







学习本学期的第一个算法——KNN。
课后完成作业1:

作业使用python+numpy和google cloud。
教程地址:http://cs231n.github.io/python-numpy-tutorial/
第一部分 KNN
图像分类是计算机视觉的核心问题。一个给定的数据集,比如猫、狗、树等,对于人来说,很容易识别,但是要让机器准确识别出却是一项很难的任务。以猫为例,计算机只看到一堆[0,255]的网格数据,怎样把这些数据和语义上的“猫”联系到一起?即便对于同一只猫,当相机移动时,也会导致最终的像素数据完全改变,而这个矩阵仍然代表同一只猫。实际识别中,还要面临如下挑战:
1.光照

2.形变

3.遮挡

4.背景杂物

5.同类差异

算法需要对以上因素具有鲁棒性,考虑到这些,问题突然变得复杂了起来。而我们要设计的算法不仅仅要能识别分类猫,还要能识别世界上的其他种类,这是一个巨大的挑战。接下来的课程中我们就是要不断的揭秘和学习这些"made this possible"的算法。
而这类算法想要写成hard-code形式的是不可能的。
由上一节课学习的hube &wissal研究的启发,边缘对于识别很重要,所以我们会想到提取猫图像的边缘,得到不同的点和边界的信息,用一种人为制定的规则进行描述,最后进行识别。然后事实证明这样行不通。首先这个方法本身鲁棒性就差,其次即使这次猫识别成功了,等到研究另外一个种类时,所有一切又要从头开始,所以这种方法扩展性差,我们要找到一种算法可以识别任何物体。这种算法就是依靠数据驱动(data-driven)的算法。我们收集带标签的各个种类的数据,然后交给机器训练出一个模型/分类器,这个分类器总结了输入的所有已知信息并能识别出这些类别。如果我们将这个模型应用于另外一个该类图片它可以成功识别出所属类别,而且并不需要对模型进行任何修改。在过去的10-20年里,这种方法发展的很好。

不过基于数据/内容的方法远比深度学习更加广泛。一种最容易想到的基于数据的分类器就是Nearest Neighbor。
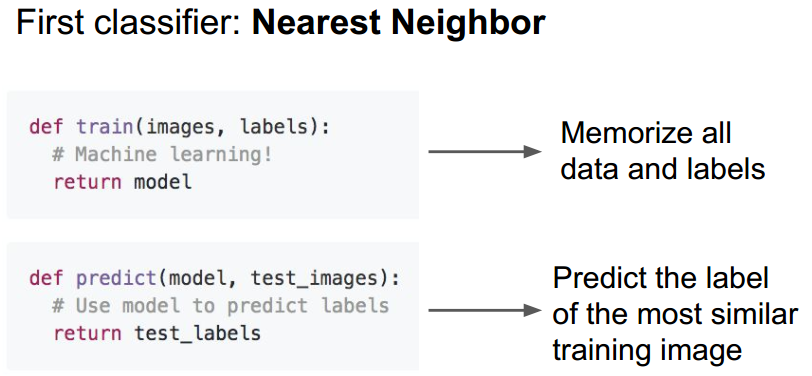
trainning很简单,仅仅是存储住所有数据,预测的时候就是将新的图片与数据集中的图片进行比较找出最相似的图片,这个最相似图片的label就是新图片的label。
可以使用的数据集:CIFAR10
10个类别:airplane、automobile、bird、cat、deer、dog、frog、horse、ship、truck
训练集:5000
测试集:1000
距离函数:衡量两幅图片之间的差异
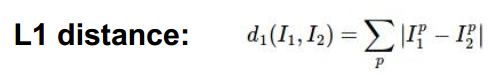
Q:how fast?
A:训练O(1)
预测O(N)
这样不好!我们期望的是:训练时间slow;预测时间fast. 后面介绍的CNN或者其他参数模型将符合这个期望。
一个可以直观感受KNN效果的网址:http://vision.stanford.edu/teaching/cs231n-demos/knn/
K=1只看最近邻:
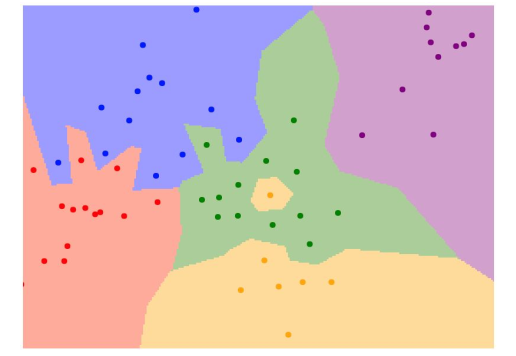
1.k=1时绿色区域出现了一个黄色小岛,这样不好
2.出现了很多fingers,由一个较远的点造成,可能是噪声
增大K,权衡k个近邻(投票):
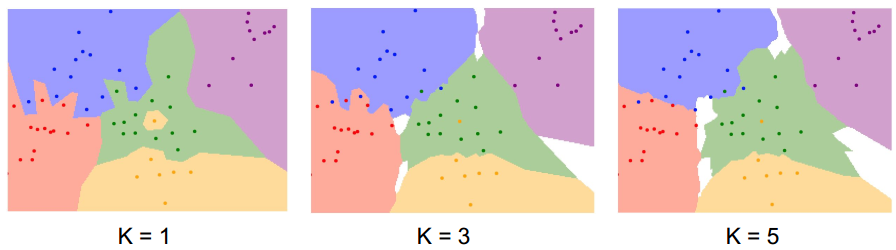
可以看出:
1.小岛效应消除了
2.fingers变得越来越smooth
(注:白色区域是没有最近邻的区域,也就是进行k近邻投票后没有majority 一方)
应用到具体图片:

绿色表示成功匹配,红色表示错误匹配,可见,KNN效果不佳。
关于距离函数的选取:
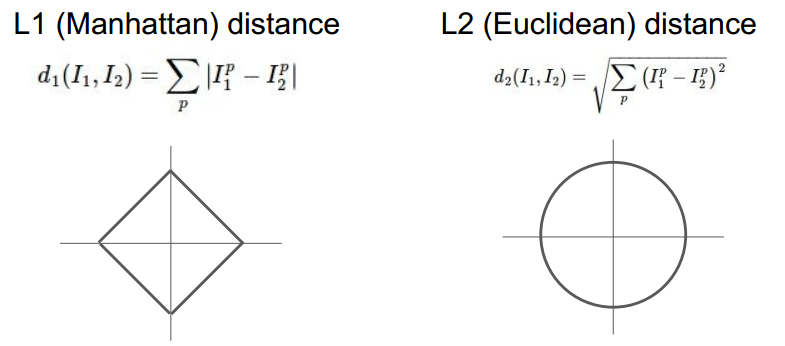
不同的距离函数代表空间下不同的几何、拓扑结构。L1在原点周围形成一个矩形,L2在原点周围形成一个圆。背后更深层的含义是L1距离与坐标系的选取有关,L2则无关,不管坐标系怎么旋转,不影响两点之间的L2距离。
通常来说:
如果数据单独的元素有着特定的意义,比如选取雇员时,考虑薪资要求,工作经验等,L1较合适;如果各个维度比较generalize,L2较合适。
针对特定的问题和数据,hyperparameters的选取:
1.numof neighbors(K)
2.distance metric
3.num of classes
这些参数无法从数据中学习,需要在训练书记之前进行设定——>problem-depend
怎样设定这些参数呢?
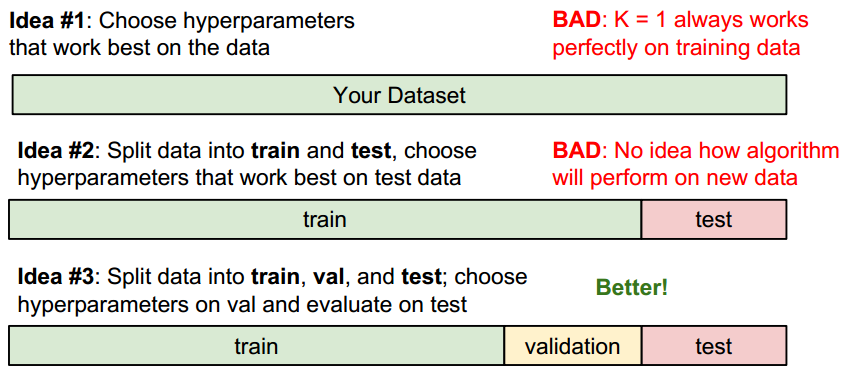
如何保证测试集具有代表性?
1.一次性收集很多数据,利用数学方法随机分组
2.收集多次数据,最先的数据用于训练,后来收集的作为测试。
Idea#4是最可取的,在交叉验证的基础上,测试不同K下的分类准确率,选择准确率最高的K。
实际上,并没有人用KNN分类图片:
1.test的时候太慢了
2.距离度量信息量太少
例如:

3.维度灾难
想要密集的覆盖整个空间我们需要大量的带label的数据,数据量随纬度的增加呈指数增长。

上图中一个点代表一个sample,不同颜色代表不同种类。
第二部分 linear classification
线性分类是一种简单的学习算法,也是神经网络的基础。
深层的神经网络可以加深对图片含义的理解,这也真是计算机视觉的目标:

千里之行始于足下,我们先从最基本的线性分类开始。
线性分类是参数模型(parametric model)的一种,
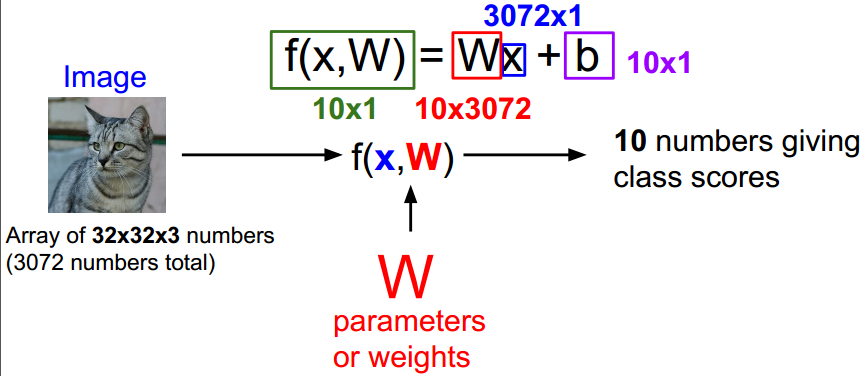
以CIFAR10数据集为例,10个种类,输入图像,得到分类结果:

在高维空间里构建线性分类器,对与一个类得到一个boundary,一边是该类,剩余的是其他类:
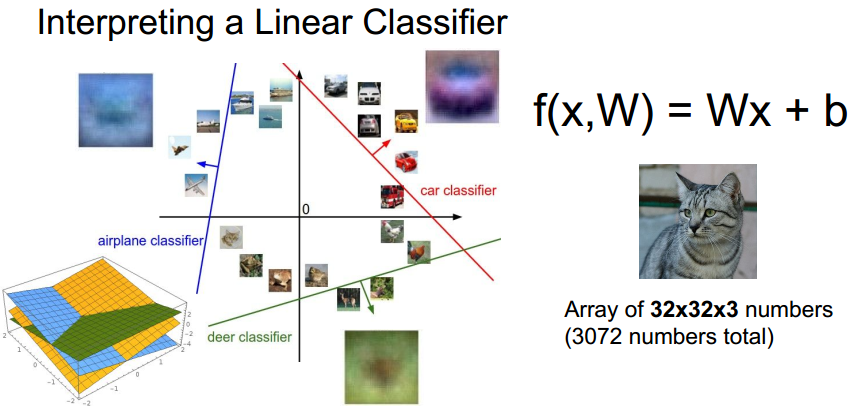
线性分类不是万能的:
注意:完成作业1。















 1403
1403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









