非业务相关的上下文,都要尽量领域纯粹,不要担任太多不相关数据,比如,用户信息就放到UserContext、筛选器放到FilterContext、模板数据放到TemplateContext、Ab实验信息放到AbTestContext等。
6.2、组件共同扩展能力实现
如debug打印日志能力,可以参考:组件切面。















 1450
1450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









