






图像压缩作为计算机视觉领域的基础问题,随着深度学习技术的进步,也开始迎来新的发展,本文汇总CVPR 2021 中图像压缩相关论文,基本代表这一领域的最新前沿,希望对大家有帮助。
大家可以在:
https://openaccess.thecvf.com/CVPR2021?day=all
按照题目下载这些论文。
如果想要下载所有CVPR 2021论文,请点击这里:
图像压缩
Attention-guided Image Compression by Deep Reconstruction of Compressive Sensed Saliency Skeleton
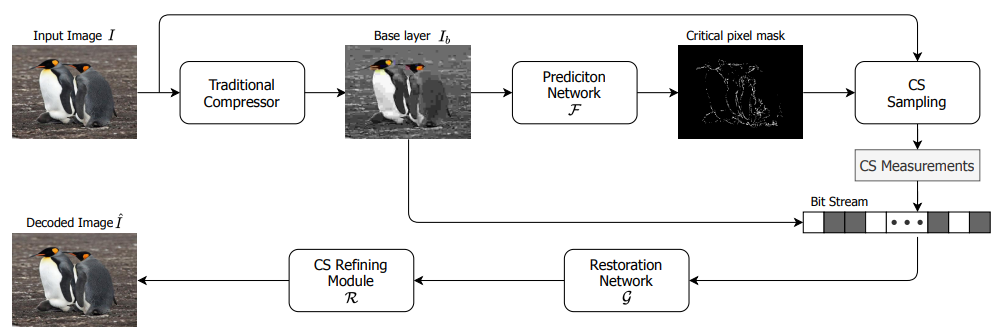
文章提出一个用于注意力引导的双层图像压缩(AGDL)的深度学习系统。在AGDL 压缩系统中,图像被编码成两层,一个基础层和一个注意力引导的 refinement 层。
与现有的 ROI 图像压缩方法不同的是,它将额外的比特预算平均用于 ROI 的所有像素。AGDL 采用一个 CNN 模块来预测 ROI 内的显著性草图上和附近的那些对感知质量至关重要的像素。只有关键像素通过压缩感应(CS)进一步采样,形成一个非常紧凑的 refinement 层。以及开放了另一种新的 CNN方法,用于联合解码两个压缩层,以实现更精细的重建,同时严格满足感知上关键像素的传输 CS 约束。
广泛的实验表明,所提出的 AGDL 系统推动了感知图像压缩技术的发展。
作者 | Xi Zhang, Xiaolin Wu
单位 | 上海交大学;麦克马斯特大学
论文 | https://arxiv.org/abs/2103.15368
Slimmable Compressive Autoencoders for Practical Neural Image Compression
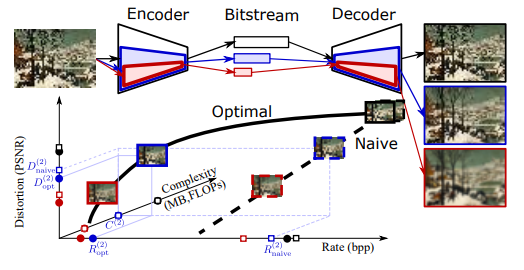
神经图像压缩利用深度神经网络,在速率-失真性能方面优于传统图像编解码器。但由此产生的模型重,计算要求很高,而且通常针对单一速率进行优化,限制了它们的实际使用。
本次工作 focus 实际的图像压缩,提出轻量级压缩式自动编码器(SlimCAEs),其中速率(R)和失真(D)针对不同的容量进行联合优化。一旦经过训练,编码器和解码器可以在不同的容量下执行,从而导致不同的速率和复杂度。作者表示 SlimCAEs 的成功实施需要适当的特定容量的 RD 权衡。
通过实验验证表明,SlimCAEs 是高度灵活的模型,具有出色的速率失真性能,可变速率,以及动态调整内存、计算成本和延迟,从而解决了实际图像压缩的主要要求。
作者 | Fei Yang, Luis Herranz, Yongmei Cheng, Mikhail G. Mozerov
单位 | 西北工业大学;西班牙巴塞罗那自治大学
论文 | https://arxiv.org/abs/2103.15726
代码 | https://github.com/FireFYF/SlimCAE
Checkerboard Context Model for Efficient Learned Image Compression
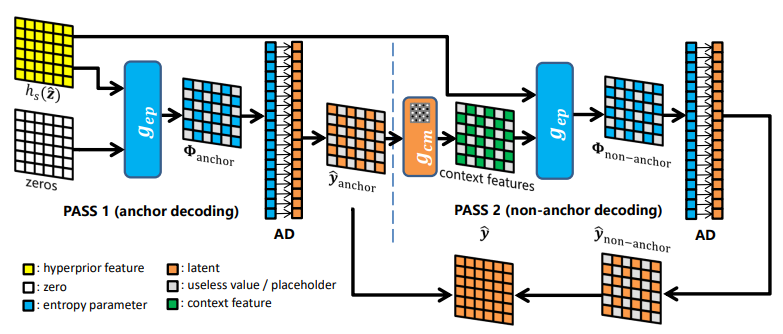
对于学习型图像压缩,自回归上下文模型可以有效地改善速率-失真(RD)性能。因为它有助于消除隐藏表征之间的空间冗余。但解码过程必须按照严格的扫描顺序进行,因此会破坏并行化。
文章提出一个可并行的棋盘式上下文模型(CCM)来解决这个问题。双通道棋盘上下文计算通过重新组织解码顺序消除了对空间位置的这种限制。实验中,解码过程加快了40多倍,在几乎相同的速率-失真性能下,实现了计算效率的显著提高。
作者称这是第一次对学习型图像压缩的并行化友好空间背景模型的探索。
作者 | Dailan He, Yaoyan Zheng, Baocheng Sun, Yan Wang, Hongwei Qin
单位 | 商汤
论文 | https://arxiv.org/abs/2103.15306
Learning Scalable ℓ∞-constrained Near-lossless Image Compression via Joint Lossy Image and Residual Compression
作者 | Yuanchao Bai, Xianming Liu, Wangmeng Zuo, Yaowei Wang, Xiangyang Ji
单位 | 鹏城实验室;哈尔滨工业大学;
论文 | https://arxiv.org/abs/2103.17015
代码 | https://github.com/BYchao100/Scalable-Near-lossless-Image-Compression
视频 | CVPR 2021 图像压缩最新进展

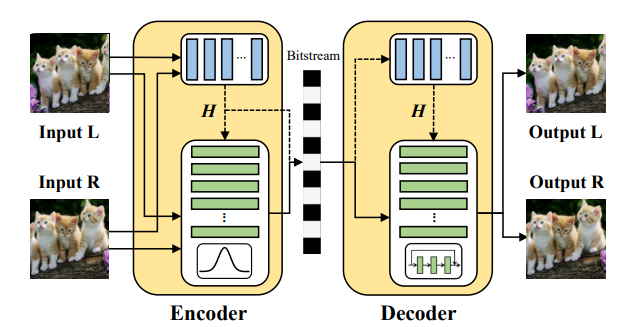
Deep Homography for Efficient Stereo Image Compression
作者 | Xin Deng、Wenzhe Yang、Ren Yang、Mai Xu2、Enpeng Liu、 Qianhan Feng、Radu Timofte
单位 | 北航;苏黎世联邦理工学院
论文 | http://buaamc2.net/pdf/cvpr21hesic.pdf
代码 | https://github.com/ywz978020607/HESIC
视频 | CVPR 2021 图像压缩最新进展
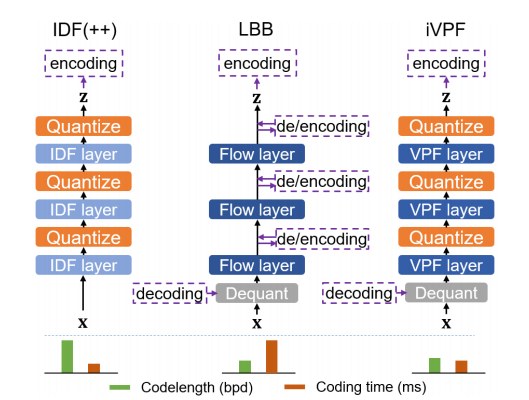
iVPF: Numerical Invertible Volume Preserving Flow for Efficient Lossless Compression
本次工作研究了用于无损压缩的 volume preserving flows,并表明无误差的双向映射是可能的。提出由一般体积保全流派生出来的 Numerical Invertible Volume Preserving Flow(iVPF)。通过在流模型上引入新的计算算法,实现了精确的双向映射,没有任何数字错误。还提出一种基于 iVPF 的无损压缩算法。在各种数据集上的实验表明,与轻量级压缩算法相比,基于 iVPF 的算法实现了最先进的压缩率。
作者 | Shifeng Zhang, Chen Zhang, Ning Kang, Li Zhenguo
单位 | 诺亚方舟实验室
论文 | https://arxiv.org/abs/2103.16211
What’s in the Image?Explorable Decoding of Compressed Images
作者 | Yuval Bahat 、 Tomer Michaeli
单位 | 以色列理工学院
论文 |
https://openaccess.thecvf.com/content/CVPR2021/papers/Bahat_Whats_in_the_Image_Explorable_Decoding_of_Compressed_Images_CVPR_2021_paper.pdf

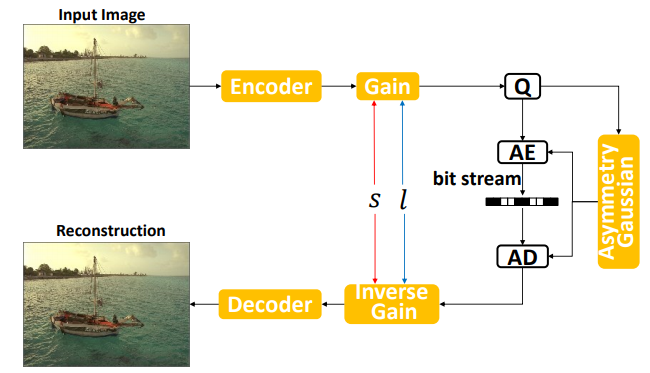
Asymmetric Gained Deep Image Compression With Continuous RateAdaptation
文章提出一个连续速率可调的学习型图像压缩框架,即Asymmetric Gained Variational Autoencoder(AGVAE)。AG-VAE 利用一对增益单元,在一个单一的模型中实现离散的速率适应,其额外的计算量可以忽略不计。然后,通过使用指数插值,在不影响性能的情况下实现连续的速率适应。此外,还提出 asymmetric Gaussian entropy ,以实现更准确的熵估计。
通过详细的实验表明,所提出方法实现了与 SOTA 学习的图像压缩方法相当的定量性能,并且比经典的图像编解码器有更好的定性性能。在消融研究中,也证实了增益单元和不对称高斯熵模型的有用性和优越性。
作者 | Ze Cui、Jing Wang、Shangyin Gao、Tiansheng Guo、Yihui Feng、Bo Bai
单位 | 华为
论文 |
https://openaccess.thecvf.com/content/CVPR2021/papers/Cui_Asymmetric_Gained_Deep_Image_Compression_With_Continuous_Rate_Adaptation_CVPR_2021_paper.pdf
- END -
编辑:CV君
转载请联系本公众号授权

备注:增强

图像增强与质量评价交流群
图像增强、去雾、去雨、图像修补、图像恢复等技术,
若已为CV君其他账号好友请直接私信。
在看,让更多人看到 















 3069
3069











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









