










AI视野·今日CS.CV 计算机视觉论文速览
Wed, 2 Jun 2021
Totally 63 papers
👉上期速览✈更多精彩请移步主页

Interesting:
****📚YOLOS You Only Look at One Sequence,纯粹基于序列,不使用空间先验的目标检测模型 。(from 华中科技大学 地平线)

code:https://github.com/hustvl/YOLOS
***📚Markpainting, 基于对抗机器学习的图像补全任务 (from 剑桥大学 多伦多大学 )
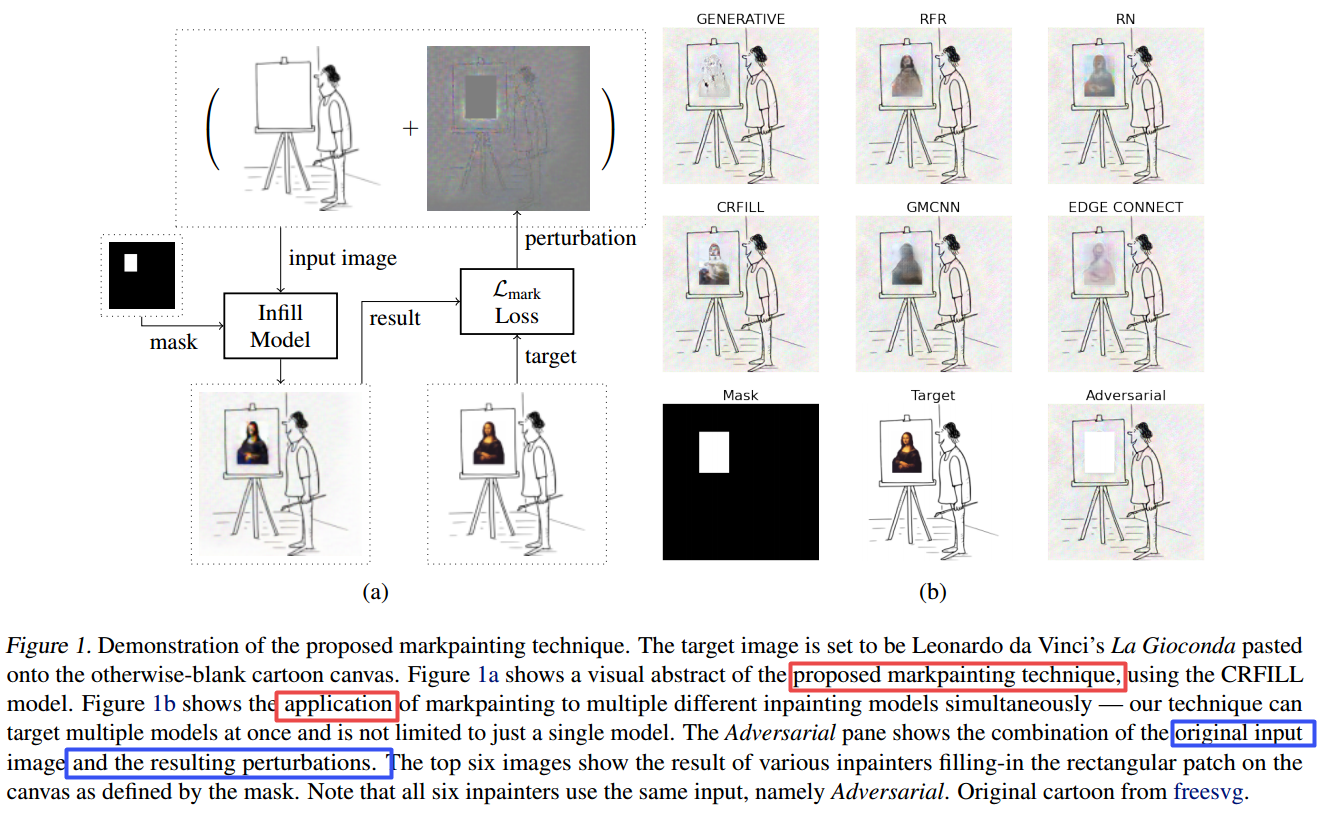
code:https://github.com/iliaishacked/markpainting
📚TransVOS,基于transformer的视频目标分割算法。 (from 浙江大学)

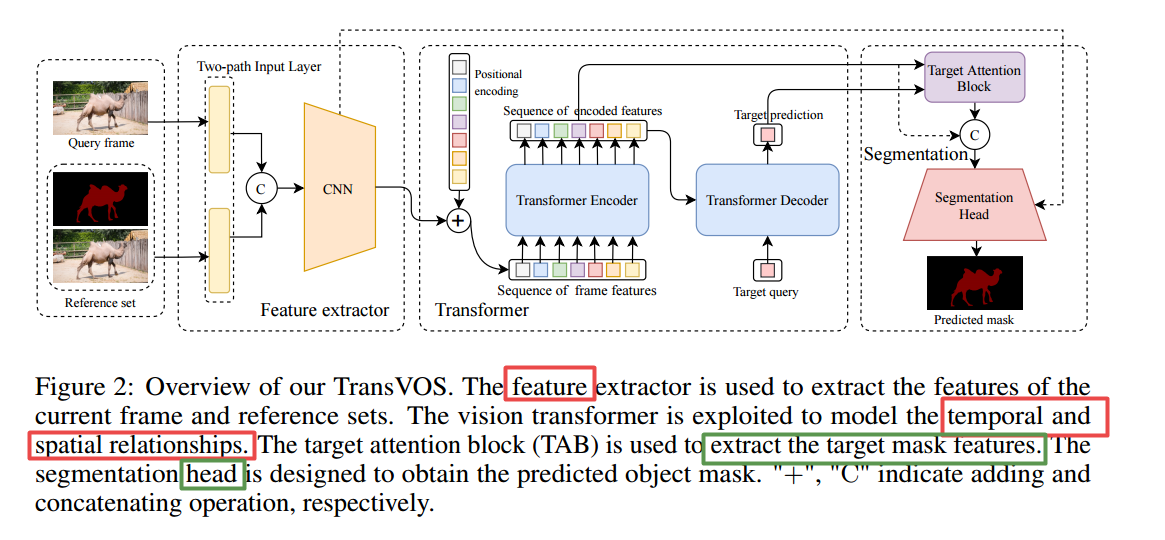
📚Adversarial VQA, 视觉问答模型测评新基准。(from 微软)

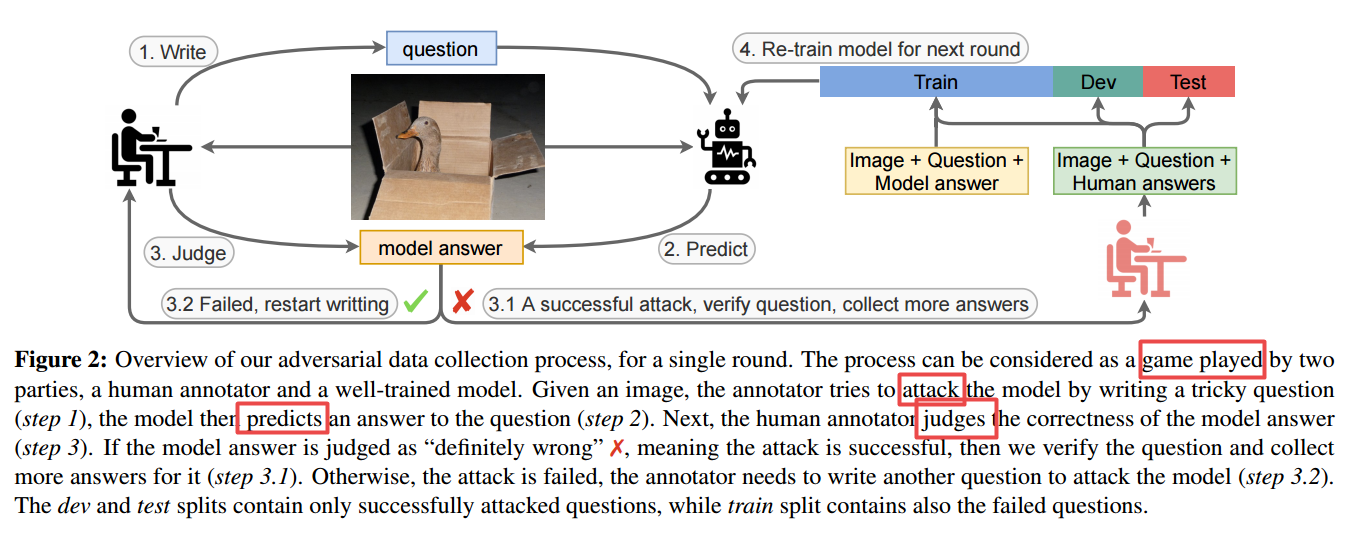
code datset:https://adversarialvqa.github.io/
📚基于复杂联网模型的红外小目标检测, (from 国风科技大学)
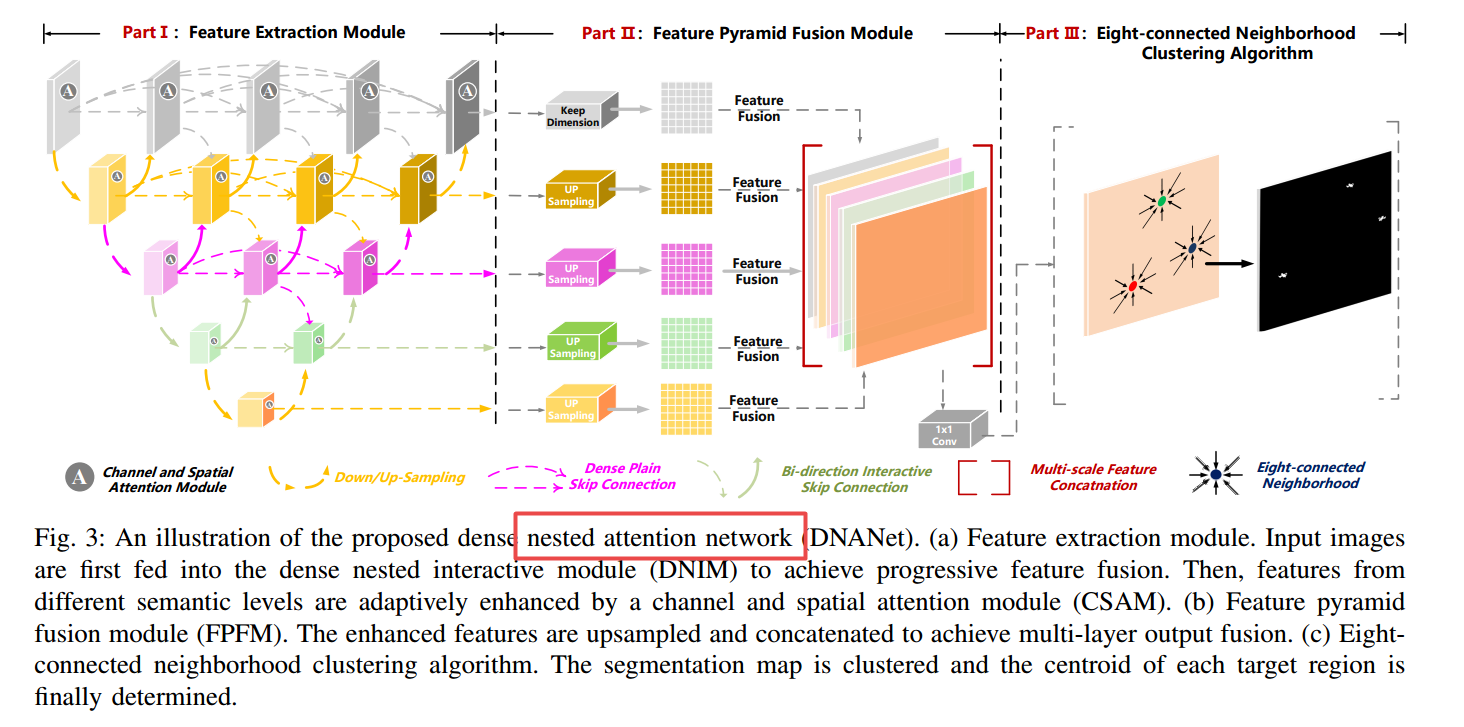
dataset:NUDT-SIRST, NUAA-SIRST
code:https://github.com/YeRen123455/Infrared-Small-Target-Detection
📚CLVA, 基于语言引导的风格迁移 (from 加州大学圣芭芭拉分校)

code: https://ai-sub.github.io/ldist/
📚[visuomotor affordance learningc , VAL)(https://arxiv.org/pdf/2106.00671.pdf), 基于视觉推理学习新技能. (from 伯克利)
📚Volta at SemEval-2021 Task 6, 基于多模态嵌入了图像标准文字语义识别(from IIIT Hyderabad)


Daily Computer Vision Papers
| Bootstrap Your Own Correspondences Authors Mohamed El Banani, Justin Johnson 几何特征提取是点云登记管道的重要组成部分。最近的工作已经证明了如何利用监督学习,以了解更好,更紧凑的3D功能。但是,这些方法依赖地面真相注释限制了它们的可扩展性。我们提出了一个自我监督的方法,从RGB D视频中学习视觉和几何特征,而不依赖地面真理构成或对应。我们的主要观察是随机初始化的CNNS容易向我们提供良好的对应关系,允许我们引导视觉和几何特征的学习。我们的方法将经典思想与更多最近的表示学习方法相结合。我们在室内场景数据集中评估我们的方法,并发现我们的方法优于传统和学习的描述符,同时竞争当前的艺术态度的监督方法。 |
| Fidelity Estimation Improves Noisy-Image Classification with Pretrained Networks Authors Xiaoyu Lin, Deblina Bhattacharjee, Majed El Helou, Sabine S sstrunk 使用深度学习,图像分类显着改善。这主要是由于能够从大型数据集学习丰富的特征提取器的卷积神经网络CNN。然而,即使应用了恢复预处理步骤,处理嘈杂的图像时,大多数深度学习分类方法都在清洁图像上培训,并且在处理嘈杂的步骤时,在处理噪声时也不稳健。虽然新方法解决了这个问题,但它们依赖于修改的特征提取器,因此需要再培训。我们推荐一种可以在佩带的分类器上应用的方法。我们的方法利用融合到特征提取器的内部表示的保真图估计,从而引导网络的注意力并使它更强大地嘈杂的数据。我们通过显着大的边距来改善嘈杂的图像分类NIC结果,特别是在高噪声水平,并且接近完全烫伤的方法。此外,作为概念证明,我们表明,在使用我们的Oracle Fidelity映射时,我们甚至擅长完全训练的方法,无论是嘈杂还是恢复的图像。 |
| You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection Authors Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu 可以从纯序列执行2 mathrm d对象级别识别到序列的透视图对2个mathrm d空间结构的最小知识来回答这个问题,我们展示你只看一个序列yolos,一系列基于的物体检测模型Na Ve Vision变压器具有最少的可能修改以及归纳偏差。我们发现yolos预先训练在中等大小的Imagenet 1K数据集上只能在Coco,Texit exit上实现竞争物体检测性能。 ,从BERT Base直接采用的yolos碱可以实现42.0盒AP。我们还通过对象检测讨论了当前预先列车计划和模型缩放策略的局限性的影响。 URL可提供代码和模型权重 |
| Comprehensive Validation of Automated Whole Body Skeletal Muscle, Adipose Tissue, and Bone Segmentation from 3D CT images for Body Composition Analysis: Towards Extended Body Composition Authors Da Ma, Vincent Chow, Karteek Popuri, Mirza Faisal Beg 计算机辅助精密医学的最新进展使得从人口广泛的模型中可以达到可用于发现基于群体的分析的集合模式,以便在可以推动治疗选择的患者具体决策,以及预测治疗结果。身体组成被认为是各种疾病的重要驾驶员和危险因素,以及对治疗选择或手术干预的个体患者特异性临床结果的预测因素。 3D CT图像通常在肿仓工作手术中获取,并提供内部解剖学的准确渲染,因此可以机会使用,以评估骨骼肌和脂肪组织隔室的量。人工智能的强大工具,如深度学习,现在可以将其分段为整个3D图像并产生所有内部解剖结构的准确测量。这些将使先前存在的严重瓶颈延长,即对手动分割的需要,这对构成3D容量图像的数百个2D轴向切片来说是禁止的。如本文所呈现的自动化工具现在将能够从3D CT或MRI图像中收集全身测量,导致基于个体组织,器官体积,形状和功能状态的各种疾病的驱动程序发现的新时代。迄今为止,这些测量值不可用,从而将该字段限制为非常小而有限的子集。这些发现和具有高速和精度的单个图像分割的可能性可能导致将这些3D测量措施结合到与营养,衰老,嗜疗性,手术和生存率相关的个体特定治疗计划模型中,在主要疾病的发作后如癌症。 |
| Robust Mutual Learning for Semi-supervised Semantic Segmentation Authors Pan Zhang, Bo Zhang, Ting Zhang, Dong Chen, Fang Wen 最近的半监督学习SSL方法通常基于伪标记。由于SSL性能受到伪标签质量的大大影响,因此已经提出了相互学习,以有效地抑制了伪监管中的噪音。在这项工作中,我们提出了强大的相互学习,可以在两个方面提高先前的方法。首先,vanilla相互学习者遭受耦合问题,模型可能会聚以学习均匀知识。我们通过介绍卑鄙教师来产生互动监督,以便在这两个学生之间没有直接互动来解决这个问题。我们还表明,强大的数据增强,模型噪声和异构网络架构对于缓解模型耦合至关重要。其次,我们注意到相互学习未能利用网络的伪标签改进的能力。因此,我们介绍了自我矫正,利用内部知识,并在相互教学之前明确地整流伪标签。这种自我整改和共同教学在整个学习过程中协同提高了伪标签准确性。所提出的强大的互访证明了在低数据制度中的语义分段上的最新性能。 |
| Unsupervised detection of mouse behavioural anomalies using two-stream convolutional autoencoders Authors Ezechukwu I Nwokedi, Rasneer S Bains, Luc Bidaut, Sara Wells, Xujiong Ye, James M Brown 本文探讨了无监督学习在鼠标视频数据中检测异常的应用。本文呈现的两种模型是双流,3D卷积AutoEncoder,具有残留连接和双流,2D卷积AutoEncoder。这里使用的公开数据集包含框架级别注释的单个家庭笼老鼠的十二个视频。在AutoEncoder仅看到正常事件的借口下,手绘以将每个行为视为伪异常,从而在训练期间消除其他行为。结果呈现出一个显眼的行为挂起,一个不起眼的行为新郎。将这些模型的性能与单个流自动码器和监督学习模型进行比较,这两者都基于自定义CAE。两种型号也在Cuhk Avenue集上测试了,发现了艺术架构的某些状态。 |
| Look Wide and Interpret Twice: Improving Performance on Interactive Instruction-following Tasks Authors Van Quang Nguyen, Masanori Suganuma, Takayuki Okatani 在社区越来越感兴趣,在制作一个体现的AI代理人在与环境之后的自然语言指令互动时执行复杂的任务。最近的研究已经解决了使用Alfred的问题,这是任务的精心设计的数据集,但仅实现了非常低的准确性。本文提出了一种新方法,其优于前面的方法大幅度。它是基于几种新想法的组合。一个是提供指令的两个阶段解释。该方法首先在不使用视觉信息的情况下选择并解释指令,产生暂定的动作序列预测。然后,它与视觉信息等集成预测,产生动作和对象的最终预测。由于在第一阶段中识别对象S类来识别,它可以精确地从输入图像中选择正确的对象。此外,我们的方法考虑了对环境的多个Enocentric视图,并通过在当前指令上应用分层注意力来提取基本信息。这有助于准确地预测导航行动。该方法的初步版本赢得了Alfred挑战2020.目前的版本通过单个视图实现了4.45的看不见的环境的成功率,这进一步改善了8.37,具有多种视图。 |
| Semi-Supervised Domain Generalization with Stochastic StyleMatch Authors Kaiyang Zhou, Chen Change Loy, Ziwei Liu 大多数关于域泛化的研究假定从多个域收集的源数据完全注释。然而,在现实世界应用中,由于高注释成本,我们可能只有几个源域提供的几个标签,以及丰富的未标记数据,更容易获得。在这项工作中,我们调查了半监督域泛化SSDG,更加现实和实用的环境。我们所提出的方法,TyperAppation,由FixMatch的启发,是基于伪标签的最先进的半监督学习方法,采用几种新的成分来解决SSDG。具体而言,1以缓解稀缺标记的源数据的过度拟合,同时提高对嘈杂的伪标签的鲁棒性,我们将随机造型引入分类器的权重,视为类原型,具有高斯分布。 2为了增强域移位下的概括,我们将根据弱和强大的增强升级FixMatch S的两个View一致性学习范例,以具有样式增强的多视图版本作为第三个互补视图。为了提供全面的研究和评估,我们建立了两个SSDG基准,该基准涵盖了各种强大的基线方法,包括域泛化和半监督学习。广泛的实验表明,TydeAvatch在低数据制度中实现了最佳分发泛化性能。我们希望我们的方法和基准可以为未来的数据有效和更广泛的学习系统进行铺平。 |
| TransVOS: Video Object Segmentation with Transformers Authors Jianbiao Mei, Mengmeng Wang, Yeneng Lin, Yong Liu 最近,基于空间时间内存网络STM的方法已经在半监控视频对象分段VOS中实现了最先进的性能。此任务中的一个关键问题是如何在不同帧和每个帧中建模依赖关系。然而,大多数这些方法忽略了每个帧内的空间关系,并且不充分利用不同帧之间的时间关系。在本文中,我们提出了一种基于变压器的基于变压器的框架,称为Transvos,引入了一个视觉变压器以充分利用和模拟时间和空间关系。此外,基于STM的方法采用两个不同的编码器来提取两个重要输入的特征,即,参考设置具有预测掩码和查询帧的历史帧,增加了模型参数和复杂性。为了保持有效性的同时缩放流行的两个编码管道,我们设计了一个单个两个路径特征提取器,以统一的方式对上述两个输入进行编码。广泛的实验证明了我们在戴维斯和YouTube VOS数据集上的现有方法的Transvos的优越性。发布时将释放代码。 |
| Prior-Enhanced Few-Shot Segmentation with Meta-Prototypes Authors Jian Wei Zhang, Lei Lv, Yawei Luo, Hao Zhe Feng, Yi Yang, Wei Chen 通过引入情节训练和课程典型原型,广泛推动了很少的射击分割FSS性能。然而,由于三个限制,FSS问题仍然挑战1型号由任务无关信息2分散注意力,单个原型的表示能力是有限的3类相关原型忽略基类的先验知识。我们提出了具有Meta原型的先前增强网络,以解决这些限制。先前的增强网络利用了特征提取中的支持和查询伪标签,该模型指导了专注于前景对象的任务相关特征,并且由于缺乏监督知识而抑制了很多噪声。此外,我们介绍了多个元原型来编码分层特征,并学习类别不可知论性信息。分层功能有助于模型突出显示决策边界并专注于硬像素,并且从基类学习的结构信息被视为新颖类的先前知识。实验表明,我们的方法在Pascal 5 I和Coco 20 I上实现了60.79和41.16的平均IOS分数,在5次拍摄设置中优于3.49和5.64的现有技术。此外,与1次结果相比,我们的方法在上述两台基准上促进了3.73和10.32的5次拍摄精度。我们的方法的源代码可用 |
| Full-Resolution Encoder-Decoder Networks with Multi-Scale Feature Fusion for Human Pose Estimation Authors Jie Ou, Mingjian Chen, Hong Wu 为了实现更准确的2D人类姿势估计,我们以三种方式扩展了成功的编码器解码器网络,简单的基线网络SBN。为了减少由大输出步伐尺寸引起的量化误差,将附加两个解码器模块附加到简单基线网络的末尾以获得完全输出分辨率。然后,将全局上下文块GCB添加到编码器和解码器模块中,以通过全局上下文特征增强它们。此外,我们提出了一种基于新的空间注意力的多尺度特征收集和分配模块SA MFCD,以保险和分配多尺度特征,以提高姿势估计。 MS Coco DataSet上的实验结果表明,我们的网络可以显着提高SBN的人类姿势估计的准确性,我们的网络使用Resnet34作为骨干网络可以实现与Resnet152的SBN相同的准确性,我们的网络可以实现卓越的结果大骨干网。 |
| Predicting Vehicles Trajectories in Urban Scenarios with Transformer Networks and Augmented Information Authors A. Quintanar, D. Fern ndez Llorca, I. Parra, R. Izquierdo, M. A. Sotelo 了解道路用户的行为对于轨迹预测系统的发展至关重要。在这方面,最新的进展集中在经常性结构上,建立了涉及现场的代理商之间的社会互动。最近,还引入了更简单的结构,用于预测基于变压器网络和使用位置信息的人行轨迹。它们允许单独使用每个代理的轨迹,而没有任何复杂的相互作用术语。我们的模型通过添加增强的数据位置和标题来利用这些简单的结构,并将其用于在城市情景中的车辆轨迹预测问题,在预测视野中最多5秒。此外,在不同类型的场景之间执行跨性能分析,包括使用最近的DataSets Ind,Round,HighD和Interaction之间的高速公路,交叉路口和环形交通。我们的模型实现了最新的艺术结果,并证明是灵活的,适应不同类型的城市环境。 |
| Towards Interpretable Attention Networks for Cervical Cancer Analysis Authors Ruiqi Wang, Mohammad Ali Armin, Simon Denman, Lars Petersson, David Ahmedt Aristizabal 深度学习的最新进展使得自动化框架的开发用于分析医学图像和信号,包括分析宫颈癌。许多以前的作品专注于对分离宫颈细胞的分析,或者不提供足够的方法来解释和理解所提出的模型如何达到多个细胞图像的分类决策。这里,我们评估了各种状态的基于艺术深度学习模型和关注的框架,用于多个宫颈细胞的图像的分类。由于我们的目标是提供可解释的深度学习模型来解决这项任务,我们还通过梯度的可视化进行比较他们的解释性。我们展示使用在使用隔离的单个小区图像上使用多个单元的图像的重要性。我们展示了残余通道注意模型的有效性,用于从一组细胞中提取重要特征,并展示该分类任务的这种模型的效率。这项工作突出了通道注意机制在分析多个细胞图像中的潜在关系和分布在一组细胞中的益处。它还提供可解释的模型来解决宫颈细胞的分类。 |
| Exploring the Diversity and Invariance in Yourself for Visual Pre-Training Task Authors Longhui Wei, Lingxi Xie, Wengang Zhou, Houqiang Li, Qi Tian 最近,自我监督的学习方法在视觉前培训任务中取得了显着成功。通过简单地将每个图像的不同增强视图拉到一起或其他新颖的机制,他们可以了解大量无监督的知识,并显着提高预培训模型的转移性能。然而,这些工作仍然无法避免表示崩溃问题,即,它们仅关注限量区域或在每个图像内的完全不同区域上的提取特征几乎相同。通常,这个问题使得预训练模型不能充分描述图像内部的多粒子信息,这进一步限制了它们的传送性能的上限。为了缓解这个问题,本文介绍了一个简单但有效的机制,称为自己探索多样性和不变性。只需简单地推动每个增强视图内的最不同区域,E DIY可以保留提取的区域级别的多样性。通过将最相似的区域从不同的增强视图拉动在一起,E DIY可以确保区域级别特征的稳健性。受益于上述多样性和不变性探索机制,E DIY最大程度地提取每个图像内的多粒度视觉信息。对下游任务的广泛实验表明了我们所提出的方法的优势,例如,与Coco上的强基线Byol相比,与R50 C4骨架和1x学习时间表的微调面膜R CNN相比,有2.1个改进。 |
| KVT: k-NN Attention for Boosting Vision Transformers Authors Pichao Wang, Xue Wang, Fan Wang, Ming Lin, Shuning Chang, Wen Xie, Hao Li, Rong Jin 由于其在捕获地区和翻译不变性的能力,卷积神经网络CNNS已经主导了计算机视觉。最近,已经提出了许多视觉变压器架构,并且他们表现出了有希望的表现。视觉变压器中的一个关键部件是完全连接的自我注意,比模拟长距离依赖性的CNN更强大。然而,由于当前密集的自我注意使用所有图像补丁令牌来计算注意力矩阵,它可能会忽略图像斑块的局部性,并且涉及嘈杂的令牌,例如噪声背景和遮挡,导致慢的训练过程和潜在的性能下降。为了解决这些问题,我们提出了一种稀疏的关注计划,称为K NN注意,用于提升视觉变压器。具体而言,而不是涉及所有引起注意矩阵计算的令牌,我们只能从每个查询中选择来自键的顶部K类似的令牌以计算注意力映射。所提出的K NN注意自然地继承了CNN的当地偏差而不引入卷积操作,因为附近的代币往往比其他令牌更相似。此外,K NN注意允许探索远程相关性,同时通过从整个图像中选择最相似的令牌来滤除无关的令牌。尽管其简单,但理论上和经验,我们验证,K NN注意力在蒸馏来自输入代币和加速培训时的蒸馏噪声。通过使用十种不同的视觉变压器架构进行了广泛的实验,以验证所提出的K NN注意力可以与任何现有的变压器架构合作,以提高其预测性能。 |
| A Novel Graph-Theoretic Deep Representation Learning Method for Multi-Label Remote Sensing Image Retrieval Authors Gencer Sumbul, Beg m Demir 本文介绍了多标签遥感RS图像检索问题的框架中的新图形理论深度陈述学习方法。所提出的方法旨在提取和利用与存档中的每个RS图像相关联的多标签CO发生关系。为此,每个训练图像最初用图形结构表示,该图形结构提供基于区域的图像表示组合本地信息和相关的空间组织。与其他基于图的方法不同,所提出的方法包含一种新的学习策略,用于训练深度神经网络,用于自动预测存档中每个RS图像的图形结构。该策略采用区域表示学习损失函数,以基于其多标签CO发生关系来表征图像内容。实验结果表明,与卢比的检索问题的效果相比,与艺术的深度表示学习方法相比。该方法的代码公开可用 |
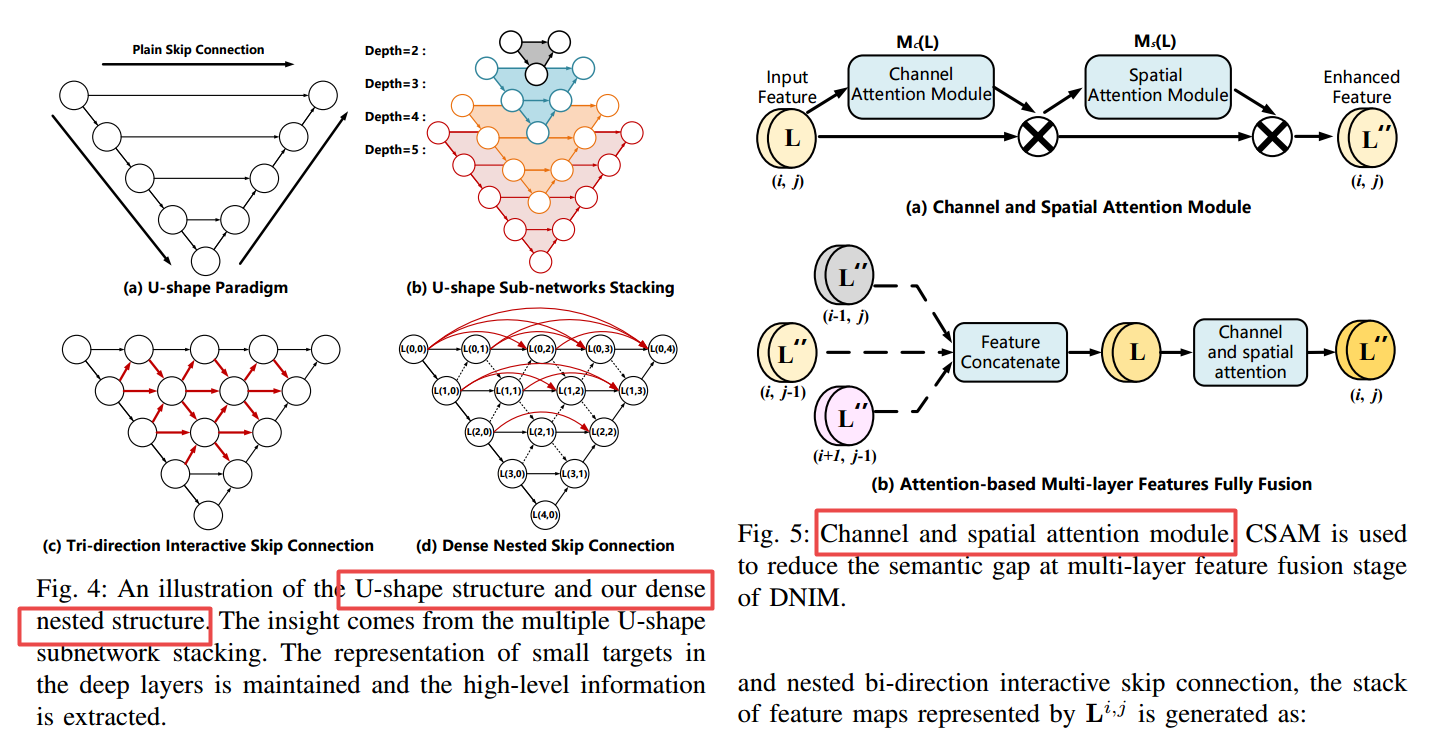
| Dense Nested Attention Network for Infrared Small Target Detection Authors Boyang Li, Chao Xiao, Longguang Wang, Yingqian Wang, Zaiping Lin, Miao Li, Wei An, Yulan Guo 单帧红外小目标SiRST检测旨在将小目标从杂波背景分开。随着深度学习的进步,由于其强大的建模能力,基于CNN的方法产生了有希望的通用物体检测结果。然而,现有的基于CNN的方法不能直接应用于红外小目标,因为其网络中的汇集层可能导致深层的目标丢失。为了处理这个问题,我们提出了一个密集的嵌套关注网络DNANet。具体而言,我们设计密集的嵌套交互模块DNIM,以实现高级和低级功能之间的渐进交互。随着DNIM的重复相互作用,可以保持深层中的红外小目标。基于DNIM,我们进一步提出了一种级联的通道和空间注意模块CSAM,可自适应地增强多级别特征。通过我们的DNANET,小目标的上下文信息可以通过重复的融合和增强充分融入并充分利用。此外,我们开发红外线小目标数据集即,NUDT SiRST并提出一系列评估指标来进行综合性能评估。公共和自我开发数据集的实验证明了我们方法的有效性。与其他技术的方法相比,我们的方法在检测PD,误报率FA和联合iou交叉口方面实现了更好的性能。 |
| Detecting Anomalies in Semantic Segmentation with Prototypes Authors Dario Fontanel, Fabio Cermelli, Massimiliano Mancini, Barbara Caputo 传统的语义分割方法可以在测试时间仅识别训练集中存在的类。这是一个显着的限制,特别是对于安装在智能自治系统上的语义分段算法,部署在现实设置中。无论系统在训练时间看到了多少个类,都是不可避免的,意外,未知的物品将在测试时间出现。在识别这种异常的情况下,在现实世界部署时,可以导致配备有这种分割模型的自治工人的不正确,甚至是危险的行为。当前的异常分割技术使用生成模型,利用他们在训练期间重建无人机的无法解决的模式。然而,训练这些模型是昂贵的,并且它们所生成的伪像可能会产生假异常。在本文中,我们采取了另一个路线,我们建议通过原型学习解决异常分割。我们的直觉是那些与模型已知的所有类原型不同的像素。我们使用基于余弦相似性的分类器以轻量级方式从训练数据中提取类原型。 Streethazars的实验表明,尽管计算开销降低,但我们的方法已经实现了新技术,在以前的作品上具有显着的余量。代码可用 |
| Highlight Timestamp Detection Model for Comedy Videos via Multimodal Sentiment Analysis Authors Fan Huang 如今,互联网上的视频是盛行的。对视频的精确和深入了解是平台和研究人员的困难但有价值的问题。现有的视频理解模型在对象识别任务中做得好,但目前仍然无法理解突出显示在喜剧视频中的突出显示幽默帧的抽象和上下文功能。目前的工业作品也主要集中在基于物体的外表的基本类别分类任务。抽象类别的特征检测方法仍为空白。包括视频帧,音频频谱和文本信息的数据结构提供了探索的新方向。提出了多模式模型,以便在深度视频理解任务中实现这一目标。在本文中,我们分析了抽象对视频的理解困难,并提出了一种多峰结构,以获得该领域的最新性能。然后我们选择多模式视频理解的几个基准,并应用最合适的模型以找到最佳性能。最后,我们在本文中评估了模型和方法的整体聚光灯和缺点,并指出了进一步改进的可能方向。 |
| PanoDR: Spherical Panorama Diminished Reality for Indoor Scenes Authors V. Gkitsas, V. Sterzentsenko, N. Zioulis, G. Albanis, D. Zarpalas 商业360 CIRC相机的上升可用性,称为室内扫描,增加了新颖应用的利益,如室内空间重新设计。 Rifinishe Reality DR符合此类应用程序的要求,以删除现有的现有对象,基本上将其转换为反事实验证任务。虽然数据驱动的尿素的最近进步在产生了现实样本方面表现出显着的进展,但它们并不被限制以产生具有现实映射结构的结果。为了保留室内重新计划应用的现实,场景S结构保存至关重要。为了确保结构意识到的反事实验证,我们提出了一种模型,该模型最初预测室内场景的结构,然后使用它来指导仅相同场景的空背景的重建。我们在为博士修改的结构化3D数据集的版本上培训和比较现有技术的方法,显示出卓越的定量度量和定性结果,但更有趣的是,我们的方法表现出更快的收敛速度。代码和型号可用 |
| Analysis of Vision-based Abnormal Red Blood Cell Classification Authors Annika Wong, Nantheera Anantrasirichai, Thanarat H. Chalidabhongse, Duangdao Palasuwan, Attakorn Palasuwan, David Bull 鉴定红细胞中的异常RBC是诊断从贫血到肝病的一系列医疗病症的关键。目前这是手动完成的,耗时和主观过程。本文提出了一种自动化过程,利用机器学习的优点来提高细胞异常检测的能力和标准化,分析其性能。三种不同的机器学习技术被支持支持向量机SVM,经典机器学习技术TABNET,一个深入的学习架构,用于表格数据U NET,是为医学图像分割而设计的语义分段网络。关键问题是数据集的高度不平衡性质,影响机器学习的功效。为了解决这个问题,通过综合少数群体通过抽样技术进行调查,在特征空间中综合进行少数群体样本,并进行成本敏感学习。研究了这两种方法的组合,以提高整体性能。发现这些策略增加对少数阶级的敏感性。证据证明了未知细胞对语义分割的影响,有一些证据对这些匿名细胞的标记细胞的模型。这些发现表明经典模型和新的深度学习网络是自动化RBC异常检测的有希望的方法。 |
| DLA-Net: Learning Dual Local Attention Features for Semantic Segmentation of Large-Scale Building Facade Point Clouds Authors Yanfei Su, Weiquan Liu, Zhimin Yuan, Ming Cheng, Zhihong Zhang, Xuelun Shen, Cheng Wang 建筑立面的语义分割在各种应用中具有重要意义,例如城市建筑重建和损害评估。由于缺乏与细粒度建筑立面相关的3D点云数据集,因此我们构建了第一个大型建筑外置点云基准数据集进行语义分割。现有的语义分割方法不能完全挖掘点云的本地邻居信息。解决这个问题,我们提出了一种学习的注意模块,了解了本文称为DLA的双地局部注意功能。所提出的DLA模块由两个块组成,包括自我注意块和周度池块,它们都嵌入了增强的位置编码块。 DLA模块可以很容易地嵌入到各种网络架构中,用于点云分割,自然导致具有编码器解码器架构的新的3D语义分段网络,称为DLA网络。我们构造的建筑面部数据集上的广泛实验结果表明,所提出的DLA网络比语义分割的最新方法更好地实现了性能。 |
| Natural Statistics of Network Activations and Implications for Knowledge Distillation Authors Michael Rotman, Lior Wolf 在类似于自然形象统计研究的类似物质中,我们研究了各层深神经网络激活的自然统计。正如我们所展示的那样,这些统计数据类似于图像统计,遵循权力法。我们还在分析和经验上展示,深度这种权力法的指数以线性速度增加。 |
| Towards Efficient Cross-Modal Visual Textual Retrieval using Transformer-Encoder Deep Features Authors Nicola Messina, Giuseppe Amato, Fabrizio Falchi, Claudio Gennaro, St phane Marchand Maillet 跨模型检索是现代搜索引擎中的重要功能,因为它通过允许查询和检索对象来增加不同的模态来增加用户体验。在本文中,我们专注于图像句子检索任务,其中目的是有效地找到给定句子图像检索的相关图像或给定的图像句子检索的相关句子。计算机愿景文献在使用PE引例和自我注意机制的深度神经网络中报告了图像句子匹配任务的最佳结果。它们通过执行整个数据集的连续扫描来评估检索任务的匹配性能。这种方法不适用于越来越多的图像或标题。在这项工作中,我们探讨了不同的预处理技术,以产生从艺术深度学习架构中提取它们的疏散深层多模态特征,用于图像文本匹配。我们的主要目标是放下复杂多模态描述的有效索引的路径。我们使用最近引入的Tern架构作为图像句子功能提取器。它被设计用于制造描述整个图像和句子的固定尺寸1024d向量,以及分别描述两个模态图像区域和句子词的各种建筑组件的1024d向量的可变长度集。所有这些向量由TERN设计强制执行,以划入相同的共同空间。我们的实验表明了探索方法的有趣初步结果,并提出了在这方面的进一步实验。 |
| Consistent Two-Flow Network for Tele-Registration of Point Clouds Authors Zihao Yan, Zimu Yi, Ruizhen Hu, Niloy J. Mitra, Daniel Cohen Or, Hui Huang 部分观察的刚性登记是各种应用领域的基本问题。在计算机图形学中,已经对扫描设备生成的两个部分点云之间的注册进行了特别的注意。当两个点云之间的重叠区域很小时,最先进的注册技术仍然努力,并且如果在扫描对之间没有重叠,则完全失败。在本文中,我们提出了一种基于学习的技术,可以减轻这个问题,并且允许以任意姿势呈现的点云之间的登记,并且几乎没有重叠,这是已被称为远程登记的设置。我们的技术基于新的神经网络设计,该设计学习在一类形状之前,并且可以完成局部形状。关键的想法是以彼此加强的方式结合注册和完成任务。特别是,我们同时使用两个耦合流量来培训登记网络和完成网络,其中一个耦合和完成,以及一个完成和注册,并鼓励两种流动产生一致的结果。我们表明,与每个单独的流程相比,这两个流程训练导致强大而可靠的远程登记,从而实现完成注册扫描的更好点云预测。还值得一提的是,我们的神经网络中的每个组件在完成和注册中优于现有技术的状态。我们进一步分析了我们的网络,具有几项消融研究,并在大量的部分点云,合成和现实世界中展示了其性能,这只有很小或没有重叠。 |
| Semi-Supervised Disparity Estimation with Deep Feature Reconstruction Authors Julia Guerrero Viu, Sergio Izquierdo, Philipp Schr ppel, Thomas Brox 尽管差距估计深入学习的成功,但域概括差距仍然是一个问题。我们提出了一个半监督的管道,通过联合监督培训在标记的合成数据和自我监督培训对未标记的实际数据的自我监督培训的联合监督培训,成功地调整了现实世界领域。此外,考虑了广泛使用的光度损失的局限性,我们分析了深度特征重建的影响作为差异估计的有希望的监控信号。 |
| Independent Prototype Propagation for Zero-Shot Compositionality Authors Frank Ruis, Gertjan Burghours, Doina Bucur 人类擅长组成零射击推理,以前从未见过斑马的人,尽管我们告诉他们它看起来像一匹黑色和白色条纹的马。另一方面,机器学习系统通常利用训练数据中的虚假相关性,而这种相关性可以帮助识别上下文中的对象,但它们损害了泛化。为了能够在分类过程中仍然利用上下文线索的同时处理欠指定的数据集,我们提出了一种新型原型传播图方法。首先,我们学习物体的原型表示,例如有条件独立的斑马。它们的属性标签例如,条纹,反之亦然。接下来我们通过组成图传播独立的原型,以了解反映目标分布依赖性的新型属性对象组合的组成原型。该方法不依赖于任何外部数据,例如类层次结构图或备用单词嵌入式。我们评估了我们在AO聪明,合成和强烈的视觉数据集中的方法,以及清洁标签,UT Zappos,一个嘈杂的真实世界数据集的细粒度鞋类类型。我们表明,在广义的成分零射击设置中,我们优于现有技术的结果,通过消融,我们展示了方法的重要性及其对最终结果的贡献。 |
| Hardness Sampling for Self-Training Based Transductive Zero-Shot Learning Authors Liu Bo, Qiulei Dong, Zhanyi Hu 转换零射击学习T ZSL可以缓解现有ZSL工作中的域移位问题,最近受到了很多关注。然而,在T ZSL中的一个开放问题如何有效利用看不见的类样品进行培训,仍然存在。解决这个问题,我们首先在基于许多ZSL方法中发现的不均匀预测现象,在训练过程中凭经验分析了看不见的课程样本的角色在训练过程中,产生了三种观察。然后,我们提出了两个硬度采样方法,用于根据这些观察结果选择来自给定的未经调整的类数据集的多样化和硬样品的子集。第一个基于模型预测的类级频率识别样本,而通过通过探索的先验估计算法预估计的近似类来归一化类频率,在第二增强前者。最后,我们设计了一种具有用于T ZSL的硬度采样的新的自我训练框架,称为STH,其中可以无缝地嵌入任意电感ZSL方法,并且通过硬度采样方法选择的观看类别样本迭代培训。我们将两种典型的ZSL方法介绍到STHS框架中,并且广泛的实验表明,衍生的T ZSL方法在三个公共基准测试中占据了许多现有技术的状态。此外,我们注意到未经调整的DataSet可以单独用于培训某些现有的转换通用ZSL方法,这对于GZSL任务来说并不严格。因此,我们建议更严格的T GZSL数据设置,并通过向T GZSL引入提议的STHS框架来建立一个竞争基线。 |
| Reconciliation of Statistical and Spatial Sparsity For Robust Image and Image-Set Classification Authors Hao Cheng, Kim Hui Yap, Bihan Wen 通过从大型数据集的深度学习深度特征,最近的图像分类算法已经实现了与基于经典的特征的方法相比的更好的结果。然而,实践中的图像分类仍然存在各种挑战,例如在限量数据集上对噪声图像或图像设置查询以及训练深图像分类模型。基于模型的方法而不是应用通用深度特征,可以更有效,并且对鲁棒图像和图像设置分类任务的数据有效,因为可以利用各种图像前沿用于在防止接合拟合的同时建模和内设定数据变化。在这项工作中,我们提出了一种新颖的联合统计和空间稀疏表示,被称为分类的图像或图像集数据,通过映射到Riemannian歧管的全局高斯分布。据我们所知,无效迄今为止,通过联合稀疏表示共同使用全局统计和本地补丁结构。我们建议通过使用关节稀疏性耦合本地和全局图像表示来解决基于J3S模型的关节稀疏编码问题。学习的J3S模型用于鲁棒图像和图像集分类。实验表明,所提出的J3S基于J3S的图像分类方案优于FMD,UIUC,ETH 80和YTC数据库上的艺术竞争方法的流行或状态。 |
| Adversarial VQA: A New Benchmark for Evaluating the Robustness of VQA Models Authors Linjie Li, Jie Lei, Zhe Gan, Jingjing Liu 凭借大规模的预培训,过去两年目睹了对VQA任务的视觉问题的显着性能提升。虽然已经进行了快速进展,但仍然尚不清楚这些艺术SOTA VQA模型是否在野生中遇到测试示例时是强大的。为研究这一点,我们介绍了一个新的大规模VQA基准,通过循环过程中的对抗人和模型来迭代地收集的对抗性VQA。通过这个新的基准,我们展示了几个有趣的发现。令人惊讶的是,在数据集收藏期间,我们发现非专家注释器可以相对容易地成功攻击SOTA VQA模型。 II我们在新数据集中测试各种SOTA VQA模型,以突出显示其脆弱性,并发现大规模预训练的型号和对抗性训练方法只能达到比标准VQA V2数据集所实现的更低的性能。 III被视为数据增强时,我们的数据集可用于提高其他强大的VQA基准测试的性能。 IV我们对数据集进行了详细的分析,为其为社区带来的挑战提供了有价值的见解。我们希望对抗性VQA可以作为一个有价值的基准,将来将通过未来的工作来测试其开发的VQA模型的稳健性。我们的数据集在HTTPS AdversarialVQA公开提供。 |
| VA-GCN: A Vector Attention Graph Convolution Network for learning on Point Clouds Authors Haotian Hu, Fanyi Wang, Huixiao Le 由于对地方聚合运营商的研究发展,在点云分析模型中取得了戏剧性的突破。但是,当前文献中的现有本地聚合运算符不能将体面重要性与点云的本地信息相提并论,这限制了模型的功率。为了符合这个差距,我们提出了一种有效的矢量注意卷积模块Vaconv,它利用K最近邻kNN提取每个输入点的邻点,然后使用中心点与其邻居之间的向量和方位角关系。构建注意力矩阵的边缘特征。之后,Vaconv采用双通道结构来熔断加权边缘特征和全局特征。为了验证Vaconv的效率,我们将Vaconv与不同的接收场并行连接,以获得多尺度图形卷积网络,VA GCN。提议的VA GCN在包括ModelNet40,S3DIS和ShapEnet的标准基准上实现了最新的最新性能。值得注意的是,与3D分类的模型网络数据集上,与基线相比,VA GCN增加了2.4。 |
| EV-VGCNN: A Voxel Graph CNN for Event-based Object Classification Authors Yongjian Deng, Hao Chen, Huiying Chen, Youfu Li 事件摄像机报告稀疏强度变化,并保持低功耗,高动态范围和高响应速度的明显优点,以便在便携式设备上进行视觉感知和理解。基于事件的学习方法最近通过将事件集成到基于密集的帧的表示来实现对象识别的大规模成功,以应用传统的2D学习算法。然而,这些方法在稀疏期间引入了很多冗余信息,以密集转换,并且需要具有较重重量和大容量的模型,限制了事件摄像机在现实生活中的潜力。为了解决基于事件的分类模型的平衡精度和模型复杂性的核心问题,我们1构建了事件数据的图表表示,更好地利用其稀疏性,并设计一个轻量级的端到端图形图形神经网络EV VGCNN用于分类2使用体素明智的顶点不是传统的点明智方法将来自更多点3的信息引入多尺度特征关系层MFR1以从每个顶点自适应地对邻居的距离提取语义和运动提示。综合实验表明,我们的方法预付了现有技术的状态准确性,同时仅实现了近20倍的参数减少了0.84M参数。 |
| Rethinking Re-Sampling in Imbalanced Semi-Supervised Learning Authors Ju He, Adam Kortylewski, Shaokang Yang, Shuai Liu, Cheng Yang, Changhu Wang, Alan Yuille 半监督学习SSL在标记数据稀缺时,在利用未标记数据的情况下表明了它的强大能力。但是,大多数SSL算法在假设中,在培训和测试集中均衡了类分布。在这项工作中,我们考虑SSL上的类别不平衡数据的问题,这更好地反映了现实世界情况,但到目前为止只接受了有限的注意。特别地,我们将表示和分类器的训练分离,并系统地研究不同数据重复采样技术的效果在训练包括分类器的整个网络以及仅精确调整特征提取器时。我们发现数据重新采样是至关重要的,以了解良好的分类器,因为它增加了伪标签的准确性,特别是对于未标记数据中的少数群体。有趣的是,我们发现准确的伪标签在训练特征提取器时无帮助,相反,数据重新采样损害了特征提取器的训练。这一发现是针对一般直觉的,错误的伪标签始终损害SSL的模型性能。基于这些发现,我们建议重新思考当前的范例,具有单个数据重新采样策略,并在类上不平衡数据上开发SSL的简单但高效的BI采样BIS策略。 BIS实现了两种不同的RE采样策略,用于训练特征提取器和分类器,并将这种解耦培训集成到结束框架中......代码将被释放 |
| Towards Real-time and Light-weight Line Segment Detection Authors Geonmo Gu, Byungsoo Ko, SeoungHyun Go, Sung Hyun Lee, Jingeun Lee, Minchul Shin 之前的基于深度学习的线段检测LSD遭受巨大的模型尺寸和高计算成本的线路预测。这将它们从实时推理到计算限制环境约束。在本文中,我们提出了一个名为Mobile LSD M LSD的资源受限环境的实时和轻型线段检测器。我们通过最大限度地减少骨干网络并在以前的方法中删除典型的多模块过程来设计一个极其高效的LSD架构。为了通过这种轻量级网络保持竞争性能,我们提出了线段SOL增强和几何学习方案的新颖训练方案。 Sol Augmentation将线段分成多个子部分,用于在训练过程中提供辅助线数据。此外,几何学习方案允许模型从匹配丢失,结和线分割,长度和度回归捕获额外的几何线索。与TP LSD Lite相比,以前最好的实时LSD方法,我们的MLD Tiny型号在使用Wireframe和Yorkurynan Datasets评估时,GPU的推广速度增加了2.5的竞争性能。此外,我们的模型分别在Android和iPhone移动设备上运行56.8 FPS和48.6 FPS。据我们所知,这是移动设备上第一个可用的真正的Deep LSD方法。 |
| Anti-aliasing Semantic Reconstruction for Few-Shot Semantic Segmentation Authors Binghao Liu, Yao Ding, Jianbin Jiao, Xiangyang Ji, Qixiang Ye 在少量拍摄语义细分中,通过利用基础课程的特征来提出令人鼓舞的进展,具有足够的培训数据来代表具有少量拍摄示例的新型课程。然而,当它们具有类似的语义构图时,这种特征共享机制在新颖类别之间不可避免地导致语义混叠。在本文中,我们将少量拍摄分段作为语义重建问题进行重整,并将基类功能转换为一系列基础向量,该载体跨越新型类重建的类级语义空间。通过引入对比损失,我们最大化基础向量的正交性,同时最小化课程之间的语义混叠。在重建的表示空间内,我们通过将查询特征投影到支持向量以获得精确语义激活来进一步抑制来自其他类的干扰。我们所提出的方法称为抗混叠语义重建ASR,为少量学习问题提供了系统但可解释的解决方案。对Pascal VOC和MS COCO数据集的广泛实验表明,与现有作品相比,ASR实现了强劲的结果。 |
| Quantification of Carbon Sequestration in Urban Forests Authors Levente Klein, Wang Zhou, Conrad Albrecht 植被,树木尤其通过吸收大气中的二氧化碳螯合碳,然而,缺乏储存在树中的碳的有效量化方法使得难以跟踪该过程。在这里,我们提出了一种基于融合多光谱空中图像和LIDAR数据来估计树木中的碳储存的方法,以识别树木覆盖,几何形状和树种,这是碳储存量化中至关重要的属性。我们证明了树种信息及其三维几何形状可以从远程图像估计,以便计算树的生物质。具体而言,对于纽约市的曼哈顿,我们估计总共52,000吨碳在树上隔离。 |
| Dual Normalization Multitasking for Audio-Visual Sounding Object Localization Authors Tokuhiro Nishikawa, Daiki Shimada, Jerry Jun Yokono 虽然已经报告了在不受约束视频中的有关视听声源定位的几个研究作品,但文献中没有提出数据集和指标,以定量评估其性能。定义声源定位的地面真相很难,因为产生声音的位置不限于源对象的范围,但振动传播并通过周围物体传播。因此,我们提出了一种新的概念,声音对象,以减少声音视觉定位的歧义,使得可以注释各种声源的位置。通过新提出的定量评估指标,我们制定了音频视觉探测对象定位AVSOL的问题。我们还通过手动注释众所周知的音频视觉活动AVE数据集的测试集来创建评估数据集AVSOL E DataSet。为了解决这个新的AVSOL问题,我们提出了一种新的多任务培训策略和架构,称为双向归一化多任务DNM,其将视频视觉对应AVC任务和视频事件的分类任务聚合到单个音频视觉相似度映射中。通过高效地利用DNM的监督,我们所提出的架构显着优于基线方法。 |
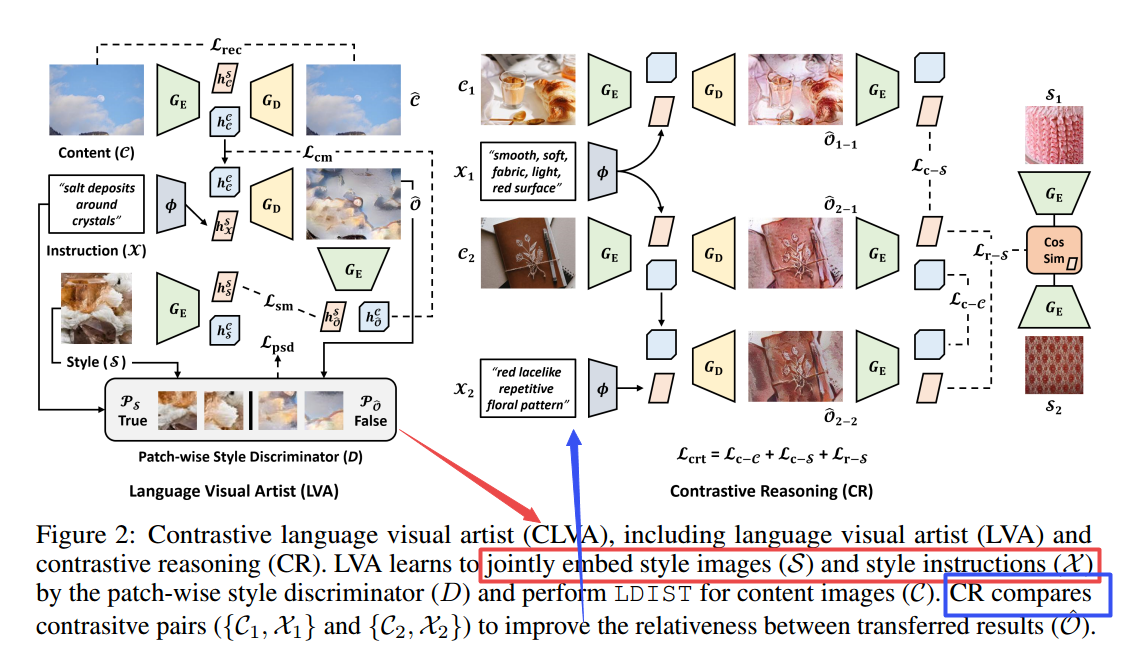
| Language-Driven Image Style Transfer Authors Tsu Jui Fu, Xin Eric Wang, William Yang Wang 尽管有希望的结果,风格转移需要提前准备风格图像,可能导致缺乏创造力和可访问性。另一方面,在人类指导之后是执行艺术风格转移的最自然的方式,可以显着提高视觉效果应用的可控性。我们介绍了一个新的任务语言驱动图像样式传输TextTT LDist,以操纵内容图像的样式,由文本引导。我们提出了对比语言视觉艺术家CLVA,了解从样式指令中提取视觉语义,并通过修补程序样式鉴别器完成Texttt Ldist。鉴别员考虑样式图像语言和补丁之间的相关性或将结果转移到共同嵌入样式指令。 CLVA进一步比较了对比度对的内容图像和风格指令,以提高转移结果之间的相互关系。来自相同内容图像的转移结果可以保留一致的内容结构。此外,它们应该从含有类似视觉语义的样式说明中呈现类似的样式模式。实验表明,我们的CLVA是有效的,在Texttt Ldist上实现了一流的转移结果。 |
| Rethinking Pseudo Labels for Semi-Supervised Object Detection Authors Hengduo Li, Zuxuan Wu, Abhinav Shrivastava, Larry S. Davis 半系统的最新进展在很大程度上由基于一致性的伪标记方法驱动,用于图像分类任务,产生伪标签作为监控信号。然而,在使用伪标签时,缺乏考虑本地化精度和放大的类别不平衡,这两者都对于检测任务至关重要。在本文中,我们介绍了针对物体检测量身定制的确定性意识的伪标签,可以有效地估算导出的伪标签的分类和定位质量。这是通过将传统定位转换为分类任务之后的传统定位来实现的。在分类和本地化质量分数上调节,我们动态调整用于为每个类别生成伪标签和重重损耗函数的阈值来缓解类别不平衡问题。广泛的实验表明,我们的方法分别在CoCo和Pascal VOC上的1 2和4 6 AP改善了现有技术的性能。在有限的注释制度中,我们的方法通过来自Coco的1个标记数据仅使用1 10个标记的数据来改善监督基准。 |
| Integrative Use of Computer Vision and Unmanned Aircraft Technologies in Public Inspection: Foreign Object Debris Image Collection Authors Travis J. E. Munyer, Daniel Brinkman, Chenyu Huang, Xin Zhong 无人驾驶飞机系统UA已成为公共服务提供商和智能城市的重要资源。本研究的目的是通过整合计算机视觉和UAS技术来实现本研究领域以自动化公共检查。作为这项工作的初始案例研究,开发了普通异物碎片FOD的数据集以评估轻量级自动检测的电位。本文提出了本数据集的理由和创建。未来的工作迭代将包括进一步的技术细节,分析实验实施。在本地机场,UAS和便携式摄像机用于收集该数据集的初始版本中包含的数据。收集以下视频后,它们被分成单独的帧并存储为几千图像。然后,这些帧按照标准计算机视觉格式注释并存储在反映我们创建方法的文件夹结构中。数据集注释是使用自定义工具验证,可以抽象以适应未来的应用程序。使用着名的初始检测模型成功创建了您只有一次看一次算法,这表明了所提出的数据的实用性。最后,提出了可以利用此数据集或类似方法的几种潜在方案。 |
| Deep learning for prediction of hepatocellular carcinoma recurrence after resection or liver transplantation: a discovery and validation study Authors Zhikun Liu, Yuanpeng Liu, Yuan Hong, Jinwen Meng, Jianguo Wang, Shusen Zheng, Xiao Xu 本研究旨在通过使用深受基于深度学习的神经网络直接分析普遍存在的组织学图像,在切除或肝移植LT进行预后的分类机。 Nucleus Map集合用于训练U网以捕获核架构信息。火车集包括通过切除治疗的HCC患者,具有明显的结果。 LT含有HCC患者的患者。火车集及其UNT提取的核架构信息用于培训MobileNet V2基于分类器MobileNetv2 HCC类,用于分类超级化异构图像的目的。 MobileNetv2 HCC类维持比HCC切除在独立验证集中或LT LT之后的其他因素相对更高的歧视性。病理综述表明,肿瘤区域最复发的肿瘤区域的特征是基质的存在,高度细胞学类别,核迁移性和缺乏免疫渗透。使用深入学习依赖于组织学幻灯片而开发了临床有用的预后分类器。分类器已被广泛评估具有不同治疗的独立患者群体,并在典型临床,生物学和病理特征中赋予一致的优异成果。分类器有助于精炼HCC患者的预后预测,并识别从更密集的管理中受益的患者。 |
| Closer Look at the Uncertainty Estimation in Semantic Segmentation under Distributional Shift Authors Sebastian Cygert, Bart omiej Wr blewski, Karol Wo niak, Rados aw S owi ski, Andrzej Czy ewski 虽然最近的计算机视觉算法在许多基准上实现了令人印象深刻的性能,但它们缺乏来自不同分布的图像的鲁棒性,例如,图像具有不同的分布。在训练期间,不考虑的天气或照明条件,它们可能会产生错误的预测。因此,期望这种模型能够可靠地预测其置信度量。在这项工作中,在交叉数据集设置中的不同域移位的不同级别的域移位和时,在从仿真中调整培训的模型时,评估对语义分割任务的不确定性估计。结果表明,简单的彩色变换已经提供了强大的基线,可与使用更复杂的样式传输数据增强相当。此外,通过构建由使用不同骨架和或增强方法的模型组成的集合,可以在域移位设置下的整体精度和不确定性估计方面提高显着的模型性能。预期的校准误差ECE对Cutycapes适应的挑战性GTA适应性降低到1.1的竞争值。此外,在自训练设置中使用模型的集合以改善伪标号的产生,这与最终模型精度的显着增益相比,与没有合并的标准微调相比。 |
| Continual 3D Convolutional Neural Networks for Real-time Processing of Videos Authors Lukas Hedegaard, Alexandros Iosifidis 本文介绍了持续的3D卷积神经网络CO3D CNN,这是一种新的时空时间3D CNN的计算配方,其中通过帧而不是通过夹子处理帧的视频。在在线处理任务中要求框架明智的预测中,CO3D CNNS分配了普通3D CNN的计算冗余,即,在多个剪辑中出现的重复卷积。在计算节省中产生幅度的数量级,CO3D CNN具有与相应的常规3D CNN的内存要求相当,并且受时间接收场大小的变化的影响较小。我们示出了从识别视频识别模型的预先存在状态的重量上初始化的持续3D CNN通过10.0 12.4X减少了框架明智计算的浮点操作,同时提高了400的动力学精度2.3 3.8。此外,我们研究了CO3D CNNS的瞬态启动响应,并在现代硬件上进行了广泛的在线处理速度的基准以及可公开的艺术状态的可公开状态。 |
| Incorporating Visual Layout Structures for Scientific Text Classification Authors Zejiang Shen, Kyle Lo, Lucy Lu Wang, Bailey Kuehl, Daniel S. Weld, Doug Downey 分类科学论文标题,作者,正文文本等的核心文本组成部分是自动科学文档理解的关键第一步。以前的工作已经显示了如何使用基本布局信息,即页面上的每个令牌的2D位置,导致更准确的分类。我们介绍了用于将视觉布局结构VILA的新方法,例如,将页面文本分组到文本行或文本块中,进入语言模型,以进一步提高性能。我们展示了IVIA方法,即在模型输入中添加了表示布局结构之间的界限的特殊令牌,可以导致令牌分类任务中的1 4.5 F1分数改进。此外,我们设计了一个分层模型H VILA,它们编码这些布局结构,并在不损害预测精度的情况下记录最多70效率提升。实验在新策划的评估套件S2 VLUE上进行,具有新的度量测量VILA意识和覆盖19个科学学科的新数据集。预先培训的权重,基准数据集和源代码将可用 |
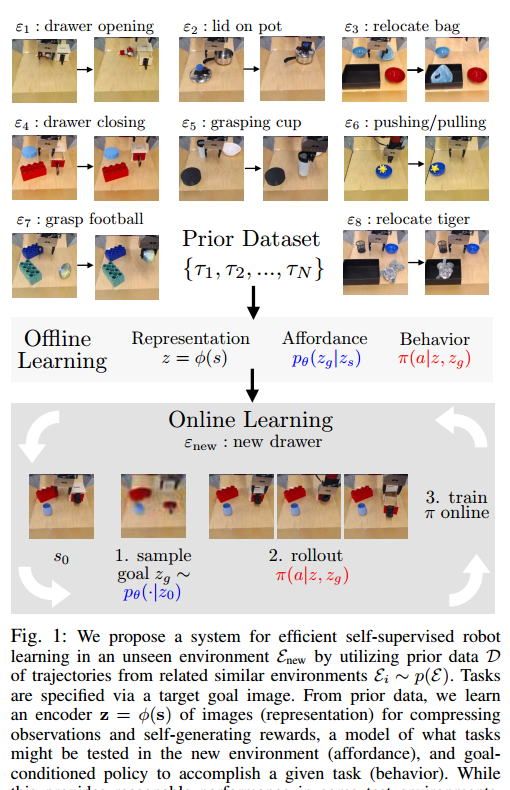
| What Can I Do Here? Learning New Skills by Imagining Visual Affordances Authors Alexander Khazatsky, Ashvin Nair, Daniel Jing, Sergey Levine 配备学习技能的一般机器人必须能够在许多不同的环境中执行许多任务。但是,对新设置的零拍摄概括并不总是可能的。当机器人遇到新的环境或对象时,可能需要芬特将其一些以前学习的技能适应这种变化。但是,至关重要的是,以前学习的行为和模型仍然适合加速这一收益。在本文中,我们的目标是研究可能结果的生成模式如何允许机器人学习带来的视觉表现,以便机器人可以在新情况下对可能的可能结果进行示范,然后进一步培训其政策以实现这些结果。实际上,先前的数据用于了解可能是什么类型的结果,使得当机器人遇到一个不熟悉的环境时,它可以从其模型中采样潜在的结果,试图到达它们,从而更新其技能及其结果模型。这种方法,Visuomotor提供学习val,可用于培训在原始图像输入上运行的目标条件策略,并且可以通过我们提出的可用定向探索方案来迅速学习来操纵新物品。我们展示VAL可以利用先前的数据来解决现实世界任务,这些抽屉打开,抓握和将物体放在新场景中,只有五分钟的在线体验。 |
| Markpainting: Adversarial Machine Learning meets Inpainting Authors David Khachaturov, Ilia Shumailov, Yiren Zhao, Nicolas Papernot, Ross Anderson 批准是一种学习的插值技术,基于生成建模,并且用于填充图像中具有广泛应用程序的屏蔽或丢失的部分。最近,初步开始用于去除水印,提高担忧。在本文中,我们研究如何使用我们的Markpainting技术来操纵它。首先,我们展示如何访问染色模型的图像所有者可以以这样的方式增强其图像,即任何尝试使用该模型编辑它的方式将添加任意可见信息。我们发现我们可以通过我们的技术同时定位多种不同的模型。如果编辑器一直在尝试删除它,这可以设计重新构建水印。其次,我们表明我们的Markpainting技术可转移到具有不同架构的模型或者在不同的数据集上培训,因此使用它的水印难以删除的对手。 Markpainting是新颖的,可以用作操纵警报,这在初始化时变得可见。 |
| Hyperspectral Band Selection for Multispectral Image Classification with Convolutional Networks Authors Giorgio Morales, John Sheppard, Riley Logan, Joseph Shaw 近年来,Hyperspectral映像HSI已成为可靠数据的强大资源,如遥感,农业和生物医学的应用中的可靠数据。然而,高光谱图像是高度数据密度,并且通常受益于减少频谱频带数量的方法,同时保留特定应用的最有用信息。我们提出了一种新的带选择方法来选择从图像分类的上下文中的HSI系统获得的减少的波长集。我们的方法由两个主要步骤组成,首先利用基于滤波器的方法来基于频带及其邻居之间的共线性分析来找到相关的光谱频带。此分析有助于删除冗余频带并大大减少搜索空间。第二步应用基于包装器的方法来根据其信息熵值从减小的集合中选择频带,并列进紧凑型卷积神经网络CNN以评估当前选择的性能。我们提出了从我们的方法获得的分类结果,并将它们与两个高光谱图像数据集的其他特征选择方法进行比较。此外,我们使用原始的超光数据立方体模拟使用多光谱成像器中的实际滤波器的过程。我们表明我们的方法为多光谱传感器设计产生了更合适的结果。 |
| Quantifying Predictive Uncertainty in Medical Image Analysis with Deep Kernel Learning Authors Zhiliang Wu, Yinchong Yang, Jindong Gu, Volker Tresp 深度神经网络越来越多地用于医学图像的分析。然而,大多数作品忽略了模型S预测中的不确定性。我们提出了一种不确定性意识的深核学习模型,该模型允许卷积神经网络的管道预测中的不确定性和稀疏高斯过程的不确定性。此外,我们适应不同的预培训方法来调查它们对所提出的模型的影响。我们将我们的方法应用于骨骼年龄预测和病变定位。在大多数情况下,与常见架构相比,所提出的模型显示出更好的性能。更重要的是,我们的模型在系统地表达更准确的预测和对较低准确的信心的信心。我们的模型也可用于检测具有挑战性和有争议的测试样本。与Monte Carlo辍学等相关方法相比,我们的方法以纯粹的分析方式导出不确定性信息,因此计算得更高。 |
| Decoupling Shape and Density for Liver Lesion Synthesis Using Conditional Generative Adversarial Networks Authors Dario Augusto Borges Oliveira 病变综合在增强培训数据,绘制病变演变情景或辅助专家培训的高效生成模型的兴起中受到了很多关注。合成数据的质量和多样性高度依赖于用于训练模型的注释数据,这不仅易于从训练中获得非常不同的现实样本。这将固有的偏差添加到病变分段算法,并有效地限制了病变演变方案。本文呈现了一种用于解耦的方法和密度,用于肝脏病变合成,产生允许直接驱动合成的框架。我们提供定性结果,通过单独修改形状和密度来提供合成控制,并证明嵌入发电机模型中的密度信息的定量结果有助于增加病变分段性能,而仅与使用形状相比使用。 |
| Exposing Previously Undetectable Faults in Deep Neural Networks Authors Isaac Dunn, Hadrien Pouget, Daniel Kroening, Tom Melham 通过约束原始特征,测试DNN的现有方法解决了原始功能。图像像素值在较小的数据集示例中,所需的DNN输出是已知的。但这限制了这些方法能够检测的类型。在本文中,我们介绍了一种新型DNN测试方法,可以在其他方法中找到DNN中的故障。该症状是,通过利用生成机器学习,我们可以生成在其高级功能中变化的新测试输入,这些内容包括对象形状,位置,纹理和颜色。我们展示我们的方法能够检测故意注入的故障以及最先进的DNN中的新故障,并且在这两种情况下,现有方法都无法找到这些故障。 |
| RAI-Net: Range-Adaptive LiDAR Point Cloud Frame Interpolation Network Authors Lili Zhao, Zezhi Zhu, Xuhu Lin, Xuezhou Guo, Qian Yin, Wenyi Wang, Jianwen Chen LIDAR点云帧插值,合成捕获帧之间的中间帧,已成为许多应用程序的重要问题。特别是为了减少点云传输的量,它是基于参考帧来预测中间帧,以将数据上拉到高帧速率。然而,由于点云的高维和稀疏特征,预测LIDAR点云的中间帧比视频更难以预测。在本文中,我们提出了一种新颖的LIDAR点云帧插值方法,其利用范围图像RIS作为CNN的中间表示来进行帧插值处理。考虑到RIS的继承特征与彩色图像的遗传特征不同,我们在自适应地提取空间自适应卷积以提取范围特征,而呈现高效的流量估计方法以产生光学流量。该建议的模型基于光学流量来扭曲输入帧和范围特征,以合成内插帧。 Kitti DataSet的广泛实验已经清楚地证明,我们的方法一致地实现了优异的帧插值,以便更好地感知质量与使用现有技术帧插值方法的状态。该提出的方法可以集成到任何LIDAR点云压缩系统中,用于帧间预测。 |
| COV-ECGNET: COVID-19 detection using ECG trace images with deep convolutional neural network Authors Tawsifur Rahman, Alex Akinbi, Muhammad E. H. Chowdhury, Tarik A. Rashid, Abdulkadir eng r, Amith Khandakar, Khandaker Reajul Islam, Aras M. Ismael Covid 19的可靠和快速识别至关重要,以防止疾病的快速传播,缓解锁定限制,减少对公共卫生基础设施的压力。最近,已经提出了几种方法和技术来使用不同的图像和数据检测SARS COV 2病毒。然而,这是第一研究,它将探讨使用深卷积神经网络CNN模型来检测来自心电图的COVID 19的可能性。在这项工作中,使用深度学习技术检测到Covid 19和其他心血管疾病CVDS。 ECG图像的公共数据集由来自五个不同类别的1937个图像组成,例如正常,Covid 19,心肌梗死MI,异常心跳AHB,并在本研究中使用了回收的心肌梗塞RMI。六种不同的深层CNN型号Reset18,Reset50,Resnet101,Inceptionv3,Densenet201和MobileNetv2用于调查三种不同的分类方案两类分类普通VS Covid 19三类分类正常,Covid 19等CVD,最后,五类分类正常,covid 19,mi,ahb和rmi。对于两类和三类分类,DenSenet201分别优于99.1和97.36的其他网络,同时为五类分类,Inceptionv3优于97.83的准确性。 Scorecam可视化确认网络正在从跟踪图像的相关区域学习。由于该方法使用智能手机可以捕获的ECG跟踪图像,并且在低资源国家的易用设施,这项研究将有助于更快的计算机辅助诊断Covid 19和其他心脏异常。 |
| Hybrid Deep Neural Network for Brachial Plexus Nerve Segmentation in Ultrasound Images Authors Juul P.A. van Boxtel, Vincent R.J. Vousten, Josien Pluim, Nastaran Mohammadian Rad 超声引导的区域麻醉UGRA可以取代全身麻醉GA,改善疼痛控制和恢复时间。这种方法可以在锁骨外科手术后施加在臂丛丛BP上。然而,即使对于训练有素的专业人员,也难以识别来自超声波的US图像是困难的。为了解决这个问题,卷积神经网络CNN和更先进的深神经网络DNN可用于识别和分割BP神经区域。在本文中,我们提出了一种由分类模型组成的混合模型,其次是分割模型,用于在超声图像中分段为BP神经区域。使用CNN模型作为分类器,以精确地选择具有BP区域的图像。然后,U Net或M净模型用于分段。我们的实验结果表明,所提出的混合模型显着提高了单个分段模型的分割性能。 |
| Markov Localisation using Heatmap Regression and Deep Convolutional Odometry Authors Oscar Mendez, Simon Hadfield, Richard Bowden 在自动驾驶车辆的背景下,基于视觉本地化和激光雷达的方法之间存在强烈竞争。虽然LIDAR提供了重要的深度信息,但它在分辨率和昂贵时稀疏。另一方面,摄像机是低成本,深度学习的最新发展意味着它们可以提供高地的本地化性能。然而,仍然存在若干基本问题,特别是在不确定性领域,基于学习的方法可以识别到信心。 |
| Learning Football Body-Orientation as a Matter of Classification Authors Adri Arbu s Sang esa, Adri n Mart n, Paulino Granero, Coloma Ballester, Gloria Haro 定位是足球运动员的一个至关重要的技能,成为一大集会中的差异因素,特别是涉及通过的事件。然而,基于计算机视觉技术的现有定向估计方法仍然有很多改进空间。据我们所知,本文介绍了直接从视频镜头估算方向的第一个深度学习模型。通过将该挑战作为分类问题接近,其中类对应于方向仓,并且通过引入循环损耗函数,优质众所周知的卷积网络以提供玩家取向数据。通过使用从可穿戴EPTS设备获得的地面真理定向数据训练,该模型是相对于当前帧中的感知方向单独地补偿。所获得的结果特别优于先前的方法,特别是绝对中值误差小于12度。包括消融研究,以便向任何类型的足球视频镜头展示潜在的概括。 |
| Analysis of classifiers robust to noisy labels Authors Alex D az, Damian Steele 我们探索了当代鲁棒分类算法,用于克服类依赖标签噪声,重要性重新加权和T修订。在最终测试数据清洁时,在类条件随机标签噪声数据上培训和评估分类器。我们演示了用于估计转换矩阵的方法,以便在使用嘈杂的数据时获得更好的分类器性能。我们将深度学习应用于三个数据集,并终止于从头开始的CIFAR数据上的未知噪声进行结束分析。分析分类器的有效性和稳健性,我们比较和对比每个实验的结果使用前1个精度作为我们的标准。 |
| 3D WaveUNet: 3D Wavelet Integrated Encoder-Decoder Network for Neuron Segmentation Authors Qiufu Li, Linlin Shen 3D神经元分割是神经元数字重建的关键步骤,这对于探索脑电路和理解大脑功能至关重要。然而,神经元的细型神经纤维可以在一个大区域中传播,这为3D神经元图像中的分割带来了很大的计算成本。同时,图像中的强烈噪音和断开的神经纤维为任务带来了巨大挑战。在本文中,我们提出了一种基于3D小波和深度学习的3D神经元分割方法。首先将神经元图像分成神经元多维数据集以简化分割任务。然后,我们设计3D WaveNet,第一三维小波集成编码器解码器网络,分段立方体中的神经光纤可以帮助深网络抑制数据噪声并连接破碎的光纤。我们还使用最大可用的被注释的神经元图像数据集,Bigneuron来生产神经元多维数据集数据集Neucuda,以培训3D WaveNet。最后,组装以立方体分段的神经纤维以产生完整的神经元,其使用可用的自动跟踪算法进行数字重建。实验结果表明,我们的神经元分段方法可以完全提取嘈杂的神经元图像中的靶神经元。集成的3D小波可以有效地提高3D神经元分割和重建的性能。这项工作的代码和预训练模型将可用 |
| ViTA: Visual-Linguistic Translation by Aligning Object Tags Authors Kshitij Gupta, Devansh Gautam, Radhika Mamidi 多式联机翻译MMT通过用于翻译的可视信息,丰富源文本。它近年来越来越受欢迎,并且已经在同一方向提出了几个管道。然而,任务缺乏优质数据集以说明在翻译系统中的视觉模型的贡献。在本文中,我们向Wat 2021的多式式翻译任务提出了从英语到印地语的系统。我们建议使用MBart,以序列模型进行预先训练的多语言序列,用于文本的唯一翻译。此外,我们通过从图像中提取对象标签并增强多模式任务的输入来将视觉信息带到文本域。我们还通过系统地降级源文本来探索我们系统的稳健性。最后,我们在测试集和挑战集中实现了44.6和51.6的Bleu得分。 |
| Volta at SemEval-2021 Task 6: Towards Detecting Persuasive Texts and Images using Textual and Multimodal Ensemble Authors Kshitij Gupta, Devansh Gautam, Radhika Mamidi MEMES是用于在线传播信息的最受欢迎的内容之一。他们可以通过修辞和心理技术影响大量的人。文本和图像中的劝说技术的任务是检测模因中的这些有说服力的技术。它由三个子任务组成了使用文本内容,B多标签分类和使用文本内容的多个标签分类和跨度标识的多标签分类,以及使用视觉和文本内容的C多标签分类。在本文中,我们提出了一种在不同方式的微调伯特的模型转移学习方法。我们还探讨了培训不同模式培训的模型的有效性。我们在相应的子任务中达到57.0,48.2和52.1的F1分数。 |
| GANs Can Play Lottery Tickets Too Authors Xuxi Chen, Zhenyu Zhang, Yongduo Sui, Tianlong Chen 深度生成的对抗网络GAN在许多场景中获得了日益的普及,而通常遭受资源受限的现实世界应用的高参数复杂性。但是,压缩GAN的压缩仍未探讨。一些作品表明,由于GAN的臭名昭着的培训不稳定,启发式应用压缩技术通常导致不令人满意的结果。同时,彩票假设显示歧视模型的普遍成功,在定位能够训练的稀疏匹配子网,以隔离到完全模型性能。在这项工作中,我们首次研究了在深局的培训匹配子网存在的存在。对于一系列的GAN,我们当然在67 74个稀疏性上找到匹配的子网。我们观察到,在没有修剪鉴别者或没有修剪的鉴别者对匹配子网的存在和质量有很小的影响,而判别者中使用的初始化权重发挥着重要作用。然后,我们展示了这些子网的强大可转换性来解除了未操作任务。此外,广泛的实验结果表明,我们发现的子网基本上倾向于以前的镜头生成中的前一种状态,例如图像生成。 SNGAN和图像图像翻译GANS e.g.加速。代码可用 |
| Clustering-friendly Representation Learning via Instance Discrimination and Feature Decorrelation Authors Yaling Tao, Kentaro Takagi, Kouta Nakata 聚类是机器学习中最基本的任务之一。最近,深度聚类已成为聚类技术的主要趋势。代表学习往往在深层聚类的有效性中发挥着重要作用,因此可以成为性能下降的主要原因。在本文中,我们提出了使用实例辨别和特征去相关的聚类友好表示学习方法。我们深入的基于学习的代表学习方法是通过经典光谱聚类的性质的动力。实例歧视在数据之间学习相似性,并且功能去相关性消除特征之间的冗余相关性。我们利用了一个实例辨别方法,其中学习各个实例类导致实例之间的学习相似性。通过详细的实验和检查,我们表明该方法可以适应学习聚类的潜在空间。我们设计小说SoftMax配制的学习结果约束。在使用CiFar 10和Imagenet 10的图像聚类评估中,我们的方法分别实现了81.5和95.4的精度。我们还表明Softmax配制的约束与各种神经网络兼容。 |
| Effect of large-scale pre-training on full and few-shot transfer learning for natural and medical images Authors Mehdi Cherti, Jenia Jitsev 转移学习旨在利用预训练的模型,以便在广泛的下游任务和数据集上进行更有效的跟进培训,并在小数据上实现成功的培训。最近的工作系列在模型规模,数据大小和计算预算增加时,对模型泛化和转移的强大益处增加了预训练。然而,它仍然很大程度上尚不清楚由于源头和目标数据分布彼此相距远远而导致的观察到的转移改善也持有。在这项工作中,我们对自然想象成21K 1K或医疗胸部X射线图像的大源数据集进行大规模预训练,并使用来自自然和医学成像域的不同目标数据集进行比较,并使用不同的目标数据集进行比较。我们的观察提供了证据表明,在密切相关的数据集上进行预培训和转移确实显示了在训练中增加了模型和数据大小的清晰益处,当源和目标数据集进一步分开时,这种益处不会清晰可见。这些观察结果跨越全部和少量射击传输,并表明扩展法律暗示泛化的泛化和转移随着模型和数据大小的增加而转移是不完整的,并且还应考虑到源和目标数据分布的不同程度,正确地预测转移训练中模型尺寸和数据尺寸变化的效果。再现实验的存储库将可用。 |
| 3D map creation using crowdsourced GNSS data Authors Terence Lines 1 , Ana Basiri 1 1 School of Geographical and Earth Sciences, University of Glasgow 3D地图对于许多诸如无人机导航,紧急服务和城市规划等许多应用越来越有用。但是,使用现有技术(如激光扫描仪)创建3D映射并保持最新映射。本文提出并实现了一种新的方法来生成2.5D,否则称为3D细节级别LOD 1映射,用于使用全局导航卫星系统GNSS信号,它们仅通过卫星和接收器之间的障碍阻止。这使我们能够找到GNSS信号可用性的模式并创建3D地图。本文将算法应用于基于引导绑定技术的GNSS信号强度模式,其在生成地图时迭代地训练信号分类器。所提出的技术的结果展示了使用自动处理的GNSS数据创建3D地图的能力。结果表明,第三维,即建筑物的高度,可以估计低于5米的精度,这是CityGML标准推荐的基准。 |
| Chinese Abs From Machine Translation |















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









