







文章目录
本文着重讲述经典BP神经网络的数学推导过程,并辅助一个小例子。本文不会介绍机器学习库(比如sklearn, TensorFlow等)的使用。 欲了解卷积神经网络的内容,请参见我的另一篇博客一文搞定卷积神经网络——从原理到应用。
本文难免会有叙述不合理的地方,希望读者可以在评论区反馈。我会及时吸纳大家的意见,并在之后的chat里进行说明。
本文参考了一些资料,在此一并列出。
- http://neuralnetworksanddeeplearning.com/chap2.html
- https://www.deeplearning.ai/ coursera对应课程视频讲义
- coursera华盛顿大学机器学习专项
- 周志华《机器学习》
- 李航《统计学习方法》
- 张明淳《工程矩阵理论》
0. 什么是人工神经网络?
首先给出一个经典的定义:“神经网络是由具有适应性的简单单元组成的广泛并行互连网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应”[Kohonen, 1988]。
这种说法虽然很经典,但是对于初学者并不是很友好。比如我在刚开始学习的时候就把人工神经网络想象地很高端,以至于很长一段时间都不能理解为什么神经网络能够起作用。类比最小二乘法线性回归问题,在求解数据拟合直线的时候,我们是采用某种方法让预测值和实际值的“偏差”尽可能小。同理,BP神经网络也做了类似的事情——即通过让“偏差”尽可能小,使得神经网络模型尽可能好地拟合数据集。
1. 神经网络初探
1.1 神经元模型
神经元模型是模拟生物神经元结构而被设计出来的。典型的神经元结构如下图1所示:
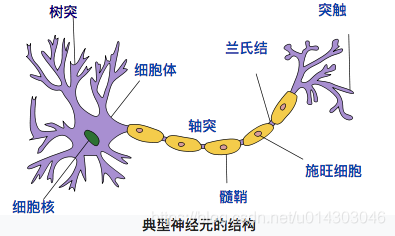
【图1 典型神经元结构 (图片来自维基百科)】
神经元大致可以分为树突、突触、细胞体和轴突。树突为神经元的输入通道,其功能是将其它神经元的动作电位传递至细胞体。其它神经元的动作电位借由位于树突分支上的多个突触传递至树突上。神经细胞可以视为有两种状态的机器,激活时为“是”,不激活时为“否”。神经细胞的状态取决于从其他神经细胞接收到的信号量,以及突触的性质(抑制或加强)。当信号量超过某个阈值时,细胞体就会被激活,产生电脉冲。电脉冲沿着轴突并通过突触传递到其它神经元。(内容来自维基百科“感知机”)
同理,我们的神经元模型就是为了模拟上述过程,典型的神经元模型如下:
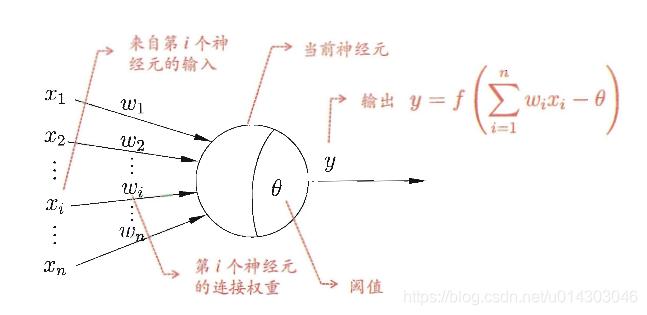
【图2 典型神经元模型结构 (摘自周志华老师《机器学习》第97页)】
这个模型中,每个神经元都接受来自其它神经元的输入信号,每个信号都通过一个带有权重的连接传递,神经元把这些信号加起来得到一个总输入值,然后将总输入值与神经元的阈值进行对比(模拟阈值电位),然后通过一个“激活函数”处理得到最终的输出(模拟细胞的激活),这个输出又会作为之后神经元的输入一层一层传递下去。
1.2 神经元激活函数
本文主要介绍2种激活函数,分别是 s i g m o i d sigmoid sigmoid和 r e l u relu relu函数,函数公式如下:
s i g m o i d ( z ) = 1 1 + e − z sigmoid(z)=\frac{1}{1+e^{-z}} sigmoid(z)=1+e−z1
r e l u ( z ) = { z z > 0 0 z ≤ 0 relu(z)= \left\{ \begin{array}{rcl} z & z>0\\ 0&z\leq0\end{array} \right. relu(z)={
z0z>0z≤0
做函数图如下:
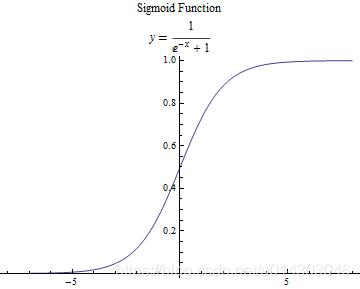
s i g m o i d ( z ) sigmoid(z) sigmoid(z)
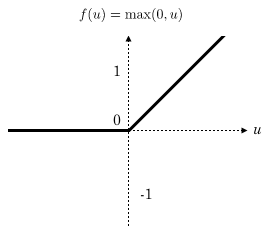
r e l u ( z ) relu(z) relu(z)
【图3 激活函数】
补充说明
【补充说明的内容建议在看完后文的反向传播部分之后再回来阅读,我只是为了文章结构的统一把这部分内容添加在了这里】引入激活函数的目的是在模型中引入非线性。如果没有激活函数,那么无论你的神经网络有多少层,最终都是一个线性映射,单纯的线性映射无法解决线性不可分问题。引入非线性可以让模型解决线性不可分问题。
一般来说,在神经网络的中间层更加建议使用 r e l u relu relu函数,两个原因:
- r e l u relu relu函数计算简单,可以加快模型速度;
- 由于反向传播过程中需要计算偏导数,通过求导可以得到 s i g m o i d sigmoid sigmoid函数导数的最大值为0.25,如果使用 s i g m o i d sigmoid sigmoid函数的话,每一层的反向传播都会使梯度最少变为原来的四分之一,当层数比较多的时候可能会造成梯度消失,从而模型无法收敛。
1.3 神经网络结构
我们使用如下神经网络结构来进行介绍,第0层是输入层(3个神经元), 第1层是隐含层(2个神经元),第2层是输出层:
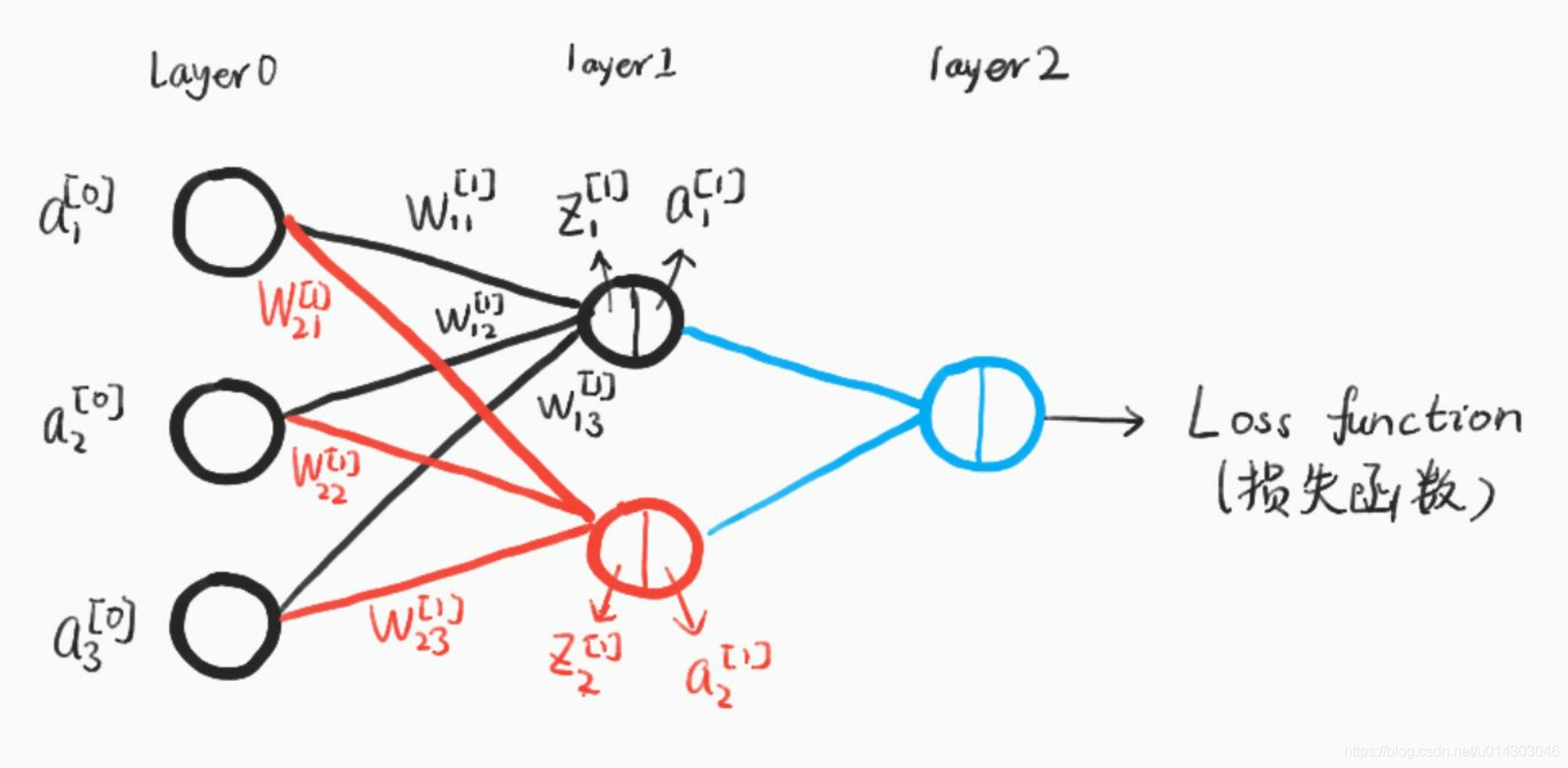
【图4 神经网络结构(手绘)】
我们使用以下符号约定, w j k [ l ] w_{jk}^{[l]} wjk[l]表示从网络第 ( l − 1 ) t h (l-1)^{th} (l−1)th中 k t h k^{th} kth个神经元指向第 l t h l^{th} lth中第 j t h j^{th} jth个神经元的连接权重,比如上图中 w 21 [ 1 ] w^{[1]}_{21} w21[1]即从第0层第1个神经元指向第1层第2个神经元的权重。同理,我们使用 b j [ l ] b^{[l]}_j bj[l]来表示第 l t h l^{th} lth层中第 j t h j^{th} jth神经元的偏差,用 z j [ l ] z^{[l]}_j zj[l]来表示第 l t h l^{th} lth层中第 j t h j^{th} jth神经元的线性结果,用 a j [ l ] a^{[l]}_j aj[l]来表示第 l t h l^{th} lth层中第 j t h j^{th} jth神经元的激活函数输出。
激活函数使用符号 σ \sigma σ表示,因此,第 l t h l^{th} lth层中第 j t h j^{th} jth神经元的激活为:
a j [ l ] = σ ( ∑ k w j k [ l ] a k [ l − 1 ] + b j [ l ] ) a^{[l]}_j=\sigma(\sum_kw^{[l]}_{jk}a^{[l-1]}_k+b^{[l]}_j) aj[l]=σ(k∑wjk[l]ak[l−1]+bj[l])
现在,我们使用矩阵形式重写这个公式:
定义 w [ l ] w^{[l]} w[l]表示权重矩阵,它的每一个元素表示一个权重,即每一行都是连接第 l l l层的权重,用上图举个例子就是:
w [ 1 ] = [ w 11 [ 1 ] w 12 [ 1 ] w 13 [ 1 ] w 21 [ 1 ] w 22 [ 1 ] w 23 [ 1 ] ] w^{[1]}=\left[ \begin{array}{cc} w_{11}^{[1]} & w_{12}^{[1]} & w_{13}^{[1]} \\ w_{21}^{[1]}& w_{22}^{[1]} & w_{23}^{[1]}\end{array}\right] w[1]=[w11[1]w21[1]w12[1]w22[1]w13[1]w23[1]]
同理,
b [ 1 ] = [ b 1 [ 1 ] b 2 [ 1 ] ] b^{[1]}=\left[ \begin{array}{cc}b^{[1]}_1 \\ b^{[1]}_2 \end{array}\right] b[1]=[b1[1]b2[1]]
z [ 1 ] = [ w 11 [ 1 ] w 12 [ 1 ] w 13 [ 1 ] w 21 [ 1 ] w 22 [ 1 ] w 23 [ 1 ] ] ⋅ [ a 1 [ 0 ] a 2 [ 0 ] a 3 [ 0 ] ] + [ b 1 [ 1 ] b 2 [ 1 ] ] = [ w 11 [ 1 ] a 1 [ 0 ] + w 12 [ 1 ] a 2 [ 0 ] + w 13 [ 1 ] a 3 [ 0 ] + b 1 [ 1 ] w 21 [ 1 ] a 1 [ 0 ] + w 22 [ 1 ] a 2 [ 0 ] + w 23 [ 1 ] a 3 [ 0 ] + b 2 [ 1 ] ] z^{[1]}=\left[ \begin{array}{cc} w_{11}^{[1]} & w_{12}^{[1]} & w_{13}^{[1]} \\ w_{21}^{[1]}& w_{22}^{[1]} & w_{23}^{[1]}\end{array}\right]\cdot \left[ \begin{array}{cc} a^{[0]}_1 \\ a^{[0]}_2 \\ a^{[0]}_3 \end{array}\right] +\left[ \begin{array}{cc}b^{[1]}_1 \\ b^{[1]}_2 \end{array}\right]=\left[ \begin{array}{cc} w_{11}^{[1]}a^{[0]}_1+w_{12}^{[1]}a^{[0]}_2+w_{13}^{[1]}a^{[0]}_3+b^{[1]}_1 \\ w^{[1]}_{21}a^{[0]}_1+w_{22}^{[1]}a^{[0]}_2+w_{23}^{[1]}a^{[0]}_3+b^{[1]}_2\end{array}\right] z[1]=[w11[1]w21[1]w12[1]w22[1]w13[1]w23[1]]⋅⎣⎢⎡a1[0]a2[0]a3[0]⎦⎥⎤+[b1[1]b2[1]]=[w11[1]a1[0]+w12[1]a2[0]+w13[1]a3[0]+b1[1]w21[1]a1[0]+w22[1]a2[0]+w23[1]a3[0]+b2[1]]
更一般地,我们可以把前向传播过程表示:
a [ l ] = σ ( w [ l ] a [ l − 1 ] + b [ l ] ) a^{[l]}=\sigma(w^{[l]}a^{[l-1]}+b^{[l]}) a[l]=σ(w[l]a[l−1]+b[l])
到这里,我们已经讲完了前向传播的过程,值得注意的是,这里我们只有一个输入样本,对于多个样本同时输入的情况是一样的,只不过我们的输入向量不再是一列,而是m列,每一个都表示一个输入样本。
多样本输入情况下的表示为:
Z [ l ] = w [ l ] ⋅ A [ l − 1 ] + b [ l ] Z^{[l]}=w^{[l]}\cdot A^{[l-1]}+b^{[l]} Z[l]=w[l]⋅A[l−1]+b[l]
A [ l ] = σ ( Z [ l ] ) A^{[l]}=\sigma(Z^{[l]}) A[l]=σ(Z[l])
其中,此时 A [ l − 1 ] = [ ∣ ∣ … ∣ a [ l − 1 ] ( 1 ) a [ l − 1 ] ( 2 ) … a [ l − 1 ] ( m ) ∣ ∣ … ∣ ] A^{[l-1]}=\left[ \begin{array}{cc} |&|&\ldots&| \\a^{[l-1](1)}&a^{[l-1](2)}&\ldots&a^{[l-1](m)} \\ |&|&\ldots&|\end{array}\right] A[l−1]=⎣⎡∣a[l−1](1)∣∣a[l−1](2)∣………∣a[l−1](m)∣⎦⎤
每一列都表示一个样本,从样本1到m
w [ l ] w^{[l]} w[l]的含义和原来完全一样, Z [ l ] Z^{[l]} Z[l]也会变成m列,每一列表示一个样本的计算结果。
之后我们的叙述都是先讨论单个样本的情况,再扩展到多个样本同时计算。
2. 损失函数和代价函数
说实话,**损失函数(Loss Function)和代价函数(Cost Function)**并没有一个公认的区分标准,很多论文和教材似乎把二者当成了差不多的东西。
为了后面描述的方便,我们把二者稍微做一下区分(这里的区分仅仅对本文适用,对于其它的文章或教程需要根据上下文自行判断含义):
损失函数主要指的是对于单个样本的损失或误差;代价函数表示多样本同时输入模型的时候总体的误差——每个样本误差的和然后取平均值。
举个例子,如果我们把单个样本的损失函数定义为:
L ( a , y ) = − [ y ⋅ l o g ( a ) + ( 1 − y ) ⋅ l o g ( 1 − a ) ] L(a,y)=-[y \cdot log(a)+(1-y)\cdot log(1-a)] L(a,y)=−[y⋅log(a)+(1−y)⋅log(1−a)]
那么对于m个样本,代价函数则是:
C = − 1 m ∑ i = 0 m ( y ( i ) ⋅ l o g ( a ( i ) ) + ( 1 − y ( i ) ) ⋅ l o g ( 1 − a ( i ) ) ) C=-\frac{1}{m}\sum_{i=0}^m(y^{(i)}\cdot log(a^{(i)})+(1-y^{(i)})\cdot log(1-a^{(i)})) C=−m1i=0∑m(y(i)⋅log(a(i))+(1−y(i))⋅log(1−a(i)))
3. 反向传播
反向传播的基本思想就是通过计算输出层与期望值之间的误差来调整网络参数,从而使得误差变小。
反向传播的思想很简单,然而人们认识到它的重要作用却经过了很长的时间。后向传播算法产生于1970年,但它的重要性一直到David Rumelhart,Geoffrey Hinton和Ronald Williams于1986年合著的论文发表才被重视。
事实上,人工神经网络的强大力量几乎就是建立在反向传播算法基础之上的。反向传播基于四个基础等式,数学是优美的,仅仅四个等式就可以概括神经网络的反向传播过程,然而理解这种优美可能需要付出一些脑力。事实上,反向传播如此之难,以至于相当一部分初学者很难进行独立推导。所以如果读者是初学者,希望读者可以耐心地研读本节。对于初学者,我觉得拿出1-3个小时来学习本小节是比较合适的,当然,对于熟练掌握反向传播原理的读者,你可以在十几分钟甚至几分钟之内快速浏览本节的内容。
3.1 矩阵补充知识
对于大部分理工科的研究生,以及学习过矩阵论或者工程矩阵理论相关课程的读者来说,可以跳过本节。
本节主要面向只学习过本科线性代数课程或者已经忘记矩阵论有关知识的读者。
总之,具备了本科线性代数知识的读者阅读这一小节应该不会有太大问题。本节主要在线性代数的基础上做一些扩展。(不排除少数本科线性代数课程也涉及到这些内容,如果感觉讲的简单的话,勿喷)
3.1.1 求梯度矩阵
假设函数 f : R m × n → R f:R^{m\times n}\rightarrow R f:Rm×n→R可以把输入矩阵(shape: m × n m\times n m×n)映射为一个实数。那么,函数 f f f的梯度定义为:
∇ A f ( A ) = [ ∂ f ( A ) ∂ A 11 ∂ f ( A ) ∂ A 12 … ∂ f ( A ) ∂ A 1 n ∂ f ( A ) ∂ A 21 ∂ f ( A ) ∂ A 22 … ∂ f ( A ) ∂ A 2 n ⋮ ⋮ ⋱ ⋮ ∂ f ( A ) ∂ A m 1 ∂ f ( A ) ∂ A m 2 … ∂ f ( A ) ∂ A m n ] \nabla_Af(A)=\left[ \begin{array}{cc} \frac{\partial f(A)}{\partial A_{11}}&\frac{\partial f(A)}{\partial A_{12}}&\ldots&\frac{\partial f(A)}{\partial A_{1n}} \\ \frac{\partial f(A)}{\partial A_{21}}&\frac{\partial f(A)}{\partial A_{22}}&\ldots&\frac{\partial f(A)}{\partial A_{2n}} \\\vdots &\vdots &\ddots&\vdots\\ \frac{\partial f(A)}{\partial A_{m1}}&\frac{\partial f(A)}{\partial A_{m2}}&\ldots&\frac{\partial f(A)}{\partial A_{mn}}\end{array}\right] ∇Af(A)=⎣⎢⎢⎢⎢⎡∂A11∂f(A)∂A21∂f(A)⋮∂Am1∂f(A)∂A12∂f(A)∂A22∂f(A)⋮∂Am2∂f(A)……⋱…∂A1n∂f(A)∂A2n∂f(A)⋮∂Amn∂f(A)⎦⎥⎥⎥⎥⎤
即 ( ∇ A f ( A ) ) i j = ∂ f ( A ) ∂ A i j (\nabla_Af(A))_{ij}=\frac{\partial f(A)}{\partial A_{ij}} (∇Af(A))ij=∂Aij∂f(A)
同理,一个输入是向量(向量一般指列向量,本文在没有特殊声明的情况下默认指的是列向量)的函数 f : R n × 1 → R f:R^{n\times 1}\rightarrow R f:Rn×1→R,则有:
∇ x f ( x ) = [ ∂ f ( x ) ∂ x 1 ∂ f ( x ) ∂ x 2 ⋮ ∂ f ( x ) ∂ x n ] \nabla_xf(x)=\left[ \begin{array}{cc}\frac{\partial f(x)}{\partial x_1}\\ \frac{\partial f(x)}{\partial x_2}\\ \vdots \\ \frac{\partial f(x)}{\partial x_n} \end{array}\right] ∇xf(x)=⎣⎢⎢⎢⎢⎡∂x1∂f(x)∂x2∂f(x)⋮∂xn∂f(x)⎦⎥⎥⎥⎥⎤
注意:这里涉及到的梯度求解的前提是函数 f f f 返回的是一个实数,如果函数返回的是一个矩阵或者向量,那么我们是没有办法求梯度的。比如,对函数 f ( A ) = ∑ i = 0 m ∑ j = 0 n A i j 2 f(A)=\sum_{i=0}^m\sum_{j=0}^nA_{ij}^2 f(A)=∑i=0m∑j=0nAij2,由于返回一个实数,我们可以求解梯度矩阵。如果 f ( x ) = A x ( A ∈ R m × n , x ∈ R n × 1 ) f(x)=Ax (A\in R^{m\times n}, x\in R^{n\times 1}) f(x)=Ax(A∈Rm×n,x∈Rn×1),由于函数返回一个 m m m行1列的向量,因此不能对 f f f求梯度矩阵。
根据定义,很容易得到以下性质:
∇ x ( f ( x ) + g ( x ) ) = ∇ x f ( x ) + ∇ x g ( x ) \nabla_x(f(x)+g(x))=\nabla_xf(x)+\nabla_xg(x) ∇x(f(x)+
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4147
4147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











