







《Topical Word Embeddings》
Liu Y, Liu Z, Chua T S, et al. 2015.
Abstract
大多数词嵌入模型通常使用单个向量来表示每个单词,因此这些模型无法区分同音异义和的一词多义的情况。为了增强判别性,我们采用潜在的主题模型为文本语料库中的每个词分配主题,并基于词和主题来学习主题词嵌入(TWE),这样我们可以灵活地获得情景词嵌入,来衡量情景中单词相似性。我们还可以构建文档的向量表示,这比一些广泛使用的文档模型(如潜在主题模型)更具有表现力。在实验中,我们评估TWE模型的两个任务:情景单词相似性和文本分类。实验结果表明,我们的模型比典型的词嵌入(包括基于上下文的词相似度的多种原型版本)表现更好,同时也优于文本分类的潜在主题模型和其他代表性文档模型。
本文的源代码可以从https://github.com/largelymfs/topical_word_embeddings 获取。
Introduction
词嵌入(word embedding),也被称为词表示( word representation),在基于语料库的上下文构建连续词向量中起着越来越重要的作用。词嵌入既能捕捉单词的语义信息,又能捕捉单词的相似性,因此广泛应用于各种IR和NLP任务中。
大多数词嵌入方法都是假定用每个词能够用单个向量代表,但是无法解决一词多义和同音异议的问题。多原型向量空间模型(Reisinger and Mooney 2010)是将一个单词的上下文分成不同的群(groups),然后为每个群生成不同的原型向量。遵循这个想法, (Huang et al. 2012) 提出了基于神经语言模型(Bengio et al. 2003)的多原型词嵌入。
尽管这些模型是有用的,但是多原型词嵌入面临以下几个挑战:(1)这些模型孤立地为每个词生成多原型向量,忽略了词之间复杂的相关性和它们的上下文。(2)在多原型设置中,一个单词的上下文被分成没有重叠的簇,而实际上,一个词的几个意义可能是相互关联的,它们之间没有明确的语义边界。
在本文中,我们提出了一个更加灵活更加强大的多原型单词嵌入框架——主题词嵌入(TWE),其中主题词是指以特定主题为背景的词。TWE的基本思想是,允许每个词在不同的主题下有不同的嵌入向量。例如,“苹果”这个词在食物主题下表示一个水果,而在IT主题下代表一个IT公司。
我们使用LDA(Blei, Ng, and Jordan 2003)来获取单词主题,执行collapsed Gibbs sampling (Griffiths and Steyvers 2004)来迭代地为每个单词令牌分配潜在的主题。这样,给定一个单词序列 D={ w1,...,wM} ,在使用LDA收敛后,每个单词 wi 被分配给一个特定的主题 zi ,形成一个单词-主题对 ⟨wi,zi⟩ ,用来学习主题词嵌入。我们设计了三种TWE模型来学习主题词向量,如图1所示,其中,窗口大小是1, wi−1 和 wi+1 是 wi 的上下文单词。
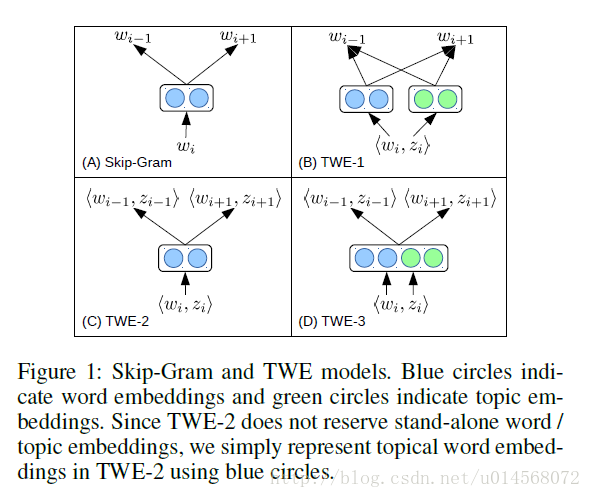
TWE-1. 我们将每个主题视为一个伪词(pseudo word),分别学习主题向量和词向量。然后根据向量 wi 和 zi 构建主题词向量 ⟨wi,zi⟩ 。
TWE-2. 我们将每个单词词-主题对 ⟨wi,zi⟩ 视为一个伪词(pseudo word),并直接学习到主题词向量。
TWE-3. 我们分别为每个词和每个主题保留不同的嵌入向量,通过连接相应的单词和主题向量来建立每个单词-主题对的向量。
对于这三个TWE模型,TWE-1没有考虑一个单词与其指定的学习主题之间的直接关联。TWE-2通过把单词-主题对视为一个伪词来考虑单词-主题对之间的内在联系,但是它存在稀疏性问题,因为出现的每个单词都被严格的区分为不同的主题。与之相比,TWE-3则在鉴别单词和稀疏性之间进行了平衡。但是在TWE-3的学习过程中,主题嵌入会影响对应的单词嵌入,这可能会导致同一主题中的单词不易辨别。
为了实现TWE模型,我们扩展了最先进的词嵌入模型Skip-Gram(Mikolov et al. 2013)。可以使用TWE模型来计算给定上下文的单词词嵌入,并且可以用词嵌入来表示一个从所有单词的单词-主题嵌入聚合得到的文档。
我们在两个任务上测试我们的模型——情景词相似度和文本分类。实验结果表明我们的模型在情景词的相似度上由于传统的和其他多元型词语嵌入模型,同时在文本分类上也超过了广泛使用的基于主题或基于嵌入向量的文本模型。
主要贡献:
- 将主题融入到基本的词嵌入表示中,并允许由此产生的主题词嵌入在不同语境下获得一个词的不同含义。
- 与分别为每个词建立多原型单词嵌入的模型相比,我们的模型通过利用主题模型来充分利用所有单词和它们的上下文,以此来学习主题词嵌入。
Our Models
Skip-Gram
Skip-Gram是一个众所周知的学习单词向量的框架(Mikolov et al. 2013),如图1(A)所示。Skip-Gram目标是预测滑动窗口中给定目标单词的上下文单词。在这个框架中,每个单词对应一个独特的向量。目标词的向量用来作为预测上下文单词的目标向量。
给定序列 D={
w1,...,wM} ,Skip-Gram的目标是最大化平均对数概率:
这里的 k 是目标单词的上下文大小。Skip-Gram使用softmax函数计算
这里 wi 和 wC 分别是目标单词 wi 和上下文单词 wC 的向量表示, W 是单词词汇表。为了使模型更有效地学习,我们使用分层softmax和负采样技术( Mikolov et al. 2013)。
通过Skip-Gram学习到的词向量可以用于计算词的相似度。单词
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1551
1551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









