







AI视野·今日CS.CV 计算机视觉论文速览
Fri, 27 Sep 2019
Totally 55 papers
?上期速览✈更多精彩请移步主页

Interesting:
TODO(rjj): details of1-2
?Learned-PCGC点云几何压缩算法, 提出了一种基于变分自编码对点云几何PCG进行有效压缩的方法。(from 南京大学)


?***多粒度注意力机制的图像超分辨, (from 密歇根)



?**基于多信息提炼网络的轻量级图像超分辨, (from 西安电子科大)

?COPHY物理动力学的反事实推理, 提出了一种可以学习物理因果关系的反事实推理模型来从视觉输入中进行学习,并在合成三维数据环境中实现了很好的预测能力。(from 1LIRIS, INSA-Lyon 2Facebook AI Research 3LIFAT, INSA-CVL4Simon Fraser University, Borealis AI 5CITI, INRIA)

ref counterfactural, 1
?**STACNAS稳定且连续的进行可微分的神经架构搜索, (from 华为 诺亚实验室)

?****Liquid Warping GAN人体运动合成,外表迁移和新视角合成, (from 上海科技大学)




code:https://svip-lab.github.io/project/impersonator.html
?***隐含语义数据增强, 观察到特征空间中某些方向对应着有意义的语义变换,所以讲特征沿着语义方向进行变换增强(from 清华)

code:https://github.com/blackfeatherwang/ISDA-for-Deep-Networks
?多尺度动态特征编码去除图像摩尔条纹


?Deep Video Deblurring基于关键细节的去模糊

?+++RLBench 机器人学习基准和运行环境

?DISCOMAN 用于SLAM建图和导航的室内场景数据集,(from Samsung AI Center)

?WiderPerson 稠密情况下行人检测数据集

?FoodAI一个智能食物识别系统用于智能记录
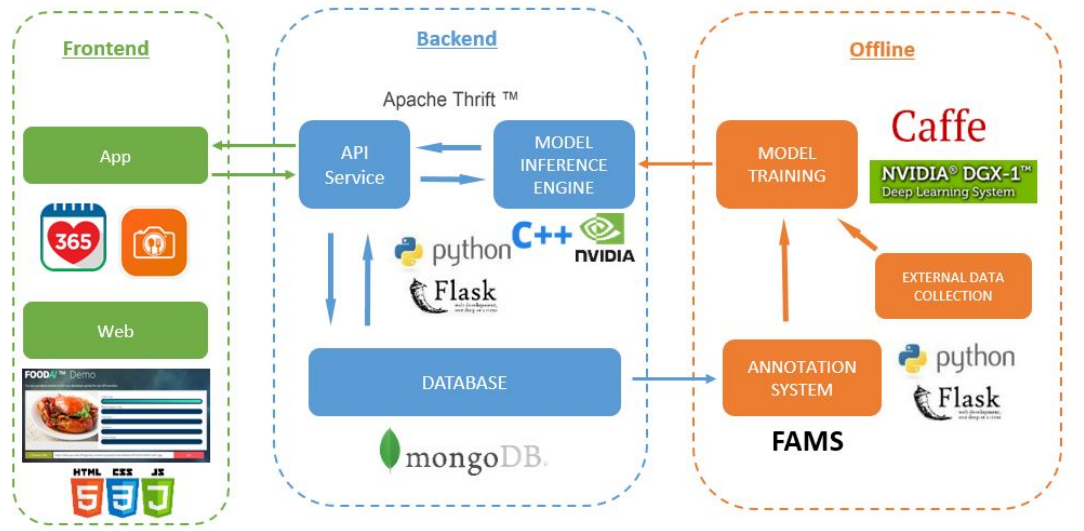
?在葡萄树上进行葡萄数量密度估计
?高速完整的基于点云的lidar回环系统
?基于VAE解耦图像的选择和平移,并应用在天文学和蛋白质数据上
?++平衡不同域间目标实例检测的gap

?**乳腺癌相关文章:
基于深度学习的低剂量高精度CT成像
乳腺癌病历组织检查分类 datset:ICIAR, BreakHis, PatchCamelyon, and Bioimaging
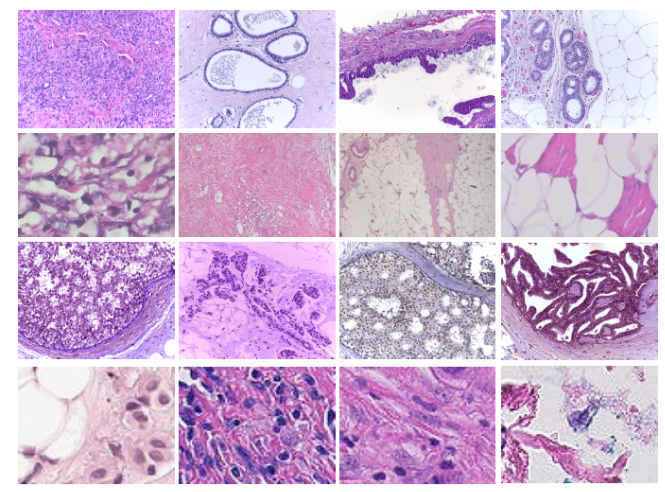
基于迁移学习和全局池化的乳腺癌检测
Daily Computer Vision Papers
| Range Adaptation for 3D Object Detection in LiDAR Authors Ze Wang, Sihao Ding, Ying Li, Minming Zhao, Sohini Roychowdhury, Andreas Wallin, Guillermo Sapiro, Qiang Qiu 基于LiDAR的3D对象检测在现代自动驾驶系统中起着至关重要的作用。 LiDAR数据通常在不同观察范围内表现出严重的特性变化。在本文中,我们探索了使用LiDAR进行3D对象检测的跨范围自适应,即远距离观测适用于近距离。这样,优化了远距离检测以实现与近距离检测相似的性能。我们采用鸟瞰BEV检测框架来执行建议的模型适配。我们的模型适应包括对抗性全局适应和细粒度局部适应。所提出的跨范围自适应框架已在基于LiDAR的三种最先进的物体检测网络上得到了验证,并且我们始终观察到远距离物体的性能有所提高,而没有向模型中添加任何辅助参数。据我们所知,本文是研究跨距离LiDAR自适应以进行点云中目标检测的首次尝试。为了证明所提出的适应框架的通用性,进一步进行了更具挑战性的跨设备适应性实验,并发布了具有高质量带注释点云的新LiDAR数据集,以促进未来的研究。 |
| Video Surveillance of Highway Traffic Events by Deep Learning Architectures Authors Matteo Tiezzi, Stefano Melacci, Marco Maggini, Angelo Frosini 在本文中,我们描述了一种视频监视系统,该系统能够检测高速公路上固定摄像机拍摄的视频中的交通事件。感兴趣的事件包括视频中发生的特定情况序列,例如在紧急车道上停车的车辆。因此,检测这些事件需要分析视频流中的时间序列。我们比较了利用基于递归神经网络RNN和卷积神经网络CNN的体系结构的不同方法。第一种方法从每个视频帧中提取主要与运动有关的特征向量,并利用馈入所得向量序列的RNN。其他方法直接基于帧序列,这些帧最终会以逐像素运动信息丰富。所获得的流由堆叠CNN和RNN的体系结构处理,并且我们还研究了基于转移学习的模型。结果是非常有希望的,最好的架构将在实际操作条件下在线测试。 |
| Liquid Warping GAN: A Unified Framework for Human Motion Imitation, Appearance Transfer and Novel View Synthesis Authors Wen Liu, Zhixin Piao, Jie Min, Wenhan Luo, Lin Ma, Shenghua Gao 我们在一个统一的框架内处理人类的运动模仿,外观转移和新颖的视图合成,这意味着该模型一旦经过训练即可用于处理所有这些任务。现有的任务特定方法主要使用2D关键点姿势来估计人体结构。但是,它们仅表达位置信息,而无法表征个人的个性化形状并模拟肢体旋转。在本文中,我们建议使用3D身体网格恢复模块来解开姿势和形状,该模块不仅可以建模关节的位置和旋转,而且可以表征个性化的身体形状。为了保留源信息,例如纹理,样式,颜色和脸部身份,我们提出了带有液体翘曲块LWB的液体翘曲GAN,它可以在图像和特征空间中传播源信息,并相对于参考图像进行合成。具体地,通过去噪卷积自动编码器提取源特征以很好地表征源身份。此外,我们提出的方法能够支持来自多个来源的更灵活的变形。此外,我们建立了一个新的数据集,即Impersonator iPER数据集,用于评估人体运动模仿,外观转移和新颖的视图合成。大量的实验证明了我们方法在多个方面的有效性,例如在遮盖情况下的鲁棒性以及保持面部身份,形状一致性和衣服细节。所有代码和数据集均可在 |
| Implicit Semantic Data Augmentation for Deep Networks Authors Yulin Wang, Xuran Pan, Shiji Song, Hong Zhang, Cheng Wu, Gao Huang 在本文中,我们提出了一种新颖的隐式语义数据扩充ISDA方法,以补充诸如翻转,平移或旋转之类的传统扩充技术。我们的工作受到有趣的属性的启发,即深层网络惊人地擅长于线性化特征,从而使深层特征空间中的某些方向对应于有意义的语义转换,例如添加太阳镜或更改背景。结果,在特征空间中沿许多语义方向翻译训练样本可以有效地扩展数据集以提高泛化性。为了有效,高效地实现这一思想,我们首先对每个类别的深度特征的协方差矩阵进行在线估计,以获取类别内语义的变化。然后从具有估计协方差的零均值正态分布中提取随机向量,以增强该类别中的训练数据。重要的是,代替显式地扩展样本,我们可以直接最小化扩展训练集上预期交叉熵CE损失的上限,从而产生高效 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









