







用卷积神经网络来给,cifar10数据集进行分类,这是一个经典的数据集,它包含60000张32x32的彩色图片,其中训练集50000张测试集10000张.照片的内容包含十个类别:airplane,automobile,bird,cat,deer,dog,frog,horse,ship和truck.各有6000张


在这个CNN中用到了新的正则化方法,分别是L2权重loss,和LRN(局部响应标准化),LRN主要用在了卷积层,L2用在全连接层的权重.
#首先下载tensorflow models里面提供了获取数据的方法
git clone https://github.com/tensorflow/models.git
下载完成后,进入models/tutotials/image/cifar10路径下找到cifar10.py cifar10_input.py放到模型同一路径下即可导入用到的库import tensorflow as tf
import numpy as np
import cifar10,cifar10_input
import time
import matplotlib.pyplot as plt
import numpy as np#cifar10.maybe_download_and_extract() # 下载cifar10数据集
# 默认下载路径:'/tmp/cifar10_data/cifar-10-batches-bin'max_steps = 8000
batch_size = 512 # 小批量数据大小
fh1_nodes = 128 # 全连接隐藏层1节点数
fh2_nodes = 64 # 隐藏层2
display = 100
data_dir = 'cifar10data/cifar-10-batches-bin' # 数据所在路径# 权重初始化+L2损失(正则)
# l2正则是为了防止模型过拟合,将权重作为损失函数的一部分,减小权防止过拟合
# stddev是标准差, w1 来控制l2正则的程度
# tf.nn.l2_loss()计算权重损失,然后乘以系数w1
# tf.add_to_collection()会创建一个集合(列表),存放每层权重的loss,最后在求和添加到损失函数中
def l2_weight_init(shape, stddev, w1):
weight = tf.Variable(tf.truncated_normal(shape, stddev=stddev))
if w1 is not None:
weight_loss = tf.multiply(tf.nn.l2_loss(weight), w1, name='weight_loss')
tf.add_to_collection('losses', weight_loss)
return weight
# 用于对卷积层权重初始化,卷积层没有使用l2正则
def weight_init(shape, stddev):
weight = tf.Variable(tf.truncated_normal(shape, stddev=stddev))
return weight
#初始化偏置,卷积,池化,局部响应正则def biases_init(shape):
return tf.Variable(tf.random_normal(shape))def conv2d(image, weight):
return tf.nn.conv2d(image, weight, strides=[1,1,1,1],padding='SAME')def max_pool(tensor):
return tf.nn.max_pool(tensor, ksize=[1,3,3,1], strides=[1,2,2,1], padding='SAME')LRN局部响应标准化,在局部对神经元创建竞争环境,使反应较大的值变得相对更大
反应较小的神经元会被抑制,以此来增强模型的泛化能力
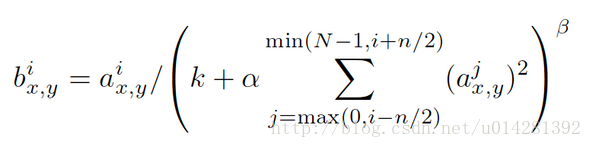
公式中的a就是原始图中的像素点,b为lrn后的.tf.nn.lrn()中的参数分别对应:4对应n, bias :对应k, alpha 对应α , beta 对应 β, N 为像素点的个数.
def LRnorm(tensor):
return tf.nn.lrn(tensor, 4, bias=1.0, alpha=0.001/9.0, beta = 0.75)# distorted_inputs函数生成训练数据,返回封装好的tensor对象
# 在生成训练数据的同时,对训练数据进行了增强处理,对图像进行随机的反转,切割,亮度调整等等(增加噪声)
# 增强处理,给每个图片增加了多个副本,可以提高数据的利用率,防止对某一图片的特征学习过拟合
# 随机切割为24x24的大小
train_images, train_labels = cifar10_input.distorted_inputs(batch_size= batch_size, data_dir= data_dir)# 测试数据是原图中间的24x24部分
# cifar10_input.inputs()返回测试数据,测试数据的label值,不是one-hot的形式,是我一个一维
test_images, test_labels = cifar10_input.inputs(batch_size= batch_size, data_dir= data_dir,eval_data= True)# 创建输入数据的占位节点
images = tf.placeholder(tf.float32, [batch_size, 24, 24, 3])
labels = tf.placeholder(tf.float32, [batch_size])# conv1 pool1 LRN1
weight1 = weight_init([5, 5, 3, 32], 0.05)
biases1 = biases_init([32])
conv1 = tf.nn.relu(conv2d(images, weight1) + biases1) #shape:[batchsize,24,24,32]
pool1 = max_pool(conv1) #shape:[batchsize,12,12,32]
lrnorm1 = LRnorm(pool1) #shape:[batchsize,12,12,32]# conv2 LRN2 pool2
weight2 = weight_init([5, 5, 32, 32], 0.05)
biases2 = biases_init([32])
conv2 = tf.nn.relu((conv2d(lrnorm1, weight2) + biases2)) #shape:[batchsize,12,12,32]
lrnorm2 = LRnorm(conv2) #shape:[batchsize,12,12,32]
pool2 = max_pool(lrnorm2) #shape:[batchsize,6,6,32]全连接
# flatten,池化后的特征转换为一维
reshape = tf.reshape(pool2, [batch_size, -1]) # batchsize x 1152
n_input = reshape.get_shape()[1].value
# 全连接隐藏层1
weight3 = l2_weight_init([n_input, fh1_nodes], 0.05, w1=0.001)
biases3 = biases_init([fh1_nodes])
fullc1 = tf.nn.relu(tf.matmul(reshape, weight3) + biases3)# 全连接隐藏层2
weight4 = l2_weight_init([fh1_nodes, fh2_nodes], 0.05, w1=0.003)
biases4 = biases_init([fh2_nodes])
fullc2 = tf.nn.relu(tf.matmul(fullc1, weight4) + biases4)
# output layer
weight5 = weight_init([fh2_nodes, 10], 1/96.0)
biases5 = biases_init([10])
logits = tf.add(tf.matmul(fullc2, weight5) , biases5) # 未激活输出
y_out = tf.nn.softmax(logits)损失函数
def loss(logits, labels):
labels = tf.cast(labels, tf.int64)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,
labels = labels,
name ='cross_entropy_per_example')
# 交叉熵损失
cross_entropy_mean = tf.reduce_mean(cross_entropy, name='cross_entropy')
# 权重损失
tf.add_to_collection('losses', cross_entropy_mean)
return tf.add_n(tf.get_collection('losses'), name='total_loss')
# 定义损失 = cross_entropy + l2_weight_loss
loss = loss(logits, labels)
# 优化Op
train_op = tf.train.AdamOptimizer(learning_rate=0.0001).minimize(loss)计算分类准确率
# Accuracy
# tf.to_int64()
# 测试数据没有进行one-hot编码
def accuracy(test_labels, test_y_out):
test_labels = tf.to_int64(test_labels)
prediction_result = tf.equal(test_labels,tf.argmax(y_out,1))
accu = tf.reduce_mean(tf.cast(prediction_result, tf.float32))
return accuinit = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)# 图片增强处理,时使用了16个线程加速,启动16个独立线程
tf.train.start_queue_runners(sess=sess)[<Thread(Thread-4, started daemon 140381744264960)>,
<Thread(Thread-5, started daemon 140381735872256)>,
...............................
<Thread(Thread-33, started daemon 140380334946048)>,
<Thread(Thread-34, started daemon 140380326553344)>,
<Thread(Thread-35, started daemon 140380318160640)>,
<Thread(Thread-36, started daemon 140380309767936)>,
<Thread(Thread-37, started daemon 140380301375232)>]
开始
Cross_loss = []
for i in range(max_steps):
start_time = time.time()
batch_images, batch_labels = sess.run([train_images, train_labels])
_, cross_entropy = sess.run([train_op, loss],feed_dict={images:batch_images,
labels:batch_labels})
Cross_loss.append(cross_entropy)
every_epoch_time = time.time() - start_time
if i % display == 0:
examples_per_sec = batch_size/ every_epoch_time
every_batch_time = float(every_epoch_time)
format_str = 'Epoch : %d, loss :%.5f, %d examples/sec, %.3f sec/batch'
print format_str%(i+100,cross_entropy,examples_per_sec,every_batch_time)
Epoch : 100, loss :3.20010, 396 examples/sec, 1.291 sec/batch
Epoch : 200, loss :2.40052, 425 examples/sec, 1.204 sec/batch
Epoch : 300, loss :2.23943, 421 examples/sec, 1.216 sec/batch
Epoch : 400, loss :2.05130, 398 examples/sec, 1.284 sec/batch
Epoch : 500, loss :1.98586, 405 examples/sec, 1.261 sec/batch
Epoch : 600, loss :1.90049, 415 examples/sec, 1.233 sec/batch
Epoch : 700, loss :1.83232, 409 examples/sec, 1.250 sec/batch
......................
Epoch : 7600, loss :1.24275, 415 examples/sec, 1.231 sec/batch
Epoch : 7700, loss :1.22947, 338 examples/sec, 1.514 sec/batch
Epoch : 7800, loss :1.23878, 414 examples/sec, 1.235 sec/batch
Epoch : 7900, loss :1.24912, 246 examples/sec, 2.078 sec/batch
Epoch : 8000, loss :1.29120, 391 examples/sec, 1.308 sec/batch
训练损失
fig,ax = plt.subplots(figsize=(13,6))
ax.plot(Cross_loss)
plt.grid()
plt.title('Train loss')
plt.show()
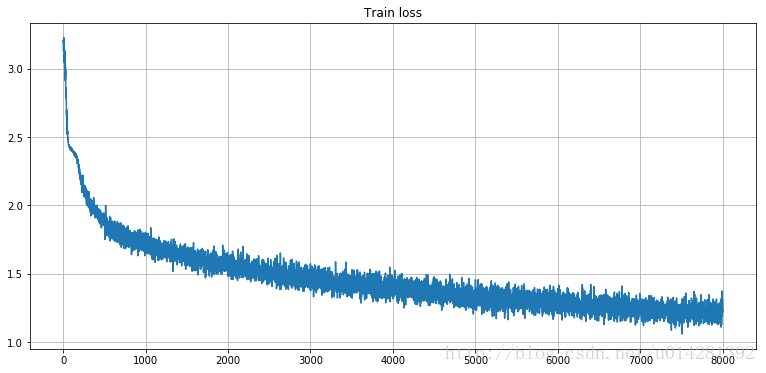
主要在cpu上训练,比较费时,如果在GPU上训练,可以考虑增加隐藏层神经元的数量,大概3000-4000轮训练,loss就会下降到1.0左右测试准确率
在每个batchsize大小的数据集上计算准确率,计算平均准确率
for i in range(10):
test_accu = []
batch_test_images, batch_test_labels = sess.run([test_images, test_labels])
batch_y_out = sess.run(y_out,feed_dict={images:batch_test_images})
test_accuracy = accuracy(batch_test_labels, batch_y_out)
accu = sess.run(test_accuracy,feed_dict={images:batch_test_images})
test_accu.append(accu)
print accu
print 'mean accuracy',np.mean(test_accu)
0.634766
0.679688
0.662109
0.636719
0.660156
0.644531
0.605469
0.658203
0.667969
0.658203
mean accuracy 0.658203
训练过程可视化
# 随便选择一个测试图片(像素经过标准化处理后的)
# ,24 x 24 x 3 imshow(h,w,channel)
input_image = batch_test_images[17]
fig1,ax1 = plt.subplots(figsize=(2,2))
ax1.imshow(input_image)
plt.show()

# 卷积1
test_image = np.reshape(input_image,(1,24,24,3))
c1 = tf.nn.relu(conv2d(test_image, weight1) + biases1)
c_1 = sess.run(c1) # c_1 shape:1, 24, 24, 32
fig2, ax2 = plt.subplots(nrows=1,ncols=32,figsize=(32,1))
for i in range(32):
ax2[i].imshow(np.reshape(c_1,(32,1,24,24))[i][0])
plt.show()

# 池化1
p1 = max_pool(c_1)
p1_shape = p1.get_shape() # 1,12,12,32
p_1 = sess.run(p1)
fig3, ax3 = plt.subplots(nrows=1,ncols=32,figsize=(32,1))
for i in range(32): # shape: 32, 1,12,12
ax3[i].imshow(np.reshape(p_1,(p1_shape[-1],p1_shape[0],p1_shape[1],p1_shape[2]))[i][0])
plt.show()
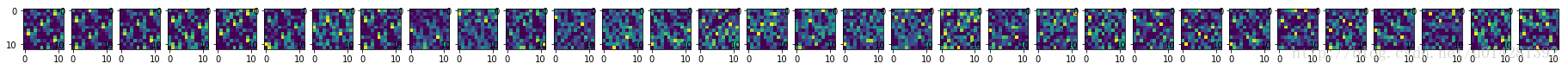
# 局部响应正则化1
lrn1 = LRnorm(p_1)
lrn1_shape = lrn1.get_shape()
lrn_1 = sess.run(lrn1) # shape: 1,12,12,32
fig4, ax4 = plt.subplots(nrows=1,ncols=32,figsize=(32,1))
for i in range(32): # shpae: 32,1,12,12
ax4[i].imshow(np.reshape(lrn_1,(lrn1_shape[-1],lrn1_shape[0],lrn1_shape[1],lrn1_shape[2]))[i][0])
plt.show()
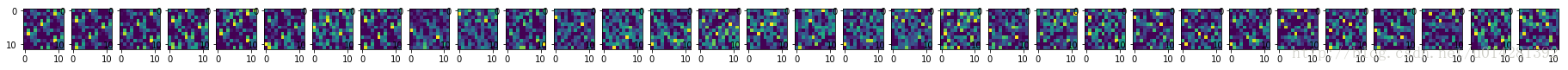
局部响应正则的效果不是特别明显# 卷积2,经过卷积后,c2 shape:1,12,12,32(可以计算出来,所以就不通过get_shape()来获得了)
c2 = tf.nn.relu(conv2d(lrn_1,weight2) + biases2)
c_2 = sess.run(c2)
fig5, ax5 = plt.subplots(nrows=1,ncols=32,figsize=(32,1))
for i in range(32):
ax5[i].imshow(np.reshape(c_2,(32,1,12,12))[i][0])
plt.show()

# 局部响应正则化2
lrn2 = LRnorm(c_2) # shape: 1,12,12,32
lrn_2 = sess.run(lrn2)
fig6, ax6 = plt.subplots(nrows=1,ncols=32,figsize=(32,1))
for i in range(32):
ax6[i].imshow(np.reshape(lrn_2,(32,1,12,12))[i][0])
plt.show()

# 池化2
p2 = max_pool(lrn_2) # shape: 1,6,6,32
p_2 = sess.run(p2)
fig7, ax7 = plt.subplots(nrows=1,ncols=32,figsize=(32,1))
for i in range(32):
ax7[i].imshow(np.reshape(p_2,(32,1,6,6))[i][0])
plt.show()















 1804
1804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









