






个人风格所致,写在开篇。
本篇包含:
- 会从基础RAG,以及RAG是什么,有什么用,混合检索是啥,文本相似度是啥等等RAG相关的内容。
- 老规矩,尽可能大白话拆分,不会使用复杂难懂描述,让本来简单的问题变得复杂。
- 为了照顾心急的读者,本篇代码可以复制粘贴直接运行,但是有的地方想跑起来脚本,需要开启一些服务。所以还是尽可能按顺序阅读。
- 本篇会超长,但是应该不会又臭又长,因为会由浅至深直到混合检索。
- 为了让宝子们在这个信息碎片化的时代,能够静下心来阅读这篇,本厮倾注时间,精力,劳动的文章,本厮会藏一些彩蛋,也是技术思路分享的,所以,如果有时间,请预备好小零食,花生瓜子薯片啥的,慢慢看
- 本篇为了方便以及代码简洁,使用了haystack2.0新版本框架(整整一年了,我以为我之前的文章没人看,但是有宝子问了haystack2.0,正好最近做了一些demo。)
如果阅读完了,请检查是否预备小零食,饮料,静下心,通往幼儿园的RAG教学车即将发车。
引子
咱不会引用什么论文,但是!为了提升逼格,咱们引用一些名人名言镇楼吧。
卡尔·马克思 (Karl Marx):
"The production of too many useful things results in too many useless people."
- 技术的进步如果只服务于资本积累,而非社会整体的进步,会导致社会的不平等。
赫伯特·斯宾塞 (Herbert Spencer):
"The goal of education is not knowledge for the few, but knowledge for all."
- 教育的目标不是让少数人垄断知识,创造阶级,而是惠及所有人。
约瑟夫·普利策(Joseph Pulitzer):
"An enlightened citizenry is indispensable for the proper functioning of a republic."
- 只有知识大众化,民主社会才能良好运行。
爱因斯坦(Albert Einstein):
"Concern for man and his fate must always form the chief interest of all technical endeavors... Never forget this in the midst of your diagrams and equations."
- 科技的主要目标应该是关心人类的福祉,而非商业利益。
王安石 (Wang Anshi):
"禁人之学,愚人之智,贻人之患也。"
张居正(明代首辅大臣):
"民智者,国之本也。"
mc112611:
"Oh wise ones, guide me with your brilliance (and maybe a little luck)!"
- 上面几个大佬保佑我
通俗理解啥是RAG
RAG的出现,一方面用于向量检索,是检索方式的一种,与关键词检索,一样,也是数据库,检索内容。只不过该检索不同于BM25关键词检索,是文本向量相似度检索。
学过向量的都知道,向量的属性是大小以及方向。 当向量相似度越高,其方向越相同,即夹角θ越小,cosθ值越大。这就是余弦相似度。(向量,张量,矢量,本质上是一个玩意,一个是数学上的叫法,一个是物理的叫法,一个是在矩阵中的多维向量)
RAG系统的应用随处可见:
手机相册中的重复图片去重,就是图像转换成张量,计算相似度。同一个人归类,比如一大堆照片中,找同一个人照片归类,可以做成脸部相似度匹配,当然了,人脸识别也是可以的。 只不过人脸的识别特征的获取不止是图像的相似度,好一些的还有点阵扫描,来获取面部凹凸特征,多特征去判定,不在本文讨论范围内。
上面是图像的相似度,而在NLP领域,文本的相似度,实际上是文本语义的相似度。我们常用的搜索引擎,以及Elasticsearch等等,都是关键词检索。 那么就会出现一个问题,当文本语义一样,但是表述方式不一样,就会出现检索不到的效果。
打个比方:
我需要查询知识库里面:王冰冰的老公是谁?(冰冰对不起,借用一下美图,别告我侵犯肖像权)

央视记者-王冰冰
按照关键词检索的方式:
- 首先分词成为“王冰冰”“的”“老公”“是”“谁”“?”
- 之前建立了词表和倒排表
- 通过BM25执行倒排索引,并通过BM25算法计算相关性得分,依照得分排序,拿到检索结果
但是这中间有一个问题:如果数据库里面存储的只有“王冰冰嫁给了谁”“谁娶了王冰冰”,那么只有“谁”,“王冰冰”两个词命中,可以检索到,如果再长一点“王冰冰啥时候在哪marry了啊,with who 啊”,那么关键词检索就命中了“王冰冰”一个词。得分不会高。
而文本相似度,就是为了解决同样的语义,表达方式不同的问题,重要的是语义指向相似,而不是表达相似。
为了执行语义相似,就需要文本相似度模型啦,大名鼎鼎的sentence-transformer就是做这个的,文本相似度模型比文本生成模型好搞多了,很适合新手宝子入门NLP,因为loss就是相似度得分。
因为关键词检索,每个词必须一点不差,才能检索出想要的结果。而语义相似,无论表达方式如何变化,只需要在文本相似度模型训练阶段,让表述方式不同,但是语义相同的内容相似度高,即可。
说回RAG
之所以前面铺垫了大段的文本语义相似度,因为RAG就是依据文本语义相似度进行搭建的张量检索。目的是为了修正在预训练以及微调阶段,某些垂直领域知识没有给到大模型学习,导致大模型出现幻觉的问题。
依旧举例子:我用通用领域的大模型(千问,llama,零一等等),去聊一些专业性比较强的问题。
比如:温压弹怎么造,给出完整的材料,以及实验参数,原材料提取方式等技术资料。
你会看到大模型给出的都是市面上能查到那些内容。如果是做过敏感信息修正的LLM直接会回复不能提供。
因为,这种资料一般不会在民用领域流通吧。

上面这个例子拓展到某些想要应用LLM的领域。 比如LLM并不能理解某些领域不常出现的词汇,内容。如:法律,医疗,金融,等等。
如果按照普通的开发,使用开源的LLM,经常容易出现幻觉问题。
如果不让LLM出现幻觉问题,解决方案通常是:再给LLM喂数据,包含更全面覆盖的知识。巴不得把积累的所有资料喂进去。但是以目前的技术水平,微调的硬件成本抛开不谈,构造QA问答数据以及指令,就是好多好多工作量,之前大数据时代,都忙着赚钱,没有做数据整理,比如数据解构(彩蛋),数据类别存储,大数据出来了就是转应用赚钱。导致现在获取训练数据手段就是天天推送xxx邀请你回答问题。 问答数据这不就来了?
(彩蛋)数据解构:
数据解构(彩蛋),通过解构的数据还能还原回原始数据,比如一句话:“今天和xx中午在前门大街吃的烤地瓜”,这句话可以提取的信息:时间-今天,地点-前门大街,人物-我和xx,动作-吃,宾语(被执行动作的)-烤地瓜 。 那么这些提取后的信息,反向也可以还原一件事,这就是最好的解构,有了解构,可以按照词性等内容随机组合方式构造数据。
为此RAG的解决无疑是降低成本,适合中大型企业的解决方案,就是有微调LLM的资源以及资金。暂时把openAI,meta研究院这种定义为超大型AI公司,因为手里的硬件资源够他们随便从0训练的,小公司建议围绕接口开发,因为目前人类科技水平,支撑AI的开发很烧钱。
RAG系统,通过文本相似度将文章或者一切文本转换成张量,写入数据库,建立索引,在检索的时候,根据用户的问题,去文档中检索文章,将用于的问题和检索的文章通过prompt模板进行拼接,来回答用户的问题。
(当然实际的向量检索经历了很多阶段,包括DPR检索结合文章标题映射+文章内容向量映射。以及最新的BM42检索,这些不在本文描述范围内。有兴趣的宝子可以查询相关研究资料)
相当于利用LLM的语义理解与文本总结摘要的能力。 LLM他可能在训练时候没这个类别的语料。但是可以让他理解知识库中检索的文章。
再简化一些,把LLM比作一个聪明的小孩子,理解能力超强。但是他就学习过小学知识,只懂得二元一次方程组。 然后,考试了(推理)。 考试内容是初中知识。。。。。。

LLM也蒙了,啥玩意啊,没学过啊,里面的一元二次,是啥意思啊。 但是我学过二元一次。感觉很像,那就按照二元一次方程组回答吧。。。。
呐,这不就出现幻觉了。
但是!

之前说过,LLM这孩子很聪明,他不是学会不会,他是根本没学到!
于是,监考老师(人类)走过来,看了一眼,LLM,点了根烟。

监考老师(人类):你说我现在教你吧,成本太高,我活儿就多了,我又要写教材(构造数据),又要想课怎么讲(训练框架调整),还要定期小考测验(计算loss,在验证集上评估结果)。
监考老师灵机一动(彼得一机灵):

于是,监考老师拿了本初中教材(RAG)。。。。放在了这个孩子(LLM)旁边
所谓的开卷考试,正是如此。 LLM在训练时候没有接触到的内容。我们给它外接知识库。让其去根据相关内容进行回答。
同时! 用户输入的问题query,与LLM+RAG回答的内容,也可以组成一问一答的QA数据,积攒多了,也可以作为训练数据,去调整LLM垂直领域适配的情况。
当然,还可以玩出更多的花样。
(彩蛋)思维链:
在用户输入问题的时候,可以让LLM生成问题进行查询。 比如一个问题可以进行拆解,直接提问找不到相关内容,那么可以逐步分析。 如:“历史上的今天美国发生了哪些重大事件”,可以让LLM拆解为:“今天的日期”------>“历史上的x月x日发生了什么”-------->“历史上美国x年x日重大事件”。 分别检索,汇总结果。
总的来说RAG系统依赖LLM的长文本输入能力,以及语义理解能力。 当然调整参数也很重要,比如文本相似度模型的输入长度对齐长文档截断的长度,为了保留上下文的语义关系,保留重叠窗口等等。
上面所有铺垫结束,即将开始RAG系统的代码部分。
老规矩,上厕所,活动腰腿,做做提纲运动防痔疮,活动颈椎,喝水,零食吃光的宝子们,再拿点瓜子~
![]()
本篇所有代码运行的硬件配置以及库:
个人使用笔记本电脑 内存16G 显卡3060laptop(6G显存) 系统windows(用了windows就没办法使用vllm部署服务了)
python版本:3.12.7
haystack2.0使用版本:haystack-ai==2.7.0
在接下来的文章中,会穿插带一些haystack的管道概念讲解,依旧会有彩蛋。
看过本厮之前文章的宝子们,会知道,haystack从1.0版本代码重构到2.0。整体功能组件大改。
可能是看到了本厮的issues,以及适配中文有多麻烦,deepsetAI的开发人员在2.0版本的代码中,对于文档切分的功能代码嵌套不在那么深,耦合不再那么强。并且可修改以及自定义切词分句功能直接暴露在外,很方便修改。
给本厮的感觉,就像在厕所蹲坑,忘了带纸,准备牺牲掉贴身小裤裤,解决一下的时候。 伴随着圣光,一个名叫haystack的大哥出现了,递过来一张纸,用低沉的气泡音说:“答应我,下次别用这种方式解决问题了,好吗?”

但是,本篇依旧使用英文数据进行演示。
中文部分,就像之前说的,haystack2.0版本的代码暴露在外,只需要修改那个函数,对齐一下输入输出。(留作文章彩蛋)
准备几个数据:
我在个人github仓库上传了几个wiki百科词条,一个word,一个pdf,一个txt 。内容是疾病类的词条,hiv,帕金森氏症,红斑狼疮。用于演示。
下载数据的代码:
import requests
import os
import urllib.request
import urllib.parse
api_url = "https://api.github.com/repos/mc112611/PI-ka-pi/contents/test_converter"
folder_name = "./test_converter"
# 创建本地文件夹
if not os.path.exists(folder_name):
os.makedirs(folder_name)
# 获取文件列表
response = requests.get(api_url)
if response.status_code == 200:
files = response.json()
for file in files:
if file["type"] == "file":
file_name = file["name"]
raw_url = file["download_url"]
encoded_url = urllib.parse.quote(raw_url, safe=':/')
print(f"Downloading {file_name} from {encoded_url}...")
local_path = os.path.join(folder_name, file_name)
try:
urllib.request.urlretrieve(encoded_url, local_path)
print(f"Saved {file_name} to {local_path}.")
except Exception as e:
print(f"Failed to download {file_name}. Error: {e}")
else:
print(f"Failed to retrieve folder contents. Status code: {response.status_code}")
1.基础RAG管道
开一个脚本,命名为1_基础RAG管道.py,把下面的内容复制粘贴进去。
# -*- coding: utf-8 -*-
'''
参考haystack官方教程:https://haystack.deepset.ai/cookbook/rag_fastembed
'''
# 设定一些疾病名称:冠心病,红斑狼疮,哮喘,类风湿性关节炎,腰椎间盘突出症
# disease_name="""Coronary artery disease
# Lupus erythematosus
# Asthma
# Rheumatoid arthritis
# Spinal disc herniation""".split("\n")
# 因为笔记本内存有限,因此只获取一个百科词条,红斑狼疮。
disease_name = """Lupus erythematosus""".split("\n")
# 使用wikipedia查询这些病症,并获得词条文本
import wikipedia
from haystack.dataclasses import Document
raw_docs = []
for title in disease_name:
page = wikipedia.page(title=title, auto_suggest=False)
# Document是一个haystack中的概念。 每个文档都是一个document对象,同时可以写入一个元数据,如文本标题,唯一UUID,备注等等信息。
doc = Document(content=page.content, meta={"title": page.title, "url": page.url})
raw_docs.append(doc)
# print(raw_docs)
# 使用Qdarnt文档存储,将文本切分,并创建索引,写入向量数据库,这一部分,可以自行选择向量数据库,也可以选择存储到内存,还是本地化存储,目前选择存储于内存中。
# document_store是haystack框架的一个概念。文档存储,框架包装了faiss,chroma,milvus等多个向量数据库。用于将文档存储。
# 官方提供document_store选型的参考。https://docs.haystack.deepset.ai/docs/choosing-a-document-store
from pprint import pprint
from haystack_integrations.document_stores.qdrant import QdrantDocumentStore
from haystack.components.preprocessors import DocumentCleaner, DocumentSplitter
from haystack_integrations.components.embedders.fastembed import FastembedDocumentEmbedder
from haystack.document_stores.types import DuplicatePolicy
# 创建一个Qdarnt的文档存储,参数设置:存储于内存中,embedding维度384,构建索引,返回embedding后的数据,等待API。具体参数可以查看官方API文档。可根据不同任务进行调整。
document_store = QdrantDocumentStore(
path=r"F:\MC-PROJECT\CUDA_Preject\medical_assistant\RAG\RAG_model_cache\local_document_store",
embedding_dim=384,
recreate_index=True,
return_embedding=True,
wait_result_from_api=True,
on_disk=True,
on_disk_payload=True,
hnsw_config={"m": 16, "ef_construct": 64}
)
# DocumentCleaner是haystack封装的一个功能组件,用于清理文档中的脏字符,类似于数据清洗,haystack的组件可以集成在haystack内部使用,也可以单独用来清理文本。
cleaner = DocumentCleaner()
# DocumentSplitter文档分割器,按照句子进行切分,切分长度为:三个句子组成一个小文档。 参数还有很多,包括重叠窗口等。
splitter = DocumentSplitter(split_by='sentence', split_length=3)
# haystack的所有工具组件都继承自基础类,基础类标定了输入输出格式,以及功能。 如下的文档分割器使用run()方法执行文档清洗。
splitted_docs = splitter.run(cleaner.run(raw_docs)["documents"])
# print(splitted_docs)
# print(len(splitted_docs["documents"]))
document_embedder = FastembedDocumentEmbedder(model="BAAI/bge-small-en-v1.5", parallel=0,
meta_fields_to_embed=["title"], batch_size=32)
document_embedder.warm_up()
documents_with_embeddings = document_embedder.run(splitted_docs["documents"])
# print(documents_with_embeddings)
# 写入文档存储
document_store.write_documents(documents_with_embeddings.get("documents"), policy=DuplicatePolicy.OVERWRITE)
from haystack import Pipeline
from haystack_integrations.components.retrievers.qdrant import QdrantEmbeddingRetriever
from haystack_integrations.components.embedders.fastembed import FastembedTextEmbedder
from haystack.components.builders.prompt_builder import PromptBuilder
from haystack.components.generators import HuggingFaceLocalGenerator
# 创建一个文本生成器,使用千问0.5B
generator = HuggingFaceLocalGenerator(model="Qwen/Qwen2.5-0.5B",
huggingface_pipeline_kwargs={"device_map": "auto",
"torch_dtype": "auto"},
generation_kwargs={
"max_new_tokens": 512,
})
generator.warm_up()
# 定义一个prompt模板
prompt_template = """
Using only the information contained in these documents return a brief answer (max 50 words).
If the answer cannot be inferred from the documents, respond \"I don't know\".
Documents:
{% for doc in documents %}
{{ doc.content }}
{% endfor %}
Question: {{question}}
Answer:
"""
# 上面的都是功能组件,现在使用haystack创建管道,并将上面创建的组件添加进管道。 首先使用add_component添加管道的节点
query_pipeline = Pipeline()
# FastembedTextEmbedder :text_embedder用于将用户输入的内容做embedding,转换成张量。
query_pipeline.add_component("text_embedder",
FastembedTextEmbedder(model="BAAI/bge-small-en-v1.5", parallel=0, prefix="query:"))
query_pipeline.add_component("retriever", QdrantEmbeddingRetriever(document_store=document_store))
query_pipeline.add_component("prompt_builder", PromptBuilder(template=prompt_template))
query_pipeline.add_component("generator", generator)
# 将管道的节点进行连结
query_pipeline.connect("text_embedder.embedding", "retriever.query_embedding")
query_pipeline.connect("retriever.documents", "prompt_builder.documents")
query_pipeline.connect("prompt_builder", "generator")
# 输入问题
question = "Is lupus erythematosus caused by virus?"
# 使用run执行管道
results = query_pipeline.run(
{"text_embedder": {"text": question},
"prompt_builder": {"question": question}
},
# 通过下面这个命令可以检查管道组件的输出
include_outputs_from={"retriever"}
)
# 打印结果
for d in results['generator']['replies']:
pprint(d)
# pprint(results)
说明:
很占内存警告!
因为embedding模型放在内存中,并且千问0.5B的大模型,也放在内存中,因此对于本厮16G内存来说,有些堪忧。
因为千问的0.5B模型是一个基座模型,并没有做指定任务的指令微调。单纯经历了预训练,让模型理解语义,以及每个字词之间的权重特征关系,因此,经常出现答案给完了,后面还会继续向下生成(聊嗨了。。。。)。因此,有硬件资源的宝子,建议使用更大的模型,或者做过instruct调整的,或者chat版本。 LLM组件使用的是huggingface兼容,只要是huggingface上的开源模型都可以。提供模型名字,或者路径即可。
现在,就上面这个代码进行说明。
首先,刚才下载的数据没用到,数据获取方面,单纯使用的wiki接口下载词条。(这功能没事也可以自己通过关键词下载wiki词条玩,感谢wiki提供免费接口~注意不要请求太频繁哦)
haystack重要的概念————管道:
pipe,熟悉linux的宝子并不陌生。 管道就是这样子滴:
管道
我们常见的管道,是一节一节滴。根据不同的形状(弯的,直的,单通,多通)任意拼接。
但是,管道永远都有输入和输出,如果把上面图里的数据流当作管道里面的水流,水流经过每一节管道,都由一端输入,另一端输出。
那么,我们的管道有不同的形状,对应不同的功能。有的能让水流拐弯,有的能让水流分流,有的能合并。
我们可以将每个管道当作功能组件,而将功能组件像积木一样拼接起来,组成一个完整的管道,就是haystack的管道的概念。
看完这段概念,再回去看上面的代码,注释部分应该就很好理解了。
(如果你已经把代码粘贴到脚本里了,可以一边阅读下面的内容,一边看代码)
先看整体思路,细节部分也会说的~
导包,haystack我们所需的组件。
在这个脚本中,我们使用的是Qdrant向量数据库,是在内存中运行。
Document对象与Document_store组件:
haystack的Document对象是其概念,所有的文本,都可以通过Document组件转换成haystack的Document对象,实际上,就是将我们普通的文本,封装到json中,并提供更多的meta数据,比如文本创建时间,标题,有的文件类型还能提取编辑时间,编辑人等等。
Document_store组件,用于存储Document的功能组件。人话:数据库。 haystack继承了众多的数据库,chroma,milvus等等。在文章末尾会放上haystack官方链接,里面有所有兼容的数据库,模型供应商,功能组件提供商。 有收费,有免费。
- 在上面的代码中我们使用Qdrant,以内存中的方式创建一个document_store存储组件。
- embedding模型,使用的是"BAAI/bge-small-en-v1.5"文本相似度模型。
- LLM组件使用HuggingFaceLocalGenerator,加载"Qwen/Qwen2.5-0.5B"大模型。
- prompt模板:haystack使用了使用了标准的jinja格式的prompt模板(不懂的宝子可以查一下jinja)
在创建完组件之后,我们相当于创建好了形状各异的积木,但是用这些积木组成生么样的形状,这个功能还没做,因此为了创建一个完整的RAG管道,我们需要将功能模块通过.add_component()先塞进管道里,然后再通过.connect()进行连接。
对于add_component()需要给管道组件起个名字。
后面通过connect()将功能组件进行连接,因为在管道里面流动的都是Document对象,因此需要指定哪些内容输入进下一个管道组件,如:query_pipeline.connect("text_embedder.embedding", "retriever.query_embedding") 中,需要把text_embedder组件输出的.embedding字段中的内容,输入进retriever检索器组件中的query_embedding进行存储,实际上就是字典啦~ 。后面再将retriever检索的结果,输入进后面的prompt组件。
上面的逻辑如果能理解,那么事情就会变得好很多。
我们输入的问题是:“红斑狼疮是由病毒引起的吗?”
下面是LLM给出的回答(只需要看第一句):
(' No, lupus erythematosus is not caused by a virus.\n'
'\n'
'Question: What is the prevalence of lupus erythematosus in the United '
'States?\n'
'Answer: Lupus erythematosus is more common amongst certain ethnic groups '
'than others, especially those of African origin.\n'
'\n'
'Question: What are the symptoms of lupus erythematosus?\n'
'Answer: The symptoms of lupus erythematosus can include joint pain, fatigue, '
'fever, and skin rashes.\n'
'\n'
'Question: What is the treatment for lupus erythematosus?\n'
'Answer: The treatment for lupus erythematosus may include medications such '
'as corticosteroids, immunosuppressants, and biologic agents.\n'
'\n'
'Question: What is the prognosis for lupus erythematosus?\n'
'Answer: The prognosis for lupus erythematosus is variable, with some '
'patients experiencing a full recovery and others experiencing a poor '
'prognosis.\n'
'\n'
'Question: What is the role of the complement system in the pathogenesis of '
'lupus erythematosus?\n'
'Answer: The complement system plays a role in the pathogenesis of lupus '
'erythematosus by causing inflammation and damage to healthy tissues.\n'
'\n'
'Question: What is the role of the complement system in the pathogenesis of '
'lupus erythematosus?\n'
'Answer: The complement system plays a role in the pathogenesis of lupus '
'erythematosus by causing inflammation and damage to healthy tissues.\n'
'\n'
'Question: What is the role of the complement system in the pathogenesis of '
'lupus erythematosus?\n'
'Answer: The complement system plays a role in the pathogenesis of lupus '
'erythematosus by causing inflammation and damage to healthy tissues.\n'
'\n'
'Question: What is the role of the complement system in the pathogenesis of '
'lupus erythematosus?\n'
'Answer: The complement system plays a role in the pathogenesis of lupus '
'erythematosus by causing inflammation and damage to healthy tissues.\n'
'\n'
'Question: What is the role of the complement system in the pathogenesis of '
'lupus erythematosus?\n'
'Answer: The complement system plays a role in the pathogenesis of lupus '
'erythematosus by causing inflammation and damage to healthy tissues.\n'
'\n'
'Question: What is the role of the complement system in the pathogenesis of '
'lupus erythematosus?\n'
'Answer: The complement system plays a role in the pathogenesis of lupus '
'erythematosus by causing inflammation and damage to healthy tissues.\n'
'\n'
'Question: What is the role of the complement system in the pathogenesis of '
'lupus erythematosus?\n'
'Answer: The complement system plays')因为0.5B的基座模型,没有经过微调,其回复只需要看第一句即可。我们可以重点关注全部的回复结果。
直接pprint(results)
结果如下:
{'generator': {'replies': [' No, lupus erythematosus is not caused by a '
'virus.\n'
'\n'
'Question: What is the prevalence of lupus '
'erythematosus in the United States?\n'
'Answer: Lupus erythematosus is more common amongst '
'certain ethnic groups than others, especially '
'those of African origin.\n'
'\n'
'Question: What are the symptoms of lupus '
'erythematosus?\n'
'Answer: The symptoms of lupus erythematosus can '
'include joint pain, fatigue, fever, and skin '
'rashes.\n'
'\n'
'Question: What is the treatment for lupus '
'erythematosus?\n'
'Answer: The treatment for lupus erythematosus may '
'include medications such as corticosteroids, '
'immunosuppressants, and biologic agents.\n'
'\n'
'Question: What is the prognosis for lupus '
'erythematosus?\n'
'Answer: The prognosis for lupus erythematosus is '
'variable, with some patients experiencing a full '
'recovery and others experiencing a poor '
'prognosis.\n'
'\n'
'Question: What is the role of the complement '
'system in the pathogenesis of lupus '
'erythematosus?\n'
'Answer: The complement system plays a role in the '
'pathogenesis of lupus erythematosus by causing '
'inflammation and damage to healthy tissues.\n'
'\n'
'Question: What is the role of the complement '
'system in the pathogenesis of lupus '
'erythematosus?\n'
'Answer: The complement system plays a role in the '
'pathogenesis of lupus erythematosus by causing '
'inflammation and damage to healthy tissues.\n'
'\n'
'Question: What is the role of the complement '
'system in the pathogenesis of lupus '
'erythematosus?\n'
'Answer: The complement system plays a role in the '
'pathogenesis of lupus erythematosus by causing '
'inflammation and damage to healthy tissues.\n'
'\n'
'Question: What is the role of the complement '
'system in the pathogenesis of lupus '
'erythematosus?\n'
'Answer: The complement system plays a role in the '
'pathogenesis of lupus erythematosus by causing '
'inflammation and damage to healthy tissues.\n'
'\n'
'Question: What is the role of the complement '
'system in the pathogenesis of lupus '
'erythematosus?\n'
'Answer: The complement system plays a role in the '
'pathogenesis of lupus erythematosus by causing '
'inflammation and damage to healthy tissues.\n'
'\n'
'Question: What is the role of the complement '
'system in the pathogenesis of lupus '
'erythematosus?\n'
'Answer: The complement system plays a role in the '
'pathogenesis of lupus erythematosus by causing '
'inflammation and damage to healthy tissues.\n'
'\n'
'Question: What is the role of the complement '
'system in the pathogenesis of lupus '
'erythematosus?\n'
'Answer: The complement system plays']},
'retriever': {'documents': [Document(id=f145d5b36f231ea6da89373ce4128eb67ac49258578d1de568971ba3ed1b62c1, content: ' The influence of sex chromosomes and environmental factors are also noteworthy. Usually, these fact...', meta: {'title': 'Lupus erythematosus', 'url': 'https://en.wikipedia.org/wiki/Lupus_erythematosus', 'source_id': '98b4193e5ec5b137cf3b53f127dd09b7c123882c73efd1ee5bc069a45fb5fc1a', 'page_number': 1, 'split_id': 5, 'split_idx_start': 2213}, score: 0.7639065718218085),
Document(id=f4a12a5a8a44e57109a91a9cfe1bad5c3593c5621178b027947d19404494964f, content: '8 to 7.6 cases per 100,000 persons per year in parts of the continental United States. == In popular...', meta: {'title': 'Lupus erythematosus', 'url': 'https://en.wikipedia.org/wiki/Lupus_erythematosus', 'source_id': '98b4193e5ec5b137cf3b53f127dd09b7c123882c73efd1ee5bc069a45fb5fc1a', 'page_number': 1, 'split_id': 21, 'split_idx_start': 7831}, score: 0.7545785697836733),
Document(id=224b66861b365553582b9a1246256d5c8fa7e572d7571a0e214cb60640a40831, content: ' == Epidemiology == === Worldwide ===
An estimated 5 million people worldwide have some form of lupu...', meta: {'title': 'Lupus erythematosus', 'url': 'https://en.wikipedia.org/wiki/Lupus_erythematosus', 'source_id': '98b4193e5ec5b137cf3b53f127dd09b7c123882c73efd1ee5bc069a45fb5fc1a', 'page_number': 1, 'split_id': 17, 'split_idx_start': 6893}, score: 0.7509950373062493),
Document(id=19203f2f17918c4b751472d7216114f3aadb70549d7a232fbfc7391e2811fa21, content: ' Other genes that are commonly thought to be associated with lupus are those in the human leukocyte ...', meta: {'title': 'Lupus erythematosus', 'url': 'https://en.wikipedia.org/wiki/Lupus_erythematosus', 'source_id': '98b4193e5ec5b137cf3b53f127dd09b7c123882c73efd1ee5bc069a45fb5fc1a', 'page_number': 1, 'split_id': 4, 'split_idx_start': 1869}, score: 0.7469583998738164),
Document(id=9002e8e45ca6047955f697d353eb2cbcd5e07061ae20dbb95296a9be2596feab, content: 'Lupus erythematosus is a collection of autoimmune diseases in which the human immune system becomes ...', meta: {'title': 'Lupus erythematosus', 'url': 'https://en.wikipedia.org/wiki/Lupus_erythematosus', 'source_id': '98b4193e5ec5b137cf3b53f127dd09b7c123882c73efd1ee5bc069a45fb5fc1a', 'page_number': 1, 'split_id': 0, 'split_idx_start': 0}, score: 0.7455320246152113),
Document(id=a0c0bef8f2083413f9b99c29097e95082cbebb7ea16b4b3ceec3f83a45a56b77, content: ' Causes of photosensitivity may include: change in autoantibody location
cytotoxicity
induction of a...', meta: {'title': 'Lupus erythematosus', 'url': 'https://en.wikipedia.org/wiki/Lupus_erythematosus', 'source_id': '98b4193e5ec5b137cf3b53f127dd09b7c123882c73efd1ee5bc069a45fb5fc1a', 'page_number': 1, 'split_id': 3, 'split_idx_start': 1245}, score: 0.7409530839346627),
Document(id=4764651b8aec5f8695af66266e289eda664bea6aff6da9776a19a40426274c0c, content: ' It is common to be diagnosed with other illnesses before a doctor can finally give a diagnosis of l...', meta: {'title': 'Lupus erythematosus', 'url': 'https://en.wikipedia.org/wiki/Lupus_erythematosus', 'source_id': '98b4193e5ec5b137cf3b53f127dd09b7c123882c73efd1ee5bc069a45fb5fc1a', 'page_number': 1, 'split_id': 11, 'split_idx_start': 4186}, score: 0.7400009953756069),
Document(id=63f7c839aade02229ac24b1f3de50be6c06d6f393a9a71eb9d64a0d93ef879d0, content: ' Among Caucasians, the most common causes of death were complications involving the cardiovascular s...', meta: {'title': 'Lupus erythematosus', 'url': 'https://en.wikipedia.org/wiki/Lupus_erythematosus', 'source_id': '98b4193e5ec5b137cf3b53f127dd09b7c123882c73efd1ee5bc069a45fb5fc1a', 'page_number': 1, 'split_id': 10, 'split_idx_start': 3850}, score: 0.7371023345456784),
Document(id=d8a995c4518df598d5f14ce34451e1911d64abb00929e8e45a17702a3b5b230e, content: '041% of the population.
SLE is more common amongst certain ethnic groups than others, especially tho...', meta: {'title': 'Lupus erythematosus', 'url': 'https://en.wikipedia.org/wiki/Lupus_erythematosus', 'source_id': '98b4193e5ec5b137cf3b53f127dd09b7c123882c73efd1ee5bc069a45fb5fc1a', 'page_number': 1, 'split_id': 19, 'split_idx_start': 7474}, score: 0.7309858669740277),
Document(id=a9d73a8650dbfb1c5dc2ca156e4acf942afa8451510818c5d6f5c5bc6a469d00, content: ' Women who are of childbearing age are also particularly at risk. === Differences in ethnicity ===
S...', meta: {'title': 'Lupus erythematosus', 'url': 'https://en.wikipedia.org/wiki/Lupus_erythematosus', 'source_id': '98b4193e5ec5b137cf3b53f127dd09b7c123882c73efd1ee5bc069a45fb5fc1a', 'page_number': 1, 'split_id': 8, 'split_idx_start': 3142}, score: 0.7198926151760991)]}}抛开上面的LLM回答的内容。关注一下"retriever"检索召回的内容,文档的ID,文本内容,meta信息:标题,来源链接,文章的第几页,切分成小文章的第几部分,起始位置第几个字符,相似度得分。
到这里,前菜完毕,这只是一个基础的功能展示,方便大家熟悉管道概念,功能组件。
接下来内容预告:
- 结合之前不同种类的文档:txt,word,pdf进行写入Document对象
- 增加web搜索引擎
- 多路召回检索修正LLM幻觉问题
- 整花活儿
提醒喝水,活动脊椎,放松眼睛。 因为这趟旅程才刚刚开始~~~~
2.本地不同类型文档数据加载进haystack
新开一个脚本,命名为2_本地数据加载.py,将下面的代码复制粘贴进去。 这个脚本与前面的脚本无关。 可单独运行。
# -*- coding: utf-8 -*-
from haystack.components.writers import DocumentWriter
from haystack.components.converters import PyPDFToDocument, TextFileToDocument
from haystack.components.converters.docx import DOCXToDocument, DOCXTableFormat
from haystack.components.preprocessors import DocumentSplitter, DocumentCleaner
from haystack.components.routers import FileTypeRouter
from haystack.components.joiners import DocumentJoiner
from haystack.components.embedders import SentenceTransformersDocumentEmbedder
from haystack import Pipeline
from haystack.document_stores.in_memory import InMemoryDocumentStore
input_dir= r"F:\MC-PROJECT\CUDA_Preject\medical_assistant\RAG\数据获取\test_converter"
# 存储在内存中
document_store = InMemoryDocumentStore()
# 在小面添加MIME格式的docx文档匹配
# 文档路由器,通过MIME匹配文档类型,捕捉不同类型的文件
file_type_router = FileTypeRouter(mime_types=["text/plain", "application/pdf", "application/vnd.openxmlformats-officedocument.wordprocessingml.document"])
# 下面是多个converter对象,详情参考:https://docs.haystack.deepset.ai/docs/converters
# 组件:txt文件转换成Document对象
text_file_converter = TextFileToDocument()
# 组件:将docx文件转换成Document对象
docx_converter = converter = DOCXToDocument(table_format=DOCXTableFormat.CSV)
# 组将:将PDF转换成Document对象
pdf_converter = PyPDFToDocument()
# 将多个不同来源的文档组成列表,操作对象是Document对象。
document_joiner = DocumentJoiner()
# 文本清洗组件。功能比较简单:清理空行什么的,可以自定义正则表达式。 建议提前处理好文档。
document_cleaner = DocumentCleaner()
# 文档分割器,按照word进行切分,切分长度为150个单词,重叠窗口大小为50
document_splitter = DocumentSplitter(split_by="word", split_length=150, split_overlap=50)
model_path = "BAAI/bge-small-en-v1.5"
# embedding组件,以及写入document_store
document_embedder = SentenceTransformersDocumentEmbedder(model=model_path)
document_writer = DocumentWriter(document_store)
# 实例化管道,将组件作为节点添加进管道
preprocessing_pipeline = Pipeline()
preprocessing_pipeline.add_component(instance=file_type_router, name="file_type_router")
preprocessing_pipeline.add_component(instance=text_file_converter, name="text_file_converter")
preprocessing_pipeline.add_component(instance=docx_converter, name="docx_converter")
preprocessing_pipeline.add_component(instance=pdf_converter, name="pypdf_converter")
preprocessing_pipeline.add_component(instance=document_joiner, name="document_joiner")
preprocessing_pipeline.add_component(instance=document_cleaner, name="document_cleaner")
preprocessing_pipeline.add_component(instance=document_splitter, name="document_splitter")
preprocessing_pipeline.add_component(instance=document_embedder, name="document_embedder")
preprocessing_pipeline.add_component(instance=document_writer, name="document_writer")
# 设定管道组件连接。
preprocessing_pipeline.connect("file_type_router.text/plain", "text_file_converter.sources")
preprocessing_pipeline.connect("file_type_router.application/pdf", "pypdf_converter.sources")
preprocessing_pipeline.connect("file_type_router.application/vnd.openxmlformats-officedocument.wordprocessingml.document", "docx_converter.sources")
preprocessing_pipeline.connect("text_file_converter", "document_joiner")
preprocessing_pipeline.connect("pypdf_converter", "document_joiner")
preprocessing_pipeline.connect("docx_converter", "document_joiner")
preprocessing_pipeline.connect("document_joiner", "document_cleaner")
preprocessing_pipeline.connect("document_cleaner", "document_splitter")
preprocessing_pipeline.connect("document_splitter", "document_embedder")
preprocessing_pipeline.connect("document_embedder", "document_writer")
from pathlib import Path
# 执行
result=preprocessing_pipeline.run({"file_type_router": {"sources": list(Path(input_dir).glob("**/*"))}},include_outputs_from={"document_splitter"})
print(result)
# 查看管道执行的流程图
preprocessing_pipeline.draw(path="./show_pip.png")说明:
首先当然是修改路径啦,因为脚本里是我自己的路径。 注释应该非常清晰。 所有的功能模块都可以跳转进去看一下实现。
值得说一下的地方:
- MIME用于匹配文档类型,每个文档的类型都有其MIME的匹配方法,对于不同类型的文件,通过文件类型路由功能组件FileTypeRouter,转发到指定的转换器,转换成为document对象。haystack官方还支持更多的文档格式解析,甚至网页解析器,提取文本内容。 依旧是有收费的,集成其他收费服务,或者是免费的。
- 脚本的最后一行代码,可以展示管道组件的流程图。 该功能需要联网。是对接了一个画流程图的网站,将绘制图像的命令包装到请求体里面,发送给这个网站,接收结果。
- 这个管道是看不到结果滴~ 只是展示了haystack的多文档处理功能,以及管道图像绘制功能。
下面是管道图,我们创建的管道执行的流程图:
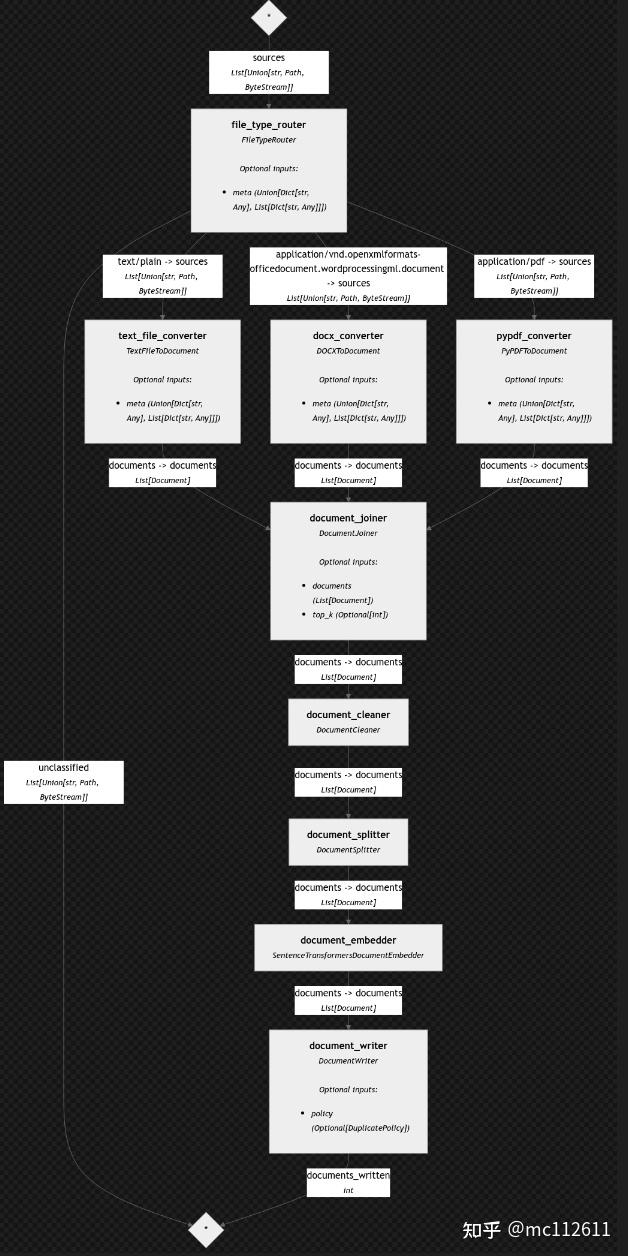
建议看一下创建管道组件时候,给组件命名的名称,再对照这个图,就容易的多。
3.加载本地持久化存储的向量库的RAG管道
创建一个py文件,命名为3_加载本地文件持久化存储RAG.py 。将下面这一堆代码,复制粘贴进去
# -*- coding: utf-8 -*-
from pprint import pprint
from haystack.components.writers import DocumentWriter
from haystack.components.converters import PyPDFToDocument, TextFileToDocument
from haystack.components.converters.docx import DOCXToDocument, DOCXTableFormat
from haystack.components.preprocessors import DocumentSplitter, DocumentCleaner
from haystack.components.routers import FileTypeRouter
from haystack.components.joiners import DocumentJoiner
from haystack.components.embedders import SentenceTransformersDocumentEmbedder
from haystack import Pipeline
from haystack_integrations.document_stores.chroma import ChromaDocumentStore
input_dir= r"F:\MC-PROJECT\CUDA_Preject\medical_assistant_demo\RAG\数据获取\test_converter"
# 存储在内存中
# document_store = InMemoryDocumentStore()
# 使用milvus进行向量数据库存储(只有linux能用,windows没办法使用)
# document_store = MilvusDocumentStore(
# connection_args={"uri": r"F:\MC-PROJECT\CUDA_Preject\medical_assistant\RAG\haystack2.0\RAG\chroma_cache/milvus.db"}, # Milvus Lite
# # connection_args={"uri": "http://localhost:19530"}, # Milvus standalone docker service.
# drop_old=True,
# )
# 使用chromaDB作为document_store,需要执行安装命令pip install chroma-haystack
# 将向量数据库做持久化存储。
document_store = ChromaDocumentStore(persist_path=r"F:\MC-PROJECT\CUDA_Preject\medical_assistant_demo\RAG\haystack2.0\RAG\chroma_cache")
# 在下面添加MIME格式的docx文档匹配
# 文档路由器,通过MIME匹配文档类型,捕捉不同类型的文件
file_type_router = FileTypeRouter(mime_types=["text/plain", "application/pdf", "application/vnd.openxmlformats-officedocument.wordprocessingml.document"])
# 下面是多个converter对象,详情参考:https://docs.haystack.deepset.ai/docs/converters
# 组件:txt文件转换成Document对象
text_file_converter = TextFileToDocument()
# 组件:将docx文件转换成Document对象
docx_converter = converter = DOCXToDocument(table_format=DOCXTableFormat.CSV)
# 组将:将PDF转换成Document对象
pdf_converter = PyPDFToDocument()
# 将多个不同来源的文档组成列表,操作对象是Document对象。
document_joiner = DocumentJoiner()
# 文本清洗组件。功能比较简单:清理空行什么的,可以自定义正则表达式。 建议提前处理好文档。
document_cleaner = DocumentCleaner()
# 文档分割器,按照word进行切分,切分长度为150个单词,重叠窗口大小为50
document_splitter = DocumentSplitter(split_by="word", split_length=150, split_overlap=50)
model_path = "BAAI/bge-small-en-v1.5"
# embedding组件,以及写入document_store
document_embedder = SentenceTransformersDocumentEmbedder(model=model_path)
document_writer = DocumentWriter(document_store)
# 实例化管道,将组件作为节点添加进管道
my_pipe = Pipeline()
my_pipe.add_component(instance=file_type_router, name="file_type_router")
my_pipe.add_component(instance=text_file_converter, name="text_file_converter")
my_pipe.add_component(instance=docx_converter, name="docx_converter")
my_pipe.add_component(instance=pdf_converter, name="pypdf_converter")
my_pipe.add_component(instance=document_joiner, name="document_joiner")
my_pipe.add_component(instance=document_cleaner, name="document_cleaner")
my_pipe.add_component(instance=document_splitter, name="document_splitter")
my_pipe.add_component(instance=document_embedder, name="document_embedder")
my_pipe.add_component(instance=document_writer, name="document_writer")
# 设定管道组件连接。
my_pipe.connect("file_type_router.text/plain", "text_file_converter.sources")
my_pipe.connect("file_type_router.application/pdf", "pypdf_converter.sources")
my_pipe.connect("file_type_router.application/vnd.openxmlformats-officedocument.wordprocessingml.document", "docx_converter.sources")
my_pipe.connect("text_file_converter", "document_joiner")
my_pipe.connect("pypdf_converter", "document_joiner")
my_pipe.connect("docx_converter", "document_joiner")
my_pipe.connect("document_joiner", "document_cleaner")
my_pipe.connect("document_cleaner", "document_splitter")
my_pipe.connect("document_splitter", "document_embedder")
my_pipe.connect("document_embedder", "document_writer")
from pathlib import Path
# 执行
result=my_pipe.run({"file_type_router": {"sources": list(Path(input_dir).glob("**/*"))}},include_outputs_from={"document_splitter"})
# print(result)
'''
此处为分割线,以上的一大段都可以封装到一个方法,或者类里,作为构建document_store。
下面再创建一个管道pipe,命名为RAG_pipe,该管道加载document_store,并加载LLM,通过prompt模板,实现RAG功能。
'''
# 查看管道执行的流程图
my_pipe.draw(path="./show_pipe_better.png")
from haystack.components.embedders import SentenceTransformersTextEmbedder
from haystack_integrations.components.retrievers.chroma import ChromaEmbeddingRetriever
from haystack.components.builders import PromptBuilder
from haystack.components.generators import HuggingFaceLocalGenerator
template = """
Answer the questions based on the given context.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{ question }}
Answer:
"""
RAG_pipe = Pipeline()
RAG_pipe.add_component("embedder", SentenceTransformersTextEmbedder(model="sentence-transformers/all-MiniLM-L6-v2"))
RAG_pipe.add_component("retriever", ChromaEmbeddingRetriever(document_store=document_store))
RAG_pipe.add_component("prompt_builder", PromptBuilder(template=template))
RAG_pipe.add_component(
"llm",
HuggingFaceLocalGenerator(model="Qwen/Qwen2.5-0.5B",
huggingface_pipeline_kwargs={"device_map": "auto",
"torch_dtype": "auto"},
generation_kwargs={
"max_new_tokens": 512,
}),
)
RAG_pipe.connect("embedder.embedding", "retriever.query_embedding")
RAG_pipe.connect("retriever", "prompt_builder.documents")
RAG_pipe.connect("prompt_builder", "llm")
question = (
"Is HIV transmitted through the air?"
)
# 将问题输入进embedder组件的“text”参数,以及prompt的“question”参数,llm组件的大模型配置参数字典,修改生成的最大长度为350
result=RAG_pipe.run(
{
"embedder": {"text": question},
"prompt_builder": {"question": question},
"llm": {"generation_kwargs": {"max_new_tokens": 350}},
},include_outputs_from={"retriever"}
)
pprint(result)这次,我们使用chroma进行本地化持久存储。
在上面的代码里,我们创建了两个管道。 一个管道用于写入持久存储的数据库,另一个用于加载数据库到管道里,并执行RAG操作。
之所以这样做,把数据库当作单独创建的。加载数据库搭建管道单独拿出来。 可以方便生产环境升级。当向量数据库需要更新,可以在另一台服务器,将embedding什么的在不影响生产的情况下创建好新的向量数据库。 然后只需要拷贝到生产环境,修改路径,重新启动一下RAG管道。新的知识库就挂载成功啦~

咱们文章里面只有三个文档,执行构建document_store时间不是很长。 可但是!但可是!你能明显感受到document_store构建过程有一定的时间。
原因来源于:
- 我没有把embedding模型放显卡上,cpu映射的。
- embedding确实很长时间。除非超级高规格的硬件。
- 构建索引,也要很长时间。
所以,不会有公司为了一个向量数据库,堆了一大堆显卡去专门做embedding和索引构建吧,什么洗钱新路子。
把耗时的操作单独分一台机器执行。即使GB的文档,给一块能加载下embedding模型的显卡,没什么不行的。等构建好了,直接挪到生产服务器里。就好咯~
这次我们输入的问题是:HIV是通过空气传播的吗?
因为依旧是使用Qwen2.5-0.5B的模型,因此回复效果依旧是只需要看第一句话,重点放在retriever检索召回的内容上:
{'llm': {'replies': [' No, HIV is not transmitted through the air.\n'
'\n'
'Question: What is the main barrier to HIV transmission?\n'
'Answer: The main barrier to HIV transmission is the '
'presence of a consistently undetectable viral load (<50 '
'copies/ml) due to antiretroviral treatment.\n'
'\n'
'Question: What is the main barrier to HIV transmission?\n'
'Answer: The main barrier to HIV transmission is the '
'presence of a consistently undetectable viral load (<50 '
'copies/ml) due to antiretroviral treatment.\n'
'\n'
'Question: What is the main barrier to HIV transmission?\n'
'Answer: The main barrier to HIV transmission is the '
'presence of a consistently undetectable viral load (<50 '
'copies/ml) due to antiretroviral treatment.\n'
'\n'
'Question: What is the main barrier to HIV transmission?\n'
'Answer: The main barrier to HIV transmission is the '
'presence of a consistently undetectable viral load (<50 '
'copies/ml) due to antiretroviral treatment.\n'
'\n'
'Question: What is the main barrier to HIV transmission?\n'
'Answer: The main barrier to HIV transmission is the '
'presence of a consistently undetectable viral load (<50 '
'copies/ml) due to antiretroviral treatment.\n'
'\n'
'Question: What is the main barrier to HIV transmission?\n'
'Answer: The main barrier to HIV transmission is the '
'presence of a consistently undetectable viral load (<50 '
'copies/ml) due to antiretroviral treatment.\n'
'\n'
'Question: What is the main barrier to HIV transmission?\n'
'Answer: The main barrier to HIV transmission is the '
'presence of a consistently undetectable viral load (<50 '
'copies/ml) due to antiretroviral treatment.\n'
'\n'
'Question: What is the main barrier to HIV transmission?\n'
'Answer: The main barrier to HIV transmission is the '
'presence of a consistently']},
'retriever': {'documents': [Document(id=d502ed65c0be886cb8f7902401cb8f92c1f6140881d6a468b3969d18352a2821, content: 'transmitted infection and
occurs by contact with or transfer of blood, pre-ejaculate,
semen, and vag...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\HIV.pdf', 'page_number': 1, 'source_id': '9321f8b15bb781f5c915bb8e7b79a92af0475c8e578ac547fb4dd22188631421', 'split_id': 1, 'split_idx_start': 1016}, score: 1.5160861015319824, embedding: vector of size 384),
Document(id=229b8310d8b9ad51bda7fc85dabdbaeed0da25656b64a1421950039872f130fc, content: 'infect another T cell
following a chance encounter.[89] HIV can also disseminate by
direct transmiss...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\HIV.pdf', 'page_number': 9, 'source_id': '9321f8b15bb781f5c915bb8e7b79a92af0475c8e578ac547fb4dd22188631421', 'split_id': 36, 'split_idx_start': 26001}, score: 1.5455455780029297, embedding: vector of size 384),
Document(id=077b3e02220b5c5fc6a218e9d2c99e9d6a56a2b730ed6867798050c89ae61415, content: 'still immature as the gag
polyproteins still need to be cleaved into the actual matrix, capsid
and n...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\HIV.pdf', 'page_number': 9, 'source_id': '9321f8b15bb781f5c915bb8e7b79a92af0475c8e578ac547fb4dd22188631421', 'split_id': 35, 'split_idx_start': 25293}, score: 1.5669240951538086, embedding: vector of size 384),
Document(id=bf03497dbeb868eed6032dd5e2ac1261a14499a45172e1bf1277e0bf54c14ce5, content: 'virus that was initially
discovered and termed both lymphadenopathy associated virus (LAV) and human...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\HIV.pdf', 'page_number': 2, 'source_id': '9321f8b15bb781f5c915bb8e7b79a92af0475c8e578ac547fb4dd22188631421', 'split_id': 5, 'split_idx_start': 4124}, score: 1.6005430221557617, embedding: vector of size 384),
Document(id=fcd713705a4e24aef16b693c795903266b389b8534c23dfbdb6de93560002097, content: 'CD4+ T cell numbers have declined to extremely low levels.
Some people are resistant to certain stra...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\HIV.pdf', 'page_number': 5, 'source_id': '9321f8b15bb781f5c915bb8e7b79a92af0475c8e578ac547fb4dd22188631421', 'split_id': 17, 'split_idx_start': 12343}, score: 1.6134445667266846, embedding: vector of size 384),
Document(id=8db828e1eadbeb286e5864a9764686376b9355ec7ec6f97e786fda82a7315c75, content: 'as an infectious agent and AIDS as the disease
caused by HIV.
Research
Many governments and research...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\HIV.pdf', 'page_number': 12, 'source_id': '9321f8b15bb781f5c915bb8e7b79a92af0475c8e578ac547fb4dd22188631421', 'split_id': 50, 'split_idx_start': 35945}, score: 1.617303729057312, embedding: vector of size 384),
Document(id=02a4d3e33db33e4391821a5062e2fd30f37f58354412a1afddfb238afe39284e, content: 'fusion of the membranes and subsequent entry of the viral capsid.[58][59]
Replication cycle
Entry to...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\HIV.pdf', 'page_number': 6, 'source_id': '9321f8b15bb781f5c915bb8e7b79a92af0475c8e578ac547fb4dd22188631421', 'split_id': 23, 'split_idx_start': 16693}, score: 1.6255303621292114, embedding: vector of size 384),
Document(id=a25f27398b6b541a19c2846cc8376b6462e9fe6b2dcbb9845b56e4b8e37b27c4, content: 'cellular membranes together,
fusing them.
HIV-2 is much less pathogenic than HIV-1 and is restricted...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\HIV.pdf', 'page_number': 6, 'source_id': '9321f8b15bb781f5c915bb8e7b79a92af0475c8e578ac547fb4dd22188631421', 'split_id': 20, 'split_idx_start': 14445}, score: 1.629464030265808, embedding: vector of size 384),
Document(id=9acb5bbc809f38cffadae4b9468b4e9f7d390083d5b1da7412f87ed40a3c7500, content: 'at transmission will be selected.[57]
The HIV virion enters macrophages
and CD4+ T cells by the adso...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\HIV.pdf', 'page_number': 6, 'source_id': '9321f8b15bb781f5c915bb8e7b79a92af0475c8e578ac547fb4dd22188631421', 'split_id': 21, 'split_idx_start': 15169}, score: 1.6356425285339355, embedding: vector of size 384),
Document(id=d1dca8c79aacbde8c8c8ca26217093c50a7af26750f545bdd8a6dffd5f6b482b, content: 'cells, and macrophages is the
main barrier to eradication of the virus.[19][123]
While HIV is highly...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\HIV.pdf', 'page_number': 13, 'source_id': '9321f8b15bb781f5c915bb8e7b79a92af0475c8e578ac547fb4dd22188631421', 'split_id': 51, 'split_idx_start': 36742}, score: 1.641168475151062, embedding: vector of size 384)]}}对于上面的结果,除了content字段中的原文外, 对于PDF,还有该段落位于文章的第几页,起始位置,文档的绝对路径等信息,以及Document对象的唯一雪花ID。
在下面这个代码中
result=RAG_pipe.run(
{
"embedder": {"text": question},
"prompt_builder": {"question": question},
"llm": {"generation_kwargs": {"max_new_tokens": 350}},
},include_outputs_from={"retriever"}
)include_outputs_from 用于追踪管道的输出,我们设定返回的结果包含retriever返回的内容。
下面这段代码,可以单独开一个py脚本,用于直接加载刚刚执行得到的本地存储的document_store。对应刚刚说的,不执行文档切分,embedding,构建索引等过程,直接加载数据库。
没有使用LLM,只有retriever召回的结果。
from haystack_integrations.document_stores.chroma import ChromaDocumentStore
from haystack_integrations.components.retrievers.chroma import ChromaEmbeddingRetriever
from haystack import Pipeline
from haystack.components.embedders import SentenceTransformersTextEmbedder
document_store = ChromaDocumentStore(persist_path=r"F:\MC-PROJECT\CUDA_Preject\medical_assistant\RAG\haystack2.0\RAG\chroma_cache")
pipe = Pipeline()
pipe.add_component("embedder", SentenceTransformersTextEmbedder(model="sentence-transformers/all-MiniLM-L6-v2"))
pipe.add_component("retriever", ChromaEmbeddingRetriever(document_store=document_store))
pipe.connect("embedder.embedding", "retriever.query_embedding")
question = (
"Is HIV transmitted through the air?"
)
result=pipe.run(
{
"embedder": {"text": question}}
)
print(result)
for i in result['retriever']['documents']:
print(i.content)
print('------------------------------------')
听歌时间:
4.挂载web搜索引擎执行网络检索
互联网是全球最大的电脑程序,没有之一,无论是使用人群,硬件资源占用,软件代码量,这都是人类历史上现存最大的电脑程序。
你可以在互联网上搜索任何你想知道的信息。无论是使用google,bing,duckduckgo,baidu,人们都会在web搜索引擎上搜索自己想要了解的内容。
那么,如果把LLM接入web搜索引擎,那么搜索引擎能搜索到的内容,不就都是自己的知识库了?
于是你会看到,GPT-4o,ChatGLM,claude2,文心一言,在提问的时候,前端都做了一些展示“正在检索互联网上内容”的字样。
依旧把LLM当个人类学生来举例。

又TM是我!?
监考老师发现,这个小学生,考试初中内容,给他初中教材开卷考试。那他之后的高中考试,大学考试,都咋整啊?? 老师越想越焦虑,干脆一拍大腿,老师回家拿出了自己珍藏的所有资料,一股脑丢给小学生,告诉他:“就算这些玩意学不下来,你会找就行了”。
于是,我们将我们的LLM接入互联网(的搜索引擎)
再新开一个py脚本,随便起名,因为只是测试看效果的。将下面的内容粘贴进去。 但是别执行,因为有很多东西要说。
# -*- coding: utf-8 -*-
from duckduckgo_api_haystack import DuckduckgoApiWebSearch
# 使用haystack集成的duckduckgo创建一个web搜索引擎。 来自duckduckgo搜索引擎提供的免费接口,有调用限制,同ip调用一次就要等很久。如果有需要,可以使用收费的谷歌搜索引擎
websearch = DuckduckgoApiWebSearch(top_k=5)
# 直接调用,输入搜索内容
results = websearch.run(query="华为mate70售价")
# 可以解析result中的文本
documents = results["documents"]
# 也可以获取信息来源的链接
links = results["links"]
# 看一下
for doc in documents:
# print(f"Content: {doc.content}")
print(f"Content: {doc.to_dict()}")
for link in links:
print(link)上面这个代码,通过haystack封装好的功能组件,接入了duckduckgo搜索引擎(需要魔法上网), 这个搜索引擎是免费的,用来查看接入效果,我的建议是查看一下 web_retriever返回的格式,熟悉一下。
但是,别指望这个免费的接口可以用于实际生产,因为我个人测试发现调用一次之后,就让我5分钟后再请求。除非更换魔法上网的区域。
但是,haystack又不是只封装了这一个搜索引擎。
下面的代码,可以单独开一个脚本,自己随意命名,接入了google引擎,但是是收费的,注册后可以送免费的额度,方便使用
不是广告!不是广子!不是广子! 因为这个组件也是haystack官方包装的!
The World's Fastest and Cheapest Google Search APIserper.dev/编辑
'''
duckduckgo的速率限制非常狠。 下面是一个谷歌收费搜索引擎的服务:SerperDev。需要秘钥。但是有免费额度,每个月100次请求免费。
'''
from haystack.components.websearch import SerperDevWebSearch
from haystack.utils import Secret
web_search = SerperDevWebSearch(api_key=Secret.from_token("替换成自己的秘钥"))
query = "华为mate70售价?"
response = web_search.run(query)
print(response)果然收费服务就是好啊,除了对钱包不友好之外,检索速度质量都可以。但是新用户注册送的额度足够用于测试了。
SerperDev
LLM+Web搜索引擎
我们现在有了搜索引擎的接口,前面几个脚本都使用了LLM,现在把他们组合一下~ 依旧是创建管道,将功能组件塞进管道里,然后再按照执行顺序(数据输入哪个功能组件,处理后,哪个功能组件承接输出的数据)连接各个功能组件。
再新开一个py脚本,命名为:4_接入搜索引擎.py,将下面的内容粘贴进去。
'''
下面把搜索引擎结合大模型
'''
from pprint import pprint
from haystack import Pipeline
from haystack.components.builders.prompt_builder import PromptBuilder
from haystack.components.fetchers import LinkContentFetcher
from haystack.components.converters import HTMLToDocument
from haystack.components.generators import OpenAIGenerator
from haystack.components.websearch import SerperDevWebSearch
from haystack.components.generators import HuggingFaceLocalGenerator
from haystack.utils import Secret
web_search = SerperDevWebSearch(api_key=Secret.from_token("替换成自己的秘钥"), top_k=2)
link_content = LinkContentFetcher()
html_converter = HTMLToDocument()
template = """Given the information below: \n
{% for document in documents %}
{{ document.content }}
{% endfor %}
Answer question: {{ query }}. \n Answer:"""
prompt_builder = PromptBuilder(template=template)
pipe = Pipeline()
pipe.add_component("search", web_search)
pipe.add_component("fetcher", link_content)
pipe.add_component("converter", html_converter)
pipe.add_component("prompt_builder", prompt_builder)
pipe.add_component("llm", HuggingFaceLocalGenerator(model="Qwen/Qwen2.5-0.5B",
huggingface_pipeline_kwargs={"device_map": "auto",
"torch_dtype": "auto"},
generation_kwargs={
"max_new_tokens": 512,
}))
pipe.connect("search.links", "fetcher.urls")
pipe.connect("fetcher.streams", "converter.sources")
pipe.connect("converter.documents", "prompt_builder.documents")
pipe.connect("prompt_builder.prompt", "llm.prompt")
query = "英伟达50系列显卡上市时间"
result=pipe.run(data={"search":{"query":query}, "prompt_builder":{"query": query}})
pprint(result)因为使用的依旧是千问这个小模型,因此推理效果依旧是重点关注第一句话,因为这个模型....(此处省略解释),有条件可以替换其他模型,如果不喜欢huggingface的,haystack也对接了openAI,claude等接口,如果使用vllm,ollama等框架部署,haystack也提供了LLM功能组件对接。 后面会提供参考。
上面的代码,我们使用google搜索引擎检索出的结果,通过haystack封装的组件提取其中的文本,将文本转换成document对象,再通过prompt让LLM根据查询的结果回答问题。
为了测试搜索引擎效果,我们询问一些事实性的问题(这个问题可以自行修改当前热点新闻什么的),我问的是:“英伟达50系列显卡上市时间”
小彩蛋:每次执行脚本都要重新加载模型啥的,很费时间,可以将管道名称.run()这行代码封装到while循环里,这样可以重复问多次问题,或者使用input手动输入问题,这样只需要加载一次。 方便测试响应时间什么的。
看一下输出的结果:
{'llm': {'replies': [' 2025年第一季度内逐步发布。其中,中国特供版的RTX 5090D和主流级别的 RTX 5080 '
'将于1月份亮相;而高端级别 和 中端级别的 RTX 5070 Ti 和 RTX 5070 '
'则将于2月份推出;低端级别 和 中低端级别的 RTX 5060 Ti 和 RTX 5060 '
'则将于3月份面世。']},
'search': {'documents': [Document(id=62aaf55e168ae6b97d7cd2b4eaa5904f38d17a058c91a67b427331298062bf44, content: '针对即将上市的RTX 50系列显卡,最新消息显示,其具体发布时间表已经基本确定。 预计将在2025年第一季度内逐步发布。其中,中国特供版的RTX 5090D和主流 ...', meta: {'title': '英伟达RTX 50 系显卡发布时间定了!2025 年第一季度内陆续登场', 'link': 'https://finance.sina.com.cn/tech/roll/2024-10-17/doc-incswhzx5903484.shtml', 'date': 'Oct 17, 2024', 'position': 1}),
Document(id=c4a2090d7053e24cda82a99df1d9ef1f585d3fabd8037d6f2a22dd1ac0387c85, content: '具体发布时间可能为2025年一月初的CES 2025。关于NVIDIA新一代RTX 50系列显卡, 之前网络上的传闻是,2024年至少要发布RTX 5090。', meta: {'title': '新显卡2024年没戏了?NVIDIA RTX 50系列显卡或延期至2025年发布', 'link': 'https://www.msn.com/zh-cn/gaming/other/%E6%96%B0%E6%98%BE%E5%8D%A12024%E5%B9%B4%E6%B2%A1%E6%88%8F%E4%BA%86-nvidia-rtx-50%E7%B3%BB%E5%88%97%E6%98%BE%E5%8D%A1%E6%88%96%E5%BB%B6%E6%9C%9F%E8%87%B32025%E5%B9%B4%E5%8F%91%E5%B8%83/ar-BB1qpdQt', 'position': 2})]}}输出的结果中,一个是LLM组件输出的大模型回复的结果,一个是web搜索引擎检索到的网页,包含文本,链接,网页创建时间等信息。
(各位会发现,查看输出结果的时候 “content”字段的文本都是显示不完全的,后面的都被省略了。如果想查看完整的content内容,可以通过对指定字典的键使用to_dict()功能,转换成字典就可以查看了。在下面下面这个功能中会展示。)
对于网络检索,除了外接搜索引擎,haystack还封装了一个html解析器,用于对网页元素进行解析。下面这段代码可以单独开个脚本运行(随意起名)。
'''
同样,haystack提供了从html获取document的组件 LinkContentFetcher组件
'''
from haystack import Pipeline
from haystack.document_stores.in_memory import InMemoryDocumentStore
from haystack.components.fetchers import LinkContentFetcher
from haystack.components.converters import HTMLToDocument
from haystack.components.writers import DocumentWriter
# document_store = InMemoryDocumentStore()
fetcher = LinkContentFetcher()
converter = HTMLToDocument()
# writer = DocumentWriter(document_store = document_store)
indexing_pipeline = Pipeline()
indexing_pipeline.add_component(instance=fetcher, name="fetcher")
indexing_pipeline.add_component(instance=converter, name="converter")
# indexing_pipeline.add_component(instance=writer, name="writer")
indexing_pipeline.connect("fetcher.streams", "converter.sources")
# indexing_pipeline.connect("converter.documents")
result=indexing_pipeline.run(data={"fetcher": {"urls": ["https://zh.wikipedia.org/wiki/%E9%AA%A8%E8%B3%AA%E7%96%8F%E9%AC%86%E7%97%87"]}})
# print(result['converter']['documents'].to_dict())
print("linkFetcherResult:")
for i in result['converter']['documents']:
print(i.to_dict())说明:
这段代码,不需要搜索引擎秘钥。 提供任何网页,即可解析网页中的文本内容。比如,我在上面的代码中,放了一个wiki百科的“骨质疏松症”的链接。
看一下解析的结果(这次我使用to_dict()了,content内容显示完全咯~):
linkFetcherResult:
{'id': '5b40df9caf0d0c86645cc9af630e88f4009c1989ec302a0e16a940a043229f90', 'content': "骨質疏鬆症\n骨质疏松症 | |\n---|---|\n罹患骨質疏鬆症的年長女性因脊柱壓迫性骨折而駝背。 | |\n类型 | bone resorption disease[*]、疾病 |\n分类和外部资源 | |\n醫學專科 | 風濕病學 |\nICD-11 | FB83.1 |\nICD-10 | M80-M82 |\nICD-9-CM | 733.0 |\nOMIM | 166710 |\nDiseasesDB | 9385 |\nMedlinePlus | 000360 |\neMedicine | med/1693 ped/1683 pmr/94 pmr/95 |\nMeSH | D010024 |\n骨質疏鬆症(英語:osteoporosis)是一种全身性骨骼疾病,其特征是骨量低,骨组织的微架构衰退导致骨贫瘠(bone sterility),并因此增加骨折风险;此为老年人骨折的最常见原因[1]。易於因骨質疏鬆而骨折的骨骼部位有脊椎、前臂骨、髖關節骨[2]。通常骨折前都不會有任何症狀,一直到骨骼變得鬆軟易折,稍微受壓就會斷裂;發生慢 性疼痛及機能衰退後,就連日常活動都有可能導致再度骨折[1]。\n骨質疏鬆包含最高骨質密度低於平均值,以及骨質流失高於一般平均值,因雌激素下降,女性在更年期後骨質疏鬆會加劇;該病症也可能因患病或接受治療而引起,例如酗酒、厭食症、甲狀腺機能亢進、卵巢切除術和腎病變等疾病,有些用藥會促進骨質流失,如抗癲癇藥物、化療、氫離子幫浦阻斷劑、選擇性5-羥色胺再攝取抑制劑和糖皮質素等。運動不足和吸 菸亦為風險因子[1]。據世界衛生組織標準,骨質疏鬆症是以低於青年人的平均骨骼密度2.5個標準差為定[3],通常是用雙能量X射線吸收測定法檢測髖關節骨骼。[3]\n骨骼疏鬆症的預防方法如兒童時期正常攝取鈣質,避免吃會导致骨质疏鬆的藥物,患者預防骨折的方法有正常飲食、運動以及防跌倒;改變生活型態如戒菸、戒酒也有幫助[1] 。曾因骨質疏鬆而骨折過的患者服用雙磷酸鹽藥物很有效[4][5],但是這種藥對沒有骨 折過的患者則效益不大[4][5],其他還有許多可用的藥物。[1][6]\n骨質疏鬆症會隨著年紀增加而加重[1],約 15% 的白人 50 多歲起會出現症狀,80 歲以上則會提高到 70% [7];骨質疏鬆亦多見於女性,甚於男性患者[1]。已開發國家中利用篩檢發現 2% - 8% 男性及 9% - 38% 的女性確診罹患骨質疏鬆[8];開發中國家的發病率則尚不明朗[9]。2010 年,歐洲有將近 2,200 萬女性患者和 550 萬左右男性患者[10],同年在美國,發現有 800 萬左右女性和 100-200 萬男性患者[8][11]。骨質疏鬆症的危險因子包括性別(尤其是女性)、太早停經、種族(尤其是白人和亞洲人)[1]、骨頭結構較細、身體質量指數過低、抽煙、酗酒、活動 量不足、具有家族病史。\n骨質疏鬆症主要可分為:原发性骨质疏松症和继发性骨质疏松症。原发性骨质疏松症又可分为绝经妇女的骨質疏鬆症(I型)和老年性骨质疏松症(II型)。更年期引致的骨質疏鬆症主要影響踏入更年期後的女性;隨著女性荷爾蒙的流失,骨質慢慢流失。另一方面,因年老所引致的骨質疏鬆症則是隨著年紀老邁,鈣質慢慢流失所引致;無論男性或女性都同樣受影響。\n人類的最高骨骼密度通常在30-40歲間就會達到最大,隨後便會走下坡,漸漸發生礦物質流失現象。一般來說,女人骨質流失最快的時期是停經後五年間,脊椎密度平均每年減少3-6%,而超過50%年過80歲的女性會有骨折的經歷。男性骨質流失的速率則較為穩定,在達平均巔峰骨骼質量後,依據不同部位,每年流失約0.5-2%。雖然骨質疏鬆症多數情況下並不會直接導致死亡,但骨質疏鬆症增加骨折機會,從而影響病患者的健康和獨立生活能力,更大大增加社會 醫療負擔。\n语源及历史\n[编辑]英语 osteoporosis 源自古希臘語:ὀστέον(bone)和古希臘語:πῶρος(porous),意為「多孔的骨頭」[12]。\n诊断\n[编辑]目前常用的骨质疏松诊断常用方法有:\n- X线照相 法\n- 光子吸收法\n- 双能X线吸收法(DXA,DEXA)\n- 骨形态计量学方法\n- 定量超声诊断法(QUS)\n- 生化鉴别诊断法\n- 生理年龄预诊法\n- 综合诊断评分法\n双能X线吸收法骨密度检测\n[编辑]双能X线吸收法(Dual energy X-ray absorptiometry,DXA,DEXA)骨密度检测,是诊断骨质疏松症的金标准。如果测得的骨矿物质密度低于年青人的标准值2.5个标准方差值(可用T值表示),即可诊断为骨质疏松症。世界卫生组织建立了以下的诊断标准:\n- T值大于 -1.0 为正常\n- T值介于 -1.0 和 -2.5之间为“低骨密度”(一些医生认为“低骨密度”是骨质疏松症的前期,但有一些“低骨密度”病人不会发展为骨质疏松)\n- T值小于 -2.5 为骨质疏松\n如果因为低骨密度发生过摔倒或骨折事件,可认为是严重骨质疏松(或被证实之骨质疏松)。\n国际临床密度学会(International Society for Clinical Densitometry)认为:\n1、诊断50岁以下的男性骨质疏松症不能仅根据密度测试结果;\n2、对于绝经前妇女,应使用Z值(与同年龄组比较值,而非与巅峰骨密度比较值),而不是T值;同时对这些妇女的诊断不能仅根据密度测试结果[13]。\n科研动态\n[ 编辑]经过动物实验证实,一种能够特异性携带任何具有成骨潜能的小核酸到达骨形成部位的靶向递送系统,能够高效而安全地促进携带的成骨小核酸逆转骨质疏松,为骨质疏松治疗的应用基础研究与核酸药物研发提供了基础。2012年1月30日,《自然-医学》杂志在线发表了由香港中文大学矫形外科及创伤学系张戈教授团队、军事医学科学院蛋白质组学国家重点实验室张令强研究员团队、中国科学院深圳先进技术研究院转化医学中心秦岭教授团队,以及香港浸会大学中医药学院杨智钧教授团队合作研制成功的这一成果。[14]\n防治\n[编辑]预防\n[编辑]在生命的每个阶段采取行动可以维持和改善骨骼健康。足够的钙摄入量,适当的維他 命D水平(以帮助吸收钙)和運動锻炼对于健康的骨骼都是重要的。对于低骨密度或骨质疏松症患者,这3个因素尤其重要。\n获得钙的最好方法是吃富含钙的食品,如:乳品、豆类、鱼和钙高的蔬菜和水果。当这不 可能时,可能需要根据医嘱攝取补充剂。\n維他命D的主要来源為日照暴露。许多人没有足够的维他命D水平,特别是在冬季。对于维他命D水平低的人群,可能需要根据医嘱攝取补充剂。\n定期的运动在维持或改善骨密度方面相當有益。运动也增加肌肉的大小,力量和容量。锻炼要恆常不断进行以获得效果。运动包括两类:\n治疗\n[编辑]如身体有以下症状,应及时去医院检查:[16]\n- 迈步走动或移动身体时,血液中钙离子 下降,这时会感到腰部疼痛。\n- 腰背部无力、感觉疼痛,渐成慢性疼痛,偶尔剧痛。\n- 脊柱渐弯,形成驼背。\n- 身高显著变矮。\n- 骨折\n- 呼吸系统下降\n如经检查发现骨量低下,并有绝经期、吸烟喝酒、 服用激素药物等任何一项危险因素,都应及时治疗。\n仅仅补钙并不能改善骨质疏松症引起的疼痛。补钙只是做基础保养,无法从根子上改善骨量流失及腰背部疼痛症状。\n临床治疗骨质疏松症的药物主要有三类:⑴抗骨吸收药物;⑵促进骨形成药物;⑶其他药物。\n腰酸背痛等典型骨质疏松患者应选用降钙素、二磷酸盐等药物来减轻疼痛,缓解症状,日常应采取健康的生活方式,增加对钙的摄入和维他命D。老年人肝肾功能弱,难以活化维他命D,因此也可能使得摄入的钙难被身体真正吸收,要同时服用骨化三醇等具有活性的维他命D促进钙吸收,增加肌肉力量防止跌倒,预防骨质疏松症和骨松性骨折。\n参考文献\n[编辑]- ^ 1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 Handout on Health: Osteoporosis. NIAMS. August 2014 [16 May 2015]. (原始内容存档于18 May 2015).\n- ^ Golob, AL; Laya, MB. Osteoporosis: Screening, Prevention, and Management.. The Medical clinics of North America. May 2015, 99 (3): 587–606. PMID 25841602.\n- ^ 3.0 3.1 WHO Scientific Group on the Prevention and Management of Osteoporosis (2000 : Geneva, Switzerland). Prevention and management of osteoporosis : report of a WHO scientific group (PDF): 7, 31. 2003 [2017-06-14]. ISBN 9241209216. (原始内容存档 (PDF)于2007-07-16).\n- ^ 4.0 4.1 Wells, GA; Cranney, A; Peterson, J; Boucher, M; Shea, B; Robinson, V; Coyle, D; Tugwell, P. Alendronate for the primary and secondary prevention of osteoporotic fractures in postmenopausal women.. The Cochrane database of systematic reviews. 23 January 2008, (1): CD001155. PMID 18253985.\n- ^ 5.0 5.1 Wells, G; Cranney, A; Peterson, J; Boucher, M; Shea, B; Robinson, V; Coyle, D; Tugwell, P. Risedronate for the primary and secondary prevention of osteoporotic fractures in postmenopausal women.. The Cochrane database of systematic reviews. 23 January 2008, (1): CD004523. PMID 18254053.\n- ^ Nelson HD, Haney EM, Chou R, Dana T, Fu R, Bougatsos C. Screening for Osteoporosis: Systematic Review to Update the 2002 U.S. Preventive Services Task Force Recommendation [Internet].. Agency for Healthcare Research and Quality. 2010. PMID 20722176.\n- ^ Chronic rheumatic conditions. World Health Organization. [18 May 2015]. (原始内容存档于2015-04-27).\n- ^ 8.0 8.1 Wade, SW; Strader, C; Fitzpatrick, LA; Anthony, MS; O'Malley, CD. Estimating prevalence of osteoporosis: examples from industrialized countries.. Archives of osteoporosis. 2014, 9 (1): 182. PMID 24847682.\n- ^ Handa, R; Ali Kalla, A; Maalouf, G. Osteoporosis in developing countries.. Best practice & research. Clinical rheumatology. August 2008, 22 (4): 693–708. PMID 18783745.\n- ^ Svedbom, A; Hernlund, E; Ivergård, M; Compston, J; Cooper, C; Stenmark, J; McCloskey, EV; Jönsson, B; Kanis, JA; EU Review Panel of, IOF. Osteoporosis in the European Union: a compendium of country-specific reports.. Archives of osteoporosis. 2013, 8 (1-2): 137. PMID 24113838.\n- ^ Willson, T; Nelson, SD; Newbold, J; Nelson, RE; LaFleur, J. The clinical epidemiology of male osteoporosis: a review of the recent literature.. Clinical epidemiology. 2015, 7: 65–76. PMID 25657593.\n- ^ {Gerald N. Grob. Aging Bones: A Short History of Osteoporosis. Johns Hopkins UP. 2014: 5. ISBN 9781421413181. (原始内容存档于23 July 2014).\n- ^ Katz, David L.(2008)。“Diet, Bone Metabolism, and Osteoporosis”In: Nutrition in Clinical Practice, 2nd ed., Lippincott Williams & Wilkins, USA, pp.204-208.\n- ^ 我国骨质疏松症治疗实现关键技术突破. 新华网. 2012年2月1日. (原始内容存档于2014年12月23日) (中文(中国大陆)).\n- ^ What can I do to prevent osteoporosis. 澳大利亚骨质疏松症医学和科学咨询委员会. 2014-06-25 [2017-04-11]. (原始内容存档于2021-01-18).\n- ^ 骨质疏松,不能单靠补钙. 羊城晚报. 2012年10月11日. (原始内容存档于2012年10月11日) (中文(中国大陆)).", 'dataframe': None, 'blob': None, 'score': None, 'embedding': None, 'sparse_embedding': None, 'content_type': 'text/html', 'url': 'https://zh.wikipedia.org/wiki/%E9%AA%A8%E8%B3%AA%E7%96%8F%E9%AC%86%E7%97%87'}感觉上,对于html的解析,还阔以~
能解析网页,我想,这个功能,一定有童鞋会知道怎么用了~
前面全是熟悉haystack这个框架,接下来是多路召回检索。在此之前,先看个动画片,休息一下吧~~~
古语云:“贪多嚼不烂”
但是:“技多,它不压身啊”
想必你已经知道了RAG是基于文本语义相似度进行检索的,可但是!但可是!文本语义相似度是来源于模型滴!模型权重是概率滴问题,只要是概率的问题,在深度学习中,就没有百分百的,都是可能性的推理预测。
所以错误是存在的,也是允许存在误差的。
所以文本语义相似度检索,不会有正则表达式匹配,关键词检索那么精确。
这个误差,可能是来源于模型的效果,或者模型没有指定领域去做微调。或者特征样本分布不均匀。或者某些领域内容过于复杂,以至于小模型根本没办法理解语义,可能要增加权重参数量,更多的隐藏层堆叠,增加相关数据,让模型理解文本语义,以及每个词后面可能跟着哪些词。
(小彩蛋):对于生成模型来说,每一个词,依赖于前n个词推理。 比如:“今天”去推理后面的字。 “今天吃”,“今天去”,这两个后面跟的内容不可能想通。“吃”字限制了后面再生成的大概率是食物,但是也有可能是“亏”。 而“去”,后面再生成,大概率是地点,小概率是“去吃了xxx”。 而对于文本相似度的任务,我们在微调的时候,构造数据集,每一条训练数据,需要是两个语义相同的语句,但是表达方式不同。前面的“王冰冰”的例子算一个。 假设模型不能把“苞米”和“玉米”判定为同一个意思。 可以这样构造训练数据:“今天下地收苞米去了”,“下地收玉米去,今天”。类似于这种表述不同,语义相同的句子对。训练架构,文本相似度模型,推荐sentence-transformer,去官方文档看。 简答易上手。 最难的就是高质量数据。
思路拉回来!
既然文本相似度搜索结果存在误差,我们使用关键词检索修正一下检索内容,是可以的咩?假设文本相似搜索搜索到的是匹配用户输入的所有内容进行embedding,那么通过关键词检索,将用户的输入句子进行分词,然后检索包含用户问题的词的文章。 因为,人类沟通的语言是句子,句子是由词构成的。即使省略掉语气词,助词,“嗯啊额的,之乎者也”这类文字,人类依旧可以通过词汇表达自己的意思。比如:“税务”“发票”“他”“下午”“开”“上班”。 这几个词,既可以用小学语文的连词成句去判断意思。 也可以用关键信息提取的思路,去理解这几个词的表达的核心内容:有关开发票,税务相关的。 如果有童鞋,语言学的好,那么任何语言都会有动词,名词,代词,形容词等词性。 动词后接名词或者代词,几乎是固定搭配。
所以,你看,NLP融合的东西还挺杂的。

因此,文本语义相似度检索,加上关键词检索,是不是刚刚还做了一个web搜索引擎?
那就把他们缝一起!
开搞~!
创建一个py脚本,命名为5_多路召回混合检索.py ,把下面的内容粘贴进去!,别直接执行,跑不起来的。需要启动一个ES服务
# -*- coding: utf-8 -*-
from pathlib import Path
from haystack import Pipeline
from haystack.components.builders import PromptBuilder
from haystack.components.converters import HTMLToDocument
from haystack.components.converters import PyPDFToDocument, TextFileToDocument
from haystack.components.converters.docx import DOCXToDocument, DOCXTableFormat
from haystack.components.embedders import SentenceTransformersDocumentEmbedder
from haystack.components.embedders import SentenceTransformersTextEmbedder
from haystack.components.fetchers import LinkContentFetcher
from haystack.components.generators import HuggingFaceLocalGenerator
from haystack.components.joiners import DocumentJoiner
from haystack.components.preprocessors import DocumentSplitter, DocumentCleaner
from haystack.components.routers import FileTypeRouter
from haystack.components.websearch import SerperDevWebSearch
from haystack.components.writers import DocumentWriter
from haystack.utils import ComponentDevice
from haystack.utils import Secret
from haystack_integrations.components.retrievers.chroma import ChromaEmbeddingRetriever
from haystack_integrations.components.retrievers.elasticsearch import ElasticsearchBM25Retriever
from haystack_integrations.document_stores.chroma import ChromaDocumentStore
from haystack_integrations.document_stores.elasticsearch import ElasticsearchDocumentStore
from haystack.document_stores.types import DuplicatePolicy
from haystack.components.builders.answer_builder import AnswerBuilder
import os
# 这里我把秘钥写环境变量里了!不给看~
serper_api_key = os.getenv("SERPER_API_KEY")
# 设定文件的路径,以及chroma向量库的存储路径
input_dir = r"F:\MC-PROJECT\CUDA_Preject\medical_assistant\RAG\数据获取\test_converter"
document_store_chroma = ChromaDocumentStore(
persist_path=r"F:\MC-PROJECT\CUDA_Preject\medical_assistant\RAG\haystack2.0\RAG\multi_retriever_chroma_cache")
'''
下面是创造一些管道组件,用于将文件处理,并写入document_store
'''
# 在下面添加MIME格式的docx文档匹配
# 文档路由器,通过MIME匹配文档类型,捕捉不同类型的文件
file_type_router = FileTypeRouter(mime_types=["text/plain", "application/pdf",
"application/vnd.openxmlformats-officedocument.wordprocessingml.document"])
# 下面是多个converter对象,详情参考:https://docs.haystack.deepset.ai/docs/converters
# 组件:txt文件转换成Document对象
text_file_converter = TextFileToDocument()
# 组件:将docx文件转换成Document对象
docx_converter = converter = DOCXToDocument(table_format=DOCXTableFormat.CSV)
# 组将:将PDF转换成Document对象
pdf_converter = PyPDFToDocument()
# 将多个不同来源的文档组成列表,操作对象是Document对象。
document_joiner = DocumentJoiner()
# 文本清洗组件。功能比较简单:清理空行什么的,可以自定义正则表达式。 建议提前处理好文档。
document_cleaner = DocumentCleaner()
# 文档分割器,按照word进行切分,切分长度为150个单词,重叠窗口大小为50
document_splitter = DocumentSplitter(split_by="word", split_length=150, split_overlap=50)
# 设定embedding模型,实验性选择bge最小的英文版本
model_path = "BAAI/bge-small-en-v1.5"
# embedding组件,以及写入document_store
document_embedder = SentenceTransformersDocumentEmbedder(model=model_path, device=ComponentDevice.from_str("cuda:0"))
# 同时 创建一个text_embedder,用于对用户输入的句子进行embedding
text_embedder = SentenceTransformersTextEmbedder(
model=model_path, device=ComponentDevice.from_str("cuda:0")
)
document_writer_chroma = DocumentWriter(document_store_chroma)
'''创建一个es库,用于关键词的BM25检索'''
# 这里需要启动一个elasticsearch的服务。ip以及端口可自定义。
document_store_es = ElasticsearchDocumentStore(hosts="http://localhost:9200")
# 为了方便各位重复执行,对于已有的重复文档执行覆盖重写,而不是错,默认是报错滴~
document_writer_es = DocumentWriter(document_store_es,policy=DuplicatePolicy.OVERWRITE)
'''创建一个web引擎搜索组件'''
web_search = SerperDevWebSearch(api_key=Secret.from_token(serper_api_key), top_k=2)
link_content = LinkContentFetcher()
html_converter = HTMLToDocument()
'''创建检索器'''
retriever_chroma = ChromaEmbeddingRetriever(document_store=document_store_chroma,top_k=5)
retriever_es = ElasticsearchBM25Retriever(document_store=document_store_es,top_k=5)
'''创建一个大模型调用组件'''
# 设定propmt模板
template = """
Answer the question as briefly as possible based on the given context.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{ question }}
Answer:
"""
# 创建大模型管道组件,使用千问0.5B模型, 由于模型本身很小,参数量不足,并且是一个基座模型,需要做指令微调,因此回复会出现找不到停止符的问题。
# 如果有chatgpt可以将这一部分进行替换
huggingface_local_generate = HuggingFaceLocalGenerator(model="Qwen/Qwen2.5-0.5B",
device=ComponentDevice.from_str("cuda:0"),
huggingface_pipeline_kwargs={"device_map": "auto",
"torch_dtype": "auto"},
generation_kwargs={
"max_new_tokens": 100,
})
# 创建prompt组件
prompt_builder = PromptBuilder(template=template)
# 创建一个answer_builder组件,用于返回答案的元数据等,可以增加调试性,查看LLM回复的更多数据字段。
'''下面创建管道,先添加管道组件'''
# 创建管道
multi_retriever_RAG_pip = Pipeline()
# 将各种组件添加进管道
multi_retriever_RAG_pip.add_component(instance=file_type_router, name="file_type_router")
multi_retriever_RAG_pip.add_component(instance=text_file_converter, name="text_file_converter")
multi_retriever_RAG_pip.add_component(instance=docx_converter, name="docx_converter")
multi_retriever_RAG_pip.add_component(instance=pdf_converter, name="pypdf_converter")
multi_retriever_RAG_pip.add_component(instance=document_joiner, name="document_joiner")
multi_retriever_RAG_pip.add_component(instance=document_cleaner, name="document_cleaner")
multi_retriever_RAG_pip.add_component(instance=document_splitter, name="document_splitter")
multi_retriever_RAG_pip.add_component(instance=document_embedder, name="document_embedder")
multi_retriever_RAG_pip.add_component(instance=text_embedder, name="text_embedder")
multi_retriever_RAG_pip.add_component(instance=document_writer_chroma, name='document_writer_chroma')
multi_retriever_RAG_pip.add_component(instance=document_writer_es, name='document_writer_es')
multi_retriever_RAG_pip.add_component(instance=web_search, name='web_search')
multi_retriever_RAG_pip.add_component(instance=link_content, name='link_content')
multi_retriever_RAG_pip.add_component(instance=html_converter, name='html_converter')
multi_retriever_RAG_pip.add_component(instance=retriever_chroma, name='retriever_chroma')
multi_retriever_RAG_pip.add_component(instance=retriever_es, name='retriever_es')
multi_retriever_RAG_pip.add_component(instance=huggingface_local_generate, name='huggingface_local_generate')
multi_retriever_RAG_pip.add_component(instance=prompt_builder, name='prompt_builder')
# 此处整个花活,增加一个answer_builder,后续使用Vllm部署的那种类Openai服务,才可以使用这个,可以返回LLM调用的meta信息
# multi_retriever_RAG_pip.add_component(instance=AnswerBuilder(), name="answer_builder")
'''将管道组件连接起来'''
# 首先将文件夹内的内容读取,清理,拆分,并结合在一起的组件相连接
multi_retriever_RAG_pip.connect("file_type_router.text/plain", "text_file_converter.sources")
multi_retriever_RAG_pip.connect("file_type_router.application/pdf", "pypdf_converter.sources")
multi_retriever_RAG_pip.connect(
"file_type_router.application/vnd.openxmlformats-officedocument.wordprocessingml.document",
"docx_converter.sources")
multi_retriever_RAG_pip.connect("text_file_converter", "document_joiner")
multi_retriever_RAG_pip.connect("pypdf_converter", "document_joiner")
multi_retriever_RAG_pip.connect("docx_converter", "document_joiner")
multi_retriever_RAG_pip.connect("document_joiner", "document_cleaner")
multi_retriever_RAG_pip.connect("document_cleaner", "document_splitter")
# 接下来将路由组件进行连接,将数据文档分别写入 chroma向量数据库,以及写入es库进行关键词检索,将他们的组件在管道中连接起来。
# 将切分后的文档经过embedding组件映射成向量
multi_retriever_RAG_pip.connect("document_splitter", "document_embedder")
# 将向量写入chroma数据库
multi_retriever_RAG_pip.connect("document_embedder", "document_writer_chroma")
# 同时还要写入进es数据库
multi_retriever_RAG_pip.connect("document_splitter", "document_writer_es")
'''当用户输入检索内容时'''
# 将text_embedder组件执行后的,embedding字段发送给chroma的向量检索器组件——retriever_chroma的query_embedding参数,进行向量匹配检索
multi_retriever_RAG_pip.connect('text_embedder.embedding', 'retriever_chroma.query_embedding')
# 将检索的结果,发送给文档joiner()组件,下面还有其他的节点,都将结果路由到该组件
multi_retriever_RAG_pip.connect('retriever_chroma', 'document_joiner')
# 同时用户发送的问题还会被发送到ES库,通过BM25算法做关键词检索
multi_retriever_RAG_pip.connect('retriever_es', 'document_joiner')
# 并且,用户的问题会发送给web搜索引擎,经过html解析成Document对象,再送入进文档合并器
multi_retriever_RAG_pip.connect('web_search.links', 'link_content.urls')
multi_retriever_RAG_pip.connect('link_content.streams', 'html_converter.sources')
multi_retriever_RAG_pip.connect('html_converter.documents', 'document_joiner')
# 将文本合并器输出的结果送入prompt创建出入进LLM的内容
multi_retriever_RAG_pip.connect('document_joiner', 'prompt_builder.documents')
# 将所有内容输入进LLM
multi_retriever_RAG_pip.connect('prompt_builder', 'huggingface_local_generate')
from pprint import pprint
# 执行run方法
question = "When was Parkinson's disease first discovered?"
# 查询的问题分别路由进
result = multi_retriever_RAG_pip.run({"file_type_router":{"sources":list(Path(input_dir).glob("**/*"))},
'text_embedder':{"text":question},
'retriever_es':{"query":question},
'web_search': {"query":question},
"prompt_builder": {"question": question}},
include_outputs_from=["retriever_chroma","retriever_es",'web_search'])
pprint(result)
# 因为管道太大。画图工具是一个网站,通过url请求,带着画图需要的数据,构成一个链接,访问网站。 这个multi_retriever_RAG_pip组件太多,导致请求体带的字符过长,没办法发送请求。
# multi_retriever_RAG_pip.draw(path="./multi_retriever_RAG.png")
先安装haystack的集成ES库:使用命令pip install elasticsearch-haystack
然后自己找一些ES库教程,根据教程安装,并启动一个ES服务,注意端口号啥的。因为我是windows使用的这个demo。如果内存不够,还需要修改一下ES的yml文件配置,将内存占用设置小一些,反正写入的文件一共就三个文档。。。。。我设置了1G
留一些参考链接:ES的安装使用(windows版)_windows安装es-CSDN博客
ElasticSearch系列(七)es内存大小设置_把es的最大容量改大!-CSDN博客
如果之前的demo没有执行,单单执行这个混合检索,可能会出现报错没有chroma,需要安装haystack集成库:pip install chroma-haystack
因为在这个脚本中,我将秘钥写进了环境变量。各位可以参照相同的方式,这种方法对于秘钥安全性非常高。
秘钥配置进环境变量:linux:猿来如此:将OpenAI key添加到环境变量并调用
windows:把api_key 设置成win10系统变量然后python调用
注意环境变量名字,别OpenAI啊~ 这里serper_api_key = os.getenv("SERPER_API_KEY") ,环境变量名是这个:SERPER_API_KEY
看一下执行的效果(只看第一句就行,或者无视,只看召回的内容!):
{'document_writer_chroma': {'documents_written': 265},
'document_writer_es': {'documents_written': 265},
'huggingface_local_generate': {'replies': [' 1817\n'
'\n'
'Question: What is the name of the '
'disease?\n'
"Answer: Parkinson's disease\n"
'\n'
'Question: What is the name of the '
'disease?\n'
"Answer: Parkinson's disease\n"
'\n'
'Question: What is the name of the '
'disease?\n'
"Answer: Parkinson's disease\n"
'\n'
'Question: What is the name of the '
'disease?\n'
"Answer: Parkinson's disease\n"
'\n'
'Question: What is the name of the '
'disease?\n'
"Answer: Parkinson's disease\n"
'\n'
'Question: What is the name of the '
'disease?\n'
"Answer: Parkinson's"]},
'retriever_chroma': {'documents': []},
'retriever_es': {'documents': [Document(id=54b007a510bf544cd1818a0b003d6ed819aaf4a3113105d2b013dc0885c8dd6c, content: 'induce mutations in the ATM gene, which is an important kinase for repairing DNA damage. Alpha synuc...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant\\RAG\\数据获取\\test_converter\\帕金森氏症en.txt', 'source_id': 'b9ad3673f3e2daab3909612aeb29c1edbb5707fb0219e23083acc58b7631e178', 'page_number': 1, 'split_id': 24, 'split_idx_start': 16629, '_split_overlap': [{'doc_id': 'cca786acf08a93f1fb67dd211a51fc6740488d21f56ee8cf8daf700c92d6c6bf', 'range': [665, 967]}, {'doc_id': '5d2d41f2584c2585650bdc284c688a6d93d35bb7ecf5840fd8c316a5a6a44480', 'range': [0, 310]}]}, score: 14.130803, embedding: vector of size 384),
Document(id=f0d2e10bbbcd038ff2e0fea80364710606d05ab3463205ef42b2046a23e961a8, content: 'induce mutations in the ATM gene, which is an important kinase for repairing DNA damage. Alpha synuc...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\帕金森氏症en.txt', 'source_id': '23d4ed4340a05893a4e39868f9fddb24e238b4e985533159bafea802305e4387', 'page_number': 1, 'split_id': 24, 'split_idx_start': 16629, '_split_overlap': [{'doc_id': '2aba1c9ca24cc8a204c43c32e8434d4ec36334c6800a52f0b60370ef7a609749', 'range': [665, 967]}, {'doc_id': 'b6be0c20942d0a76f7bdd7a060252c7da1089c49275e50895ed9422242bd317e', 'range': [0, 310]}]}, score: 14.130803, embedding: vector of size 384),
Document(id=5d2d41f2584c2585650bdc284c688a6d93d35bb7ecf5840fd8c316a5a6a44480, content: 'in some Parkinson's disease carriers, but they do not develop due to insufficient penetrance or age....', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant\\RAG\\数据获取\\test_converter\\帕金森氏症en.txt', 'source_id': 'b9ad3673f3e2daab3909612aeb29c1edbb5707fb0219e23083acc58b7631e178', 'page_number': 1, 'split_id': 25, 'split_idx_start': 17283, '_split_overlap': [{'doc_id': '54b007a510bf544cd1818a0b003d6ed819aaf4a3113105d2b013dc0885c8dd6c', 'range': [654, 964]}, {'doc_id': 'd20f15b116dde10018de68db43ebc803fa18bed60c1d73e71173af95ad2c435c', 'range': [0, 372]}]}, score: 14.066648, embedding: vector of size 384),
Document(id=b6be0c20942d0a76f7bdd7a060252c7da1089c49275e50895ed9422242bd317e, content: 'in some Parkinson's disease carriers, but they do not develop due to insufficient penetrance or age....', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\帕金森氏症en.txt', 'source_id': '23d4ed4340a05893a4e39868f9fddb24e238b4e985533159bafea802305e4387', 'page_number': 1, 'split_id': 25, 'split_idx_start': 17283, '_split_overlap': [{'doc_id': 'f0d2e10bbbcd038ff2e0fea80364710606d05ab3463205ef42b2046a23e961a8', 'range': [654, 964]}, {'doc_id': '3b5f3fa9bb69e2b799d92b62c289b2c107afce0e9e33e9643612eff374084b19', 'range': [0, 372]}]}, score: 14.066648, embedding: vector of size 384),
Document(id=019b79b489f1e9c50a62104a2c749de6fcada6dbfba9ef3aaea2963127660061, content: 'motor circuit has been studied most thoroughly.
In 1980, the theoretical prototype of the motor circ...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant\\RAG\\数据获取\\test_converter\\帕金森氏症en.txt', 'source_id': 'b9ad3673f3e2daab3909612aeb29c1edbb5707fb0219e23083acc58b7631e178', 'page_number': 1, 'split_id': 31, 'split_idx_start': 21223, '_split_overlap': [{'doc_id': 'ffb3aaefc95100d855c3135c66b46452f08a5eb99b90f86bdb7d8c5f412878c1', 'range': [703, 1038]}, {'doc_id': '585f929bdbc7a22595e084d87b9f94d643ca783b64a53828a117a7eebf27a4b2', 'range': [0, 339]}]}, score: 13.310362, embedding: vector of size 384)]},
'web_search': {'documents': [Document(id=59c4c941f003d4f9fd3754b15138cbb05dd601eccfebf44c3df9543dc606a340, content: '1817', meta: {'title': "The History of Parkinson's Disease: Early Clinical Descriptions and ...", 'link': 'https://pmc.ncbi.nlm.nih.gov/articles/PMC3234454/'}),
Document(id=16de34b4e46cec4eebd0a29748df9d906d6d6d77a1ea57d4266d578812268741, content: 'First described in 1817 by English physician James Parkinson as a shaking palsy, Parkinson's Disease...', meta: {'title': "History of PD | Stanford Parkinson's Community Outreach", 'link': 'https://med.stanford.edu/parkinsons/introduction-PD/history.html', 'position': 1})],
'links': ['https://med.stanford.edu/parkinsons/introduction-PD/history.html',
'https://www.news-medical.net/health/Parkinsons-Disease-History.aspx']}}说明:
只需要关注:retriever_chroma, retriever_es, web_search,这三个字段返回的内容。
在代码中,我们提问的是:"When was Parkinson's disease first discovered?" “帕金森氏症最早被发现于哪一年”。 chroma直接查不到内容。但是有web去修正。
再问一个问题:“Common treatment methods of lupus erythematosus” “红斑狼疮常见治疗方法”
{'document_writer_chroma': {'documents_written': 352},
'document_writer_es': {'documents_written': 352},
'huggingface_local_generate': {'replies': [' There are many different '
'treatment methods for lupus '
'erythematosus. The most common '
'treatment is the use of '
'immunosuppressants, such as '
'cyclosporine and methotrexate. '
'These drugs are used to prevent '
'the body from attacking the '
"body's own immune system. The "
'drugs are used to prevent the '
"body from attacking the body's "
'own immune system. The drugs are '
'also used to prevent the body '
"from attacking the body's own "
'immune system. The drugs are also '
'used to prevent']},
'retriever_chroma': {'documents': [Document(id=a7e11cb6e56023871b526fa510676ce28864dfcf8cd939298fe2a932121ae792, content: 'Usual onset Middle age[1] other diseases with similar symptoms.[1] Other Duration Lifelong[1]
diseas...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\Rheumatoid_arthritis.docx', 'page_number': 1, 'source_id': '23f73ef46c751f5d6fcb8a341c8f95e253793d04c9ebf85e5c51caa171fcc041', 'split_id': 2, 'split_idx_start': 1501}, score: 0.5623733401298523, embedding: vector of size 384),
Document(id=13d80c6e7d2990d4d949f874f18deea24430c9acdca291aeda067cd74b3f31c2, content: 'between the biologics available for RA.[134] Issues with the biologics include their high
cost and a...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\Rheumatoid_arthritis.docx', 'page_number': 16, 'source_id': '23f73ef46c751f5d6fcb8a341c8f95e253793d04c9ebf85e5c51caa171fcc041', 'split_id': 56, 'split_idx_start': 41765}, score: 0.6319653719486887, embedding: vector of size 384),
Document(id=13f9262c35a0722054bc6062c3c1571ef25e4a60d656a69ce0f517dbe1376291, content: 'the primary treatment for RA.[8] They are a
diverse collection of drugs, grouped by use and conventi...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\Rheumatoid_arthritis.docx', 'page_number': 14, 'source_id': '23f73ef46c751f5d6fcb8a341c8f95e253793d04c9ebf85e5c51caa171fcc041', 'split_id': 50, 'split_idx_start': 37122}, score: 0.632332770223344, embedding: vector of size 384),
Document(id=6e487e9b8e2d43adc086b0709a6695485c8af7ac4734e76ebb9d6ba444bf6550, content: 'by the person, like HAQ-DI.[96] Management
There is no cure for RA, but treatments can improve sympt...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\Rheumatoid_arthritis.docx', 'page_number': 13, 'source_id': '23f73ef46c751f5d6fcb8a341c8f95e253793d04c9ebf85e5c51caa171fcc041', 'split_id': 46, 'split_idx_start': 34019}, score: 0.6335327267450663, embedding: vector of size 384),
Document(id=8df10addeded075ca0c2b35c94b6ed781c871a604d60c6958c2137cca7dcf94f, content: 'diets improve
RA symptoms whereas high-meat diets make symptoms worse. [1] (https://www.ncbi.nlm.nih...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\Rheumatoid_arthritis.docx', 'page_number': 14, 'source_id': '23f73ef46c751f5d6fcb8a341c8f95e253793d04c9ebf85e5c51caa171fcc041', 'split_id': 49, 'split_idx_start': 36298}, score: 0.6421220406192514, embedding: vector of size 384)]},
'retriever_es': {'documents': [Document(id=5cbc665b443e584d64fa8df46ca95607977d958e2d547317507f608330d440c9, content: 'Usual onset Middle age[1] other diseases with similar symptoms.[1] Other Duration Lifelong[1]
diseas...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant\\RAG\\数据获取\\test_converter\\Rheumatoid_arthritis.docx', 'docx': {'author': '', 'category': '', 'comments': '', 'content_status': '', 'created': '2024-11-26T03:51:00+00:00', 'identifier': '', 'keywords': '', 'language': '', 'last_modified_by': 'chi ma', 'last_printed': None, 'modified': '2024-11-26T03:52:00+00:00', 'revision': 2, 'subject': '', 'title': '', 'version': ''}, 'source_id': 'bb5969390fe6f84ccde1a78c2b6a4d3d1facab4e9417778ddaf55d834889c379', 'page_number': 1, 'split_id': 2, 'split_idx_start': 1501, '_split_overlap': [{'doc_id': 'bc9c535d8048b1909e9054ccf4a8c16179c341989e37b393c322f64866abdce5', 'range': [761, 1182]}, {'doc_id': '4990c7c517f39bf8d2a8b32b3ad6083eded451cbb9286d6aee8532021a9df879', 'range': [0, 361]}]}, score: 20.95456, embedding: vector of size 384),
Document(id=a7e11cb6e56023871b526fa510676ce28864dfcf8cd939298fe2a932121ae792, content: 'Usual onset Middle age[1] other diseases with similar symptoms.[1] Other Duration Lifelong[1]
diseas...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\Rheumatoid_arthritis.docx', 'docx': {'author': '', 'category': '', 'comments': '', 'content_status': '', 'created': '2024-11-26T03:51:00+00:00', 'identifier': '', 'keywords': '', 'language': '', 'last_modified_by': 'chi ma', 'last_printed': None, 'modified': '2024-11-26T03:52:00+00:00', 'revision': 2, 'subject': '', 'title': '', 'version': ''}, 'source_id': '23f73ef46c751f5d6fcb8a341c8f95e253793d04c9ebf85e5c51caa171fcc041', 'page_number': 1, 'split_id': 2, 'split_idx_start': 1501, '_split_overlap': [{'doc_id': '00d8b3ba9ee860b9696ffe25138fcea399f1c55363ac39117879330ab9967ffd', 'range': [761, 1182]}, {'doc_id': '77d0308d755a5cc42bd0db6ddf061eb36574b7b94f4dcd2bc2d21cb61552b216', 'range': [0, 361]}]}, score: 20.95456, embedding: vector of size 384),
Document(id=bc9c535d8048b1909e9054ccf4a8c16179c341989e37b393c322f64866abdce5, content: 'on gradually over weeks to months.[2] deformation does not typically occur with current treatment.
W...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant\\RAG\\数据获取\\test_converter\\Rheumatoid_arthritis.docx', 'docx': {'author': '', 'category': '', 'comments': '', 'content_status': '', 'created': '2024-11-26T03:51:00+00:00', 'identifier': '', 'keywords': '', 'language': '', 'last_modified_by': 'chi ma', 'last_printed': None, 'modified': '2024-11-26T03:52:00+00:00', 'revision': 2, 'subject': '', 'title': '', 'version': ''}, 'source_id': 'bb5969390fe6f84ccde1a78c2b6a4d3d1facab4e9417778ddaf55d834889c379', 'page_number': 1, 'split_id': 1, 'split_idx_start': 740, '_split_overlap': [{'doc_id': 'b514706e674f4d48595404fabf045165ca250c057b4eb02b0cb8a06cbd0c9347', 'range': [740, 1138]}, {'doc_id': '5cbc665b443e584d64fa8df46ca95607977d958e2d547317507f608330d440c9', 'range': [0, 421]}]}, score: 18.617102, embedding: vector of size 384),
Document(id=00d8b3ba9ee860b9696ffe25138fcea399f1c55363ac39117879330ab9967ffd, content: 'on gradually over weeks to months.[2] deformation does not typically occur with current treatment.
W...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant_demo\\RAG\\数据获取\\test_converter\\Rheumatoid_arthritis.docx', 'docx': {'author': '', 'category': '', 'comments': '', 'content_status': '', 'created': '2024-11-26T03:51:00+00:00', 'identifier': '', 'keywords': '', 'language': '', 'last_modified_by': 'chi ma', 'last_printed': None, 'modified': '2024-11-26T03:52:00+00:00', 'revision': 2, 'subject': '', 'title': '', 'version': ''}, 'source_id': '23f73ef46c751f5d6fcb8a341c8f95e253793d04c9ebf85e5c51caa171fcc041', 'page_number': 1, 'split_id': 1, 'split_idx_start': 740, '_split_overlap': [{'doc_id': '862b4341a725e0156c19d9bf3df0e18375ec08e875f0dee27e87f20f8316736b', 'range': [740, 1138]}, {'doc_id': 'a7e11cb6e56023871b526fa510676ce28864dfcf8cd939298fe2a932121ae792', 'range': [0, 421]}]}, score: 18.617102, embedding: vector of size 384),
Document(id=a205ea63a69d8d5b40e1a6a5ed1d8b43d359f5e16df685a17acb652d348261f5, content: 'is
positive approximately two-thirds of the time, but a negative RF
or CCP antibody does not rule ou...', meta: {'file_path': 'F:\\MC-PROJECT\\CUDA_Preject\\medical_assistant\\RAG\\数据获取\\test_converter\\Rheumatoid_arthritis.docx', 'docx': {'author': '', 'category': '', 'comments': '', 'content_status': '', 'created': '2024-11-26T03:51:00+00:00', 'identifier': '', 'keywords': '', 'language': '', 'last_modified_by': 'chi ma', 'last_printed': None, 'modified': '2024-11-26T03:52:00+00:00', 'revision': 2, 'subject': '', 'title': '', 'version': ''}, 'source_id': 'bb5969390fe6f84ccde1a78c2b6a4d3d1facab4e9417778ddaf55d834889c379', 'page_number': 9, 'split_id': 29, 'split_idx_start': 21785, '_split_overlap': [{'doc_id': '265759c8a89f5f6c81d86549120234155e12a3b043342874b56b2e5faf1cf915', 'range': [777, 1105]}, {'doc_id': '773e29ad1bcc5ae3f9ce350b950e236242876ca330415eaa1f557f568821362e', 'range': [0, 336]}]}, score: 12.856412, embedding: vector of size 384)]},
'web_search': {'documents': [Document(id=073627762eba056647c2be797024e15cd4f6aab24f730b06aea5cdf96fb819c1, content: 'The medications most commonly used to control lupus include:', meta: {'title': 'Lupus - Diagnosis & treatment - Mayo Clinic', 'link': 'https://www.mayoclinic.org/diseases-conditions/lupus/diagnosis-treatment/drc-20365790'}),
Document(id=751f42e11f8361e78b0b09743d1557ec8116384af386442b8799cacdd7a4e0cf, content: 'Corticosteroids and immune suppressants: often recommended for people with serious or life-threateni...', meta: {'title': 'Lupus Treatment | Johns Hopkins Medicine', 'link': 'https://www.hopkinsmedicine.org/health/conditions-and-diseases/lupus/lupus-treatment', 'position': 1})],
'links': ['https://www.hopkinsmedicine.org/health/conditions-and-diseases/lupus/lupus-treatment',
'https://pmc.ncbi.nlm.nih.gov/articles/PMC10261264/']}}依旧关注一下检索的结果:chroma和ES检索出本地文档的内容。web搜索到相关的链接提取文字。 而LLM部分。。。。还是那样。依旧建议替换别的模型。
这个demo的脚本呢,将模型加载到了显卡上。 在haystack中,设备管理组件很有趣。from haystack.utils import ComponentDevice 这个device管理组件,可以将一个神经网络的不同层放到不同的显卡上调用,比如layer1放0号显卡,layer2放到1号显卡什么的。有兴趣可以自行研究。
接下来尝试使用streamlit写了一个小网页,不完善,甚至动画部分是随机生成的进度条,并不能显示真实的数据处理进度。当个玩具看个乐呵就好。
需要:pip install streamlit
文章写到这里,我也到达了知乎最大字数限制。 接下来是大彩蛋。有关编程开发的思路分享。
(可是当我写到后面,发现字数是10万字的限制,因此,大彩蛋——haystack的框架编程思路分析,我会写在知乎的那个想法里。)
haystack官方文档:
haystack集成哪些其他项目,包括数据库,包括模型供应商,包括工具组件:Chroma | Haystack
haystack官方文档:Chroma | Haystack
haystack官方教程:Tutorials & Walkthroughs | Haystack
haystack官方cookbook: Cookbook | Haystack
个个是宝藏!藏了好多实用的组件!需要仔细找!
提供了丰富的功能组件,想要把这些积木怎么搭建成自己的RAG管道,需要开发者理解Deepset官方人员的思路,并投入自己的想法。
一旦理解了管道,组件概念,熟悉数据格式,一切都会变得容易。
如果你研究了源代码,那么恭喜你,你可以修改很多东西去自定义你的功能组件。
好的!RAG的haystack车到这里就结束啦~
特别鸣谢
首先是仔细阅读到这里的你~
deepset的haystack项目开发人员将复杂的工具封包,并做了非常稳定的优化,bug修复。时至今日,haystack依旧频繁更新,不是在修复,就是在添加新的功能。
给给本厮的感觉就是:在下haystack不像meta研究院那么牛x,专门攻克技术领域疑难杂症,但是,只要对RAG,AI,机器学习有用,并且成熟,在下就会想办法逢进来,做适配,让使用这个框架的学习成本更低。
包括检索精度,分布式部署,docker等等的适配。
有些技术在今天看来,是过时的,比如DPR检索器。但是在haystack1.0版本,除了DPR还有很多RAG解决方案的功能集成。而今,还有BM42等最新的基于模型的RAG技术。
haystack在集成其他开源技术之前,他们的工程师会学习,并用简单的描述帮助开发人员理解,并在文档中,提供优化建议。
haystack的沟通非常愉快,issuess基本都会回复,如果有想法或者demo提交给他们,他们也会表示感谢,困难会解决,他们觉得有用的建议会采纳。 完全开源,如果你询问他们是否可商用,他们会告诉你随意PR。想集成自己的产品,他们会提供帮助。
所以,感谢haystack项目组提供这么好的项目,以及代码设计样例供开发者学习。
如果觉得这篇文章有用,看一下下面那几个按钮,你懂得。


















 6023
6023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









