










Image Correction via Deep Reciprocating HDR Transformation

[ Project ]
Image Correction via Deep Reciprocating HDR Transformation 2018 CVPR

[ 全文简述 ]
本文的方法启发于这样的发现:曝光不足或曝光过度图像中缺失的那部分细节,存在于其相应的高动态范围 HDR 数据中。
基于此,本文的方法是将曝光不足或曝光过度图像先转换到 HDR 域中,此过程可以恢复丢失的细节;再将 HDR 域转换到输入的曝光不足或曝光过度域中。
转换网络结构用的是很简单的 U-Net。
目录
Image Correction via Deep Reciprocating HDR Transformation
Abstract
Image correction aims to adjust an input image into a visually pleasing one. Existing approaches are proposed mainly from the perspective of image pixel manipulation. They are not effective to recover the details in the under/over exposed regions.
In this paper, we revisit the image formation procedure and notice that the missing details in these regions (under/over exposed regions) exist in the corresponding high dynamic range (HDR) data. These details are well perceived by the human eyes but diminished in the low dynamic range (LDR) domain because of the tone mapping process.
Therefore, we formulate the image correction task as an HDR transformation process and propose a novel approach called Deep Reciprocating HDR Transformation (DRHT).
Given an input LDR image, we first reconstruct the missing details in the HDR domain. We then perform tone mapping on the predicted HDR data to generate the output LDR image with the recovered details.
To this end, we propose a united framework consisting of two CNNs for HDR reconstruction and tone mapping. They are integrated end-to-end for joint training and prediction.
Experiments on the standard benchmarks demonstrate that the proposed method performs favorably against state-of-the-art image correction methods.
研究对象及现有问题:
图像校正的目的是将输入的图像调整为视觉上悦目的图像。现有的方法主要是从图像像素处理的角度提出的,这些方法对于恢复曝光不足或曝光过度区域的细节是无效的。
研究动机和方法:
本文重新审视图像的形成过程,并注意到这些区域(under/over exposed regions)缺失的细节存在于相应的高动态范围 (HDR) 数据。人眼可以很好地感知这些细节,但在低动态范围 (LDR) 域中,由于 tone mapping 过程而减弱。
因此,本文将图像校正任务转变为一个 HDR 转换过程,并提出了一种名为 Deep Reciprocating HDR Transformation (DRHT) 的方法。给定一个输入的 LDR 图像,首先在 HDR 域中重建缺失的细节。然后对预测的 HDR 数据进行 tone mapping,生成包含恢复细节的输出 LDR 图像。
为此,本文提出了一个由两个 CNN 组成的统一框架,用于 HDR 重建和 tone mapping。
Method
The image correction problem has been studied for decades. It dates back to the production of Charge-Coupled Devices (CCDs), which convert optical perception to digital signals. Due to the semiconductors used in the CCDs, there is an unknown nonlinearity existed between the scene radiance and the pixel values in the image. This nonlinearity is usually modeled by gamma correction, which has resulted in a series of image correction methods. These methods tend to focus on image pixel balance via different approaches including histogram equalization [28], edge preserving filtering [11, 1], and CNN encoder-decoder [41]. Typically, they function as a preprocessing step for many machine vision tasks, such as optical flow estimation [3, 15], image decolorization [37, 36], image deblurring [30, 29], face stylization [39, 35] and tracking [38].
研究背景和意义:
图像校正问题已经研究了几十年。它可以追溯到 Charge-Coupled Devices (CCDs) 的产生,这种器件将光学感知转换为数字信号。由于 CCDs 使用的是半导体器件,所以场景亮度和图像中的像素值之间存在未知的非线性。这种非线性通常用伽马校正来模拟,这引起了一系列的图像校正方法。这些方法通过直方图均衡化 [28]、边缘保持滤波 [11,1] 和 CNN 编码器-解码器 [41] 等不同的方法来关注图像的像素平衡。通常,它们作为许多机器视觉任务的预处理步骤,如光流估计、图像脱色、图像去模糊、人脸风格化和目标跟踪。
Despite the demonstrated success, existing methods have the limitation in correcting images with under/over exposure. An example is shown in Figure 1, where the state-ofthe-art image correction methods fail to recover the missing details in the underexposed regions. This is because the pixel values around these regions are close to 0, and the details are diminished within them. Although different image pixel operators have been proposed for image correction, the results are still unsatisfactory, due to the ill-posed nature of the problem. Thus, a question is raised if it is possible to effectively recover the missing details during the image correction process.
尽管已有的方法被证明是成功的,但在校正曝光不足/过曝光的图像方面存在局限性。如图 1,SOTA 的图像校正方法无法恢复曝光不足区域的缺失细节。这是因为这些区域周围的像素值接近于0,其中的细节减少了。虽然提出了不同的图像像素算子进行图像校正,但由于问题的病态性质,其结果仍然不令人满意。这就提出了一个问题,在图像校正过程中,是否有可能有效地恢复缺失的细节?
To answer the aforementioned question, we trace back to the image formation procedure. Today’s cameras still require the photographer to carefully choose the exposure duration (∆t) and rely on the camera response functions (CRFs) to convert a natural scene (S) into an LDR image (I), which can be written as [5]:
However, when an inappropriate exposure duration is chosen, the existing CRFs can neither correct the raw data in the CCDs nor the output LDR images. This causes the under/over exposure in the LDR images. Based on this observation, we propose an end-to-end framework, called Deep Reciprocating HDR Transformation (DRHT), for image correction. It contains two CNN networks. The first CNN network reconstructs the missing details in the HDR domain and the second CNN network transfers the details back to the LDR domain. Through the reciprocating HDR transformation process, LDR images are corrected in the intermediate HDR domain.
为了回答上述问题,本文首先回溯到图像形成过程。如今的相机仍然要求摄影师仔细选择曝光时间 (∆t),并依靠相机响应函数 (CRFs) 将自然场景 (S) 转换为 LDR 图像 (I),可以写成式(1)。
然而,当曝光时间选择不当时,现有的 CRFs 既不能校正 CDDs 中的原始数据,也不能校正输出的 LDR 图像。这将导致 LDR 图像曝光不足/过度。基于这一观察,本文提出了一个端到端的框架,称为深度往复 HDR 变换 (DRHT),用于图像校正。它包含两个 CNN 网络。第一个 CNN 网络重建 HDR 域中缺失的细节,第二个 CNN 网络将细节传输回 LDR 域中。通过往复 HDR 变换过程,在中间 HDR 域对 LDR 图像进行校正。
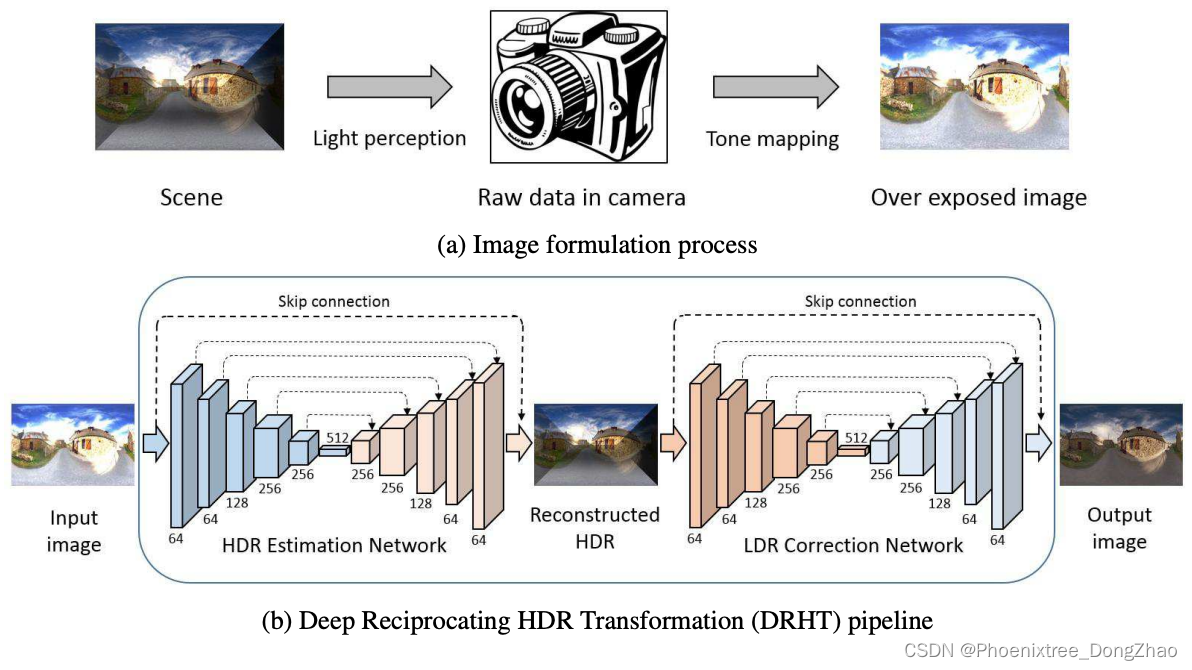
Figure 2: An overview of image formulation process and the proposed DRHT pipeline. Given an input under/over exposed LDR image, we first reconstruct the missing details in the HDR domain and map them back to the output LDR domain.
Hierarchical Supervision
We train this LDR correction network together with the aforementioned HDR estimation network. We adopt this end-to-end training strategy in order to adapt our whole model to the domain reciprocating transformation. To facilitate the training process, we adopt the hierarchical supervision training strategies similar to [13]. Specifically, we start to train the encoder part and the shallowest deconv layer of the LDR correction network by freezing the learning rates of all other higher deconv layers. During training, higher deconv layers are gradually added for fine tuning while the learning rates of the encoder and shallower deconv layers will be decreased. In this way, this network can learn to transfer the HDR details to LDR domain in a coarse-to-fine manner.
本文将这个 LDR 校正网络与前面提到的 HDR 估计网络一起训练。我们采用这种端到端的训练策略,以使我们的整个模型适应领域往复变换。为了方便训练过程,本文采用了类似于 [13] 的分级监督训练策略。具体来说,通过冻结所有其他更高解压缩层的学习速率,开始训练 LDR 校正网络的编码器部分和最浅层解压缩层。在训练过程中,逐渐增加较高的 deconv 层进行微调,同时降低编码器和较浅的 deconv 层的学习速率。这样,该网络可以学习从粗到细的方式将 HDR 细节转移到 LDR 域。
[13] Delving into salient object subitizing and detection. ICCV, 2017.
Experiments
Datasets
We conduct experiments on the city scene panorama dataset [51] and the Sun360 outdoor panorama dataset [45]. Specifically, since the low-resolution (64×128 pixels) city scene panorama dataset [51] contains LDR and ground truth HDR image pairs, we use the black-box Adobe Photoshop software to empirically generate ground truth LDR images with human supervision. Therefore, we use 39, 198 image pairs (i.e., the input LDR and the ground truth HDR) to train the first network and use 39, 198 triplets (i.e., the input LDR, the ground truth HDR and the ground truth LDR) to train the whole network. We use 1, 672 images from their testing set for evaluation. To adapt our models to the real images with high resolution, we use the Physically Based Rendering Technology (PBRT) [27] to generate 119 ground truth HDR scenes as well as the input and ground truth LDR images, which are then divided into 42, 198 patches for training. We also use 6, 400 images from the Sun360 outdoor panorama dataset [45] for end-toend finetuning (i.e., ǫ in Eq. 4 is fixed as 0), as they do not have ground truth HDR images, and use 1, 200 images for evaluation. The input images are corrupted from the originals by adjusting the exposure (selected from the interval [-6, 3], in order not to learn the mapping between one specific exposure degree and the ground truth) and contrasts to over/under expose the visible details. We resize the images to 256×512 pixels in this dataset.
本文在城市场景全景数据集 [51] 和 Sun360 户外全景数据集 [45] 上进行了实验。具体来说,由于低分辨率 (64×128像素) 的城市场景全景数据集 [51] 包含了 LDR 和 ground truth HDR 图像对,本文使用 Adobe Photoshop 软件,在人工监督下,经验地生成 ground truth LDR 图像。
因此,本文用39198 幅图像对 (即输入 LDR 和 ground truth HDR) 来训练第一网络,使用 39198 幅 (即输入 LDR、ground truth HDR 和 ground truth LDR) 来训练整个网络。
测试集:从上述数据集中的的测试集中选取了 1672 张图像进行评估。
为了使本文的模型适应高分辨率的真实图像,本文使用物理基础渲染技术(physical Based Rendering Technology, PBRT) [27] 生成 119 个 GT HDR 场景以及输入和 GT LDR 图像,然后将这些图像分割成 42,198 个小块进行训练。
本文使用了来自 Sun360 户外全景数据集 [45] 的 6400 幅图像进行端到端精细调整 (即,公式 4 中 ǫ 固定为 0),因为它们没有 ground truth HDR 图像,并使用了 1200 幅图像进行评估。通过调整曝光(从间隔 [- 6,3] 中选择,以避免学习特定曝光度和 ground truth 度之间的映射)和对比,输入的图像与原始图像之间发生了破坏,并对可见细节曝光过/过少进行了对比。
[45] J. Xiao, K. Ehinger, A. Oliva, and A. Torralba. Recognizing scene viewpoint using panoramic place representation. In IEEE Conference on Computer Vision and Pattern Recognition, 2012.
[51] J. Zhang and J.-F. Lalonde. Learning high dynamic range from outdoor panoramas. In IEEE International Conference on Computer Vision, 2017.

Figure 4: Visual comparison on overexposed images in the bright scenes. The proposed DRHT method can effectively recover the missing details buried in the overexposed regions compared with state-of-the-art approaches.

Figure 5: Visual comparison on under/over exposed images in the dark scenes. The proposed DRHT method can effectively recover the missing details in the under/over exposed regions while maintaining the global illumination.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









