







1、下图展示了Hadoop MapReduce 并行计算框架上执行一个用户提交的MapReduce程序的过程。
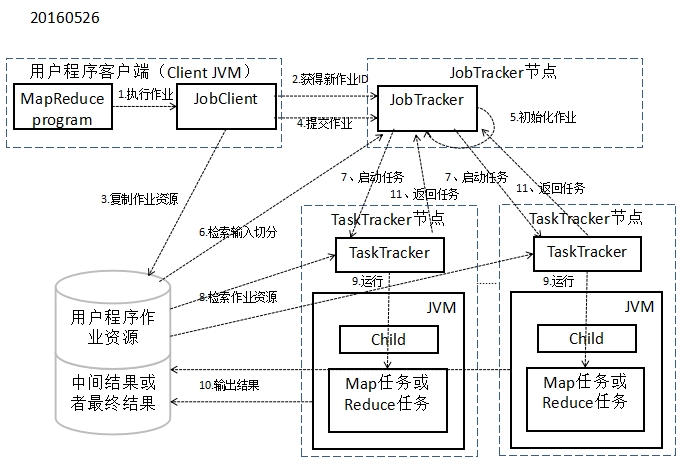
①首先,程序客户端通过作业客户端接口程序JobClient提交一个用户程序。
②然后JobClient先JobTracker提交作业执行请求并获得一个JobID
③JobClient同时也会将用户程序作业和待处理的数据文件信息准备好并存储在HDFS中。
④JobClient正式向JobTracker提交和执行该作业
⑤JobTracker接受并调度该作业,并进行作业的初始化准备工作,根据待处理数据的实际分片情况,调度和分配一定的Map节点来完成作业
⑥JobTracker查询作业中的数据分片信息,构建并准备相应的任务。
⑦JobTracker启动TashTracker节点开始执行具体的任务
⑧TaskTracker根据所分配的具体任务,获取相应的作业数据
⑨TaskTracker节点创建所需要的java虚拟机,并启动相应的Map任务(或Reduce任务)的执行
十TashTracker执行完所分配的任务之后,若是Map任务,则把中间结果数据输出到HDFS中,若是Reduce任务,则输出到最终结果
十一 TaskTracker向JobTracker报告所分配的任务完成,若是Map任务完成并且后去还有Reduce任务,则JobTracker会分配和启动Reduce节点继续处理中结果并输出最终结果。















 3256
3256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









