










AI视野·今日CS.CV 计算机视觉论文速览
Thu, 27 May 2021
Totally 48 papers
👉上期速览✈更多精彩请移步主页

Interesting:
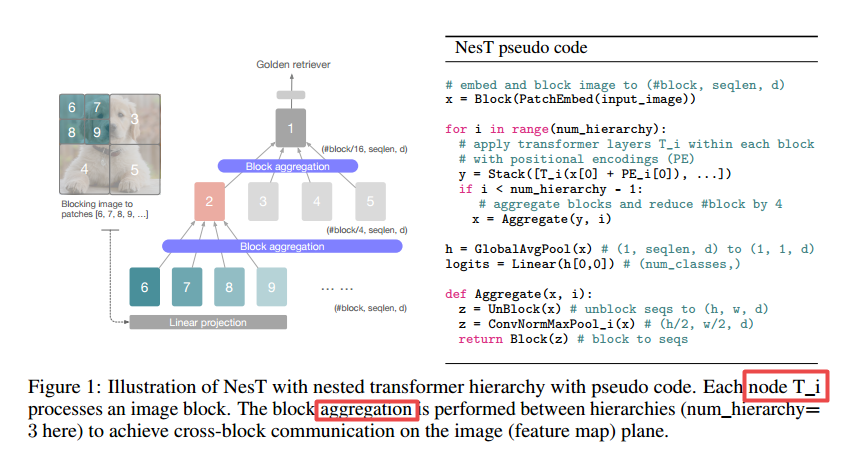
📚NesT: Aggregating Nested Transformers, 新的transformer(from 谷歌)
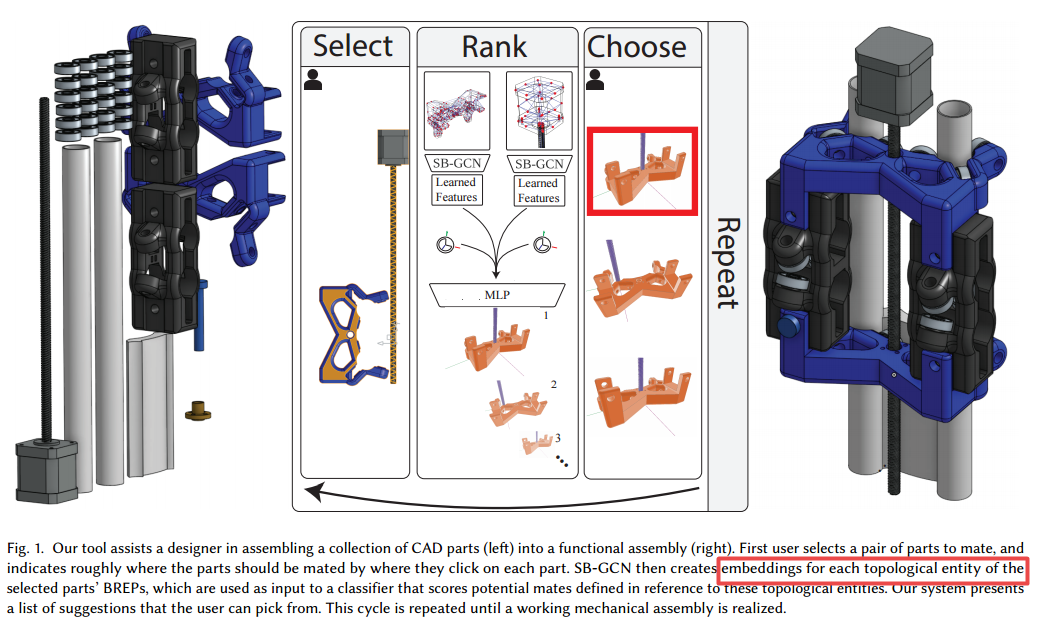
📚SB-GCN: 自动生成组装家具流程的模型, (from 华盛顿大学)
📚从产品设计风格的视角实现产品推荐, (from New Jersey Institute of Technology)

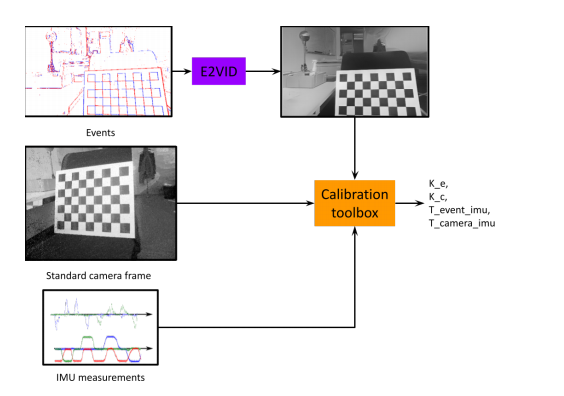
📚标定事件相机的方法, (from 苏黎世理工 )
code:https://github.com/uzh-rpg/e2calib
Daily Computer Vision Papers
| Aggregating Nested Transformers Authors Zizhao Zhang, Han Zhang, Long Zhao, Ting Chen, Tomas Pfister 虽然分层结构在最近的视觉变压器中很受欢迎,但它们需要复杂的设计和大规模的数据集。在这项工作中,我们探讨了在非重叠图像块上嵌套基本本地变压器的想法,并以分层方式聚合它们。我们发现块聚合函数在启用交叉块非本地信息通信方面发挥着关键作用。此观察导致我们设计简化的架构,其中具有次要代码更改的原始视觉变压器,与现有方法相比获得改进的性能。我们的经验结果表明,该方法嵌套会聚得更快,需要更少的培训数据来实现良好的概括。例如,具有68M参数的巢在想象中培训100 300时期的Imagenet验证82.3 83.8精度在224次图像尺寸上进行评估,优于最多57个参数减少的先前方法。使用单个GPU训练来自CIFAR10的3M参数,使用单个GPU实现96个精度,为视觉变压器设置新技术。除了图像分类之外,我们将关键的想法扩展到图像生成,并将巢显示到强的解码器,比以前的基于变压器的发电机快8倍。此外,我们还提出了一种用于视觉解释学习模型的新方法。 |
| Sli2Vol: Annotate a 3D Volume from a Single Slice with Self-Supervised Learning Authors Pak Hei Yeung, Ana I.L. Namburete, Weidi Xie 这项工作的目的是通过仅通过注释单个切片来分割3D卷中的任何任意兴趣SOI结构,即半自动3D分段。我们表明,通过简单地将2D片段与连续切片之间的亲和力矩阵传播,可以在自我监督的方式中学到,即切片重建来实现高精度。具体而言,我们将所提出的框架与SLI2VOL称为SLI2VOL,具有监督方法和另外两个无监督的自我监督的切片登记方法,在8个公共数据集中CT和MRI扫描,跨越9种不同的SOI。如果没有任何参数调整,相同的型号可以使用骰子分数0 100尺度为80多个基准,包括在培训期间看不见的模型。我们的结果表明,跨不同机器数据的建议方法的普遍性,并且具有不同的SEAI的主要用例,即半自动分割方法的全自动分割方法通常会挣扎。源代码将公开可用 |
| Spatio-Contextual Deep Network Based Multimodal Pedestrian Detection For Autonomous Driving Authors Kinjal Dasgupta, Arindam Das, Sudip Das, Ujjwal Bhattacharya, Senthil Yogamani 行人检测是自主驱动系统中最关键的模块。虽然相机通常用于此目的,但其质量严重降低了低光夜间驾驶场景。另一方面,热摄像机图像的质量在类似条件下保持不受影响。本文提出了一种使用RGB和热图像的行人检测结束到结束多峰融合模型。其新颖的SPATIO语境深网络架构能够有效利用多模式输入。它由两个不同的可变形Reseage 50编码器组成,用于来自两个模态的特征提取。这些两个编码特征的融合发生在多模式特征嵌入模块MUFEM内部,由几组图形关注网络和特征融合单元组成。 MUFEM的最后一个特征融合单元的输出随后传递到两个CRF的空间细化。通过在四个不同方向横穿四个RNN的帮助下,通过应用渠道明智的关注和提取上下文信息来实现特征的进一步增强。最后,这些特征映射由单级解码器使用,以生成每个行人和分数图的边界框。我们已经在三个公开的多式联播行人检测基准数据集,即Kaist,CVC 14和Utokyo上进行了广泛的实验。每个结果都改善了最新的最新状态。一个简短的视频概述了这项工作以及定性结果可以看到 |
| Enhance to Read Better: An Improved Generative Adversarial Network for Handwritten Document Image Enhancement Authors Sana Khamekhem Jemni, Mohamed Ali Souibgui, Yousri Kessentini, Alicia Forn s 手写的文档图像可以对不同的原因造成纸张老化,日常生活场景皱纹,灰尘等,扫描过程等较差的劣势。这些工件提高了当前手写文本识别HTR算法的许多可读性问题,并且严重贬值了它们的效率。在本文中,我们提出了基于生成的对抗网络GAN的结束到最终架构,以将降级的文档恢复为清洁和可读的形式。与最着名的文档二值化方法不同,该方法尝试提高降级文档的视觉质量,所提出的体系结构集成了手写的文本识别器,该识别器促使所生成的文档图像更加可读。据我们所知,这是第一个在二值化手写文件时使用文本信息的工作。在退化的阿拉伯语和拉丁语手写文件上进行的广泛实验证明了集成识别器在GAN架构内的有用性,这提高了视觉质量和降级文档图像的可读性。此外,在微调我们的预训练模型与综合降级的拉丁语手写图像,在这项任务上,我们优于HDIBCO 2018挑战的挑战。 |
| Deep Learning for Weakly-Supervised Object Detection and Object Localization: A Survey Authors Feifei Shao, Long Chen, Jian Shao, Wei Ji, Shaoning Xiao, Lu Ye, Yueting Zhuang, Jun Xiao 弱监督对象检测WSOD和定位WSOL,即使用图像级标签中的图像中的边界框检测多个和单个实例,是在CV社区中的长站和具有挑战性的任务。随着物体检测中深度神经网络的成功,WSOD和WSOL都接受了前所未有的关注。已经在深度学习时代提出了数百个WSOD和WSOL方法和许多技术。为此,在本文中,我们认为WSOL是WSOD的子任务,并对WSOD最近的成就提供全面的调查。具体而言,我们首先描述了WSOD的配方和设置,包括背景,挑战,基本框架。同时,我们总结和分析了所有先进的技术和培训技巧,以提高检测性能。然后,我们介绍了WSOD的广泛使用的数据集和评估度量。最后,我们讨论了WSOD的未来方向。我们认为,这些摘要可以帮助为未来的WSOD和WSOL进行铺平方法。 |
| Low Resolution Information Also Matters: Learning Multi-Resolution Representations for Person Re-Identification Authors Guoqing Zhang, Yuhao Chen, Weisi Lin, Arun Chandran, Xuan Jing 作为视频监控和取证领域的主要任务,人物RE识别RE ID旨在将从非重叠摄像机捕获的人物匹配。在不受约束的情景中,人物图像经常遭受分辨率不匹配问题,即Emph跨解析人员重新ID。为了克服这个问题,大多数现有方法通过超分辨率SR将低分辨率LR图像恢复到高分辨率HR。但是,它们仅关注HR特征提取并忽略原始LR图像的有效信息。在这项工作中,我们探讨了决议对特征提取的影响,并开发了一种新的横向分辨率人员的方法,称为EMPH TextBF M Ulti Stoction TextBF R Epresentations TextBF J oint TextBF L收入TextBF MRJF。我们的方法包括分辨率重建网络RRN和双重特征融合网络DFFN。 RRN使用输入图像构建HR版本和使用编码器和两个解码器的LR版本,而DFFN采用双分支结构以生成来自多分辨率图像的人表示。五个基准测试的综合实验验证了所提出的MRJL的优越性在最新方法的相关状态。 |
| Detecting Biological Locomotion in Video: A Computational Approach Authors Soo Min Kang, Richard P. Wildes 动物当地出于寻找食物的各种原因,找到合适的栖息地,追求猎物,逃离掠夺者,或寻求伴侣。生物多样性的大规模有助于大量的机器人设计和模式多样性。各种生物利用腿,翅膀,翅片等手段贯穿世界。在本报告中,我们指的是一般生物物种作为生物模型的运动。我们提出了一种计算方法来检测未加工的视频中的生物变量。 |
| Disentangled Face Attribute Editing via Instance-Aware Latent Space Search Authors Yuxuan Han, Jiaolong Yang, Ying Fu 最近的作品表明,生成的对抗网络GAN的潜在空间中存在丰富的语义方向,这使得各种面部属性编辑应用能够。然而,现有方法可能遭受较差的属性变化解体,导致在改变所需的时其他属性的不需要的变化。现有方法使用的语义方向处于属性级别,这很难建模复杂的属性相关性,尤其是在GaN S训练集中的属性分发偏差存在。在本文中,我们提出了一种新颖的框架IAL,其执行实例意识到的潜在空间搜索,以找到解除andandled属性编辑的语义方向。通过从输入图像上评估的一组属性分类器中利用监督来注入实例信息。我们进一步提出了一种解剖转换转换DT度量,以量化属性转换和解剖学效能,并根据其查找属性级别和实例特定方向之间的最佳控制因子。 GaN的实验结果产生和现实世界的图像共同表明,我们的方法优于最近通过宽边缘提出的现有技术的状态。代码可用 |
| Recent Standard Development Activities on Video Coding for Machines Authors Wen Gao, Shan Liu, Xiaozhong Xu, Manouchehr Rafie, Yuan Zhang, Igor Curcio 近年来,视频数据占据了Internet流量,并成为主要数据格式之一。通过新兴的5G和Internet Internet Int技术,越来越多的视频由边缘设备生成,跨网络发送,并由机器消耗。机器消耗的视频量超过人类消耗的视频量。机器视觉任务包括对象检测,分段,跟踪和基于机器的应用程序,与人类消费完全不同。另一方面,由于大量的视频数据,因此必须在传输之前压缩视频。因此,用于机器VCM的有效视频编码已成为学术界和工业中的重要课题。 2019年7月,国际标准化组织,即MPEG,创建了一个名为VCM的特设组,以研究潜在标准化工作的要求。在本文中,我们将解决MPEG VCM集团最近的发展活动。具体而言,我们将首先提供MPEG VCM组的概述,包括用例,要求,处理管道,潜在VCM标准的计划,其次是评估框架,包括机器视觉任务,数据集,评估度量和锚代代。然后,我们介绍了迄今提出的技术解决方案,并讨论了最近对MPEG VCM集团发出的证据呼吁的答复。 |
| Edge Detection for Satellite Images without Deep Networks Authors Joshua Abraham, Calden Wloka 卫星图像广泛用于许多应用领域,包括农业,导航和城市规划。通常,卫星图像涉及大量图像以及高像素计数,使计算方式分析昂贵的数据集。最近的卫星图像分析方法很大程度上强调了深度学习方法。虽然极其强大,但深度学习有一些缺点,包括专业计算硬件的要求和高度依赖训练数据。在处理大型卫星数据集时,计算资源和培训数据注释的成本可能是禁止的。 |
| Predicting invasive ductal carcinoma using a Reinforcement Sample Learning Strategy using Deep Learning Authors Rushabh Patel 侵入性导管癌是一种普遍的,潜在的致命疾病,其具有高的发病率和死亡率。恶性肿瘤是妇女癌症死亡的第二个主要原因。乳房X线照片是一种极其有用的质量检测和侵入性导管癌诊断资源。我们旨在提出一种侵入性导管癌的方法,将在乳房X光线照片上使用卷积神经网络CNN来帮助放射科医师诊断疾病。由于图像清晰度和某些乳房图的结构不同,难以观察诸如微钙化和质量的主要癌症特征,并且通常难以解释和诊断这些属性。本研究的目的是建立一种新的侵袭性导管癌计算机辅助诊断CAD系统中全自动特征提取和分类的新方法。本文介绍了一种肿瘤分类算法,可以在乳房乳房图像图像上进行新的卷积神经网络,以提高特征提取和训练速度。该算法进行两种贡献。 |
| Context-aware Cross-level Fusion Network for Camouflaged Object Detection Authors Yujia Sun, Geng Chen, Tao Zhou, Yi Zhang, Nian Liu 由于物体和周围环境之间的低边界对比度,伪装的物体检测鳕鱼是一个具有挑战性的任务。此外,伪装物体的外观显着变化,例如,物体尺寸和形状,加剧了精确鳕鱼的困难。在本文中,我们提出了一种新颖的上下文意识交叉电平融合网络C2F网来解决具有挑战性的COD任务。具体而言,我们提出了一种注意力诱导的交叉电平融合模块ACFM,以将多电平特征集成,具有信息性注意系数。然后将融合功能馈送到所提出的双分支全部上下文模块DGCM,从而产生用于利用丰富的全局上下文信息的多尺度特征表示。在C2F网中,两个模块使用级联方式在高电平特征上进行。三个广泛使用的基准数据集的广泛实验表明,我们的C2F网是一个有效的COD模型,并且优于最优异的艺术模型。我们的代码公开提供 |
| KLIEP-based Density Ratio Estimation for Semantically Consistent Synthetic to Real Images Adaptation in Urban Traffic Scenes Authors Artem Savkin, Federico Tombari 合成数据已应用于许多深度学习的计算机视觉任务。仅采用域适应技术(如基于生成的对抗框架)的域适应技术接近了仅接近合成数据的算法的有限性能。我们展示了单独的对抗性培训如何在翻译图像中引入语义不一致。为了解决这个问题,我们使用基于KLIEP的密度比率估计程序提出了密度的超轻策略。最后,我们表明上述策略提高了基础方法的翻译图像的质量及其在自主驾驶范围内的语义细分任务的可用性。 |
| Unsupervised Video Summarization via Multi-source Features Authors Hussain Kanafani, Junaid Ahmed Ghauri, Sherzod Hakimov, Ralph Ewerth 视频摘要旨在生成紧凑又具有代表性的视觉摘要,该概要传达了原始视频的本质。无监督方法的优势在于,他们不需要人类注释来学习总结能力并概括到更广泛的域。以前的工作依赖于相同类型的深度特征,通常基于预先培训的模型在想象中数据。因此,我们建议将多个特征源的融合融入块和跨越融合,以提供有关视觉内容的更多信息。对于TVSUM和SUMPE的两个基准测试的全面评估,我们将我们的方法与四个最先进的方法进行比较。这些方法中的两个是由自己实施的,以重现报告的结果。我们的评估表明,我们在两个数据集中获得最新的艺术状态,同时还突出了对评估方法的先前工作的缺点。最后,我们对两个基准数据集的视频进行错误分析,总结和发现导致错误分类的因素。 |
| Pattern Detection in the Activation Space for Identifying Synthesized Content Authors Celia Cintas, Skyler Speakman, Girmaw Abebe Tadesse, Victor Akinwande, Edward McFowland III, Komminist Weldemariam 生成的对抗网络GAN最近从低维随机噪声的照片现实图像合成中取得了前所未有的成功。在大规模中合成高质量内容的能力将产生潜在的风险,因为所产生的样本可能导致可能产生严重的社会,政治,健康和业务危害的错误信息。我们提出了子刻甘来通过检测预训练的神经网络的内层中的异常节点激活的子集来识别生成的内容。作为组的这些节点最大化远离从真实数据创建的激活的预期分布的非参数分配的非参数测量。这使我们能够识别合成的图像,而无需先前了解其分发。子集本有效地评分节点的子集,并在预训练的分类器中返回贡献的最大分数的节点组。分类器可以是来自不同GANS的多个源或鉴别器网络的样本培训的一般假分类器。我们的方法在艺术艺术GAN PGGAN,Stargan和Crycangan的几个状态跨越若干状态的现有检测方法以及超不同比例的产生含量的检测能力始终如一。 |
| Social-IWSTCNN: A Social Interaction-Weighted Spatio-Temporal Convolutional Neural Network for Pedestrian Trajectory Prediction in Urban Traffic Scenarios Authors Chi Zhang 1 , Christian Berger 1 , Marco Dozza 2 1 Department of Computer Science and Engineering, University of Gothenburg, Gothenburg, Sweden, 2 Department of Maritime Sciences and Mechanics, Chalmers University of Technology, Gothenburg, Sweden 城市情景中的行人轨迹预测对于自动驾驶至关重要。这项任务是具有挑战性的,因为行人的行为受到自己的历史路径和与他人的互动的影响。以前的研究与汇集机制建模或用手工制作的注意力汇总的相互作用。在本文中,我们展示了社会互动加权时空卷积神经网络社交IWSTCNN,其包括空间和时间特征。我们提出了一种小说设计,即社会互动提取者,了解行人的空间和社会互动特征。最先前的作品使用了eth和ucy数据集,其中包括五场场景,但不会覆盖城市交通方案,广泛地培训和评估。在本文中,我们在城市交通方案中使用最近发布的大型Waymo开放数据集,其中包括374个城市培训场景和76个城市测试场景,以分析我们所提出的算法与艺术艺术型号的状态相比的表现。结果表明,我们的算法优于SOTA算法,如社会LSTM,社会LSTM,社交STGCNN等平均位移误差ADE和最终位移误差FDE。此外,我们的社交IWSTCNN在数据预处理速度方面速度快54.8倍,总测试速度速度快4.7倍,而不是当前最佳的SOTA算法社交STGCNN。 |
| Anticipating human actions by correlating past with the future with Jaccard similarity measures Authors Basura Fernando, Samitha Herath 我们通过将过去的功能与jaccard矢量相似性,Jaccard交叉相关和Jaccard Frobenius内部产品在Covari arce上的三个新颖的相似度措施来提出早期行动认可和预期的框架,以与未来的功能与未来相关联。利用新的损失和使用我们的框架的这些组合,我们通过分别获得201.7和83.5精度来获得UCF101和JHMDB数据集在UCF101和JHMDB数据集中获得最新的最新状态。类似地,我们获得最新的艺术结果对于Epic Kitcher55和早餐数据集,通过分别获得20.35和41.8前1个精度来预期行动预期。 |
| Unsupervised Part Segmentation through Disentangling Appearance and Shape Authors Shilong Liu, Lei Zhang, Xiao Yang, Hang Su, Jun Zhu 我们研究了对象部分的无监督发现和分割的问题,作为中间本地表示,能够找到内在物体结构并提供更可说明的识别结果。最近的无监督方法极大地放宽了对昂贵的数据获得的依赖性,但仍然依赖于其他信息,例如对象分段掩码或显着图。为了删除这样的依赖性并进一步提高零件分割性能,我们通过解开对象部件的外观和形状表示,在不使用附加对象掩码信息的情况下进行对象部件的外观和形状表示,开发一种新的方法。为避免退化的解决方案,瓶颈块设计用于挤压和扩展外观表示,导致几何形状和外观之间更有效的解剖。结合自我监督的零件分类损失和改进的几何浓度约束,我们可以通过语义含义进行更一致的部件。综合实验,如面部,鸟类和帕斯卡VOC物体等各种物体证明了该方法的有效性。 |
| Improving Sign Language Translation with Monolingual Data by Sign Back-Translation Authors Hao Zhou, Wengang Zhou, Weizhen Qi, Junfu Pu, Houqiang Li 尽管现有的开创性工作在手语翻译SLT上,但有一个非琐碎的障碍物,即,并行标志文本数据的有限数量。为了解决这个并行数据瓶颈,我们提出了一个标志转换标志的方法,它将大规模的口语语言文本融入了SLT培训。通过文本到光泽翻译模型,我们首先将单音文本翻译成其光泽序列。然后,通过将部分从估计的光泽拼接来生成配对的标志序列以在特征级别签署银行。最后,合成并行数据用作Encoder解码器SLT框架的结束终端训练的强度补充。 |
| Learning to Detect Fortified Areas Authors Allan Gr nlund, Jonas Tranberg 高分辨率数据模型,如LIDAR数据制成的网格地形模型是现代地理信息系统应用的先决条件。除了为非常精确的数字地形模型提供基础之外,LIDAR数据也广泛地用于分类所考虑的表面的哪些部分包括水,建筑物和植被等相关元素。在本文中,考虑到分类给定表面的哪个领域的问题,例如,道路,人行道,停车位,铺砌的车道和露台。我们考虑使用LIDAR数据和矫正器,组合和单独,以表明现代机器学习算法梯度升降树木和卷积神经网络能够在大型现实世界数据上检测强化区域。 LIDAR数据特征,特别是测量返回信号强度的强度特征,我们考虑在该项目中考虑的是严重依赖于制造测量的实际激光雷达传感器。这是非常有问题的,特别是对于模式匹配算法的泛化能力,因为这意味着测试数据的数据特征可能与模型训练的数据非常不同。我们通过设计一个神经网络嵌入式架构来提出算法解决问题,该解决问题是将数据从所有不同传感器系统转换为适用的新公共表示以及训练数据和测试数据源自同一传感器的新的常见表示。最终的算法结果高于96%的准确性,AUC评分高于0.99。 |
| How to Calibrate Your Event Camera Authors Manasi Muglikar, Mathias Gehrig, Daniel Gehrig, Davide Scaramuzza 我们提出了一种使用图像重建的通用事件相机校准框架。除了依赖LED模式或外部屏幕上,而不是依靠闪烁,而不是闪烁的基于神经网络的图像重建非常适合事件摄像机的内在和外在校准的任务。我们提出的方法的优点是我们可以使用不依赖于主动照明的标准校准模式。此外,我们的方法使得能够在没有额外复杂性的情况下执行基于帧和事件的传感器之间的外在校准。仿真和现实世界的实验都表明,通过图像重建的校准在常见的失真模型和各种失真参数中是准确的 |
| Multiple Domain Experts Collaborative Learning: Multi-Source Domain Generalization For Person Re-Identification Authors Shijie Yu, Feng Zhu, Dapeng Chen, Rui Zhao, Haobin Chen, Shixiang Tang, Jinguo Zhu, Yu Qiao 近年来见证了人类重新识别Reid的重要进展。然而,当测试目标域表现出从训练器的不同特征表现出域移位问题时,当前的REID方法遭受了相当大的性能下降。为了使Reid更实用和更广泛,我们将人员重新识别为域泛化DG问题,并提出了一种新颖的培训框架,名为多个域专家协同学习MD Exco。具体而言,MD ICICO由普遍专家和几个领域专家组成。每个域专家都专注于从特定领域学习,并定期与其他领域专家沟通,以规范其在元学习方式中的学习策略,以避免过度装备。此外,普遍专家从领域专家收集知识,并为他们提供监督作为反馈。关于DG Reid基准的广泛实验表明,我们的MD Exco通过大幅的余量优于现有技术的状态,显示其提高Reid模型的泛化能力的能力。 |
| PSGAN++: Robust Detail-Preserving Makeup Transfer and Removal Authors Si Liu, Wentao Jiang, Chen Gao, Ran He, Jiashi Feng, Bo Li, Shuicheng Yan 在本文中,我们同时解决了化妆传输和删除任务,其目的是将构成从参考图像转移到源图像,并分别从带化妆图像中删除化妆。现有方法在受约束方案中取得了很大的进步,但它们仍然非常具有挑战性,以便在具有大姿势和表达差异的图像之间传输化妆,或者处理脸颊上的腮红或鼻子上的突出显示的化妆细节。此外,它们几乎不能控制转移期间的化妆程度,或者在输入面上传输指定部分。在这项工作中,我们提出了PSGAN,其能够进行保存化妆和有效化妆的细节。对于化妆传输,PSGAN使用构成蒸馏网络来提取化妆信息,该化妆信息嵌入到空间感知的化妆矩阵中。我们还规定了一个细化妆的变形模块,指定源图像中的构成如何从参考图像传动,以及在所选化妆细节区域内监督模型的化妆细节丢失。另一方面,为了拆卸化妆,PSGAN应用一个身份蒸馏网络来将身份信息与化妆图像嵌入到标识矩阵中。最后,所获得的化妆标识矩阵被馈送到能够编辑特征映射以实现化妆或删除的样式传输网络。为了评估我们的PSGAN的有效性,我们在包含具有不同姿势和表达式的诸有图像的野生数据集中收集化妆传输,以及包含高分辨率图像的化妆传输高分辨率数据集。实验表明,即使在大型姿势表达差异的情况下,PSGaN不仅通过精细的化妆细节实现了最新的结果,而且可以执行部分或程度可控化妆转移。 |
| Performance Analysis of a Foreground Segmentation Neural Network Model Authors Joel Tom s Morais, Ant nio Ramires Fernandes, Andr Leite Ferreira, Bruno Faria 近年来,对细分的兴趣一直在增长,在广泛的应用中使用,如欺诈检测,异常检测在公共卫生和入侵检测中。我们展示了FGSegnet V2的消融研究,分析了其三个阶段I编码器,II特征池模块和III解码器。该研究的结果是提出上述方法的变化,其超越了最先进的结果。三个数据集用于测试CDNET2014,SBI2015和CityScapes。在CDNET2014中,与本领域的国家相比,我们得到了整体改进,主要是在Lowframet子集中。所提出的方法是有前途的,因为它在非常不同的条件下产生了与现有技术的状态和城市景观数据集的可比结果,例如不同的照明条件。 |
| FINNger -- Applying artificial intelligence to ease math learning for children Authors Rafael Baldasso Audibert, Vinicius Marinho Maschio 孩子们拥有令人惊叹的能力来利用平板电脑,智能手机等现代电子设备等。这一点通过易于访问这些设备的易于访问,因为这些设备通过世界的扩展,即使是第三世界国家达到这种设备。此外,众所周知,孩子们倾向于难以在预学校学习一些科目。我们作为一个社会在字母化上广泛聚焦,但最终,儿童最终有所存在的另一个基本地区数学。通过这项工作,我们为直观的应用程序创造了一个直观的应用程序,这些应用程序可以加入儿童在使用这种技术应用时大量放松,试图缩小有趣和愉快的活动之间的差距,与改善孩子们的知识和能够在较低时期理解概念,通过使用新的卷积神经网络实现所以,命名为FENNED。 |
| Style Similarity as Feedback for Product Design Authors Mathew Schwartz, Tomer Weiss, Esra Ataer Cansizoglu, Jae Woo Choi 匹配和推荐产品对客户和公司都有益。随着家庭货物电子商品的迅速增加,对数百万产品提供此类建议的定量方法越来越大。这种方法很大程度上通过亚马逊和Wayfair等在线商店,其中目标是最大限度地销售。我们通过采用大数据分析来确定强烈推荐产品的设计质量,而不是专注于整体销售,而不是专注于整体销售,而不是专注于整体销售。具体来说,我们专注于这种产品的视觉风格兼容性。我们从上一项工作中建立了成千上万家具产品的基于风格的相似度量。使用分析和可视化,我们提取具有高度兼容风格的家具产品的属性。我们提出了循环工作流程中的设计者,以镜像向消费者浏览电子商务网站的应用程序。我们的调查结果在设计新产品时很有用,因为他们提供了有关在多种风格中的家具强烈兼容的家具的洞察力,因此,更有可能建议。 |
| SB-GCN: Structured BREP Graph Convolutional Network for Automatic Mating of CAD Assemblies Authors Benjamin Jones, Dalton Hildreth, Duowen Chen, Ilya Baran, Vova Kim, Adriana Schulz 装配建模是计算机辅助设计CAD的核心任务,包括CAD工作流程中的三分之一。因此,优化此过程代表了CAD系统设计中的巨大机会,但目前基于组装的建模的研究不适用于现代CAD系统,因为它避免了现代CAD参数边界表示BREPS的主导数据结构。 CAD装配建模将组件定义为成对约束系统,称为配对,部分之间,部分与BREP拓扑中定义,而不是在现有工作中共同的世界坐标之间定义。我们提出了SB GCN,BREPS的表示学习方案保留了零件的拓扑结构,并使用这些学习的表示来预测CAD类型配对。要培训我们的系统,我们编制了Brep CAD组件的第一个大型数据集,我们正在释放与基准伴侣预测任务一起释放。最后,我们通过构建一个工具来展示与现有的商业CAD系统的模型兼容,该工具通过建议使用72.2精度来帮助用户使用MATE创建的伴侣创建。 |
| Learning a Model-Driven Variational Network for Deformable Image Registration Authors Xi Jia, Alexander Thorley, Wei Chen, Huaqi Qiu, Linlin Shen, Iain B Styles, Hyung Jin Chang, Ales Leonardis, Antonio de Marvao, Declan P. O Regan, Daniel Rueckert, Jinming Duan 数据驱动的图像登记的深度学习方法比传统的迭代方法更加准确,尤其是当训练数据有限时。为了解决这个问题,虽然保留了深度学习的快速推理速度,我们提出了VR Net,这是一个用于无监督变形图像配准的新型级联变分网络。使用变量分割优化方案,我们首先将图像配准问题转换为一般变分框架,分为两个子问题,一个带有点明智的,闭合形式解决方案,而另一个是另一个是去噪的问题。然后,我们提出了两个神经层,即翘曲层和强度一致性层,以模拟分析溶液和残留U网来制定去噪问题I.E.广泛的去噪层。最后,我们级联翘曲层,强度一致性层和广义的去噪层形成VR网。三个两个2D和一个3D心脏磁共振成像数据集的广泛实验表明,VR净优于艺术艺术状态的艺术深度学习方法对登记准确性,同时保持了深度学习的快速推断速度和变分模型的数据效率。 |
| Self-Guided Instance-Aware Network for Depth Completion and Enhancement Authors Zhongzhen Luo, Fengjia Zhang, Guoyi Fu, Jiajie Xu 深度完成旨在从稀疏深度测量推断密集深度图像,因为传感器不能正确扫描光泽,透明或远处的表面。大多数现有方法基于像素明智图像内容和相应的相邻深度值直接插入缺失的深度测量。因此,这导致对象的模糊或不准确的结构。为了解决这些问题,我们提出了一种新颖的自我指导实例意识到网络SG IANET,它利用自我引导机制来提取深度恢复所需的实例级别特征,2利用几何和上下文信息进入网络学习以符合底层约束对于边缘清晰度和结构一致性,3规范深度估计,并通过实例意识到噪声的影响,并通过域随机化仅具有合成数据的4列,以弥合现实差距。对合成和现实世界数据集的广泛实验表明,我们的提出方法优于以前的作品。进一步的消融研究进入了所提出的方法,并证明了我们模型的泛化能力。 |
| Occlusion Aware Kernel Correlation Filter Tracker using RGB-D Authors Srishti Yadav 与需要大型训练数据集的深度学习不同,基于相关滤波器,如凯尼相关的相关滤波器KCF,类似于跟踪图像循环矩阵的隐式属性,实时训练。尽管他们在追踪方面进行了实际应用,但需要更好地理解与理论上,数学上,数学和实验存在于科技的基本面。本文首先详细调了跟踪器的工作原型,并在实时应用中调查其有效性并支持可视化。我们进一步解决了跟踪器的一些缺点,在闭塞,缩放变化,对象旋转,视图和模型漂移,与我们的新颖RGB D内核相关跟踪器。我们还研究了粒子过滤器来提高跟踪器精度。我们的结果是使用Microsoft Kinect V2传感器使用标准数据集和B实验评估。我们认为这项工作将更好地了解基于内核的相关滤波器跟踪器的有效性,并进一步定义其在跟踪中的一些可能的优点。 |
| AutoReCon: Neural Architecture Search-based Reconstruction for Data-free Compression Authors Baozhou Zhu, Peter Hofstee, Johan Peltenburg, Jinho Lee, Zaid Alars 数据免费压缩提出了一个新的挑战,因为由于隐私或传输问题,无法进行压缩的预训练模型的原始训练数据集。因此,共同的方法是在压缩之前计算重建的训练数据集。当前重建方法通过从预训练模型中利用信息来计算与发电机的重建训练数据集。然而,目前的重建方法专注于从预训练模型中提取更多信息,但不利用网络工程。这项工作是第一个考虑网络工程作为设计重建方法的方法。具体地,我们提出了基于神经架构搜索的重建方法的自动反应方法。在提议的自动升性方法中,发电机架构自动设计为重建预先训练的模型。实验结果表明,使用自动射频法发现的发电机始终提高数据自由压缩的性能。 |
| Smile Like You Mean It: Driving Animatronic Robotic Face with Learned Models Authors Boyuan Chen, Yuhang Hu, Lianfeng Li, Sara Cummings, Hod Lipson 生成智能和普遍化面部表情的能力对于建立人类的社会机器人至关重要。目前,这场领域的进展受到人类需要由人类编程的每个面部表情的影响。为了使机器人行为实时适应与人类受试者互动时出现的不同情况,需要能够能够在不需要人类标签的情况下训练自己,以及制定快速行动决策并将所获得的知识推广到多种和新的环境。我们通过设计具有柔软皮肤的物理狂热的机器人面部,并通过开发面部模仿的视觉自我监督学习框架来解决这一挑战。我们的算法不需要任何知识的机器人运动模型,相机校准或预定义表达式集。通过将学习过程分解为生成模型和反向模型,我们的框架可以使用单个Motor Babbly DataSet培训。综合评估表明,我们的方法可以通过各种人类受试者进行准确和多样化的面部模拟。项目网站是在 |
| Towards Transparent Application of Machine Learning in Video Processing Authors Luka Murn, Marc Gorriz Blanch, Maria Santamaria, Fiona Rivera, Marta Mrak 由于深入学习的突破,已经开发了用于更高效的视频压缩和视频增强的机器学习技术。新技术被认为是人工智能AI先进的先进形式,带来了以前不可预见的能力。然而,它们通常以资源饥饿的黑匣子的形式过度复杂,而内部工作的透明度很小。因此,它们的应用可能是不可预测的并且通常不可靠,因为大规模使用例如在直播。这项工作的目的是了解和优化视频处理应用中的学习模型,因此包含它们的系统可以以更值得信赖的方式使用。在这种情况下,所提出的工作介绍了用于简化学习模型的原则,该模型针对视频制作和分配应用的机器学习的提高透明度。这些原则在视频压缩示例上证明,可以通过简化相关的深度学习模型来实现比特率的节省和降低的复杂性。 |
| On the Advantages of Multiple Stereo Vision Camera Designs for Autonomous Drone Navigation Authors Rui Pimentel de Figueiredo, Jakob Grimm Hansen, Jonas Le Fevre, Martim Brand o, Erdal Kayacan 在这项工作中,我们在耦合与自主导航的艺术规划和映射算法耦合时,展示了多个摄像机UAV的性能的设计和评估。该系统利用最先进的地平线勘探技术,用于下一个最佳视图NBV规划,通过可重新配置的多立体相机系统提供的3D和语义信息。我们在基于自主无人机的检查任务中采用我们的方法,并在自主探索和映射方案中进行评估。我们讨论了使用多立体声相机飞行系统的优缺点,以及相机数量和映射性能之间的折衷。 |
| Dynamic Probabilistic Pruning: A general framework for hardware-constrained pruning at different granularities Authors Lizeth Gonzalez Carabarin, Iris A.M. Huijben, Bastiaan S. Veeling, Alexandre Schmid, Ruud J.G. van Sloun 非结构化的神经网络修剪算法已经实现了令人印象深刻的压缩速率。然而,由此产生的通常不规则不规则的稀疏矩阵妨碍有效的硬件实现,导致额外的内存使用和复杂的控制逻辑,以减少非结构化修剪的益处。这刺激了结构化的粗粒粒子修剪解决方案,该解决方案修剪了整个过滤器或均匀的层,以牺牲柔韧性降低,实现有效的实施。在这里,我们提出了一种灵活的新修剪机制,便于在不同的粒度重量,内核,过滤器特征图中修剪,同时保持有效的记忆组织。对于每个输出神经元的每个输出神经元,修剪完全k为n重量,或者为每个特征映射完全修剪n内核的k。我们将该算法称为动态概率修剪DPP。 DPP利用Gumbel Softmax弛豫,以便对N采样的可分辨率K外,促进结束到最终优化。我们显示DPP在修剪在不同基准数据集接受的常见深度学习模型进行图像分类时实现竞争压缩率和分类准确性。相关的是,DPP的非幅度性质允许进行修剪和权重量化的联合优化,以便进一步压缩我们也显示的网络。最后,我们提出了新颖的信息理论度量,显示了层内修剪掩模的置信度和修剪多样性。 |
| Blurs Make Results Clearer: Spatial Smoothings to Improve Accuracy, Uncertainty, and Robustness Authors Namuk Park, Songkuk Kim 贝叶斯神经网络BNN在不确定性估算和稳健性方面取得了成功。然而,至关重要的挑战禁止他们在实践中使用贝叶斯NNS需要大量预测来产生可靠的结果,从而显着增加计算成本。为了缓解这个问题,我们提出了空间平滑,这是一个合并邻近的CNN的特征映射点的方法。通过简单地将一些模糊层添加到模型中,我们经验证明空间平滑可以提高BNN的精度,不确定性估计和整个集合尺寸的鲁棒性。特别地,包含空间平滑的BNN仅通过少数集合来实现高预测性能。此外,该方法还可以应用于规范确定性神经网络以改善性能。许多证据表明,改进可以归因于损失景观的平滑和平坦化。此外,我们通过作为空间平滑的特殊情况来解决它们的全球平均池,预激活和Relu6,为先前作品提供了基本的解释。这些不仅提高了准确性,而且通过以与空间平滑相同的方式使损失景观更加顺畅,改善不确定性估计和鲁棒性。代码可用 |
| Predict then Interpolate: A Simple Algorithm to Learn Stable Classifiers Authors Yujia Bao, Shiyu Chang, Regina Barzilay 我们提出预测然后插入PI,这是一种简单的算法,用于学习跨环境稳定的相关性。算法从直觉中遵循,即在使用一个环境上训练的分类器时,将对来自另一个环境的示例进行预测的,其错误是信息的信息,以及哪些相关性不稳定。在这项工作中,我们证明,通过插入正确预测和错误预测的分布,我们可以揭示不稳定的相关性消失的Oracle分布。由于无法访问Oracle插值系数,因此我们使用组分布稳健的优化来最小化所有此类插值的最坏情况风险。我们在文本分类和图像分类上评估我们的方法。经验结果表明,我们的算法能够在合成环境中向23.85和自然环境中的12.41学习强大的分类器优于IRM。我们的代码和数据可供选择 |
| Adversarial robustness against multiple $l_p$-threat models at the price of one and how to quickly fine-tune robust models to another threat model Authors Francesco Croce, Matthias Hein 为了实现对抗性鲁棒性WRT单L P威胁模型的对抗训练已经广泛讨论。但是,对于安全关键系统,应同时实现WRT所有L P威胁模型的对抗性鲁棒性。在本文中,我们开发了一种简单而有效的培训方案,以实现对L P威胁模型的联盟的对抗鲁棒性。我们的小说L 1 L 1 Indty的方案基于不同的L P球的几何考虑,以及对单个L P威胁模型的正常对抗训练的成本。此外,我们表明,在方案中使用我们的L 1 L infty可以在1,2,漂移和达到多种常见的对抗鲁棒性中使用3个时尚任何L P鲁棒模型。通过这种方式,我们提升了以上常规鲁棒性的先前现有技术,在CIFAR 10上超过6,并向我们的知识报告了具有多种规范鲁棒性的第一个想象成型模型。此外,我们研究了不同威胁模型之间的对抗鲁棒性的一般转移,并以这种方式将先前的SOTA L 1在CIFAR 10上提升了几乎10的鲁棒性。 |
| Calibrated prediction in and out-of-domain for state-of-the-art saliency modeling Authors Akis Linardos, Matthias K mmerer, Ori Press, Matthias Bethge 自2014年以来,转让学习已成为改善空间显着性预测的关键驱动因素,但在过去3年的最后3年内具有停滞的进展。我们进行大规模转移学习研究,该研究测试了不同的想象底座,始终使用来自DeepGaze II采用的相同读出的架构和学习协议。通过用Reset50替换DeepGaze II的VGG19骨干,我们可以从78到85提高显着性预测的性能。但是,随着我们继续测试更好的想象型模型作为备属衬底,如高效网络,我们遵守显着性预测的额外提高。通过进一步分析底部,发现对其他数据集的概括基本上不同,模型在其固定预测中始终如一地过分。我们表明,通过以原则性地组合多个骨架,可以实现看不见的数据集上的良好置信度校准。这产生了基准性能的显着飞跃,并从域中的域中的域中有15%,在MIT1003上有15%的点改善,标志着所有可用度量标准AUC 88.3,SAUC 79.4的MIT TUEBINGEN固定性基准上的新技术。 CC 82.4。 |
| Towards an IMU-based Pen Online Handwriting Recognizer Authors Mohamad Wehbi, Tim Hamann, Jens Barth, Peter Kaempf, Dario Zanca, Bjoern Eskofier 大多数在线手写识别系统都需要使用特定的写入曲面来提取位置数据。在本文中,我们提出了一种用于Word识别的在线手写识别系统,其基于惯性测量单元IMU用于数字化在纸上写的文本。这是通过装备的传感器获得的传感器,其提供通过蓝牙流动的加速度,角速度和磁力。我们的模型结合了卷积和双向LSTM网络,并通过连接主人的时间分类丢失训练,允许将原始传感器数据解释为单词而不需要序列分割。我们使用使用多个传感器增强笔收集的单词的数据集,并在不使用字典或语言模型的情况下,分别评估我们的不同测试集和未经检测组的模型和看不及17.97和17.08的字符错误率 |
| Weighing Features of Lung and Heart Regions for Thoracic Disease Classification Authors Jiansheng Fang, Yanwu Xu, Yitian Zhao, Yuguang Yan, Junling Liu, Jiang Liu 胸部X射线是筛查胸疾病最常用和价格合理的放射学检查。根据筛选胸部X射线的域名知识,病理信息通常留在肺和心脏区域。然而,在实践中获取区域级注释是昂贵的,模型训练主要依赖于弱监督的方式依赖于弱监督的方式,这对于计算机辅助胸部X射线筛选具有高度挑战性。为了解决这个问题,最近已经提出了一些方法来鉴定含有病理信息的局部区域,这对于胸疾病分类至关重要。受到这一点的启发,我们提出了一种新的深度学习框架,探讨肺和心脏地区的歧视信息。我们设计一个配备多种关注模块的功能提取器,以了解全局图像的全球注意图。为了有效利用疾病特异性提示,我们通过训练有素的像素明智的分割模型定位含有病理信息的肺和心脏区域,以产生二值化掩模。通过在学习的全球关注地图和二值化掩模上引入元素明智的逻辑和运营商,我们获得当地的注意图,其中像素为肺和心区域为1,对于其他区域为0。通过在注意力地图中归零非肺和心脏区域的特征,我们可以有效利用肺和心脏区域的疾病特异性提示。与现有方法融合了全球和本地特征,我们采用了功能权重,以避免肺和心脏区域独一无二的视觉线索。通过基准分流在公开可用的胸部X Ray14数据集进行评估,综合实验表明,与现有技术相比,我们的方法达到了卓越的性能。 |
| Permutation invariance and uncertainty in multitemporal image super-resolution Authors Diego Valsesia, Enrico Magli 最近的进步表明,从低分辨率图像的多模型集合开始,神经网络在超级解析遥感图像中如何非常有效。然而,现有模型忽略了时间置换问题,从而输入图像的时间顺序不携带超分辨率任务的任何相关信息,并导致这种模型与通常稀缺,通常稀缺的地面真实数据效率低下训练。因此,模型不应学习依赖于时间顺序的特征提取器。在本文中,我们展示了建立完全不变的模型到时间置换的模型显着提高了性能和数据效率。此外,我们研究了如何量化超分辨图像的不确定性,以便在产品的本地质量上通知最终用户。我们展示了不确定性如何与系列中的时间变化相关,以及如何加入它进一步提高模型性能。 Proba V挑战数据集的实验显示出对现有技术的显着改进,而无需自乐合并,以及提高数据效率,达到挑战获奖者的表现,只需25个培训数据。 |
| CBANet: Towards Complexity and Bitrate Adaptive Deep Image Compression using a Single Network Authors Jinyang Guo, Dong Xu, Guo Lu 在本文中,我们提出了一种名为复杂性和比特率自适应网络CBanet的新的深度图像压缩框架,其旨在学习一个单个网络来支持不同计算复杂性约束下的变量比特率编码。与现有的基于艺术的图像压缩框架的现有状态相比,仅考虑速率失真折衷而不引入与计算复杂性相关的任何约束,我们的CBanet考虑了动态计算复杂性约束下的速率和失真之间的折衷。具体地,为了在各种计算复杂性约束下用一个单个解码器解码图像,我们提出了一种新的多分支复杂性自适应模块,其中每个分支仅需要解码器的计算预算的一小部分。通过使用不同数量的分支,可以容易地生成具有不同视觉质量的重建图像。此外,为了实现与单个解码器的变量比特率解码,我们提出了比特率自适应模块,以将基本比特率的表示从基站比特率投影到目标比特率的预期表示。然后,它将将目标比特率的传输表示投影回到解码过程的基站处的传输表示。所提出的位自适应模块可以显着降低部署平台的存储要求。因此,我们的CBanet使单个编解码器能够在各种计算复杂性约束下支持多个比特率解码。两个基准数据集的综合实验展示了我们的年轻图像压缩的有效性。 |
| Using the Overlapping Score to Improve Corruption Benchmarks Authors Alfred Laugros, Alice Caplier, Matthieu Ospici 神经网络对各种损坏敏感,通常发生在真实世界应用中,例如模糊,噪音,低的照明条件等。估计神经网络对这些共同损坏的鲁棒性,我们通常使用聚集到基准中的一组建模损坏。遗憾的是,没有人们没有客观标准来确定基准是否代表了大量独立损坏。在本文中,我们提出了一种称为腐败重叠分数的度量标准,可用于揭示腐败基准中的缺陷。当神经网络与这些损坏的稳健性相关时,两个损坏重叠。我们认为考虑到腐败之间的覆盖可以帮助改善现有的基准或构建更好的基准。 |
| What data do we need for training an AV motion planner? Authors Long Chen, Lukas Platinsky, Stefanie Speichert, Blazej Osinski, Oliver Scheel, Yawei Ye, Hugo Grimmett, Luca del Pero, Peter Ondruska 我们调查在人类专家演示中培训基于模仿学习的AV计划所需的传感器数据。机器知识策划者对培训数据非常饥饿,通常使用配备有用于自主操作的相同传感器的车辆收集。这是昂贵和不可扩展的。如果更便宜的传感器可以用于收集,则数据可用性将上升,这在数据卷要求大而且可用性小的领域至关重要。我们使用多达1000小时的专家演示展示实验,并发现具有10X较低质量数据的培训在规划师表现方面优于1x AV等级数据。对此的重要意义是可以确实使用更便宜的传感器。这有助于改善基于模仿的运动计划的数据访问和民主化。除此之外,我们对规划师表现的敏感性分析作为感知范围,视野,准确性和数据量的函数,以及较低质量数据仍提供良好规划结果的原因。 |
| SimNet: Learning Reactive Self-driving Simulations from Real-world Observations Authors Luca Bergamini, Yawei Ye, Oliver Scheel, Long Chen, Chih Hu, Luca Del Pero, Blazej Osinski, Hugo Grimmett, Peter Ondruska 在这项工作中,我们展示了一个简单的端到最终培训机器学习系统,能够逼真地模拟驾驶体验。这可用于验证自动驱动系统性能而不依赖于昂贵且耗时的道路测试。特别是,我们将模拟问题框架作为马尔可夫过程,利用深度神经网络来模拟状态分布和转换功能。这些是直接从现有的原始观察中进行培训,而无需以植物或运动模型的形式的任何手段。所需要的只是历史流量剧集的数据集。我们的配方允许系统构建从未见过的场景展现与自动驾驶汽车行为的实际反应。我们培训我们的系统直接从1000小时的驾驶日志中训练并测量现实主义,模拟的反应性作为模拟的两个关键属性。与此同时,我们应用该方法来评估最近提出的现有技术培训的最近建议的现有状态从人为驾驶日志培训的规划系统。我们发现该规划系统容易出现以前未报告的因果困惑问题,这些问题难以通过非反应模拟进行测试。据我们所知,这是第一个直接合并高度现实数据驱动模拟的工作,为自动驾驶车辆进行闭环评估。我们通过公开提供数据,代码和预训练的型号,以进一步刺激模拟开发。 |
| Graph Self Supervised Learning: the BT, the HSIC, and the VICReg Authors Sayan Nag 在过去几年中,自我监督的学习和预训练策略特别是对于卷积神经网络CNNS。最近应用这些方法也可以用于图形神经网络GNN。在本文中,我们使用了一种基于图的自我监督学习策略,具有不同的损失功能条形孪晶,HSIC 4,ViCREG 1,其在用CNN施用之前显示了有希望的结果。我们还提出了一种混合损失功能,将VICREG和HSIC的优点结合起来并称为vicreghsic。当施加到两个不同的数据集时,已经比较了这些上述方法的性能即诱色和蛋白质。此外,还探讨了不同批量尺寸,投影仪尺寸和数据增强策略的影响。结果是初步的,我们将继续与其他数据集探索。 |
| The Nonlinearity Coefficient -- A Practical Guide to Neural Architecture Design Authors George Philipp 实质上,神经网络是任意可分辨率的参数化功能。为任何任务选择神经网络架构是搜索这些功能的空间的复杂性。在过去的几年里,神经结构设计一直在很大程度上是神经结构搜索NAS的同义词,即蛮力,大规模搜索。 NAS对实际任务产生了显着的收益。然而,NAS方法最终搜索了基于CNN或LSTM的架构周围的架构中的小社区中的架构空间中的局部最优。 |
| Chinese Abs From Machine Translation |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









