










AI视野·今日CS.CV 计算机视觉论文速览
Fri, 4 Jun 2021
Totally 60 papers
👉上期速览✈更多精彩请移步主页

Interesting:
**📚Anticipative Video Transformer , 预测视频后续帧的transformer模型(from facebook)


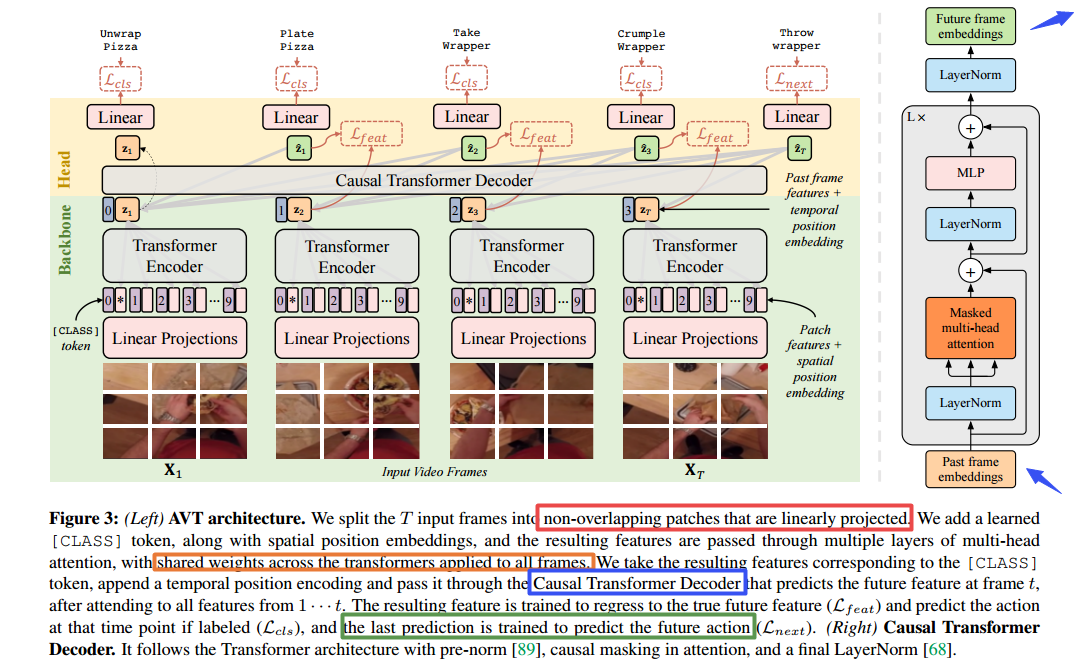
code: http://facebookresearch.github.io/AVT
*****📚DynamicViT, 基于动态transformer的高效视觉算法(from 清华 )

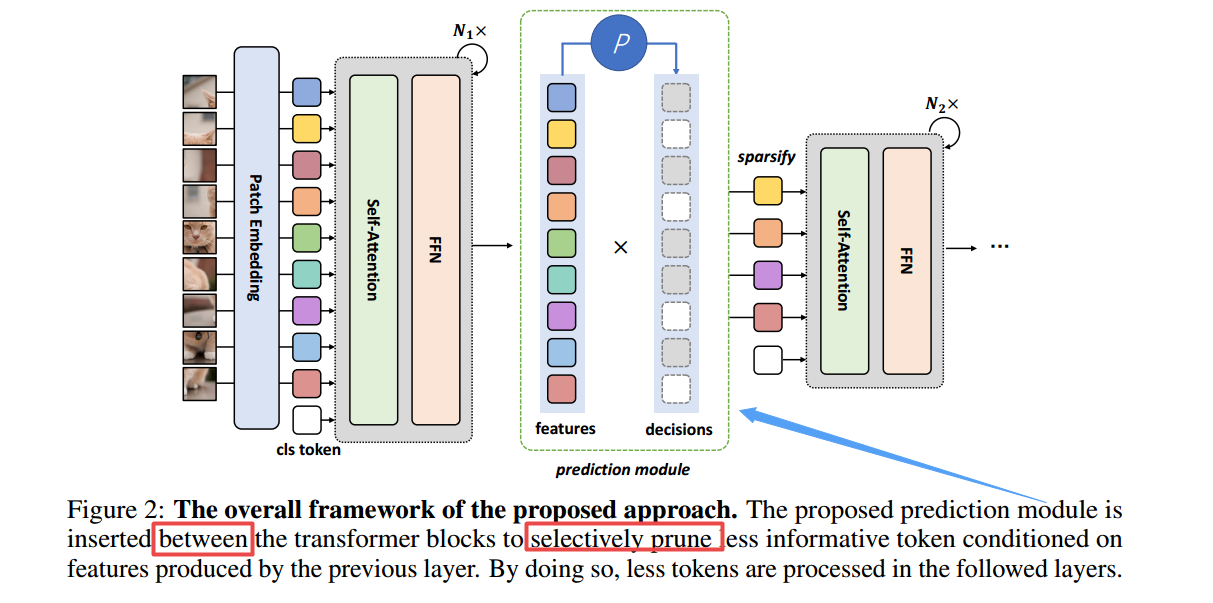
code:https://github.com/raoyongming/DynamicViT
📚DEEPCOMPRESS,高效点云几何压缩算法 (from 伍斯特理工 )

📚Container, 上下文聚合网络(from 港中文)

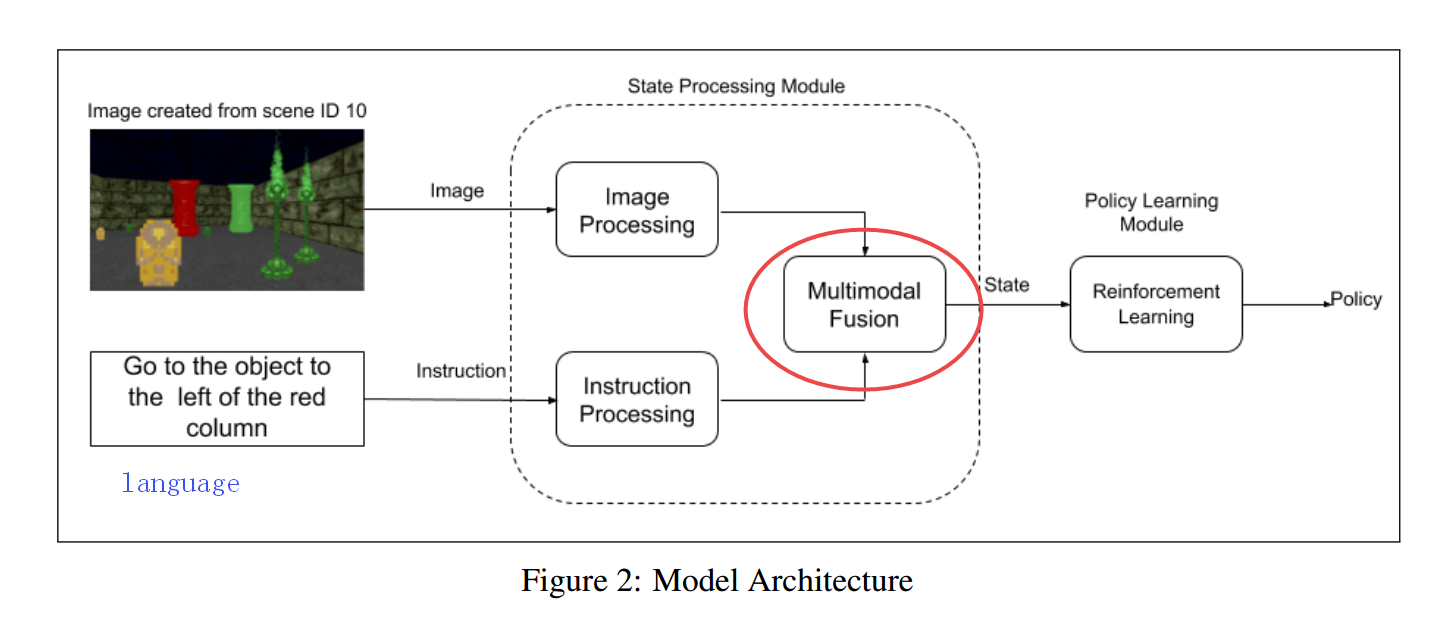
📚基于场景图结构的复杂导航指令, (from CMU)
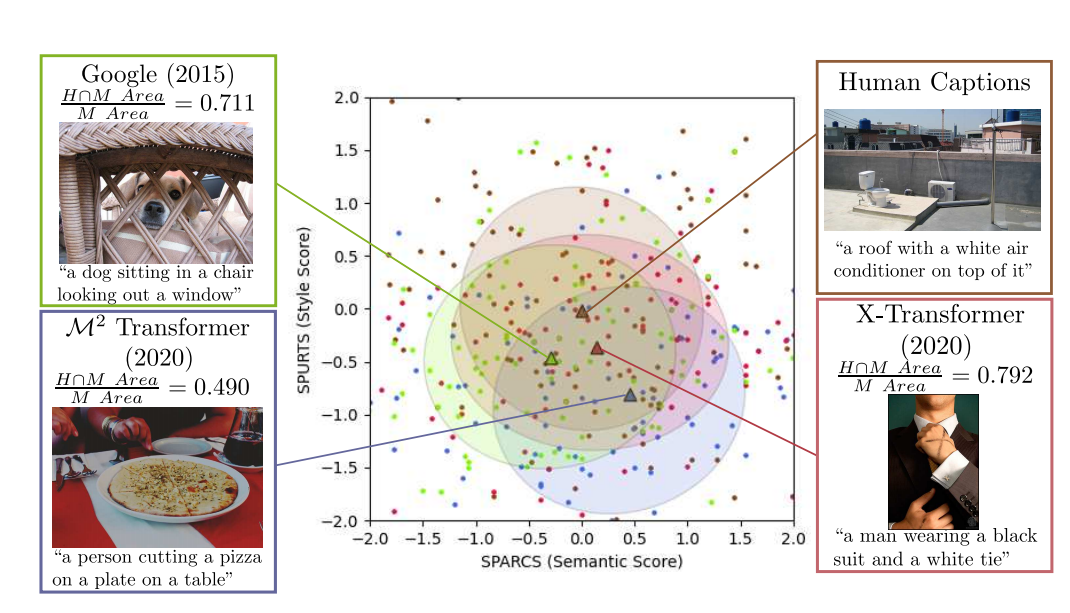
📚SMURF, 基于典型性分析的语义图像理解(from 亚利桑那大学)
Daily Computer Vision Papers
| Anticipative Video Transformer Authors Rohit Girdhar, Kristen Grauman 我们提出了预期的视频变换器AVT,结束了基于最终注意的视频建模架构,该架构参加先前观察到的视频,以预测未来的行动。我们共同培训模型来预测视频序列中的下一个动作,同时还可以学习框架特征编码器,其预测连续的未来帧特征。与现有的时间聚合策略相比,AVT具有维护观察到的行动的连续进展,同时仍然捕获对预期任务至关重要的长范围依赖性。通过广泛的实验,我们表明AVT在四个流行的行动预期基准测试中获得了最佳报告的性能,渗入沉积物55,EpicisCitchens 100,EGTEA凝视和50个沙拉,包括优于EpicisCitchens 100 CVPR 21攻击的所有提交。 |
| DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification Authors Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, Cho Jui Hsieh 关注在视觉变压器中稀疏。我们观察视觉变压器的最终预测仅基于大多数信息令牌的子集,这足以用于准确的图像识别。基于此观察,我们提出了一种动态的令牌稀疏框架,用于基于输入逐渐和动态地修剪冗余令牌。具体地,我们设计了轻量级预测模块来估计给定当前功能的每个令牌的重要性得分。该模块被添加到不同的图层中,以分层冗余令牌。为了结束预测模块以结束以结束方式,我们提出了一种注意掩蔽策略来通过阻止与其他令牌的相互作用来分化令牌。从自我注意的性质中受益,非结构化稀疏代币仍然是硬件友好,这使我们的框架易于实现实际加速。通过输入令牌的分层修剪66,我们的方法大大减少了31个37幅拖波,并通过40多个吞吐量,而各种视觉变压器的精度在0.5内。配备动态令牌稀疏框架,DynamicVIT模型可以实现非常竞争力的复杂性精度折衷,与ImageNet上的ART CNNS和视觉变压器的状态相比。代码可用 |
| Single Image Depth Estimation using Wavelet Decomposition Authors Micha l Ramamonjisoa, Michael Firman, Jamie Watson, Vincent Lepetit, Daniyar Turmukhambetov 我们提出了一种新的方法,用于预测具有高效率的单眼图像的精确深度。通过利用小波分解来实现这种最佳效率,该效率集成在完全可微分的编码器解码器架构中。我们证明我们可以通过预测稀疏小波系数来重建高保真深度映射。与以前的作品相比,我们表明可以在没有直接对系数的直接监督的情况下学习小波系数。相反,我们仅监督通过逆小波变换重建的最终深度图像。我们还表明,可以在完全自我监督的场景中学习小波系数,而无需访问地面真相深度。最后,我们将我们的方法应用于不同的艺术单眼估计模型的不同状态,在每种情况下给出类似或更好的结果与原始模型相比,同时需要不到一半的乘法增加在解码器网络中。代码 |
| Neural Actor: Neural Free-view Synthesis of Human Actors with Pose Control Authors Lingjie Liu, Marc Habermann, Viktor Rudnev, Kripasindhu Sarkar, Jiatao Gu, Christian Theobalt 我们提出了神经演员NA,从任意观点和任意可控姿势的高质量合成人类的新方法。我们的方法是基于最近的神经场景表示和渲染工作,从而从仅从2D图像学习几何形状和外观的表示。虽然现有的作品表现出令人兴奋的静态场景渲染和动态场景的播放,但具有神经隐式方法的人类的逼真重建和渲染,特别是在用户受控的小说姿势中,仍然很困难。为了解决这个问题,我们利用一个粗体模型作为将周围的3D空间留到典型姿势的代理。神经辐射场学习来自多视图视频输入的规范空间中的姿势依赖几何变形和姿势和观察依赖性外观效果。为了综合高保真动态几何和外观的新颖视图,我们利用身体模型上定义的2D纹理地图作为预测残余变形和动态外观的潜在变量。实验表明,我们的方法比播放的播放状态以及新的姿势合成,甚至可以概括到与训练造成的新姿势呈现很好。此外,我们的方法还支持合成结果的体形控制。 |
| ProtoRes: Proto-Residual Architecture for Deep Modeling of Human Pose Authors Boris N. Oreshkin, Florent Bocquelet, F lix H. Harvey, Bay Raitt, Dominic Laflamme 我们的工作侧重于开发人类姿势的学习神经表征,为先进的AI辅助动画工具。具体地,我们解决基于稀疏和可变用户输入构建完整静态人姿势的问题。身体关节子集的位置和或取向。为了解决这个问题,我们提出了一种新颖的神经结构,它将残余连接与局部指定的姿势的原型编码结合起来,以创建来自学习的潜在空间的新完全姿势。我们展示了我们的体系结构在准确性和计算效率方面,基于变压器的基线优于基线。此外,我们开发了一个用户界面,以将我们的神经模型集成在Unity中,是一个实时3D开发平台。此外,我们介绍了两个代表静态人类姿势建模问题的新数据集,基于高质量的人类运动捕获数据,该数据将与模型代码一起公开释放。 |
| NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination Authors Xiuming Zhang, Pratul P. Srinivasan, Boyang Deng, Paul Debevec, William T. Freeman, Jonathan T. Barron 我们解决了从由一个未知的照明条件照射的物体的构成的多视图图像中恢复物体的形状和空间变化反射率的问题。这使得能够在任意环境照明下呈现对象的新颖视图和对象S材料属性的编辑。我们呼叫神经辐射分解成形的方法的关键是蒸馏神经辐射场Nerf Mildenhall等人的体积几何形状。 2020将物体表示到表面表示,然后在求解空间变化的反射率和环境照明时共同细化几何形状。具体而言,Nerfactor恢复了表面法线,光可见性,反射率和双向反射率分布函数BRDF的3D神经领域,而没有任何监督,简单的平滑度前沿和数据驱动BRDF从真实世界的BRDF测量中获悉。通过显式建模光可视性,心脏请能够将来自Albedo的阴影分离,并在任意照明条件下合成现实的软或硬阴影。 Nerfactor能够恢复令人信服的3D模型,以便在这一具有挑战性和占据合成和真实场景的挑战和占用捕获设置中的免费视点。定性和定量实验表明,在各种任务中,内部表灶性优于基于经典和深度学习的艺术状态。我们的代码和数据可供选择 |
| A Comparison for Anti-noise Robustness of Deep Learning Classification Methods on a Tiny Object Image Dataset: from Convolutional Neural Network to Visual Transformer and Performer Authors Ao Chen, Chen Li, Haoyuan Chen, Hechen Yang, Peng Zhao, Weiming Hu, Wanli Liu, Shuojia Zou, Marcin Grzegorzek 图像分类取得了前所未有的进展,随着深度学习的快速发展。但是,微小物体图像的分类仍然没有很好地研究。在本文中,我们首先简要介绍深受深入学习的卷积神经网络和视觉变压器的发展,并引入了传统噪声和对抗性攻击的来源和发展。然后,我们使用各种型号的卷积神经网络和视觉变压器在微小物体精子和杂质的图像数据集上进行一系列实验,并比较实验结果中的各种评估度量,以获得具有稳定性能的模型。最后,我们讨论了微小物体分类中的问题,并为未来进行了微小物体的分类前景。 |
| You Never Cluster Alone Authors Yuming Shen, Ziyi Shen, Menghan Wang, Jie Qin, Philip H.S. Torr, Ling Shao 近期自我监督学习的进展,实例水平对比目标促进了无监督的聚类。然而,独立的数据库不是识别整体集群的上下文,并且可以进行副最优分配。在本文中,我们将主流对比学习范例扩展到群集级方案,其中经过相同群集的所有数据都有助于对每个数据组的上下文进行统一的表示。与此表示的对比学习然后奖励每个数据的分配。为了实现这一愿景,我们提出了双对比度聚类TCC。我们将一组分类变量定义为群集分配置信度,它将实例级别学习跟踪与群集级别联系起来。一方面,利用相应的分配变量是权重,沿数据点的加权聚合实现集群的集合表示。我们进一步提出了启发式集群增强等价物,以实现集群级对比度学习。另一方面,我们通过作业导出了实例级别对比目标的证据下限。通过重新处理分配变量,TCC训练结束到结束,不需要其他交替步骤。广泛的实验表明,TCC优于挑战基准的最新技术。 |
| Adversarially Adaptive Normalization for Single Domain Generalization Authors Xinjie Fan, Qifei Wang, Junjie Ke, Feng Yang, Boqing Gong, Mingyuan Zhou 单个域泛化旨在学习一个在许多看不见的域上表现良好的模型,只有一个域数据进行培训。现有的工作侧重于研究对抗域增强ADA,以提高模型的泛化能力。仍然存在对归一化层统计数据统计数据统计数据的影响。在本文中,我们提出了一种通用的归一化方法,自适应标准化和重新定义正常化ASR标准,以补充以前的作品中的缺失部分。 ASR Norm通过神经网络来学习标准化和重新统计统计数据。这种新的归一化形式可以被视为传统常规的通用形式。当用ADA培训时,学习ASR规范中的统计数据被评为来自来自不同域的数据,因此提高了域跨域的模型泛化性能,尤其是从源域具有大的差异的目标域。实验结果表明,ASR规范可以分别为1.6,2.7和6.3分别对最新的ADA方法带来一致的改进,平均分别对数字,CiFar 10c和PACS基准。作为通用工具,ASR规范引入的改进是可靠的,对ADA方法的选择是不可知的。 |
| Learning High-Precision Bounding Box for Rotated Object Detection via Kullback-Leibler Divergence Authors Xue Yang, Xiaojiang Yang, Jirui Yang, Qi Ming, Wentao Wang, Qi Tian, Junchi Yan 现有的旋转对象探测器主要继承自水平检测范式,因为后者已经进化到发达的区域。然而,由于当前回归损耗设计的限制,这些检测器难以高精度地检测,特别是对于具有大纵横比的物体。通过透视图,水平检测是旋转物体检测的特殊情况,本文在旋转与水平检测之间的关系方面,我们的动力将从感应范例改变到扣除方法的旋转回归损失。我们表明,一个基本挑战是如何调制旋转回归损耗中的耦合参数,因为这种估计参数可以在动态联合优化期间彼此影响,以自适应和协同方式。具体而言,我们首先将旋转边界框转换为2d高斯分布,然后计算高斯分布之间的Kullback Leibler发散KLD作为回归损耗。通过分析每个参数的梯度,我们显示KLD及其衍生物可以根据对象的特征动态调整参数梯度。它将根据宽高比调整角度参数的重要性梯度权重。对于高精度检测来说,这种机制可能是至关重要的,因为略有角度误差会导致大型纵横比物体的严重精度下降。更重要的是,我们证明了KLD是规模不变的。我们进一步表明,KLL损失可以退化为水平检测的流行L N常态损失。使用不同探测器的七个数据集的实验结果显示其一致的优势,并且代码可用 |
| Robust Reference-based Super-Resolution via C2-Matching Authors Yuming Jiang, Kelvin C.K. Chan, Xintao Wang, Chen Change Loy, Ziwei Liu 基于参考的超分辨率REF SR最近被揭示为有前途的范例来通过引入额外的高分辨率HR参考图像来增强低分辨率LR输入图像。现有的REF SR方法主要依赖于隐式对应匹配,以从参考图像借用HR纹理,以补偿输入图像中的信息丢失。然而,由于输入和参考图像之间的两个间隙,变换间隙例如,执行本地传输是困难的。尺度和旋转和分辨率差距。 HR和LR。为了解决这些挑战,我们提出了在这项工作中的C2匹配,这产生了明确的强大匹配交叉转换和分辨率。 1对于转换差距,我们提出了一种对比的对应网络,其使用输入图像的增强视图来学习变换强大的对应关系。 2对于解决方案缺口,我们采用教师学生相关蒸馏,从而从更容易的人力资源HR匹配中蒸馏出知识,以引导更加模糊的LR HR匹配。 3最后,我们设计一个动态聚合模块来解决潜在的错位问题。此外,为了忠实地评估REF SR在现实环境下的表现,我们贡献了扫视的SR WR SR数据集,模仿实际使用情况。广泛的实验表明,我们所提出的C2匹配在标准Cufed5基准上超过1dB的最高型技术。值得注意的是,它还在WR SR数据集中展示了极大的普遍性,以及大规模和旋转变换的鲁棒性。 |
| Self-Supervised Learning of Event-Based Optical Flow with Spiking Neural Networks Authors Federico Paredes Vall s, Jesse Hagenaars, Guido de Croon 神经形态传感和计算具有高度节能和高带宽传感器处理的承诺。神经形态计算的主要挑战是传统人工神经网络的学习算法由于离散的尖峰和更复杂的神经元动态而直接转移到尖峰神经网络SNNS。因此,SNNS尚未成功应用于复杂的大规模任务。在本文中,我们专注于从基于事件的相机输入的光流量估计的自我监督学习问题,并研究艺术ANN训练管道状态所需的变化,以便成功用SNN地解决它。更具体地说,我们首先修改输入事件表示,以编码具有最小明确的时间信息的更小的时间片。因此,我们使网络的网络的神经元动力学和反复连接,负责随时间集成信息。此外,我们为基于事件的光流量的重构自我监督损失功能,以提高其凸起。我们使用所提出的管道进行各种类型的经常性ANN和SNN进行实验。关于SNNS,我们研究了参数初始化和优化,替代梯度形状和自适应神经元机制等元素的影响。我们发现初始化和替代梯度宽度在使能稀疏输入启用学习时扮演至关重要的部分,而包含适应性和学习的神经元参数可以提高性能。我们表明,拟议的Anns和SNNS的表现与在自我监督的艺术培训的艺术ANNS的当前状态的表现相提并论。 |
| E2E-VLP: End-to-End Vision-Language Pre-training Enhanced by Visual Learning Authors Haiyang Xu, Ming Yan, Chenliang Li, Bin Bi, Songfang Huang, Wenming Xiao, Fei Huang Vision Language在大规模图像文本对上进行VLP对跨模型下游任务取得了巨大成功。最现有的预训练方法主要采用两步训练程序,首先采用预训练的对象检测器来提取基于区域的视觉特征,然后将图像表示和嵌入的图像表示和文本嵌入为培训的变压器的输入。然而,这些方法面临使用任务特定的特定对象检测器的特定视觉表示进行通用跨模型理解的问题,以及两个阶段管道的计算效率。在本文中,我们提出了第一端到最终视觉语言预训练模型,用于v l了解和生成,即E2E VLP,在那里我们构建一个统一的变压器框架,以共同学习视觉表示,并在图像和文本之间进行语义对齐。我们将物体检测和图像标题的任务纳入预训练中,通过统一的变压器编码器解码器架构来增强视觉学习。已经在熟悉的视觉语言下游任务上进行了广泛的实验,以证明这部小型VLP范例的有效性。 |
| Less is More: Sparse Sampling for Dense Reaction Predictions Authors Kezhou Lin, Xiaohan Wang, Zhedong Zheng, Linchao Zhu, Yi Yang 获取来自视频的观众响应对于创造者和流媒体平台有用,以分析视频性能并改善未来的用户体验。在本报告中,我们介绍了我们2021个诱发的询问表达的方法。特别是,我们的模型利用音频和图像方式作为输入来预测观众的情绪变化。为了模拟长距离情绪变化,我们使用GRU基于GRU的模型来预测1Hz的一个稀疏信号。我们观察到情绪变化是平滑的。因此,通过线性插值地获得最终密集预测,该信号是鲁棒到预测波动的信号。尽管如此,所提出的方法已经在最终私人测试集中实现了Pearson S相关得分为0.04430。 |
| Multi-Scale Feature Aggregation by Cross-Scale Pixel-to-Region Relation Operation for Semantic Segmentation Authors Yechao Bai, Ziyuan Huang, Lyuyu Shen, Hongliang Guo, Marcelo H. Ang Jr, Daniela Rus 利用多尺度特征在解决语义分割问题中表现出很大的潜力。聚合通常用SUM或串联求解后跟卷积的CONV层完成。但是,在不考虑他们的相互关系的情况下,它完全将高级上下文递减到以下层次结构。在这项工作中,我们的目标是使低级特征通过交叉量程像素到区域关系操作来实现低级特征来聚合来自相邻的高级特征映射的互补上下文。我们利用横梁上下文传播,使得即使通过高分辨率低级特征也能使长距离依赖性。为此,我们采用了一个有效的功能金字塔网络来获得多尺度功能。我们提出了一个关系语义提取器RSE和关系语义传播器RSP,分别用于上下文提取和传播。然后我们将几个RSP堆叠到RSP头中,以实现上下文的渐进式下降分布。实验结果在两个具有挑战性的数据集Citycapes和Coco表明RSP头在具有高效率的语义分割和Panoptic Seation上竞争地表现得很竞争。它优于deeplabv3 1,通过75次拖薄,在语义分割任务中增加了75个。 |
| GMAIR: Unsupervised Object Detection Based on Spatial Attention and Gaussian Mixture Authors Weijin Zhu, Yao Shen, Linfeng Yu, Lizeth Patricia Aguirre Sanchez 最近根据空间关注的无监督对象检测的研究取得了有希望的结果。型号,如空气和空间,输出分别代表场景中物体属性和位置的潜在变量和潜在的变量。最前面的研究专注于本地化性能的位置,我们声称获取对象属性对代表学习也是必不可少的。本文介绍了一个框架,Gmair,用于无监督的对象检测。它在统一的深度生成模型中包含空间注意和高斯混合物。 Gmair可以在场景中找到对象,并同时在没有监督的情况下纳入它们。此外,我们分析了潜在的变量和聚类过程。最后,我们评估了我们在多名单和Fruit2D数据集上的模型,并显示Gmair与本地化和集群相比实现竞争结果与现有方法的状态相比。 |
| Towards urban scenes understanding through polarization cues Authors Marc Blanchon, D sir Sidib , Olivier Morel, Ralph Seulin, Fabrice Meriaudeau 自治机器人受其现场了解算法的稳定性影响。我们提出了一个基于极化指标的两个轴管道来分析动态城市场景。随着机器人在未知环境中发展,它们易于遇到镜面障碍。通常,通过算法很少考虑镜面现象,导致误解和错误估计。通过利用所有灯属性,系统可以大大增加对事件的鲁棒性。除了传统的光度特性之外,我们提出包括偏振感。 |
| Cross-Domain First Person Audio-Visual Action Recognition through Relative Norm Alignment Authors Mirco Planamente, Chiara Plizzari, Emanuele Alberti, Barbara Caputo 由于可穿戴相机的普及度越来越受欢迎,第一人称行动识别是一项越来越多的研究。这带来了在这种背景下尚未解决的光跨域问题。实际上,从学习的陈述中提取的信息遭受了内在环境偏差。这会强烈影响概括到看不见方案的能力,限制了在训练期间不可用修剪的标记数据的实际设置中的当前方法的应用。在这项工作中,我们建议利用音频视觉信号的内在互补性质来学习适用于训练期间看到的数据的表示,同时能够拓展不同的域。为此,我们介绍了一种音频视觉损失,通过表现出它们的特征范围表示的幅度来对准两个模式的贡献。这种新的损失,插入了最小的多模态动作识别架构,导致跨领域第一人称动作识别的强劲结果,如广泛的史诗厨房数据集所证明的大量实验。 |
| APES: Audiovisual Person Search in Untrimmed Video Authors Juan Leon Alcazar, Long Mai, Federico Perazzi, Joon Young Lee, Pablo Arbelaez, Bernard Ghanem, Fabian Caba Heilbron 人类可以说是视频流中最重要的科目之一,许多真实世界的应用程序,例如视频摘要或视频编辑工作流程通常需要自动搜索和检索一个感兴趣的人。尽管在重新入学和检索域名巨大努力,但很少有效已经开发了视听搜索策略。在本文中,我们介绍了视听人员搜索数据集APE,这是一个由未经监测视频组成的新数据集,其音频声音和视觉面条流是密集的注释。 APE包含超过1.9k的标识,沿36小时的视频标记,使其成为未限制视听人员搜索的最大数据集。 APE的一个关键属性是它包括链接到相同身份的语音段的密集时间注释。为了展示我们新数据集的潜力,我们提出了一个人检索的视听基线和基准。我们的研究表明,建模的视听提示有利于承认人民身份。为了实现可重复性并促进未来的研究,可以提供数据集注释和基线代码 |
| Generalized Domain Adaptation Authors Yu Mitsuzumi, Go Irie, Daiki Ikami, Takashi Shibata 已经提出并单独解决了无监督域适应UDA问题的许多变体。其副作用是一种用于一种变体的方法通常是无效的,甚至可以适用于另一种方法,这阻止了实际应用。在本文中,我们给出了UDA问题的一般表示,名为Generalized域适应GDA。 GDA涵盖了主要变体作为特殊情况,这使我们能够在全面的框架中组织它们。此外,该概率导致新的具有挑战性的设置,其中现有方法失败,例如当域标签未知时,并且类标签仅部分给出每个域。我们提出了一种新的新环境的新方法。我们方法的关键是自我监督的阶级破坏性学习,它可以在不使用任何域标签的情况下学习类不变的表示和域对抗性分类器。使用三个基准数据集进行广泛的实验表明,我们的方法在新设置中优于现有的UDA方法的状态,并且它在现有的UDA变化中具有竞争力。 |
| Semantic Palette: Guiding Scene Generation with Class Proportions Authors Guillaume Le Moing, Tuan Hung Vu, Himalaya Jain, Patrick P rez, Matthieu Cord 尽管最近在综合照片现实图像时产生了生成的对抗性网络的进展,但生产复杂的城市场景仍然是一个具有挑战性的问题。以前的作品将场景分解为两个连续阶段无条件语义布局合成和图像合成在布局上调节。在这项工作中,我们提出了对更高的语义控制来调整课堂比例的向量的布局生成,我们用匹配组成产生布局。为此,我们介绍了一种有条件的框架,具有新颖的建筑设计和学习目标,有效地适应课堂比例以指导现场生成过程。所提出的架构还允许使用有趣的应用程序进行部分布局编辑。由于语义控制,我们可以生产靠近真正分配的布局,帮助增强整个场景生成过程。在不同的指标和城市场景基准测试中,我们的模型优于现有基准。此外,我们展示了我们对真实布局图像对培训的数据增强语义分段器的方法的优点,以及我们的方法产生的额外的绩效模型仅在真实对上培训。 |
| Transferable Adversarial Examples for Anchor Free Object Detection Authors Quanyu Liao, Xin Wang, Bin Kong, Siwei Lyu, Bin Zhu, Youbing Yin, Qi Song, Xi Wu 已经证明了深度神经网络易受对抗攻击细微扰动可以完全改变预测结果的影响。脆弱性导致在此方向上的研究激增,包括对象检测网络的对抗攻击。然而,之前的研究专用于攻击基于锚的对象探测器。在本文中,我们介绍了对锚自由对象探测器的第一个对抗攻击。它进行类别方向,而不是以前实例的,对象检测器攻击,并利用高电平语义信息来有效地产生可转移的对手示例,其也可以被传送到攻击其他物体检测器,甚至基于锚定的检测器,例如更快的检测器,例如更快的R CNN。两个基准数据集上的实验结果表明,我们所提出的方法实现了现有性能和可转移性的状态。 |
| Imperceptible Adversarial Examples for Fake Image Detection Authors Quanyu Liao, Yuezun Li, Xin Wang, Bin Kong, Bin Zhu, Siwei Lyu, Youbing Yin, Qi Song, Xi Wu 用DeepFake或Gans生成的高度现实假图像愚弄人为我们的社会带来了极大的社会障碍。已经提出了许多方法来检测假图像,但它们容易受到对抗的扰动故意设计的噪声,这可能导致错误预测。现有的攻击假图像探测器的方法通常会产生对扰动几乎整个图像的对抗扰动。这是冗余的,增加了扰动的可见度。在本文中,我们提出了一种通过将键像素确定到虚假图像检测器并仅攻击键像素来破坏假图像检测的新方法,从而导致逆势扰动的L 0和L 2规范远小于现有的作品。两个具有三个假图像探测器的两个公共数据集的实验表明我们所提出的方法在白色盒子和黑匣子攻击中实现了最先进的性能状态。 |
| CT-Net: Channel Tensorization Network for Video Classification Authors Kunchang Li, Xianhang Li, Yali Wang, Jun Wang, Yu Qiao 3D卷积对于视频分类来说是强大的,但往往是计算昂贵的,最近的研究主要集中在空间时间和或通道尺寸上分解它。不幸的是,大多数方法都无法在卷积效率与特征相互作用之间实现优选的平衡。因此,我们通过将输入特征的信道维度视为k子维度的乘法来提出简洁和新的信道张化网络CT网络。一方面,它自然地以多维尺寸方式分解卷积,从而导致光计算负担。另一方面,它可以有效地增强不同通道的特征相互作用,并且逐渐扩大这种相互作用的3D接收领域以提高分类精度。此外,我们用张量激励TE机制装备CT模块。它可以学习以高维方式利用空间,时间和渠道注意力,以改善CT模块中所有特征尺寸的协作功率。最后,我们灵活适应Reset作为CT网。在几个具有挑战性的视频基准测试中进行了广泛的实验,例如,动力学400,某种东西为V1和V2。我们的CT净在准确性和效率方面优于最近的许多SOTA方法。将提供代码和模型 |
| Attention-Guided Supervised Contrastive Learning for Semantic Segmentation Authors Ho Hin Lee, Yucheng Tang, Qi Yang, Xin Yu, Shunxing Bao, Bennett A. Landman, Yuankai Huo 对比学习在计算机视觉中嵌入全球和空间不变特征的卓越性能。,图像分类。然而,其嵌入本地和空间变体功能的整体成功仍然有限,特别是对于语义分割。在每个像素预测任务中,在单个图像中可以存在多于一个标签,用于分段,例如,图像包含猫,狗和草,从而难以在规范对比学学习设置中定义正或负对对。在本文中,我们提出了一种注意导致的监督对比学习方法,每次都是突出一个单个语义对象。通过我们的设计,可以将相同的图像嵌入到不同的语义集群,具有语义关注,即将语义掩模作为额外的输入通道。为实现这种关注,提出了一种新的两级训练策略。我们评估了多器官医学图像分割任务的提出方法,作为我们的主要任务,包括HUSE数据和BTCV 2015数据集。与Reset 50的骨干中的骨干中最新的训练状态相比,我们所提出的管道分别为医学图像分割队列的骰子分数分别产生5.53和6.09的实质性提高。通过Pascal VOC 2012 DataSet评估所提出的自然图像方法的性能,并实现了2.75实质性的改进。 |
| Spline Positional Encoding for Learning 3D Implicit Signed Distance Fields Authors Peng Shuai Wang, Yang Liu, Yu Qi Yang, Xin Tong 通过将3D坐标映射到相应的符号距离值或占用值,已经成功地成功地用于隐式和紧凑地地用来表示3D形状的Multilayer Perceptrons。在本文中,我们提出了一种新颖的位置编码方案,称为样条位位置编码,以将输入坐标映射到高尺寸空间,以便在将它们传递到MLP之前,帮助恢复具有来自未组织的3D点的微尺几何细节的3D符号距离场云。从输入点云和形状空间学习,我们验证了我们对其他位置编码方案的方法的优势。还证明和评估了我们对图像重建扩展到图像重建的方法的功效。 |
| When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations Authors Xiangning Chen, Cho Jui Hsieh, Boqing Gong 视觉变压器VITS和MLPS信号进一步努力替换具有通用神经架构的手有线功能或电感偏差。现有工作通过大规模数据授权模型,例如大规模预先训练和或重复强大的数据增强,仍然报告优化相关问题,例如,对初始化和学习率的敏感性。因此,本文研究了VITS和MLP混合器从损耗几何镜头,打算在推理时提高培训和泛化的模型数据效率。可视化和黑森州揭示了极锋利的融合模型的最小值。通过利用最近提出的锐利感知优化器促进平滑度,我们大大提高了VITS和MLP混合器对跨越监督,对抗,对比和转移学习的各种任务的准确性和稳健性,例如,5.3和11.0前1个对VIT B 16的Imagenet上的精度。和混频器B 16分别具有简单的初始风格预处理。我们表明,在前几层中改善了稀疏活性神经元的平滑度属性。在没有大规模预先预测或强大的数据增强的情况下从想象中的划痕训练时,所得到的更优于相似大小和吞吐量的更优于相似大小和吞吐量的吞吐量。他们还拥有更具看法的关注图。 |
| SSMD: Semi-Supervised Medical Image Detection with Adaptive Consistency and Heterogeneous Perturbation Authors Hong Yu Zhou, Chengdi Wang, Haofeng Li, Gang Wang, Shu Zhang, Weimin Li, Yizhou Yu 半监督分类和分割方法已被广泛研究医学图像分析。两种方法都可以提高完全监督方法的性能,具有额外的未标记数据。然而,作为一个基本任务,半监督物体检测在医学图像分析领域没有足够的关注。在本文中,我们提出了一种新型半监督医学图像探测器SSMD。 SSMD背后的动机是通过规范每个位置的预测来提供对未标记数据的免费但有效的监督。为了实现上述思想,我们开发了一种新颖的自适应一致性成本函数,以规范预测中的不同组件。此外,我们介绍了在特征空间和图像空间中工作的异构扰动策略,因此提出的探测器很有希望产生强大的图像表示和强大的预测。广泛的实验结果表明,所提出的SSMD在广泛的环境下实现了最先进的性能。我们还展示了各种建议模块的强度,具有全面的消融研究。 |
| Deconfounded Video Moment Retrieval with Causal Intervention Authors Xun Yang, Fuli Feng, Wei Ji, Meng Wang, Tat Seng Chua 我们解决视频时刻检索VMR的任务,旨在根据文本查询本地化视频中的特定时刻。现有方法主要通过复杂的跨模型交互来模拟查询和时刻之间的匹配关系。尽管有其有效性,但目前的模型主要忽略了数据集偏差,同时忽略了视频内容,从而导致相互不良的差。我们认为该问题是由VMR中隐藏的混淆引起的,即瞬间的时间位置,这使得模型输入和预测的效果相关。如何根据时间位置偏差设计强大的匹配模型是至关重要的,但据我们所知,尚未对VMR进行研究。 |
| Noise Doesn't Lie: Towards Universal Detection of Deep Inpainting Authors Ang Li, Qiuhong Ke, Xingjun Ma, Haiqin Weng, Zhiyuan Zong, Feng Xue, Rui Zhang 深度图像染色旨在恢复具有现实内容的图像中的损坏或丢失的区域。虽然具有广泛的应用,例如对象去除和图像恢复,但深入的染色技术也具有被操纵的风险用于图像伪造。对这种伪造者的承诺对策是深入的验证检测,旨在找到图像中的染子区域。在本文中,我们首次尝试普遍检测深度染色,其中检测网络在检测不同深度尿液方法时概括。为此,我们首先提出了一种新的数据生成方法来生成通用训练数据集,其模仿噪声差异与训练通用探测器的识别图像内容存在噪声差异。然后,我们设计噪声图像交叉融合网络NIX网络,以有效利用图像中包含的辨别信息及其噪声模式。我们在多个基准数据集上经验显示,我们的方法通过大的余量优于现有的检测方法,并概括不良,以不均匀地进行深入的避免技术。我们的通用训练数据集还可以显着提高现有检测方法的普遍性。 |
| Barbershop: GAN-based Image Compositing using Segmentation Masks Authors Peihao Zhu, Rameen Abdal, John Femiani, Peter Wonka 由于照明,几何形状和部分遮挡的复杂关系,从多个图像中无缝混合的功能非常具有挑战性,这导致图像的不同部分之间的耦合。尽管最近的GAN的工作能够合成逼真的头发或面,但将它们与单个,连贯性和合理的形象相结合,而不是脱节的图像补丁。我们提出了一种对图像混合的新解决方案,特别是对于发型转移问题,基于GaN反转。我们提出了一种用于图像混合的新型潜在空间,其更好地保留细节和编码空间信息,并提出了一种新的GaN嵌入算法,该算法能够略微修改图像以符合公共分割掩码。我们的新颖表示使得能够从包括诸如摩尔和皱纹的特定细节的多个参考图像传送视觉特性,并且因为我们在潜在的空间中进行图像混合我们能够合成相干的图像。我们的方法避免了在其他方法中存在的混合伪像,并找到全球一致的图像。我们的结果表明,在用户学习中对现有技术的最新状态有了重大改善,用户希望超过95%的混合解决方案。 |
| DeepCompress: Efficient Point Cloud Geometry Compression Authors Ryan Killea, Yun Li, Saeed Bastani, Paul McLachlan 点云是一种基本数据类型,越来越多地感兴趣,随着3D内容变得更加无处不在。使用点云的应用程序包括虚拟,增强和混合现实和自主驾驶。我们提出了一种更有效的基于深度学习的编码器架构,用于点云压缩,它包含来自已建立的3D对象检测和图像压缩架构的原理。通过烧蚀研究,我们表明,从计算有效的神经图像压缩敏感和设计更多参数高效卷积块的学习激活函数产生了效率和性能的显着增益。我们所提出的架构包括广义分区正常化激活,并提出空间可分离的IncepionV4启发块。然后,我们评估标准JPEG Pleno 8i Voxized全体数据集的速率失真曲线,以评估我们的模型的性能。我们所提出的修改优于Bjontegard Delta Rate和PSNR值的小幅度的基线方法,但速度将必要的编码器卷积操作减少了8%,并将总编码器参数减少了20%。我们拟议的拱门在倒角的距离中的距离下的402%的额度下降0.02%,比特率增加到同一峰值信号的平面距离。 |
| Personalizing Pre-trained Models Authors Mina Khan, P Srivatsa, Advait Rane, Shriram Chenniappa, Asadali Hazariwala, Pattie Maes 在大规模数据集上培训的自我监督或弱监督模型已经显示出在几次拍摄设置中的不同数据集的样本高效转移。我们考虑如何为下游射门,多责备和持续学习任务来利用上行佩尔覆盖的模型。我们的模型Clipper Clip个性化使用剪辑图像表示,使用弱自然语言监督训练的大规模图像表示学习模型。我们开发了一种称为多标签重量的技术,称为Mult Label MWI,用于多标签,持续的,很少的拍摄学习,而Clipper使用MWI与剪辑图像表示。我们在10个单个标签和5个多标签数据集中评估了Clipper。我们的模型显示了强大和竞争性的性能,我们为几次拍摄,多标签和持续学习设置了新的基准。我们的轻量级技术也是计算高效,并使得隐私保存应用程序作为数据不发送到上游模型以进行微调。 |
| Multiscale Domain Adaptive YOLO for Cross-Domain Object Detection Authors Mazin Hnewa, Hayder Radha 域适应领域已经有助于解决许多应用程序所遇到的域移位问题。由于用于训练的源数据分布与现实测试方案期间使用的目标数据相比,此问题出现了该问题。在本文中,我们介绍了一种新型多尺度域自适应yolo MS Dayolo框架,该框架在最近引入的yolov4对象检测器的不同尺度上采用多个域适配路径和相应的域分类器,以生成域不变的功能。我们使用流行数据集训练并测试我们提出的方法。我们的实验表现出使用所提出的MS DayoLo训练Yolov4的物体检测性能的显着改善,并且当考虑到代表自主驾驶应用的挑战天气条件的目标数据时。 |
| Domain Adaptation for Facial Expression Classifier via Domain Discrimination and Gradient Reversal Authors Kamil Akhmetov 一旦机器能够理解客户意图,可以显着提高人机通信的质量,将同理化能够显着提高人机通信的质量,并更好地满足他们的需求。根据不同的研究文献综述,视觉信息是人类交互最重要的通道之一,并且包含可能从面部表情捕获的重要行为信号。因此,由于具有多样化的应用领域,包括卫生保健,社会学,心理学,驾驶员安全,虚拟现实,认知科学,安全,娱乐,营销等。我们提出了一种新的架构,为FER的任务,并检查域歧视损失正规化对学习过程的影响。关于观察,包括经典培训条件和无监督的域适应情景,跟踪所考虑的域适应方法集成的重要方面。结果可以作为进一步研究该领域的基础。 |
| NTIRE 2021 Challenge on High Dynamic Range Imaging: Dataset, Methods and Results Authors Eduardo P rez Pellitero, Sibi Catley Chandar, Ale Leonardis, Radu Timofte 本文介绍了高动态范围HDR成像的第一个挑战,是与CVPR 2021一起举行的图像恢复和增强NTIRE研讨会的新趋势的一部分。该稿件专注于新引入的数据集,提出的方法及其结果。挑战旨在估计来自一个或多个相应的低动态范围LDR观察的HDR图像,这可能遭受暴露的区域或暴露的区域和不同的噪声来源。挑战由轨道1中的两个轨道组成,仅提供单个LDR图像作为输入,而在轨道2中,可以使用具有帧间运动的三种不同暴露的LDR图像。在这两种曲目中,最终目标是在PSNR方面实现最佳客观的HDR重建,即地面真相图像,直接和规范的调色剂操作评估。 |
| Unsharp Mask Guided Filtering Authors Zenglin Shi, Yunlu Chen, Efstratios Gavves, Pascal Mettes, Cees G.M. Snoek 本文的目标是引导图像滤波,这在通过附加指导图像中强调了在过滤期间的结构转移的重要性。在经典导向滤波器使用手动设计功能传输结构的情况下,通过深网络的参数学习,最近的引导滤波器已经大大提升。本领域的状态利用深网络来估计引导滤波器的两个核心系数。在这项工作中,我们同时估算两个系数的问题是次优,导致Halo伪影和结构不一致。灵感来自Unsharp掩蔽,一种用于边缘增强的经典技术,所述边缘增强仅需要单个系数,我们提出了一种新的和简化的引导滤波器的制定。我们的配方在低通滤波器之前享有过滤,并通过估计单个系数来实现显式结构传输。基于我们提出的制定,我们引入了一个连续的引导滤波网络,它提供了来自单个网络的多种过滤结果,允许在精度和效率之间进行折扣。广泛的消融,比较和分析表明我们的配方和网络的有效性和效率,从而导致最先进的滤除任务,如上采样,去噪和交叉模态滤波。 URL可提供代码 |
| Learning to Select: A Fully Attentive Approach for Novel Object Captioning Authors Marco Cagrandi, Marcella Cornia, Matteo Stefanini, Lorenzo Baraldi, Rita Cucchiara 在应用于标准数据集时,图像标题模型最近显示了令人印象深刻的结果。然而,切换到现实生活方案构成了由于现有培训集中未涵盖的各种视觉概念而导致的挑战。因此,新颖的对象标题NOC最近被出现为范例,以测试在训练阶段看不见的对象上的标题模型。在本文中,我们提出了一种新的NOC方法,了解要选择图像的最相关的对象,无论其遵守训练集,并相应地约束语言模型的生成过程。我们的架构完全关注并结束了最终培训,也在结合限制时。我们在举行的Coco DataSet上执行实验,在那里我们展示了对本领域技术的改进,无论是对新的对象和标题质量的适应性。 |
| Container: Context Aggregation Network Authors Peng Gao, Jiasen Lu, Hongsheng Li, Roozbeh Mottaghi, Aniruddha Kembhavi 卷积神经网络CNNS在计算机视觉中普遍存在,具有多种有效和有效的变化。最近,计算机愿景越来越多地采用了最初以自然语言处理引入的变压器。虽然早期采用者继续采用CNN骨架,但最新网络已结束以最终CNN免费变压器解决方案。最近的令人惊讶的发现表明,没有任何传统卷积或变压器组件的基于简单的MLP解决方案可以产生有效的视觉表现。虽然CNN,变压器和MLP混频器可以被认为是完全不同的架构,但是我们提供了一个统一的视图,表明它们实际上是一种更通用的方法来聚合神经网络堆栈中的空间上下文的特殊情况。我们介绍了模型上下文聚合网络,用于多头上下文聚合的通用构建块,可以利用长距离交互,从而仍然利用本地卷积操作的感应偏差,导致更快的收敛速度,经常在CNN中看到。与基于变压器的方法相比,不符合依赖于较大的输入图像分辨率的下游任务,我们的有效网络名为Modellight,可以用于对象检测和实例分段网络,例如Detr,RetinAnet和Mask RCNN以获得令人印象深刻的检测映射为38.9,43.8,45.1和41.3的掩模地图,与具有可比计算和参数大小的Reset 50骨架相比,分别提供了6.6,7.3,6.9和6.6分的大量改进。与DINO框架上的DEIT相比,我们的方法还达到了对自我监督学习的有希望的结果。 |
| Convolutional Neural Network(CNN/ConvNet) in Stock Price Movement Prediction Authors Kunal Bhardwaj 通过技术进步和数据的指数增长,我们一直在展开不同部门的神经网络的不同能力。在本文中,我试图在股票市场中使用称为卷积神经网络CNN ConvNet的特定类型的神经网络。换句话说,我试图在过去的股票价格上建造和培训卷积神经网络,然后试图预测股票价格的运动,即在未来时间股价将上升或跌倒。 |
| Pathology-Aware Generative Adversarial Networks for Medical Image Augmentation Authors Changhee Han 卷积神经网络CNNS在大规模注释数据集下可以在医学图像分析中发挥关键作用。但是,准备这种大规模数据集要求苛刻。在这种情况下,生成的对抗性网络GAN可以产生现实但新的样本,从而有效地覆盖真实的图像分布。在插值方面,基于GaN的医学图像增强是可靠的,因为医学模式可以在固定位置显示人体的强解剖一致性,同时清楚地反映了帧间的可变性,我们建议将噪声用于图像GAN,例如随机噪声样本我医疗数据增强DA和II医生培训的不同病理学图像。关于DA,GaN生成的图像可以改善基于监督学习的计算机辅助诊断。对于医生培训,虽然基础设施法律限制,但GAN可以展示新颖的病理学图像,并帮助培训医疗学员。本论文包含四个GAN项目,旨在呈现与医生合作的临床相关性。虽然这些方法更普遍适用,但本论文仅探讨了一些肿瘤学应用。 |
| Robotic Inspection and 3D GPR-based Reconstruction for Underground Utilities Authors Jinglun Feng, Liang Yang, Jiang Biao, Jizhong Xiao 地面穿透雷达GPR是一种有效的非破坏性评估NDE器件,用于检查和测量地下对象等,即复杂环境中的钢筋,公用事业管。然而,GPR数据收集的当前做法需要人类检查员沿着预先标记的网格线移动GPR车,并记录在x和y方向上的GPR数据,用于通过3D GPR成像软件发布处理。调查大面积是耗时和繁琐的工作。此外,识别地下目标取决于经验丰富的工程师的知识,他们必须制作限制GPR应用程序的手动和主观解释,尤其是在大规模场景中。此外,目前的GPR成像技术不直观,而不是普通用户理解,而不友好以可视化。为了解决上述挑战,本文提出了一种新颖的机器人系统,用于收集GPR数据,解释GPR数据,本地化地下实用程序,以用户友好的方式重建和可视化地下物体密集点云模型。该系统由三个模块1 A vision辅助全定向机器人数据收集平台组成,其使得GPR天线能够在使用基于视觉惯性的定位模块的同时使用任意轨迹自由地扫描目标区域,其标记GPR测量与定位信息2a深神经网络DNN迁移模块将原始GPR B扫描图像解释为对象模型3的横截面,基于DNN的基于DNN的3D重建方法,即GPRNET,以产生地下实用模型表示为FINE 3D点云。对具有各种不完整性和噪声的合成和现场GPR原料数据的比较研究。 |
| Denoising and Optical and SAR Image Classifications Based on Feature Extraction and Sparse Representation Authors Battula Balnarsaiah, G Rajitha 光学图像数据已被遥感劳动力用于学习土地使用和封面,因为此类数据很容易解释。合成孔径雷达SAR具有在整天获得图像的特征,所有天气和提供不同于可见和红外传感器的对象信息。但是,SAR图像具有更大的散斑噪声和更少的尺寸。本文提出了一种用于去噪,特征提取和比较光学和SAR图像的分类的方法。使用K个奇异值分解K SVD算法对图像进行去噪。通过提供给监督分类器的输入事实,使用支持向量机SVM来映射特殊目标签名的方法。最初,灰度直方图GLH和灰度CO发生矩阵GLCM用于特征提取。其次,使用相关性分析来组合来自第一步的提取特征向量以减小特征空间的维度。第三,SAR图像的分类是在稀疏表示分类SRC中完成的。开发了上述分类技术,并且性能参数是使用Matlab 2018A计算的准确性和κ系数。 |
| Simultaneous Multi-View Object Recognition and Grasping in Open-Ended Domains Authors Hamidreza Kasaei, Sha Luo, Remo Sasso, Mohammadreza Kasaei 在人类为中心的环境中工作的机器人需要知道场景中存在哪种物体,以及如何掌握和操纵不同情况下的各种对象,以帮助人类在日常任务中。因此,对象识别和抓握是此类机器人的两个关键功能。最先进的最先进地应对对象识别并掌握两个单独的问题,同时都使用可视输入。此外,在训练阶段之后,机器人的知识是固定的。在这种情况下,如果机器人面临新的对象类别,则必须从头开始重新培训,并在没有灾难性干扰的情况下结合新信息。为了解决这个问题,我们提出了一个深入的学习架构,增强了内存能力,以处理开放的目标识别和同时抓握。特别地,我们的方法将物体的多视图作为输入,并共同估计像素明智的掌握配置以及作为输出的深度和旋转不变表示。然后通过元主动学习技术使用所获得的表示用于开放的对象识别。我们展示了我们在对象之前从未见过的方法的能力,并在模拟和真实世界设置中使用非常少数的例子快速学习新的对象类别。 |
| Separated-Spectral-Distribution Estimation Based on Bayesian Inference with Single RGB Camera Authors Yuma Kinoshita, Hitoshi Kiya 在本文中,我们提出了一种用于单独估计由典型的RGB照相机捕获的图像的频谱分布的新方法。该方法允许我们分别估计照明,反射率或相机灵敏度的光谱分布,而最近的高光谱相机仅限于捕获来自场景的关节光谱分布。此外,使用贝叶斯推理使得可以考虑频谱分布和图像噪声的先前信息作为概率分布。结果,所提出的方法可以以统一的方式估计光谱分布,并且可以增强噪声估计的鲁棒性,传统的光谱分布估计方法不能。使用贝叶斯推论也使我们能够获得估计结果的置信度。在实验中,所提出的方法不仅可以在RMSE方面优于常规估计方法,而且还具有稳健的噪声。 |
| Noisy Labels are Treasure: Mean-Teacher-Assisted Confident Learning for Hepatic Vessel Segmentation Authors Zhe Xu, Donghuan Lu, Yixin Wang, Jie Luo, Jayender Jagadeesan, Kai Ma, Yefeng Zheng, Xiu Li 手动分割计算机断层扫描CT的肝血管比其他结构的专业知识更高,而不是由于血管的低对比度和复杂形态,导致极度缺乏高质量的标记数据。没有足够的高质量注释,通常的数据驱动的基于学习的方法与缺乏训练的斗争。另一方面,直接引入具有低质量注释的附加数据可能会使网络混淆,导致不良性能下降。为了解决这个问题,我们提出了一部小说均衡的自信学习框架,以强大地利用对挑战性肝血管分割任务的嘈杂标记数据。具体而言,利用第三方协助的适应自动学习,即重量平均教师模型,额外的低质量数据集中的噪声标签可以通过渐进像素明智的软校正从笼中转换为宝藏,从而提供生产力指导。使用两个公共数据集的广泛实验证明了所提出的框架的优越性以及每个组件的有效性。 |
| Deep Learning Based Analysis of Prostate Cancer from MP-MRI Authors Pedro C. Neto 前列腺癌的诊断面临过过度诊断的问题,导致由于不必要的治疗导致副作用破坏。研究表明,使用多参数磁共振图像来进行活检可以大大帮助减轻过度诊断,从而降低了对健康患者的副作用。本研究旨在调查深度学习技术的使用,探讨基于MRI作为输入的计算机辅助诊断。几种诊断问题范围从病变分类中,以临床显着或不检测和分割病变的检测和分割,并以深入的学习方法解决。 |
| Effort-free Automated Skeletal Abnormality Detection of Rat Fetuses on Whole-body Micro-CT Scans Authors Akihiro Fukuda, Changhee Han, Kazumi Hakamada 基于机器学习的快速和定量自动化筛选在分析计算机断层扫描CT扫描上的人体骨骼方面发挥着关键作用。然而,尽管有需要药物安全评估,但由于其费力的数据收集和注释,这种研究罕见的动物胎儿微型CT扫描。因此,我们提出了各种骨骼特征工程技术,以彻底自动化全身微型CT扫描对全身微型CT扫描对大鼠胎儿的骨骼定位标记异常检测。尽管49胎儿训练数据有限,但在骨骼标签和异常检测中,我们达到0.900和0.810的精度。 |
| Partial Graph Reasoning for Neural Network Regularization Authors Tiange Xiang, Chaoyi Zhang, Yang Song, Siqi Liu, Hongliang Yuan, Weidong Cai 常规方帮助深度神经网络防止特征CO适应。丢弃,作为常用的正则化技术,随机禁用网络优化期间的神经元AC传动系统。但是,这种完整的特征处理可以影响特征表示和网络理解。对于更好的潜在表示,我们展示了通过从骨干组件构建独立图形来学习正则化功能的删除。 Dropraph首次采样随机空间特征向量,然后包含图形推理方法以产生特征图失真。此添加图形在训练期间将网络正规化,并且可以在推理期间完全跳过。我们在图形推理和下列图之间的联动中提供了直接的联系,进一步讨论了部分图形推理方法如何降低特征相关性。为此,我们广泛地研究了GraphVertex依赖关系的建模和用于扭曲骨干姿势的图形的利用。 DropGraph在四个任务中验证了总共7个不同的数据集。实验结果表明,我们的方法在留下推理期间未改性的基础模型结构的同时优于最优异的现有状态。 |
| Advances in Classifying the Stages of Diabetic Retinopathy Using Convolutional Neural Networks in Low Memory Edge Devices Authors Aditya Jyoti Paul 糖尿病视网膜病变博士是一种严重的并发症,可能导致视网膜血管损伤,是视力障碍和失明的主要原因之一。博士广泛分为两种阶段不增殖的NPDR,除了几种微生物瘤外几乎没有症状,以及涉及大量微生物瘤和出血,柔软和硬渗出物,新血管化,黄斑缺血或这些血管缺血或这些组合的增殖PDR ,更容易检测到。更具体地,DR通常被分为五个层次,标记为0 4,从0表示没有最严重的DR至4。本文首先讨论了疾病的危险因素,然后调查最近的文献,然后检查发现某些技术,这些技术在提高预后准确性方面是高度有效的。最后,提出了一种卷积神经网络模型来检测低存储器边缘微控制器上的所有DR的阶段。该模型的尺寸仅为5.9 MB,精度和F1分数为94,推断速度为每秒约20帧。 |
| Fast improvement of TEM image with low-dose electrons by deep learning Authors Hiroyasu Katsuno, Yuki Kimura, Tomoya Yamazaki, Ichigaku Takigawa 低电子剂量观察对于使用透射电子显微镜观察各种样本是必不可少的,因此已经使用图像处理来改善透射电子显微镜TEM图像。为了应用此类图像处理以原位观察,我们在这里将卷积神经网络应用于TEM成像。使用包括短曝光图像和长曝光图像的数据集,我们开发用于处理后的短曝光图像的管道,基于端到端培训。每像素的总剂量获得的图像的图像的质量与每像素的总剂量约为1000 e获取的图像的图像相当。因为转换时间约为8ms,所以可以在125 FPS处于原位观察。该成像技术能够以电子束敏感标本的原位观察。 |
| Machine Learning Based Texture Analysis of Patella from X-Rays for Detecting Patellofemoral Osteoarthritis Authors Neslihan Bayramoglu, Miika T. Nieminen, Simo Saarakkala 目的是评估膝关节侧视图射线照片检测射线照相髌型骨关节炎PFOA的纹理特征的能力。我们使用了来自大多数公共使用数据集N 5507膝盖的侧视图膝盖X线片。使用地标检测工具BoneFinder自动检测到髌骨区域ROI。然后提取基于局记性模式LBP的手工制作特征,以描述髌骨纹理。首先,培训机器学习模型梯度升压机以检测来自LBP功能的射线照相PFOA。此外,我们使用端到端训练的深卷积神经网络CNNS直接放在纹理贴片上,用于检测PFOA。最终将拟议的分类模型与使用临床评估和参与者特征(如年龄,性别,体重指数BMI,WOMAC总成绩)和胫甲型Kellgren Lawrence KL等级的临床评估和参与者特征进行比较。 Atlas通过最公共使用数据集提供的专家阅读器的PFOA状态的视觉评估用作模型的分类结果。使用接收器操作特性曲线Roc AUC下的区域评估预测模型的性能,该面积在精密召回PR曲线平均精度AP,并在分层5折叠验证设置中的Brier得分.F 5507膝关节,953 17.3有PFOA。 AUC和AP用于最强的参考模型,包括年龄,性别,BMI,WOMAC评分和胫脂型KL级以预测PFOA分别为0.817和0.487。使用CNN的纹理ROI分类显着改善了预测性能ROC AUC 0.889,AP 0.714。我们提出了第一项研究,分析了髌骨骨质地以诊断PFOA。我们的结果展示了使用髌骨质地特征来预测PFOA的潜力。 |
| Improving the Transferability of Adversarial Examples with New Iteration Framework and Input Dropout Authors Pengfei Xie, Linyuan Wang, Ruoxi Qin, Kai Qiao, Shuhao Shi, Guoen Hu, Bin Yan 深度神经网络DNNS容易受到对抗例的攻击。黑匣子攻击是最威胁的攻击。目前,黑匣子攻击方法主要采用基于梯度的迭代攻击方法,通常限制迭代步长,迭代次数和最大扰动之间的关系。在本文中,我们提出了一种新的梯度迭代框架,其重新定义了上述三个之间的关系。在此框架下,我们很容易提高DI TI MIM的攻击成功率。此外,我们提出了一种基于输入辍学的渐变迭代攻击方法,可以与我们的框架合并。我们进一步提出了这种方法的多丢失率版本。实验结果表明,我们的最佳方法可以平均实现防御模型的96.2的攻击成功率,高于最先进的梯度攻击状态。 |
| Grounding Complex Navigational Instructions Using Scene Graphs Authors Michiel de Jong, Satyapriya Krishna, Anuva Agarwal 培训钢筋学习代理进行自然语言指示受到可用监督的限制,即知道指令的实施。我们调整Clevr视觉问题应答DataSet以生成复杂的自然语言导航指令和随附的场景图,产生了一个环境不可知的监督数据集。为了演示使用此数据集的使用,我们将场景映射到VizDoom环境,并使用Citet GateTittent中的体系结构培训代理商执行这些更复杂的语言指令。 |
| Exploring Memorization in Adversarial Training Authors Yinpeng Dong, Ke Xu, Xiao Yang, Tianyu Pang, Zhijie Deng, Hang Su, Jun Zhu 众所周知,深度学习模型也具有倾向于拟合整个训练集合的倾向,即使随机标签也需要记忆每个训练样本。在本文中,我们研究了对抗促进能力,收敛,泛化,特别是普遍培训的分类器的更深入了解的对抗训练中的记忆效应。我们首先表明深网络具有足够的能力来记住具有完全随机标签的培训数据的对抗性示例,但并非所有在算法都可以在极端情况下收敛。我们对随机标签的研究促进了对at的收敛性和泛化的进一步分析。我们发现某些方法遭受梯度不稳定问题,最近建议的复杂性措施无法通过考虑在随机标签上培训的模型来解释强大的泛化。此外,我们确定了记忆中的重大缺点,即它可能导致稳健的过度装备。然后,我们提出了一种通过详细记忆分析的新缓解算法。各种数据集的广泛实验验证了所提出的方法的有效性。 |
| PDPGD: Primal-Dual Proximal Gradient Descent Adversarial Attack Authors Alexander Matyasko, Lap Pui Chau 最神经网络的状态对小输入扰动敏感。自发现这种有趣的脆弱性以来,已经提出了许多防御方法,试图改善对抗对抗噪声的鲁棒性。需要快速准确的攻击来比较各种防御方法。然而,评估对抗性稳健性已被证明是非常具有挑战性的。现有的常态最小化对抗性攻击需要成千上万的迭代。 Carlini Wagner攻击,仅限于特定的规范。快速自适应边界,或产生次最优效果。布伦德尔遭遇攻击。另一方面,PGD攻击是快速,一般和准确的,忽略了规范最小化惩罚,并解决了更简单的扰动受限的问题。在这项工作中,我们介绍了一种快速,一般和准确的对抗攻击,优化原始非凸的最小化问题。我们解释优化对抗攻击优化问题的Lagrangian作为两个玩家游戏,第一个玩家最小化Lagrangian WRT对抗对抗噪声第二玩家最大化Lagrangian WRT的正则化罚款。我们的攻击算法同时优化了原始和双变量,以找到最小的对抗扰动。另外,对于非平滑的L P常态最小化,例如L infty,L 1和L 0规范,我们介绍了原始双近梯度下降攻击。我们在实验中展示了我们的攻击优于现有技术的最新状态L介入,L 2,L 1和L 0对MNIST,CIFAR 10和限制的想象形数据集进行攻击,防止对抗未说明的和过内培训的模型。 |
| Not All Knowledge Is Created Equal Authors Ziyun Li, Xinshao Wang, Haojin Yang, Di Hu, Neil M. Robertson, David A. Clifton, Christoph Meinel 相互知识蒸馏MKD通过从另一种模型中蒸馏知识来改善模型。但是,并非所有知识都肯定和纠正,特别是在不利条件下。例如,由于不希望的记忆1,2,标签噪声通常导致更可靠的模型。错误的知识误导了学习而不是帮助。这个问题可以通过两个方面来处理我提高知识来自I.的模型的可靠性I.,知识源S可靠性II选择可靠的蒸馏知识。在文献中,在选择性MKD接收到很少的关注时,将更可靠地进行更可靠的模型。因此,我们专注于学习选择性MKD并突出其在这项工作中的重要性。 |
| LLC: Accurate, Multi-purpose Learnt Low-dimensional Binary Codes Authors Aditya Kusupati, Matthew Wallingford, Vivek Ramanujan, Raghav Somani, Jae Sung Park, Krishna Pillutla, Prateek Jain, Sham Kakade, Ali Farhadi 学习实例和类的二进制表示是具有几个高潜在应用的经典问题。在现代设置中,对低维二进制代码的高维神经表示的压缩是一个具有挑战性的任务,并且通常需要大的比特码来准确。在这项工作中,我们提出了一种用于学习低维二进制代码LLC的新方法,用于实例以及类。我们的方法不需要任何侧面信息,例如注释属性或标签元数据,并学习Imagenet 1K的极低尺寸二进制代码20位。学习的代码是超级有效的,同时仍然可以确保Imagenet 1K上的Reset50的近似最佳的分类精度。我们证明,学习的代码通过在课堂上发现直观的分类来捕获数据中的本质上重要特征。我们通过将其应用于高效图像检索以及出于分配的检测问题,我们进一步定量测量了我们的代码的质量。对于Imagenet 100检索问题,我们所学的二进制代码胜过16位Hashnet,仅使用10位,也可以准确为10维实际表示。最后,我们的学习二进制代码可以以框中的检测,尽可能准确地作为需要3000个样本来调整其阈值的基线,而我们要求无需。可以使用代码和预训练型号 |
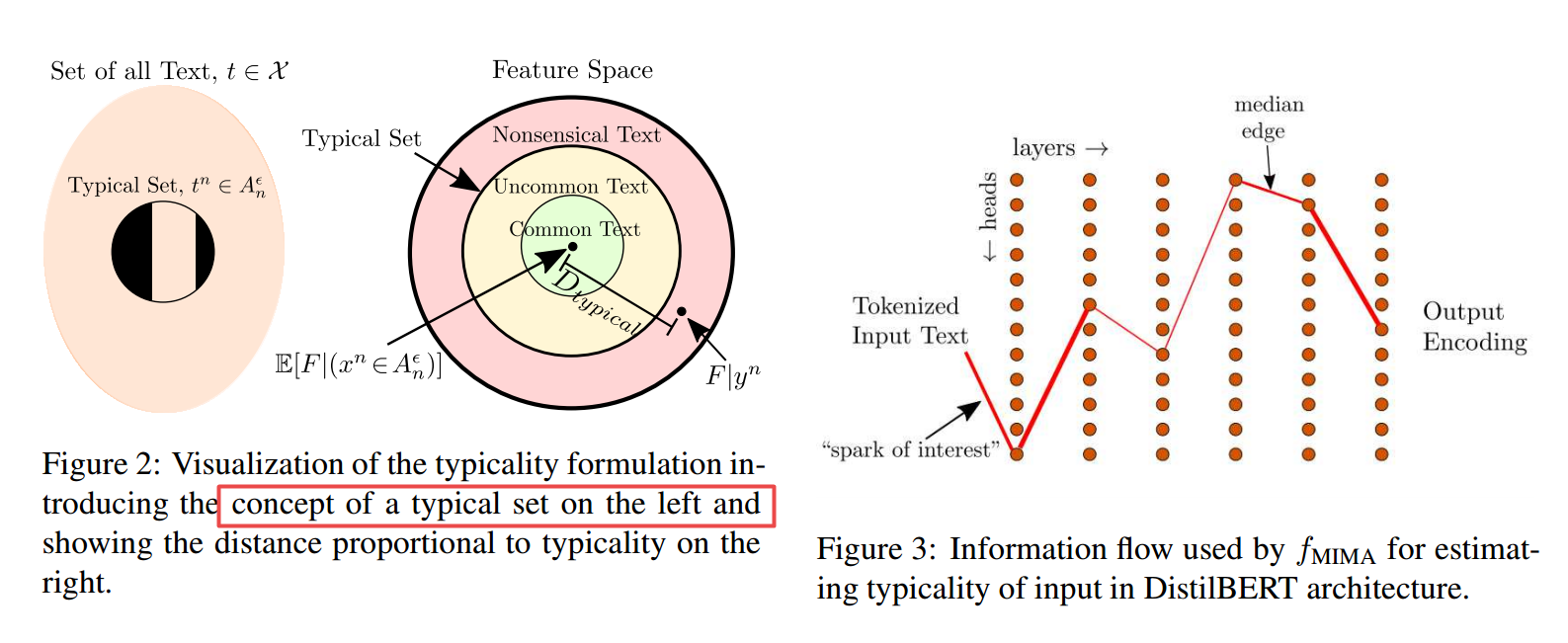
| SMURF: SeMantic and linguistic UndeRstanding Fusion for Caption Evaluation via Typicality Analysis Authors Joshua Feinglass, Yezhou Yang 视觉标题的开放性质使其成为评估的具有挑战性的区域。大多数拟议模型依赖于专业培训来改善人类关联,导致采用有限,普遍性和解释。我们介绍了典型的评价制定,源于信息理论,这非常适合缺乏明确的实践的问题。典型性是我们的框架,以开发一种新颖的语义比较,SPARC,以及可转让的流畅评估度量。在我们的分析过程中,由公制刺激和语法捕获的两种单独的流利程度自然出现的风格,以语法异常罚款的形式捕获。通过对基准数据集的广泛实验和消融研究,我们展示了这些语义和流畅程度的这些分解维度如何为标题器差异提供更大的系统级别。我们拟议的指标与他们的组合,SMURF,与基于其他规则的评估指标相比,与人为判断的最新关系。 |
| One Representation to Rule Them All: Identifying Out-of-Support Examples in Few-shot Learning with Generic Representations Authors Henry Kvinge, Scott Howland, Nico Courts, Lauren A. Phillips, John Buckheit, Zachary New, Elliott Skomski, Jung H. Lee, Sandeep Tiwari, Jessica Hibler, Courtney D. Corley, Nathan O. Hodas 在开发在小型数据制度中运行的强大模型,少数拍摄学习领域取得了显着的进步。几乎所有这些方法都假设遇到的每个未标记的实例都属于一个有少数已知类,其中一个有一个例子。这对于现实世界使用案例可能是有问题的,其中一个定期发现上述示例都不找到。在本文中,我们描述了识别我们术语超出支持OOS示例的挑战。我们介绍了如何与分发检测进行微妙地不同的问题,并使用我们称之为通用表示的固定点来描述识别原型网络框架内的OOS示例的新方法。我们表明我们的方法优于文献中的其他现有方法以及我们在本文中提出的其他方法。最后,我们调查这种通用点的使用如何影响模型S特征空间的几何形状。 |
| Chinese Abs From Machine Translation |















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









