







前言
前面我们学习了基于Langchain4j的大模型的很多玩法,今天我们把这些玩法整合成一个综合案例:智能挂号系统,案例不会特别复杂,主要功能包括医疗问答,挂号咨询,预约挂号,取消挂号等几个功能,其中会使用到的技术包括:RAG知识库,回话记忆功能,Tools的使用,流式输出,提示词等等,希望该案例可以一点打面,给你更多的遐想,那么下面我们就开始吧。
基础环境
首先我们需要创建一个SpringBoot工程,然后导入我们需要的依赖,具体版本如下
- SpringBoot : 3.3.8
- mybatis-plus : 3.5.5
- langchain4j : 1.0.0-beta2
- hutool-all : 5.8.26
- lombok : 1.18.36
- langchain4j-easy-rag : RAG知识库
- langchain4j-pgvector : 向量数据库
<properties>
<maven.compiler.source>21</maven.compiler.source>
<maven.compiler.target>21</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<langchain4j.version>1.0.0-beta2</langchain4j.version>
<mybatis-plus.version>3.5.5</mybatis-plus.version>
</properties>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.3.8</version>
</parent>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-bom</artifactId>
<version>1.0.0-beta2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!--互联网搜索API-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-web-search-engine-searchapi</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<!--通义千问-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
</dependency>
<!--RAG知识库-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<!--pgvector向量数据库-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pgvector</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<!--Ollama本地模型-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama-spring-boot-starter</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<!--流式输出支持-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.26</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<scope>provided</scope>
</dependency>
</dependencies>
数据库准备
数据库我们需要三个数据库,分别是:mysql,mongo,pgvector , 可以使用docker-desk安装,具体不会的话可以百度一下,或者直接在windos安装也可以。
- MongoDB : 主要是用来实现大模型记忆功能,存储对话内容
- pgvector : 向量数据库,用来存储RAG知识库
- Mysql数据库,用来存储挂号单和排班表,以为只是一个小案例,设计的就比较简单,导入以下表机构
CREATE TABLE `appointment_order` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT 'ID',
`name` varchar(255) DEFAULT NULL COMMENT '姓名',
`id_card` varchar(255) DEFAULT NULL COMMENT '身份证',
`dept` varchar(255) DEFAULT NULL COMMENT '科室',
`time` varchar(255) DEFAULT NULL COMMENT '预约时间',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`doctor_name` varchar(255) DEFAULT NULL COMMENT '医生名字',
`date` varchar(255) DEFAULT NULL COMMENT '预约日期',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='挂号单';
CREATE TABLE `doctor_scheduling` (
`id` bigint NOT NULL AUTO_INCREMENT,
`doctor_name` varchar(255) DEFAULT NULL COMMENT '医生名字',
`dept` varchar(255) DEFAULT NULL COMMENT '科室',
`date` varchar(255) DEFAULT NULL COMMENT '排班日期',
`time_start` int DEFAULT NULL COMMENT '时间开始',
`num` int DEFAULT NULL COMMENT '票数',
`time_end` int DEFAULT NULL COMMENT '时间结束',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='医生排班';
配置文件
配置文件的内容这里我就一步到位了,在项目的application.properties中我们需要配置如下内容
- streaming-chat-model : 大模型配置,可以使用ollama或者三方模型 ,对话模型需要执行stream流式对话
- embedding-model : 向量模型,主要是用来支持RAG知识库
- mongodb :配置mongo的链接信息 , 用户存储对话内容以实现记忆存储(前提是你需要安装好Mongo)
- pgvector :配置向量数据库,以实现RAG知识库(前提是你需要安装好向量数据库,看前面的文章)
- mysql : 配置Mysql数据库,主要是存储排班和挂号的数据(前提是你需要安装好Mysql)
langchain4j:
ollama:
streaming-chat-model:
base-url: http://localhost:11434
model-name: qwen2:7b
chat-model:
log-requests: false
log-responses: false
embedding-model:
model-name: all-minilm
base-url: http://localhost:11434
community:
dashscope:
streaming-chat-model:
api-key: sk-xx
model-name: qwen-max-latest
spring:
data:
mongodb:
uri: mongodb://admin:123456@localhost:27018/doctor_message?authSource=admin
datasource:
url: jdbc:mysql://localhost:3306/ai-doctor?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
logging:
level:
org.whale: debug
pgvector:
database: postgres
host: 127.0.0.1
port: 5433
user: postgres
password: 123456
table: doctor_rag
search:
apiKey: xxx
engine: baidu
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
创建AI智能体
我们创建一个名字为 DoctorAgent 接口,其中提供对话方法,并通过 @UserMessage 指定用户消息,通过 @MemoryId 做记忆存储隔离。另外还需要为智能体指定提示词,这里我使用@SystemMessage(fromResource = "prompt-template.txt")外部文件的方式指定,如下:
/**
* 定义挂号智能体
* @AiService(
* wiringMode = EXPLICIT ,
* streamingChatModel = " " ,
* chatMemoryProvider = " " ,
* tools = " " ,
* contentRetriever = "")
*/
public interface DoctorAgent {
@SystemMessage(fromResource = "prompt.txt")
Flux<String> streamChat(@UserMessage String message , @MemoryId String memoryId);
}
智能体的提示词内容中需要明确的定义出AI的身份,以及它具备的能力,在resources/prompt.txt内容如下
你是天府新区人民医院的官方智能医疗助手「康康」,具备专业医疗知识库支持。请用温暖、清晰的中文与用户交互,所有回答需符合医院官方政策。
开场自动发送欢迎语:『您好!这里是天府新区人民医院智能助手康康,可为您提供:① 医疗百科 ②就诊咨询 ③ 预约/取消挂号 ④ 就诊查询 请问需要什么帮助?』
1.医疗百科
如果用户在询问医疗相关的知识,请从向量存储中查找答案,如果未检索到数据再进行互联网搜索。
2.就诊咨询
根据症状建议医疗方案以及就诊科室(如头痛→神经内科)
根据科室建议就诊医生(如神经内科->王医生)
3.预约/取消挂号
科室推荐:根据用户的病情推荐合适的科室
医生推荐:根据科室查询该科室下的医生,并推荐一名医生
智能挂号:如果用户需要挂号让用户提供:身份证号(idCard),姓名(name),挂号日期(date),挂号时间(time),科室(dept),医生名字(doctorName),如果用户不确定科室和医生可以给用户推荐科室以及医生,挂号时需要用户确认挂号信息后才能执行挂号
用户提供挂号信息格式如:身份证:111111111111,姓名:张三,挂号日期:2025-4-26 ,挂号时间:11:45,科室:神经内科,医生名:张医生。如果用户未指定医生或科室可以根据用户的症状自动匹配科室和医生
取消挂号:输入挂号单号+身份验证后即可取消
4.就诊查询
支持通过姓名/日期查询挂号记录
实时推送就诊排队进度
5.今天的时间是 {{current_date}}
配置AI智能体
接下来我们创建配置类,为智能体赋予相应的能力,其中包括如下几个能力
- 指定对话模型,采用支持流式输出的千问模型,也可以使用ollama,就是会比较慢一点(机器不行)
- 指定记忆存储
@Configuration
@EnableConfigurationProperties({PGVectorProperties.class,SearchProperties.class})
public class LLMConfig {
/**
* 医疗助手智能体
*/
@Bean
public DoctorAgent doctorAgent(
QwenStreamingChatModel chatModel,
ChatMessageRepository chatMessageStore,
DoctorTool doctorTool ,
EmbeddingStore<TextSegment> embeddingStore,
SearchApiWebSearchEngine webSearchEngine,
EmbeddingModel embeddingModel){
//RAG内容检索
EmbeddingStoreContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(1) //每次只需要找到一个结果
.minScore(0.8) //准确率,越大越精准
.build();
return AiServices.builder(DoctorAgent.class)
//流式对话
.streamingChatLanguageModel(chatModel)
//记忆功能
.chatMemoryProvider((memoryId -> MessageWindowChatMemory.builder().id(memoryId).chatMemoryStore(chatMessageStore).maxMessages(20).build()))
//调用自定义工具
.tools(doctorTool ,new WebSearchTool(webSearchEngine))
//RAG知识库检索
.contentRetriever(contentRetriever)
.build();
}
/**
* 创建向量存储
*/
@Bean
public EmbeddingStore<TextSegment> embeddingStore(PGVectorProperties properties, EmbeddingModel embeddingModel) {
//基于 PgVector的向量存储 - 基于yml配置读取
return PgVectorEmbeddingStore.builder()
.table(properties.getTable())
//.dropTableFirst(true) 每次重启都要重新创建
.createTable(true) //自动创建表
.host(properties.getHost())
.port(properties.getPort())
.user(properties.getUser())
.password(properties.getPassword())
.dimension(embeddingModel.dimension()) //all-minilm模型的向量维度(简单理解就是内容长度如[111,222 ... 333])
.database(properties.getDatabase())
.build();
}
/**
* web搜索引擎
*/
@Bean
public SearchApiWebSearchEngine webSearchEngine(SearchProperties properties) {
return SearchApiWebSearchEngine.builder()
.engine(properties.getEngine())
.apiKey(properties.getApiKey())
.build();
}
}
这里的配置内容挺多的,我们稍微整理一下
- 通过@EnableConfigurationProperties 启用了PGVectorProperties.class 向量数据库配置, 以及SearchProperties.class 互联网搜索配置,这2个配置我们在后面定义
- 定了 DoctorAgent 智能体Bean,指定的是千问的steam模型QwenStreamingChatModel
- 给智能体指定了ChatMessageRepository 消息持久化的存储,该类我们在后面定义
- 给智能体指定了 DoctorTool 工具,该工具主要是根据用户的提问实现智能问答,智能挂号等。以及WebSearchTool 互联网搜索统计股
- 给智能体指定了 contentRetriever RAG内容检索能力,主要是医疗问答需要检索RAG
整合Mongo持久化消息
整合Mongo需要引入spring-boot-starter-data-mongodb依赖,并在yml配置链接信息,然后创建支持会话记忆存储的持久层repository , 主要是和Mongo对接实现对话消息的CRUD,需要注意的是一个memoryId回话对应的是一条数据,也就是说在mongo中采用 memoryId : [json数组]的方式存储对话内容
/**
* 对话记录持久化
*/
@Repository
@Slf4j
public class ChatMessageRepository implements ChatMemoryStore {
@Resource
private MongoTemplate mongoTemplate;
@Override
public List<ChatMessage> getMessages(Object memoryId) {
Query query = new Query(Criteria.where("messageId").is(memoryId));
ChatMessages chatMessages = mongoTemplate.findOne(query, ChatMessages.class);
log.debug("持久化 - 查询对话消息 memoryId = {}",memoryId);
if(ObjectUtil.isNull(chatMessages)){
return CollectionUtil.newArrayList();
}
List<ChatMessage> chatMessageList = ChatMessageDeserializer.messagesFromJson(chatMessages.getContent());
return chatMessageList;
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
log.debug("持久化 - 插入或更新消息 messages = {}",messages);
Query query = new Query(Criteria.where("messageId").is(memoryId));
Update update = new Update();
update.set("content", ChatMessageSerializer.messagesToJson(messages));
mongoTemplate.upsert(query, update, ChatMessages.class);
}
@Override
public void deleteMessages(Object memoryId) {
log.debug("持久化 - 删除对话消息 memoryId = {}",memoryId);
mongoTemplate.remove(memoryId);
}
}
Mongo-对话消息持久化,实体类
@Document("chat_message")
@Data
public class ChatMessages {
/**
* 消息ID
*/
@Id
private String messageId;
/**
* 对话内容
*/
private String content;
}
整合向量数据库
整合向量数据库需要引入langchain4j-easy-rag , langchain4j-pgvector 这2个依赖,向量数据库的链接信息已经在yml中配置好了,接下来需要一个properties对象读取配置,如果你还没有安装向量数据库请看前面的文章
@ConfigurationProperties(prefix = "pgvector")
@Data
public class PGVectorProperties {
//主机
private String host;
//端口
private int port;
//数据库
private String database;
//账号
private String user;
//密码
private String password;
//向量表
private String table;
}
然后需要配置 EmbeddingStore 向量存储,并给智能体指定 EmbeddingStoreContentRetriever RAG检索,在上面配置类中已经定义完成。
定义tools实现挂号逻辑
我们的tools会比较复杂,因为智能挂号相关的能力都主要是通过tools调用数据库来完成的,tools中应该具备如下几个方法
- 查询科室和医生
- 查询用户的挂号单
- 查询预约条件时候可预约(检查号源)
- 根据用户的预约信息帮助用户挂号
- 取消挂号功能
每个tools方法都需要指明作用,触发条件,以及通过@P指定tools需要的参数。tools方法拿到参数应该去Mysql执行相关的能力,具体如下
/**
* AI Tools
*/
@Component
@Slf4j
public class DoctorTool {
//预约挂号服务
@Resource
private AppointmentOrderService appointmentOrderService;
//医生排班信息服务
@Resource
private DoctorSchedulingService doctorSchedulingService;
/**
* 查询医生
*/
@Tool(name = "根据科室推荐合适的医生",value = "根据科室查询该科室下的医生,并推荐一名医生")
public String queryDoctorName(@P("科室")String dept){
log.info("根据科室推荐合适的医生 {}",dept);
List<DoctorScheduling> doctorSchedulings = doctorSchedulingService.list(new LambdaQueryWrapper<>(DoctorScheduling.class).eq(DoctorScheduling::getDept, dept));
if(CollectionUtil.isEmpty(doctorSchedulings)){
return "[]";
}
return JSONUtil.toJsonStr(doctorSchedulings);
}
/**
* 查询订单
*/
@Tool(name = "查询用户的所有挂号单",value = "根据用户的身份证查询所有挂号单,以友好的方式返回给用户,注意结果的可读性")
public String queryOrder(@P("身份证")String idCard){
log.info("查询用户的挂号单 {}",idCard);
List<AppointmentOrder> appointmentOrders = appointmentOrderService.list(new LambdaQueryWrapper<>(AppointmentOrder.class).eq(AppointmentOrder::getIdCard,idCard));
if(CollectionUtil.isEmpty(appointmentOrders)){
return "没有查询到挂号单";
}
return JSONUtil.toJsonStr(appointmentOrders);
}
/**
* 查询是否有号
*/
@Tool(name = "查询是否可预约",value = "根据用户提供的挂号科室,日期,时间,医生名字查询号源并返回给用户,如果查到的号源为空提示用户没有号源")
public String queryCanAppointmentOrder(
@V("科室")String dept,
@V("预约日期") String date,
@V("预约时间") String time,
@V("医生名字") String doctorName){
log.info("查询是否可以预约 {} - {} - {} - {}",dept , date , time , doctorName);
List<DoctorScheduling> doctorSchedulings = doctorSchedulingService.list(new LambdaQueryWrapper<>(DoctorScheduling.class)
.eq(ObjectUtil.isNotNull(date),DoctorScheduling::getDate,date)
.eq(ObjectUtil.isNotNull(doctorName),DoctorScheduling::getDoctorName,doctorName )
.eq(ObjectUtil.isNotNull(dept),DoctorScheduling::getDept, dept));
if(CollectionUtil.isEmpty(doctorSchedulings)){
return null;
}
List<DoctorScheduling> list = doctorSchedulings.stream().filter(d -> d.inTime(time)).toList();
if(CollectionUtil.isEmpty(list)){
return null;
}
return JSONUtil.toJsonStr(list);
}
/**
* 执行挂号
*/
@Tool(name = "预约挂号",value = "根据用户提供的挂号信息,优先执行工具方法 queryCanAppointmentOrder 查询是否可以预约并告知用户," +
"如果可以预约需要让用户确认预约信息,确认后执行预约挂号并把挂号结果:科室,医生,时间,单号以友好的方式返回")
public String doAppointmentOrder(AppointmentOrder appointmentOrder){
log.info("预约挂号 {}",appointmentOrder);
AppointmentOrder exist = appointmentOrderService.queryOrder(appointmentOrder);
if(ObjectUtil.isNotNull(exist)){
return "已经有挂号单了";
}
//保持预约单
appointmentOrderService.saveAppointmentOrder(appointmentOrder);
return JSONUtil.toJsonStr(appointmentOrder);
}
/**
* 取消预约
*/
@Tool(name = "取消挂号",value = "根据用户提供的挂号信息取消挂号,要求用户提供身份证号和挂号单")
public String cancelAppointmentOrder(AppointmentOrder appointmentOrder){
log.info("取消挂号 {}",appointmentOrder);
if(ObjectUtil.isNull(appointmentOrder.getId())){
return "请提供单号";
}
if(ObjectUtil.isNull(appointmentOrder.getIdCard())){
return "请提供身份证";
}
AppointmentOrder exist = appointmentOrderService.getBaseMapper().selectOne(new LambdaQueryWrapper<AppointmentOrder>()
.eq(AppointmentOrder::getId,appointmentOrder.getId())
.eq(AppointmentOrder::getIdCard,appointmentOrder.getIdCard())
);
if(ObjectUtil.isNull(exist)){
return "没有挂号单";
}
appointmentOrderService.removeById(exist.getId());
return "成功取消挂号";
}
}
整合Mysql实现挂号逻辑
整合数据库就比较简单了,只需要引入mybaitsplus的依赖以及Mysql的驱动,然后在yml配置好链接信息就可以定义Mapper接口以及Service,这里就不多赘述了,这里贴一下挂号服务的实现代码
@Service
@Slf4j
public class AppointmentOrderServiceImpl extends ServiceImpl<AppointmentOrderMapper,AppointmentOrder> implements AppointmentOrderService {
@Resource
private DoctorSchedulingService doctorSchedulingService;
@Override
public AppointmentOrder getByIdCard(String idCard) {
return super.getOne(new LambdaQueryWrapper<>(AppointmentOrder.class).eq(AppointmentOrder::getIdCard, idCard));
}
@Override
public AppointmentOrder queryOrder(AppointmentOrder order) {
return super.getOne(new LambdaQueryWrapper<>(AppointmentOrder.class)
.eq(AppointmentOrder::getDept,order.getDept())
.eq(AppointmentOrder::getIdCard,order.getIdCard())
.eq(AppointmentOrder::getDate,order.getDate())
.eq(AppointmentOrder::getTime,order.getTime())
);
}
@Override
@Transactional(rollbackFor = Exception.class)
public void saveAppointmentOrder(AppointmentOrder appointmentOrder) {
String hour = appointmentOrder.getTime().split("-")[0].split(":")[0];
//扣减排班号数
DoctorScheduling doctorScheduling = doctorSchedulingService.getOne(new LambdaQueryWrapper<>(DoctorScheduling.class)
.eq(DoctorScheduling::getDate, appointmentOrder.getDate())
.eq(DoctorScheduling::getDoctorName, appointmentOrder.getDoctorName())
.le(DoctorScheduling::getTimeStart, hour)
.ge(DoctorScheduling::getTimeEnd, hour)
.eq(DoctorScheduling::getDept, appointmentOrder.getDept()));
if(ObjectUtil.isNull(doctorScheduling)){
throw new ArithmeticException("没有号源");
}
if(doctorScheduling.getNum() <= 0){
throw new ArithmeticException("没有号源");
}
doctorScheduling.setNum(doctorScheduling.getNum()-1);
doctorSchedulingService.updateById(doctorScheduling);
appointmentOrder.setId(null);
super.save(appointmentOrder);
}
}
相关实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName("appointment_order")
public class AppointmentOrder {
/**
* 单号
*/
@TableId(type = IdType.AUTO)
private Long id ;
/**
* 姓名
*/
private String name ;
/**
* 身份证
*/
private String idCard ;
/**
* 科室
*/
private String dept ;
/**
* 预约时间
*/
private String date ;
/**
* 预约时间段
*/
private String time ;
/**
* 创建时间
*/
private LocalDateTime createTime ;
/**
* 医生
*/
private String doctorName ;
}
@Document("chat_message")
@Data
public class ChatMessages {
/**
* 消息ID
*/
@Id
private String messageId;
/**
* 对话内容
*/
private String content;
}
@Data
@TableName("doctor_scheduling")
public class DoctorScheduling {
/**
* ID编号
*/
@TableId(type = IdType.AUTO)
private Long id ;
/**
* 科室
*/
private String dept ;
/**
* 预约日期
*/
private String date ;
/**
* 上班时间段
*/
private Integer timeEnd ;
/**
* 上班时间段
*/
private Integer timeStart ;
/**
* 医生
*/
private String doctorName ;
/**
* 医生
*/
private Integer num ;
public Boolean inTime(String time){
//06:27
int intTime = Integer.parseInt(time.split(":")[0]);
return getTimeStart() <= intTime && intTime <= getTimeEnd();
}
}
配置互联网搜索能力
还是采用websearch功能,需要引入 langchain4j-web-search-engine-searchapi 依赖,并配置 search.apiKey 和引擎,然后通过properties对象读取
/**
* 配置读取
*/
@ConfigurationProperties(prefix = "search")
@Data
public class SearchProperties {
private String apiKey;
private String engine;
}
然后定义SearchApiWebSearchEngine 的Bean然后配置给智能体,在上面已经配置过了。
开发Controller接口
接下来我们来开发Controller,这里我们定义2个接口,一个是用来加载RAG知识库,一个是用来智能对话的,RAG知识库我在网上随便找了一个篇医疗知识100问,然后通过DocumentByParagraphSplitter段落的方式去加载形成知识库。
@RestController
public class DoctorController {
@Resource
private EmbeddingStore<TextSegment> embeddingStore;
@Resource
private EmbeddingModel embeddingModel;
@GetMapping("/rag/load")
public String reagLoad(){
List<Document> documents = FileSystemDocumentLoader.loadDocuments("C:\\Users\\Administrator\\Desktop\\rag");
EmbeddingStoreIngestor.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
//文档切割 - 按照什么样的规则把文档分段
.documentSplitter(new DocumentByParagraphSplitter(60,10,new HuggingFaceTokenizer()))
.build().ingest(documents);
return "success";
}
}
对话我们采用 Flux 流式输出,下面是 ChatMessageDTO 参数
//AI智能对话接口
@Resource
private DoctorAgent doctorAgent;
@PostMapping(value = "/stream/chat",produces = "text/stream;charset=utf-8")
public Flux<String> streamChat(@RequestBody ChatMessageDTO chatMessageDTO){
try{
return doctorAgent.streamChat(chatMessageDTO.getMessage(),chatMessageDTO.getMemoryId());
}catch (Exception e){
e.printStackTrace();
return Flux.just("康康有点忙不过来啦,请稍后重新提问");
}
}
//参数对象
@Data
public class ChatMessageDTO {
private String memoryId;
private String message;
}
开发UI
启动项目
项目代码已经上传到:https://gitee.com/baidu11.com/doctor-agent,可以自行下载,你需要在电脑上安装Nodejs环境,然后执行npm run dev 即可启动,然后你需要在 vite.config.js 中 修改 target地址为你的后台地址。
测试项目
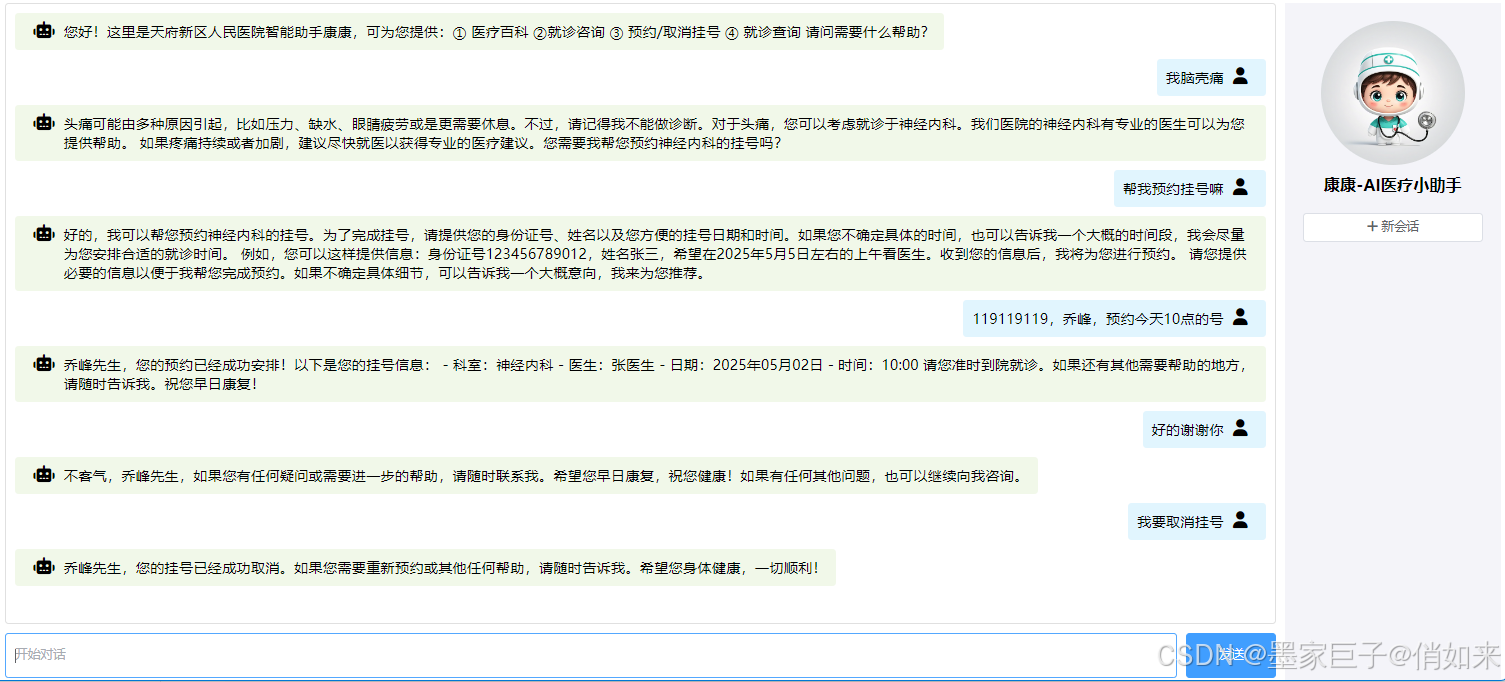
首先你需要通过http请求执行一下 /rag/load 知识库,然后启动并访问UI界面,测试效果如下
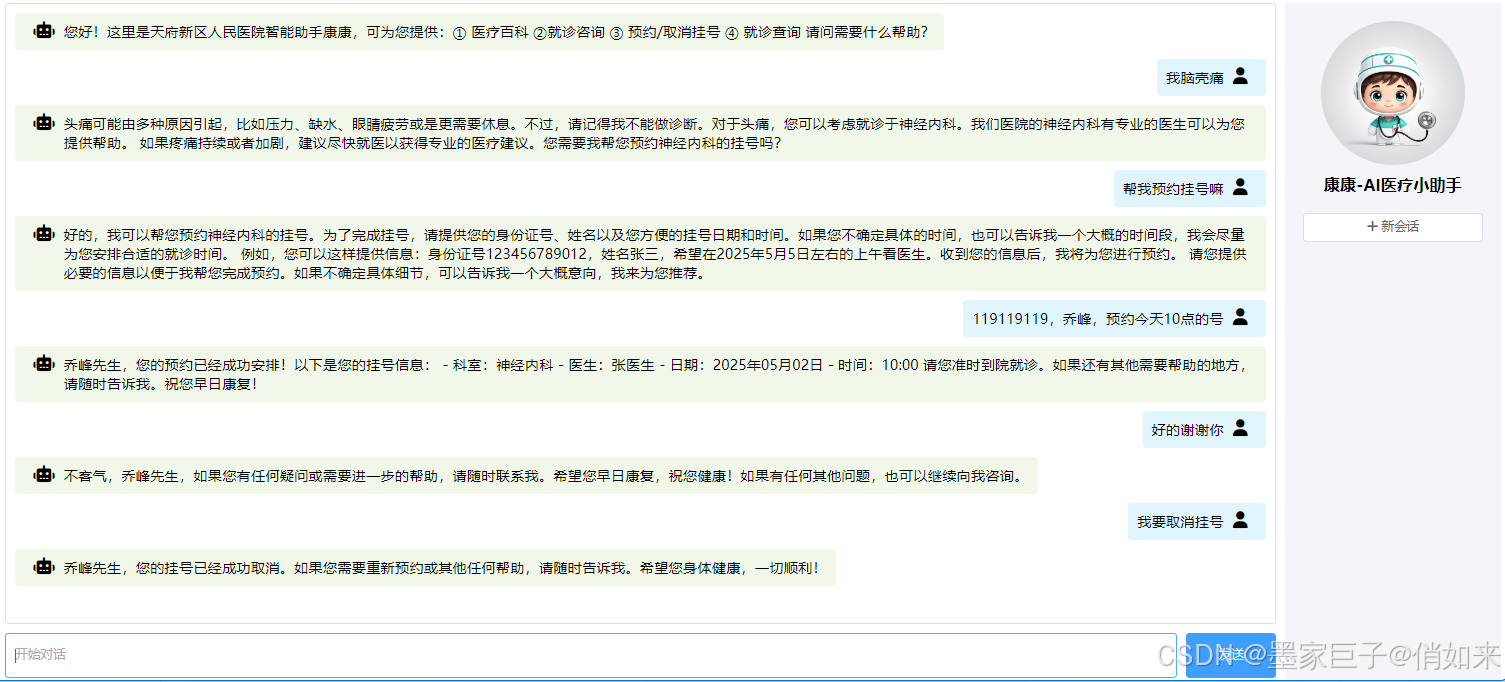
总结
本篇我们我们把前面八章的内容综合起来实现了AI智能挂号系统,其中涉及到:流式对话,记忆存储,对话隔离,Function Call (tools),WebSerach(互联网搜索),RAG(向量数据库-知识库搭建),prompt 提示词等等技术手段,希望文章对你有所帮助,白嫖可耻,观众老爷们请三联呀!!!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











