







文章目录
介绍
**自然语言处理(Natural Language Processing,NLP)**是计算机科学领域与人工智能领域中的一个重要方向。它研究的是人类(自然)语言与计算机之间的交互。NLP的目标是让计算机能够理解、解析、生成人类语言,并且能够以有意义的方式回应和操作这些信息。
NLP的任务可以分为多个层次,包括但不限于:
- 词法分析:将文本分解成单词或标记(token),并识别它们的词性(如名词、动词等)。
- 句法分析:分析句子结构,理解句子中词语的关系,比如主语、谓语、宾语等。
- 语义分析:试图理解句子的实际含义,超越字面意义,捕捉隐含的信息。
- 语用分析:考虑上下文和对话背景,理解话语在特定情境下的使用目的。
- 情感分析:检测文本中表达的情感倾向,例如正面、负面或中立。
- 机器翻译:将一种自然语言转换为另一种自然语言。
- 问答系统:构建可以回答用户问题的系统。
- 文本摘要:从大量文本中提取关键信息,生成简短的摘要。
- 命名实体识别(NER):识别文本中提到的特定实体,如人名、地名、组织名等。
- 语音识别:将人类的语音转换为计算机可读的文字格式。
NLP技术的发展依赖于算法的进步、计算能力的提升以及大规模标注数据集的可用性。近年来,深度学习方法,特别是基于神经网络的语言模型,如BERT、GPT系列等,在许多NLP任务上取得了显著的成功。随着技术的进步,NLP正在被应用到越来越多的领域,包括客户服务、智能搜索、内容推荐、医疗健康等。
Word2Vec 介绍
Word2Vec 是一种广泛应用于自然语言处理(NLP)的算法,用于生成词向量(Word Embeddings),即将词语映射到一个连续的向量空间中。这些词向量能够捕捉词语之间的语义关系,使得语义相近的词语在向量空间中的位置也相近。Word2Vec 由 Google 的研究团队(Tomas Mikolov 等人)于 2013 年提出。
Word2Vec 的核心概念
-
词向量(Word Embeddings):
- 将词语表示为向量,向量的维度通常为几十到几百维。
- 通过训练,语义相近的词语在向量空间中的距离较近。
-
训练目标:
- Word2Vec 通过从大量文本中学习词语的上下文关系来生成词向量。
- 核心思想是:一个词语的语义可以通过它的上下文来推断。
-
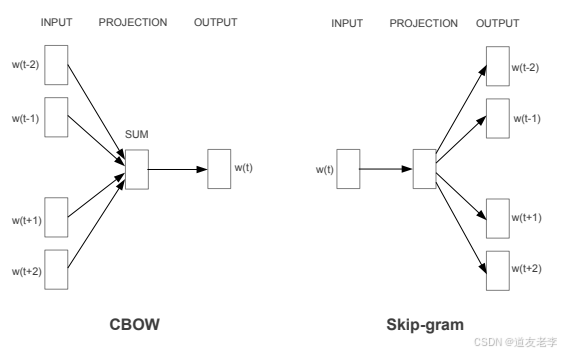
两种模型架构:
- CBOW(Continuous Bag of Words):
- 根据上下文词语预测目标词语。
- 训练速度较快,适合处理高频词。
- Skip-Gram:
- 根据目标词语预测上下文词语。
- 更适合处理低频词,训练时间较长,但对语义的捕捉更细致。
- CBOW(Continuous Bag of Words):
Word2Vec 的优点
- 语义捕捉能力强:
- 能够捕捉词语之间的语义关系,例如:
- 国王 - 男人 + 女人 ≈ 女王
- 北京 - 中国 + 法国 ≈ 巴黎
- 能够捕捉词语之间的语义关系,例如:
- 计算效率高:
- 相比于传统的词袋模型(Bag of Words),Word2Vec 生成的词向量维度更低,计算更高效。
- 可扩展性强:
- 可以应用于各种 NLP 任务,如文本分类、机器翻译、情感分析等。
Word2Vec 的缺点
- 无法处理多义词:
- 每个词语只有一个向量表示,无法区分多义词的不同含义。
- 依赖大量数据:
- 需要大规模的文本数据才能训练出高质量的词向量。
- 无法动态更新:
- 一旦模型训练完成,词向量就固定了,无法动态适应新词或新语义。
Word2Vec 的应用场景
- 文本分类:
- 将词向量作为输入特征,用于情感分析、垃圾邮件检测等任务。
- 机器翻译:
- 利用词向量的语义信息提升翻译质量。
- 推荐系统:
- 将用户行为或商品描述转化为向量,用于相似度计算。
- 问答系统:
- 通过词向量匹配问题和答案。
Word2Vec 的实现工具
- Gensim:
- Python 库,提供了简单易用的 Word2Vec 实现。
- 示例代码:
from gensim.models import Word2Vec sentences = [["我", "喜欢", "自然语言处理"], ["Word2Vec", "是", "一个", "强大", "的", "工具"]] model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, sg=1) # sg=1 表示使用 Skip-Gram print(model.wv["自然语言处理"]) # 输出 "自然语言处理" 的词向量
- TensorFlow / PyTorch:
- 可以手动实现 Word2Vec 模型。
- 预训练词向量:
- 例如 Google 提供的预训练 Word2Vec 模型(基于 Google News 数据集)。
总结
Word2Vec 是 NLP 领域的重要里程碑,它通过简单的神经网络模型将词语转化为向量,从而捕捉语义信息。尽管后续有更先进的模型(如 GloVe、FastText、BERT 等),Word2Vec 仍然是理解词向量和语义表示的基础工具。
Word2Vec 数学推导过程
Word2Vec 的数学推导过程主要围绕其两种模型架构:CBOW(Continuous Bag of Words) 和 Skip-Gram。这两种模型的核心思想是通过神经网络学习词语的分布式表示(词向量),并利用上下文信息来预测目标词语。
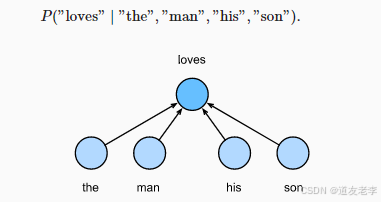
1. CBOW 模型的数学推导
CBOW 模型的目标是通过上下文词语预测目标词语。假设上下文窗口大小为 C C C,即每个目标词语有 C C C 个上下文词语。
(1)输入表示
- 假设词汇表大小为 V V V,词向量维度为 D D D。
- 每个词语用一个 one-hot 向量表示: x ∈ R V \mathbf{x} \in \mathbb{R}^V x∈RV。
- 输入是 C C C 个上下文词语的 one-hot 向量: x 1 , x 2 , … , x C \mathbf{x}_1, \mathbf{x}_2, \dots, \mathbf{x}_C x1,x2,…,xC。
(2)词向量矩阵
- 定义一个词向量矩阵 W ∈ R V × D \mathbf{W} \in \mathbb{R}^{V \times D} W∈RV×D,其中每一行对应一个词语的词向量。
- 上下文词语的词向量通过矩阵乘法得到:
v i = W ⊤ x i ( i = 1 , 2 , … , C ) \mathbf{v}_i = \mathbf{W}^\top \mathbf{x}_i \quad (i = 1, 2, \dots, C) vi=W⊤xi(i=1,2,…,C) - 将所有上下文词向量求平均:
v avg = 1 C ∑ i = 1 C v i \mathbf{v}_{\text{avg}} = \frac{1}{C} \sum_{i=1}^C \mathbf{v}_i vavg=C1∑i=1Cvi
(3)输出层
- 定义另一个矩阵 W ′ ∈ R D × V \mathbf{W}' \in \mathbb{R}^{D \times V} W′∈RD×V,用于将词向量映射回词汇表空间。
- 计算目标词语的得分:
z = W ′ ⊤ v avg \mathbf{z} = \mathbf{W}'^\top \mathbf{v}_{\text{avg}} z=W′⊤vavg - 使用 softmax 函数将得分转化为概率分布:
p ( y ∣ x 1 , x 2 , … , x C ) = softmax ( z ) p(\mathbf{y} | \mathbf{x}_1, \mathbf{x}_2, \dots, \mathbf{x}_C) = \text{softmax}(\mathbf{z}) p(y∣x1,x2,…,xC)=softmax(z)
其中:
softmax ( z i ) = exp ( z i ) ∑ j = 1 V exp ( z j ) \text{softmax}(z_i) = \frac{\exp(z_i)}{\sum_{j=1}^V \exp(z_j)} softmax(zi)=∑j=1Vexp(zj)exp(zi)
(4)损失函数
- 使用交叉熵损失函数:
L = − ∑ i = 1 V y i log ( p i ) \mathcal{L} = -\sum_{i=1}^V y_i \log(p_i) L=−∑i=1Vyilog(pi)
其中 y i y_i yi 是目标词语的 one-hot 标签, p i p_i pi 是模型预测的概率。
(5)参数更新
- 通过反向传播算法更新参数 W \mathbf{W} W 和 W ′ \mathbf{W}' W′。
2. Skip-Gram 模型的数学推导
Skip-Gram 模型的目标是通过目标词语预测其上下文词语。与 CBOW 相反,Skip-Gram 的输入是目标词语,输出是上下文词语。
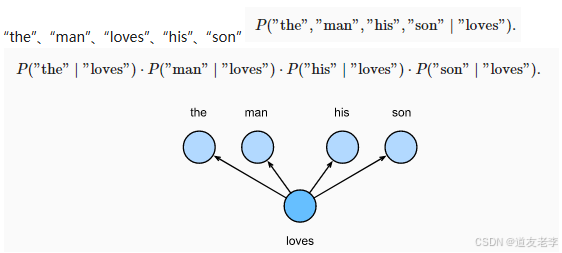
(1)输入表示
- 输入是目标词语的 one-hot 向量: x ∈ R V \mathbf{x} \in \mathbb{R}^V x∈RV。
(2)词向量矩阵
- 定义词向量矩阵
W
∈
R
V
×
D
\mathbf{W} \in \mathbb{R}^{V \times D}
W∈RV×D,目标词语的词向量为:
v = W ⊤ x \mathbf{v} = \mathbf{W}^\top \mathbf{x} v=W⊤x
(3)输出层
- 定义矩阵 W ′ ∈ R D × V \mathbf{W}' \in \mathbb{R}^{D \times V} W′∈RD×V,用于将词向量映射回词汇表空间。
- 计算上下文词语的得分:
z = W ′ ⊤ v \mathbf{z} = \mathbf{W}'^\top \mathbf{v} z=W′⊤v - 使用 softmax 函数将得分转化为概率分布:
p ( y j ∣ x ) = softmax ( z ) p(\mathbf{y}_j | \mathbf{x}) = \text{softmax}(\mathbf{z}) p(yj∣x)=softmax(z)
其中 y j \mathbf{y}_j yj 是第 j j j 个上下文词语的 one-hot 标签。
(4)损失函数
- Skip-Gram 的损失函数是多个上下文词语的交叉熵损失之和:
L = − ∑ j = 1 C ∑ i = 1 V y j i log ( p j i ) \mathcal{L} = -\sum_{j=1}^C \sum_{i=1}^V y_{ji} \log(p_{ji}) L=−∑j=1C∑i=1Vyjilog(pji)
其中 y j i y_{ji} yji 是第 j j j 个上下文词语的 one-hot 标签, p j i p_{ji} pji 是模型预测的概率。
(5)参数更新
- 通过反向传播算法更新参数 W \mathbf{W} W 和 W ′ \mathbf{W}' W′。
3. 优化技巧
为了提高训练效率,Word2Vec 使用了以下优化技巧:
(1)负采样(Negative Sampling)
- 在 softmax 计算中,分母需要对整个词汇表求和,计算量很大。
- 负采样通过随机采样少量负样本(非目标词语)来近似 softmax,从而减少计算量。
(2)层次 softmax(Hierarchical Softmax)
- 使用二叉树结构表示词汇表,将 softmax 的计算复杂度从 O ( V ) O(V) O(V) 降低到 O ( log V ) O(\log V) O(logV)。
4. 总结
Word2Vec 的数学推导过程可以概括为:
- 通过词向量矩阵将词语映射到低维空间。
- 使用上下文信息(CBOW 或 Skip-Gram)预测目标词语。
- 通过 softmax 计算概率分布,并使用交叉熵损失函数优化模型。
- 使用负采样或层次 softmax 加速训练。
Word2Vec 的核心思想是通过简单的神经网络模型学习词语的分布式表示,从而捕捉语义信息。



















 270
270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











