







 本文介绍了布朗聚类算法,这是一种自底向上的层次聚类方法,应用于自然语言处理。文章详细阐述了算法原理,包括评价函数、优化策略,并提供了代码实现的关键步骤解析。通过对语料库中的词进行聚类,生成一个二叉树结构,以提高n-gram模型的效率。
本文介绍了布朗聚类算法,这是一种自底向上的层次聚类方法,应用于自然语言处理。文章详细阐述了算法原理,包括评价函数、优化策略,并提供了代码实现的关键步骤解析。通过对语料库中的词进行聚类,生成一个二叉树结构,以提高n-gram模型的效率。
一、算法
布朗聚类是一种自底向上的层次聚类算法,基于n-gram模型和马尔科夫链模型。布朗聚类是一种硬聚类,每一个词都在且只在唯一的一个类中。

w是词,c是词所属的类。
布朗聚类的输入是一个语料库,这个语料库是一个词序列,输出是一个二叉树,树的叶子节点是一个个词,树的中间节点是我们想要的类(中间结点作为根节点的子树上的所有叶子为类中的词)。
初始的时候,将每一个词独立的分成一类,然后,将两个类合并,使得合并之后评价函数最大,然后不断重复上述过程,达到想要的类的数量的时候停止合并。
上面提到的评价函数,是对于n个连续的词(w)序列能否组成一句话的概率的对数的归一化结果。于是,得到评价函数:
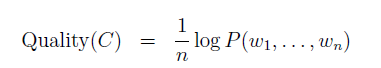
n是文本长度,w是词
上面的评价公式是PercyLiang的“Semi-supervised learning for natural languageprocessing”文章中关于布朗聚类的解释,Browm原文中是基于class-based bigram language model建立的,于是得到下面公式:
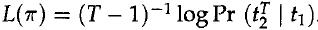
T是文本长度,t是文本中的词
上述公式是由于对于bigram,于是归一化处理只需要对T-1个bigram。我觉得PercyLiang的公式容易理解评价函数的定义,但是,Brown的推导过程更加清晰简明,所以,接下来的公式推导遵循Brown原文中的推导过程。
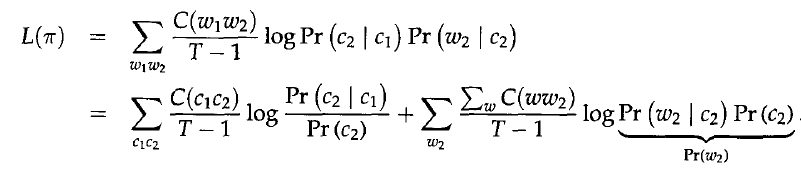
上面的推导式数学推导,接下来是一个重要的近似处理,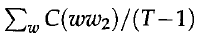
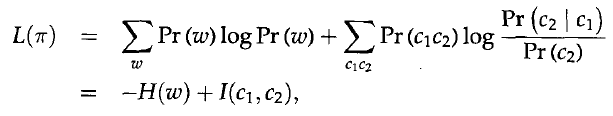
H(w)是熵,只跟1-gram的分布有关,也就是与类的分布无关,而I(c1,c2)是相邻类的平均互信息。所以,I决定了L。所以,只有最大化I,L才能最大。
二、优化
Brown提出了一种估算方式进行优化。首先,将词按照词频进行排序,将前C(词的总聚类数目)个词分到不同的C类中,然后,将接下来词频最高的词,添加到一个新的类,将(C+1)类聚类成C类,即合并两个类,使得平均互信息损失最小。虽然,这种方式使得计算不是特别精确,类的加入顺序,决定了合并的顺序,会影响结果,但是极大的降低了计算复杂度。
显然上面提及的算法仍然是一种naive的算法,算法复杂
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









