







PySpider 是一个我个人认为非常方便并且功能强大的爬虫框架,支持多线程爬取、JS动态解析,提供了可操作界面、出错重试、定时爬取等等的功能,使用非常人性化
爬取目标网站:https://mm.taobao.com/json/request_top_list.htm?page=1
命令行输入
pyspider all可以发现程序已经正常启动,并在 5000 这个端口运行。
接下来在浏览器中输入 http://localhost:5000,可以看到 PySpider 的主界面,点击右下角的 Create,命名为 taobaomm,当然名称你可以随意取,继续点击 Create。
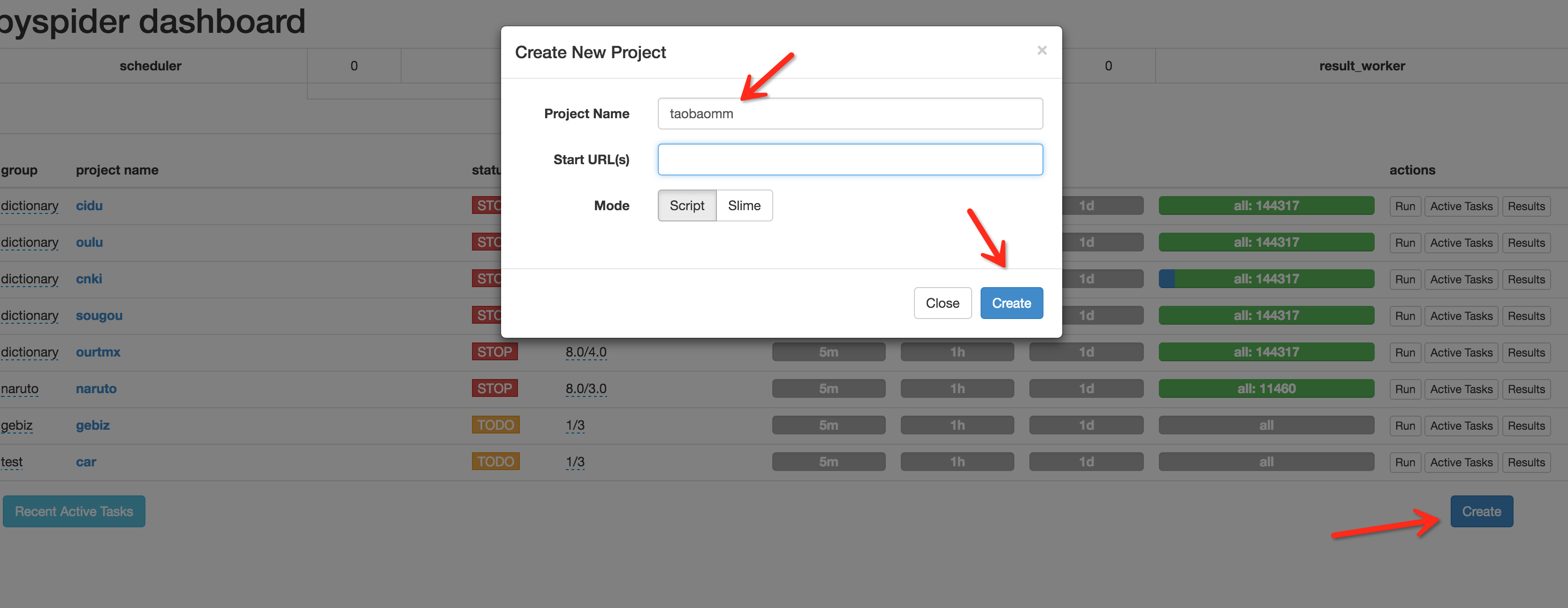
这样我们会进入到一个爬取操作的页面。
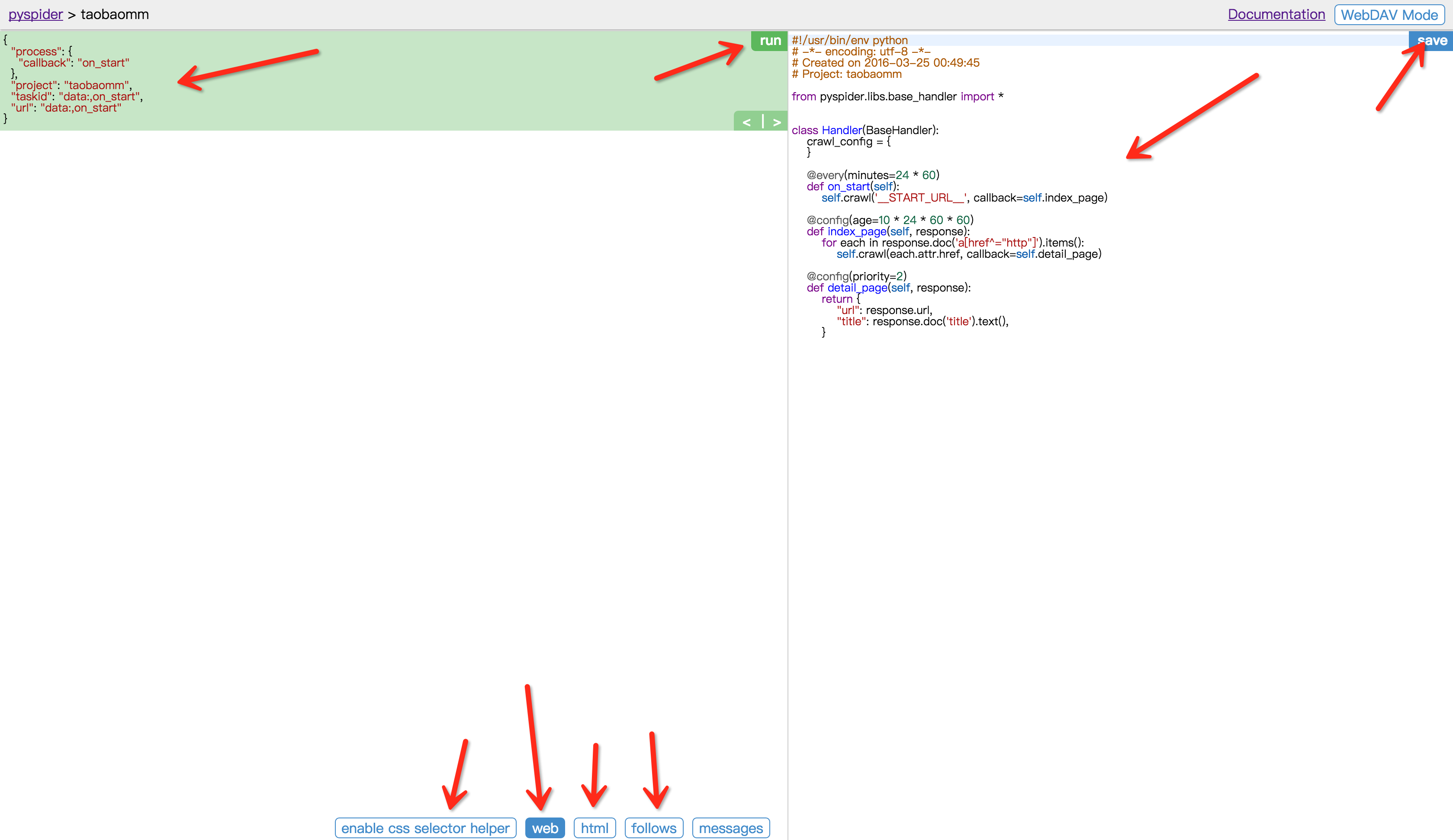
代码
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2016-11-23 10:20:15
# Project: taobaomm
from pyspider.libs.base_handler import *
PAGE_START = 1
PAGE_END = 30
DIR_PATH = 'F:\taobaomm'
class Handler(BaseHandler):
crawl_config = {
}
def __init__(self):
self.base_url = 'https://mm.taobao.com/json/request_top_list.htm?page='
self.page_num = 1
self.total_num = 30
self.deal = Deal()
@every(minutes=24 * 60)
def on_start(self):
while self.page_num <= self.total_num:
url = self.base_url + str(self.page_num)
print url
self.crawl(url, callback=self.index_page, validate_cert=False)
self.page_num += 1
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('.lady-name').items():
print each.attr.fref
self.crawl(each.attr.href, callback=self.detail_page, validate_cert=False,fetch_type='js')
@config(priority=2)
def detail_page(self, response):
domain = 'https:'+response.doc('.mm-p-domain-info li > span').text()
print domain
self.crawl(domain, callback = self.domain_page,validate_cert=False)
def domain_page(self,response):
'''
name = response.doc('.mm-p-model-info-left-top dd>a').text()
print name+"***"
dir_path = self.deal.mkDir(name)
brief = response.doc('.mm-aixiu-content').text()
if dir_path:
imgs = response.doc('.mm-aixiu-content img').items()
count = 1
self.deal.saveBrief(brief,dir_path,name)
for img in imgs:
url = img.attr.src
if url:
extension = self.deal.getExtension(url)
file_name = name+str(count)+'.'+extension
count += 1
self.crawl(img.attr.src,callback = self.save_img,save = {'dir_path':dir_path,'file_name':file_name},validate_cert = False)
'''
def save_img(self,response):
content = response.content
dir_path = response.save['dir_path']
file_name = response.save['file_name']
file_path = dir_path + '/' + file_name
self.deal.saveImg(content,file_path)
import os
class Deal:
def __init__(self):
self.path = DIR_PATH
if not self.path.endswith('/'):
self.path = self.path + '/'
if not os.path.exists(self.path):
os.makedirs(self.path)
def mkDir(self,path):
path = path.strip()
dir_path = self.path + path
exists = os.path.exists(dir_path)
if not exists:
print dir_path
os.makedirs(dir_path)
return dir_path
else:
return dir_path
def saveImg(self,content,path):
f = open(path,'wb')
print path
f.write(content)
f.close()
def saveBrief(self, content, dir_path, name):
file_name = dir_path + "/" + name + ".txt"
f = open(file_name,"w+")
print file_name
f.write(content.encode('utf-8'))
def getExtension(self,url):
extension = url.split('.')[-1]
return extension















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









