






数据中心网络技术概览
一、数据中心网络架构
-
Crossbar架构:源自早期电话交换网络,由多个输入/输出端口和开关矩阵组成,实现设备间的任意连接,灵活且高效。
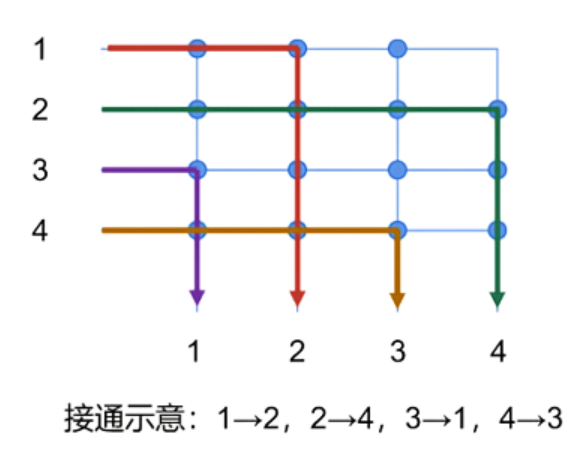
**Crossbar架构(Crossbar Architecture)是一种计算机内存结构,用于连接处理器、存储器和其他组件。**在Crossbar架构中,所有的组件都通过一个交叉点矩阵(crossbar switch)相互连接。这种结构允许任何处理器同时访问任何存储器位置或其他资源,而不会互相干扰,从而提高了系统的并行性和性能。
Crossbar架构常见于高性能计算系统和一些专用硬件中,例如网络交换机和路由器。它也被用于某些类型的非易失性存储器技术,例如阻变随机存取存储器(ReRAM)和相变存储器(PCM)中的交叉点阵列。
在交叉点矩阵(crossbar switch)中,设置一个输入端口连接到多个输出端口通常涉及以下几种方法:
- 软件配置:在一些系统中,可以通过软件来配置交叉点矩阵的连接状态。这种情况下,你可以使用专用的软件工具或命令行接口来指定哪些输入端口应该连接到哪些输出端口。
- 硬件控制:在一些硬件设备中,例如网络交换机或路由器,交叉点矩阵的配置可能通过硬件控制信号来实现。这可能涉及到设置特定的寄存器值或使用硬件控制线路来指定连接状态。
- 编程接口:在一些支持可编程逻辑的系统中,如FPGA(现场可编程门阵列)或某些类型的专用集成电路(ASIC),你可以使用硬件描述语言(如VHDL或Verilog)来编写代码,以实现特定的连接逻辑。
- 微控制器或处理器:在一些小型系统或嵌入式设备中,可以使用微控制器或处理器来控制交叉点矩阵的连接状态,通常通过编写控制代码来实现。
-
Clos架构:1952年由Charles Clos提出,描述多级电路交换网络结构,是对Crossbar的改进,提供无阻塞网络,降低成本并提高效率。
Clos架构是一种多级交换网络结构,由法国数学家Charles Clos在1953年提出。它被设计用来提供高度可扩展和非阻塞的交换能力,适用于大型电话交换系统和数据中心网络。Clos架构通过将交换机组织成多个级别来实现这一点,通常分为三级:入口级别、中间级别和出口级别。
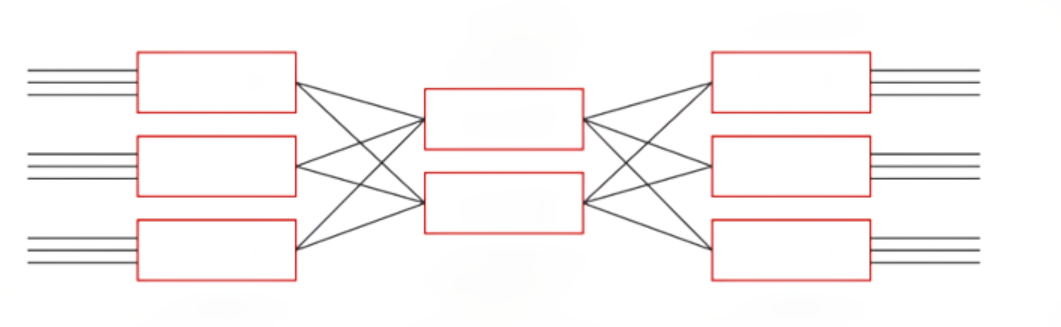
主要特点:
- 非阻塞性:在理想情况下,Clos架构可以实现非阻塞通信,即任何一对入口和出口都可以在不干扰其他通信的情况下建立连接。
- 可扩展性:通过增加中间级别交换机的数量,可以轻松扩展系统以支持更多的入口和出口,使其适用于大型网络。
- 冗余:Clos架构天然支持冗余,提高了系统的可靠性和容错能力。
结构组成:
- 入口级别(Ingress stage):包含多个入口交换机,负责将外部输入连接到中间级别交换机。
- 中间级别(Middle stage):包含多个中间交换机,负责在入口级别和出口级别之间路由数据。
- 出口级别(Egress stage):包含多个出口交换机,负责将来自中间级别的数据路由到最终目的地。
-
胖树(Fat-Tree)架构:一种CLOS网络架构,类似于真实树结构,从叶子到树根,网络带宽不收敛。使用大量低性能交换机构建大规模无阻塞网络。
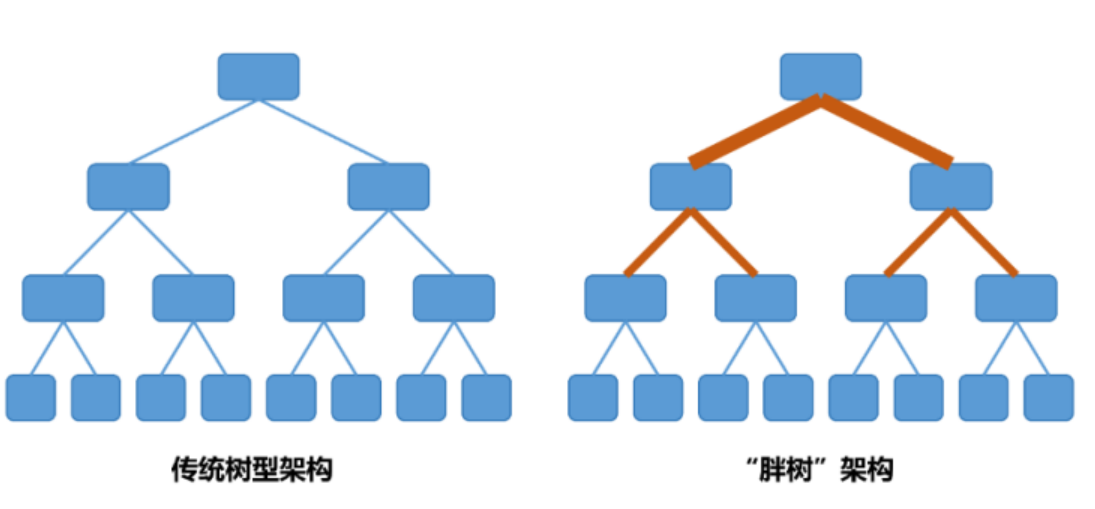
**胖树(Fat-Tree)架构是一种常用于大型网络和数据中心的层次化网络拓扑结构。**它是一种特殊类型的树形结构,其中网络的带宽随着接近根节点而增加,因此被称为“胖树”。这种设计使得网络的核心部分拥有更高的带宽,以支持大量的数据传输和避免瓶颈。
胖树架构通常用于构建高性能计算(HPC)集群、数据中心和其他需要高带宽、低延迟的网络环境。它能够提供良好的扩展性和容错能力,因为它允许多条路径从任意源节点到达任意目的节点,从而增加了网络的冗余性和鲁棒性。
**在胖树架构中,叶节点(leaf nodes)通常是网络中的终端设备,如服务器或存储设备。**随着向上移动到树的更高层次,交换机的端口数量和带宽会增加,这就是为什么它们被称为“胖”的原因。这种设计确保了数据在网络中向上或向下流动时,可用的带宽始终足够,从而减少了拥塞和提高了性能。
胖树(Fat-Tree)架构和传统树形架构(也称为细树或标准树形架构)的主要区别在于它们对网络带宽的分配方式不同:
- 带宽分配:
- 在胖树架构中,随着接近树的根节点,网络的带宽逐渐增加。这意味着位于树顶层的交换机拥有更多的端口和更高的带宽,以支持从多个下层节点汇聚而来的流量。因此,胖树可以有效地减少网络瓶颈,提高数据传输效率。
- 在传统树形架构中,所有层级的交换机通常具有相同数量的端口和相同的带宽。这种设计在流量密集时容易在树的上层出现瓶颈,因为上层交换机需要处理来自多个下层节点的聚合流量,但带宽没有相应增加。
- 扩展性和容错能力:
- 胖树架构由于其带宽随层级增加的特性,提供了更好的扩展性和容错能力。它允许网络在保持性能的同时增加更多的节点,并且可以通过多条路径在节点间进行通信,从而增强了网络的鲁棒性。
- 传统树形架构在扩展时可能会遇到性能瓶颈,并且在某些路径出现故障时可能无法提供足够的备用路径,导致网络的容错能力较弱。
- 数据中心的传统三层结构
数据中心的传统三层结构指的是一种常见的网络架构,它将数据中心网络分为三个逻辑层级:接入层(Access Layer)、汇聚层(Aggregation Layer)或称之为分布层(Distribution Layer),以及核心层(Core Layer)。每一层都有其特定的功能和责任,共同确保数据中心网络的高效运行和可靠性。:
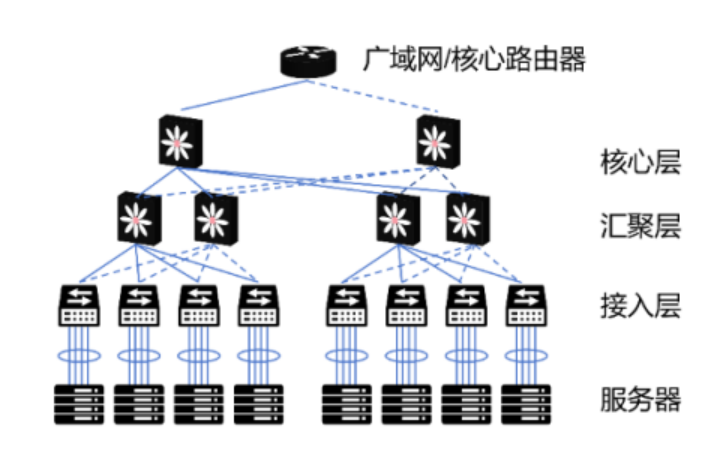
- 接入层(Access Layer):
- **这是数据中心网络的最底层,主要负责将服务器和存储设备连接到网络中。**接入层交换机通常提供较低的带宽和端口密度,因为它们直接连接到终端设备。接入层的主要职责包括端口安全、VLAN 分段和负载均衡。
- 汇聚层(Aggregation Layer)或分布层(Distribution Layer):
- **汇聚层位于接入层和核心层之间,主要负责汇总来自多个接入层交换机的流量,并提供向核心层的路由。**汇聚层交换机通常具有较高的带宽和处理能力,以支持来自下层的聚合流量。此外,汇聚层还可能负责提供一些高级服务,如防火墙、负载均衡和访问控制列表(ACL)。
- 核心层(Core Layer):
- **核心层是数据中心网络的最顶层,负责提供高速的数据传输和连接到外部网络(如互联网或其他数据中心)。**核心层交换机需要具有非常高的带宽和处理能力,以支持整个数据中心的流量。核心层的主要职责包括确保网络的高可用性、可靠性和可扩展性。
- 带宽分配:
-
叶脊(Spine-Leaf)网络:叶交换机相当于接入交换机,直接连接物理服务器。带宽利用率高,网络延迟可预测,故障影响小。
叶脊(Spine-Leaf)网络是一种现代数据中心网络架构,它采用两层拓扑结构,以提供更高的带宽、更低的延迟和更好的可扩展性。叶脊架构由两种类型的交换机组成:叶节点(Leaf Nodes)和脊节点(Spine Nodes)。

- 叶节点(Leaf Nodes):
- 叶节点交换机位于网络的边缘,负责将服务器、存储设备和其他终端设备连接到网络中。在叶脊架构中,所有的叶节点都直接连接到所有的脊节点,但叶节点之间通常不直接连接。叶节点主要负责本地数据交换、访问控制和负载均衡。
- 脊节点(Spine Nodes):
- 脊节点交换机位于网络的核心,负责连接所有的叶节点,并提供高速数据传输的路径。脊节点之间通常不直接连接,它们的主要作用是在叶节点之间转发流量。脊节点需要具有高带宽和处理能力,以支持大量并发的数据流。
叶脊架构的主要优点包括:
- 高可扩展性:通过简单地添加更多的叶节点或脊节点,可以轻松扩展网络以适应增长的需求。
- 低延迟:由于叶节点直接连接到脊节点,数据在节点之间的传输路径很短,从而减少了延迟。
- 负载均衡:多条路径可用于在叶节点和脊节点之间传输数据,有助于实现流量的负载均衡和避免拥塞。
- 容错能力:故障隔离更容易实现,因为叶节点和脊节点之间存在多条路径,一条路径的故障不会影响整个网络。
- 叶节点(Leaf Nodes):
- 叶脊网络架构与传统三层网络架构的区别
叶脊(Spine-Leaf)网络架构与传统三层网络架构(接入层、汇聚层、核心层)在设计理念和目标上有一定的区别,同时也存在一些关联性:
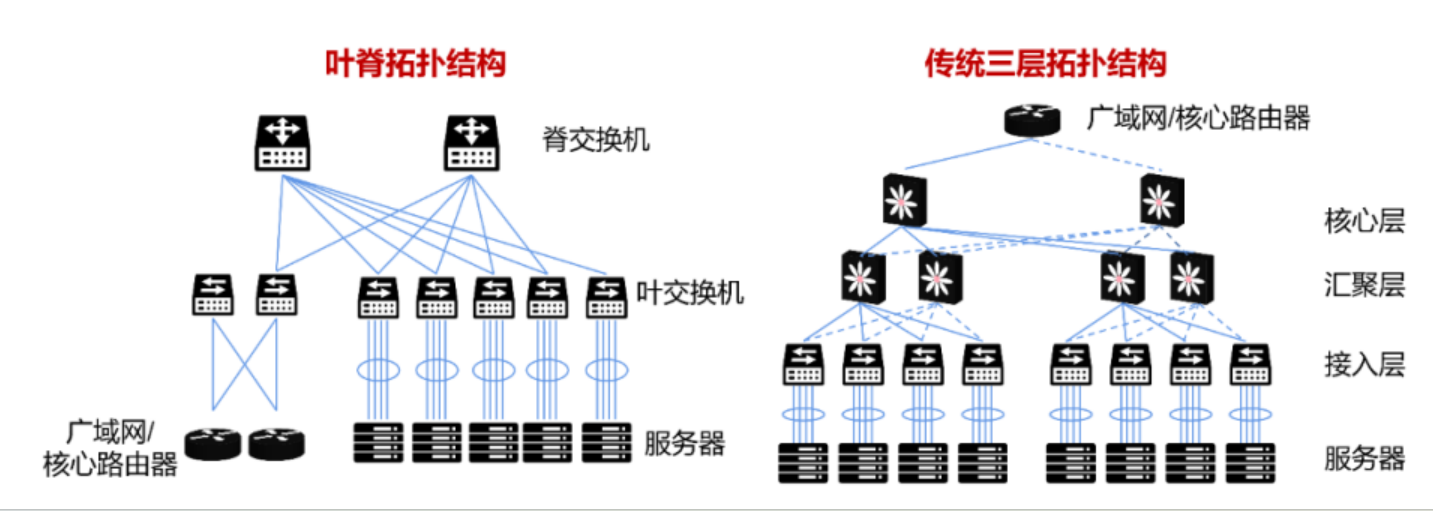
- 设计理念的差异:
- 传统三层网络架构:这种架构通过将网络划分为接入层、汇聚层和核心层来管理网络流量和提供服务。它主要适用于传统的分层网络设计,其中每一层都有明确的职责,但可能存在性能瓶颈,特别是在汇聚层和核心层。
- 叶脊网络架构:这种架构采用两层拓扑结构,包括叶节点(负责连接终端设备)和脊节点(负责高速数据传输)。它旨在提供更高的带宽、更低的延迟和更好的可扩展性,适用于现代数据中心和云环境。
- 目标的关联性:
- 尽管两种架构在设计上有所不同,但它们的目标都是为了提高网络的性能、可靠性和可扩展性。叶脊架构可以被视为传统三层架构的一种演进,它解决了三层架构在大规模数据中心环境中可能遇到的一些限制和挑战。
- 适用场景的变化:
- 随着数据中心规模的增长和云计算技术的发展,传统三层网络架构可能难以满足日益增长的带宽需求和对低延迟的要求。叶脊架构因其更好的可扩展性和性能而成为现代数据中心网络设计的首选。
- 为何不一开始就传统三层结构就设计成叶脊网络架构?
传统三层网络架构(接入层、汇聚层、核心层)和叶脊(Spine-Leaf)二层网络架构的设计差异主要是由于它们所面临的技术挑战、性能需求和应用场景在不同时间点上的变化。以下是一些原因:
- 技术限制:当传统三层网络架构最初被设计时,网络设备的性能和带宽有限,处理能力和存储容量也相对较低。三层架构通过分层来简化网络设计,减少了单个设备的负载,使得网络更易于管理和维护。
- 网络规模和复杂性:早期的数据中心和企业网络规模相对较小,流量模式主要是北-南流量(即从终端用户到数据中心的流量和反向流量)。传统三层架构能够有效地处理这种流量模式,并提供足够的性能和可靠性。
- 成本考虑:在过去,网络设备成本较高,特别是具有高带宽和高处理能力的设备。三层架构允许使用较便宜的设备在接入层和汇聚层,而只在核心层使用高性能的设备,从而降低了整体网络成本。
- 技术进步和需求变化:随着时间的推移,网络设备的性能大幅提升,数据中心规模不断扩大,应用对带宽和延迟的要求也越来越高。同时,东-西流量(即数据中心内部服务器之间的流量)的增加使得传统三层架构的性能瓶颈和延迟问题变得更加明显。这些变化促使了叶脊架构的出现,它通过二层扁平化设计,提供了更高的带宽、更低的延迟和更好的可扩展性,以满足现代数据中心的需求。
- 优缺点比较
| 特征 | 传统三层网络架构 | 叶脊网络架构 | 胖树架构 |
|---|---|---|---|
| 架构层级 | 三层(接入层、汇聚层、核心层) | 二层(叶层、脊层) | 多层(叶节点、中间节点、根节点) |
| 设计原则 | 分层管理 | 扁平化网络 | 多路径、分层 |
| 带宽分配 | 每层固定带宽 | 叶节点和脊节点通常具有固定带宽 | 带宽随着接近根节点而增加 |
| 延迟 | 相对较高 | 相对较低 | 低于传统三层,高于叶脊 |
| 可扩展性 | 有限 | 高 | 高 |
| 故障恢复 | 较慢 | 快 | 快 |
| 负载均衡 | 有限 | 支持多路径负载均衡 | 支持多路径负载均衡 |
| 适用场景 | 小型至中型网络、传统企业网络 | 大型数据中心、云计算环境 | 大型数据中心、高性能计算环境 |
| 优点 | 简单、成熟、易于管理 | 高可扩展性、低延迟、快速故障恢复 | 高可扩展性、多路径负载均衡、容错能力强 |
| 缺点 | 可扩展性有限、可能出现性能瓶颈 | 设备成本可能较高、需要高性能交换机 | 结构相对复杂、成本较高 |
二、InfiniBand技术
-
诞生背景:
InfiniBand 是一种高性能的计算机网络通信标准,主要用于高性能计算(HPC)和企业数据中心。它支持非常高的数据传输速率和低延迟,使其成为连接服务器、存储系统和其他设备的理想选择,特别是在需要大量数据交换的环境中。
InfiniBand 的主要特点包括:
- 高带宽:InfiniBand 提供的带宽远高于传统的以太网,可达数百 Gbps,适合大规模数据传输。
- 低延迟:InfiniBand 采用了专用的交换芯片和网络协议,大大减少了数据传输的延迟,适合延迟敏感的应用。
- 可扩展性:InfiniBand 支持大规模网络的构建,可以连接成千上万的节点,适合大型计算集群和数据中心。
- 远程直接内存访问(RDMA):InfiniBand 支持 RDMA,允许服务器之间直接交换数据而无需通过操作系统,进一步降低延迟并减轻 CPU 负担。
- 质量服务(QoS):InfiniBand 支持多种质量服务等级,确保关键任务的数据传输优先级。
-
组网架构:基于通道的结构,包括HCA、TCA、InfiniBand交换机和路由器等组件。
- 主机通道适配器(HCA):HCA 是安装在服务器或计算节点上的网络接口卡(NIC),负责处理与 InfiniBand 网络的连接和通信。每个 HCA 有一个或多个端口,可以连接到 InfiniBand 交换机或其他节点。
- 交换机(Switch):InfiniBand 交换机是网络中的中心设备,负责连接多个 HCA 和其他交换机。它们可以提供高带宽和低延迟的数据交换,并支持大规模网络的构建。
- 子网管理器(Subnet Manager, SM):子网管理器是一个软件或硬件组件,负责配置和管理 InfiniBand 网络中的所有设备,包括地址分配、路由和链路聚合等。子网管理器可以运行在专用的管理设备上,也可以集成在交换机或其他设备中。
- 链路和路由:InfiniBand 支持多种链路聚合和路由策略,以提高网络的带宽和可靠性。链路聚合允许多条物理链路合并为一条逻辑链路,而路由策略确定数据在网络中的传输路径。
- 组件之间通信
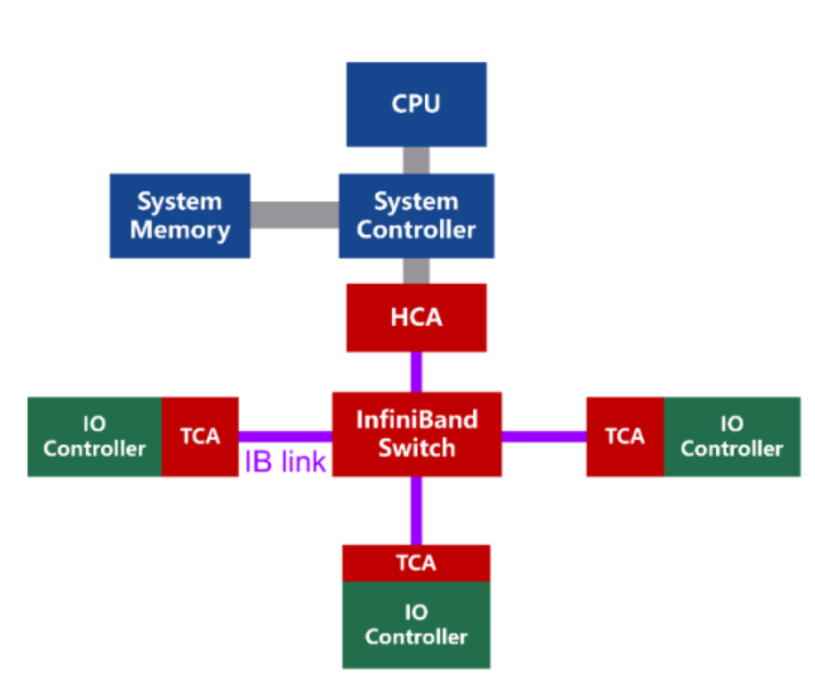
InfiniBand 网络中的组件(如主机通道适配器(HCA)、交换机、存储设备等)通过以下方式互相通信:
- 物理连接:InfiniBand 设备之间通过物理电缆(通常是光纤或铜缆)连接。每个设备上的 HCA 通过端口与 InfiniBand 交换机或其他设备的端口相连。
- 初始化和配置:当 InfiniBand 网络启动时,子网管理器(Subnet Manager, SM)会发现网络中的所有设备,分配地址,并配置路径和其他参数。这个过程称为子网初始化,确保了网络中的每个设备都可以被正确地识别和配置。
- 数据传输:
- InfiniBand 支持远程直接内存访问(RDMA),允许一台主机直接读写另一台主机的内存,而无需操作系统的介入。这种方式可以显著降低延迟和 CPU 负担。
- 数据传输还可以通过传统的消息传递方式进行,其中数据在发送方和接收方的操作系统之间进行复制。
- 交换机路由:InfiniBand 交换机根据子网管理器配置的路由表来转发数据包。当一个数据包到达交换机时,交换机根据目的地址查找路由表,确定下一跳的端口,并将数据包转发到相应的端口。
- 流控制和拥塞管理:InfiniBand 网络使用流控制机制来确保数据传输的可靠性,防止数据丢失。当网络出现拥塞时,拥塞管理机制会调整数据流量,减少拥塞情况。
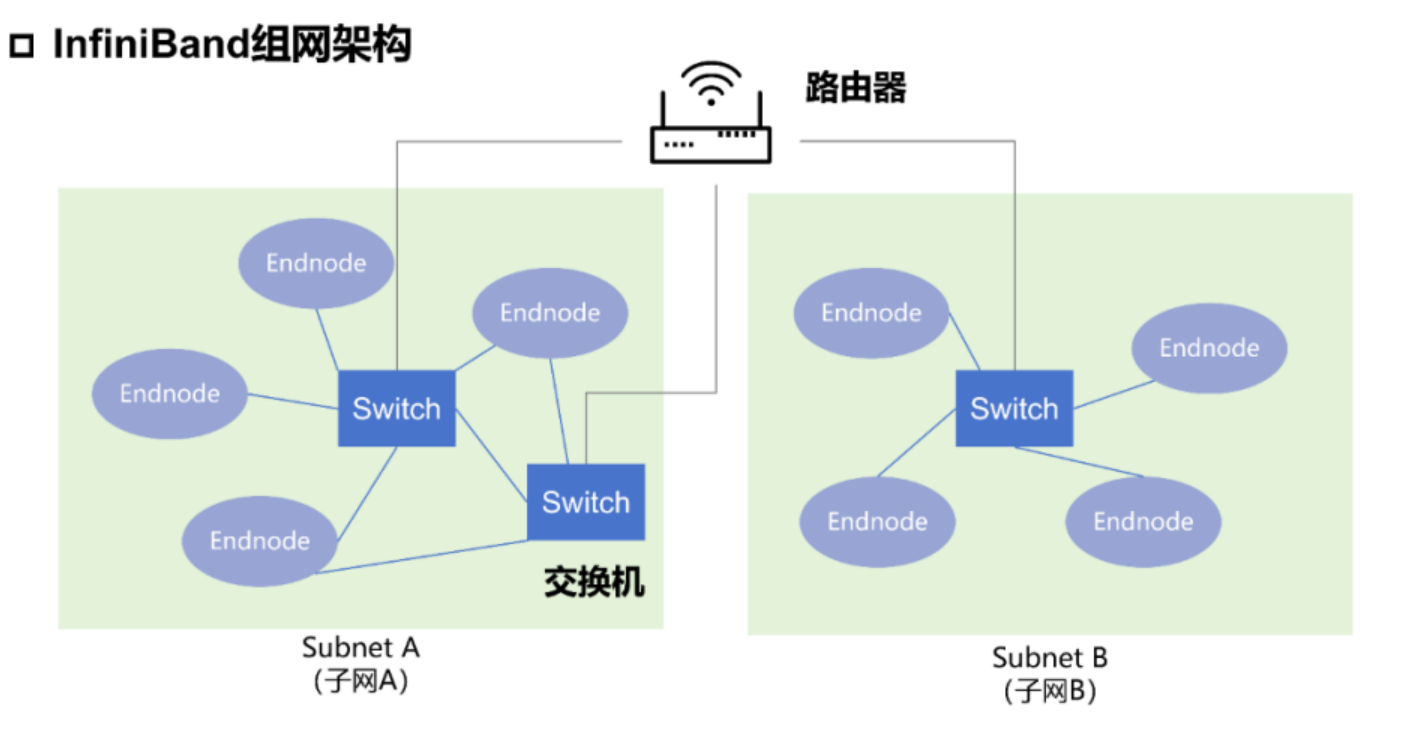
这张图展示了一种典型的InfiniBand网络拓扑结构,包含了两个子网:Subnet A(子网A)和Subnet B(子网B)。下面详细介绍图中的各个部分:
- Endnode(端节点):这些通常是服务器或存储设备,它们包含有主机通道适配器(HCA),使得这些设备能够连接到InfiniBand网络。
- Switch(交换机):这些设备负责在网络中转发来自端节点的数据。每个子网中的交换机都会将其下的端节点连接在一起,并可能与其他交换机连接以便于不同子网之间的通信。
- 连接线:图中的实线表示端节点和交换机之间的物理连接。在InfiniBand中,这些连接能够提供高速的数据传输。
- 无线信号图标:代表与外部网络的连接,可能是通过路由器或网关实现的。这样的连接允许InfiniBand网络与外部的其他网络通信,如以太网或其他类型的网络。
- 实线框:表示子网的边界。在InfiniBand网络中,一个子网是由一个子网管理器进行管理的一个逻辑分区。每个子网可以独立地管理其地址、路由和其他配置。
在实际的应用中,两个子网可能连接到同一个物理InfiniBand交换机,也可能通过路由器或网关连接到外部网络。InfiniBand的子网管理器(SM)负责管理这些子网的配置和路由表。高可用性可以通过在每个子网中配置多个路径和冗余的子网管理器来实现。如果一个子网内的路径发生故障,数据可以通过其他路径进行路由,保证通信的连续性和网络的稳定性。
- 网络层次
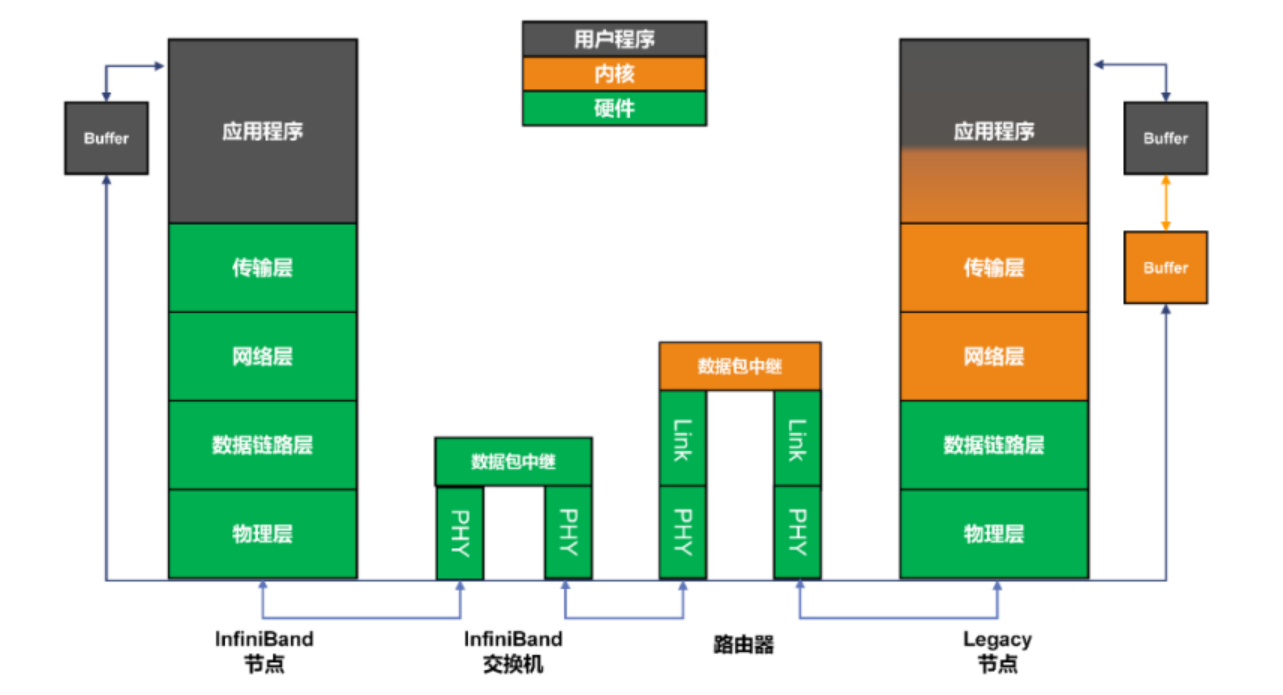
这张图展示的是 InfiniBand 技术的协议栈和它如何与传统网络协议栈进行比较。在我们的讨论中,我们将从下至上概述每一层的功能,并解释 InfiniBand 如何提供高效和高性能的网络解决方案。
**在底层,我们有物理层(PHY),它负责将数据编码成电信号,通过物理媒介进行传输。**在 InfiniBand 技术中,这一层是高度优化的,以支持高带宽和低延迟。
**上一层是链路层,它包括两部分:数据链路层和网络层。**数据链路层负责点对点的数据传输,确保数据的完整性和可靠性。网络层则负责路由和数据分组的交付,这是 InfiniBand 架构中实现高效数据传输的关键。
**数据链路层在 InfiniBand 协议栈中处于物理层之上,它负责在两个直接相连的节点之间实现可靠的数据传输。**具体来说,在 InfiniBand 网络中,数据链路层主要负责以下几个方面:
- 帧传输:数据链路层将来自上层的数据包封装成帧,每个帧包含数据以及必要的头部信息,如源和目的地地址。
- 流控制:确保数据不会过快地发送到无法及时处理这些数据的节点,从而避免数据溢出和丢失。
- 差错控制:数据链路层会检测和可能纠正在物理层传输过程中可能出现的错误。这通常通过校验和或循环冗余检查(CRC)等机制来实现。
- 帧同步:数据链路层通过添加起始和终止标识符,确保接收节点能够准确识别帧的边界。
- 介质访问控制(MAC):虽然在 InfiniBand 网络中,交换机负责路径选择,而不需要传统意义上的MAC地址解析协议(如ARP),但是数据链路层仍然涉及处理帧的发送和接收,确保它们能够在物理层正确地被发送和识别。
- 可靠性传输:尽管物理层可能非常可靠,数据链路层还是提供了确认和重传机制,确保数据正确无误地到达目的地。
在 InfiniBand 中,数据链路层的实现是高度优化的,以提供极高的数据传输速率和极低的帧丢失率。这一层也负责维护和管理路径,使得数据可以在不同节点之间高效地传输。此外,数据链路层还提供了一定级别的安全性,例如通过帧加密和身份验证来确保数据的安全性。
**网络层在 InfiniBand 架构中起着至关重要的角色,它负责在源和目的地之间路由和传输数据包。**在 InfiniBand 的上下文中,网络层确保数据通过最有效的路径从一个节点传输到另一个节点,同时支持各种服务质量(QoS)和管理功能。
这个层级通常处理以下关键任务:
- 寻址:为网络中的每个设备分配唯一的地址,以便于数据包的正确路由。
- 路由决策:确定数据包在网络中的路径。在 InfiniBand 网络中,路由决策可以基于静态路由或动态路由算法来实现。
- 错误检测和恢复:网络层包含了错误检测机制,以识别并可能纠正在数据传输过程中发生的错误。
- 拥塞控制:监控网络中的流量,避免过度拥塞,确保数据流畅传输。
- 分段和重组:在源端将大块数据分割成更小的数据包进行传输,并在目的端对其进行重新组装。
- 服务质量(QoS):管理不同类型的流量,并根据预设的策略给予不同的优先级,保证关键应用的性能。
**接下来是传输层,这一层特有于 InfiniBand,提供了端到端的通信服务。**这是通过远程直接内存访问(RDMA)实现的,它允许在不同节点之间直接传输数据,大大减少了传统网络协议栈中所需的中间复制和上下文切换。
**在InfiniBand架构中,传输层位于数据链路层之上,它负责管理端到端的通信连接,确保数据可靠地从一个节点传输到另一个节点。**InfiniBand的传输层特别设计来支持高吞吐量和低延迟的通信,这是高性能计算(HPC)和数据中心环境所需的。
传输层的主要职责包括:
- 端到端连接:传输层建立并维护端到端的连接。在InfiniBand中,这通常涉及到队列对,其中包括发送队列和接收队列。
- 段分割和重组:大数据块将被分割成小的段进行传输,并在接收端重新组装成原始数据块。
- 流控制:控制数据流以防止接收端被发送端的数据淹没。
- 可靠传输:通过序列号和确认机制,确保所有分段的数据都能够正确无误地到达,并且丢失的数据能够被重传。
- 拥塞避免:监测网络条件并相应地调整数据流,以避免可能导致性能下降的网络拥塞。
- 远程直接内存访问(RDMA):InfiniBand的传输层支持RDMA操作,允许一个节点直接读取或写入另一个节点的内存,无需中间拷贝或CPU介入,极大提高了数据传输的效率。
- 传输服务:提供不同类型的传输服务,包括可靠的连接(RC)、可靠的数据报(RD)、无连接的数据报(UD)和其他服务。
- 消息传递:支持面向消息的通信模型,允许应用程序发送和接收消息,而无需担心底层的数据传输细节。
**最后,我们有应用层,这是用户与网络交互的层面。**在 InfiniBand 中,这层直接受益于下层提供的高速、低延迟服务,使得高性能计算和数据中心的应用能够高效地运行。
在讨论 InfiniBand 与传统网络协议的比较时,我们可以看到,在每一层,InfiniBand 都是为了性能而设计的。从物理层到应用层,每一步都进行了优化,以确保数据传输尽可能地快速和可靠。这种专注于性能的设计方法使得 InfiniBand 成为高性能计算和企业级数据中心网络的理想选择。
- 子网管理器在网络层么?
**子网管理器(Subnet Manager, SM)不是网络层的一部分,而是 InfiniBand 网络中的一个独立的管理实体,它负责维护整个 InfiniBand 子网的正常运行。**子网管理器位于 InfiniBand 架构的管理层,高于网络层和其他通信层,可以视为位于 OSI 模型的应用层。
子网管理器的作用和功能包括:
- 初始化网络:当 InfiniBand 网络设备启动时,子网管理器负责初始化和配置网络,包括激活链接、配置端口等。
- 寻址和路由:子网管理器负责为网络内的所有组件分配唯一的地址,并计算最佳的路由表,以便数据包在设备之间有效地传输。
- 监控和诊断:子网管理器会监控网络状态,包括链路的健康状况和性能参数,并能够执行诊断以识别问题所在。
- 拓扑发现:子网管理器会发现网络中的所有设备及其连接方式,建立整个 InfiniBand 子网的拓扑结构。
- 管理更改:当网络中添加或移除设备时,子网管理器会更新网络配置,以反映这些更改。
- 维持高可用性:在有多个子网管理器的情况下,一个子网管理器可以作为主要管理器,而其他的可以作为备份。如果主子网管理器宕机,一个备份可以接管,确保网络的持续运行。
- InfiniBand报文架构
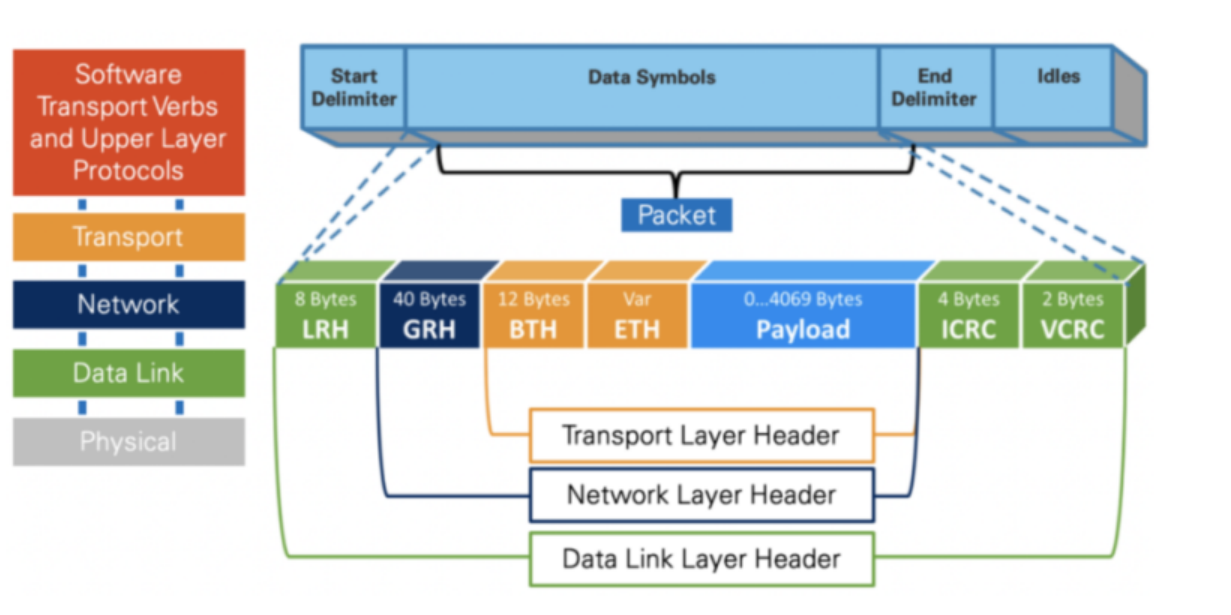
这张图描绘了InfiniBand架构中的协议栈和一个典型InfiniBand帧的结构。从下到上,协议栈包括物理层、数据链路层、网络层和传输层,每层都有自己的功能和负责的特定任务。
具体到帧结构,从左到右依次描述了一个完整帧的各个部分:
- 物理层:是协议栈的最底层,负责传输原始的比特流。
- 数据链路层:在图中展示为帧中的“Data Link Layer Header”,它可能包含控制信息,如帧同步和帧定界符。
- LRH(Local Route Header):含有局部连接的路由信息。
- ICRC(Invariant Cyclic Redundancy Check):用于错误检测和纠正,以确保数据在传输过程中的完整性。
- VCRC(Variant Cyclic Redundancy Check):为传输层提供另一层错误检测。
- 网络层:这一层的头部在帧中称为“Network Layer Header”,它负责路由和分包的任务。
- GRH(Global Route Header):当跨子网通信时含有全局路由信息。
- 传输层:这是协议栈中的“Transport Layer Header”,负责端到端的数据传输,包括流量控制、拥塞控制和数据的分段与重组。
- BTH(Base Transport Header):包含传输层的核心控制信息。
- ETH (Ethernet Header):以太网头部包含源地址和目的地址、以及用于定义帧内数据类型或长度的以太网类型字段(2个字节)。
- Payload:这是用户数据的主体部分,可以达到4069字节。
- 起始和结束定界符:表示帧的开始和结束。
- 软件层:图的最顶部提到了软件传输动作和上层协议,这涉及到应用程序级别的数据封装和处理。
在帧的两端,你会看到“Start Delimiter”和“End Delimiter”,以及在传输帧之间可能出现的“Idles”状态,这些是用来保持物理介质同步的控制字符。
- 传输机制
- 主机和目标通信过程
在InfiniBand网络中,主机和目标建立连接的过程主要涉及配置和初始化队列对(Queue Pairs,QPs)以及相关的资源。下面是一个概括的步骤:
- 资源分配:
- 主机操作系统的网络子系统会为即将建立的连接分配必要的资源,包括创建队列对(QPs)。每个QP由两个工作队列组成:发送队列(SQ)和接收队列(RQ)。
- 配置QP:
- 每个QP都需要被配置以适应预期的通信模式。这包括设置QP状态、定义QP编号以及配置相关的参数,例如最大传输单元(MTU)和超时值。
- 交换信息:
- 主机和目标之间需要交换所需的连接信息,如QPs的编号、LID(本地标识符)、GID(全局标识符)和路径信息。这个信息交换可以通过外部的管理软件或应用程序级别的交换来完成。
- 激活QP:
- 一旦相关的QP配置信息被双方获取并设置,QP可以被转移到激活状态。在此状态下,QP能够开始处理工作请求。
- 同步和握手:
- 主机和目标将执行一个同步或握手过程,确保双方都准备好接收和发送数据。这通常涉及到使用特殊的控制消息来确认双方的准备状态。
- 数据传输:
- 完成上述步骤后,主机和目标之间的连接就建立起来了。应用程序可以开始提交工作请求(Work Requests,WRs)到QP的工作队列。这些请求将被网络适配器取出并执行,如将数据包发送到远程节点或从远程节点接收数据包。
- 完成通知:
- 一旦数据传输完成,完成队列元素(Completion Queue Element,CQE)会被生成,并可选择性地通知应用程序传输已完成。
这个过程涉及到InfiniBand子网管理器(Subnet Manager),它在网络上管理地址分配、路由和其他配置任务。子网管理器通过子网管理员协议(Subnet Administration Protocol,也称为SM)进行操作,该协议处理节点之间的连接和配置信息。
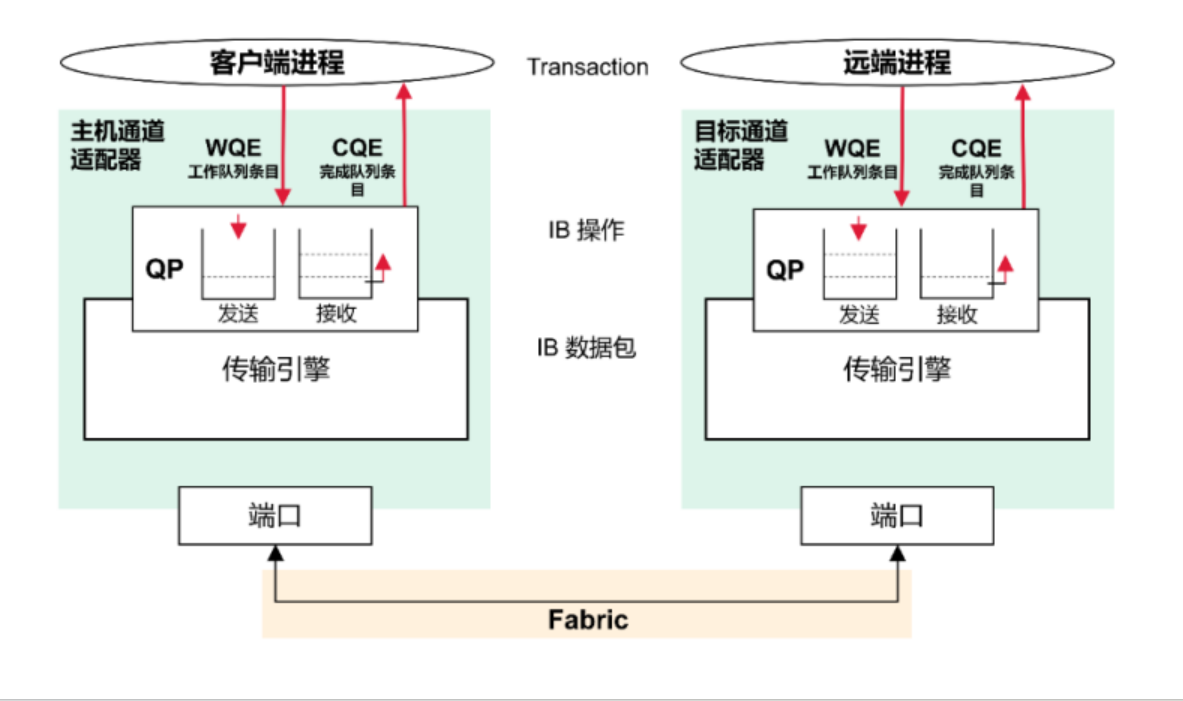
在这张图中,我们可以看到InfiniBand架构中的两个关键组件:队列对(Queue Pair, QP)和工作队列元素(Work Queue Element, WQE)。
在这张图中,我们分别看到了两个不同的操作场景:
左侧的图表显示了“发送操作”:在这个场景中,应用程序创建一个WQE,指定了发送数据的详细信息,并将它放入到QP的发送队列中。然后,硬件会处理WQE,将数据发送出去。一旦数据发送完成,一个完成队列元素(Completion Queue Element, CQE)将被生成,以通知应用程序该操作已经完成。
右侧的图表展示了“接收操作”:在这个过程中,接收队列提前配置了WQE以准备接收数据。当数据到达并被硬件处理后,它被放置到相应的内存位置,并生成一个CQE以通知应用程序数据已经准备好。
在两种操作中,QP是关键的中介。QP实际上是一个抽象的概念,它包含了两个工作队列:一个用于发送操作,另一个用于接收操作。每个QP都与一个特定的远程QP直接相连,确保了数据传输的端到端性质。
此外,图表下方的“Fabric”代表了InfiniBand网络的物理连接基础设施。这可以是由交换机、路由器和线缆组成的网络,它们共同提供了数据传输的物理路径。
图中的主要组件包括:
- 队列对(Queue Pair, QP):它是InfiniBand通信的基本单位,由一个发送队列和一个接收队列组成。每个队列都包含多个工作队列元素(Work Queue Entries, WQEs),用于指定数据传输的操作。
- 工作队列(Work Queue, WQ):分为两种,一种是发送工作队列(Send WQ),用于存放输出数据的操作指令;另一种是接收工作队列(Receive WQ),用于存放输入数据的操作指令。
- 完成队列(Completion Queue, CQ):用于存放已经完成的工作队列元素(WQEs)的状态信息。无论是发送还是接收操作完成,相关的状态信息都会被放入完成队列。
三、RDMA(远程直接数据存取)协议
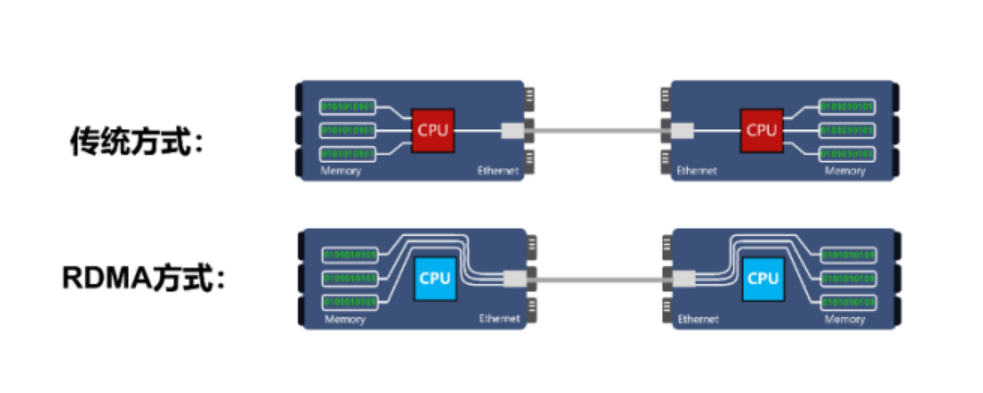
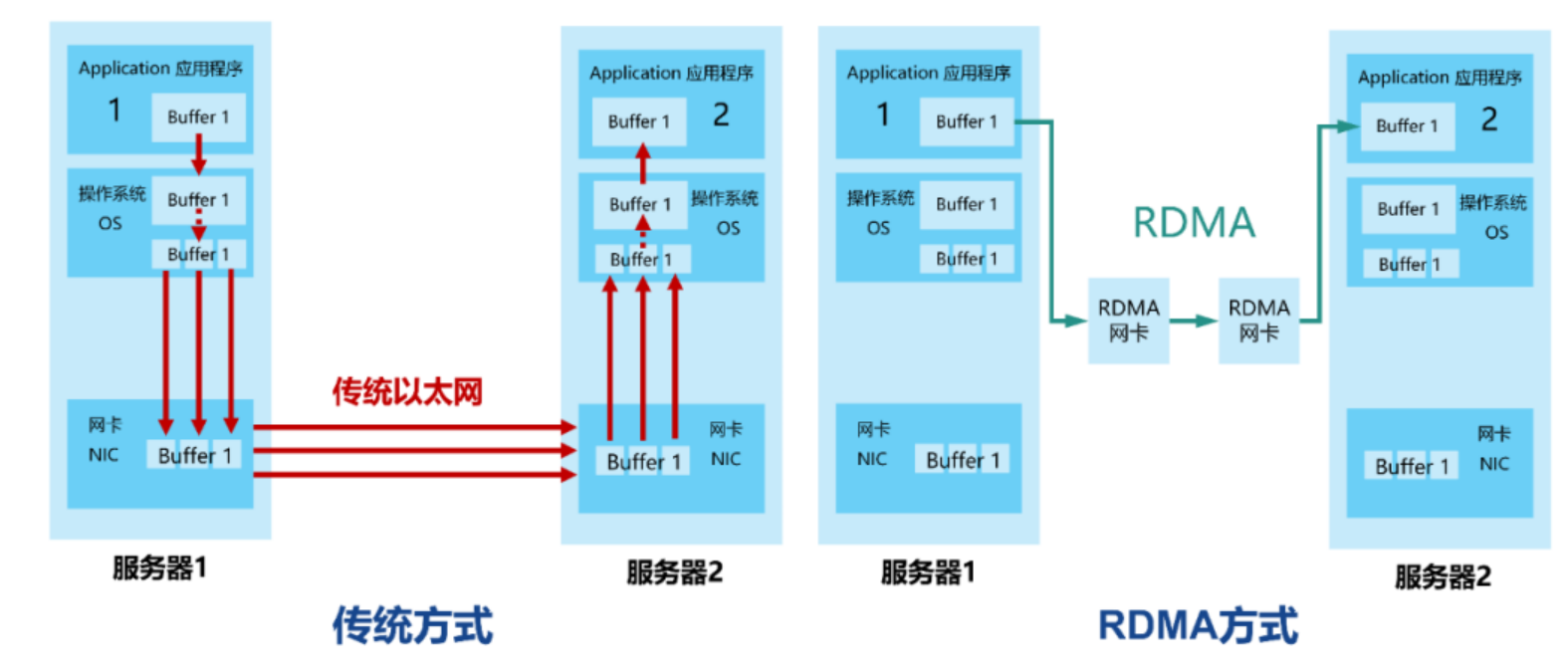
RDMA(Remote Direct Memory Access)是一种网络技术,它允许计算机直接在另一台计算机的内存上进行读写操作,而无需操作系统的介入,从而显著降低了延迟和CPU的使用率。这种技术特别适用于需要高吞吐量和低延迟的应用,如高性能计算(HPC)、大数据分析和存储网络。
RDMA具有以下特点:
- 低延迟:通过绕过操作系统的网络栈,直接在应用程序之间传输数据,RDMA减少了数据传输的延迟。
- 高吞吐量:RDMA允许大量数据直接从发送方的内存传输到接收方的内存,减少了传统网络传输中的拷贝次数。
- CPU卸载:数据传输不通过CPU,因此在数据传输过程中CPU几乎不需要参与,这意味着更多的CPU资源可以用于其他计算任务。
- 零拷贝:数据直接从源内存传送到目标内存,无需在内存间进行多次拷贝。
RDMA的工作机制如下:
- 连接建立:主机和目标设备之间首先需要建立连接。在InfiniBand架构中,这涉及到设置队列对(QPs),它们是RDMA通信的端点。
- 内存注册:在可以进行RDMA操作之前,必须在参与通信的每个节点上“注册”内存区域。这意味着对这些内存区域进行标记,允许远程直接访问。
- 地址交换:建立连接后,节点交换所需的信息,以便它们知道对方内存的确切位置。
- 数据传输:发送方使用RDMA写或RDMA读操作直接在接收方的内存上写数据或读数据。
RDMA通信需要特定的硬件支持,如RDMA capable network cards(例如InfiniBand HCA、RoCE enabled NICs、iWARP compatible NICs),和支持RDMA的交换机。这些硬件组件共同提供必要的功能来实现RDMA操作。
四、总结
数据中心网络架构和InfiniBand技术是现代数据中心高效、稳定运行的关键。不同的网络架构各有优缺点,需要根据实际需求选择合适的架构。同时,RDMA协议和InfiniBand技术的应用,进一步提升了数据中心的性能和稳定性。

















 2711
2711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









