






本文是datawhale part3实践打卡
sora的优势
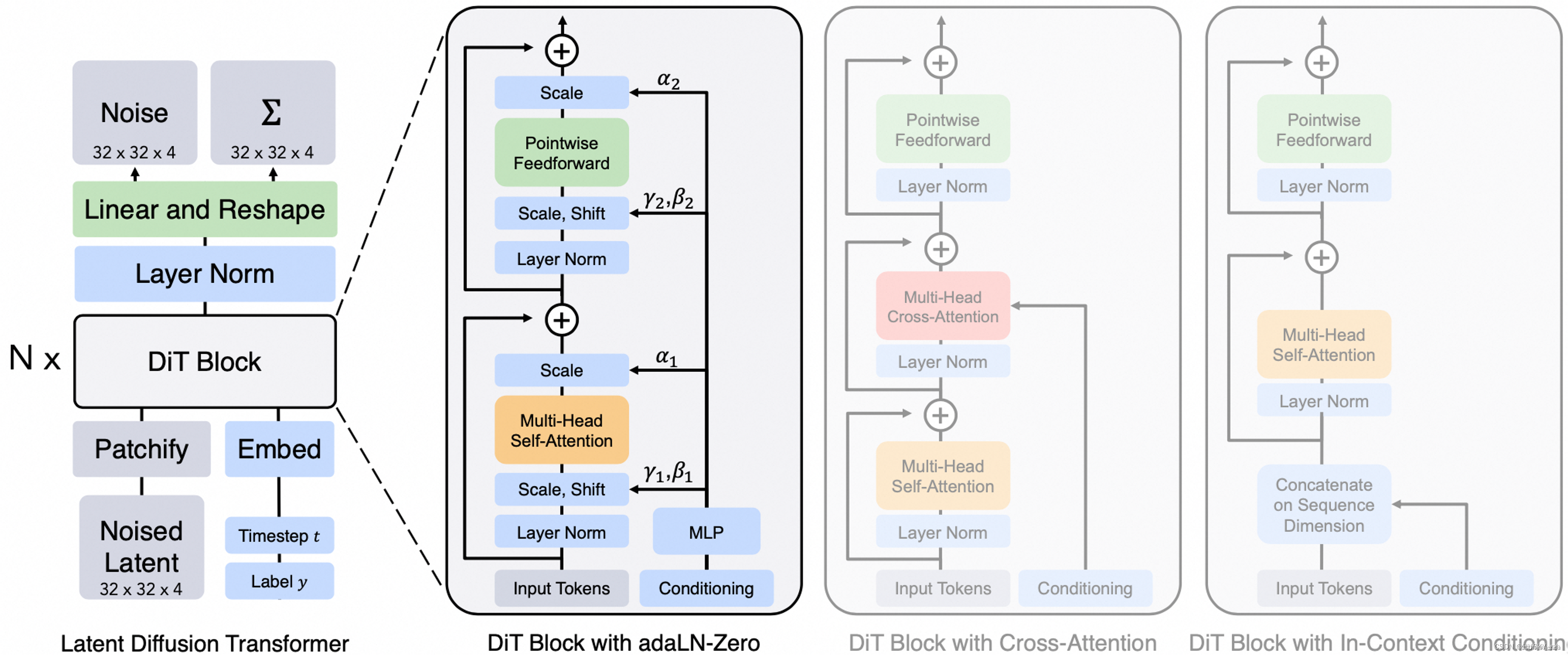
Sora模型的一大特点就是使用Transformer模型替换了Diffusion的U-net架构,从ChatGPT到Sora,OpenAi也一再的验证了Transformer大力出奇迹的能力在拥有更多数据,算力的情况下这条路,Transformer这条路是可行的结论,其他厂商可以卯足了劲,向前冲就可以。
基于Transformers的扩散(diffusion)模型
结合了Transformers架构和扩散模型的优点,这类模型利用Transformers强大的序列建模能力来改进扩散模型的生成过程。Transformers能够处理长距离依赖问题,使得基于Transformers的扩散模型在理解和生成复杂数据方面更为有效。这种模型特别适合于处理大规模数据集,并且能生成高质量的图像、文本等数据。
视频生成大致流程
- 先使用ChatGPT,写分镜剧本。
- 在使用SD,MJ等软件画图。
- 最后利用SVD,Pika,Runway登软件生成视频。
实践生成
使用魔塔社区案例,具体请参考:
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
import cv2
pipe = pipeline(task=Tasks.text_to_image_synthesis,
model='AI-ModelScope/stable-diffusion-xl-base-1.0',
use_safetensors=True,
model_revision='v1.0.0')
prompt = "Beautiful and cute girl, 16 years old, denim jacket, gradient background, soft colors, soft lighting, cinematic edge lighting, light and dark contrast, anime, art station Seraflur, blind box, super detail, 8k"
output = pipe({'text': prompt})
cv2.imwrite('SDXL.png', output['output_imgs'][0])
这段代码演示了如何使用ModelScope库来执行文本到图像合成任务,具体是利用Stable Diffusion XL模型根据给定的文本描述生成图像,并使用OpenCV将生成的图像保存到文件。
从modelscope.utils.constant导入Tasks,从modelscope.pipelines导入pipeline函数,该函数用于创建和配置特定任务的处理管道。导入cv2,即OpenCV库,用于图像处理和保存功能。
使用pipeline函数初始化一个管道,指定任务类型为Tasks.text_to_image_synthesis,表明这是一个文本到图像的合成任务。
指定模型为'AI-ModelScope/stable-diffusion-xl-base-1.0',这是ModelScope平台上的一个预训练模型,基于Stable Diffusion技术。use_safetensors=True是指在处理数据时使用安全的张量操作,model_revision='v1.0.0'指定了模型的版本。
创建一个字符串prompt,包含用于生成图像的详细文本描述。这里描述了一个场景,包含年龄、服装、背景、颜色、光照条件等多个维度。
调用初始化好的管道pipe,并传入一个字典,其中'text'键对应于之前定义的文本提示prompt。管道处理该输入并返回生成的图像。
用cv2.imwrite函数,将生成的图像保存到文件'SDXL.png'。output['output_imgs'][0]从输出中取出第一张生成的图像
引用
【AI+X组队学习】Sora原理与技术实战:文生图片技术路径、原理与SD实战_哔哩哔哩_bilibili
https://stablediffusionweb.com/
https://en.wikipedia.org/wiki/Variational_autoencoder
















 1701
1701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











