







前言
此篇博客仅供自己观看,记录实验复现中的问题。
本实验在实验室集群跑
1、数据集准备
数据集取自于 ImageNet Validation dataset,该数据集中包含50000 张 JPEG 图像,从中取最大的 16000 张作为训练集,再取剩余图像中最大的2000 张作为测试集。
λ 的值设置为{0.0016, 0.0032, 0.0075, 0.015, 0.03, 0.045},对应六个不同码率的模型,前三个模型的超参数设置为 N = 192,M = 192,后三个模型为 N = 192, M = 320。
2、调用train.py进行训练
调用脚本进行训练,调用.sh脚本方法
python3 -u train.py -d /home/disk/lilin/datasets/imageNet --epochs 501 -lr 1e-4 --lambda 0.0016 --batch-size 16 --cuda --save > log.out
3、整理训练流程
- 读取数据集地址,加载数据集
- 将数据集分为训练集与测试集,然后随机剪裁数据中的图片为patchsize*patchsize大小
- 加载构建好的网络模型
- 将设置好的模型与相应设置的参数传入优化器
- 判断是否有训练一部分的模型,如果有则继续训练,如果没有则重新开始
- 若重新开始训练模型,则将数据送入优化器,进行正向传播与反向梯度传播,并计算bpp、mse、loss的均值打印(10次迭代打印一次)计算率失真损失,并保存节点信息
4、整理三维棋盘格网络模型
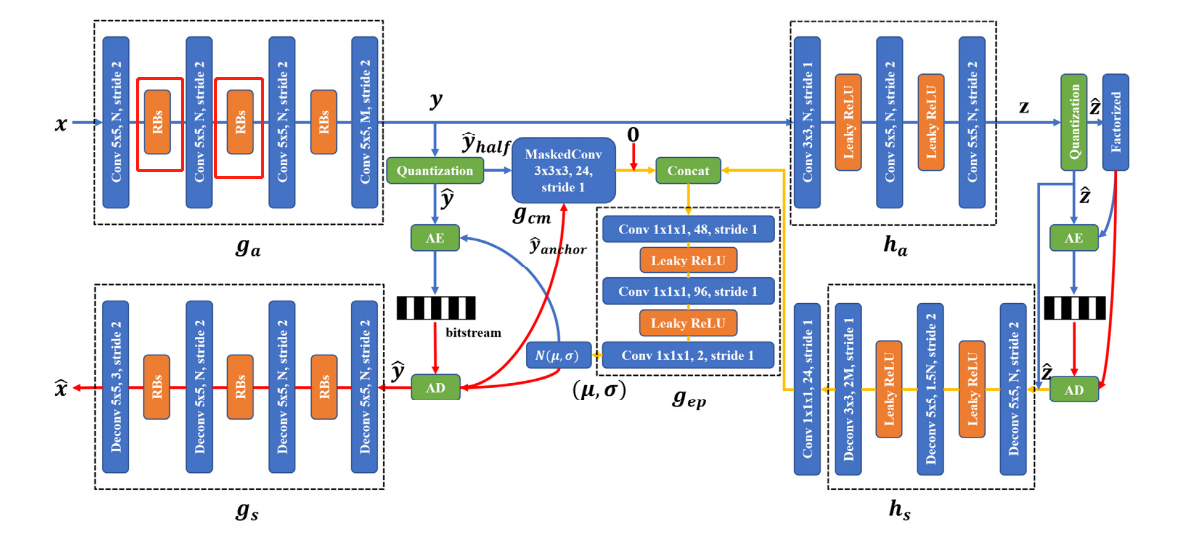
主要框架沿用JointAutoregressiveHierarchicalPriors的部分(compressai中直接引用),改动的仅仅是上下文模型与熵模型建模建模,所以下面只针对这两部分模进行说明
4.1 JointAutoregressiveHierarchicalPriors整体架构
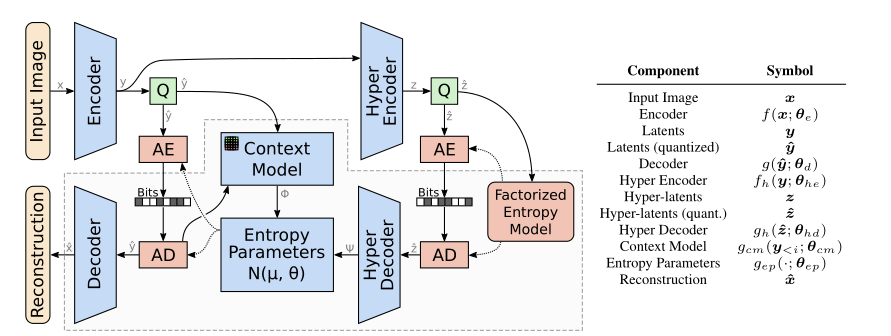
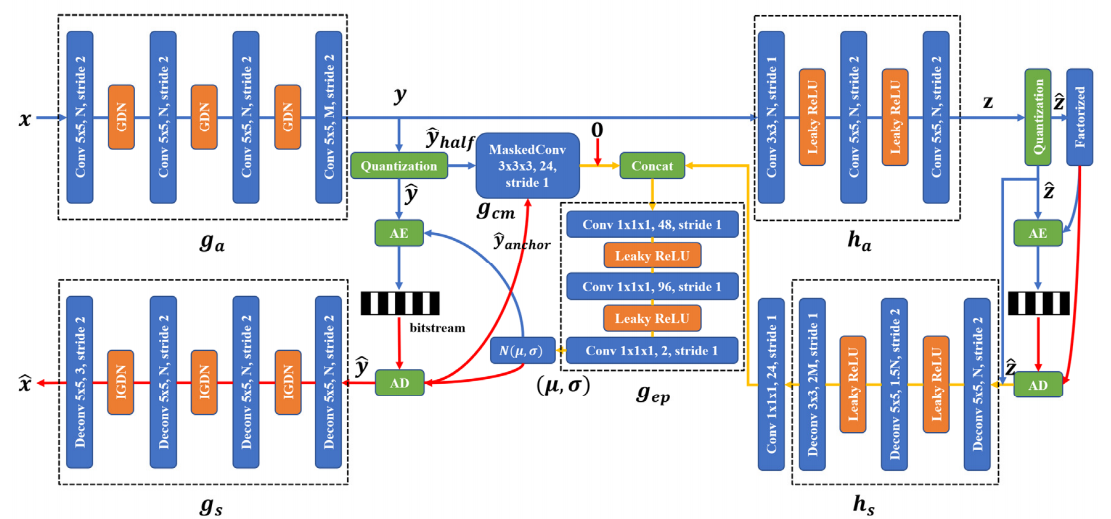
4.2 基于三维棋盘格上下文模型的超先验变分自编码器
4.2.1 模型初始化
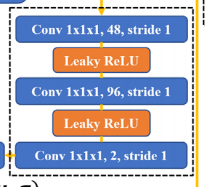
初始化以24为基的通道数G、高斯建模、偏差、3d卷积、熵模型网络gep
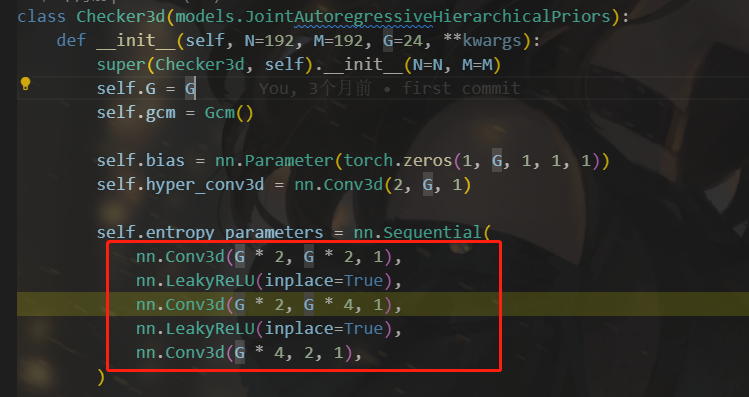
4.2.2 模型的前向传播
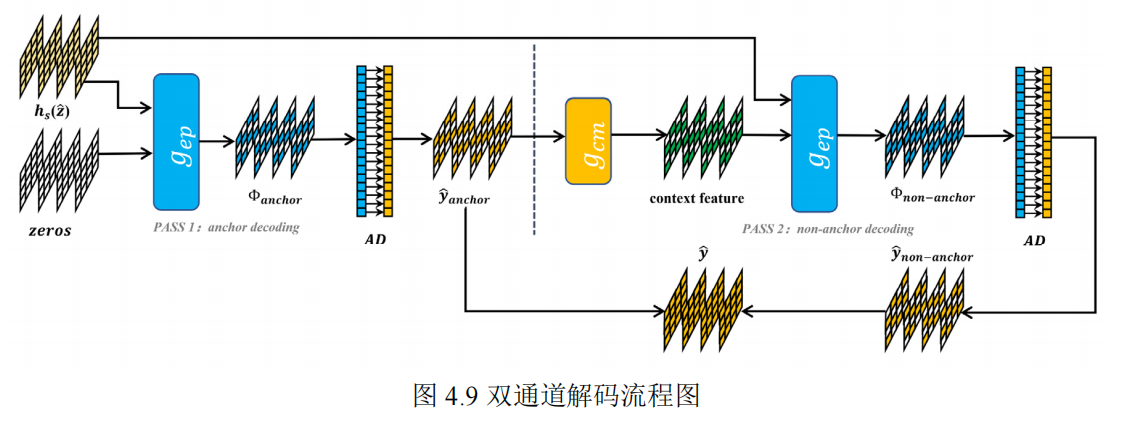
- 通过输入的x,通过g_a、h_a获取隐表示y与超隐表示z
- 获取量化后的y_hat、z_hat
- 将上述信息送入h_s获取超先验解码信息并进行shape重塑
- 根据y_hat的shape初始化锚点与非锚点(hs与0结合形成锚点)
- 锚点对应的y_hat经过熵模型建模得到对应的概率分布信息,经过熵解码得到解码后的锚点yanchor
- 通过锚点送入三维棋盘格上下文模型获取非锚点,非锚点经过熵模型建模获取其对应的特征概率分布信息,进而通过解码器获取解码后的ynon-anchor,并且仅为非锚位置添加偏差以加快收敛速度(添加掩膜)
- 合并锚点与非锚点
- 获取整合后的方差、均值信息送入高斯建模
- 最后将y_hat送入g_s解码,获取重建的x_hat
4.2.3 模型的压缩方法compress
- 通过原始输入x,通过g_a、h_a,获取对应的隐表示y、超隐表示z
- 超隐表示z通过量化、熵编码得到对应的二进制比特流z_strings
- z_strings通过熵解码、h_s后得到z_hat(concat右侧支路走完)
- 从y出发,初始化分为锚点与非锚点
- 锚点部分正常量化、编码,解码,并将解码后的锚点部分送入上下文模型
- 根据锚点,对非锚点进行解码(添加掩膜)
- 将上述三部分信息(锚点、非锚点、z_strings)送入高斯建模,进而编码得到对应二进制比特流(锚点、非锚点不合并,直接得到两部分比特流)
4.2.4 模型的解压缩方法decompress
- 从编码后获取的二进制比特流中获取解码获取z_hat
- z_hat经过h_s获取超先验网络解码信息
- h_s(z)进入解码双通道解码流程
- 首先通过熵模型获取锚点的概率特征分布,进而解码获取对应的yanchor,将yanchor送入上下文模型,获取非锚点信息
- 将非锚点信息送入熵模型建模,获取对应的特征概率分布,进而解码获取对应的解码后的ynon-anchor
- 整合锚点与非锚点信息,一起送入g_s获取对应重建的x_hat
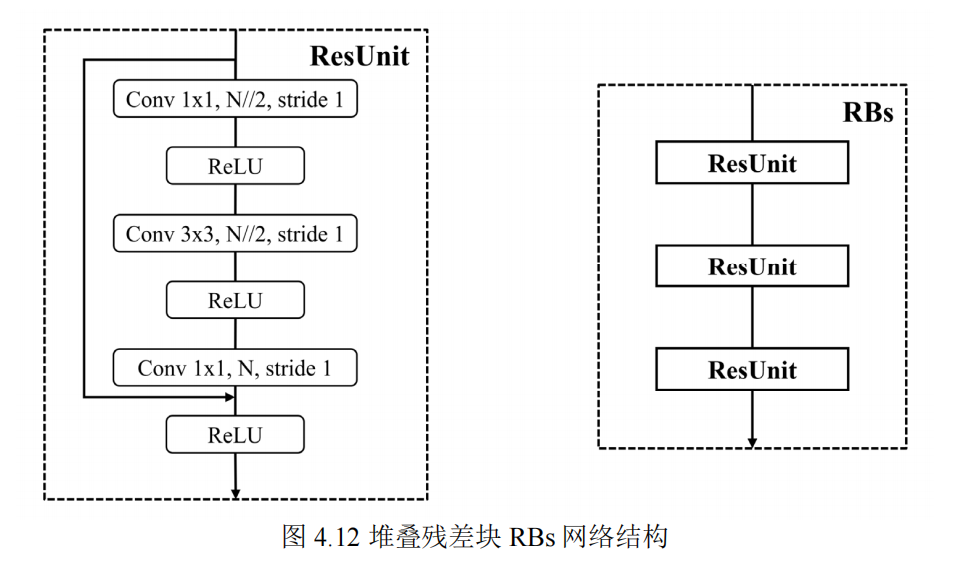
4.3 基于三维棋盘格上下文模型和堆叠残差块 RBs 的超先验变分自编码器
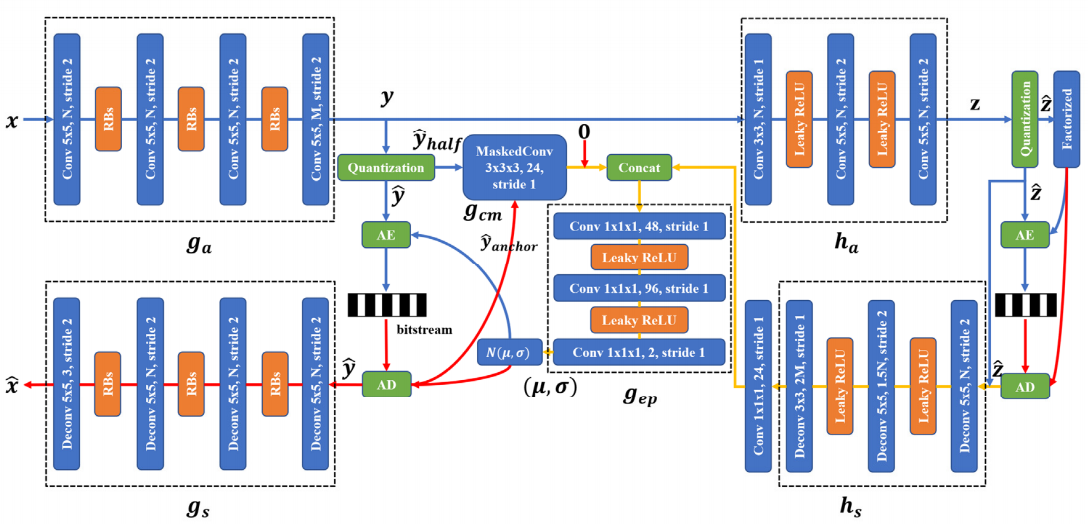
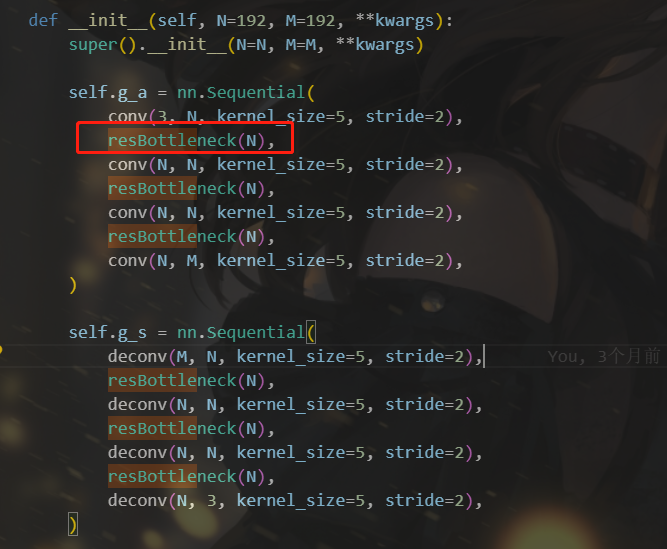
主要内容与上述基于三维棋盘格上下文模型的超先验变分自编码器一直,主要区别是g_a、g_s的激活函数换做了堆叠残差块的RBs。
由于这里是在主要框架中进行更改的激活函数,所以这里的网络不再引用compressai中的JointAutoregressiveHierarchicalPriors,而是将google.py复制出来,改动其中JointAutoregressiveHierarchicalPriors的网络结构的激活函数

4.3.1 RBs结构
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 485
485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









