






Sora学习笔记
Datawhale Sora原理与技术实战 的直播视频总结自用打卡笔记
暂时先写着这样打个卡先,等周末有空再完善笔记QAQ
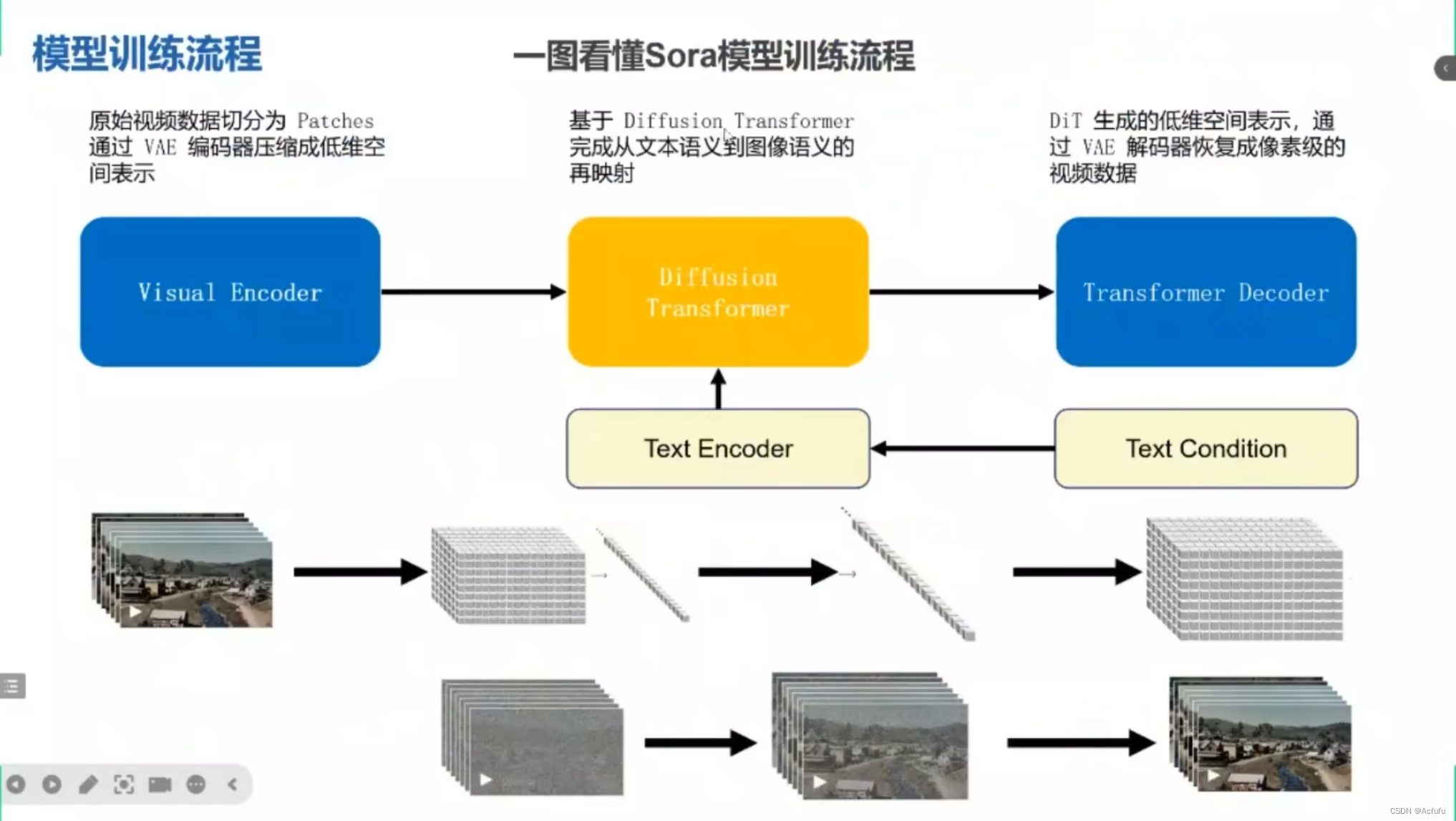
Sora模型训练流程
sora模型训练链路
(1)Visual Encoder 将原始视频切分为一个个patches,通过VAE编码器压缩成低维表示。
(2)基于Diffusion Transformer (DIT)技术,完成文本语义到图像语义的再映射。
(3)DIT通过VAE解码器恢复成像素级别视频数据。
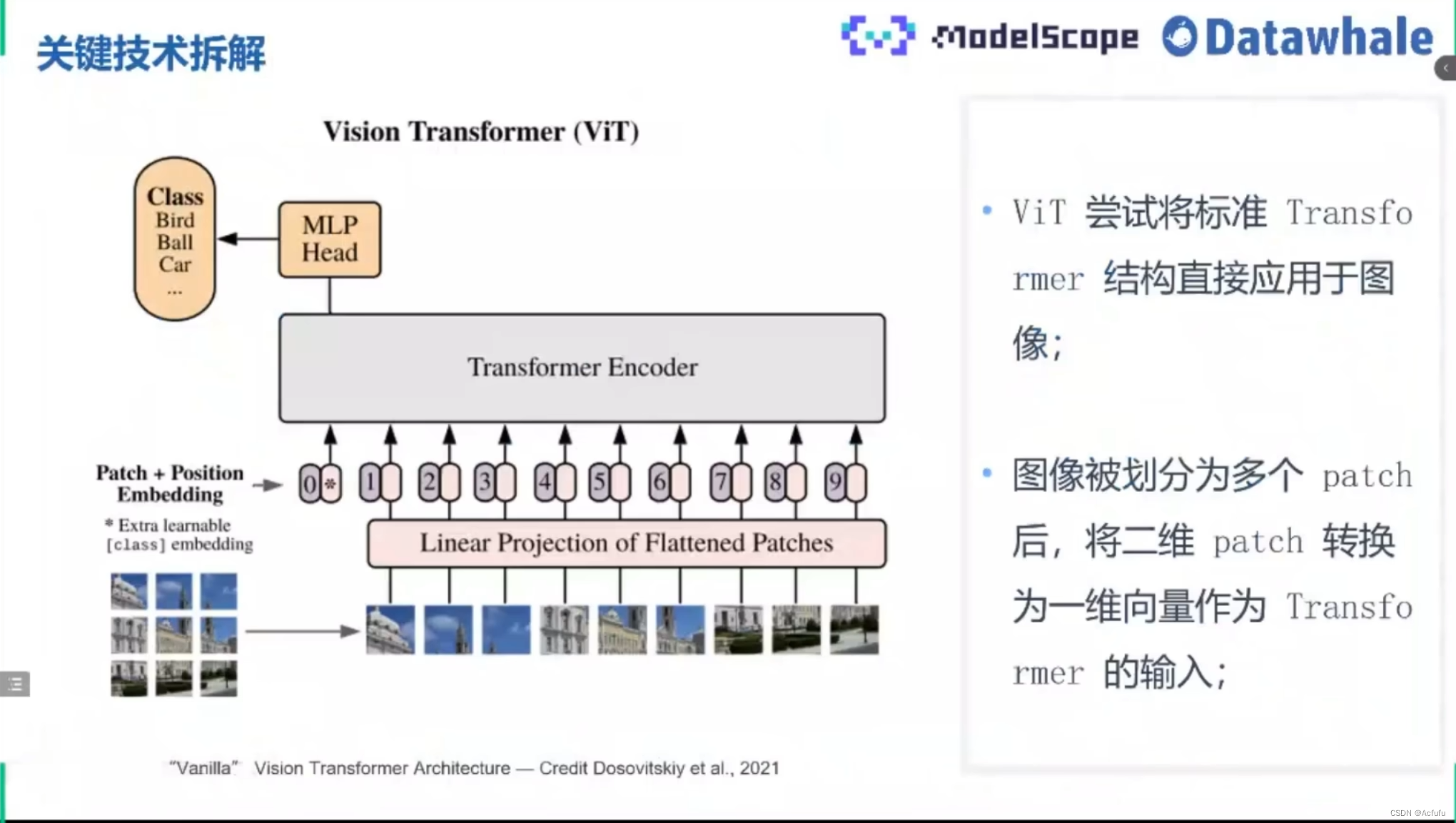
Sora关键技术拆解
1.VAE编码(Variational Auto-Encoder)变分自编码器
(1)首先了解Auto-Encoder (AE)自编码器(可以简单理解为自己训练自己)
(2)AE由两部分组成,分别为Encoder(编码器)与Decoder(解码器)E与D有相同数量神经元。
(3)由从Encoder层输入(图像)数据,通过神经网络内部latent(隐藏层)进行过滤,提取特征,(latent通常神经元数量少于ED),然后由Decoder层进行重建数据,最终输出数据。
(4)重建图像和原始图像之间的误差由损失函数实现。
VAE编码不再把输入映射到固定变量上,而是映射到分布上,例如混合高斯(GMM)
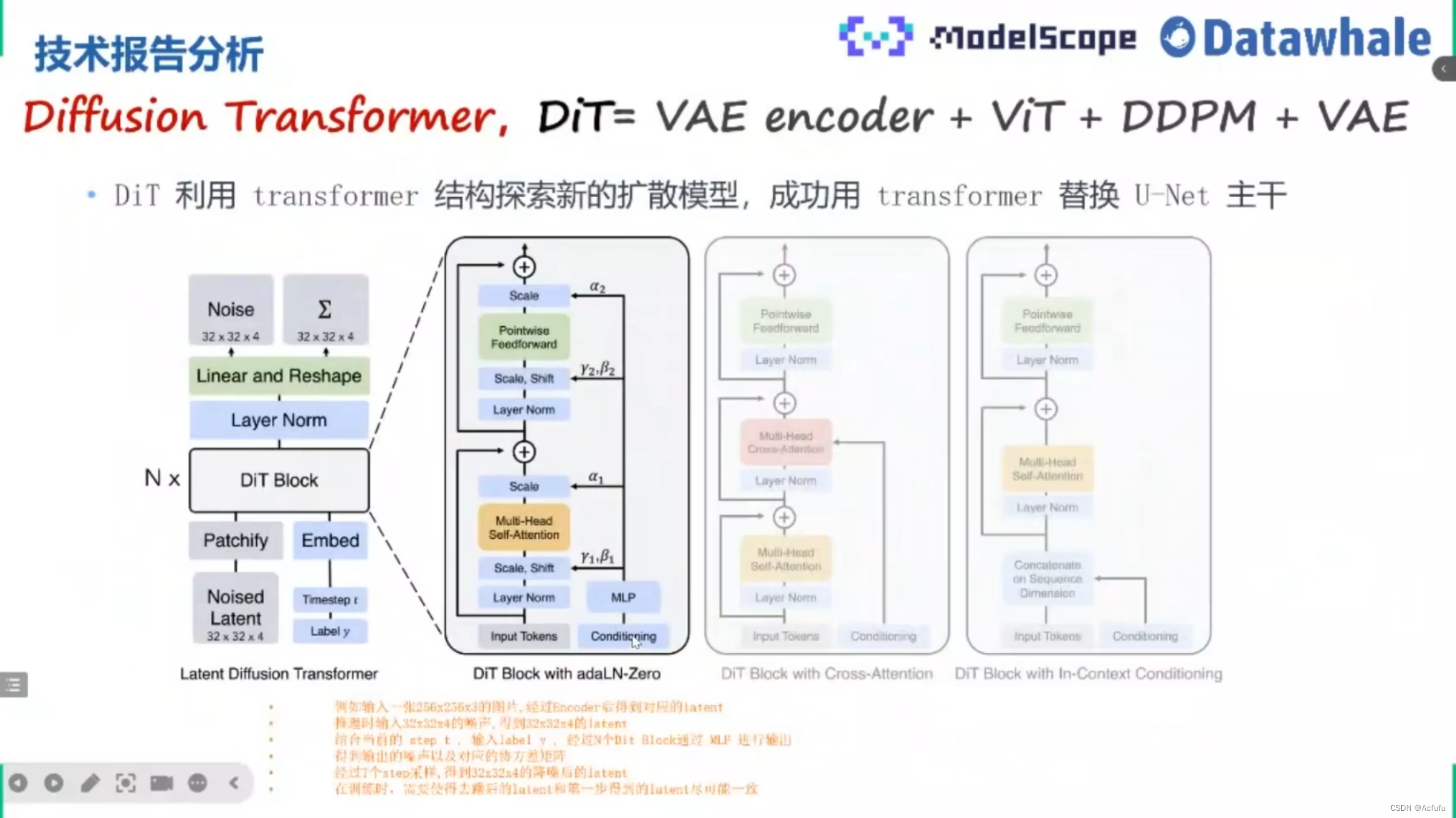
2.Diffusion(扩散模型)
1.目前市面上文生图工具基本应用此模型,已有比较惊艳的成绩。
(1)原理简单理解为,在模型训练过程中,在图像上增加噪音,直到整张图片被噪音覆盖,再通过去噪来重建图像。
(2)扩散模型比VAE打乱的更彻底。
(3)数学概率公式推导学习中,推导过程较为复杂。
个人的思考与总结
暂时先写着这样打个卡先,等周末有空再完善笔记QAQ
















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











