









Explainability for Vision Foundation Models: A Survey

Abstract
As artificial intelligence systems become increasingly integrated into daily life, the field of explainability has gained significant attention. This trend is particularly driven by the complexity of modern AI models and their decision-making processes. The advent of foundation models, characterized by their extensive generalization capabilities and emergent uses, has further complicated this landscape. Foundation models occupy an ambiguous position in the explainability domain: their complexity makes them inherently challenging to interpret, yet they are increasingly leveraged as tools to construct explainable models. In this survey, we explore the intersection of foundation models and eXplainable AI (XAI) in the vision domain. We begin by compiling a comprehensive corpus of papers that bridge these fields. Next, we categorize these works based on their architectural characteristics. We then discuss the challenges faced by current research in integrating XAI within foundation models. Furthermore, we review common evaluation methodologies for these combined approaches. Finally, we present key observations and insights from our survey, offering directions for future research in this rapidly evolving field.
随着人工智能系统日益融入日常生活,可解释性领域引起了广泛关注。这一趋势尤其受到现代AI模型的复杂性及其决策过程的驱动。基础模型的出现,以其广泛的泛化能力和新兴用途为特征,进一步复杂化了这一领域。基础模型在可解释性领域中占据了一个模棱两可的位置:其复杂性使其本质上难以解释,但它们越来越多地被用作构建可解释模型的工具。在本综述中,探讨了基础模型与可解释人工智能(XAI)在视觉领域的交叉点。首先汇编了连接这两个领域的综合文献集。接着,根据这些工作的架构特征对其进行分类。然后,讨论了当前研究在将XAI集成到基础模型中所面临的挑战。此外,回顾了这些组合方法的常见评估方法。最后,提出了本综述的关键观察和见解,并为这一快速发展领域的未来研究方向提供了建议。
1 Introduction
Deep Neural Networks (DNNs), i.e., networks with a large number of trainable parameters, have had a significant impact on computer vision in recent years [1]. They have achieved state-of-the-art performance in various tasks such as semantic segmentation [2], classification [3], and image generation [4]. However, the depth and complexity of DNNs also lead to a lack of transparency [5] in decision-making and in the interpretability of predictions [6]. There is an increasing demand for transparent DNN models in high-stakes environments where both performance and interpretability are crucial [7]. A wide range of approaches that add transparency and interpretability is broadly referred to as eXplainable Artificial Intelligence (XAI) [8] (see Figure 1).
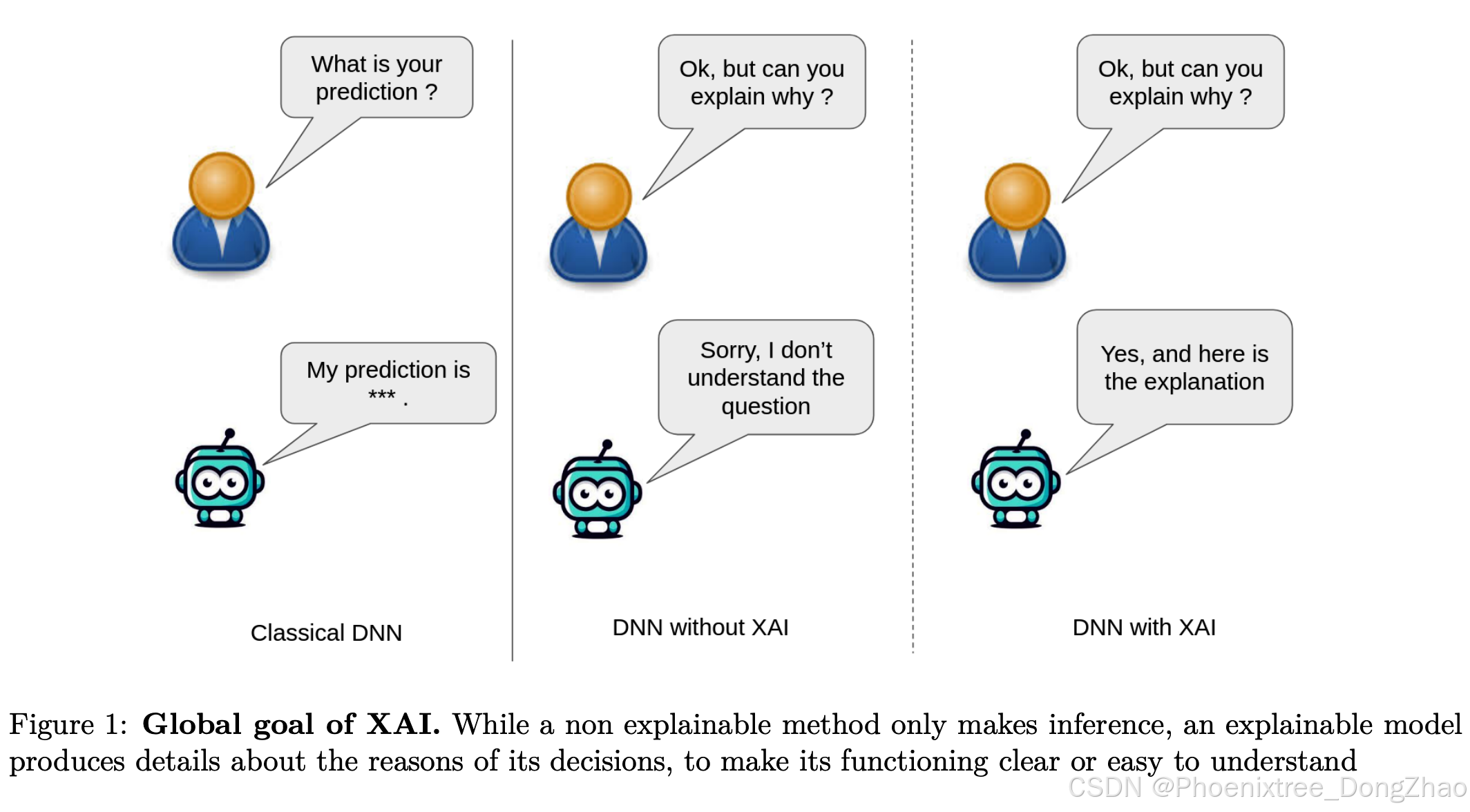
XAI methods provide a bridge between an automated system and human users, whose perceptions and interpretations are inherently subjective. An explanation that satisfies one user may not necessarily satisfy another [9], so to be effective, XAI methods should ensure consistency in the interpretations across different users [10]. XAI has garnered increasing interest, particularly in fields where ethical concerns are paramount, such as medical diagnosis [11] and autonomous driving [12], since opaque models may conceal functionalities that contradict moral principles. For instance, gender-biased outcomes have been observed in [13].
Several properties have been identified in the literature as essential for XAI [14, 6], such as trustworthiness, complexity, robustness, generalizability, and objectiveness. We explore this issue further in Section 4.1.
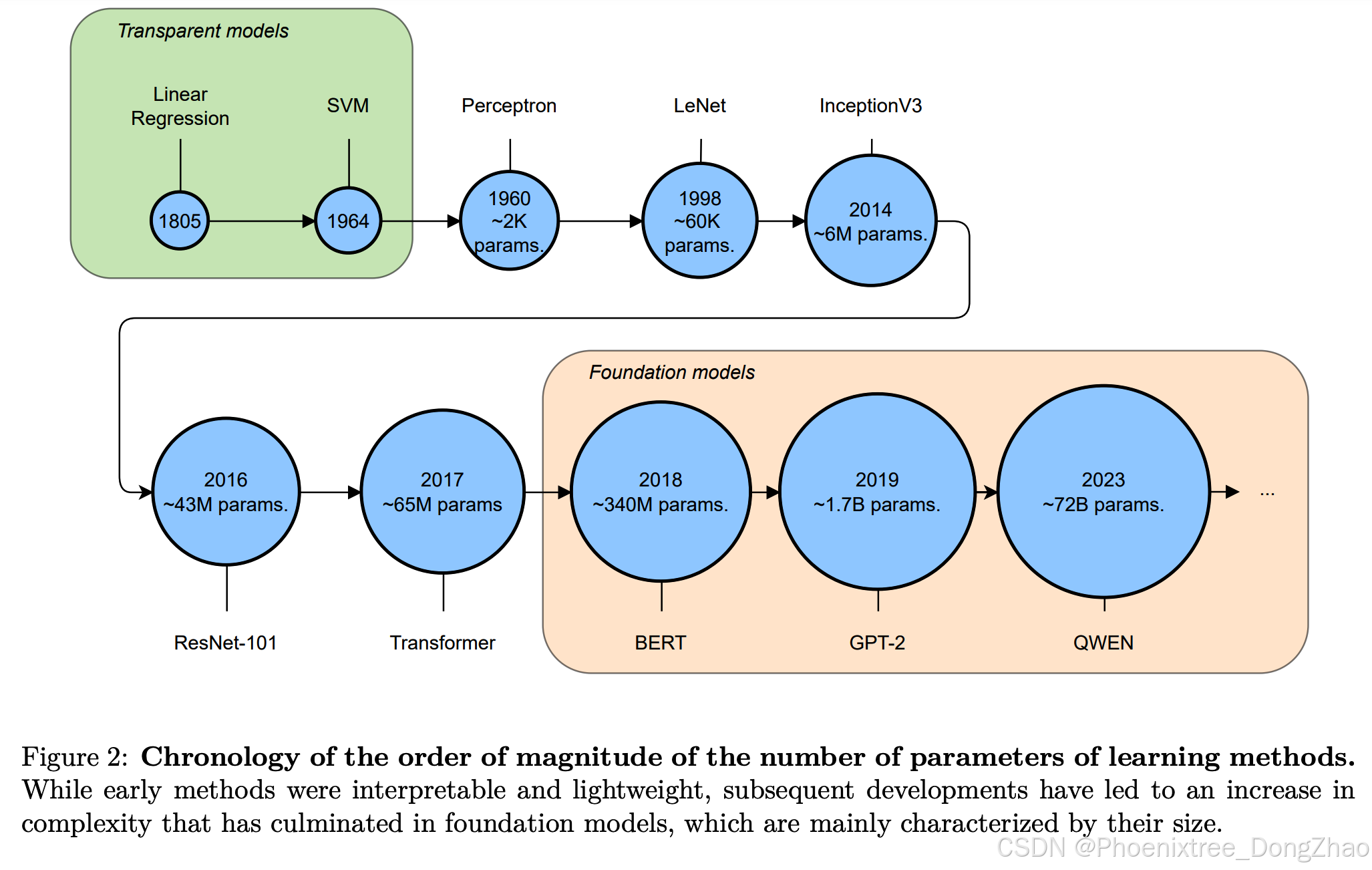
A noticeable trend in deep learning is the use of models that are larger and larger (see Figure 2). The trend began in computer vision with LeNet (60,000 parameters) in 1998, then InceptionV3 (6.23M parameters) in 2014, and Resnet (42.70M parameters) in 2016. Then, the field of natural language processing followed with Transformers (65M parameters) in 2017, then BERT (340M parameters) in 2018, then GPT-2 (1.5T parameters) in 2019, and then QWEN (72B parameters) in 2023. The success of these “large language models” has sparked interest in applying the benefits of high parameter counts and extensive training data to other domains, such as visual question answering [15] and object detection [16]. This has led to the broader classification of such architectures under the global term “foundation models.” Foundation models are in an ambiguous position in the XAI field. On the one hand, the complexity of foundation models makes them particularly difficult to explain. On the other hand, they become increasingly used in the literature as tools to build explainable models.
This survey provides a panorama of explainability techniques within the field of foundation models in computer vision, and more particularly pretrained foundation models (PFMs). It is structured as follows. Section 2 provides background on foundation models and XAI methods, takes stock of existing surveys, and proposes a taxonomy for XAI methods. Section 3 defines the identified classes of XAI methods and describes their background, their use of PFMs, their applications, and their evaluation. In Section 4, we discuss different methods used to evaluate the quality of produced explanations. Some observations from our survey are presented in Section 5. The different challenges faced by XAI methods are described in Section 6, including a description of problems that remain open. Finally, Section 7 presents our conclusions and potential avenues for further research.
深度神经网络(DNNs),即具有大量可训练参数的网络,近年来在计算机视觉领域产生了重大影响。它们在各种任务中实现了最先进的性能,例如语义分割、分类和图像生成。然而,DNN的深度和复杂性也导致了决策过程缺乏透明度以及预测的可解释性不足。在高风险环境中,对透明DNN模型的需求日益增加,因为在这些环境中,性能和可解释性都至关重要。一系列增加透明度和可解释性的方法被统称为可解释人工智能(XAI)(见图1)。
XAI方法在自动化系统与人类用户之间架起了一座桥梁,而人类用户的感知和解释本质上是主观的。满足一个用户的解释不一定能满足另一个用户,因此,为了有效,XAI方法应确保不同用户之间解释的一致性。XAI在伦理问题至关重要的领域,例如医学诊断和自动驾驶,引起了越来越多的关注,因为不透明的模型可能隐藏与道德原则相冲突的功能。例如,[13] 中观察到了性别偏见的结果。
文献中已确定了几种对XAI至关重要的属性,例如可信性、复杂性、鲁棒性、泛化能力和客观性。本文将在第4.1节中进一步探讨这一问题。
深度学习中的一个显著趋势是使用越来越大的模型(见图2)。这一趋势始于1998年计算机视觉领域的LeNet(60,000参数),随后是2014年的InceptionV3(6.23M参数)和2016年的Resnet(42.70M参数)。接着,自然语言处理领域在2017年推出了Transformers(65M参数),2018年推出了BERT(340M参数),2019年推出了GPT-2(1.5T参数),2023年推出了QWEN(72B参数)。这些“大语言模型”的成功激发了人们将高参数数量和广泛训练数据的优势应用于其他领域的兴趣,例如视觉问答和目标检测。这导致这些架构被更广泛地归类为“基础模型”。基础模型在XAI领域中处于模棱两可的位置:一方面,基础模型的复杂性使其特别难以解释;另一方面,它们在文献中越来越多地被用作构建可解释模型的工具。
本综述提供了计算机视觉领域基础模型中可解释性技术的全景,特别是预训练基础模型(PFMs)。其结构如下:第2节介绍了基础模型和XAI方法的背景,总结了现有综述,并提出了XAI方法的分类法。第3节定义了已识别的XAI方法类别,并描述了它们的背景、对PFMs的使用、应用及其评估。第4节讨论了用于评估生成解释质量的不同方法。第5节提出了本文综述中的一些观察结果。第6节描述了XAI方法面临的不同挑战,包括尚未解决的问题。最后,第7节提出了本文的结论和未来研究的潜在方向。
2 Background
In this section, we delineate the scope of our investigation through the definition of the main terminologies. Subsection 2.1 presents the range of vision foundation models, offering a comprehensive understanding of their fundamental aspects. Subsection 2.2 refers to the contextual background associated with XAI and its interrelation with interpretability. Subsection 2.3 points out similar surveys and how the present one differs from them. Lastly, Subsection 2.4 presents a spectrum of distinct strategies aimed at amalgamating foundation models with XAI methodologies.
在本节中,通过定义主要术语来明确研究范围。2.1 小节介绍了视觉基础模型的范围,对其基本方面进行了全面阐述。2.2 小节涉及与可解释人工智能(XAI)相关的背景及其与可解释性的相互关系。2.3 小节指出了类似的综述以及本综述与它们的不同之处。最后,2.4 小节展示了将基础模型与 XAI 方法相结合的各种策略。
2.1. Foundation models
According to [17], a foundation model is defined as “any model trained on broad data that can be adapted to a wide range of downstream tasks.” The significance of foundation models lies in their demonstrated ability to generalize across diverse tasks, leading to their emergent utilization in various applications. While there is widespread consensus to label deep learning models like GPT [18] or CLIP [19] as foundation models, a significant debate persists regarding the delineation between foundation models and other DNNs models [20]. The definition pivots on the notion of extensive datasets and a high volume of data, a criterion that remains subjective and open to interpretation.
While the concept of foundation model is relatively recent, the use of large pretrained models to enhance performance predates their emergence. Ancestral to foundation models, the widely employed feature representation backbones, such as VGG [21], ResNet [22], and ViT [23] pretrained on ImageNet [24], paved the way of modern computer vision with DNNs. These pretrained feature representation backbones were used as an initialization for other vision tasks [25]. Indeed, it has been observed that incorporating such techniques facilitates faster convergence, particularly in scenarios with limited training data [26]. Another emphasis of foundation models is the prevalent use of self-supervised techniques to benefit from the widest corpus of data.
2.1 基础模型
根据 [17],基础模型被定义为“在广泛数据上训练的任何模型,可以适应各种下游任务。”基础模型的重要性在于其跨任务泛化能力,这使其在各种应用中得到了新兴的利用。虽然人们普遍认为像GPT或 CLIP这样的深度学习模型是基础模型,但关于基础模型与其他DNN模型之间的界限,仍然存在重大争议。这一定义依赖于广泛数据集和大量数据的概念,这是一个主观且开放解释的标准。
尽管基础模型的概念相对较新,但使用大型预训练模型来提高性能的做法早于其出现。作为基础模型的先驱,广泛使用的特征表示骨干网络,例如在ImageNet上预训练的VGG、ResNet和 ViT,为现代计算机视觉中的DNN铺平了道路。这些预训练的特征表示骨干网络被用作其他视觉任务的初始化。事实上,已经观察到,在训练数据有限的情况下,采用这些技术可以加速收敛。基础模型的另一个重点是自监督技术的广泛应用,以从最广泛的数据集中受益。
The initial models recognized as foundation models emerged from the domain of large language models based on transformers [27], such as GPT-2 [28] and BERT [29]. Their designation as such stemmed from the fact that these large language models exhibit remarkable generalization performances, coupled with their exploitation of extensive text datasets. This success has subsequently led to various emerging applications [30, 31].
The success observed in large language models encouraged a shift towards scaling models in other domains, notably in computer vision [15, 32], where substantial volumes of data are readily accessible. Moreover, the widespread adoption of transformers in vision tasks aligns with the structural foundation laid by language models. Consequently, this evolution has led to a new wave of models. Notably, language/vision models, capable of processing textual and visual inputs and projecting them into a shared embedding space. A prominent example of this category is CLIP [19], known for its ability to represent text and language modalities within a unified framework. Also, text-conditioned diffusion models, capable of generating high-quality images across a diverse spectrum of tasks like stable diffusion [33]. These models demonstrate proficiency in creating images through conditioning on extensive textual information, marking a significant advancement within the domain.
最初被认可为基础模型的模型源于基于Transformer的大语言模型领域,例如GPT-2 和 BERT。它们被如此命名的原因在于,这些大语言模型展示了卓越的泛化性能,并且利用了大量的文本数据集。这一成功随后催生了各种新兴应用。
大语言模型的成功鼓励了在其他领域扩展模型的趋势,特别是在计算机视觉领域,因为那里有大量数据可用。此外,Transformer在视觉任务中的广泛应用与语言模型奠定的结构基础相契合。因此,这一演变催生了新一代模型。值得注意的是,语言/视觉模型能够处理文本和视觉输入,并将它们投影到一个共享的嵌入空间。这一类别的一个突出例子是CLIP,它能够在一个统一的框架内表示文本和语言模态。此外,文本条件扩散模型能够生成高质量图像,例如Stable Diffusion,展示了其在通过广泛文本信息生成图像方面的能力,标志着该领域的重大进展。
After the success achieved by leveraging diverse modalities and driven by the aspiration to craft increasingly versatile agents, a new wave of foundation models has emerged. These models endeavor to incorporate an expanding array of modalities, exemplified by innovations like IMAGEBIND [34] and GATO [35]. These advanced foundation models not only process text and images but also integrate additional elements such as sound or action data, enriching their capacity to comprehend varied inputs across multiple modalities. Furthermore, the scaling-up trend has extended beyond conventional data sources, embracing more challenging and intricate datasets. For instance, there has been a notable trend towards scaling up models to handle more diverse tasks. A widely explored task in this context is visual question answering, which leverages the capabilities of large language models by incorporating visual tokens. For instance, LLaVa [15] extends the LLaMa architecture [36] to handle visual data, BLIP [32] adapts BERT [29] for image-based tasks. Another rapidly growing area is zero-shot object detection and segmentation, exemplified by recent models such as SAM [37], SAM2 [38], and Grounding DINO [16]. Finally, the trend to scale up models has progressed, as shown by the examples of GPT-4 [39] or Pixtral [40].
在通过利用多种模态取得成功并渴望开发更通用的智能体之后,新一代基础模型应运而生。这些模型致力于整合越来越多的模态,例如IMAGEBIND和 GATO。这些高级基础模型不仅处理文本和图像,还整合了声音或动作数据等额外元素,增强了其理解多种模态输入的能力。此外,扩展模型的趋势已经超越了传统数据源,开始处理更具挑战性和复杂性的数据集。例如,在视觉问答任务中,通过结合视觉标记,利用了大语言模型的能力。例如,LLaVa扩展了 LLaMa架构 以处理视觉数据,BLIP 将 BERT 适配于基于图像的任务。另一个快速发展的领域是零样本目标检测和分割,例如最近的模型SAM、SAM2 和 Grounding DINO。最后,扩展模型的趋势仍在继续,例如 GPT-4 或 Pixtral 的出现。
These models are commonly used in a pretrained modality, where their weights remain fixed, hence the term Pretrained Foundation Models (PFMs). Subsequently, there are two primary approaches to their utilization. First, these models can be fine-tuned by training a lightweight probe on top of them (or on top of their intermediate feature embeddings). Another technique is to use a low rank adaptator to fine tune the PFM [41]. Alternatively, they can be employed end-to-end to execute specific tasks, facilitated by conditioning techniques such as prompt engineering. For a more visual representation, a comprehensive non exhaustive summary of these models is depicted in Table 1.
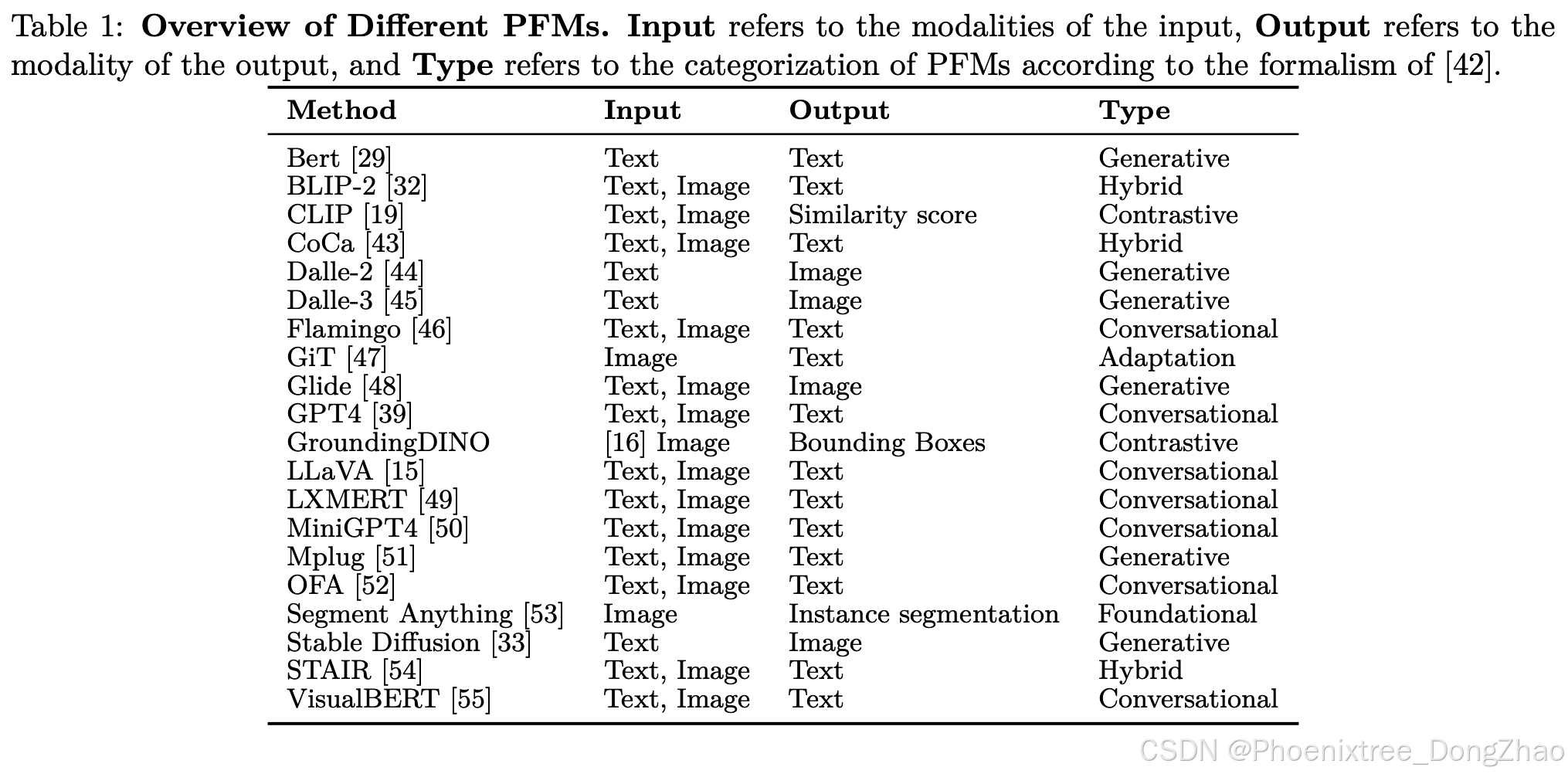
We delineate the scope of our investigation from the range of existing PFMs as follows:
• we include methods using vision PFMs: these models are characterized by their handling of the vision modality, including images or videos, either as input or output modalities;
• we exclude backbones pretrained exclusively on ImageNet due to the ambiguity surrounding their classification as PFMs.
这些模型通常以预训练模态使用,其权重保持不变,因此被称为预训练基础模型(PFMs)。随后,有两种主要的利用方式:首先,可以通过在其上(或在其中间特征嵌入上)训练一个轻量级探针来微调这些模型。另一种技术是使用低秩适配器来微调PFM。或者,它们可以通过提示工程等条件技术,以端到端的方式执行特定任务。为了更直观地展示,表1中提供了这些模型的非详尽总结。
通过以下方式界定研究的范围,与现有的预训练基础模型(PFMs)区分开来:
- 包括使用视觉PFMs的方法:这些模型的特点是对视觉模态的处理,包括图像或视频,无论是作为输入还是输出模态。
- 排除了仅在ImageNet上预训练的骨干网络,因为它们在分类为PFMs时存在模糊性。
2.2. Explainable AI (XAI)
According to [6], we can define an explainable model as a computational model that is designed to provide specific details or reasons regarding its functioning, to ensure clarity and ease of understanding. In broader terms, an explanation denotes the information or output that an explainable model delivers to elucidate its operational processes.
In the literature, as notably highlighted in [56, 57], there exists a nebulous distinction between the terminologies “interpretability” and “explainability”. In some instances, these terms are used interchangeably, further complicating their differentiation. To ensure coherence and eliminate ambiguity, we choose to use the terms explainable and interpretable synonymously.
From a historical perspective, the primary explainability methods for early AI algorithms involved employing transparent models. Such models are characterized by their simplicity, which allows their decision process to serve as an explanation in itself. These models are easily interpretable due to their straightforward nature and clear features. Examples of such models include linear regression [58], logistic regression [59], and decision trees [60]. For instance, an explanation generated by a decision tree consists of a series of logical assertions that lead to the selection of a specific leaf node, narrowing the gap with neural symbolic AI [61]. However, as noted by previous research, the explainability potential of these methods is contingent upon the complexity of their construction: if the number of parameters becomes too large, transparency is compromised.
2.2 可解释人工智能(XAI)
根据 [6],可以将可解释模型定义为一种计算模型,旨在提供关于其功能的具体细节或原因,以确保清晰性和易于理解。广义上讲,解释是指可解释模型为阐明其操作过程而提供的信息或输出。
在文献中,如 [56, 57] 所强调的,“可解释性”和“可解释性”这两个术语之间存在模糊的区分。在某些情况下,这些术语被互换使用,进一步增加了区分的复杂性。为了确保一致性和消除歧义,本文选择将可解释和可解释性视为同义词。
从历史角度来看,早期AI算法的主要可解释性方法是使用透明模型。这些模型的特点是简单性,其决策过程本身就可以作为解释。由于它们的直接性和清晰特征,这些模型很容易被解释。例如,线性回归、逻辑回归和决策树都属于此类模型。例如,决策树生成的解释由一系列逻辑断言组成,这些断言导致选择特定的叶节点,缩小了与神经符号AI的差距。然而,正如先前研究指出的,这些方法的可解释性潜力取决于其构建的复杂性:如果参数数量过多,透明度就会受到损害。
In particular, the pursuit of performance, as evidenced by the competition to achieve the highest ImageNet top-1 accuracy, has led to the development of models with increasingly large numbers of parameters. Consequently, state-of-the-art methods have gained a reputation for being opaque, as their inner workings are often incomprehensible to humans. In response to this challenge, additional techniques known as post-hoc methods have emerged [62, 63, 64]. These methods are applied to the model after the training process to provide explanations. Commonly used post-hoc methods include different approaches such as visualization techniques [63], which highlight influential parts in an image that contribute most to the model’s decision-making. Sensitivity analysis [65] represents another approach, based on the analysis of the variations of the model’s predictions when the input data change. Local explanation techniques, such as LIME [62], aim to explain the model’s predictions by creating a local, simplified model around a point of interest, which is transparent. Finally, feature relevance techniques, such as SHAP [66], estimate the impact of each feature on the model’s decision.
特别是,追求性能的竞争,例如在ImageNet top-1准确率上的竞争,导致了参数数量不断增加的模型的发展。因此,最先进的方法被认为是不透明的,因为它们的内部运作通常对人类来说是难以理解的。为了应对这一挑战,出现了称为事后解释方法的额外技术。这些方法在训练过程后应用于模型,以提供解释。常用的事后解释方法包括可视化技术,它突出显示图像中对模型决策最有影响的部分。敏感性分析是另一种方法,基于对输入数据变化时模型预测变化的分析。局部解释技术,例如 LIME,旨在通过在兴趣点周围创建局部简化模型来解释模型的预测,这种模型是透明的。最后,特征相关性技术,例如 SHAP,估计每个特征对模型决策的影响。
In opposition to post-hoc ones, ante-hoc methods produce explanations by design [42]. With the growing availability of models capable of performing auxiliary tasks and architectures structured as a sequence of subtasks, there has been a shift towards what [67] describes as “inherently explainable models.” These models, while not inherently transparent, incorporate interpretable components that facilitate human understanding. It is noteworthy that inherently explainable models are not transparent in nature. Instead, they achieve interpretability through the incorporation of interpretable components, in a way that makes their functioning understandable by humans. A typical example of such models is those based on Chains of Thought reasoning (see Section 3.1.3). These models, while being complex and opaque, are considered interpretable because they provide textual hints in addition to their output, helping to understand their functioning. Another example is Concept Bottleneck Models (Section 3.1.1), which, while not inherently transparent, are designed to describe inputs using semantically interpretable concepts. Similarly, Prototypical Networks (Section 3.1.4) learn semantically meaningful prototypes during training, providing an additional layer of interpretability. These families of models allow for the integration of various interpretability tools. For instance, logical reasoning can be incorporated into Concept Bottleneck Models to process and analyze concepts or used to establish relationships between components in chain-of-thought-based models.
与事后解释方法相对的是事前解释方法,这些方法在设计时就生成解释。随着能够执行辅助任务的模型和结构化子任务架构的日益普及,出现了一种向 [67] 所描述的“固有可解释模型”的转变。这些模型虽然本质上并不透明,但通过整合可解释组件,使其功能对人类来说更容易理解。值得注意的是,固有可解释模型本质上并不透明,而是通过整合可解释组件来实现可解释性,使其功能对人类来说更易理解。这类模型的一个典型例子是基于思维链推理的模型(见第3.1.3节)。这些模型虽然复杂且不透明,但由于它们在输出之外还提供了文本提示,帮助理解其功能,因此被认为是可解释的。另一个例子是概念瓶颈模型(第3.1.1节),它们虽然本质上并不透明,但旨在使用语义可解释的概念来描述输入。类似地,原型网络(第3.1.4节)在训练过程中学习语义上有意义的原型,提供了额外的可解释性。这些模型家族允许整合各种可解释性工具。例如,可以将逻辑推理整合到概念瓶颈模型中以处理和分析概念,或用于在基于思维链的模型中建立组件之间的关系。
We delineate the scope of our study from the spectrum of available XAI methods as follows:
• Our focus is solely on XAI methods used in conjunction with vision PFMs. This encompasses the corpus of available PFMs, as constrained by the scope defined in Section 2.1.
• We examine papers focusing on either “interpretable” or “explainable” artificial intelligence, without differentiation.
It is important to note that transparent methods are absent from our study by design, as the presence of PFMs inherently leads to opaque models. Then, our study is categorized into (1) PFMs to facilitate XAI methods, whether as post-hoc methods or inherently explainable models (see Section 3), and (2) papers tackling issues and challenges about explaining PFMs (see Section 6). For further insights about transparent models, we redirect the reader to the survey of [6].
本文通过以下方式界定研究的范围,与现有的XAI方法区分开来:
- 本文的研究重点是与视觉PFMs结合使用的XAI方法。这包括在2.1节定义的范围内可用的PFMs。
- 本文研究关注“可解释”或“可解释性”人工智能的论文,不作区分。
需要注意的是,透明方法在本文的研究中是故意排除的,因为PFMs的存在本质上导致模型不透明。因此,本文的研究分为两类:(1)PFMs用于促进XAI方法,无论是作为事后解释方法还是固有可解释模型(见第3节),以及(2)解决解释PFMs问题的论文(见第6节)。关于透明模型的更多见解,本文建议读者参考 [6] 的综述。
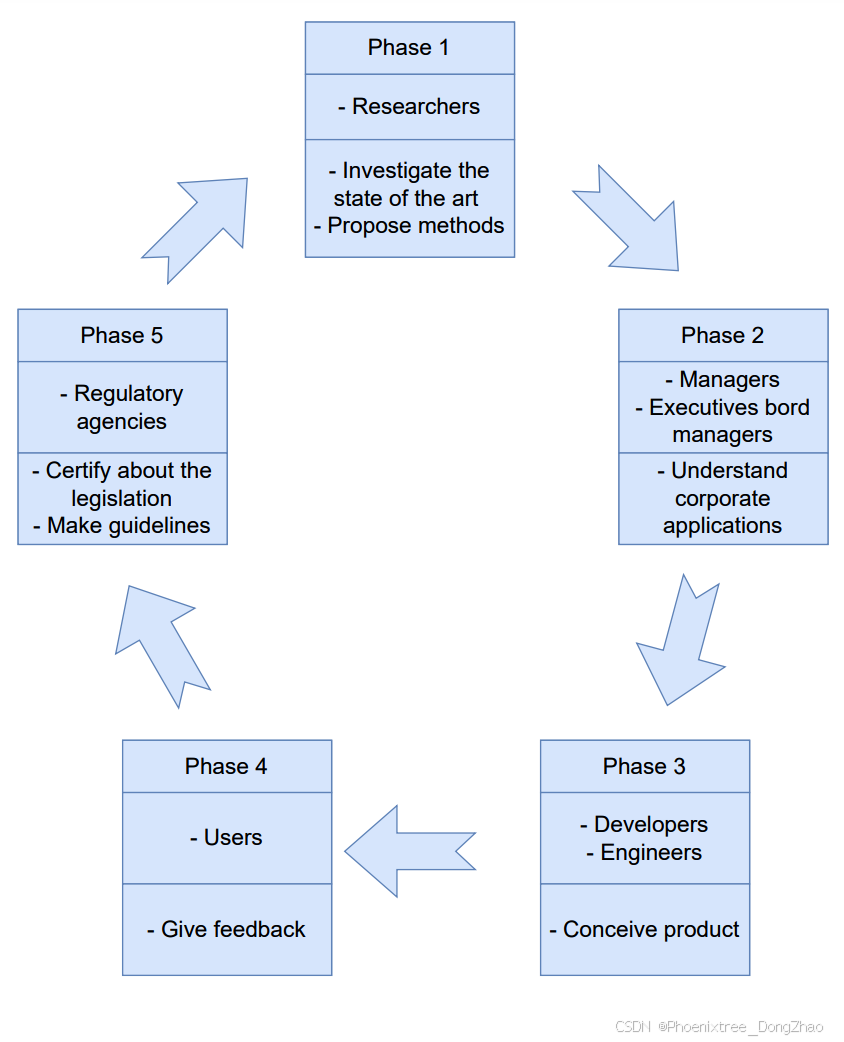
Figure 3: Chain representing the acceptance of AI in society. Each box presents the involved audience (middle) and the description of the step (bottom).
2.3. Existing surveys
The burgeoning need for feedback on AI models has resulted in a substantial surge in publications in the domain of XAI. This escalation is highlighted by the emergence of meta-surveys and comprehensive analyses, reflecting the growing landscape of research in this area [68, 69]. Numerous prior studies have delved into subjects closely aligned with our investigations. For instance, [70] focuses specifically on elucidating explainability within multimodal contexts, while [56] centers on the explainability of large language models. Additionally, [42] addresses related taxonomies, underscoring the breadth and depth of prior research relevant to our study. Compared to existing works, our survey emphasizes on the recent use of vision PFMs in XAI.
2.3 现有综述
对AI模型反馈的需求激增,导致XAI领域的出版物大幅增加。这一趋势通过元综述和综合分析的出现得到了体现,反映了该领域研究的日益增长。许多先前的研究深入探讨了与本文的调查密切相关的话题。例如,[70] 特别关注多模态背景下的可解释性,而 [56] 则集中在大语言模型的可解释性上。此外,[42] 讨论了相关的分类法,强调了与本文研究相关的先前研究的广度和深度。与现有工作相比,本文的综述强调了视觉PFMs在XAI中的近期应用。
2.4. Corpus
Methodology.
To gain a comprehensive understanding of how PFMs are utilized in XAI methods, we began by assembling a corpus of relevant papers. This corpus comprises 122 studies, including 76 on inherently explainable models (Section 3.1), 20 on post-hoc methods (Section 3.2), and 26 papers addressing enhancing the explainability of PFMs (Section 6). All the selected papers were published until January 2025.
2.4 文献集
方法论
为了全面了解PFMs在XAI方法中的应用,本文首先汇编了相关论文的文献集。该文献集包括122项研究,其中76项关于固有可解释模型(第3.1节),20项关于事后解释方法(第3.2节),以及26项关于增强PFMs可解释性的论文(第6节)。所有选定的论文均发表于2025年1月之前。
Taxonomy.
In prior studies, the need for adaptable organizational frameworks in the large field of XAI has led to the introduction of various taxonomies. As presented in [42], which extensively examines diverse taxonomies across surveys, prevalent approaches encompass stages, types of results, functioning approaches, output formats of explanations, and scope.
Drawing upon the definitions provided in [42], we separate each of the methods of our corpus. The resulting taxonomy is presented in Figure 4 and 13, as well as Tables 2 and 3. A detailed characterization and discussion of each of the identified categories is provided in the next section.
分类法
在先前的研究中,由于XAI领域庞大,需要适应性强的组织框架,因此引入了各种分类法。如 [42] 所述,该研究广泛考察了不同综述中的分类法,主要方法包括阶段、结果类型、功能方法、解释的输出格式和范围。
基于 [42] 提供的定义,本文对文献集中的每种方法进行了分类。最终的分类法如图4和图13以及表2和表3所示。下一节将对每个识别出的类别进行详细描述和讨论。
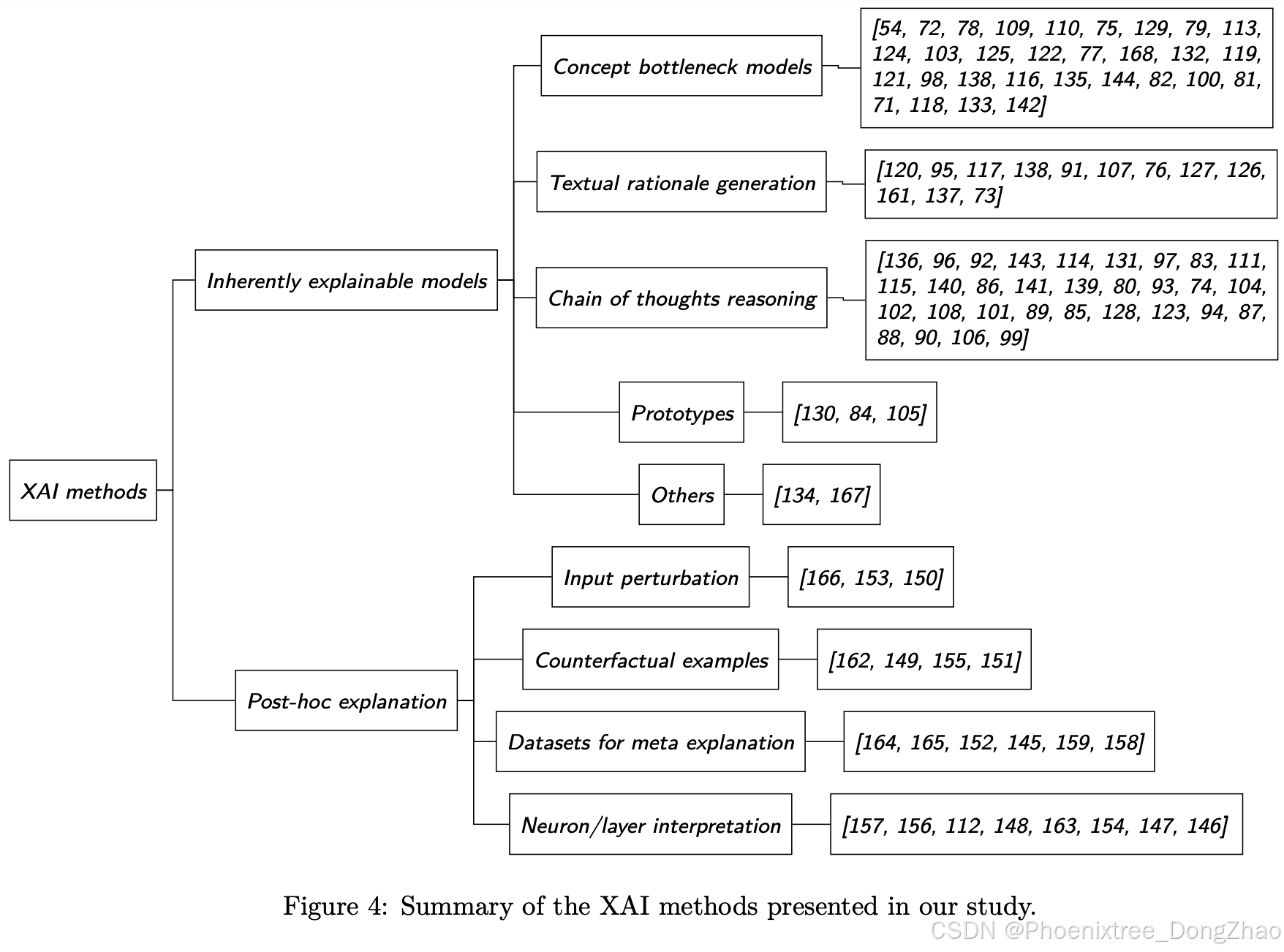
3 XAI Methods for Pretrained Foundation Models
In this section, we present and discuss different categories of PFMs for XAI. They are divided into two main groups. First, we examine inherently explainable models, which are designed to produce explanations by incorporating interpretable components directly into their architecture. Second, we explore post hoc methods, which encompass any external tool to the model, used after the training phase to provide explanations.
本节介绍并讨论了用于 XAI 的 PFMs 的不同类别。它们分为两大组。首先,研究 固有可解释模型,这些模型通过在其架构中直接引入 可解释组件 来生成解释。其次,探讨 事后方法,这些方法包括在训练阶段后使用的任何外部工具,用于提供解释。
3.1. Inherently explainable models
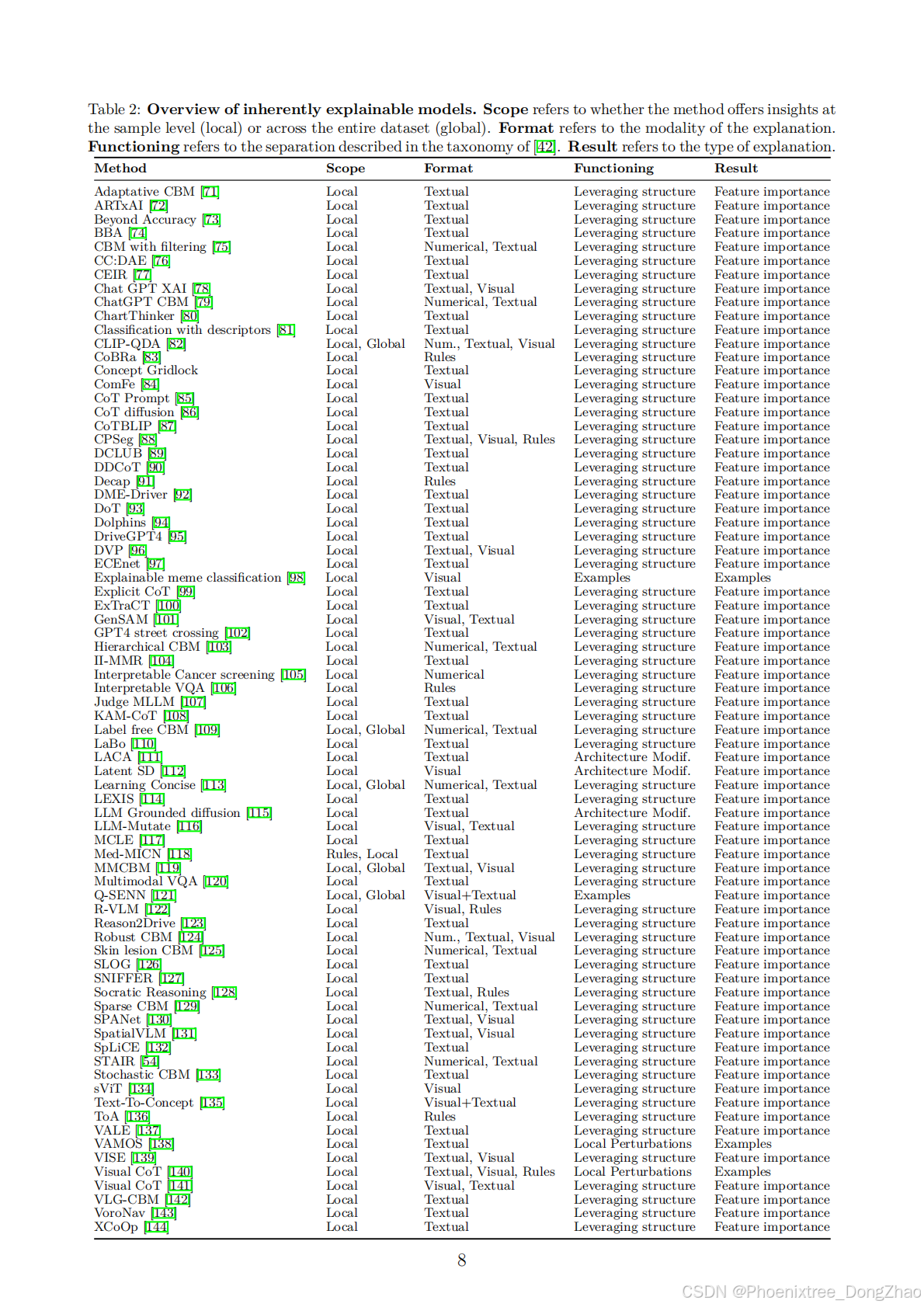
The complete list of inherently interpretable methods is presented in Table 2. Each method is associated with the taxonomy of [42], which includes scope, output format, functioning, and type of result.
固有可解释方法的完整列表见表2。每种方法都与 [42] 的分类法相关联,该分类法包括范围、输出格式、功能和结果类型。
3.1.1. Concept bottleneck models
Definition.
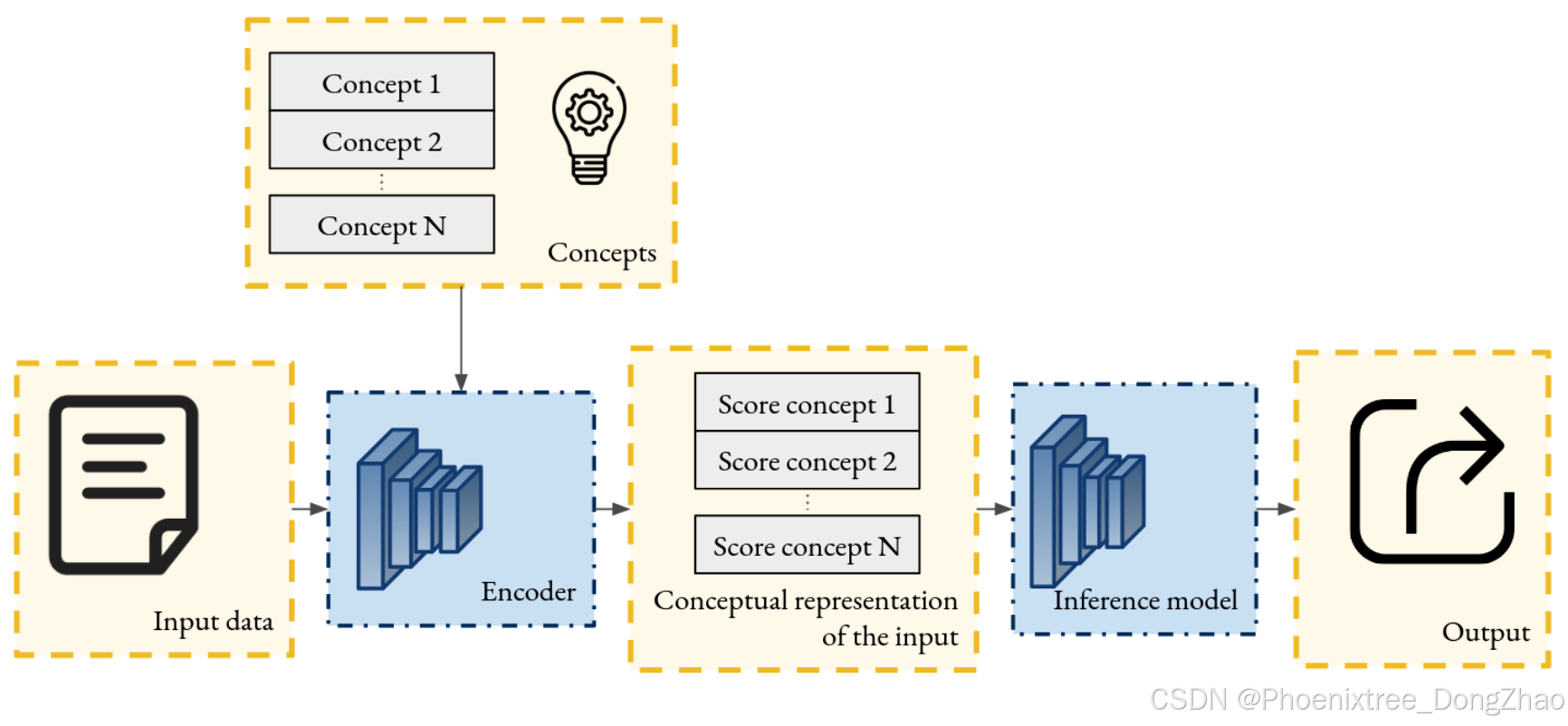
A family of ante-hoc explainability techniques designed to make the predictions of DNNs interpretable by modifying their structure. Specifically, a DNN is partitioned into two components: (1) a concept predictor that maps input data to a set of semantic concepts, and (2) a classifier that predicts the final output class based on these concepts, as shown in Table 5. The concepts typically represent high-level, human-understandable features that are relevant to the prediction task. Explanations are derived from the latent space of concepts, as the model’s predictions can be attributed to a specific set of concepts it focuses on during inference.
Figure 5: Scheme of the principle of an inherently interpretable model through a concept bottleneck. Given an input, the CBM first generates a conceptual representation based on a predefined set of concepts. Subsequently, the model produces an output using this conceptual representation.
Background.
Concept Bottleneck Models (CBMs) represent an interpretable approach in machine learning, where models make predictions based on high-level, human-interpretable concepts extracted from the data—often designated by descriptive terms (e.g., words), rather than on direct data-to-prediction mappings. While the term “Concept Bottleneck Models” is relatively new, this paradigm has roots in pre-deep learning literature [169, 170]. The concept of CBMs was formally introduced by [171], with similar ideas presented as “Semantic Bottleneck Networks” by [172]. Recent advancements have leveraged large language models to construct concepts from CLIP text embeddings [110, 109], giving rise to a family of CLIP-based CBMs. This direction has spurred extensive research [54, 72, 78, 75, 129].
Use of Pretrained Foundation Models.
In their inner functioning, CBMs require models to incorporate semantically meaningful concepts, which is challenging without specially tailored datasets. The introduction of PFMs has made it possible to overcome this limitation through their multimodal generalizability. By leveraging PFMs in the encoder, CBMs can effectively embed meaningful concepts. One of the pioneering works in this direction is [81], which employs text descriptions of classes to augment zero-shot classification by CLIP through score thresholds on these descriptors. Additionally, [78] uses CLIP to encode both image and text tokens associated with these concepts, resulting in a latent space that captures the combined encoding of text and image representations. An additional advantage of this approach is its training efficiency: since concept representations are inherently semantically meaningful and low-dimensional, training can focus primarily on the inference model, keeping it lightweight. Beside CLIP, a notable work is [142] that uses Grounding DINO [16] to spot the position of the detected concepts as bounding boxes.
Application and benchmark.
CBMs are primarily applied to image classification tasks, as the structure of the latent space—often aligned with words due to its design—naturally supports classification processes. Notably, CBMs have also been adapted for applications beyond image classification, including video understanding [138] and image representation learning [77]. Given the broad range of applications, a variety of datasets are utilized, spanning domains like medical imaging [75, 124], art [72], and autonomous driving [168].
Evaluation.
Primarily due to the challenges of conducting evaluations, many studies rely on qualitative explanations using datasets adapted to their respective models. However, some works have adopted tailored XAI evaluation metrics to provide quantitative insights. For example, deletion metrics [64] are utilized in [82, 103], while sparsity metrics [173] are employed in [129].
3.1.1 概念瓶颈模型
定义。
一类 先验可解释性技术,旨在通过修改 DNN 的结构使其预测变得可解释。具体来说,DNN 被划分为两个组件:(1) 一个 概念预测器,将输入数据映射到一组 语义概念;(2) 一个 分类器,基于这些概念预测最终的输出类别,如 表 5 所示。这些概念通常代表与预测任务相关的 高层、人类可理解的特征。解释源自概念潜在空间,因为模型的预测可以归因于其在推理过程中关注的特定概念集。
背景。
概念瓶颈模型 (CBMs) 代表了机器学习中的一种 可解释方法,其中模型基于从数据中提取的 高层、人类可理解的概念 进行预测——通常用描述性术语(例如词语)表示,而不是直接的数据到预测映射。尽管“概念瓶颈模型”这一术语相对较新,但这一范式在 深度学习前文献 中已有根源。CBMs 的概念由 [171] 正式提出,类似的想法被 [172] 称为“语义瓶颈网络”。最近的进展利用大语言模型从 CLIP 文本嵌入中构建概念,从而催生了一类 基于 CLIP 的 CBMs。这一方向引发了广泛的研究 [54, 72, 78, 75, 129]。
使用预训练基础模型。
在其内部机制中,CBMs 要求模型能够整合 语义上有意义的概念,这在没有专门定制数据集的情况下是具有挑战性的。PFMs 的引入通过其多模态通用性克服了这一限制。 通过在编码器中利用 PFMs,CBMs 可以有效地嵌入有意义的概念。这一方向的先驱性工作之一是 [81],它使用类别的文本描述通过 CLIP 的分数阈值增强 零样本分类。此外,[78] 使用 CLIP 对与这些概念相关的图像和文本标记进行编码,从而生成一个 潜在空间,捕捉文本和图像表示的联合编码。这种方法的一个额外优势是其训练效率:由于概念表示本质上是语义上有意义且低维的,训练可以主要集中在推理模型上,使其保持轻量级。除了 CLIP,一个值得注意的工作是 [142],它使用 Grounding DINO 来定位检测到的概念的位置,并生成边界框。
应用与基准。
CBMs 主要应用于 图像分类任务,因为其潜在空间的结构——通常与词语对齐——自然支持分类过程。值得注意的是,CBMs 也被应用于 图像分类之外的任务,包括 视频理解和 图像表示学习。鉴于其广泛的应用,使用了多种数据集,涵盖 医学影像、艺术和 自动驾驶等领域。
评估。
由于评估的挑战性,许多研究依赖于使用适应其各自模型的 定性解释。然而,一些工作采用了 定制的 XAI 评估指标 以提供定量见解。例如,[82, 103] 使用了 删除指标 ,而 [129] 则使用了 稀疏性指标。
3.1.2. Textual rationale generation
Definition.
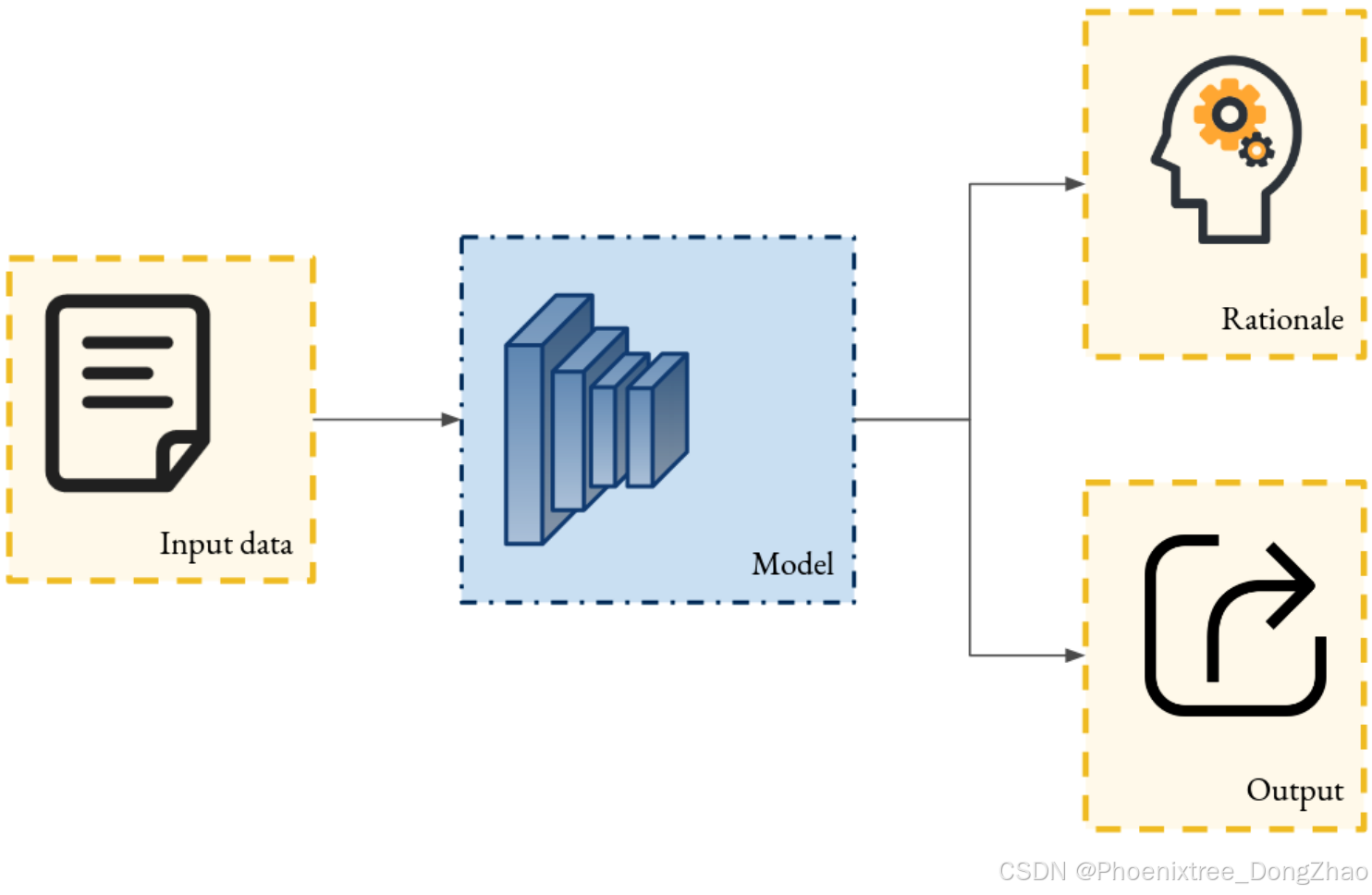
A family of ante-hoc explainability techniques designed to make the predictions of DNNs interpretable by modifying their structure. These methods incorporate a specialized component trained to generate textual justifications for the model’s predictions. This component produces explanations by decoding the latent space of the network (as illustrated in Table 6) and often derived from an LLM. The generated explanations typically take the form of concise textual statements that directly address the question: “Why did the model make this specific inference?”
Figure 6: Scheme of the principle of an inherently interpretable model through the generation of textual rationale. Given an input, the model generates a textual rationale alongside its output, providing insights into the reasoning behind the prediction. Compared to other methods that imply some interpretable decomposition of the model, the model here can be opaque.
Background.
Rationales provide context and reasoning that closely align with human language and cognitive processes, offering explanations that are more naturally interpretable by humans. This concept has been explored since the early days of AI, often through template-based approaches that consist in triggering predefined sentences based on specific conditions within the system framework being met [174, 175]. However, generating multimodal, text-based rationales from deep vision models has been particularly challenging due to the complexity of combining visual and linguistic information. The first successful approach to tackle this was introduced by [176], which involved training a model on a custom dataset specifically designed for multimodal rationale generation. Recent advancements in large language models [18] and large multimodal models [32] have since opened new avenues for rationale generation, reducing dependence on dataset-specific constraints and enabling more flexible and generalizable methods across the field.
- Use of Pretrained Foundation Models.
Analogous to Concept Bottleneck Models, the emergence of multimodal PFMs has significantly accelerated the development of approaches utilizing textual rationales. Due to their more flexible framework, a wider variety of PFMs have been employed in this domain, including CLIP [91, 117], as well as BLIP [120] and LLaVA [76]. This diversity is particularly noteworthy since the latter two models are specifically designed for image captioning tasks, highlighting their adaptability and relevance in generating coherent and contextually appropriate textual explanations. In addition, we also noticed some works using extra modules to guide the image captioning module on areas the model focuses on [137, 177].
Application and benchmark.
The established nature of rationale-generating methods with standardized architectures has paved the way for adaptations tailored to specific domains, such as autonomous driving [95] and harmful meme detection [107]. Recent work has also focused on refining architectures to enhance informativeness [91] and contextual relevance [97], and on extending rationale generation to more complex data types, such as video [138]. Additional approaches, such as [117], incorporate visual explanations through bounding boxes, while others like [161] apply rationales to image quality assessment. The VQA-X dataset [176] is a popular benchmarking tool, providing a standard for comparison across studies in rationale-based explainability.
Evaluation.
The field of rationale generation benefits from well-established text perceptual similarity metrics [178, 179], providing a solid baseline for evaluating generated explanations. The standard approach for assessing explanation quality involves calculating the similarity between generated rationales and ground-truth rationales found in datasets like VQA-X [176]. Furthermore, more specialized datasets are available for domain-specific applications, such as [180], which is tailored for autonomous driving contexts.
3.1.2 文本理由生成
定义。
一类 先验可解释性技术,旨在通过修改 DNN 的结构使其预测变得可解释。这些方法引入了一个 专门组件,训练用于生成模型预测的 文本理由。该组件通过解码网络的 潜在空间(如 表 6 所示)生成解释,通常源自 大语言模型 (LLM)。生成的解释通常以 简洁的文本陈述 形式呈现,直接回答以下问题:“为什么模型做出了这一特定推断?”
背景。
理由 提供了与 人类语言和认知过程 紧密对齐的上下文和推理,提供了更自然且易于人类理解的解释。这一概念自 人工智能早期 以来就被探索,通常通过 基于模板的方法 实现,即在系统框架内满足特定条件时触发预定义的句子。然而,从 深度视觉模型 生成 多模态、基于文本的理由 特别具有挑战性,因为结合 视觉和语言信息 的复杂性。第一个成功解决这一问题的方法由 [176] 提出,它涉及在专门设计用于多模态理由生成的自定义数据集上训练模型。最近在大语言模型和大多模态模型方面的进展 为理由生成开辟了新途径,减少了对数据集特定约束的依赖,并实现了更灵活和可推广的方法。
使用预训练基础模型。
与 概念瓶颈模型 类似,多模态 PFMs 的出现显著加速了利用 文本理由 的方法的发展。由于其更灵活的框架,这一领域使用了更广泛的 PFMs,包括 CLIP,以及 BLIP和 LLaVA。这种多样性尤其值得注意,因为后两种模型专门设计用于 图像字幕任务,突显了它们在生成 连贯且上下文适当的文本解释 方面的适应性和相关性。此外,本文还注意到一些工作使用 额外模块 来引导图像字幕模块关注模型聚焦的区域。
应用与基准。
理由生成方法 的标准化架构为适应特定领域的应用铺平了道路,例如 自动驾驶和 有害模因检测。最近的工作还专注于 优化架构,以提高 信息量和 上下文相关性,并将理由生成扩展到更复杂的数据类型,例如 视频。其他方法,如 [117],通过 边界框 结合 视觉解释,而像 [161] 这样的方法则将理由应用于 图像质量评估。VQA-X 数据集是一个流行的基准工具,为 基于理由的可解释性 研究提供了比较标准。
评估。
理由生成领域 受益于 成熟的文本感知相似性指标,为评估生成的解释提供了坚实的基础。评估解释质量的标准方法 是计算生成的理由与 VQA-X等数据集中 真实理由 之间的相似性。此外,还有针对特定领域应用的 专门数据集,例如 [180],它专为 自动驾驶 场景设计。
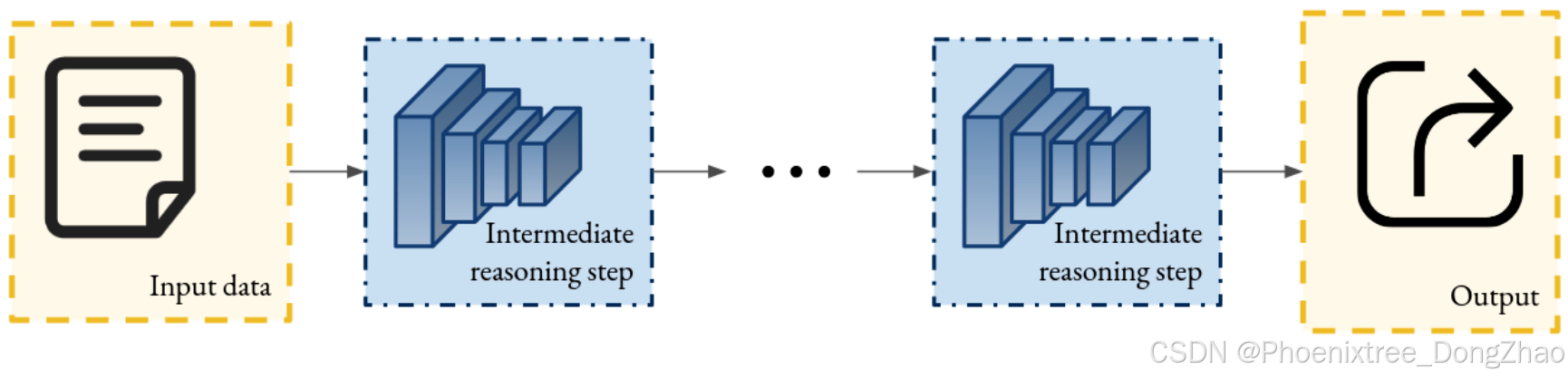
3.1.3. Chain of thought reasoning
Definition.
A family of ante-hoc explainability techniques designed to make the predictions of DNNs interpretable by modifying their way to produce inference. This involves decomposing the network into multiple interpretable blocks, as illustrated in Table 7. Chain-of-thought explanation aims to elucidate the reasoning process that leads to the model’s predictions. The interpretability stems from the fact that humans can more easily understand and follow the sequential reasoning behind the decision. Such methodologies are frequently implemented in large language models to enhance the transparency of their decision-making processes.
Background.
The initial developments of Chain of Thought (CoT) explanations originated in language-only tasks with large language models (LLMs) [181]. These methods, often referred to as zero-shot approaches, involve sequentially applying prompts to simulate a reasoning process closer to human-like thinking. In this paradigm, the explanation unfolds as a series of decomposed steps or actions (see Figure 7). A related paradigm, known as few-shot CoT, extends this by using a parallel decomposition of reasoning steps. With advancements in PFMs and their capability to process multimodal inputs, CoT reasoning has now been adapted for visual tasks [90, 87]. Additionally, increasingly complex reasoning structures have been developed to enhance outputs through advanced integration of reasoning blocks [80, 128, 102].
Figure 7: Scheme of the principle of an inherently interpretable model through chain of thought. The model processes its input in multiple sequential steps, resulting in an iterative reasoning process.
Use of Pretrained Foundation Models.
Due to their close relationship with large language models, CoT techniques have naturally extended to multimodal PFMs. Notably, BLIP-2 has become particularly popular in CoT applications [123, 111, 143]. Additionally, models like GPT-4 are increasingly used to develop CoT-based techniques [83], especially as API-based prompting approaches simplify integration.
Application and benchmark.
Building on a solid foundation from previous work in large language models, CoT-based methods in XAI have gained substantial traction in the literature. These approaches leverage step-by-step reasoning to improve both explainability and accuracy. Researchers have explored a variety of CoT-inspired enhancements, such as Socratic reasoning [128], visual/non-visual information separation [101], the integration of knowledge graphs [108], decision tree frameworks [106], and segmentation techniques [88]. Contrary to the common assumption that interpretability often reduces model accuracy, CoT methods have shown promise in maintaining or even improving accuracy when integrated with PFMs. This versatility has also led to the development of CoT approaches for specialized domains, including autonomous driving [102, 123, 94, 90] and mathematical reasoning [128, 74].
Evaluation.
Given the complexity of capturing a ground truth that accurately reflects human reasoning, evaluating CoT methods is substantially more challenging than assessing simpler textual rationales. As a result, many studies rely on qualitative examples for evaluation, as seen in works such as [90, 101, 85]. In specific cases, researchers have devised evaluation methods involving sub-questions that aim to break down reasoning processes, sometimes even proposing these methods as potential benchmarks, as seen in [87, 123].
3.1.3 思维链推理
定义。
一类 先验可解释性技术,旨在通过修改 DNN 的推理方式使其预测变得可解释。这涉及将网络分解为多个 可解释的模块,如 表 7 所示。思维链解释 旨在阐明导致模型预测的 推理过程。其可解释性源于人类可以更容易理解和跟随决策背后的 顺序推理。这类方法通常应用于 大语言模型,以增强其决策过程的 透明度。
背景。
思维链 (CoT) 解释 的最初发展起源于 纯语言任务 中的 大语言模型 (LLMs)。这些方法通常被称为 零样本方法,涉及 顺序应用提示 以模拟更接近人类思维的推理过程。在这一范式中,解释展开为一系列 分解的步骤或操作(见 图 7)。一个相关的范式是 少样本 CoT,它通过 并行分解推理步骤 扩展了这一方法。随着 PFMs 的发展及其处理 多模态输入 的能力,CoT 推理现已适应于 视觉任务。此外,越来越复杂的推理结构 已被开发出来,通过 高级推理模块的集成 来增强输出。
使用预训练基础模型。
由于与 大语言模型 的密切关系,CoT 技术自然扩展到 多模态 PFMs。值得注意的是,BLIP-2 在 CoT 应用中变得特别流行。此外,像 GPT-4 这样的模型越来越多地用于开发 基于 CoT 的技术,尤其是 基于 API 的提示方法 简化了集成。
应用与基准。
基于 大语言模型 的先前工作的坚实基础,基于 CoT 的方法 在 XAI 领域获得了大量关注。这些方法利用 逐步推理 来提高 可解释性和准确性。研究人员探索了多种 CoT 启发的增强方法,例如 苏格拉底式推理、视觉/非视觉信息分离、知识图谱集成、决策树框架和 分割技术。与通常认为可解释性会降低模型准确性的假设相反,CoT 方法在与 PFMs 集成时显示出保持甚至提高准确性的潜力。 这种多功能性还导致了 CoT 方法 在 自动驾驶和 数学推理等专门领域的应用。
评估。
由于捕捉准确反映人类推理的 真实情况 的复杂性,评估 CoT 方法比评估更简单的 文本理由 更具挑战性。因此,许多研究依赖于 定性示例 进行评估,如 [90, 101, 85] 中的工作所示。在特定情况下,研究人员设计了涉及 子问题 的评估方法,旨在分解推理过程,有时甚至将这些方法提议为潜在的基准,如 [87, 123] 所示。
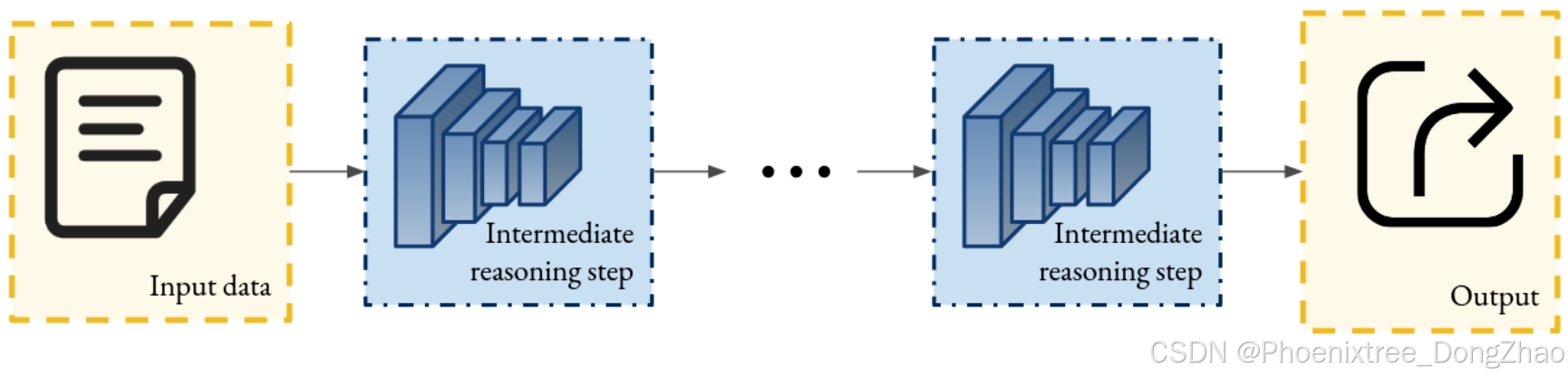
3.1.4. Prototypical networks
- Definition.
A family of ante-hoc explainability techniques designed to make the predictions of DNNs interpretable by modifying their structure. Specifically, the DNN is divided into three core components (Figure 8): (1) an encoder that transforms inputs into fixed-size vectorized representations, (2) a mapper that translates the latent space vectors into semantic prototypes, and (3) an inference module that derives the final output from these prototypes. Unlike CBMs, this approach learns the set of prototypes during training. Interpretability arises from attributing the model’s predictions to specific prototypes activated during inference, offering insight into the decision-making process. These techniques can be applied to any model.
Figure 8: Scheme of the principle of an inherently interpretable model through prototypes. The input is embedded into a latent space and mapped to regions corresponding to previously learned prototypes, which are then used to produce the output.
- Background.
Prototypical networks were first introduced by [182] for few-shot and zero-shot learning, where the concept of prototypes is closely related to clustering techniques. This idea was later adapted for interpretable object recognition, such as in the work on ProtoNet [183], which probes training images of each class to identify common prototypes. Subsequent improvements have incorporated methods like decision trees [184] and vision transformers [185] to enhance model performance. However, these approaches still face challenges related to computational costs. To address these limitations, new solutions leveraging Prototypical Networks with PFMs have been proposed, offering more scalable and interpretable alternatives [130, 84, 105].
- Use of Pretrained Foundation Models.
One of the key benefits of using PFMs in prototypical networks is the ability to represent prototypes across multiple modalities, such as text using CLIP, while simultaneously reducing both computational and labeling costs [130]. Additionally, the incorporation of models like DINOv2 [186] and SAM [37], which enable the segmentation of relevant regions within an image, has been shown to enhance the identification of more expressive prototypes [84, 105].
- Application and benchmark.
The applications of prototypes using PFMs are diverse. [130] and [84] applied their methods to the CUB dataset [187], which has been widely used in previous research on prototypical networks. Additionally, [105] propose the application of prototypical networks to medical images.
- Evaluation.
Current methods are often limited to qualitative examples, as the prototype set is not fixed by the dataset, which complicates the evaluation of explanations. However, [130] addresses this challenge by proposing a quantitative evaluation using the deletion metric [64], which assesses the importance of the pixels highlighted by their explanations.
3.1.4 原型网络
定义。
一类 先验可解释性技术,旨在通过修改 DNN 的结构使其预测变得可解释。具体来说,DNN 被划分为三个核心组件(表 8):(1) 一个 编码器,将输入转换为 固定大小的向量化表示;(2) 一个 映射器,将 潜在空间向量 转换为 语义原型;(3) 一个 推理模块,从这些原型中推导出最终输出。与 CBMs 不同,这种方法在训练过程中 学习原型集。可解释性 源于将模型的预测归因于推理过程中激活的特定原型,从而提供对 决策过程 的洞察。这些技术可以应用于任何模型。
背景。
原型网络 最初由 [182] 提出,用于 少样本和零样本学习,其中 原型的概念 与 聚类技术 密切相关。这一想法后来被用于 可解释的目标识别,例如 ProtoNet,它探测每个类别的训练图像以识别 共同的原型。随后的改进引入了 决策树和 视觉变换器等方法,以增强模型性能。然而,这些方法仍面临 计算成本 的挑战。为了解决这些限制,提出了利用 PFMs 的原型网络 的新解决方案,提供了更 可扩展和可解释的替代方案。
使用预训练基础模型。
在 原型网络 中使用 PFMs 的一个关键优势是能够跨 多模态(例如使用 CLIP 的文本)表示原型,同时减少 计算和标注成本。此外,DINOv2和 SAM等模型的引入,能够 分割图像中的相关区域,从而增强了 更具表现力的原型 的识别。
应用与基准。
使用 PFMs 的原型应用多种多样。[130] 和 [84] 将他们的方法应用于 CUB 数据集,该数据集在 原型网络 的先前研究中被广泛使用。此外,[105] 提出了将 原型网络 应用于 医学图像 的建议。
评估。
当前的方法通常局限于 定性示例,因为 原型集 不是由数据集固定的,这使得解释的评估变得复杂。然而,[130] 通过提出使用 删除指标的 定量评估 解决了这一挑战,该指标评估了其解释所突出显示的 像素的重要性。
3.1.5. Others
Among the corpus of inherently explainable methods, there are certain approaches that are too specific to fit neatly into the families previously discussed. For example, Finetune [167] presents a method for fine-tuning diffusion models to enhance their interpretability. This is achieved by using CLIP to generate activations related to textual concepts, specifically applied to radiology images. Similarly, sViT [134] employs SAM (Segment Anything Model) to segment the input image, allowing for the clustering of the image into semantically meaningful regions, as opposed to the typical patch-based process used in vision transformers.
3.1.5 其他
在 固有可解释方法 的语料库中,有一些方法过于特定,无法很好地归入先前讨论的类别。例如,Finetune 提出了一种 微调扩散模型 的方法,以增强其 可解释性。这是通过使用 CLIP 生成与 文本概念 相关的激活来实现的,特别是应用于 放射学图像。类似地,sViT使用 SAM(Segment Anything Model) 对输入图像进行分割,从而将图像聚类为 语义上有意义的区域,而不是在 视觉变换器 中使用的典型的 基于补丁的过程。
3.2. Post-hoc explanation methods
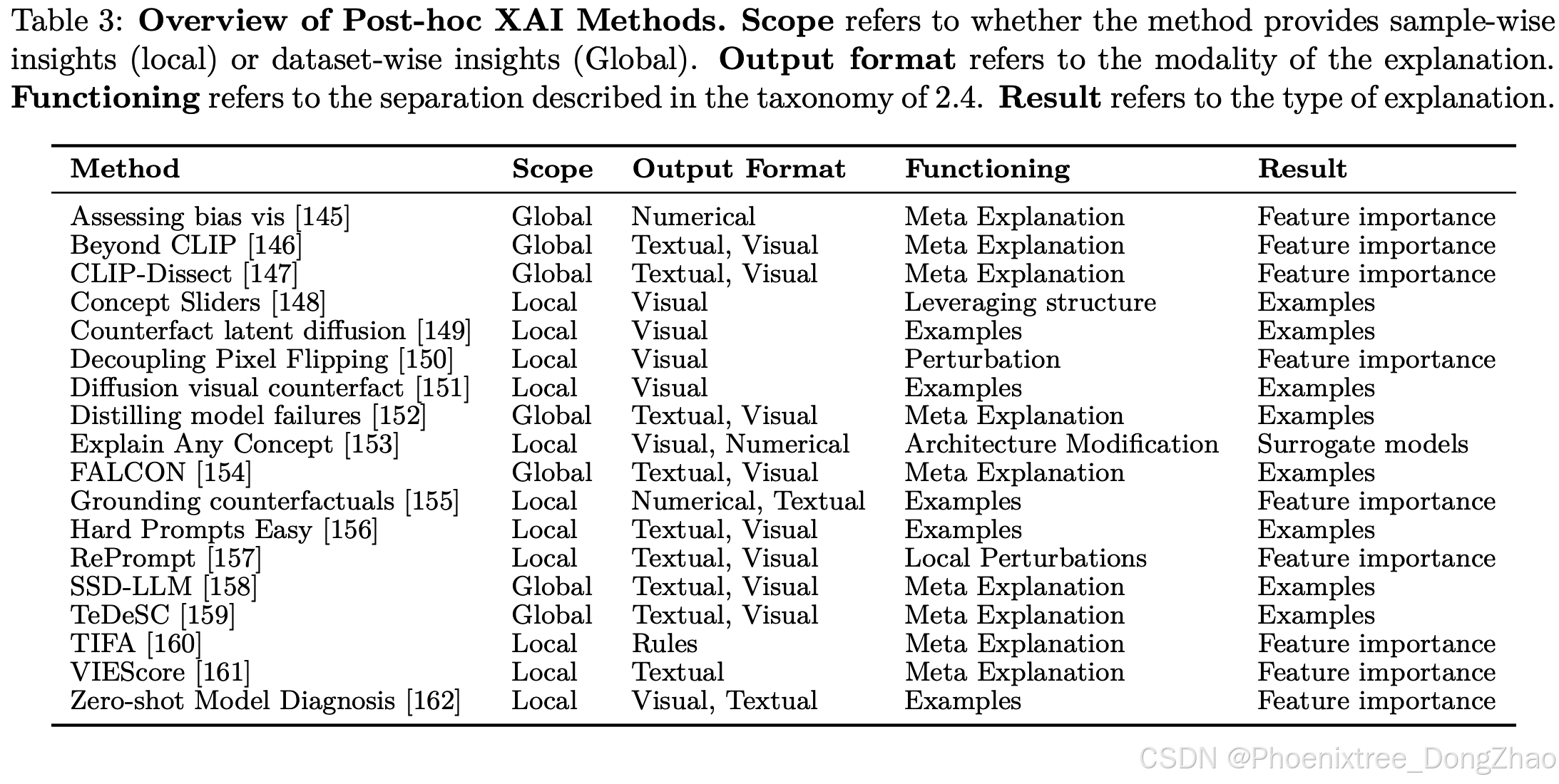
The complete list of post-hoc methods is presented in Table 3. Each method is associated with the taxonomy of [42], which includes scope, output format, functioning, and type of result.
3.2 事后解释方法
事后方法 的完整列表见 表 3。每种方法都与 [42] 的分类法相关联,该分类法包括 范围、输出格式、功能 和 结果类型。
3.2.1. Input perturbation
Definition.
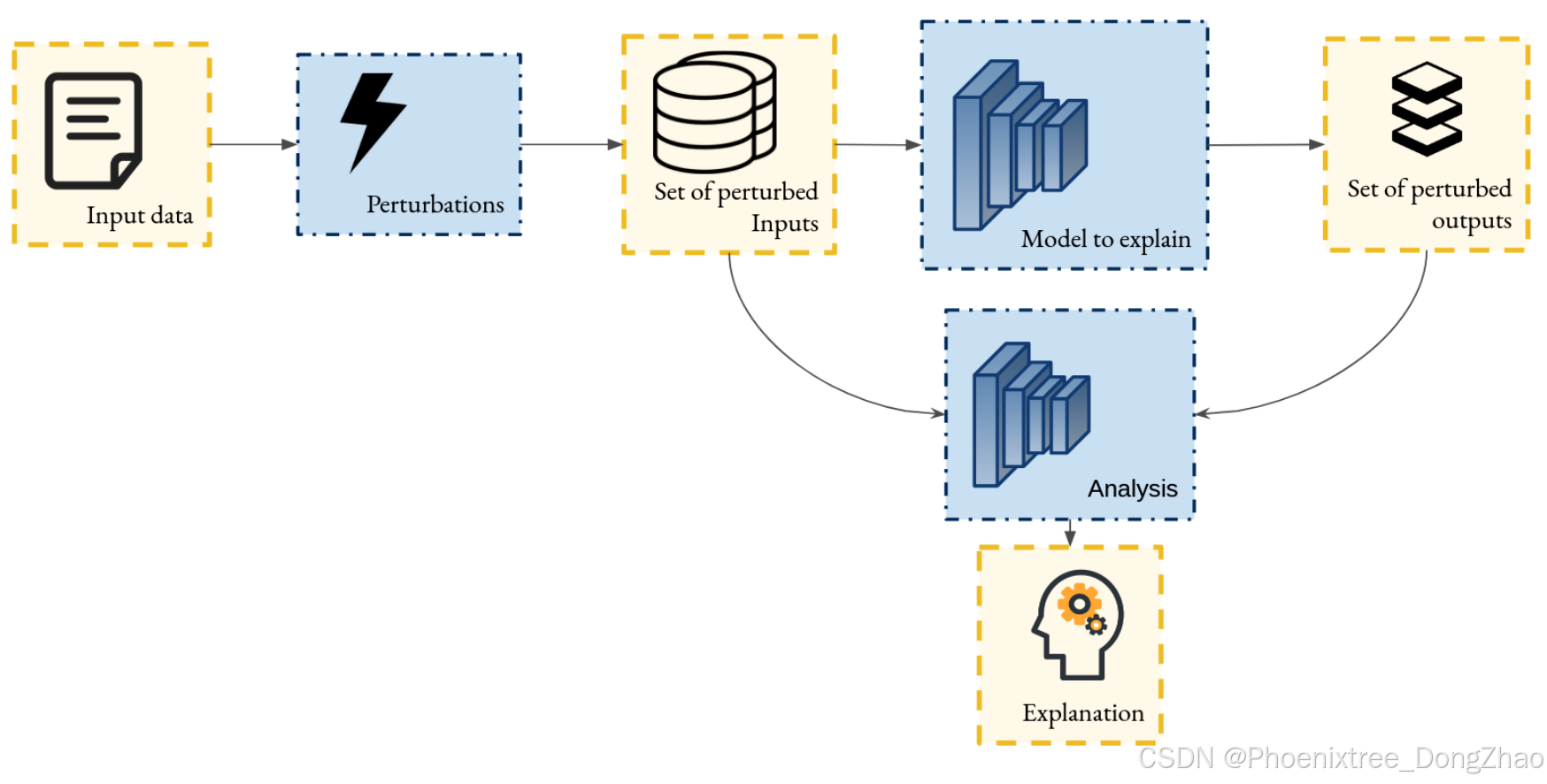
A family of post-hoc explainability techniques designed to make an explanation of any model without modifying the structure of the model by probing its behavior on a set of perturbed input variants. The process is typically divided into two steps (Figure 9): (1) generating outputs for various perturbations of the input, and (2) training an auxiliary interpretable model to approximate the local behavior of the original model around the perturbed input space. Explanations are then derived by analyzing this local approximation model, focusing on the impact of each input feature on the model’s decision (feature attribution). These techniques can be applied to any model.
Figure 9: Scheme of the principle of post-hoc explanation by perturbing input data. Given an input, a set of perturbed samples is generated. The model’s behavior in response to these perturbations is then analyzed, and the resulting analysis provides explanations for the model’s inference.
Background.
Input perturbation refers to a class of post-hoc techniques that aim to explain the inference of a given model by testing the model on a set of slightly perturbed variants of the input sample. This approach has gained significant interest, as the diversity of DNN architectures necessitates a flexible and robust process for producing sample-wise explanations. Early contributions to this field include methods like LIME [62] and SHAP [66], which have become widely adopted for their ability to provide interpretable explanations for opaque models. Subsequent works have focused on improving these methods, particularly by developing better approximations for high-dimensional inputs, such as images.
Use of Pretrained Foundation Models.
Given the challenges associated with creating superpixels, PFMs dedicated to semantic segmentation, such as SAM [37], have proven useful for producing semantically meaningful decompositions of images. Consequently, extensions of SHAP have been developed using SAM [150, 153], which enhance the quality of explanations. In addition, [166] have proposed integrating semantic segmentation with LIME.
- Application and benchmark.
Due to the versatility of these methods, there are no specific datasets or applications that are strictly tied to them. While the papers presented here often focus on commonly used datasets like ImageNet or COCO, these techniques can be adapted to a wide range of datasets and tasks.
- Evaluation.
In the context of attribution-based XAI methods, a variety of quantitative evaluation metrics are commonly employed. [153] and [166] adopt the deletion metric [64] to assess the trustworthiness of explanations, which measures the drop in model accuracy when the most important pixels are occluded. This approach helps evaluate how crucial the identified features are to the model’s decision-making process. Additionally, [150] introduce a variant of this metric, named as Symmetric Relevance Gain. Note that other metrics, such as Noise Stability [188] and Preservation Check [189], are also used [166].
We focus here on post-hoc methods from our corpus of articles. The full list of methods is presented in Table 3. Notably, we associate each method with the taxonomy of [42], including scope, output format, functioning, and type of result.
3.2.1 输入扰动
定义。
一类 事后可解释性技术,旨在通过 探测模型在一组扰动输入变体上的行为 来解释任何模型,而无需修改模型的结构。该过程通常分为两个步骤(表 9):(1) 为输入的各种 扰动 生成输出,(2) 训练一个 辅助可解释模型 以近似原始模型在 扰动输入空间 附近的局部行为。解释 是通过分析这个 局部近似模型 得出的,重点关注每个输入特征对模型决策的影响(特征归因)。这些技术可以应用于任何模型。
背景。
输入扰动 是指一类 事后技术,旨在通过测试模型在 输入样本的轻微扰动变体 上的行为来解释给定模型的推理。这种方法引起了极大的兴趣,因为 DNN 架构的多样性 需要一个 灵活且稳健的过程 来生成 样本级别的解释。该领域的早期贡献包括 LIME 和 SHAP 等方法,这些方法因其能够为 不透明模型 提供 可解释的解释 而被广泛采用。后续工作专注于改进这些方法,特别是通过开发更好的 高维输入(如图像)的近似方法。
使用预训练基础模型。
鉴于创建 超像素 的挑战,专门用于语义分割的 PFMs,如 SAM,已被证明在生成 语义上有意义的图像分解 方面非常有用。因此,使用 SAM 扩展了 SHAP,从而提高了 解释的质量。此外,[166] 提出了将 语义分割 与 LIME 集成的建议。
应用与基准。
由于这些方法的 多功能性,没有特定的数据集或应用严格绑定到它们。虽然这里提到的论文通常关注 ImageNet 或 COCO 等常用数据集,但这些技术可以适应 广泛的数据集和任务。
评估。
在 基于归因的 XAI 方法 的背景下,通常采用多种 定量评估指标。[153] 和 [166] 采用 删除指标来评估 解释的可信度,该指标测量当 最重要的像素 被遮挡时模型准确性的下降。这种方法有助于评估 识别出的特征 对模型决策过程的 重要性。此外,[150] 引入了该指标的一个变体,称为 对称相关性增益。需要注意的是,其他指标,如 噪声稳定性和 保留检查,也被使用 [166]。
在这里重点介绍本文文章语料库中的 事后方法。完整的方法列表 见 表 3。值得注意的是,将每种方法与 [42] 的 分类法 相关联,包括 范围、输出格式、功能 和 结果类型。
3.2.2. Counterfactual examples
- Definition.
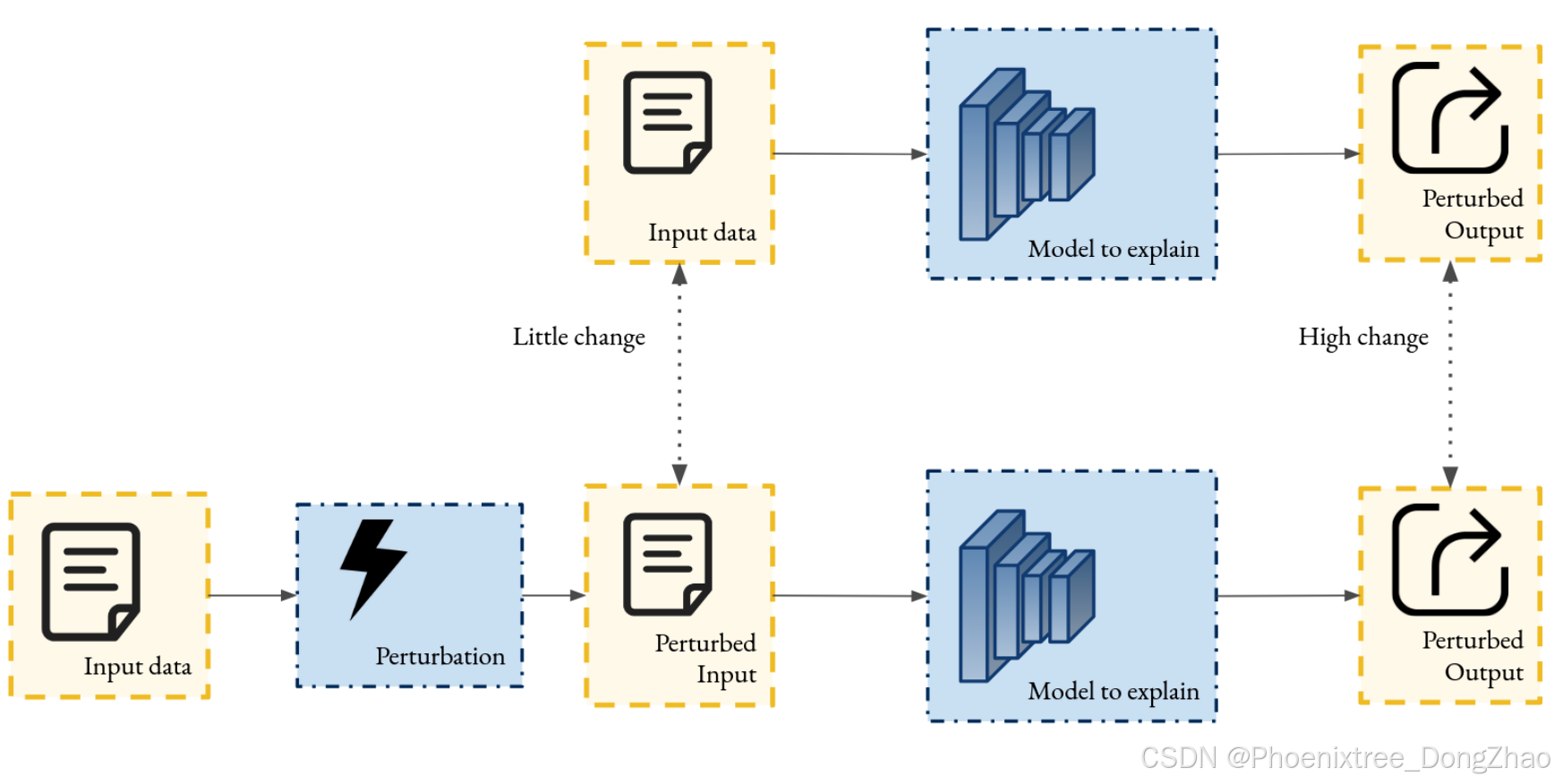
A family of post-hoc explainability techniques designed to make an explanation of any model without modifying the structure, by searching for counterfactual examples. To do so, an optimizing process is performed to search for a minimal perturbation that induces high changes in the prediction (for example a label shift in classification tasks), represented as do(Z = z0 + ε), where z0 is a fixed input value and ε is a small perturbation, using a common notation in causal inference [190]. A figure representing the process is available in Figure 10. The resulting explanation is the pair constituted of a original image, the perturbated image, and the prediction given the original image and the prediction given the perturbated image. Explanations are derived from the fact that finding counterfactuals give to the users examples of causal interventions that rules the functioning of the model. These methods can be applied to any model.
Figure 10: Schema of the principle of post-hoc explanation through counterfactuals. A minimal perturbation is applied to the input to generate a variant that results in a significant change in the model’s inference compared to the original input.
- Background.
Counterfactual explanations seek to identify minimal perturbations in the input data that induce a significant shift in the model’s prediction. These methods have relevance across disciplines, including philosophy, psychology, and social sciences, where theories on counterfactual reasoning have been extensively explored [191, 192]. Recent advancements in machine learning, particularly those that enable the encoding of data into structured latent spaces, have catalyzed a new wave of counterfactual generation techniques. A foundational contribution in this domain is provided by [193], which leverages variational encoders to create counterfactual instances, initially focusing on tabular data. This approach has been further refined and generalized; for instance, [194] integrates flow-based models to enhance the flexibility of counterfactual generation. In computer vision, latent space manipulation for counterfactual creation has also gained traction, as seen in the methods proposed by [195] and [196].
- Use of Pretrained Foundation Models.
For image inputs, the generation of counterfactuals heavily relies on advancements in image editing techniques. In this regard, diffusion models like Stable Diffusion [33] have shown significant promise. By optimizing for gradients within the diffusion steps that highlight model sensitivities, these methods can effectively generate meaningful counterfactuals [149, 151]. Another approach leverages PFMs to identify counterfactual directions that align with specific concepts. For instance, [155] utilize the CLIP embedding space to discover directions corresponding to concept addition in a model-agnostic manner (note that CLIP-QDA also proposes counterfactuals but is not model-agnostic). Similarly, [162] apply CLIP to interpret the latent space of StyleGAN, producing counterfactuals in the form of edited images.
- Application and benchmark.
To date, most methods in this domain have been demonstrated on well-known datasets like CELEB-A [197] and CUB [187], providing convenient, straightforward use cases. These datasets support methods by offering controlled scenarios with interpretable attributes, facilitating analysis and comparison. In terms of application tasks, the primary focus has been on image classification. However, these approaches hold potential for adaptation to a range of tasks involving image inputs, suggesting the feasibility of extending these techniques to other domains in visual processing like regression or semantic segmentation.
- Evaluation.
A key criterion for effective counterfactual generation is maintaining proximity to the original input image, which ensures the counterfactual’s relevance and interpretability. Consequently, popular evaluation metrics for counterfactual quality are derived from image quality assessment frameworks, such as the Fr´echet Inception Distance (FID) [198] and the Learned Perceptual Image Patch Similarity [199], where a smaller distance generally indicates a more effective counterfactual. Given the importance of perceptual similarity, traditional distance metrics like Peak Signal-to-Noise Ratio and Structural Similarity Index Measure are less commonly used in this context, as they may not capture semantic nuances as effectively.
3.2.2 反事实示例
定义。
一类 事后可解释性技术,旨在通过 搜索反事实示例 来解释任何模型,而无需修改模型的结构。为此,执行一个 优化过程 来搜索 最小扰动,该扰动会引发预测的 显著变化(例如分类任务中的标签转移),表示为 do(Z = z0 + ε),其中 z0 是固定输入值,ε 是 小扰动,使用 因果推理 中的常见符号。表 10 中提供了表示该过程的图示。生成的解释 由 原始图像、扰动图像、原始图像的预测 和 扰动图像的预测 构成。解释 源于 反事实的发现,为用户提供了 因果干预的示例,这些干预规则了模型的功能。这些方法可以应用于任何模型。
背景。
反事实解释 旨在识别输入数据中的 最小扰动,这些扰动会引发模型预测的 显著变化。这些方法在 哲学、心理学 和 社会科学 等多个学科中具有相关性,其中 反事实推理 的理论已被广泛探讨。机器学习 的最近进展,特别是那些能够将数据编码为 结构化潜在空间 的技术,推动了 反事实生成技术 的新浪潮。该领域的基础性贡献由 [193] 提供,其利用 变分编码器 创建 反事实实例,最初专注于 表格数据。这一方法已被进一步改进和推广;例如,[194] 集成了 基于流的模型,以增强 反事实生成 的灵活性。在 计算机视觉 中,潜在空间操作 用于 反事实创建 也获得了关注,如 [195] 和 [196] 提出的方法所示。
使用预训练基础模型。
对于 图像输入,反事实生成 在很大程度上依赖于 图像编辑技术 的进展。在这方面,像 Stable Diffusion 这样的 扩散模型 显示出显著的潜力。通过在扩散步骤中优化梯度以突出模型的敏感性,这些方法可以有效地生成 有意义的反事实。另一种方法利用 PFMs 来识别与 特定概念 对齐的 反事实方向。例如,[155] 使用 CLIP 嵌入空间 来发现与 概念添加 对应的方向,并以 模型无关的方式 实现(注意,CLIP-QDA 也提出了反事实,但不是模型无关的)。类似地,[162] 应用 CLIP 来解释 StyleGAN 的潜在空间,生成 编辑图像形式 的反事实。
应用与基准。
迄今为止,该领域的大多数方法已在 CELEB-A和 CUB等知名数据集上进行了演示,提供了方便、直接的使用案例。这些数据集通过提供 具有可解释属性的受控场景 来支持方法,从而促进分析和比较。在应用任务方面,主要关注 图像分类。然而,这些方法具有适应涉及 图像输入 的其他任务的潜力,表明将这些技术扩展到 视觉处理 的其他领域(如 回归 或 语义分割)的可行性。
评估。
有效反事实生成 的一个关键标准是 保持与原始输入图像的接近性,这确保了反事实的 相关性和可解释性。因此,反事实质量 的流行评估指标源自 图像质量评估框架,例如 Fr´echet Inception Distance (FID) 和 Learned Perceptual Image Patch Similarity,其中 较小的距离 通常表示 更有效的反事实。鉴于 感知相似性 的重要性,传统的距离指标(如 峰值信噪比 和 结构相似性指数)在此背景下较少使用,因为它们可能无法有效捕捉 语义上的细微差别。
3.2.3. Datasets for meta explanation
- Definition.
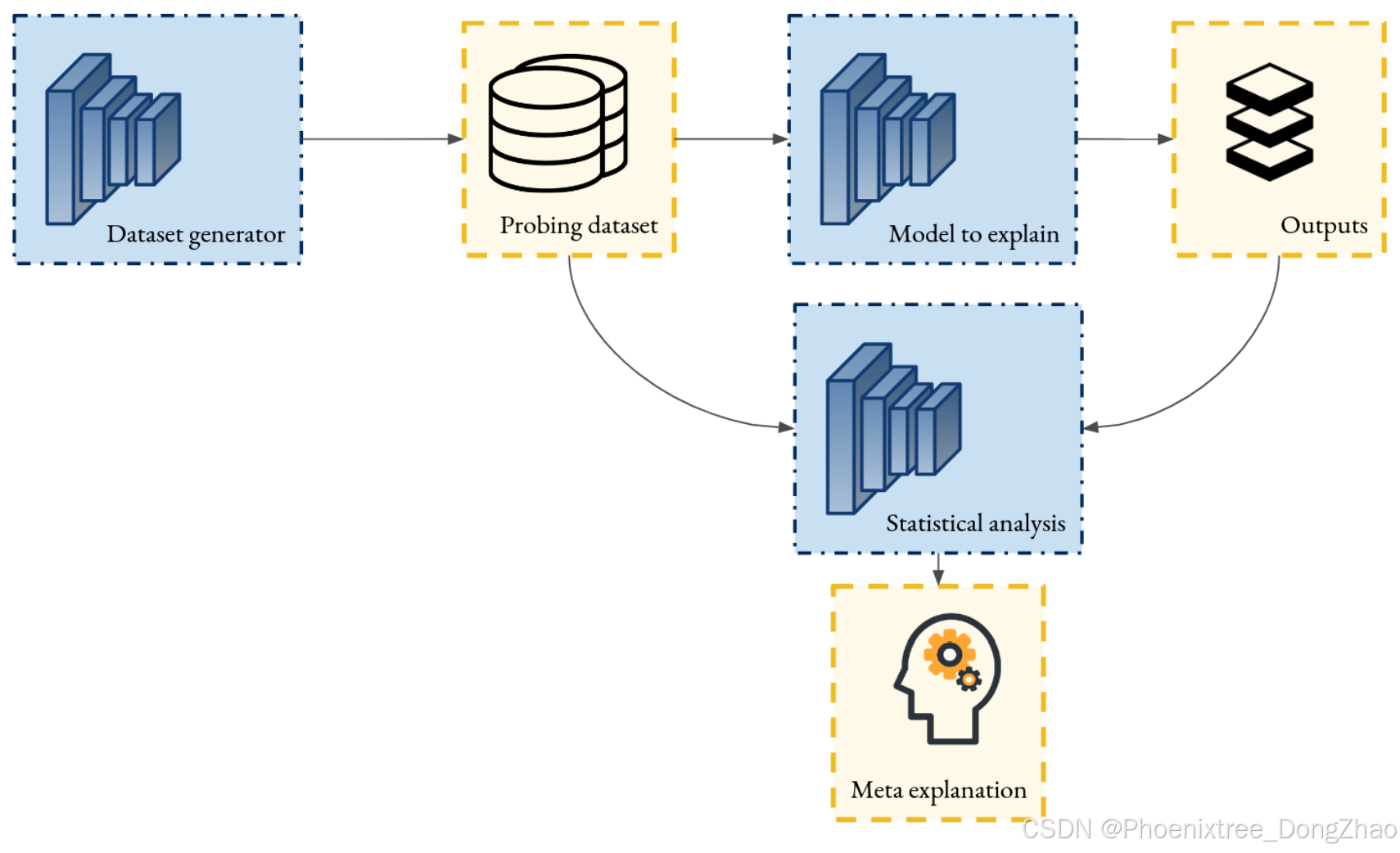
A family of post-hoc explainability techniques designed to explain the global functioning of a model without modifying the structure by probing its responses on an auxiliary dataset specifically designed to reveal potential biases. Explanations are generated through statistical analysis of the model’s behavior across the entire dataset (Figure 11). These techniques can be applied to any model.
Figure 11: Scheme of the principle of post-hoc explanation through meta explanations. A dataset, generated through a prior process, is provided to the model. The model’s responses are then analyzed through statistical methods to produce a meta-explanation that offers insights into the model’s behavior.
- Background.
The prevalence of biases in deep neural networks has driven substantial interest in studying model sensitivity to various forms of bias, with foundational work by [200] exploring this topic early on. This line of research spurred the creation of datasets specifically designed to probe for bias, either by extending existing datasets [201] or through the development of entirely new ones [202]. Such datasets enable statistical analyses of a model’s behavior in response to biases, an approach sometimes referred to as “meta-explanation”, e.g., in the review by Speith [42]. However, due to the high costs associated with designing these datasets, progress has been limited. The advent of PFMs has mitigated some of these costs by facilitating artificial dataset creation for meta-explanation purposes, as illustrated by recent works in this area [164, 165, 152, 145].
- Use of Pretrained Foundation Models.
As previously noted, a fundamental aspect of meta explanations is the design of a probing dataset. Here, PFMs offer significant value by generating high-quality images with flexible customization options. For instance, [145] leverage stable diffusion to build a dataset featuring objects in varying contexts (e.g., with and without background), providing controlled conditions to study model biases. Similarly, [165] generate images that follow specific logical reasoning criteria, enhancing the robustness of bias analysis. Another advantage of PFMs is their ability to map both text and image data into a shared latent space, as demonstrated by [152], who use CLIP to represent model failures in this space as textual attributes, offering a more interpretable view of latent biases.
- Application and benchmark.
Currently, research on model biases in deep learning primarily targets the biases known to be particularly challenging, such as over-reliance on background features [145], societal biases that stem from dataset imbalances [152], and limitations in reasoning abilities [165]. Most of this work focuses on images representing everyday objects, including categories like food, transportation, and faces.
- Evaluation.
This type of explanation serves as a benchmark in itself, making direct comparisons between different meta-explanation techniques less meaningful. Instead, the evaluation of the quality of these methods is typically left to the discretion of the user, relying on qualitative examples to assess their effectiveness and relevance.
3.2.3 元解释数据集
定义。
一类 事后可解释性技术,旨在通过 探测模型在专门设计的辅助数据集上的响应 来解释模型的 全局功能,而无需修改模型的结构。这些数据集专门用于揭示 潜在偏差。解释 是通过 对整个数据集中模型行为的统计分析 生成的(见 图 11)。这些技术可以应用于任何模型。
背景。
深度神经网络中偏差的普遍性 引发了对研究 模型对各类偏差的敏感性 的广泛兴趣,[200] 的早期工作探索了这一主题。这一研究方向推动了 专门用于探测偏差的数据集 的创建,这些数据集要么通过 扩展现有数据集,要么通过 开发全新的数据集实现。此类数据集使得对 模型在偏差下的行为 进行 统计分析 成为可能,这种方法有时被称为 “元解释”,例如在 Speith 的综述中。然而,由于 设计这些数据集的高成本,进展有限。PFMs 的出现 通过促进 人工数据集的创建 来用于 元解释,缓解了部分成本,如 [164, 165, 152, 145] 等近期工作所示。
使用预训练基础模型。
如前所述,元解释 的一个基本方面是 探测数据集的设计。在这方面,PFMs 通过生成 高质量图像 并提供 灵活的定制选项 提供了重要价值。例如,[145] 利用 稳定扩散 构建了一个数据集,其中包含 不同背景下的对象(例如有背景和无背景),从而为研究 模型偏差 提供了 受控条件。类似地,[165] 生成 遵循特定逻辑推理标准 的图像,增强了 偏差分析 的 鲁棒性。PFMs 的另一个优势是能够将 文本和图像数据 映射到 共享潜在空间,如 [152] 所示,他们使用 CLIP 将 模型失败 表示为该空间中的 文本属性,从而提供了对 潜在偏差 的更 可解释的视图。
应用与基准。
目前,深度学习中的模型偏差研究 主要针对那些已知特别具有挑战性的偏差,例如 对背景特征的过度依赖、源于数据集不平衡的社会偏差以及 推理能力的局限性。大多数工作集中在 日常对象的图像 上,包括 食品、交通工具 和 人脸 等类别。
评估。
这种类型的解释本身就是一个 基准,使得 不同元解释技术之间的直接比较 变得不那么有意义。相反,这些方法的 质量评估 通常由用户自行决定,依赖于 定性示例 来评估其 有效性和相关性。
3.2.4. Neuron/layer interpretation
- Definition.
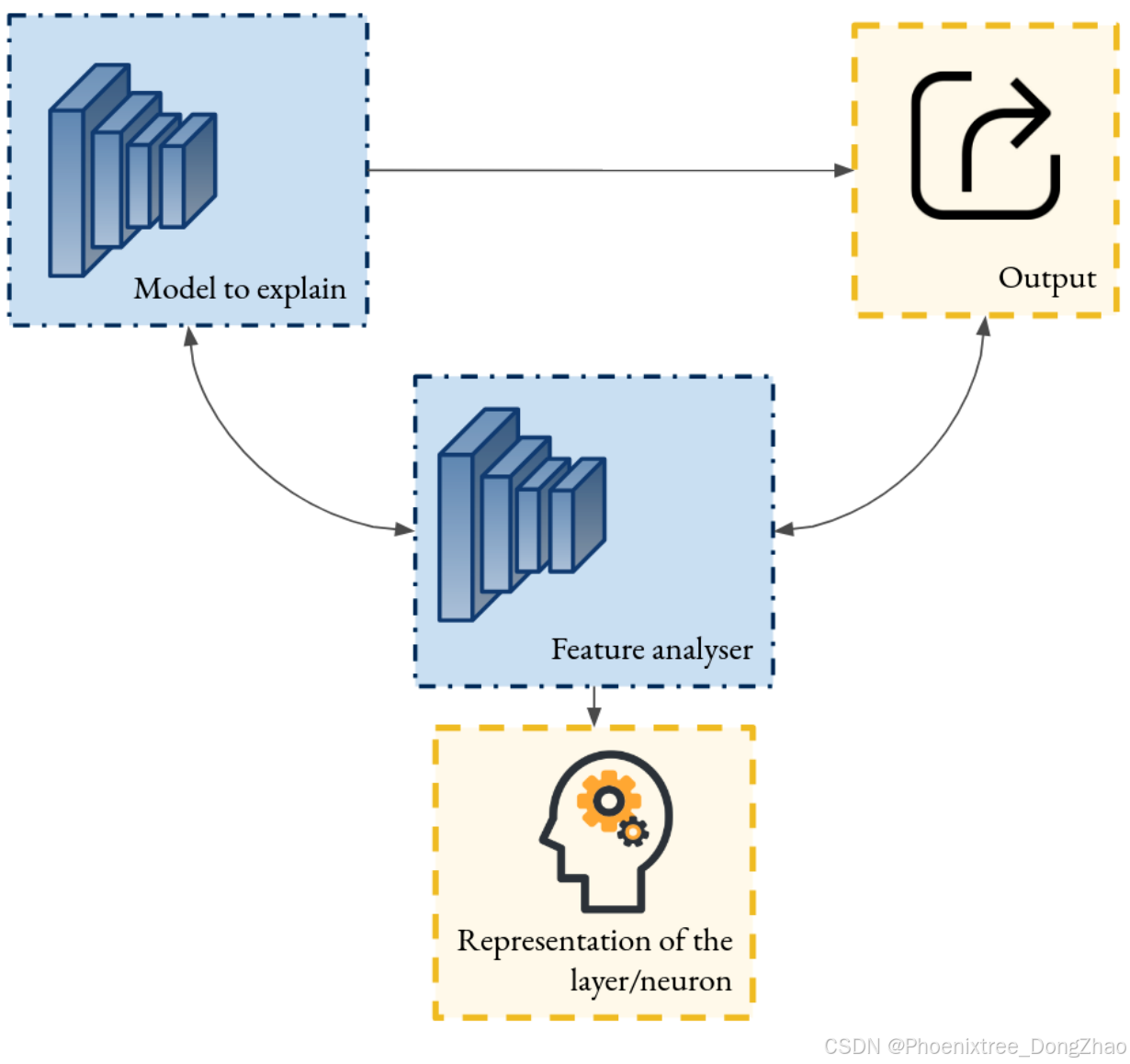
A family of post-hoc explainability techniques designed to explain the global functioning of a model without modifying the structure. These methods operate by identifying patterns that most strongly activate a specific neuron or layer within a DNN, as illustrated in Figure 12. Two primary strategies are commonly employed. The first involves optimization techniques, where the objective is to determine an input [157, 156] or latent space direction [112, 148] that maximizes the activation of the targeted pattern. In this case, the explanation is represented by the optimized input obtained through this process. The second strategy leverages a dataset of images, selecting the top-activating examples [163, 154]. Here, the explanation is provided by the subset of examples that elicit the strongest activations. These methods can be applied to any model.
Figure 12: Scheme of the principle of post-hoc explanation through neuron or layer interpretation. Given a specific layer or neuron to analyze, an optimization module is employed to probe the layer’s behavior. The output of this process provides insights into what the layer or neuron is sensitive to.
- Background.
As DNNs operate by extracting meaningful patterns to perform inference, a natural approach to understanding their behavior is to investigate which patterns trigger a selected layer or neuron. This type of analysis dates back to the earliest papers presenting foundational architectures, such as [203, 204]. Many approaches, often referred to as “feature visualization” [205], aim to reveal to the user the specific patterns a network focuses on during its processing. Despite the increasing width and complexity of modern networks, which make interpretation more challenging, numerous works continue to explore methods for interpreting layers. Notably, areas such as text-based interpretations and the relationship between prompts and latent space have become central themes in recent research.
- Use of Pretrained Foundation Models.
Compared to traditional feature visualization methods, the integration of PFMs allows for a more advanced analysis, extending beyond merely displaying the inputs to which the model is sensitive. PFMs enable the connection of these inputs to other modalities, offering a richer interpretability framework. For instance, CLIP can be used to relate the top-activating images to textual concepts, as seen in works by [147] and [154]. Additionally, CLIP enhances the optimization process in methods designed to interpret the relationship between prompts and generated images, particularly in text-to-image models [157, 156].
- Application and benchmark.
In terms of task types, we have identified two main areas of application. The first one is text-to-image translation, where neuron/layer interpretation is of particular interest due to the significance of prompt engineering. A deeper understanding of the relationship between the input prompt and the network’s behavior has substantial implications for the development of more effective prompt engineering techniques. The second type of task focuses on feature extraction, where the goal is to inspect a pretrained backbone model independently of the final output layer. Here, the focus is placed on understanding the behavior of specific portions of the network.
- Evaluation.
The evaluation of explanation quality is largely dependent on whether the method is applied to text-to-image generation or not. For image generation tasks, the quality of explanations often depends on the user’s intent, making perceptual distances and user studies key evaluation metrics. These evaluations focus on how well the generated explanations align with the intended manipulation or interpretation of the image. In contrast, for methods that inspect the backbone of a pretrained model, quantitative evaluations are more common. These evaluations often involve detecting expected samples or specific patterns on toy examples, providing a more objective measure of the method’s effectiveness in identifying meaningful network activations and features [154].
3.2.4 神经元/层解释
定义。
一类 事后可解释性技术,旨在解释模型的 全局功能,而无需修改模型的结构。这些方法通过 识别最强烈激活特定神经元或层的模式 来操作,如 图 12 所示。通常采用两种主要策略。第一种涉及 优化技术,其目标是确定一个 输入或 潜在空间方向,以 最大化目标模式的激活。在这种情况下,解释 由通过此过程获得的 优化输入 表示。第二种策略利用 图像数据集,选择 激活最强的示例。在这里,解释 由 引发最强激活的示例子集 提供。这些方法可以应用于任何模型。
背景。
由于 DNNs 通过提取 有意义的模式 来执行推理,理解其行为的自然方法是 研究哪些模式触发了选定的层或神经元。这种分析可以追溯到 最早提出基础架构的论文,例如 [203, 204]。许多方法,通常称为 “特征可视化”,旨在向用户揭示 网络在处理过程中关注的特定模式。尽管 现代网络的宽度和复杂性 不断增加,使得解释更具挑战性,但许多工作仍在探索 解释层的方法。值得注意的是,基于文本的解释 和 提示与潜在空间之间的关系 已成为 近期研究 的核心主题。
使用预训练基础模型。
与传统的 特征可视化方法 相比,PFMs 的集成 允许进行 更高级的分析,而不仅仅是显示模型敏感的输入。PFMs 能够将这些输入与其他 模态 连接起来,提供 更丰富的可解释性框架。例如,CLIP 可以用于将 激活最强的图像 与 文本概念 相关联,如 [147] 和 [154] 的工作所示。此外,CLIP 增强了 优化过程,特别是在 文本到图像模型 中,用于解释 提示与生成图像之间的关系。
应用与基准。
在任务类型方面,本文确定了两个主要的应用领域。第一个是 文本到图像翻译,其中 神经元/层解释 由于 提示工程的重要性 而特别受关注。对输入提示与网络行为之间关系的深入理解 对开发 更有效的提示工程技术 具有重要影响。第二种任务类型是 特征提取,其目标是 独立于最终输出层 检查 预训练的主干模型。在这里,重点是理解 网络特定部分的行为。
评估。
解释质量的评估 在很大程度上取决于该方法是否应用于 文本到图像生成。对于 图像生成任务,解释的质量通常取决于 用户的意图,因此 感知距离 和 用户研究 是关键评估指标。这些评估侧重于 生成的解释 与 图像的预期操作或解释 的 对齐程度。相比之下,对于 检查预训练主干模型 的方法,定量评估 更为常见。这些评估通常涉及在 玩具示例 上检测 预期样本或特定模式,从而提供 识别有意义网络激活和特征 的方法 有效性的客观衡量标准。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









