










 本文探讨了基于计算机视觉生成人物文字描述的技术,如CogView,通过Transformer模型提升多模态理解。研究了如何在运动模糊与超分辨率中结合动态和静态处理,以及如何处理人物描述的伦理困境。BMDSRNet展示了在单帧图像中恢复清晰图像的创新方法。
本文探讨了基于计算机视觉生成人物文字描述的技术,如CogView,通过Transformer模型提升多模态理解。研究了如何在运动模糊与超分辨率中结合动态和静态处理,以及如何处理人物描述的伦理困境。BMDSRNet展示了在单帧图像中恢复清晰图像的创新方法。
AI视野·今日CS.CV 计算机视觉论文速览
Fri, 28 May 2021
Totally 42 papers
👉上期速览✈更多精彩请移步主页

Interesting:
📚CogView, 基于transformer的text2image方法(from 清华 达摩院)
多模态统一的text2img,值得学习;视觉问答+transformer的调优方式,结果很不错。

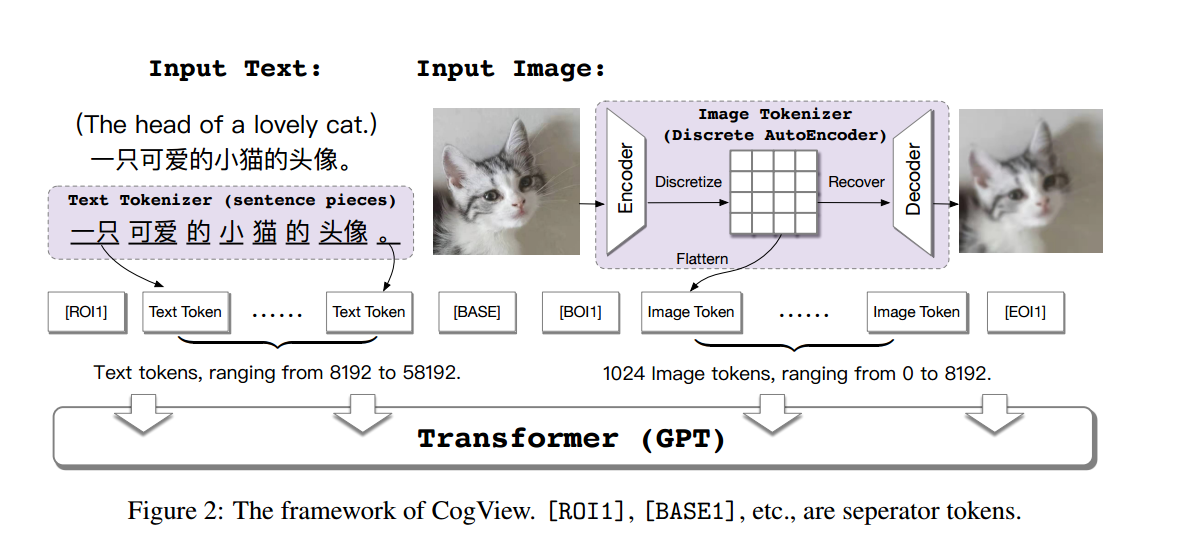
https://lab.aminer.cn/cogview/index.html
https://github.com/THUDM/CogView
📚Computer Vision and Conflicting Values, 从图片中如何生成人物的文字描述。(from )

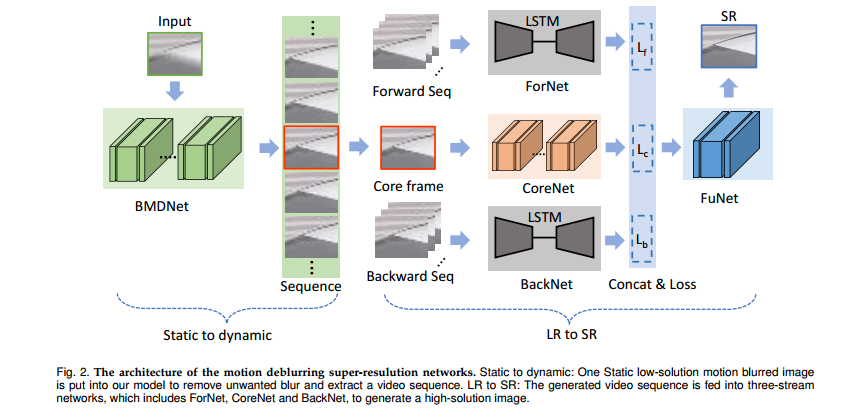
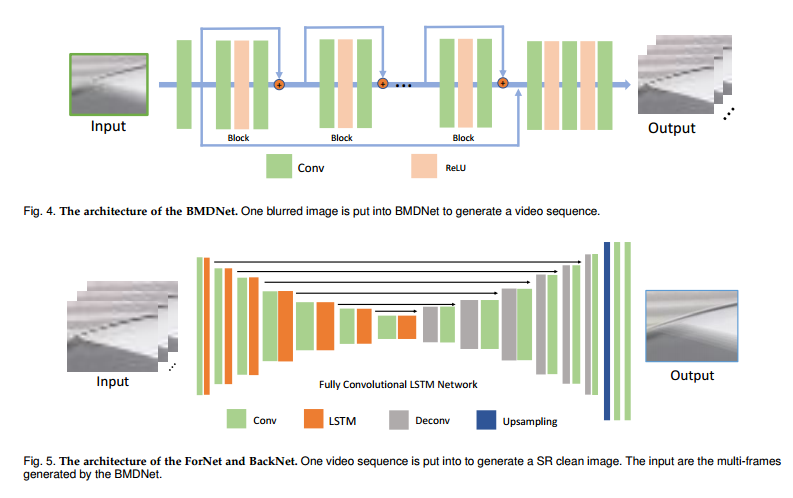
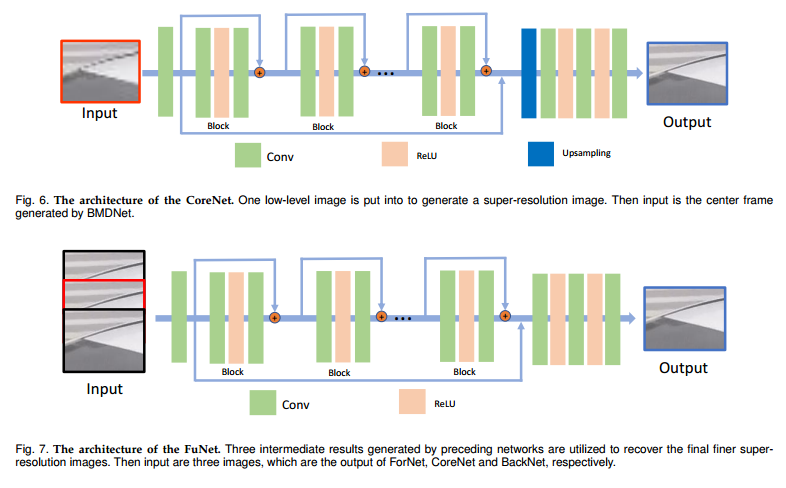
📚BMDSRNet, 运动模糊与超分辨处理结合的模型,结合动态和静态处理(from 河北工业大学)
Blind Motion Deblurring Super-Reslution Networks, BMDSRNet, is proposed to learn dynamic spatio-temporal information from single static motion-blurred images. Motion-blurred images are the accumulation over time during the exposure of cameras, while the proposed BMDSRNet learns the reverse process and uses three-streams to learn Bidirectional spatio-temporal information based on well designed reconstruction loss functions to recover clean high-resolution images.
📚Style-VTON, 高效的虚拟试装网络(from )
Daily Computer Vision Papers
| Unsupervised Activity Segmentation by Joint Representation Learning and Online Clustering Authors Sateesh Kumar, Sanjay Haresh, Awais Ahmed, Andrey Konin, M. Zeeshan Zia, Quoc Huy Tran 我们为无监督活动分割提出了一种新颖的方法,它使用视频帧聚类作为借口任务,并同时执行表示学习和在线群集。这与先前作品相反,其中通常顺序地执行表示学习和在线群集。我们通过采用时间最佳运输和时间相干损失来利用视频中的时间信息。特别是,我们将时间正则化术语纳入标准最优传输模块,该模块保留了活动的时间顺序,产生用于计算伪标签群集分配的时间最优传输模块。接下来,时间相干损耗鼓励邻近视频帧映射到附近的点,而远处视频帧被映射到嵌入空间中的远处点。这两个组分的组合导致无监督活动细分的有效陈述。此外,先前的方法需要在以离线方式培养整个数据集之前存储学习功能,而我们的方法在在线方式一次处理一个迷你批次。在三个公共数据集的广泛评估,即50个沙拉,YouTube说明和早餐,以及我们的数据集,即桌面装配,表明我们的方法在PAR或更好地表现出对未经监督的活动分割的先前方法,尽管内存限制显着较低。 |
| Tracking Without Re-recognition in Humans and Machines Authors Drew Linsley, Girik Malik, Junkyung Kim, Lakshmi N Govindarajan, Ennio Mingolla, Thomas Serre 想象一下,试图在百分之一的人中跟踪一个特定的果蝇。较高的生物视觉系统通过依赖于外观和运动特征来追踪移动物体。我们调查用于视觉跟踪的最先神经网络的状态是否能够相同。为此,我们介绍了往返于综合视觉挑战的综合视觉挑战,要求人类观察者和机器在相同的观看的分散组对象中跟踪目标物体。虽然人类毫不费力地学习路地,但概括了任务设计的系统变化,艺术深度网络的斗争。为了解决本限制,我们识别和模型在基于运动提示基于运动提示跟踪对象的生物大脑中的电路机制。当被实例化作为经常性网络时,我们的电路模型学会了解往返往返策略的轨客攻击,竞争于人类性能,并解释了他们对挑战作出决策的大量比例。我们还表明,该电路模型的成功延伸到自然视频中的对象跟踪。将基于变压器的架构添加到用于对象跟踪的架构构建对影响对象外观的视觉滋扰的容差,从而在大规模跟踪网对象跟踪挑战上产生新的最新状态。我们的工作凸显了建设人工视觉模型的重要性,这些模型可以帮助我们更好地了解人类的愿景并改善计算机视觉。 |
| CogView: Mastering Text-to-Image Generation via Transformers Authors Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, Jie Tang 常规域中的图像生成的文本长期以来一直是一个开放的问题,这需要生成模型和跨模仿理解。我们提出CogView,一个带VQ VAE牌器的40亿参数变压器来推进此问题。我们还展示了各种下游任务的FineTuning策略,例如,风格学习,超级分辨率,文本图像排名和时装设计,以及稳定预制尺寸预测的方法。消除南损失。 Cogview Zero Shot达到了模糊的MS Coco上的最新状态,以前的GAN模型和最近的类似工作Dall E. |
| Dynamic Network selection for the Object Detection task: why it matters and what we (didn't) achieve Authors Emanuele Vitali, Anton Lokhmotov, Gianluca Palermo 在本文中,我们希望展示深神经网络DNN上下文中推断过程的动态自动调谐方法的潜在好处,解决对象检测挑战。我们基准显示不同的神经网络,为众所周知的CoCo 17数据库找到最佳探测器,我们证明了即使我们只考虑预测的质量,也没有单个最优网络。如果我们也考虑到可评估的度量标准,则这更明显,然后选择,选择,最合适的网络。这将打开根据运行时要求在不同的对象检测网络之间切换自适应方法的可能性。最大质量在于解决方案约束的时间。 |
| ICDAR 2021 Competition on Historical Map Segmentation Authors Joseph Chazalon 1 , Edwin Carlinet 1 , Yizi Chen 1 and 2 , Julien Perret 2 and 3 , Bertrand Dum nieu 3 , Cl ment Mallet 2 , Thierry G raud 1 , Vincent Nguyen 4 and 5 , Nam Nguyen 4 , Josef Baloun 6 and 7 , Ladislav Lenc 6 and 7 , Pavel Kr l 6 and 7 1 EPITA Research and Development Lab. LRDE , EPITA, France, 2 Univ. Gustave Eiffel, IGN ENSG, LaSTIG, France, 3 LaD HiS, CRH, EHESS, France, 4 L3i, University of La Rochelle, France, 5 Liris, INSA Lyon, France, 6 Department of Computer Science and Engineering, University of West Bohemia, Univerzitn , Pilsen, Czech Republic, 7 NTIS New Technologies for the Information Society, University of West Bohemia, Univerzitn , Pilsen, Czech Republic 本文介绍了历史地图分割MAPSEG上的ICDAR 2021竞争的最终结果,鼓励对法国巴黎的一系列历史地图空间的研究,在1894年至1937年间绘制了1 5000规模。比赛专为三个任务而分开授予。任务1包括检测构建块,并由L3IRIS团队使用DENSENET 121网络以弱监督的方式培训。在包含数百个形状的3个大图像上评估此任务以检测。任务2包括从较大的地图表中分段地图内容,并由UWB团队使用像FCN的UNET相结合的UWB团队,以提高检测边缘精度。任务3包括定位Geo引用行的交叉点,也由使用专用管道组合二值化的UWB团队赢得,与Hough变换,候选滤波和模板匹配的交叉变换。任务2和3在具有复杂内容的95张映射纸上进行评估。数据集,评估工具和结果可在URL的许可许可下提供 |
| How saccadic vision might help with theinterpretability of deep networks Authors Iana Sereda, Grigory Osipov 我们描述了如何解决一些问题,通过调整感知生物合理的宏观机制来解决现代深度网络的对象导向。提出了这种扫视视觉模型的草图。概念实验结果证明是支持提出的方法。 |
| Using Early-Learning Regularization to Classify Real-World Noisy Data Authors Alessio Galatolo, Alfred Nilsson, Roderick Karlemstrand, Yineng Wang 记忆问题在计算机视野领域是众所周知的。刘等。提出一种称为早期学习正规化的技术,这在存在标签噪声时提高了CIFAR数据集的准确性。该项目复制了他们的实验,并通过内在噪声调查了真实世界数据集的性能。结果表明,他们的实验结果是一致的。除了SGD外,我们还探讨了清晰度意识的最小化,并观察到进一步的14.6个百分点。未来的工作包括使用所有600万图像并手动清洁图像的一小部分以微调转移学习模型。最后但并非最不重要的是,可以访问用于测试的清洁数据也将改善精度的测量。 |
| A Dataset for Provident Vehicle Detection at Night Authors Sascha Saralajew, Lars Ohnemus, Lukas Ewecker, Ebubekir Asan, Simon Isele, Stefan Roos 在当前对象检测中,算法需要将对象直接可见,以便被检测到。然而,作为人类,我们直观地使用由各个物体引起的视觉暗示来造成其外观的假设。在驾驶的背景下,这种提示可以在白天是阴影,并且在夜间经常反射。在本文中,我们研究了如何将这种直观的人类行为映射到计算机视觉算法,以便在夜晚的光线反射中检测迎面而来的车辆。为此,我们展示了一个广泛的开源数据集,其中包含59746个注释的灰度图像,在农村环境中的346个不同的场景中,在夜间环境中的346个。在这些图像中,所有迎面而来的车辆,它们相应的光对象例如,前照灯和它们各自的光反射都是标记的光反射。在这种情况下,我们讨论了数据集的特征以及客观地描述视觉提示等视觉思考的挑战。我们为不同的方式提供不同的指标来接近任务,并报告使用现有技术和自定义对象检测模型实现的结果作为第一个基准。有了这个,我们希望注意计算机视觉研究中的一个新的,到目前为止的忽视领域,鼓励更多的研究人员解决问题,从而进一步揭示人类性能和计算机视觉系统之间的差距。 |
| Pose2Drone: A Skeleton-Pose-based Framework forHuman-Drone Interaction Authors Zdravko Marinov, Stanka Vasileva, Qing Wang, Constantin Seibold, Jiaming Zhang, Rainer Stiefelhagen 无人机已成为一个共同的工具,其在许多任务中使用,例如航空摄影,监视和交付。但是,操作无人机需要越来越多的与用户的交互。用于人类无人机交互HDI的自然和安全方法使用手势。在本文中,我们在基于骨架的姿势估计上引入了HDI框架构建。我们的框架提供了控制无人机与简单手臂手势的动作的功能,并在保持安全距离的同时跟随用户。我们还提出了一种单眼距离估计方法,其完全基于图像特征,并且不需要任何额外的深度传感器。为了进行全面的实验和定量分析,我们创建了一个定制的测试数据集。实验表明,我们的HDI框架可以在识别11个常见手势中平均达到93.5的准确性。该代码将公开可供使未来的研究培养。代码可用 |
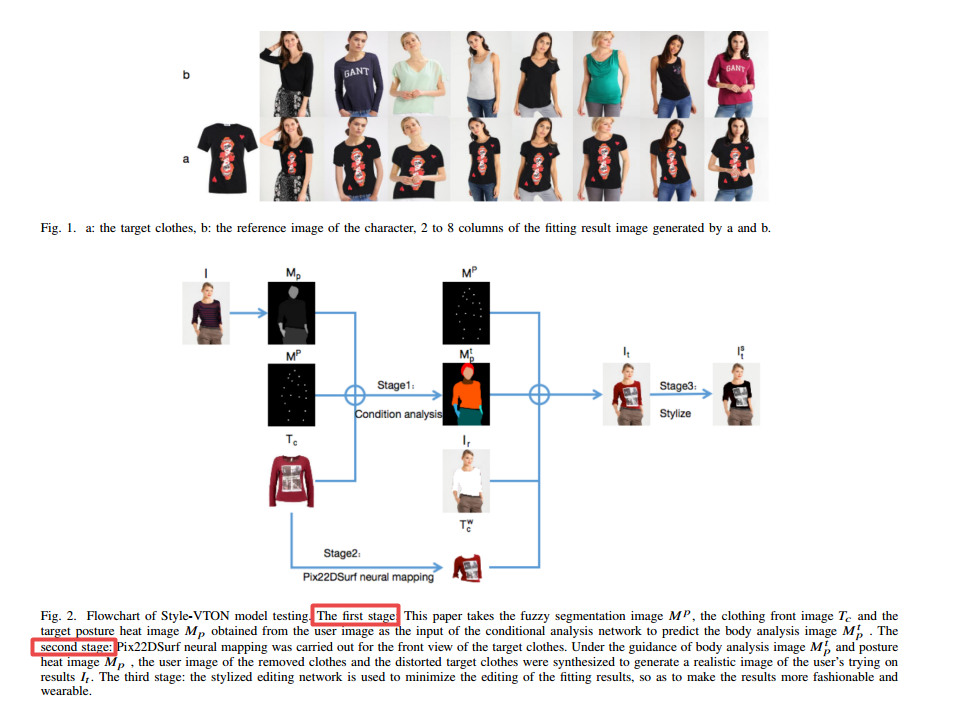
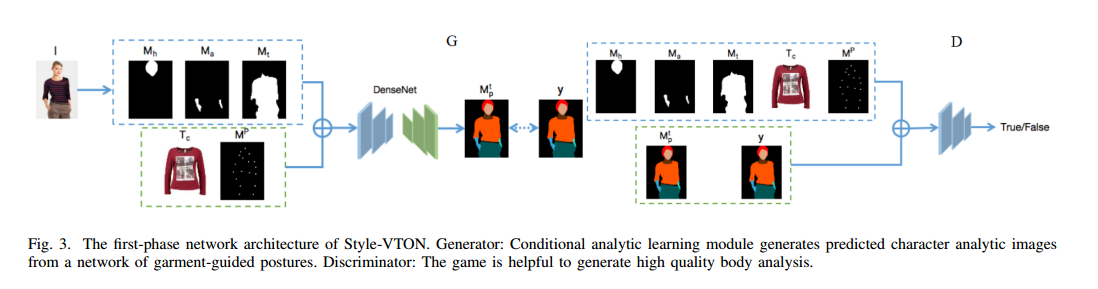
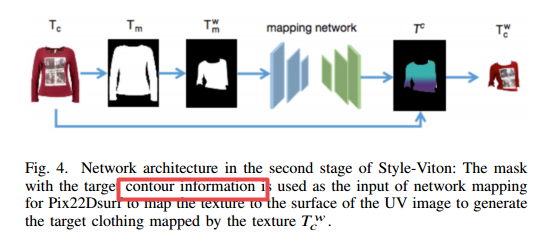
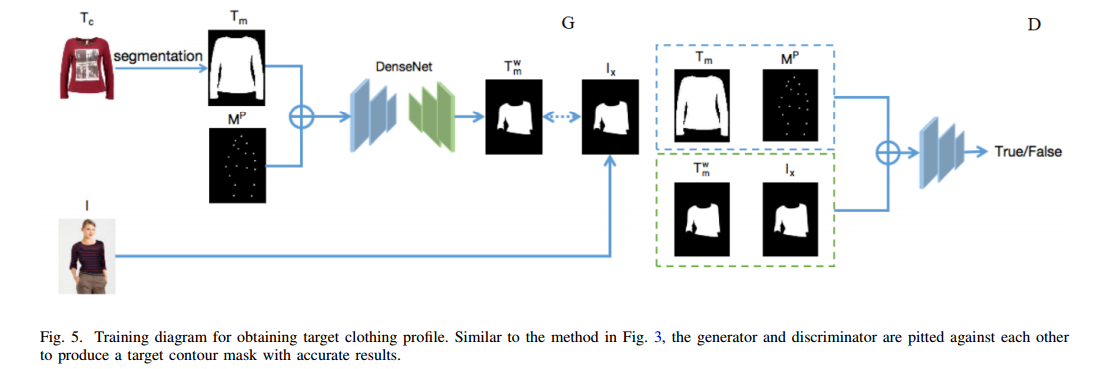
| An Efficient Style Virtual Try on Network Authors Shanchen Pang, Xixi Tao, Yukun Dong 随着服装制造业的发展越来越多,越来越多地支付了与工业以降低产品冗余的行业结合神经网络的方法 |
| When Liebig's Barrel Meets Facial Landmark Detection: A Practical Model Authors Haibo Jin, Jinpeng Li, Shengcai Liao, Ling Shao 近年来,在面部地标检测的研究中取得了重大进展。然而,很少有效地讨论了实际应用的模型。相反,他们经常专注于一次在忽略其他人的时间内改进几个问题。为了弥合这一差距,我们的目标是探索一个准确,坚固,高效,更广泛的实用模型,并同时结束终端培训。为此,我们首先提出一个配备有一个变压器解码器作为检测头的基线模型。为了实现更好的准确性,我们进一步提出了两个轻量级模块,即动态查询初始化DQInit和查询感知内存Qamem。具体而言,DQInit动态地从输入中初始化解码器的查询,使模型能够实现为具有多个解码器层的良好准确性。 Qamem旨在通过将单独的存储器值分配给每个查询而不是共享的,增强低分辨率特征映射的查询的判别能力。在Qamem的帮助下,我们的模型消除了对高分辨率特征映射的依赖,并且仍然能够获得卓越的准确性。三种流行基准的广泛实验和分析表明了拟议模型的有效性和实际优势。值得注意的是,我们的模型在WFLW上实现了新的技术状态,以及300W和COFW的竞争结果,同时仍在50 FPS运行。 |
| Blind Motion Deblurring Super-Resolution: When Dynamic Spatio-Temporal Learning Meets Static Image Understanding Authors Wenjia Niu, Kaihao Zhang, Wenhan Luo, Yiran Zhong, Xin Yu, Hongdong Li 单个图像超分辨率SR和多帧SR是超级解析低分辨率图像的两种方法。单个图像SR通常独立处理每个图像,但忽略在继续帧中隐含的时间信息。多帧SR能够通过捕获运动信息来模拟时间依赖性。但是,它依赖于在现实世界中并不总是可用的邻近框架。同时,轻微的相机抖动很容易导致长距离拍摄低分辨率图像的重型运动模糊。为了解决这些问题,提出了一种盲运动去掩模超级恢复网络,BMDSRNET,用于从单个静态运动模糊图像中学习动态时空时间信息。运动模糊图像是摄像机曝光期间的累积时间,而建议的BMDSRNET学习反向过程,并使用三个流基于精心设计的重建损耗函数来学习双向时空时间信息以恢复清洁的高分辨率图像。广泛的实验表明,所提出的BMDSRNET优于最近现有技术的方法,具有同时处理图像去孔和SR的能力。 |
| The Imaginative Generative Adversarial Network: Automatic Data Augmentation for Dynamic Skeleton-Based Hand Gesture and Human Action Recognition Authors Junxiao Shen, John Dudley, Per Ola Kristensson 深入学习方法在识别时空人类运动数据的情况下提供最新性能的状态。但是,这些识别任务中的主要挑战之一是有限的可用培训数据。培训数据不足导致拟合和数据增强是一种解决这一挑战的方法。现有的数据增强策略,如转换,包括缩放,移位和插值,需要高参数优化,可以容易地花费数百个GPU小时。在本文中,我们提出了一种新型的自动数据增强模型,该模型近似于该分布的输入数据的分布和样本新数据的难以想象的生成的对抗性网络GaN。它是自动的,因为它不需要数据检查,并且很少的超参数调整,因此它是生成合成数据的低成本和低成本方法。所提出的数据增强策略快速训练,合成数据导致更高的识别精度,而不是使用经典方法增强数据。 |
| SSAN: Separable Self-Attention Network for Video Representation Learning Authors Xudong Guo, Xun Guo, Yan Lu 由于建模长距离依赖性的有效性,已成功应用于视频表示学习。现有方法仅通过同时计算沿空间和时间尺寸的成对相关性来构建依赖关系。然而,空间相关性和时间相关性表示场景和时间推理的不同上下文信息。直观地,学习空间上下文信息首先将有利于时间建模。在本文中,我们提出了一种可分离的自我注意SSA模块,其依次模拟空间和时间相关性,从而可以在时间建模中有效地使用空间上下文。通过将SSA模块添加到2D CNN中,我们构建一个SSA网络SSAN进行视频表示学习。关于视频动作识别的任务,我们的方法优于现有方法的状态和动力学400数据集的状态。我们的模型通常优于较浅的网络和更少的方式。我们进一步验证了我们在视频检索的视觉语言任务中的方法的语义学习能力,展示了视频表示和文本嵌入的同质性。在MSR VTT和YOUCOOK2数据集上,SSA学习的视频表示显着提高了最先进的性能状态。 |
| Stylizing 3D Scene via Implicit Representation and HyperNetwork Authors Pei Ze Chiang, Meng Shiun Tsai, Hung Yu Tseng, Wei sheng Lai, Wei Chen Chiu 在这项工作中,我们的目标是在任意新颖的视图角度地解决生成场景的程式化图像的3D场景程式化问题。直接解决方案是将现有的新颖观看合成和图像视频风格转移方法组合,这通常会导致模糊的结果或外观不一致。灵感来自神经辐射场NERF方法的高质量结果,我们提出了一个联合框架,直接用所需风格呈现新颖的视图。我们的框架由两个组件组成了具有神经辐射场模型的3D场景的隐式表示,以及将样式信息转移到场景表示中的HyperNetwork。特别是,我们的隐式表示模型将场景解除到几何和外观分支中,Hypernetwork学会从参考样式图像预测外观分支的参数。为了缓解培训困难和记忆负担,我们提出了两个阶段的培训程序和补丁子采样方法,以优化了神经辐射场模型的风格和内容损失。优化后,我们的模型能够以任意样式的任意视角呈现一致的新颖视图。定量评估和人类主题研究已经证明,该方法产生忠实的程式化结果,在不同视图上具有一致的外观。 |
| PSRR-MaxpoolNMS: Pyramid Shifted MaxpoolNMS with Relationship Recovery Authors Tianyi Zhang, Jie Lin, Peng Hu, Bin Zhao, Mohamed M. Sabry Aly 非最大抑制NMS是用于物体检测的现代卷积神经网络的必要性后处理步骤。与本质上的卷积不同,NMS的DE事实标准,即GreeNynm,不能轻易并行化,因此可以是卷积物体检测管道中的性能瓶颈。 MaxPoolNMS被引入并行的综合替代方案,曲率又可以在可比准确率下实现比GREEDYNM更快的速度。然而,MaxPoolnms仅能够在两个阶段探测器的第一阶段更换Gredynms,如RCNN更快。在最终检测阶段应用MaxPoolnms时,在最终检测阶段应用MaxPoolnms,由于MaxPoolnms在边界框选择方面可以准确地近似Greexynms,因此有显着下降。在本文中,我们提出了一般,并行化和可配置的方法PSRR MaxPoolnms,以在所有探测器中的所有阶段完全替换综合鼠。通过引入简单的关系恢复模块和金字塔移位的MAXPOOLNMS模块,我们的PSRR MAXPOOLNMS能够比MAXPOOLNMS更精确地近似蠕变。综合实验表明,我们的方法优于MaxPoolnms的大幅度,并且其比具有可比准确性的磁力速度更快。首次,PSRR MAXPOOLNMS为定制硬件设计提供了一个完全并化的解决方案,可以重用以加速到处的NMS。 |
| Joint-DetNAS: Upgrade Your Detector with NAS, Pruning and Dynamic Distillation Authors Lewei Yao, Renjie Pi, Hang Xu, Wei Zhang, Zhenguo Li, Tong Zhang 我们提出了一个关于对象检测的统一NAS框架的联合Detnas,它集成了3个关键组件神经结构搜索,修剪和知识蒸馏。我们的联合Detnas联合优化了它们,而不是天真地流水。该算法由两个核心进程组成,学生怪异优化学生的架构并消除冗余参数,而动态蒸馏旨在找到最佳匹配教师。对于学生思维方式,采用了重量继承策略,允许学生灵活地更新其体系结构,同时充分利用前身的S权重,这显着加速了搜索,以便于动态蒸馏,通过集成的渐进缩小策略培训,从中培训弹性教师池可以在后续搜索中进行对教师探测器进行采样,而无需额外成本。鉴于基本检测器作为输入,我们的算法直接输出具有高性能的派生学生检测器,无需额外培训。实验表明,我们的联合Detnas优于朴素的流水线方法。考虑到经典R101 FPN作为基础检测器,联合DetNA能够在MS Coco上将其映射从41.4升至43.9,并减少47的延迟,这与SOTA高效指数有关,同时需要更少的搜索成本。我们希望我们的建议方法能够以共同优化NAS,KD和修剪的新方式提供社区。 |
| Feature Reuse and Fusion for Real-time Semantic segmentation Authors Tan Sixiang 对于实时语义分割,如何提高速度,同时保持高分辨率是已经讨论和解决的问题。骨干设计和融合设计始终是实时语义细分的两个基本部分。我们希望根据先前的设计经验设计轻量级网络,并在没有任何预训练的情况下达到最新的实时语义细分状态。为了实现这一目标,提出了一种编码器解码器架构来解决这个问题来解决这个问题,通过将解码器网络应用于设计用于实时分割任务的骨干模型,并设计了三种不同的方法来融合阶段的熔断器语义和详细信息。我们对两个语义分割基准进行了广泛的实验。 CityScapes和Camvid数据集上的实验表明,所提出的FRFNET在速度计算和准确性之间击中平衡。它达到了76.4均匀的联盟Miou在CityCapes测试数据集上的平均交叉点,在单个RTX 2080Ti卡上的速度为161 FPS。代码可用 |
| Unsupervised Adaptive Semantic Segmentation with Local Lipschitz Constraint Authors Guanyu Cai, Lianghua He 无监督域适应的最新进展在语义细分中看到了相当大的进展。现有方法与对抗培训对齐不同的域,或者涉及利用伪标签进行监督培训的自学。前者始终遭受由对抗性训练引起的不稳定培训,并且只关注暗示域内知识的互域间隙。后者倾向于对错误类别进行过度自信的标签预测,这将误差传播到更多样本。为了解决这些问题,我们提出了一种基于本地Lipschitz约束的两个阶段自适应语义分割方法,以满足统一原理的域对齐和域特定探索。在第一阶段,我们将当地的嘴唇尖锐正规化作为目标函数来通过利用域内知识来对齐不同的域,这探讨了非对抗自适应语义分割的有希望的方向。在第二阶段,我们使用本地嘴唇正则化来估计每个像素满足嘴唇的概率,然后动态地设定伪标签的阈值以进行自学。这种动态自学有效避免了噪声标签引起的错误传播。两个阶段的优化基于相同的原理,即本地Lipschitz约束,从而可以在第二阶段保持第一阶段中学到的知识。此外,由于模型不可知属性,我们的方法可以容易地适应基于CNN的语义分段网络。实验结果表明我们对标准基准测试的优异性能。 |
| YOLO5Face: Why Reinventing a Face Detector Authors Delong Qi, Weijun Tan, Qi Yao, Jingfeng Liu 近年来使用卷积神经网络近年来取得了巨大进展。虽然许多面部探测器使用指定用于检测面部的设计,但我们将面部检测视为一般物体检测任务。我们基于YOLOV5对象检测器实现面部探测器并呼叫它YOLO5FACE。我们将五点地标回归头添加到其中并使用翼丢函数。我们设计具有不同型号大小的探测器,从大型模型实现最佳性能,到一个超小型模型,用于嵌入或移动设备上的实时检测。 WileRace Dataset上的实验结果表明,我们的脸部探测器可以在几乎所有简单,介质和硬质子集中达到最先进的性能,超过更复杂的指定面检测器。代码可在URL上获得 |
| Image-Based Plant Wilting Estimation Authors Changye Yang, Sriram Baireddy, Enyu Cai, Valerian Meline, Denise Caldwell, Anjali S. Iyer Pascuzzi, Edward J. Delp 许多植物通过热量,丧失水或疾病而变得跛行或下垂。这也被称为萎。在本文中,我们检查由细菌感染引起的植物萎缩。特别是,我们希望基于植物获取的图像设计用于WiLting的度量。可量化的衰竭度量可用于研究细菌枯萎和识别抗性基因。由于没有标准估计WILTing的方法,因此通常使用临时视觉分数。这是非常主观的,需要对植物和疾病机制的专家知识。我们的解决方案包括使用从植物的RGB图像获取的各种衰落度量。我们还设计了几个实验,以证明我们的指标在植物中估算萎缩。 |
| Self-Ensembling Contrastive Learning for Semi-Supervised Medical Image Segmentation Authors Jinxi Xiang, Zhuowei Li, Wenji Wang, Qing Xia, Shaoting Zhang 使用具有手动标签的足够大量的训练数据,深入学习已经证明了医学图像分割的显着改进。收购井代表性标签需要专家知识和详尽的劳动力。在本文中,我们的目标是使用自组合对比学习技术提高有限标签的医学图像分割的半监控学习的性能。为此,我们建议在图像级别培训具有少量标记图像的编码器解码器网络,更重要的是,我们通过对未标记图像进行对比损失来直接在特征级别学习潜在的表示。该方法强化帧内紧凑性和帧间间可分离性,从而获得更好的像素分类器。此外,我们设计了一个学生编码器进行在线学习和IT的指数移动平均版本,称为教师编码器,以自身合并方式迭代地提高性能。为了构建具有未标记图像的对比样本,研究了两种采样策略,其利用医学图像的结构相似性并利用伪标签进行施工,被称为区域意识和解剖学意识的对比采样。我们对MRI和CT分割数据集进行广泛的实验,并证明在有限的标签设置中,所提出的方法实现了最新性能的状态。此外,使用伪标签在飞行中准备对比样本的解剖学意识策略实现了对特征表示的更好的对比正规化。 |
| 3D Segmentation Learning from Sparse Annotations and Hierarchical Descriptors Authors Peng Yin, Lingyun Xu, Jianmin Ji 3D语义细分的主要障碍之一是为完全监督培训产生昂贵的点明智注释所需的大量努力。为了减轻手动努力,我们提出了Gidseg,一种新的方法,可以通过推理全球区域结构和个别张平性能同时学习稀疏注释的细分。 Gidseg通过与内核识别符耦合的动态边缘卷积网络描述全局和个人关系。通过赋予低分辨率体柔性地图来获得聚合剂效应。在我们的Gidseg中,对抗性学习模块还被设计用于进一步增强联合特征分布内的身份描述符的条件约束。尽管简单的简单性,但我们所提出的方法可以通过仅具有稀疏注释的推移3D密集分割来实现最先进的技术。特别是,使用原始数据的5个注释,Gidseg优于其他3D分段方法。 |
| i3dLoc: Image-to-range Cross-domain Localization Robust to Inconsistent Environmental Conditions Authors Peng Yin, Lingyun Xu, Ji Zhang, Sebastian Scherer 我们介绍了一个关于在室内和室外场景中的点云图定位单个相机的方法。问题是具有挑战性的,因为局部不变特征的对应关系在图像和3D之间的域中不一致。由于该方法必须处理诸如照明,天气和季节性变化的各种环境条件,因此问题更具挑战性。我们的方法可以通过提取横域对称位置描述符来匹配常规图像到3D范围投影。我们的主要洞察力是保留来自有限数据样本的条件不变的3D几何特征,同时通过设计的生成对冲网络消除了条件相关的特征。基于此类特征,我们进一步设计了一个球形卷积网络来学习ViewPoint不变的对称位置描述符。我们在广泛的自集数据集中评估我们的方法,涉及纺织长期变体外观条件,短尺度高达2km的结构非结构化环境,以及纺织多元化四层限制空间。我们的方法通过在较高的地方检索到不一致的环境中,超越了其他目前的技术状态,并且在线本地化的3次高于3倍的准确性。为了突出我们的方法的泛化能力,我们还会评估不同数据集的识别。通过单一培训的模型,I3DLOC可以在随机条件下展示可靠的视觉本地化。 |
| Benchmarking Scientific Image Forgery Detectors Authors Jo o P. Cardenuto, Anderson Rocha 科学形象完整性地区呈现出具有挑战性的研究瓶颈,缺乏可用的数据集设计和评估法医技术。其数据敏感性创造了一个法律障碍,这可以防止一个人依靠真正的篡改案例来构建任何类型的可访问的取证基准。为了缓解此瓶颈,我们提供了一个可扩展的开源库,可通过研究完整性社区复制,修饰和清洁来复制最常见的图像伪造操作。使用这个图书馆和现实的科学图像,我们创建一个大型科学伪造图像基准39,423图像,具有丰富的地面真相。此外,由于图像复制,关注大量缩回文件,使用新的度量来评估所提出的数据集中的最先进复制移动检测方法的最新操作,该方法在源和复制的区域之间断言一致匹配检测。数据集和源代码将在接受纸张时自由使用。 |
| Multi-Modal Semantic Inconsistency Detection in Social Media News Posts Authors Scott McCrae, Kehan Wang, Avideh Zakhor 随着计算机生成的内容和Deepfakes使得稳定的改进,多媒体取证的语义方法将变得更加重要。在本文中,我们介绍了一种新的分类架构,用于识别社交媒体新闻帖子中的视频外观和文本标题之间的语义不一致。我们通过利用基于字幕,自动音频转录,语义视频分析,对象检测,命名实体一致性和面部验证的文本分析,通过利用基于文本分析来识别社交媒体帖子中的视频和标题之间的多模态融合框架来识别视频和标题之间的不匹配。要培训和测试我们的方法,我们策划了一个用于4,000个现实世界Facebook新闻帖子的新视频数据集进行分析。我们的多模态方法在标题和外观之间的随机不匹配方面实现了60.5分类准确性,而UNI模态模型的精度低于50。进一步的消融研究证实了跨多种方式融合的必要性,以正确识别语义不一致。 |
| Issues in Object Detection in Videos using Common Single-Image CNNs Authors Spencer Ploeger, Lucas Dasovic 计算机视觉的越来越多的分支是对象检测。对象检测用于许多应用,例如工业过程,医学成像分析和自主车辆。检测视频中对象的能力至关重要。对象检测系统在大图像数据集上培训。对于诸如自主车辆的应用,对象检测系统可以通过视频中的多个帧识别对象至关重要。将这些系统应用于视频有许多问题。阴影或亮度的变化,可能导致系统错误地识别对象帧到帧并导致意外的系统响应。有许多用于对象检测的神经网络,如果有一种方法可以消除帧之间的对象,则可以消除这些问题。对于这些神经网络,在识别视频中识别对象时,需要重新培训。必须使用表示连续视频帧的图像创建数据集,并且具有匹配的地面真实图层。提出了一种可以生成这些数据集的方法。地面真相层仅包含移动对象。为了生成该层,使用FlowNet2 Pytorch使用新颖的幅度方法来创建流动掩模。同样,将使用诸如掩模R CNN或RefineNet等网络生成分割掩模。这些分段掩码将包含在帧中检测到的所有对象。通过将该分割掩码与流掩码接地真理层进行比较,产生损耗函数。这种损失函数可用于训练神经网络更好地在录像中进行一致的预测。系统在多个视频样本上进行测试,并且为每个帧产生损耗,证明了在将来工作中培训对象检测神经网络的幅度方法。 |
| ViPTT-Net: Video pretraining of spatio-temporal model for tuberculosis type classification from chest CT scans Authors Hasib Zunair, Aimon Rahman, Nabeel Mohammed 预先训练已经引发了对深度学习工作流程的兴趣,以从有限的数据中学习并改善泛化。虽然这对于2D图像分类任务很常见,但其应用于胸部CT解释等3D医学成像任务的限制是有限的。我们探讨了售价售价售前模式是否可以提高性能,而不是从划痕中培训模型,用于从胸部CT扫描的结核型分类。为了纳入空间和时间特征,我们开发混合卷积神经网络CNN和经常性神经网络RNN模型,其中通过CNN从CT扫描的每个轴向切片提取特征,这些图像特征序列被输入到RNN用于CT扫描的分类。我们的模型被称为Viptt网,接受过1300多个视频剪辑,具有人类活动标签,然后在胸部CT扫描上进行微调,用结核型标签。我们发现预先介绍视频模型导致更好的表示,从Kappa得分为0.17至0.35,特别是对于所代表的类样本而言,显着改善了模型验证性能。我们的最佳方法在ImageClef 2021结核病TBT分类任务中实现了第二个位置,在最终测试集中的Kappa得分为0.20,只有图像信息,不使用临床元数据。所有代码和型号都可提供。 |
| DFPN: Deformable Frame Prediction Network Authors M. Ak n Y lmaz, A. Murat Tekalp 学习帧预测是当前计算机视觉和视频压缩的感兴趣的当前问题。尽管已经提出了几个深度网络架构,但据我们所知,据我们所知,虽然我们的知识,但没有基于使用可变形卷曲的帧预测的工作。为此,我们提出了一种可变形的帧预测网络DFPN,用于面向任务的隐式运动建模和下一帧预测。实验结果表明,所提出的DFPN模型实现了本领域的状态,导致下一帧预测。我们的型号和结果可供选择 |
| RSCA: Real-time Segmentation-based Context-Aware Scene Text Detection Authors Jiachen Li, Yuan Lin, Rongrong Liu, Chiu Man Ho, Humphrey Shi 基于分割的场景文本检测方法最近被广泛用于任意形状的文本检测,因为它们对弯曲文本实例进行了准确的像素级别预测,并且可以促进实时推断而在锚固锚上没有耗时处理。然而,基于当前的基于分段的模型无法学习曲线文本的形状,并且通常需要复杂的标签分配或重复的特征聚合以进行更准确的检测。在本文中,我们向RSCA提出了基于任意形状的场景文本检测的基于实时分割的上下文感知模型,它为场景文本检测设置了具有两个简单但有效的策略本地上下文感知Ups采样和动态文本脊椎标签的强大基线,该模型本地空间转换并单独简化标签分配。基于这些策略,RSCA以速度和准确性实现了最新性能,而无需复杂的标签分配或重复的特征聚合。我们对多个基准进行广泛的实验,以验证我们方法的有效性。 RSCA 640在CTW1500数据集上以48.3 FPS达到83.9 f。 |
| cofga: A Dataset for Fine Grained Classification of Objects from Aerial Imagery Authors Eran Dahan, Tzvi Diskin, Amit Amram, Amit Moryossef, Omer Koren 架空图像中对象的检测和分类是计算机视觉中的两个重要和具有挑战性的问题。在该领域的各种研究领域中,由于高分辨率卫星和空气传播的成像系统的最近进步,在多种现实世界应用中,架空图像中对象的对象分类的任务已经变得无处不在。小型阶级变化和由细粒度的大型性质引起的大型课堂变化使其成为一个具有挑战性的任务,特别是在低资源案例中。在本文中,我们介绍了Cofga一个新的公开数据集,用于提高细粒度分类研究。数据集中的2,104个图像在5 15厘米的地面采样距离中从机载成像系统中收集,提供比大多数公共开销图像数据集更高的空间分辨率。将数据集中的14,256个注释对象分为2类,15个子类,14个独特功能,8个感知颜色,共37个不同的标签,使其适合于细粒度分类的任务,而不是任何其他公开的架空图像数据集。我们将Cofga与其他开销图像数据集进行比较,然后描述在我们为此任务进行的开放数据科学竞赛期间探索的一些尊敬的精细谷物分类方法。 |
| DSLR: Dynamic to Static LiDAR Scan Reconstruction Using Adversarially Trained Autoencoder Authors Prashant Kumar, Sabyasachi Sahoo, Vanshil Shah, Vineetha Kondameedi, Abhinav Jain, Akshaj Verma, Chiranjib Bhattacharyya, Vinay Viswanathan 精确地重建静态环境的静态环境,其中LIDAR扫描的场景中包含动态对象的场景,我们称为动态静态翻译DST,是自主导航中的一个重要研究领域。此问题最近探讨了视觉奴役,但对于我们所知,没有任何作品则没有尝试解决LIDAR扫描的DST。由于激光器在自动车辆中的广泛涂抹,问题是重要的重要性。我们展示了当适用于LIDAR扫描时,为视觉域开发的现有技术的状态。 |
| An Online Learning System for Wireless Charging Alignment using Surround-view Fisheye Cameras Authors Ashok Dahal, Varun Ravi Kumar, Senthil Yogamani, Ciaran Eising 电动汽车越来越普遍,具有电感折动路,被认为是充电电动车辆的方便和有效的手段。然而,驾驶员通常较差地将车辆对准到必要的精度以进行高效电感充电,使得两个充电板的自动对准是所需的。与车辆队列的电气化平行,利用环绕式相机系统的自动化停车系统变得越来越受欢迎。在这项工作中,我们提出了一种基于Surround View相机架构的系统来检测,本地化并自动将车辆与电感充电板对齐。电荷板的视觉设计不是标准化的,并且不一定事先已知。因此,在某些情况下,依赖离线培训的系统将失败。因此,我们提出了一种在线学习方法,在手动将车辆与ContionPad手动对准时,利用驾驶员行动并将其与语义分割和深度的弱监督组合起来,以学习自动为视频中的分类器注释用于进一步的培训的分类器。通过这种方式,当面对以前看不见的ChardPad时,驾驶员只需手动对准车辆即可。随着电荷板在地上平坦,从远处检测到它并不容易。因此,我们建议使用Visual Slam管道来学习相对于ChiftPad的地标,以实现从更大范围的对齐。我们在视频中说明了自动化车辆上的工作系统 |
| Drawing Multiple Augmentation Samples Per Image During Training Efficiently Decreases Test Error Authors Stanislav Fort, Andrew Brock, Razvan Pascanu, Soham De, Samuel L. Smith 在计算机视觉中,它是标准的做法,可以从迷你批量中的每个唯一图像中绘制单个样本,但目前尚不清楚这种选择是否是最佳的泛化。在这项工作中,我们提供了一种详细的实证评估,对每个唯一图像的增强样本数量如何影响所持数据的性能。值得注意的是,我们发现每张图像的多个样本一致地增强了对小型和大型批量培训所达到的测试精度,尽管每次迷你批次中的独特训练示例的数量减少。即使不同的增强倍数执行相同数量的参数更新和渐变评估,也会出现这种好处。我们的研究结果表明,尽管从数据集的离子采样引起的梯度估计的方差具有隐式正则化效益,但是从数据增强过程中产生的方差损害了测试精度。通过向最近提出的NFNET模型系列应用增强多重性,我们实现了86.8前1个W o额外数据的新想象。 |
| Cardiac Segmentation on CT Images through Shape-Aware Contour Attentions Authors Sanguk Park, Minyoung Chung 在计算机断层扫描CT图像中的心房,心室和心肌的心脏分割是一个重要的第一线任务,用于假设心血管疾病诊断。在最近的几项研究中,深度学习模型在医学图像分割任务中表现出显着的突破。与其他器官(如肺和肝脏)不同,心脏器官包括多个子结构,即心室,庭,主动脉,动脉,静脉和心肌。这些心脏子结构彼此靠近并且具有毫无辨认的边界即,均匀的强度值,使分段网络难以聚焦在子结构之间的边界上。在本文中,为了提高近代器官之间的分割准确性,我们介绍了一种新颖的模型来利用形状和边界意识功能。我们主要提出一种形状的感知注意模块,该注意力模块利用距离回归,这可以指导模型聚焦在子结构之间的边缘,使得它可以优于基于传统的轮廓的关注方法。在实验中,我们使用了具有20个CT心脏图像的多模态整个心脏分割数据集进行培训和验证,以及40 CT的心脏图像进行测试。实验结果表明,通过提高骰子相似度系数得分,所提出的网络通过4.97的骰子相似度分数产生更准确的结果。我们所提出的形状意识的轮廓注意力机制展示了距离变换和边界特征改善了实际的注意图,以加强边界区域的响应。此外,我们提出的方法显着降低了最终输出的误判响应,导致准确的细分。 |
| Graph-Based Deep Learning for Medical Diagnosis and Analysis: Past, Present and Future Authors David Ahmedt Aristizabal, Mohammad Ali Armin, Simon Denman, Clinton Fookes, Lars Petersson 随着数据驱动机器学习研究的进步,已经解决了各种各样的预测问题。探讨如何利用机器学习和专门的深度学习方法来分析医疗保健数据,这一点至关重要。现有方法的一个主要限制一直是数据的重点,如数据,生理记录的结构往往是不规则和无序的,这使得难以将它们视为矩阵。因此,图形神经网络通过利用驻留在生物系统中的隐式信息而引起了重要的关注,其中由边缘连接的交互节点,其权重可以是时间关联或解剖结。在本调查中,我们彻底审查了不同类型的图形架构及其在医疗保健中的应用程序。我们以系统的方式提供这些方法的概述,其通过其应用领域组织,包括功能连通性,解剖结构和基于电气的分析。我们还概述了现有技术的局限性,并讨论了未来研究的潜在方向。 |
| Continual Learning at the Edge: Real-Time Training on Smartphone Devices Authors Lorenzo Pellegrini, Vincenzo Lomonaco, Gabriele Graffieti, Davide Maltoni 关于个性化学习的设备培训是一个具有挑战性的研究问题。能够在边缘快速调整深度预测模型是为了更好地适应个人用户需求。然而,对边缘的适应对学习过程的效率和可持续性以及在转换数据分布下工作的能力构成了一些问题。实际上,只有在新可用的数据上只能在新可用的数据上调整预测模型,导致灾难性的遗忘,突然擦除先前获得的知识。在本文中,我们详细介绍了混合持续学习策略AR1在天然的Android应用程序上,实时对设备个性化而不会忘记。我们的基准基于Core50 DataSet的扩展,显示了我们解决方案的效率和效率。 |
| HDRUNet: Single Image HDR Reconstruction with Denoising and Dequantization Authors Xiangyu Chen, Yihao Liu, Zhengwen Zhang, Yu Qiao, Chao Dong 由于传感器约束,大多数消费者级数码相机只能在现实世界场景中捕获有限范围的亮度。此外,噪声和量化误差通常在成像过程中引入。为了获得具有出色的视觉质量的高动态范围HDR图像,最常见的解决方案是将多个图像与不同的曝光相结合。然而,获得相同场景的多个图像并不总是可行的,并且大多数HDR重建方法都忽略了噪声和量化损耗。在这项工作中,我们提出了一种使用空间动态编码器解码器网络,HDRUNET的基于新的基于学习的方法,用于学习单幅图像HDR重建的结束映射,并具有去噪和脱屑。该网络由发利风格基础网络组成,用于充分利用分层多尺度信息,条件网络来执行模式特定调制和用于选择性地保留信息的加权网络。此外,我们提出了一个Tanh L1损失函数来平衡暴露值的影响以及对网络学习的良好暴露值。我们的方法在定量比较和视觉质量方面实现了最先进的性能。拟议的HDRUNET模型在NITRE2021高动态范围挑战的单一框架轨道中获得了第二位。 |
| Efficient High-Resolution Image-to-Image Translation using Multi-Scale Gradient U-Net Authors Kumarapu Laxman, Shiv Ram Dubey, Baddam Kalyan, Satya Raj Vineel Kojjarapu 最近,有条件的生成对抗网络条件GaN在几种图像中显示出非常有希望的性能到图像翻译应用。然而,这些条件GAN的用途非常仅限于低分辨率图像,例如256x256. PIX2PIX HD是利用条件GaN用于高分辨率图像合成的尝试。在本文中,我们提出了一种用于高分辨率图像的多尺度梯度基于UNT MSG U净模型,到达2048x1024的图像转换。通过允许从多个判别从多个鉴别器流到单个发电机的梯度流动来训练所提出的模型。提出的MSG U Net架构导致照片逼真的高分辨率图像到图像转换。此外,所提出的模型作为COM计算到PIX2PIX HD的计算方式,其推测时间几乎达到2.5倍。我们提供MSG U Net Model的代码 |
| Passing Multi-Channel Material Textures to a 3-Channel Loss Authors Thomas Chambon, Eric Heitz, Laurent Belcour 我们的目标是计算纹理损失,可用于培训具有通常用于物理基于渲染的多种材料通道的纹理发生器,例如反向,正常,粗糙度,金属,环境遮挡等。神经纹理损失通常在顶部构建预卷曲卷积神经网络的特征空间。不幸的是,这些预磨模的模型仅适用于3个通道RGB数据,因此将神经纹理损失限制为此格式。为了克服这种限制,我们认为将随机三元组传递给3通道损耗提供了一种多通道损耗,可用于产生高质量的材料纹理。 |
| Robust Navigation for Racing Drones based on Imitation Learning and Modularization Authors Tianqi Wang, Dong Eui Chang 本文介绍了一种基于视觉的模块化无人机赛车导航系统,它使用定制的卷积神经网络CNN用于感知模块来产生高级导航命令,然后利用艺术策划器和控制器的状态来产生低级控制命令,从而利用基于数据的数据和基于模型的方法的优点。与仅将当前相机图像作为CNN输入的现有技术的状态不同,我们进一步将最新的三个无人机状态添加为输入的一部分。我们的方法在各种轨道布局中优于现有技术的状态,并提供两个具有单个训练网络的可切换导航行为。基于CNN的感知模块训练以模仿基于PRE计算的全局轨迹自动生成地面真相导航命令的专家策略。由于随机化的广泛随机化和数据集合,我们的导航系统,纯粹在仿真与合成纹理的仿真中,成功地在随机选择的光电环境纹理的环境中运行,而无需进一步进行微调。 |
| Computer Vision and Conflicting Values: Describing People with Automated Alt Text Authors Margot Hanley, Solon Barocas, Karen Levy, Shiri Azenkot, Helen Nissenbaum 学者们最近引起了一系列有争议的问题,通过使用计算机愿景来自动生成图像中人们的描述。尽管有这些问题,自动形象描述已成为确保公平获取盲目和低视力人民信息的重要工具。在本文中,我们调查了公司所面临的伦理困境,这些困境已经采用了使用计算机愿景,以便为盲人和低视力人员的图像制作图像的Alt文本文本描述,我们使用Facebook的自动Alt Text Tool作为我们的主要案例研究。首先,我们分析了Facebook已经采用了关于身份类别的政策,例如种族,性别,年龄等,以及关于是否在ALT文本中呈现这些条款的决定。然后,我们描述了博物馆社区实行的另一种和手工方法,专注于博物馆如何确定文化工件的替代文本描述中的内容。我们使用显着的对比度进行比较这些策略,以开发一个分析框架,其特征在于这些政策选择背后的特定担忧。我们通过考虑两种似乎以某种问题的策略来得出结论,发现没有简单的方法可以避免使用计算机愿景来自动化替代文本的规范性困境。 |
| Chinese Abs From Machine Translation |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









