










MambaVision:
A Hybrid Mamba-Transformer Vision Backbone

Abstract
We propose a novel hybrid Mamba-Transformer backbone, denoted as MambaVision, which is specifically tailored for vision applications. Our core contribution includes redesigning the Mamba formulation to enhance its capability for efficient modeling of visual features. In addition, we conduct a comprehensive ablation study on the feasibility of integrating Vision Transformers (ViT) with Mamba. Our results demonstrate that equipping the Mamba architecture with several selfattention blocks at the final layers greatly improves the modeling capacity to capture long-range spatial dependencies. Based on our findings, we introduce a family of MambaVision models with a hierarchical architecture to meet various design criteria. For Image classification on ImageNet-1K dataset, MambaVision model variants achieve a new State-of-the-Art (SOTA) performance in terms of Top-1 accuracy and image throughput. In downstream tasks such as object detection, instance segmentation and semantic segmentation on MS COCO and ADE20K datasets, MambaVision outperforms comparably-sized backbones and demonstrates more favorable performance. Code: https://github.com/NVlabs/MambaVision.
本文提出了一种新颖的混合Mamba-Transformer骨干网络,命名为MambaVision,该网络专为视觉应用而设计。
本文的核心贡献包括重新设计Mamba公式,以增强其有效建模视觉特征的能力。
此外,本文还对将Vision Transformers(ViT)与Mamba集成的可行性进行了全面的消融研究。研究结果表明,在最终层为Mamba架构配备多个自注意力块可以极大地提高其建模能力,以捕获长距离空间依赖性。
基于上述的发现,本文引入了一系列具有层次结构的MambaVision模型,以满足各种设计标准。
在ImageNet-1K数据集上的图像分类任务中,MambaVision模型变体在Top-1准确率和图像吞吐量方面取得了新的最先进(SOTA)性能。在MS COCO和ADE20K数据集上的下游任务,如目标检测、实例分割和语义分割中,MambaVision的表现优于同等规模的骨干网络,并展示了更有利的性能。
动 机
Transformers在计算机视觉中的局限性
尽管Transformers在自然语言处理和其他领域中取得了巨大成功,但在计算机视觉任务中,其自注意力机制的二次复杂度(相对于序列长度)使得训练和部署成本高昂。因此,尽管Transformers的注意力机制在处理长距离依赖关系上表现优异,但在资源受限的环境中并不实用。
Mamba的优势与局限性
文章提到了Mamba(一种状态空间模型SSM)作为一种替代方案,其实现了线性时间复杂度并在语言建模任务中表现出色。然而,传统的Mamba模型(尤其是其自回归特性)在视觉任务中面临挑战:
缺乏全局上下文:自回归模型(如Mamba)需要逐步处理数据,这限制了它们在一次前向传递中捕获和利用全局上下文的能力。视觉任务通常需要理解全局上下文以做出准确预测。
空间数据处理的低效性:图像像素之间的依赖性是局部的,而Mamba的逐步处理方式对于处理这种并行和集成的空间数据来说是不高效的。
现有解决方案的不足
文章还指出了现有基于Mamba的视觉骨干模型(如Vision Mamba和EfficientVMamba)的不足之处:
双向SSM的延迟:尽管双向SSM能够捕获更多全局上下文,但处理整个序列后才进行预测的方式增加了延迟。
复杂性和过拟合风险:增加的复杂性可能导致训练难度增加和过拟合风险。
性能限制:尽管进行了修改,但最佳Mamba-based视觉模型在某些视觉任务上的表现仍不及Vision Transformer(ViT)和卷积神经网络(CNN)模型。
4. 提出MambaVision的必要性
基于上述分析,文章提出MambaVision作为一种混合架构,旨在结合Mamba和Transformers的优势,克服各自的局限性:
提升全局上下文捕获能力:通过在最后阶段集成Transformer块,显著增强了模型捕获全局上下文和长距离空间依赖的能力。
提升图像吞吐量:混合架构在保持高效特征建模的同时,提高了图像处理的吞吐量。
更适合视觉任务:通过重新设计Mamba块和集成Transformer块,使模型更适合处理视觉数据。
这些动机共同驱动了MambaVision模型的设计和开发,以应对现有模型在处理视觉数据时的局限性。
方法
方法概述
文章的主要贡献在于重新设计了Mamba模块以更好地适应视觉任务,并通过引入Transformer块来增强模型的全局上下文和长距离空间依赖性的捕捉能力。最终,提出了一个包含多个分辨率层次的MambaVision模型家族。
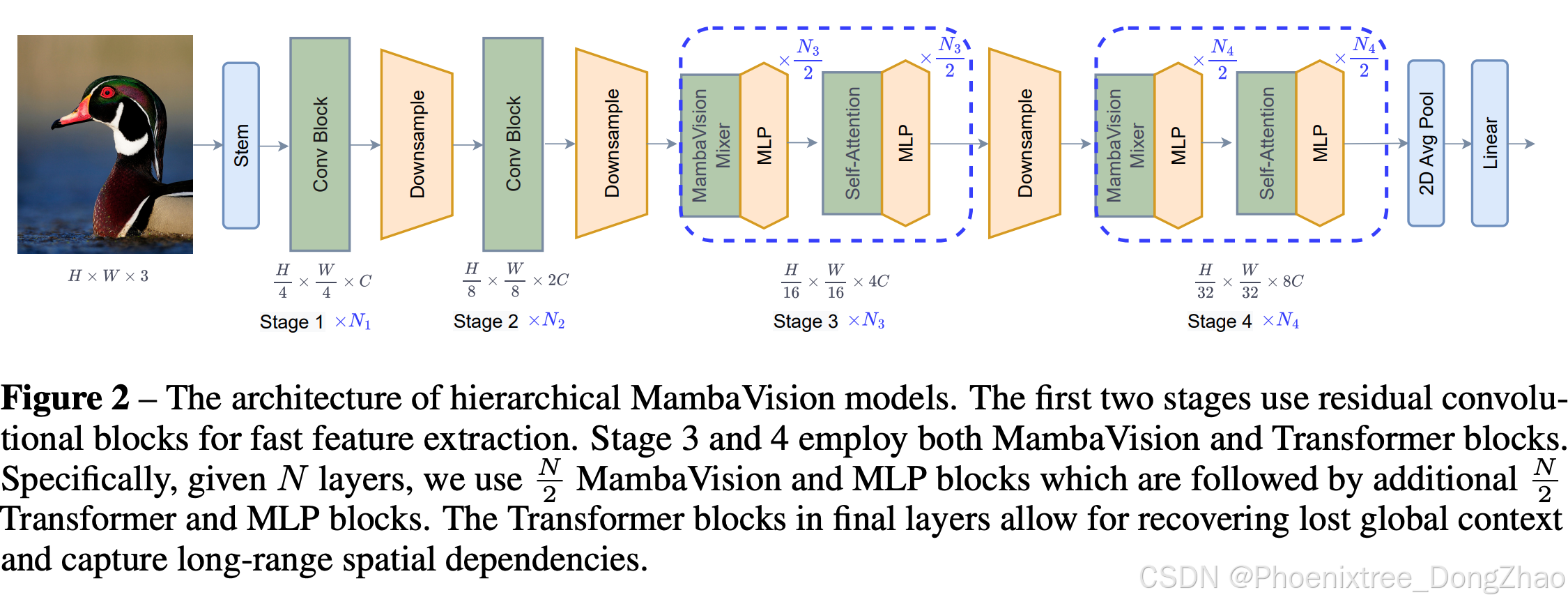
宏观架构(Macro Architecture)
MambaVision模型采用了一种分层架构,包含四个不同的阶段,如图2所示:
阶段1和阶段2:使用基于CNN的层在较高的输入分辨率下快速提取特征。
阶段3和阶段4:结合MambaVision块和Transformer块,用于进一步的特征提取和全局上下文的捕捉。
在每个阶段之间,使用降采样层(由批量归一化的3x3 CNN层组成,步长为2)来减少图像分辨率。
微观架构(Micro Architecture)
1 Mamba基础
Mamba是结构化状态空间序列模型(S4)的扩展,通过可学习的隐藏状态h(t)将一维连续输入x(t)转换为输出y(t)。离散化后,使用零阶保持规则将连续参数转换为离散参数,并通过全局卷积计算输出。
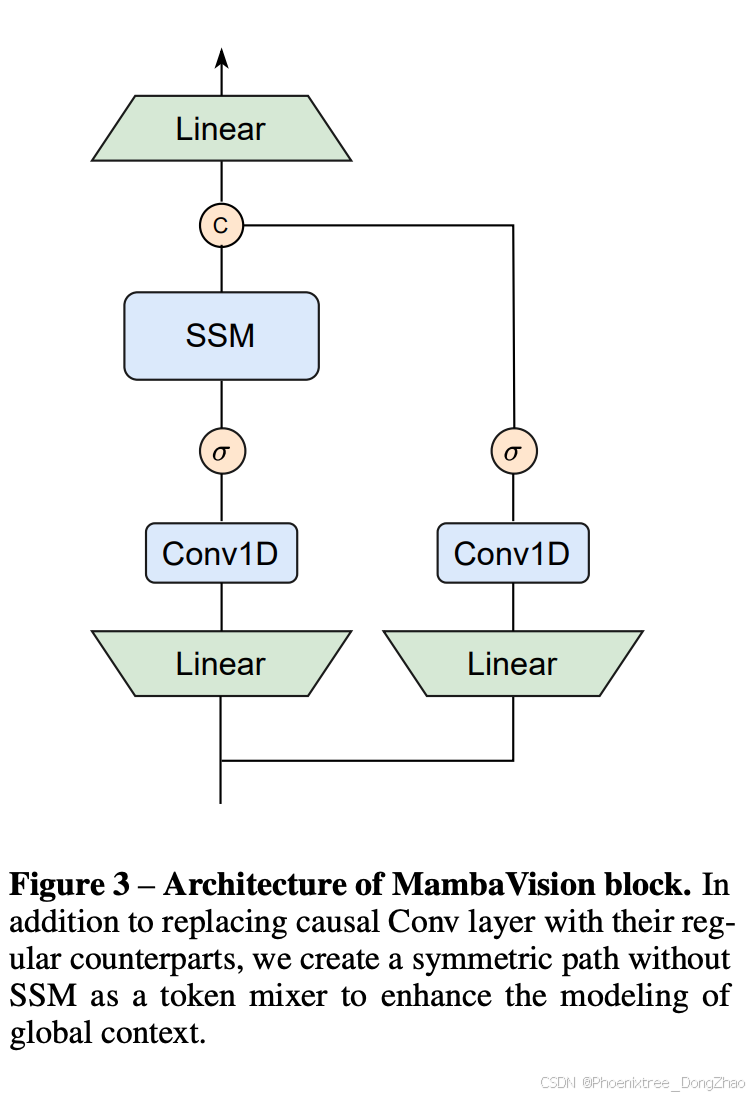
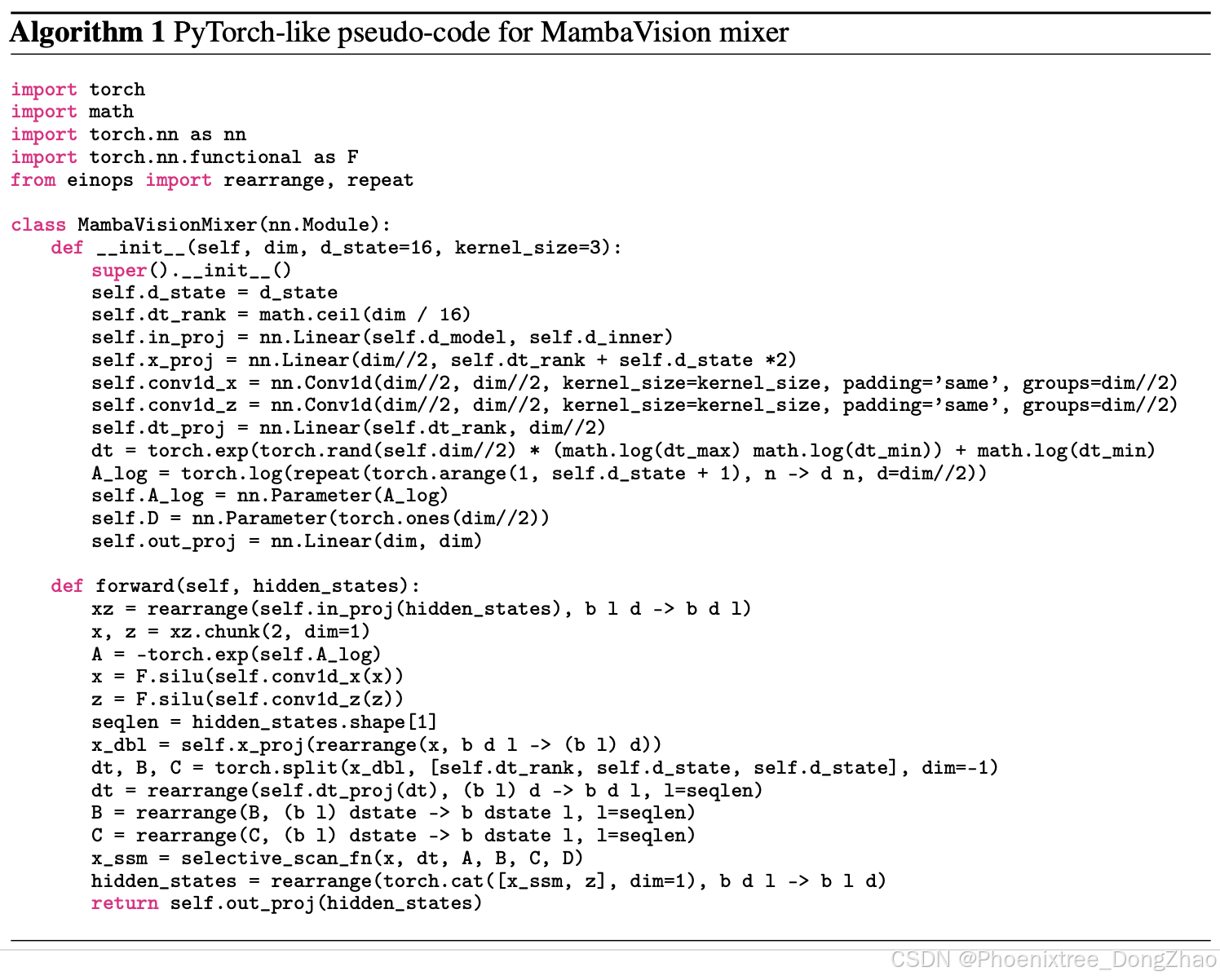
2 MambaVision块
MambaVision块在Mamba的基础上进行了重新设计,以适应视觉任务的需求。具体来说,做了以下改进:
移除因果卷积层:用常规的卷积层替换,以增强全局上下文的建模能力。
引入对称路径:在没有SSM的情况下创建一个对称路径作为token mixer,进一步提升全局建模能力。
图3展示了MambaVision块的架构,其中包含了线性层、SSM、1D卷积等组件。
3 Transformer块的集成
在MambaVision的最后阶段(阶段3和阶段4),引入了Transformer块来捕捉全局上下文和长距离空间依赖性。通过在不同的层次(如最后几层或每隔几层)添加Transformer块,并进行详尽的消融研究,确定了最佳集成模式。
实验
实验设置
数据集:
ImageNet-1K:用于图像分类任务,评估模型的Top-1准确率和图像吞吐量。
MS COCO 和 ADE20K:用于下游任务如目标检测、实例分割和语义分割,以验证模型在复杂视觉任务中的表现。
硬件:所有实验均在A100 GPU上进行,批量大小为128。
实验结果
1 图像分类(ImageNet-1K)
性能对比:
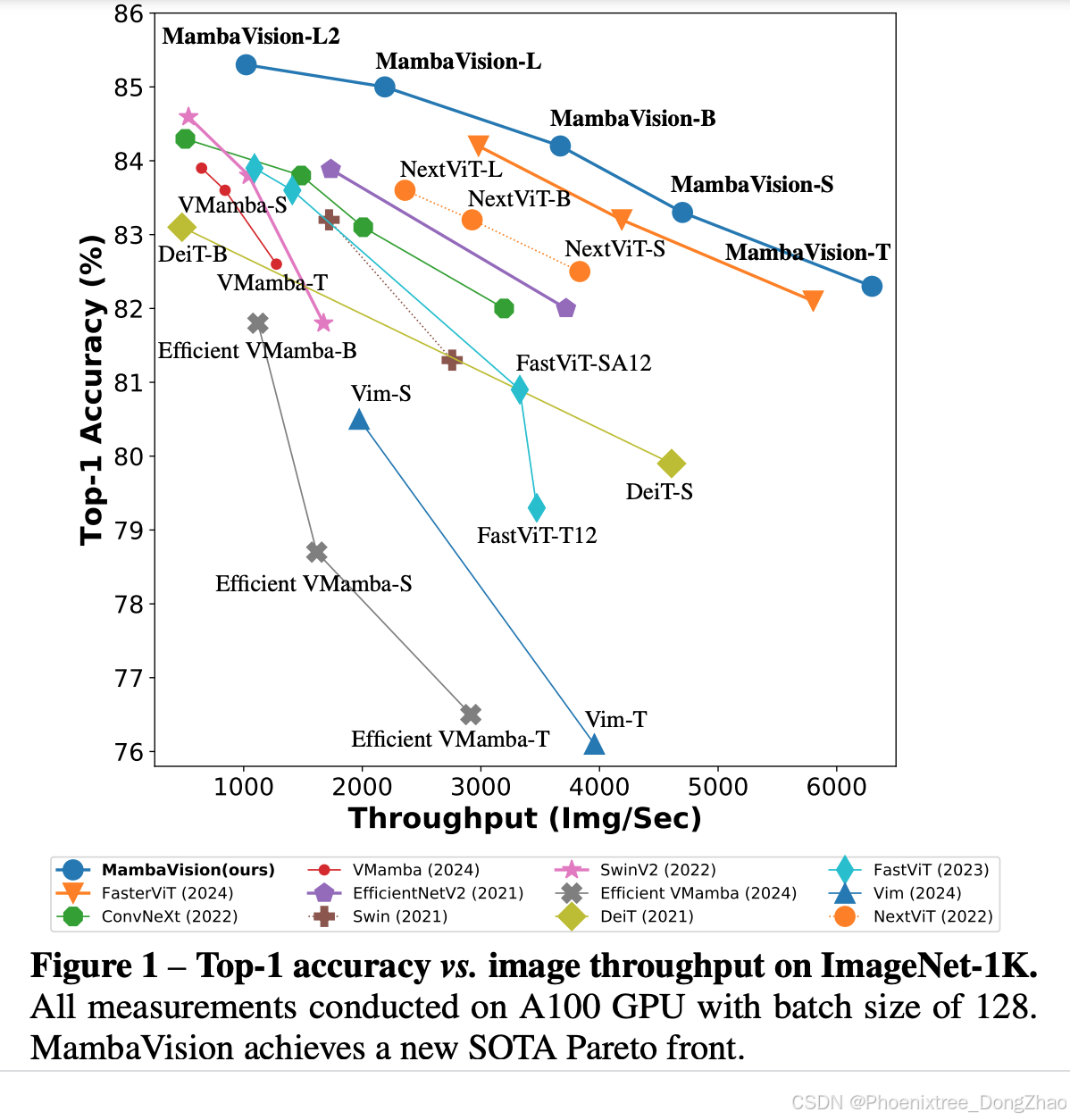
MambaVision模型在ImageNet-1K数据集上实现了新的SOTA(State-of-the-Art)性能,在Top-1准确率和图像吞吐量之间达到了新的Pareto前沿。
如图1所示,MambaVision模型(如MambaVision-T, MambaVision-S, MambaVision-B, MambaVision-L, MambaVision-L2)在准确率和吞吐量上均优于其他模型,包括FasterViT、ConvNeXt、VMamba、EfficientNetV2、Swin、SwinV2、Efficient VMamba、DeiT、FastViT和Vim等。
模型变体:
MambaVision模型家族包括不同大小的变体,以满足不同的设计需求。
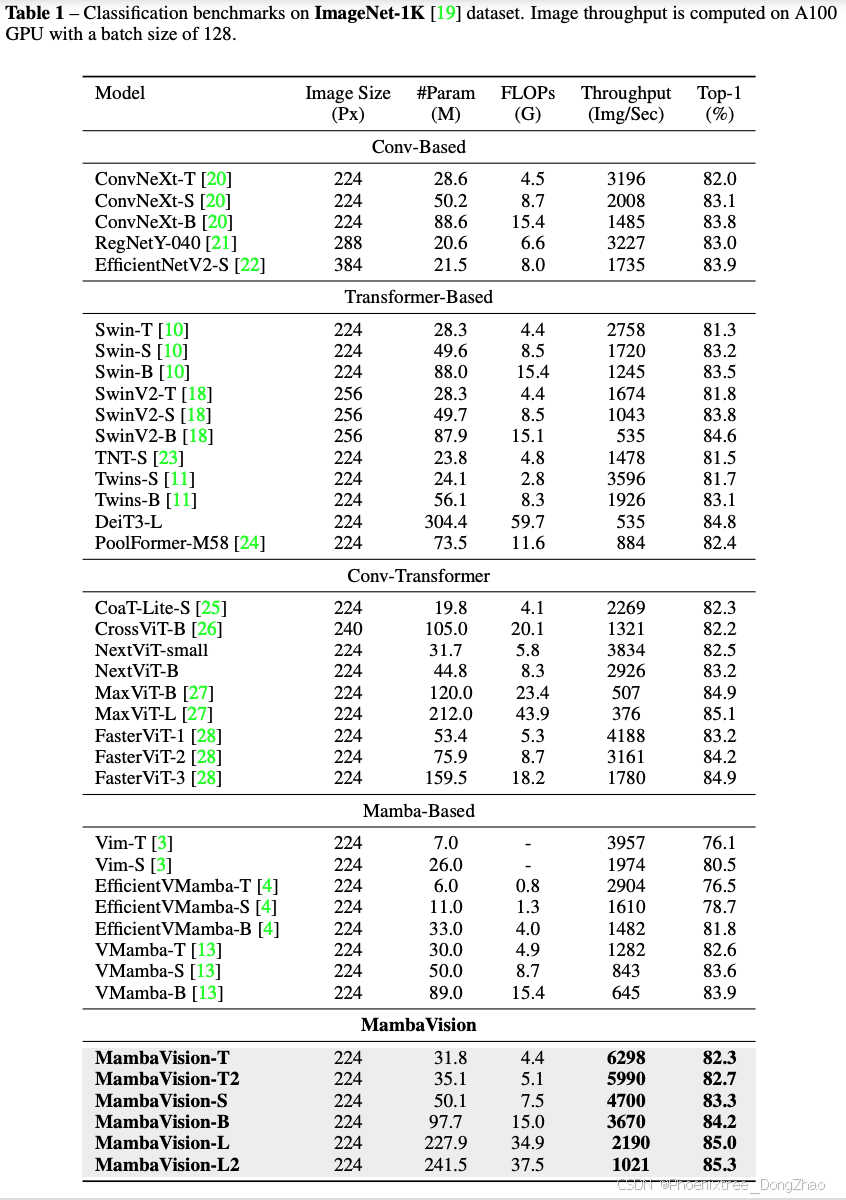
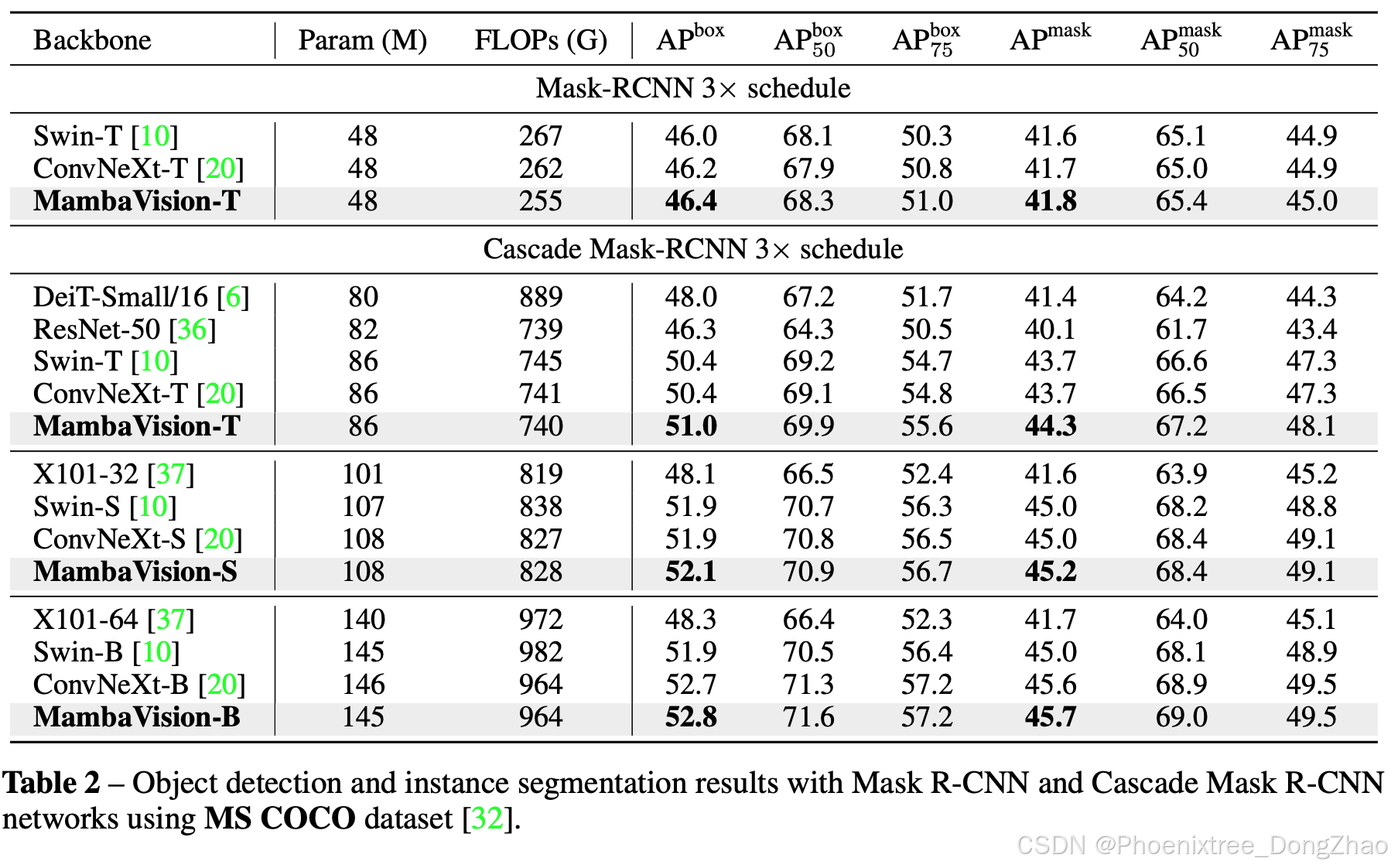
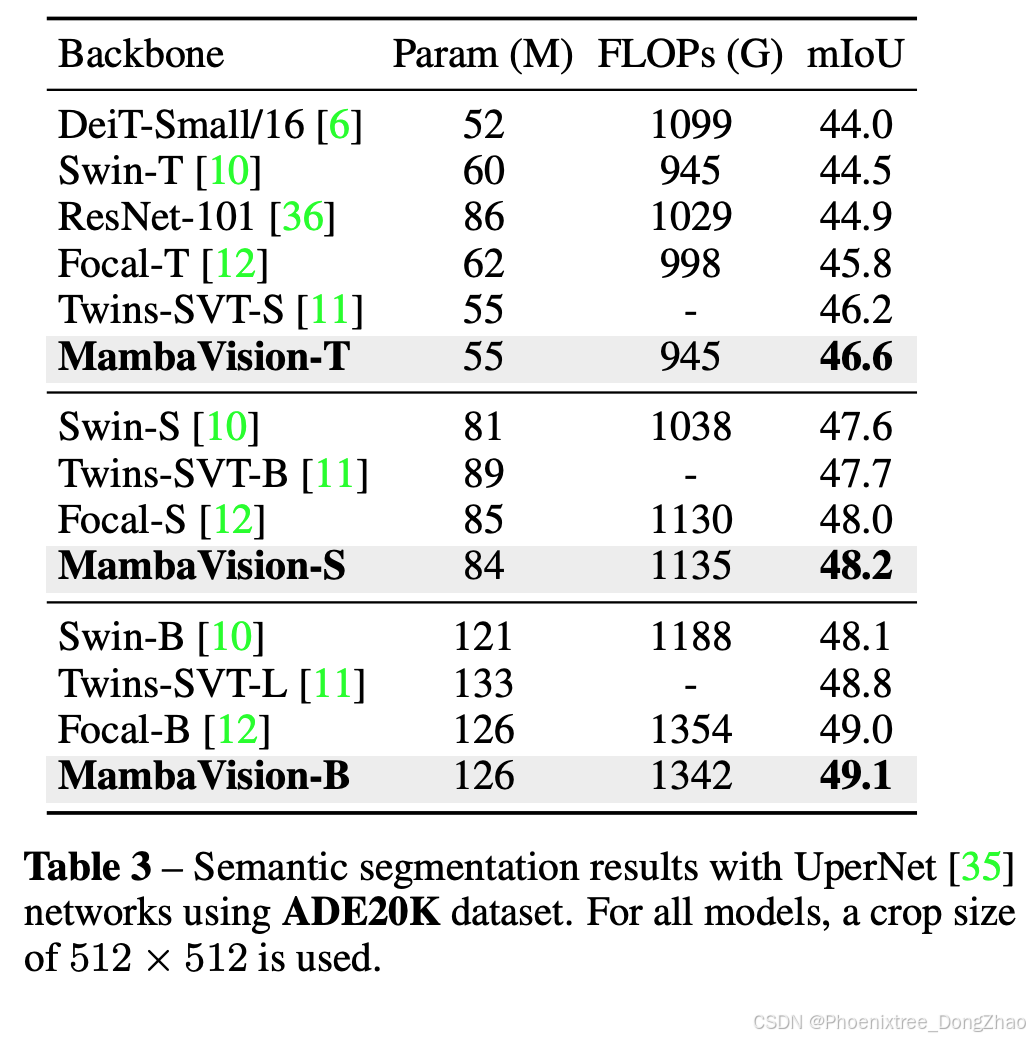
2 下游任务(MS COCO 和 ADE20K)
目标检测与实例分割:
在MS COCO数据集上,使用MambaVision作为骨干的模型在目标检测和实例分割任务中表现出色,优于同等大小的骨干模型。
语义分割:
在ADE20K数据集上,MambaVision同样展示了其在语义分割任务中的优势。
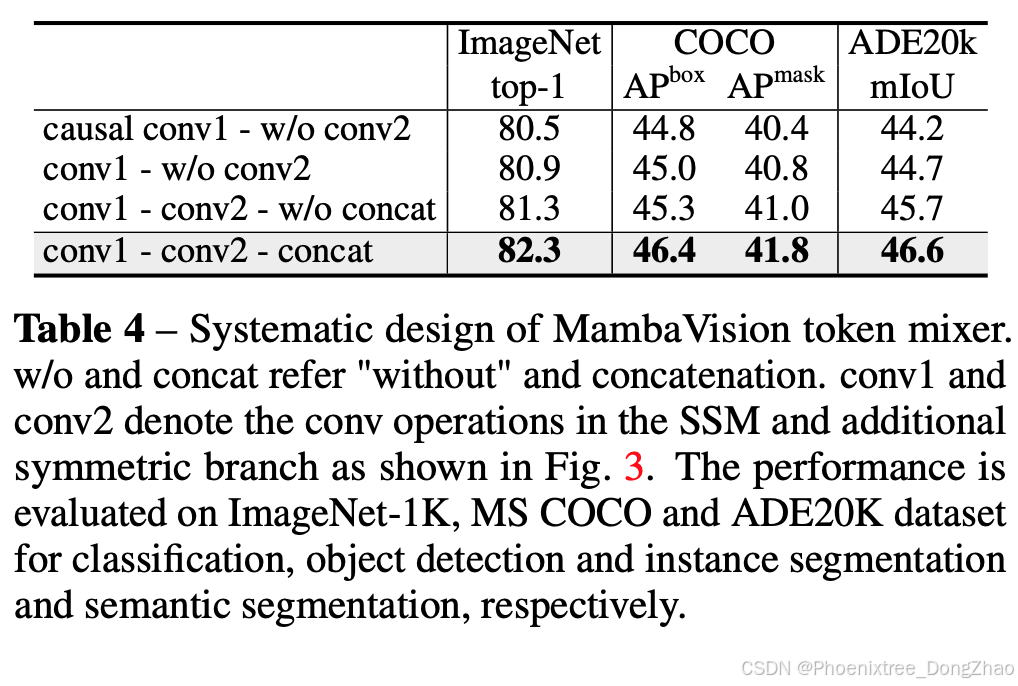
3. 消融研究
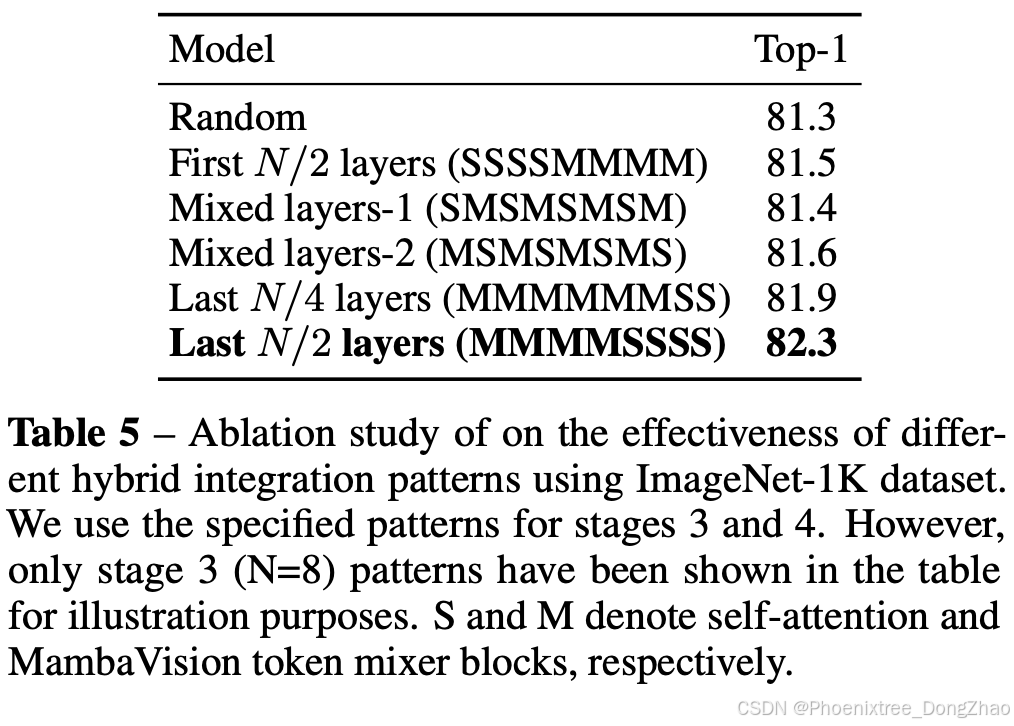
Mamba与Transformer的集成模式:
文章系统地研究了Mamba和Transformer块的集成模式,包括在早期、中期、最终层以及每隔l层添加Transformer块。
结果表明,在最终层添加几个自注意力块可以显著提高模型捕获全局上下文和长距离空间依赖的能力。
MambaVision Mixer的设计:
提出了MambaVision Mixer,通过替换因果卷积层为常规卷积层,并创建了一个没有SSM的对称路径作为令牌混合器,以增强全局上下文的建模。

















 50
50

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









