







Meta AI | 指令回译:如何从大量无标签文档挖掘高质量大模型训练数据?
文章来自Meta AI,self-Alignment with Instruction Backtranslation[1]:通过指令反向翻译进行自对准。
一种从互联网大量无标签数据中挖掘高质量的指令遵循数据集的方案,它利用少量种子数据,从大量互联网上无标签的数据,挖掘出大量高质量的、多样性也不错的训练数据,成功将llama(美洲驼)进化成Humpback(座头鲸)。

Title:Self-Alignment with Instruction Backtranslation
论文地址:https://arxiv.org/pdf/2308.06259.pdf
1 Motivation
现状:高质量指令数据太少,互联网上human-written text倒是比较多,但是大量的无标签数据缺乏对应的指令。
目标:研究如何利用互联网上大量的无标签的数据,生成高质量的指令集,进而提升模型的表现。
大白话:无标签文本 -> 对应的指令是什么?
2 Methods
主要依赖于两个假设:
- 在互联网上大量的无标签数据中,有些是可以作为user instructions的标准回复gold answer的。
2.根据gold answers生成的指令,可以作为一个高质量的样本去训练指令遵循模型。
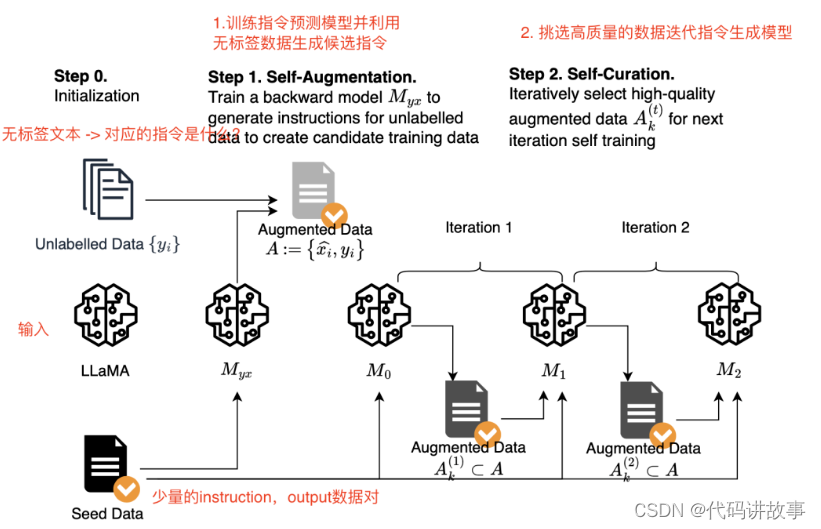
指令回译具体内容:
self-augmentation:利用种子数据训练模型并从无标签数据生成指令。1. 指令预测模型(Myx)训练:先利用少量的instruction,output数据对,训练LLama模型让其学习根据output生成对应instruction的能力。2. 利用指令预测模型Myx + 大量无标签数据 => 生成候选指令A。
self-curation: 从候选指令A中选择部分高质量的(instruction,output)数据对,然后迭代训练指令预测模型v2版本,通过这种方式迭代2轮,提升生成的指令集的质量。
步骤1 Initialization(初始化设置):收集少量种子数据和大量无标注的文本
Seed Data训练:收集少量的种子instruction,output数据,从两个方向来训练模型,第一种是根据指令生成回复。第二种种是根据回复生成指令。
Unlabelled data数据处理:对于每个文档,提取HTML标题后面的文本部分。并进行重复数据删除、长度过滤,并使用几种启发式方法删除潜在的低质量段,例如标题中大写字母的比例。
步骤2 Self-Augmentation (generating instructions指令生成):训练指令预测模型并根据无标签数据生成指令
指令预测模型训练,利用(output,instruction)训练指令预测模型,用于根据无标签的数据生成指令。注意:并不是所有的候选指令对都是高质量的,如果将它们全部用于训练不一定会有益。
步骤3 Self-Curation (selecting high-quality examples指令挑选):利用大模型本身筛选高质量的数据构建新的数据集
筛选打分步骤:
仅根据seed(指令、输出)种子示数据训练模型M0。
使用M0为每个增强示例{(xˆi, yi)}评分,以得出质量评分ai。使用提示对生成的候选指令进行评级打分(5个纬度)。
选择分数为ai ≥ k的增强示例的子集来形成高质量数据集。
筛选评分的prompt:

Iterative self-curation:迭代方法产生更高质量的预测结果。
在第t次迭代上,我们使用上一轮t-1迭代模型挑选的数据A(t-1)与种子数据一起作为训练数据,进行微调训练当前轮模型Mt。
这个模型反过来可以用于对质量的增强示例进行重新评分,从而产生一个增强集A(t)。这里执行两次数据选择和微调,以获得最终的模型M2。
其他注意事项:当合并seed data和augmented data来训练模型时,利用不同的标签来区别不同sources的数据。
对于seed data,在prompt中添加Answer in the style of an AI Assistant的句子
对于augmented data。在prompt中添加Answer with knowledge from web search句子。
3 Conclusion
在Alpaca leaderboard排行榜上,在使用少量的人类标注数据的情况下,比所有其他non-distilled instruction-following(非其他大模型蒸馏数据训练的大模型)都要好【3k的种子数据+50万无标注数据 + LLaMA大大超过了其它同类型的模型】。
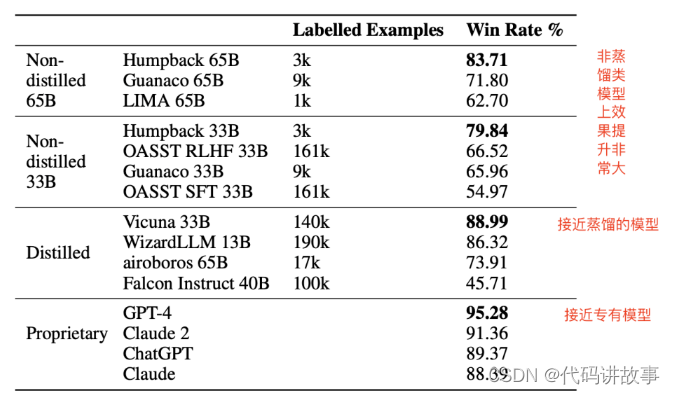
后续可以继续利用更多的无标签语料来生成更多的数据,理论上会得到更大的收益。
4 limitation
safety和bias:由于利用网上的数据来增强样本,不可避免可能会存在bias,另外也没有red teaming等策略来提升安全性,可能也会有一些风险。
二、详细内容
1 实验设置
seed data:从Open Assistant dataset挑选3200个样本作为seed data,只挑选了英文的数据,同时挑选人类标注的rank指标中最高的。
Base model&finetuning:1.LLaMA系列7B,33B,65B的模型。2.只对输出计算loss。3.利用SFT方法来微调。4.生成阶段,利用nucleus sampling(T=0.7,p=0.9)来生成结果。
Unlabelled Data:Clueweb corpus中sampled 502k个segments。
Nucleus Sampling是什么?【多样性和效果都不错的解码方案】
“Nucleus Sampling” 是一种生成文本的采样策略,主要用于语言模型生成任务,例如文本生成、对话生成等。这种采样方法的目标是在保持生成文本多样性的同时,减少一些低概率、不太可能的生成结果,从而提高生成文本的质量和可读性。
在 Nucleus Sampling 中,首先计算出每个可能的生成词的概率分布。然后,将这些概率值按照大小排序,从高到低排列。接下来,从排好序的概率分布中选择一部分概率最高的词,这部分概率总和达到一个预先设定的阈值。换句话说,从整个词汇中选取了一部分核心词(nucleus),这些词的累积概率超过了设定的阈值。
Nucleus Sampling 的一个主要优势在于它能够在一定程度上平衡生成文本的多样性和可控性。与传统的贪婪解码相比,Nucleus Sampling 能够避免过于保守的生成,同时又能够避免太多的不合理或不相关的生成。这种方法尤其在生成较长文本或需要一定上下文逻辑的任务中表现出色。
总之,Nucleus Sampling 是一种有效的生成文本的采样方法,能够在生成结果的多样性和可控性之间取得一种平衡。它在语言模型的研究和应用中具有一定的重要性。
2 数据量级和分布
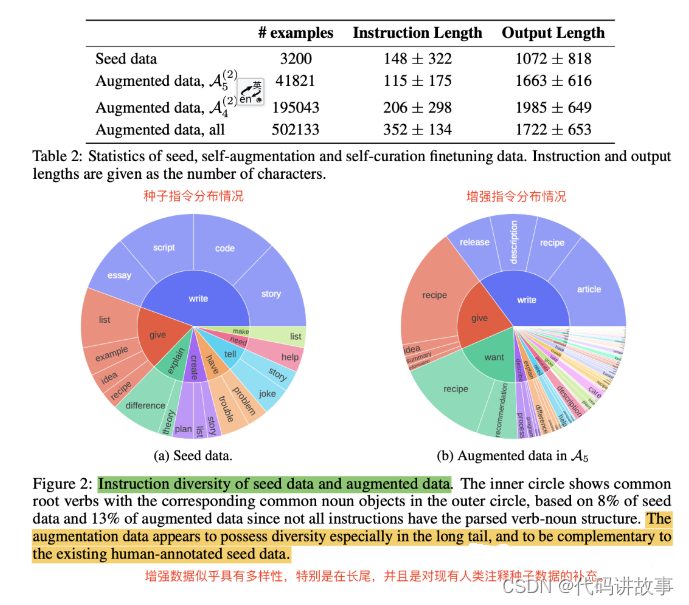
总结:增强的数据似乎多样性也不错,特别是在长尾数据上,可以看作是对现有人类标记的种子数据的补充。
3 数据量重要还是数据质量更重要?
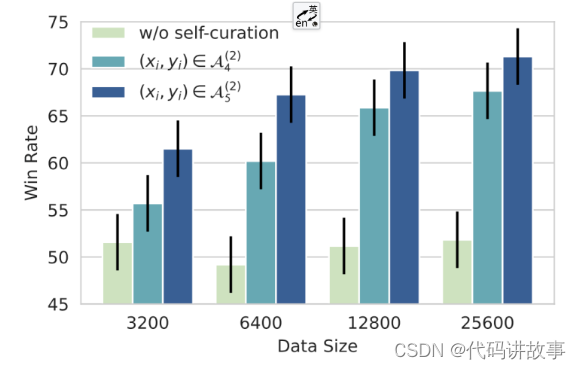
方法:拿7B的LLaMa模型+增强的数据微调,并与text-davinci-003做对比,y轴为胜率,A4数据集(19万数据),A5的数据集(4万数据)数据质量高。
结论1:不用self-curation挑选高质量的数据,只增大数据量级对模型的指令遵循能力没有任何提高,反而还可能会有下降。
结论2:质量比数量更重要,self-curation打分越高的数据,对模型效果提升越大。相对于A4(score>4)数据集来说,A5(score>4.5)的数据集筛选更高质量的数据,更大提升了模型的效果。
4 不同数据集效果对比
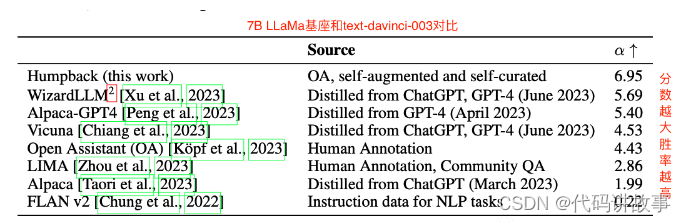
方法:对比了包括利用更好的模型蒸馏数据集(例如利用GPT-4蒸馏数据集),利用NLP任务构建数据集,本文方法构建数据集下,7B基座模型微调后与text-davinci-003对比的胜率。
结论1:大多数蒸馏指令数据集(GPT-4)比从其他来源(NLP任务(FLAN v2)或从社区问答(LIMA)中提取)创建的数据集具有更好的数据效率。
结论2:本文方法构建的数据集A5取得了更高的指令遵循performance和更好的data scaling efficient(更少的数据,更好的效果,说明本文方法生成的数据的多样性和质量都非常的高)
5 相对于不从GPT-4等模型蒸馏数据来训练模型效果提升非常大(GPT4评估)
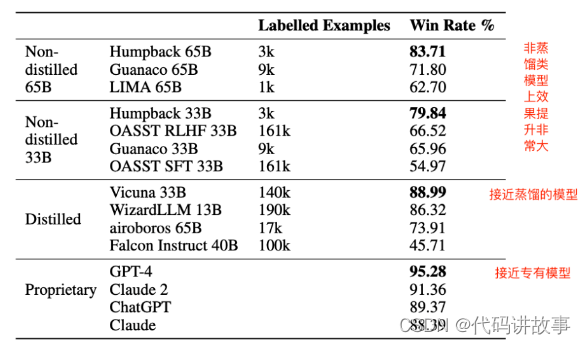
结论:不从其他大模型来蒸馏数据,利用本文提出的方法构建的数据,比其它同大小的模型对比提上非常大。
其它:本文的labelled examples3k是种子数据,最终增强后大概4万数据,4万数据开始饱和。
6 在不同大小的模型上都能带来持续的提升
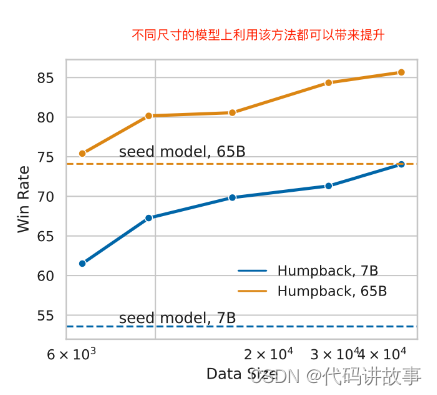
结论:不同尺寸的模型上利用该方法都可以带来提升,大概在4万指令的时候饱和。
7 NLP Benchmarks【Commonsense Reasoning和MMLU数据集】上评估
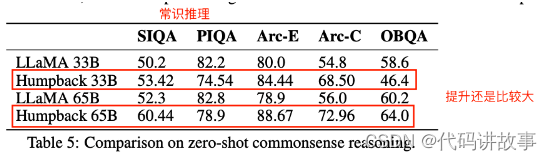
结论1: 比原始LLaMA65B提升还是非常多的,说明强如LLaMA65B,继续在数据的多样性和质量上做文章还是有比较大的空间,同时也说明本文方法构建数据的质量和多样性都非常不错。
8 消融实验
1 种子数据+增强数据同时使用效果最好
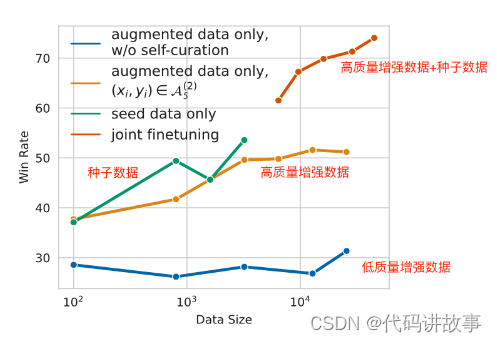
结论1: 单独使用种子数据或者增强数据,胜率都不太高,混合之后使用,胜率一下子上去了,说明种子数据和增强数据的数据分布情况也不太一样。
2 区分种子数据和增强数据也能带来不错的提升

说明:对于种子数据和增强数据,用不同的prompt来指明,发现也有不错的提升。
三、总结
直接利用互联网上的数据构建指令遵循数据集是可行的,但是要解决如何生成对应的指令,如何挑选高质量的结果,本文Instruction Backtranslation根据答案生成指令可以作为一个参考方案。
大模型指令微调最重要的还是得依赖更好的质量、更丰富的多样性。互联网上的数据多样性更好,但是缺乏对应指令,如果能利用互联网产生更多的高质量和多样性的数据,还可以继续给现有大模型像LLaMA65B等,带持续来比较大的提升。
目前开源的一些指令遵循数据集可能多样性和质量都不是特别够,还有持续优化的空间,本文方法相当于主要是提供更好的多样性。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











