










AI视野·今日CS.CV 计算机视觉论文速览
Wed, 3 Nov 2021
Totally 48 papers
👉上期速览✈更多精彩请移步主页

Interesting:
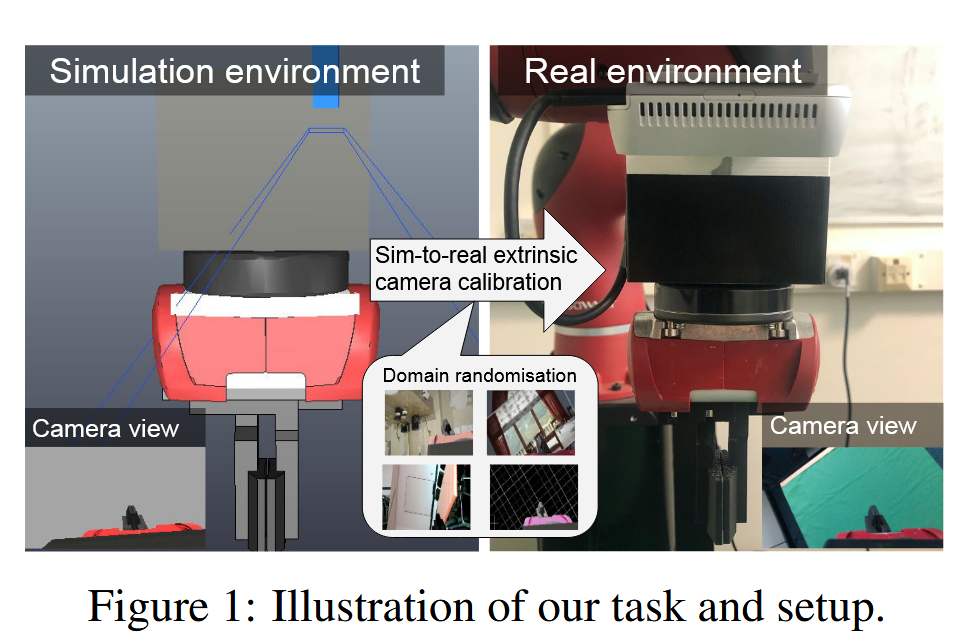
📚基于单图的手眼标定预测, (from 帝国理工机器人实验室)
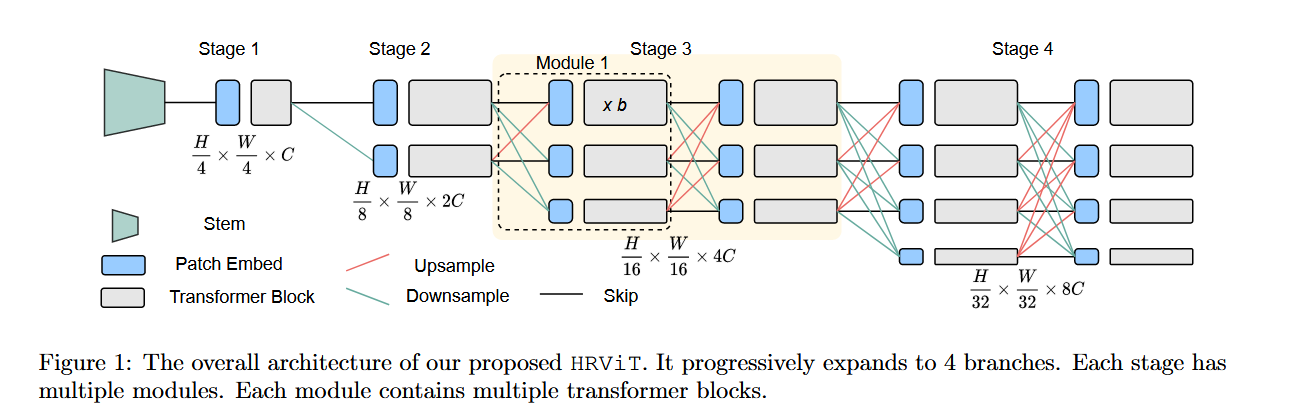
📚多尺度高分辨率Transformer, (from Facebook 德州大学奥斯丁分校)
📚CAN VISION TRANSFORMERS PERFORM CONVOLUTION?, ViT层与卷积层的互换—>多头注意力机制相对位置编码提供了核心作用!给出了ViT要实现CNNs的理论下界;(from 北大、UCLA、微软)
📚基于最小能量耗散模型的腿式机器人步态研究,在不同运动速度下的步态 (from CMU 伯克利)

code:https://energy-locomotion.github.io/
📚LogAvgExp新型池化操作, (from Dalhousie University Halifax, Nova Scotia;Vector Institute for Artificial Intelligence, Canada)
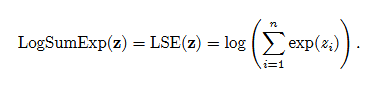
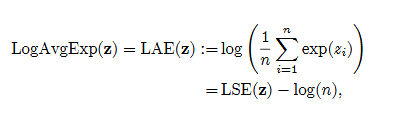

Daily Computer Vision Papers
| PatchGame: Learning to Signal Mid-level Patches in Referential Games Authors Kamal Gupta, Gowthami Somepalli, Anubhav Gupta, Vinoj Jayasundara, Matthias Zwicker, Abhinav Shrivastava 我们研究了一种参考游戏,一种信号游戏,其中两个代理通过离散瓶颈相互通信以实现共同目标。在我们的参考游戏中,说话者的目标是撰写信息或重要图像块的符号表示,而听者的任务是将说话者的信息与同一图像的不同视图相匹配。我们表明,这两个代理确实可以在没有显式或隐式监督的情况下开发通信协议。我们进一步研究了开发的协议,并展示了通过仅使用重要补丁来加速最近的 Vision Transformers 的应用,以及作为下游识别任务(例如分类)的预训练。 |
| Personalized One-Shot Lipreading for an ALS Patient Authors Bipasha Sen, Aditya Agarwal, Rudrabha Mukhopadhyay, Vinay Namboodiri, C V Jawahar 从说话者的嘴巴运动中读唇或从视觉上识别语音是一项具有挑战性和精神负担的任务。不幸的是,多种医疗状况迫使人们在日常生活中依赖这种技能进行必要的交流。患有肌萎缩侧索硬化症 ALS 的患者通常会失去对肌肉的控制,因此他们能够通过嘴唇运动来说话和交流。现有的大型数据集不关注医疗患者或策划与个人相关的个性化词汇。然而,收集患者的大规模数据集以训练现代数据饥渴的深度学习模型是极具挑战性的。在这项工作中,我们提出了一个个性化的网络,仅使用一个镜头示例对 ALS 患者进行唇读。我们依靠合成生成的嘴唇运动来增强一次性场景。基于变分编码器的域自适应技术用于弥合真实的合成域差距。我们的方法显着提高并实现了最高的 5accuracy,准确度为 83.2,相比之下,患者的可比方法达到的 62.6。 |
| CPSeg: Cluster-free Panoptic Segmentation of 3D LiDAR Point Clouds Authors Enxu Li, Ryan Razani, Yixuan Xu, Bingbing Liu 快速准确的 LiDAR 点云全景分割系统对于自动驾驶车辆了解周围物体和场景至关重要。现有方法通常依靠提议或聚类来分割前景实例。因此,他们很难实现实时性能。在本文中,我们为 LiDAR 点云提出了一种新颖的实时端到端全景分割网络,称为 CPSeg。特别地,CPSeg 包括一个共享编码器、一个双解码器、一个任务感知注意力模块 TAM 和一个无簇实例分割头。 TAM 旨在强制这两个解码器学习语义和实例嵌入的丰富任务感知特征。此外,CPSeg 结合了一个新的无集群实例分割头,根据学习到的嵌入动态地柱化前景点。然后,它通过成对嵌入比较找到连接的柱子来获取实例标签。因此,传统的基于提议或基于聚类的实例分割被转换为成对嵌入比较矩阵上的二元分割问题。为了帮助网络回归实例嵌入,提出了一种快速且确定性的深度补全算法来实时计算每个点云的表面法线。所提出的方法在两个大规模自动驾驶数据集上进行了基准测试,即 SemanticKITTI 和 nuScenes。 |
| MixFace: Improving Face Verification Focusing on Fine-grained Conditions Authors Junuk Jung, Sungbin Son, Joochan Park, Yongjun Park, Seonhoon Lee, Heung Seon Oh 由于 CNN 的快速发展,人脸识别的性能对于 LFW、CFP FP 和 AgeDB 等公共基准数据集已经饱和。然而,由于缺乏此类数据集,尚未研究具有各种细粒度条件的人脸对 FR 模型的影响。本文使用 K FACE 分析了它们在不同条件和损失函数方面的影响,K FACE 是最近引入的具有细粒度条件的 FR 数据集。我们提出了一种新的损失函数 MixFace,它结合了分类和度量损失。 |
| Absolute distance prediction based on deep learning object detection and monocular depth estimation models Authors Armin Masoumian, David G. F. Marei, Saddam Abdulwahab, Julian Cristiano, Domenec Puig, Hatem A. Rashwan 通过使用立体相机或 3D 相机估计深度图像,可以从 2D 图像确定场景中的物体与相机传感器之间的距离。深度估计的结果是相对距离,可用于计算实际适用的绝对距离。然而,使用 2D 单目相机进行距离估计非常具有挑战性。本文提出了一个深度学习框架,该框架由两个深度网络组成,用于使用单个图像进行深度估计和目标检测。首先,使用 You Only Look Once YOLOv5 网络检测和定位场景中的对象。同时,使用深度自动编码器网络计算估计的深度图像以检测相对距离。提出的基于目标检测的 YOLO 使用监督学习技术进行训练,而深度估计网络则是自监督训练。所提出的距离估计框架在室外场景的真实图像上进行了评估。 |
| Rethinking the Knowledge Distillation From the Perspective of Model Calibration Authors Lehan Yang, Jincen Song 近年来,知识蒸馏得到了显着改善,可以生成紧凑的学生模型以提高效率,同时保留教师模型的模型有效性。以往的研究发现,由于能力不匹配,更准确的教师不一定会成为更好的教师。在本文中,我们旨在从模型校准的角度分析这种现象。我们发现较大的教师模型可能过于自信,因此学生模型无法有效模仿。 |
| Using Synthetic Images To Uncover Population Biases In Facial Landmarks Detection Authors Ran Shadmi, Jonathan Laserson, Gil Elbaz 为了分析经过训练的模型性能并识别其弱点,必须留出一部分数据进行测试。测试集必须足够大,以检测目标人群中所有相关子组的统计显着偏差。这一要求可能难以满足,尤其是在数据饥渴的应用程序中。我们建议通过生成合成测试集来克服这个困难。我们使用人脸地标检测任务来验证我们的提议,方法是显示在真实数据集上观察到的所有偏差也可以在精心设计的合成数据集上看到。 |
| Saliency detection with moving camera via background model completion Authors Yupei Zhang, Kwok Leung Chan 检测视频中的显着性是许多计算机视觉系统中的一个基本步骤。显着性是视频中的重要目标。感兴趣的对象被进一步分析用于高级应用程序。如果显着性和背景表现出不同的视觉线索,则可以进行显着性和背景的分离。因此,显着性检测通常被表述为背景减法。然而,显着性检测具有挑战性。例如,动态背景会导致误报。在另一种情况下,伪装会导致假阴性错误。使用移动相机,捕捉到的场景处理起来更加复杂。我们提出了一个新框架,称为通过背景模型完成 SD BMC 的显着性检测,它由背景建模器和深度学习背景前景分割网络组成。背景建模器从短图像序列生成初始干净的背景图像。基于视频补全的思想,在变化的背景和运动的物体并存的情况下,可以合成一个好的背景帧。我们采用了背景前景分割器,虽然用特定的视频数据集进行了预训练,但也可以检测看不见的视频中的显着性。当背景前景分割器在处理长视频过程中输出恶化时,背景建模器可以动态调整背景图像。据我们所知,我们的框架是第一个采用视频补全对移动相机捕获的视频进行背景建模和显着性检测的框架。从 PTZ 视频中获得的结果表明,我们提出的框架优于一些基于深度学习的背景减法模型 11 或更多。 |
| Top1 Solution of QQ Browser 2021 Ai Algorithm Competition Track 1 : Multimodal Video Similarity Authors Zhuoran Ma, Majing Lou, Xuan Ouyang 在本文中,我们描述了 QQ 浏览器 2021 人工智能算法大赛 AIAC Track 1 的解决方案。我们使用多模态变换器模型进行视频嵌入提取。在预训练阶段,我们用三个任务训练模型,1 个视频标签分类 VTC,2 个掩码语言建模 MLM 和 3 个掩码帧建模 MFM。在微调阶段,我们基于等级归一化的人类标签训练具有视频相似性的模型。我们的完整管道在集成了多个模型后,在排行榜上的得分为 0.852,我们在比赛中获得了第一名。 |
| Relational Self-Attention: What's Missing in Attention for Video Understanding Authors Manjin Kim, Heeseung Kwon, Chunyu Wang, Suha Kwak, Minsu Cho 卷积可以说是现代神经网络最重要的特征转换,导致了深度学习的进步。最近出现的 Transformer 网络,用自注意力块代替卷积层,揭示了静止卷积核的局限性,打开了动态特征变换时代的大门。然而,现有的动态变换,包括自我注意,都受限于视频理解,其中空间和时间的对应关系,即运动信息,对于有效表示至关重要。在这项工作中,我们引入了一种关系特征转换,称为关系自我注意 RSA,它通过动态生成关系内核和聚合关系上下文来利用视频中丰富的时空关系结构。 |
| Human Attention in Fine-grained Classification Authors Yao Rong, Wenjia Xu, Zeynep Akata, Enkelejda Kasneci 人类处理、处理和分类给定图像的方式有可能极大地提高深度学习模型的性能。当模型偏离正确决策的基本特征时,利用人类关注的地方可以纠正模型。为了验证人类注意力是否包含用于决策过程(例如细粒度分类)的有价值信息,我们在发现重要特征时比较了人类注意力和模型解释。为了这个目标,我们为细粒度分类数据集 CUB 收集人类注视数据,并构建了一个名为 CUB GHA Gaze based Human Attention 的数据集。此外,我们提出了凝视增强训练 GAT 和知识融合网络 KFN,将人类凝视知识整合到分类模型中。我们在 CUB GHA 和最近发布的胸部 X 射线图像医学数据集 CXR Eye 中实施了我们的建议,其中包括从放射科医生那里收集的凝视数据。我们的结果表明,整合人类注意力知识有利于有效分类,例如在 CXR 上将基线提高了 4.38。因此,我们的工作不仅为在细粒度分类中理解人类注意力提供了宝贵的见解,而且有助于未来将人类凝视与计算机视觉任务相结合的研究。 |
| A Tri-attention Fusion Guided Multi-modal Segmentation Network Authors Tongxue Zhou, Su Ruan, Pierre Vera, St phane Canu 在多模态分割领域,可以考虑不同模态之间的相关性来改善分割结果。考虑到不同 MR 模态之间的相关性,在本文中,我们提出了一种由新型三注意力融合引导的多模态分割网络。我们的网络包括具有 N 个图像源的 N 个模型独立编码路径、一个三注意力融合块、一个双注意力融合块和一个解码路径。独立于模型的编码路径可以从 N 个模态中捕获模态特定的特征。考虑到并非所有从编码器中提取的特征都对分割有用,我们建议使用基于双重注意的融合来重新加权沿着模态和空间路径的特征,这可以抑制信息量较少的特征并强调每个模态的有用特征不同的职位。由于不同模态之间存在很强的相关性,基于双重注意力融合块,我们提出了一个相关性注意力模块来形成三注意力融合块。在相关注意模块中,首先使用相关描述块来学习模态之间的相关性,然后使用基于相关性的约束来引导网络学习与分割更相关的潜在相关特征。最后,得到的融合特征表示被解码器投影得到分割结果。 |
| StyleGAN of All Trades: Image Manipulation with Only Pretrained StyleGAN Authors Min Jin Chong, Hsin Ying Lee, David Forsyth 最近,由于高质量的生成和解开的潜在空间,StyleGAN 实现了各种图像处理和编辑任务。然而,不同的任务通常需要额外的架构或特定于任务的训练范式。在这项工作中,我们更深入地研究了 StyleGAN 的空间特性。我们表明,通过预训练的 StyleGAN 以及一些操作,无需任何额外架构,我们可以在各种任务上与最先进的方法相媲美,包括图像混合、全景生成、从单个图像生成、可控和局部多模态图像到图像翻译和属性转移。 |
| PolyTrack: Tracking with Bounding Polygons Authors Gaspar Faure, Hughes Perreault, Guillaume Alexandre Bilodeau, Nicolas Saunier 在本文中,我们提出了一种称为 PolyTrack 的新方法,用于使用边界多边形进行快速多对象跟踪和分割。 Polytrack 通过生成对象中心关键点的热图来检测对象。对于它们中的每一个,粗略分割是通过在每个实例上计算边界多边形而不是传统的边界框来完成的。跟踪是通过将两个连续帧作为输入并计算第一帧中检测到的每个对象的中心偏移来完成的,以预测其在第二帧中的位置。还应用了卡尔曼滤波器来减少 ID 开关的数量。由于我们的目标应用是自动驾驶系统,因此我们将我们的方法应用于城市环境视频。我们在 MOTS 和 KITTIMOTS 数据集上训练和评估 PolyTrack。结果表明,跟踪多边形可以很好地替代边界框和蒙版跟踪。 |
| A Critical Study on the Recent Deep Learning Based Semi-Supervised Video Anomaly Detection Methods Authors Mohammad Baradaran, Robert Bergevin 视频异常检测是当今计算机视觉领域的热门研究课题之一,因为异常事件包含大量信息。异常是监视系统中的主要检测目标之一,通常需要实时操作。关于用于训练的标记数据的可用性,即没有足够的异常标记数据,半监督异常检测方法最近引起了人们的兴趣。本文向该领域的研究人员介绍了一个新的视角,并基于他们用于异常检测的通用策略,回顾了最近基于深度学习的半监督视频异常检测方法。我们的目标是帮助研究人员开发更有效的视频异常检测方法。由于选择正确的深度神经网络在此任务的多个部分中起着重要作用,因此首先准备对 DNN 进行快速比较。与之前的调查不同,DNN 是从时空特征提取的角度进行审查的,专为视频异常检测而定制。这部分评论可以帮助该领域的研究人员为其方法的不同部分选择合适的网络。此外,一些最先进的异常检测方法,基于其检测策略,受到严格调查。 |
| Estimating 3D Motion and Forces of Human-Object Interactions from Internet Videos Authors Zongmian Li, Jiri Sedlar, Justin Carpentier, Ivan Laptev, Nicolas Mansard, Josef Sivic 在本文中,我们介绍了一种从单个 RGB 视频自动重建与对象交互的人的 3D 运动的方法。我们的方法估计人的 3D 姿势以及物体姿势、接触位置和施加在人体上的接触力。这项工作的主要贡献有三方面。首先,我们引入了一种方法,通过对接触和相互作用的动力学建模,联合估计人在被操纵物体上的运动和驱动力。这是一个大规模的轨迹优化问题。其次,我们开发了一种方法,可以从输入视频中自动识别人与物体或地面之间接触的 2D 位置和时间,从而显着简化优化的复杂性。 |
| Detect-and-Segment: a Deep Learning Approach to Automate Wound Image Segmentation Authors Gaetano Scebba, Jia Zhang, Sabrina Catanzaro, Carina Mihai, Oliver Distler, Martin Berli, Walter Karlen 慢性伤口严重影响生活质量。如果管理不当,它们可能会严重恶化。基于图像的伤口分析可以通过量化与愈合相关的重要特征来帮助客观评估伤口状态。然而,伤口类型、图像背景组成和捕获条件的高度异质性挑战了伤口图像的稳健分割。我们提出了 Detect and Segment DS,这是一种深度学习方法,可以生成具有高泛化能力的伤口分割图。在我们的方法中,专用的深度神经网络检测伤口位置,将伤口与无信息背景隔离,并计算伤口分割图。我们使用一个包含糖尿病足溃疡图像的数据集评估了这种方法。为了进一步测试,使用了 4 个补充的独立数据集,这些数据集具有来自不同身体部位的更多种类的伤口类型。 Matthews 相关系数 MCC 从计算全图分割时的 0.29 提高到以相同方法结合检测和分割时的 0.85。当对从补充数据集提取的伤口图像进行测试时,DS 方法将平均 MCC 从 0.17 增加到 0.85。 |
| HHP-Net: A light Heteroscedastic neural network for Head Pose estimation with uncertainty Authors Giorgio Cantarini, Federico Figari Tomenotti, Nicoletta Noceti, Francesca Odone 在本文中,我们介绍了一种从一小组头部关键点开始估计单个图像中人物头部姿势的新方法。为此,我们提出了一种回归模型,该模型利用由 2D 姿态估计算法自动计算的关键点,并输出由偏航、俯仰和滚动表示的头部姿态。我们的模型易于实现,并且相对于现有技术更高效,推理速度更快,内存占用更小,精度相当。我们的方法还提供了与三个角度相关的异方差不确定性的度量,通过适当设计的损失函数,我们表明误差和不确定性值之间存在相关性,因此这种额外的信息来源可用于后续计算步骤。作为示例应用,我们解决了图像中的社交互动分析,我们提出了一种算法,用于定量估计人与人之间的互动水平,从他们的头部姿势和对他们相互位置的推理开始。 |
| A Pixel-Level Meta-Learner for Weakly Supervised Few-Shot Semantic Segmentation Authors Yuan Hao Lee, Fu En Yang, Yu Chiang Frank Wang 很少镜头语义分割解决了学习任务,其中只有少数具有真实像素级标签的图像可用于感兴趣的新类别。通常需要收集大量数据,即具有此类真实信息的基类,然后是元学习策略来解决上述学习任务。当在训练和测试期间只能观察到图像级语义标签时,弱监督少镜头语义分割被认为是一项更具挑战性的任务。为了解决这个问题,我们提出了一种新的元学习框架,它从有限数量的数据及其语义标签中预测伪像素级分割掩码。更重要的是,我们的学习方案进一步利用生成的像素级信息用于具有分割保证的查询图像输入。因此,我们提出的学习模型可以被视为像素级元学习器。 |
| Boundary Distribution Estimation to Precise Object Detection Authors Haoran Zhou, Hang Huang, Rui Zhao, Wei Wang, Qingguo Zhou 在主要的现代检测器中,目标定位的任务由专注于边界框回归的框子网实现。框子网通常通过回归框中心位置和缩放因子来预测对象的位置。尽管经常采用这种方法,但我们观察到定位结果仍然存在缺陷,这使得检测器的性能不令人满意。在本文中,我们通过理论分析和实验验证证明了先前方法的缺陷,并提出了一种精确检测物体的新解决方案。我们的方法不是简单地关注中心和大小,而是通过估计对象边界处的分布来细化先前定位结果的边界框的边缘。 |
| Can Vision Transformers Perform Convolution? Authors Shanda Li, Xiangning Chen, Di He, Cho Jui Hsieh 最近的几项研究表明,基于注意力的网络,例如 Vision Transformer ViT,可以在不使用卷积层的情况下在多项计算机视觉任务上胜过卷积神经网络 CNN。这自然会导致以下问题 ViT 的自注意力层能否表达任何卷积操作相对位置编码起着至关重要的作用。我们进一步为 Vision Transformers 提供了表达 CNN 的头部数量的下限。 |
| Attribute-Based Deep Periocular Recognition: Leveraging Soft Biometrics to Improve Periocular Recognition Authors Veeru Talreja, Nasser M. Nasrabadi, Matthew C. Valenti 近年来,眼周识别已发展成为一种有价值的生物特征识别方法,尤其是在野外环境中,例如,由于 COVID 19 大流行而导致面部识别可能不适用的蒙面人脸。本文提出了一种新的深度眼周识别框架,称为基于属性的深度眼周识别 ADPR,它可以预测软生物特征并将预测结合到眼周识别算法中,以高精度地从眼周图像中确定身份。我们提出了一个端到端框架,它使用几个共享的卷积神经网络 CNN 层一个公共网络,其输出馈送两个独立的专用分支模态专用层,第一个分支对眼周图像进行分类,而第二个分支预测软生物识别。接下来,来自这两个分支的特征融合在一起以进行最终的眼周识别。所提出的方法不同于现有方法,因为它不仅使用共享的 CNN 特征空间来联合训练这两个任务,而且还在训练步骤中将预测的软生物特征与眼周特征融合,以提高整体眼周识别性能。我们提出的模型使用四种不同的公开可用数据集进行了广泛评估。 |
| Exploring the Semi-supervised Video Object Segmentation Problem from a Cyclic Perspective Authors Yuxi Li, Ning Xu, Wenjie Yang, John See, Weiyao Lin 现代视频对象分割 VOS 算法在顺序处理顺序中取得了非常高的性能,而目前大多数流行的流水线仍然表现出一些明显的不足,如累积误差、未知的鲁棒性或缺乏适当的解释工具。在本文中,我们将半监督视频对象分割问题置于循环工作流中,并发现上述缺陷可以通过半监督 VOS 系统固有的循环特性共同解决。首先,结合到标准顺序流中的循环机制可以为逐像素对应产生更一致的表示。依靠起始帧中的准确参考掩码,我们表明可以减轻错误传播问题。接下来,一个简单的梯度校正模块,自然地将离线循环管道扩展为在线方式,可以突出结果的高频和细节部分,以进一步提高分割质量,同时保持可行的计算成本。同时这种校正可以保护网络免受干扰信号导致的严重性能下降。最后,我们开发了基于梯度校正过程的循环有效感受野循环 ERF,为分析对象特定的兴趣区域提供了新的视角。我们对 DAVIS16、DAVIS17 和 Youtube VOS 的具有挑战性的基准进行全面比较和详细分析,证明循环机制有助于提高分割质量,提高 VOS 系统的鲁棒性,并进一步提供不同 VOS 算法如何工作的定性比较和解释. |
| Masking Modalities for Cross-modal Video Retrieval Authors Valentin Gabeur, Arsha Nagrani, Chen Sun, Karteek Alahari, Cordelia Schmid 大规模未标记数据集的预训练在计算机视觉和自然语言处理领域显示出令人印象深刻的性能改进。鉴于大规模教学视频数据集的出现,预训练视频编码器的常见策略是使用伴随语音作为弱监督。然而,由于语音用于监督预训练,因此视频编码器永远不会看到它,它不会学习处理该模态。我们解决了当前预训练方法的这个缺点,这些方法无法利用口语中的丰富线索。我们的建议是使用所有可用的视频模态作为监督来预训练视频编码器,即外观、声音和转录的语音。我们屏蔽输入中的整个模态并使用其他两种模态对其进行预测。这鼓励每种模态与其他模态进行协作,我们的视频编码器学习处理外观和音频以及语音。 |
| Joint Detection of Motion Boundaries and Occlusions Authors Hannah Halin Kim, Shuzhi Yu, Carlo Tomasi 我们提出了 MONet,这是一种卷积神经网络,可以在时间上向前和向后联合检测视频中的运动边界 MB 和遮挡区域 Occ。检测很困难,因为光流沿 MB 是不连续的,并且在 Occ 中是未定义的,而许多流估计器假设平滑并且在任何地方都定义了流。为了同时在两个时间方向上进行推理,我们直接扭曲了两帧之间的估计图。由于帧之间的外观不匹配通常表示 MB 或 Occ 附近,我们构建了一个成本块,为一帧中的每个特征记录与搜索范围内匹配特征的最低差异。这个成本块是二维的,比流量分析中使用的四维成本量要便宜得多。成本块特征由编码器计算,MB 和 Occ 估计由解码器计算。我们发现将解码器层从细到粗排列,而不是从粗到细排列,可以提高性能。 |
| Neural Scene Flow Prior Authors Xueqian Li, Jhony Kaesemodel Pontes, Simon Lucey 在深度学习革命之前,许多感知算法基于运行时优化并结合强先验正则化惩罚。计算机视觉中的一个主要例子是光学和场景流。监督学习在很大程度上取代了显式正则化的需要。相反,他们依赖大量标记数据来捕获先前的统计数据,而这些数据对于许多问题并不总是可用的。尽管使用优化来学习神经网络,但该网络的权重在运行时被冻结。因此,这些学习解决方案是特定领域的,不能很好地推广到其他统计上不同的场景。本文重新审视了主要依赖运行时优化和强正则化的场景流问题。这里的一个核心创新是包含神经场景流先验,它使用神经网络的架构作为一种新型的隐式正则化器。与基于学习的场景流方法不同,优化发生在运行时,我们的方法不需要离线数据集,因此非常适合在自动驾驶等新环境中部署。我们展示了完全基于多层感知器 MLP 的架构可以用作先验场景流。我们的方法在场景流基准测试中获得了具有竞争力的结果,如果不是更好的话。此外,我们的神经先验隐式和连续场景流表示允许我们估计一系列点云之间的密集长期对应关系。密集运动信息由场景流场表示,其中点可以通过整合运动矢量随时间传播。 |
| HRViT: Multi-Scale High-Resolution Vision Transformer Authors Jiaqi Gu, Hyoukjun Kwon, Dilin Wang, Wei Ye, Meng Li, Yu Hsin Chen, Liangzhen Lai, Vikas Chandra, David Z. Pan 视觉转换器 ViT 因其在计算机视觉任务上的卓越性能而备受关注。为了解决其单尺度低分辨率表示的局限性,先前的工作使 ViT 适应具有分层架构的高分辨率密集预测任务,以生成金字塔特征。然而,鉴于 ViT 的分类如顺序拓扑,多尺度表示学习仍在探索中。为了增强 ViTs 学习语义丰富和空间精确的多尺度表示的能力,在这项工作中,我们提出了高分辨率多分支架构与视觉转换器的有效集成,称为 HRViT,将密集预测任务的帕累托前沿推向一个新的方向。等级。我们探索异构分支设计,减少线性层的冗余,并增强模型非线性以平衡模型性能和硬件效率。拟议的 HRViT 在语义分割任务的 ADE20K 上实现了 50.20 mIoU,在 Cityscapes 上实现了 83.16 mIoU,超过了最先进的 MiT 和 CSWin,平均提高了 1.78 mIoU、28 个参数减少和 21 FLOPs 减少,证明了 HRViT 的潜力同样强大 |
| Gradient Frequency Modulation for Visually Explaining Video Understanding Models Authors Xinmiao Lin, Wentao Bao, Matthew Wright, Yu Kong 在许多应用中,理解机器学习模型为何做出它所做的决定是必不可少的,但这受到最先进神经网络的黑匣子性质的抑制。因此,人们越来越关注深度学习中的可解释性,包括视频理解领域。由于视频数据的时间维度,解释视频动作识别模型的主要挑战是产生时空一致的视觉解释,这在现有文献中已被忽略。在本文中,我们提出了基于频率的极值扰动 F EP 来解释视频理解模型的决策。由于扰动方法给出的解释在空间和时间上都是嘈杂且不平滑的,我们建议使用离散余弦变换 DCT 调制来自神经网络模型的梯度图的频率。 |
| Increasing Liquid State Machine Performance with Edge-of-Chaos Dynamics Organized by Astrocyte-modulated Plasticity Authors Vladimir A. Ivanov, Konstantinos P. Michmizos 液态机器 LSM 结合了低训练复杂性和生物学合理性,这使其成为边缘和神经形态计算范式的有吸引力的机器学习框架。 LSM 最初是作为大脑计算模型提出的,在没有梯度反向传播的情况下调整其内部权重,与多层神经网络相比,这导致性能较低。神经科学的最新发现表明,星形胶质细胞是一种长期被忽视的非神经元脑细胞,它调节突触可塑性和大脑动力学,将大脑网络调整到有序和混沌之间计算上最优的临界相变附近。受这种对大脑网络如何自我调节的颠覆性理解的启发,我们提出了神经元星形胶质细胞液体状态机 NALSM,它通过自我组织的近临界动态来解决表现不佳的问题。与其生物学对应物类似,星形胶质细胞模型整合了神经元活动,并为尖峰时间依赖性可塑性 STDP 提供全局反馈,STDP 围绕与混沌边缘相关的关键分支因子自我组织 NALSM 动力学。我们证明了 NALSM 与可比较的 LSM 方法相比达到了最先进的准确性,而无需进行数据特定的手动调整。 NALSM 在 MNIST 上的最高准确率为 97.61,在 N MNIST 上为 97.51,在 Fashion MNIST 上为 85.84,NALSM 的性能与当前通过反向传播训练的全连接多层尖峰神经网络相当。 |
| LogAvgExp Provides a Principled and Performant Global Pooling Operator Authors Scott C. Lowe, Thomas Trappenberg, Sageev Oore 我们寻求通过应用理论上更合理的运算符来改进神经网络中的池化操作。我们证明 LogSumExp 为 logits 提供了一个自然的 OR 运算符。当对池运算符中的元素数量进行更正时,这将变为 text LogAvgExp log text mean exp x 。通过引入单个温度参数,LogAvgExp 从其操作数的最大值平滑过渡到在 t 到 0 和 t 到 infty 的极限情况下找到的平均值。 |
| Meta-Learning the Search Distribution of Black-Box Random Search Based Adversarial Attacks Authors Maksym Yatsura, Jan Hendrik Metzen, Matthias Hein 最近,基于随机搜索方案的对抗性攻击在黑盒鲁棒性评估中获得了最先进的结果。然而,正如我们在这项工作中所展示的,它们在不同查询预算制度中的效率取决于手动设计和基础提案分布的启发式调整。我们研究如何通过根据攻击期间获得的信息在线调整提议分布来解决这个问题。我们考虑 Square Attack,这是一种最先进的基于分数的黑盒攻击,并展示了如何通过学习控制器来提高其性能,该控制器在攻击期间在线调整提议分布的参数。我们在具有白盒访问权限的 CIFAR10 模型上使用基于梯度的端到端训练来训练控制器。我们证明,对于具有黑盒访问权限的各种不同模型,将学习到的控制器插入到攻击中可以一致地将其在不同查询机制中的黑盒鲁棒性估计提高多达 20。 |
| Progressive observation of Covid-19 vaccination effects on skin-cellular structures by use of Intelligent Laser Speckle Classification (ILSC) Authors Ahmet Orun, Fatih Kurugollu 我们使用完善的基于智能激光斑点分类 ILSC 图像的技术对 Covid 19 Astra Zeneca 疫苗接种对皮肤细胞网络和特性的影响进行了渐进观察,并通过激光斑点皮肤图像采样设法区分了三个不同的受试者组,例如早期接种疫苗、晚期接种疫苗和未接种疫苗的个体。 |
| Minimizing Energy Consumption Leads to the Emergence of Gaits in Legged Robots Authors Zipeng Fu, Ashish Kumar, Jitendra Malik, Deepak Pathak 腿式运动通常被研究并表示为一组离散的步态模式,如步行、小跑、疾驰,它们通常被视为给定的,并在腿式机器人中预先编程,以实现不同速度的高效运动。然而,固定一组预先编程的步态限制了运动的普遍性。最近的动物运动研究表明,这些传统步态仅在理想的平坦地形条件下普遍存在,而现实世界的运动是非结构化的,更像是间歇性的步态。哪些原理可以导致哺乳动物的结构化和非结构化模式以及如何在机器人中合成它们在这项工作中,我们通过合成方法进行分析,并通过最小化机械能来学习移动。我们证明,学习最大限度地减少能源消耗在真实四足机器人中以不同速度出现的自然运动步态中起着关键作用。紧急步态结构在理想的地形中,看起来类似于马和羊的步态。同样的方法会导致崎岖地形中的非结构化步态,这与动物运动控制的发现一致。我们在自然地形的模拟和真实硬件中验证了我们的假设。 |
| Explainable Medical Image Segmentation via Generative Adversarial Networks and Layer-wise Relevance Propagation Authors Awadelrahman M. A. Ahmed, Leen A. M. Ali 本文通过提出基于生成对抗网络的模型来分割内窥镜图像中的息肉和器械,有助于自动化医学图像分割。这项工作的一个主要贡献是使用分层相关性传播方法为预测提供解释,指定哪些输入图像像素与预测相关以及在多大程度上相关。在息肉分割任务上,模型的准确度为 0.84,Jaccard 指数为 0.46。在仪器分割任务上,模型的准确度为 0.96,Jaccard 指数为 0.70。 |
| Trajectory Prediction with Graph-based Dual-scale Context Fusion Authors Lu Zhang, Peiliang Li, Jing Chen, Shaojie Shen 交通参与者的运动预测对于安全和强大的自动驾驶系统至关重要,尤其是在杂乱的城市环境中。然而,由于复杂的道路拓扑以及其他代理的不确定意图,这是非常具有挑战性的。在本文中,我们提出了一个基于图形的轨迹预测网络,名为 Dual Scale Predictor DSP,它以分层方式对静态和动态驾驶环境进行编码。与基于光栅化地图或稀疏车道图的方法不同,我们将驾驶环境视为具有两层的图,同时关注几何和拓扑特征。应用图神经网络 GNN 来提取不同粒度级别的特征,然后将特征与基于注意力的层间网络进行聚合,从而实现更好的局部全局特征融合。遵循最近的目标驱动轨迹预测管道,提取目标代理的高可能性目标候选者,并以这些目标为条件生成预测轨迹。由于提出的双尺度上下文融合网络,我们的 DSP 能够生成准确的和人类一样的多模态轨迹。 |
| Fitness Landscape Footprint: A Framework to Compare Neural Architecture Search Problems Authors Kalifou Ren Traor , Andr s Camero, Xiao Xiang Zhu 神经架构搜索是一个很有前途的研究领域,致力于自动化神经网络模型的设计。这个领域正在迅速发展,方法论激增,从贝叶斯优化、神经转化到可微搜索,以及在各种环境中的应用。然而,尽管取得了巨大的进步,但很少有研究对问题本身的难度提出见解,因此这些方法的成功或失败仍然无法解释。从这个意义上说,优化领域已经开发出突出关键方面来描述优化问题的方法。在描述可靠和定量的搜索算法时,适应性景观分析脱颖而出。在本文中,我们建议使用适应度景观分析来研究神经架构搜索问题。特别是,我们引入了适应度景观足迹,这是八个 8 个通用指标的聚合,用于综合架构搜索问题的景观。我们研究了两个问题,经典图像分类基准 CIFAR 10 和遥感问题 So2Sat LCZ42。结果提供了对问题的定量评估,允许表征相对难度和其他特征,例如坚固性或持久性,这有助于为问题定制搜索策略。 |
| Overcoming Catastrophic Forgetting in Incremental Few-Shot Learning by Finding Flat Minima Authors Guangyuan Shi, Jiaxin Chen, Wenlong Zhang, Li Ming Zhan, Xiao Ming Wu 这篇论文考虑了增量小样本学习,这需要一个模型来不断地识别新类别,只提供几个例子。我们的研究表明,现有方法严重遭受灾难性遗忘,这是增量学习中众所周知的问题,由于数据稀缺和少数镜头设置不平衡而加剧。我们的分析进一步表明,为了防止灾难性遗忘,需要在原始阶段采取行动,即基础类的训练,而不是后来的几个镜头学习课程。因此,我们建议搜索基础训练目标函数的平坦局部最小值,然后在新任务的平坦区域内微调模型参数。通过这种方式,模型可以在保留旧类的同时有效地学习新类。综合实验结果表明,我们的方法优于所有现有技术方法,并且非常接近近似上限。 |
| Comprehensive and Clinically Accurate Head and Neck Organs at Risk Delineation via Stratified Deep Learning: A Large-scale Multi-Institutional Study Authors Dazhou Guo, Jia Ge, Xianghua Ye, Senxiang Yan, Yi Xin, Yuchen Song, Bing shen Huang, Tsung Min Hung, Zhuotun Zhu, Ling Peng, Yanping Ren, Rui Liu, Gong Zhang, Mengyuan Mao, Xiaohua Chen, Zhongjie Lu, Wenxiang Li, Yuzhen Chen, Lingyun Huang, Jing Xiao, Adam P. Harrison, Le Lu, Chien Yu Lin, Dakai Jin, Tsung Ying Ho 准确的危险器官 OAR 分割对于减少放疗后的并发症至关重要。共识指南建议在头颈部 HN 区域设置超过 40 个 OAR,但是,由于这项任务的可预测劳动力成本过高,大多数机构通过描绘较小的 OAR 子集并忽略剂量分布,选择了一个大大简化的协议与其他 OAR 相关联。在这项工作中,我们提出了一种新颖、自动化且高效的分层 OAR 分割 SOARS 系统,使用深度学习来精确描绘 42 H N OAR 的综合集。 SOARS 将 42 个 OAR 分层为锚、中级和小硬子类别,并通过神经架构搜索 NAS 原则为每个类别专门导出神经网络架构。我们使用内部机构的 176 名受训患者构建 SOARS 模型,并对来自六个不同机构的 1327 名外部患者进行独立评估。对于每个机构评估,它在 Dice 得分上始终优于其他最先进的方法至少 3 5,其他指标的相对误差减少高达 36。更重要的是,广泛的多用户研究显然表明,98 项 SOARS 预测只需要非常小的修改或无需修改即可直接临床接受,从而节省了 90 名放射肿瘤学家的工作量,并且它们的分割和剂量测定精度在用户间差异以内或小于用户间差异。 |
| ISP-Agnostic Image Reconstruction for Under-Display Cameras Authors Miao Qi, Yuqi Li, Wolfgang Heidrich 近年来,人们提出了屏下摄像头作为一种减少移动设备外形尺寸同时最大化屏幕面积的方法。不幸的是,将相机放在屏幕后面会导致显着的图像失真,包括对比度损失、模糊、噪声、色移、散射伪影和光敏感度降低。在本文中,我们提出了一种与 ISP 无关的图像恢复管道,即它可以与任何传统 ISP 结合以生成与使用相同 ISP 的常规相机的外观相匹配的最终图像。这是通过执行 RAW 到 RAW 图像恢复的深度学习方法实现的。为了获得大量具有足够对比度和场景多样性的真实欠显示相机训练数据,我们进一步开发了一种利用 HDR 监视器的数据捕获方法,以及一种数据增强方法来生成合适的 HDR 内容。监视器数据补充了现实世界的数据,这些数据具有较少的场景多样性,但允许我们在不受监视器分辨率限制的情况下实现精细的细节恢复。 |
| Out of distribution detection for skin and malaria images Authors Muhammad Zaida, Shafaqat Ali, Mohsen Ali, Sarfaraz Hussein, Asma Saadia, Waqas Sultani 深度神经网络在使用医学图像数据的疾病检测和分类方面显示出有希望的结果。然而,他们仍然面临处理现实世界场景的挑战,尤其是可靠地检测分布外的 OoD 样本。我们提出了一种对皮肤和疟疾图像中的 OoD 样本进行稳健分类的方法,而无需在训练期间访问标记的 OoD 样本。具体来说,我们使用度量学习和逻辑回归来强制深度网络学习更丰富的类代表特征。为了指导针对 OoD 示例的学习过程,我们通过删除图像中特定于类的显着区域或排列图像部分并使它们远离分布样本来生成 ID 相似的示例。在推理期间,使用 K 倒数最近邻来检测分布之外的样本。对于皮肤癌 OoD 检测,我们采用两个标准的基准皮肤癌 ISIC 数据集作为 ID,并将六个不同难度级别的不同数据集作为分布外的数据集。对于疟疾 OoD 检测,我们使用 BBBC041 疟疾数据集作为 ID,使用五个不同的具有挑战性的数据集作为分布。 |
| Constructing High-Order Signed Distance Maps from Computed Tomography Data with Application to Bone Morphometry Authors Bryce A. Besler, Tannis D. Kemp, Nils D. Forkert, Steven K. Boyd 提出了一种为用计算机断层扫描成像的两相材料构建高阶符号距离场的算法。有符号距离场是高阶的,因为它没有与采样信号的距离变换相关联的量化伪影。使用最近点算法来解决窄带问题,该算法针对非带符号距离场的隐式嵌入进行了扩展。高阶快速扫描算法用于将窄带扩展到域的其余部分。在理想的隐式表面上验证了窄带和扩展方法的精度顺序。该方法应用于十块切除的牛小梁骨立方体。表面的定位、相位密度的估计和局部形态测量学通过这些主题进行了验证。 |
| Federated Split Vision Transformer for COVID-19CXR Diagnosis using Task-Agnostic Training Authors Sangjoon Park, Gwanghyun Kim, Jeongsol Kim, Boah Kim, Jong Chul Ye 联邦学习在不同客户之间共享神经网络的权重,在医疗保健领域越来越受到关注,因为它可以在保持数据隐私的同时对大量分散数据进行训练。例如,这可以在胸部 X 射线 CXR 图像上进行 COVID 19 诊断的神经网络训练,而无需跨多家医院收集患者 CXR 数据。不幸的是,如果采用高表现力的网络架构,权重的交换会迅速消耗网络带宽。所谓的分裂学习通过将神经网络分为客户端和服务器部分来部分解决这个问题,使得网络的客户端部分占用较少的计算资源和带宽。然而,目前尚不清楚如何在不牺牲整体网络性能的情况下找到最佳分割。为了合并这些方法,从而最大限度地发挥它们的独特优势,我们在这里展示了 Vision Transformer,一种最近开发的具有直接可分解配置的深度学习架构,非常适合在不牺牲性能的情况下进行拆分学习。即使在使用来自多个来源的 CXR 数据集模拟医院之间真正协作的非独立和同分布的数据分布下,所提出的框架也能够获得与数据集中训练相当的性能。此外,所提出的框架以及异构多任务客户端还提高了单个任务的性能,包括 COVID 19 的诊断,消除了与无数参数共享大权重的需要。 |
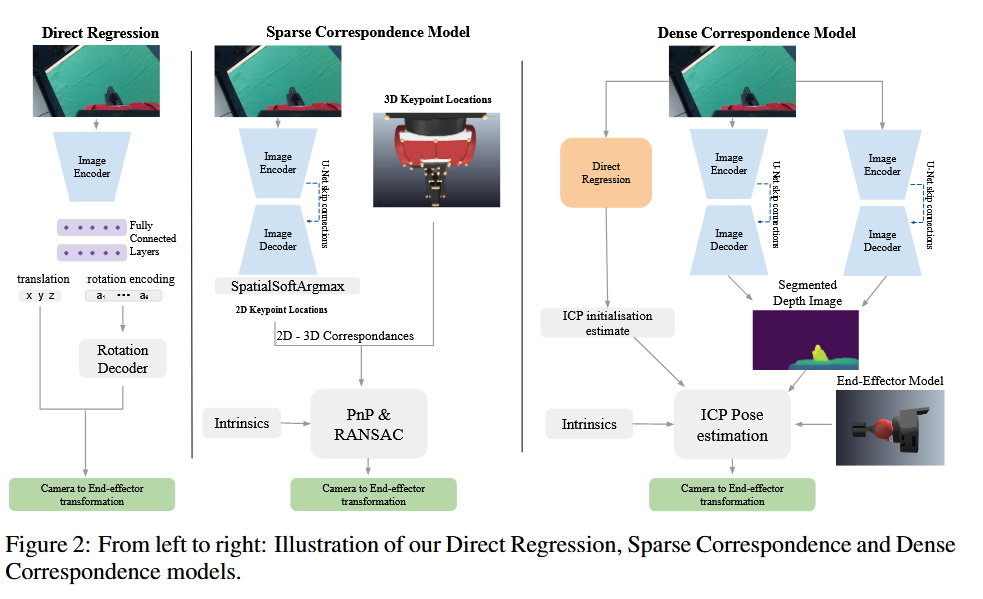
| Learning Eye-in-Hand Camera Calibration from a Single Image Authors Eugene Valassakis, Kamil Dreczkowski, Edward Johns 手眼相机校准是机器人技术中一个基本且长期研究的问题。我们提出了一项关于使用基于学习的方法从单个 RGB 图像在线解决此问题的研究,同时使用完全合成的数据训练我们的模型。我们研究了三种主要方法:一种直接从图像中预测外在矩阵的直接回归模型,一种回归 2D 关键点然后使用 PnP 的稀疏对应模型,以及一种使用回归深度和分割图来启用 ICP 姿态估计的密集对应模型。 |
| Arch-Net: Model Distillation for Architecture Agnostic Model Deployment Authors Weixin Xu, Zipeng Feng, Shuangkang Fang, Song Yuan, Yi Yang, Shuchang Zhou 深度神经网络对计算能力的巨大需求是其实际应用的主要障碍。许多最近的专用集成电路 ASIC 芯片都具有对神经网络加速的专用硬件支持。然而,由于 ASIC 需要多年的开发时间,它们不可避免地会被神经架构研究的最新发展赶上。例如,Transformer Networks 在许多流行的芯片上都没有原生支持,因此很难部署。在本文中,我们提出了 Arch Net,这是一个神经网络家族,仅由大多数 ASIC 架构有效支持的算子组成。生成 Arch Net 时,不太常见的网络结构,如层归一化和嵌入层,会通过无标签的 Blockwise Model Distillation 以渐进的方式消除,同时执行亚 8 位量化以最大化性能。机器翻译和图像分类任务的实证结果证实,我们可以将最新开发的神经架构转化为快速运行且准确的 Arch Net,准备部署在多个批量生产的 ASIC 芯片上。 |
| Comparing Bayesian Models for Organ Contouring in Headand Neck Radiotherapy Authors Prerak Mody, Nicolas Chaves de Plaza, Klaus Hildebrandt, Rene van Egmond, Huib de Ridder, Marius Staring 用于放射治疗中器官轮廓的深度学习模型已准备好用于临床,但目前几乎没有用于预测轮廓的自动质量评估 QA 的工具。使用贝叶斯模型及其相关的不确定性,人们可以潜在地自动化检测不准确预测的过程。我们研究了两个用于自动轮廓绘制的贝叶斯模型 DropOut 和 FlipOut,使用定量测量预期校准误差 ECE 和基于区域的定性测量精度与不确定性 R AvU 图。众所周知,模型应该具有较低的 ECE 才能被认为是值得信赖的。但是,在 QA 环境中,模型还应该在不准确的区域中具有高不确定性,在准确的区域中具有低不确定性。这种行为可以将专家用户的视觉注意力引导到可能不准确的区域,从而加快 QA 过程。使用 R AvU 图,我们定性地比较了不同模型在准确和不准确区域中的行为。实验在 MICCAI2015 Head and Neck Segmentation Challenge 和 DeepMindTCIA CT 数据集上进行,使用三个模型 DropOut DICE、Dropout CE Cross Entropy 和 FlipOut CE。定量结果表明,DropOut DICE 的 ECE 最高,而 Dropout CE 和 FlipOut CE 的 ECE 最低。为了更好地理解 DropOut CE 和 FlipOut CE 之间的区别,我们使用了 R AvU 图,该图显示 FlipOut CE 在不准确区域的不确定性覆盖范围比 DropOut CE 更好。 |
| Chinese Abs From Machine Translation |















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









