










AI视野·今日CS.CV 计算机视觉论文速览
Wed, 4 Oct 2023
Totally 79 papers
👉上期速览✈更多精彩请移步主页
Interesting:
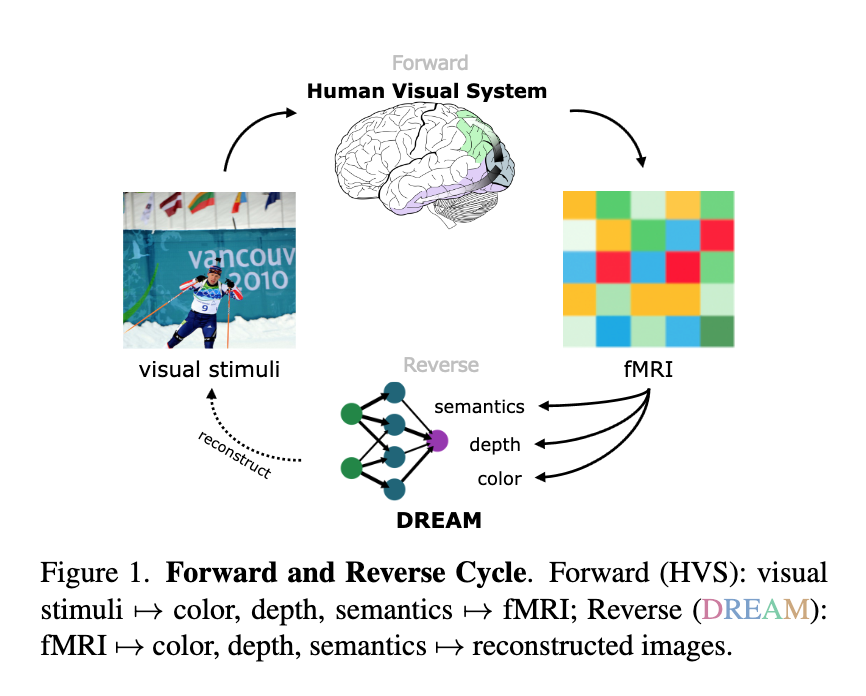
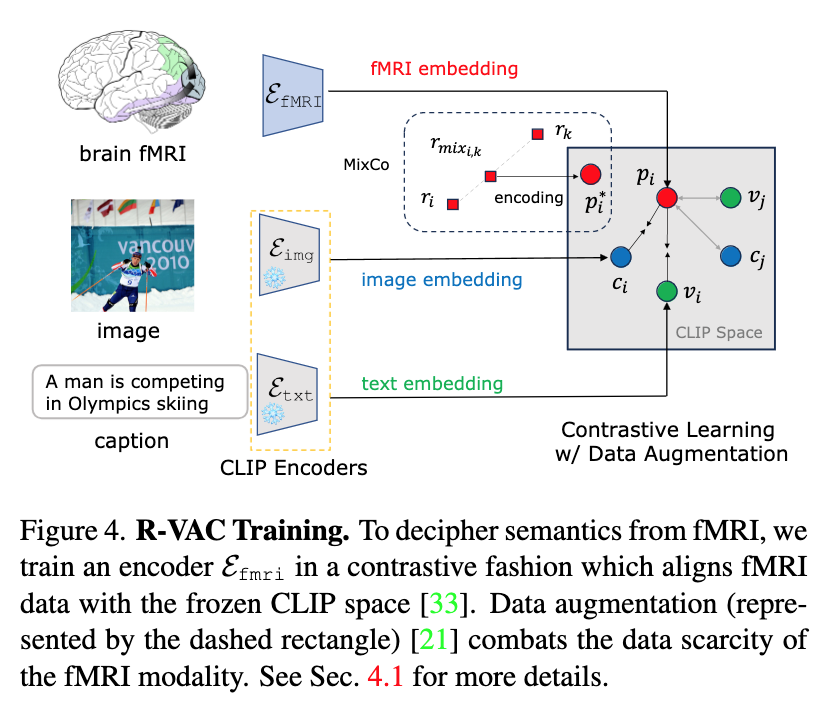
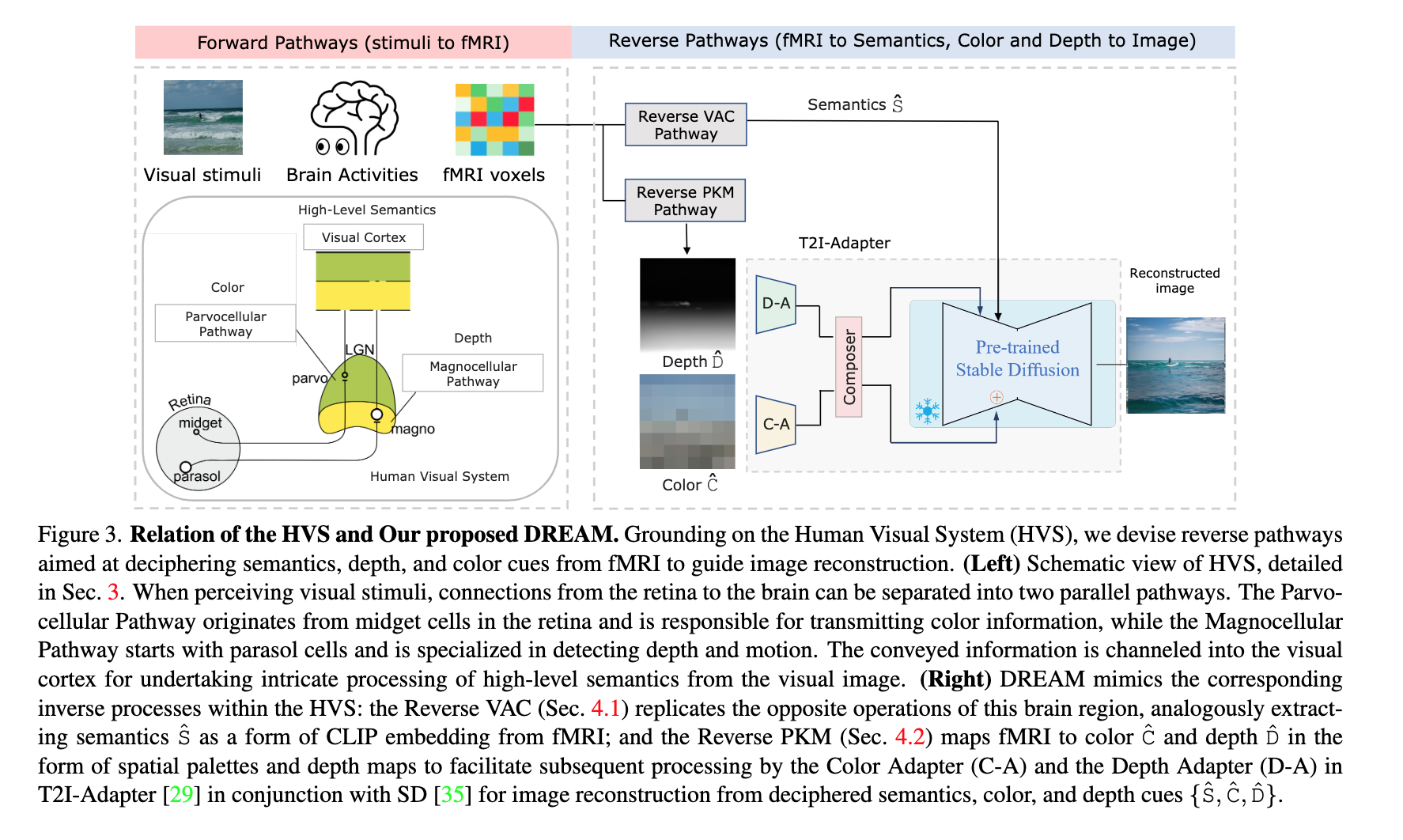
📚DREAM, 基于功能核磁共振信号重建人类看见的视觉图像。(from UCL London)
📚RSRD,公路路面数据集(from 清华 )

website: https://thu-rsxd.com/rsrd/
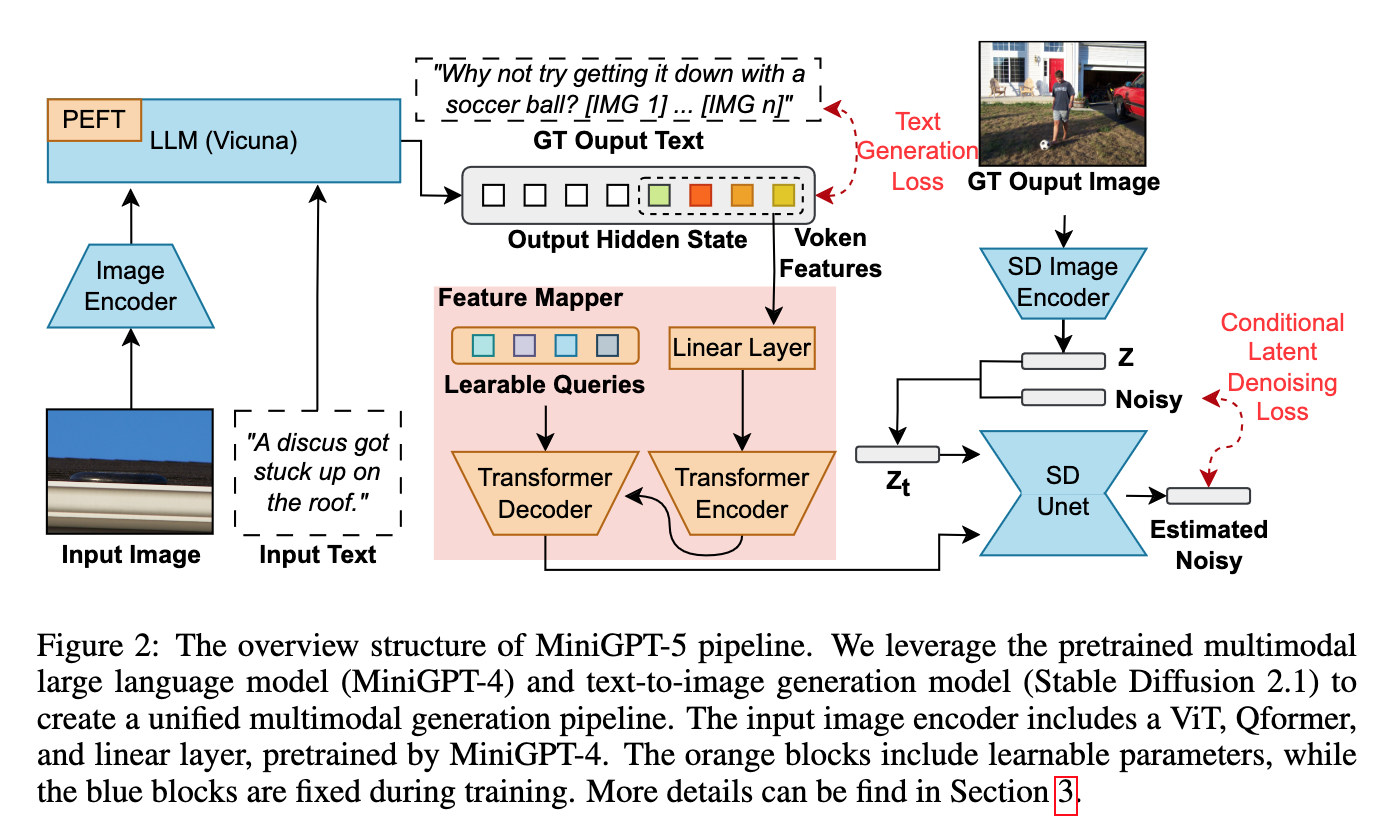
📚MiniGPT5, 构建了viken用于作为图像与文件的中介。(from ucsc)

website:https://github.com/eric-ai-lab/MiniGPT-5
📚MarineDet, 海洋实体目标检测数据集(from 香港科技)


Daily Computer Vision Papers
| DREAM: Visual Decoding from Reversing Human Visual System Authors Weihao Xia, Raoul de Charette, Cengiz ztireli, Jing Hao Xue 在这项工作中,我们提出了 DREAM,一种基于人类视觉系统基础知识的功能磁共振成像图像方法,用于根据大脑活动重建观察到的图像。我们精心设计反向路径来模拟人类感知视觉世界的层次和并行性质。这些定制的路径专门用于破译 fMRI 数据中的语义、颜色和深度线索,反映从视觉刺激到 fMRI 记录的正向路径。为此,两个组件模拟人类视觉系统内的逆过程:反向视觉关联皮质 R VAC 反转该大脑区域的路径,从 fMRI 数据中提取语义;反向并行 PKM R PKM 组件同时从 fMRI 信号预测颜色和深度。实验表明,我们的方法在外观、结构和语义的一致性方面优于当前最先进的模型。 |
| RSRD: A Road Surface Reconstruction Dataset and Benchmark for Safe and Comfortable Autonomous Driving Authors Tong Zhao, Chenfeng Xu, Mingyu Ding, Masayoshi Tomizuka, Wei Zhan, Yintao Wei 本文解决了智能机器人系统(特别是自动驾驶汽车)对安全性和舒适性日益增长的需求,其中路况在整体驾驶性能中发挥着关键作用。例如,重建路面有助于增强运动规划和控制系统对车辆响应的分析和预测。我们介绍了路面重建数据集 RSRD,这是一个真实世界、高分辨率、高精度的数据集,通过专门的平台在不同的驾驶条件下收集。它涵盖了常见的道路类型,包含约 16,000 对立体图像、原始点云和地面真实深度视差图,并具有精确的后处理管道以确保其质量。基于RSRD,我们进一步建立了一个通过深度估计和立体匹配恢复道路轮廓的综合基准。使用各种最先进方法的初步评估揭示了我们数据集的有效性和任务的挑战,强调了 RSRD 作为先进技术的宝贵资源的巨大机会,例如实现安全自动驾驶的多视图立体。 |
| TransRadar: Adaptive-Directional Transformer for Real-Time Multi-View Radar Semantic Segmentation Authors Yahia Dalbah, Jean Lahoud, Hisham Cholakkal 场景理解在实现自动驾驶以及保持高标准的性能和安全性方面发挥着至关重要的作用。为了解决这一任务,相机和激光扫描仪 LiDAR 一直是最常用的传感器,雷达不太受欢迎。尽管如此,雷达仍然是成本低廉、信息密集且能够抵抗恶劣天气条件的快速传感技术。虽然之前已经提出了基于雷达的场景语义分割的多项工作,但由于固有的噪声和稀疏性以及不成比例的前景和背景,雷达数据的性质仍然提出了挑战。在这项工作中,我们提出了一种新的雷达场景语义分割方法,通过一种新颖的架构和损失函数来使用雷达数据的多输入融合,以解决雷达感知的缺点。我们的新颖架构包括一个有效的注意力模块,可以自适应地捕获重要的特征信息。 |
| MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts Authors Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai Wei Chang, Michel Galley, Jianfeng Gao 尽管大型语言模型法学硕士和大型多模态模型法学硕士在各个领域表现出令人印象深刻的技能,但它们在视觉上下文中进行数学推理的能力尚未得到正式检验。为法学硕士和法学硕士配备这种能力对于通用人工智能助手至关重要,并展示了在教育、数据分析和科学发现方面的巨大潜力。为了弥补这一差距,我们推出了 MathVista,这是一个旨在合并来自不同数学和视觉任务的挑战的基准。我们首先对文献中的关键任务类型、推理技能和视觉上下文进行分类,以指导我们从 28 个现有的数学重点和视觉问答数据集中进行选择。然后,我们构建了三个新数据集:IQTest、FunctionQA 和 PaperQA,以适应缺失的视觉上下文类型。这些问题通常需要 OCR 或图像字幕之外的深入视觉理解,以及使用丰富的特定领域工具进行组合推理,从而对现有模型提出了显着的挑战。我们对 11 个著名的开源和专有基础模型 LLM、使用工具增强的 LLM 和 LMM 以及 GPT 4V 的早期实验进行了全面评估。性能最好的模型 Multimodal Bard 仅达到人类性能的 58(34.8 vs 60.3),表明还有足够的进一步改进空间。鉴于这一巨大差距,MathVista 推动了通用人工智能代理开发的未来研究,这些人工智能代理能够处理数学密集型和视觉丰富的现实世界任务。初步测试表明,MathVista 也对 GPT 4V 提出了挑战,凸显了该基准测试的重要性。 |
| Talk2BEV: Language-enhanced Bird's-eye View Maps for Autonomous Driving Authors Vikrant Dewangan, Tushar Choudhary, Shivam Chandhok, Shubham Priyadarshan, Anushka Jain, Arun K. Singh, Siddharth Srivastava, Krishna Murthy Jatavallabhula, K. Madhava Krishna Talk2BEV 是一种大型视觉语言模型 LVLM 接口,用于自动驾驶环境中鸟瞰 BEV 地图。虽然自动驾驶场景的现有感知系统主要集中在预定义的封闭对象类别和驾驶场景集,但 Talk2BEV 将通用语言和视觉模型的最新进展与 BEV 结构化地图表示相结合,消除了对特定任务模型的需求。这使得单个系统能够满足各种自动驾驶任务,包括视觉和空间推理、预测交通参与者的意图以及基于视觉提示的决策。我们在大量场景理解任务上广泛评估 Talk2BEV,这些任务依赖于解释自由形式自然语言查询的能力,以及将这些查询基于嵌入到语言增强 BEV 地图中的视觉上下文的能力。 |
| Hierarchical Generation of Human-Object Interactions with Diffusion Probabilistic Models Authors Huaijin Pi, Sida Peng, Minghui Yang, Xiaowei Zhou, Hujun Bao 本文提出了一种生成人类与目标物体交互的 3D 运动的新方法,重点是解决合成长范围和多样化运动的挑战,这是现有的自回归模型或基于路径规划的方法无法实现的。我们提出了一个分层生成框架来解决这一挑战。具体来说,我们的框架首先生成一组里程碑,然后综合它们的运动。因此,长距离运动的生成可以简化为合成几个由里程碑引导的短运动序列。在 NSM、COUCH 和 SAMP 数据集上的实验表明,我们的方法在质量和多样性方面都大大优于以前的方法。 |
| MiniGPT-5: Interleaved Vision-and-Language Generation via Generative Vokens Authors Kaizhi Zheng, Xuehai He, Xin Eric Wang 大型语言模型法学硕士因其在自然语言处理方面的进步而受到广泛关注,展示了在文本理解和生成方面无与伦比的能力。然而,同时生成具有连贯文本叙述的图像仍然是一个不断发展的前沿领域。为此,我们引入了一种创新的交错视觉和语言生成技术,该技术以生成 vokens 的概念为基础,充当协调图像文本输出的桥梁。我们的方法的特点是独特的两阶段训练策略,专注于无描述多模态生成,其中训练不需要图像的全面描述。为了增强模型的完整性,引入了无分类器指导,从而增强了 vokens 在图像生成方面的有效性。 |
| Exploring Model Learning Heterogeneity for Boosting Ensemble Robustness Authors Yanzhao Wu, Ka Ho Chow, Wenqi Wei, Ling Liu 深度神经网络集成具有提高复杂学习任务泛化性能的潜力。本文提出了形式分析和实证评估,表明具有高集成多样性的异构深度集成可以有效地利用模型学习异质性来提高集成的鲁棒性。我们首先证明,为解决相同学习问题(例如目标检测)而训练的异构 DNN 模型可以通过我们的加权边界框集成共识方法显着增强平均精度 mAP。其次,我们通过引入基于连接组件标记 CCL 的对齐,进一步组合异构模型来解决不同的学习问题,例如对象检测和语义分割。我们证明,这种两层异构性驱动的集成构建方法可以组成一个集成团队,促进集成成员模型之间的高集成多样性和低负相关性,从而增强集成针对负面例子和对抗性攻击的鲁棒性。第三,我们对负相关性方面的集成鲁棒性进行了正式分析。大量的实验验证了异构集成在良性和对抗性环境中增强的鲁棒性。 |
| MIS-AVioDD: Modality Invariant and Specific Representation for Audio-Visual Deepfake Detection Authors Vinaya Sree Katamneni, Ajita Rattani Deepfakes 是使用深度生成算法生成的合成媒体,并构成了严重的社会和政治威胁。除了面部操纵和合成声音之外,最近还出现了一种新颖的深度伪造技术,可以操纵音频或视觉方式。在这方面,正在研究新一代多模态视听深度伪造检测器,以共同关注音频和视觉数据以进行多模态操纵检测。现有的多模态视听深度伪造检测器通常基于视频中音频和视频流的融合。现有研究表明,这些多模态检测器通常获得与单模态音频和视觉深度伪造检测器相当的性能。我们推测,音频和视频信号的异构性质造成了分布模态差距,并对有效融合和高效性能提出了重大挑战。在本文中,我们在表示级别解决这个问题,以帮助融合音频和视觉流以进行多模态深度伪造检测。具体来说,我们建议联合使用模态音频和视觉不变性和特定表示。这确保了代表原始或虚假内容的常见模式和特定于每种模态的模式被保留和融合,以用于多模态深度伪造操纵检测。我们在 FakeAVCeleb 和 KoDF 视听 Deepfake 数据集上的实验结果表明,我们提出的方法相对于 SOTA 单模态和多模态视听 Deepfake 检测器的准确度分别提高了 17.8 和 18.4。 |
| Leveraging Diffusion Disentangled Representations to Mitigate Shortcuts in Underspecified Visual Tasks Authors Luca Scimeca, Alexander Rubinstein, Armand Nicolicioiu, Damien Teney, Yoshua Bengio 数据中的虚假相关性(其中多个线索可以预测目标标签)通常会导致捷径学习现象,其中模型可能依赖于错误的、易于学习的线索,而忽略可靠的线索。在这项工作中,我们提出了一个集成多样化框架,利用扩散概率模型 DPM 生成合成反事实。我们发现 DPM 具有独立表示多个视觉线索的固有能力,即使它们在训练数据中很大程度上相关。我们利用这一特征来鼓励模型多样性,并凭经验证明该方法在几个多样化目标方面的有效性。 |
| Learnable Data Augmentation for One-Shot Unsupervised Domain Adaptation Authors Julio Ivan Davila Carrazco, Pietro Morerio, Alessio Del Bue, Vittorio Murino 本文提出了一种基于可学习数据增强的分类框架,以解决一次性无监督域适应操作系统 UDA 问题。 OS UDA 是域适应中最具挑战性的设置,因为假设只有一个未标记的目标样本可用于模型适应。在这样的单个样本的驱动下,我们的方法 LearnAug UDA 学习如何增强源数据,使其在感知上与目标数据相似。因此,在此类增强数据上训练的分类器将很好地推广到目标域。为了实现这一目标,我们设计了一种编码器解码器架构,它利用感知损失和风格转移策略来增强源数据。我们的方法在两个众所周知的域适应基准 DomainNet 和 VisDA 上实现了最先进的性能。 |
| PAD-Phys: Exploiting Physiology for Presentation Attack Detection in Face Biometrics Authors Luis F. Gomez, Julian Fierrez, Aythami Morales, Mahdi Ghafourian, Ruben Tolosana, Imanol Solano, Alejandro Garcia, Francisco Zamora Martinez 演示攻击检测 PAD 是面部识别系统中的关键阶段,以避免个人信息泄露或实体身份欺骗。 |
| SIEVE: Multimodal Dataset Pruning Using Image Captioning Models Authors Anas Mahmoud, Mostafa Elhoushi, Amro Abbas, Yu Yang, Newsha Ardalani, Hugh Leather, Ari Morcos 视觉语言模型 VLM 在大型、多样化且嘈杂的网络爬取数据集上进行了预训练。这强调了数据集修剪的迫切需要,因为这些数据集的质量与 VLM 在下游任务上的性能密切相关。使用预训练模型中的 CLIPScore 来仅训练使用高度对齐样本的模型是最成功的修剪方法之一。我们认为这种方法存在多种限制,包括 1 由于预训练 CLIP 模型捕获的虚假相关性而导致误报,2 误报由于硬样本和坏样本之间的区分不佳,以及 3 对类似于预训练 CLIP 数据集的样本的排名存在偏差,因此出现了负面结果。我们提出了一种剪枝方法 SIEVE,它采用由在小型、多样化且对齐良好的图像文本对上预训练的图像字幕模型生成的合成字幕来评估噪声图像文本对的对齐情况。为了弥合生成的标题的有限多样性和替代文本 alt text 的高度多样性之间的差距,我们估计了在数十亿个句子上预训练的语言模型的嵌入空间中的语义文本相似性。 |
| Leveraging Classic Deconvolution and Feature Extraction in Zero-Shot Image Restoration Authors Tom Chobola, Gesine M ller, Veit Dausmann, Anton Theileis, Jan Taucher, Jan Huisken, Tingying Peng 非盲反卷积的目的是在给定获得的内核的情况下从模糊的对应图像中恢复清晰的图像。现有的深度神经架构通常是基于清晰的地面实况图像的大型数据集构建的,并在监督下进行训练。然而,清晰、高质量的地面实况图像并不总是可用,特别是对于生物医学应用。这严重阻碍了当前方法在实践中的适用性。在本文中,我们提出了一种新颖的非盲反卷积方法,该方法利用深度学习和经典迭代反卷积算法的力量。我们的方法结合了预先训练的网络,通过迭代 Richardson Lucy 反卷积步骤从输入图像中提取深层特征。随后,采用零样本优化过程来集成解卷积特征,从而产生高质量的重建图像。通过使用经典的迭代反卷积方法进行初步重建,我们可以有效地利用较小的网络来生成最终图像,从而加速重建,同时减少对宝贵计算资源的需求。 |
| Point Neighborhood Embeddings Authors Pedro Hermosilla 点卷积运算依靠不同的嵌入机制对每个点的邻域信息进行编码,以检测 3D 空间中的模式。然而,由于卷积通常作为一个整体进行评估,因此没有做太多的工作来研究哪种是编码此类邻域信息的理想机制。在本文中,我们提供了第一个广泛的研究,在受控实验设置中单独分析此类点邻域嵌入 PNE。从我们的实验中,我们得出了一组 PNE 建议,有助于改进点云神经网络架构的未来设计。我们最令人惊讶的发现表明,最常用的基于具有 ReLU 激活函数的多层感知器 MLP 的嵌入在所有嵌入中提供了最低的性能,甚至在某些任务上被点坐标的简单线性组合超越。此外,我们还表明,使用基于此类嵌入的简单卷积的神经网络架构能够在多个任务上实现最先进的结果,优于最近和更复杂的操作。 |
| Content Bias in Deep Learning Age Approximation: A new Approach Towards more Explainability Authors Robert J chl, Andreas Uhl 在时间图像取证的背景下,根据不同时隙类别的图像进行训练的神经网络仅利用年龄相关的特征并不明显。通常,在时间上接近的图像(例如属于同一年龄层的图像)共享一些共同的内容属性。这种内容偏差可以被神经网络利用。在这项工作中,提出了一种评估图像内容影响的新方法。这种方法使用合成图像进行验证,其中可以通过嵌入年龄信号来排除内容偏差。基于所提出的方法,结果表明,在年龄分类背景下训练的标准神经网络强烈依赖于图像内容。 |
| Global Attractor for a Reaction-Diffusion Model Arising in Biological Dynamic in 3D Soil Structure Authors Mohamed Elghandouri, Khalil Ezzinbi, Mouad Klai, Olivier Monga 偏微分方程偏微分方程作为建模和理解复杂自然过程的工具发挥着至关重要的作用,特别是在生物学领域。这项研究探索了 3D 土壤结构复杂矩阵内微生物活动的领域,为解决方案的存在性和唯一性以及相应 PDE 模型的渐近行为提供了有价值的理解。我们的研究结果发现了全局吸引子,这是一个对长期系统行为具有重大影响的基本特征。 |
| Exploring Generalisability of Self-Distillation with No Labels for SAR-Based Vegetation Prediction Authors Laura Mart nez Ferrer, Anna Jungbluth, Joseph A. Gallego Mejia, Matt Allen, Francisco Dorr, Freddie Kalaitzis, Ra l Ramos Poll n 在这项工作中,我们使用中国、Conus、欧洲三个地区的两个合成孔径雷达数据集 S1GRD 或 GSSIC 预训练基于 DINO ViT 的模型。我们在较小的标记数据集上对模型进行微调,以预测植被百分比,并凭经验研究模型的嵌入空间与其泛化不同地理区域和未见数据的能力之间的联系。对于S1GRD,不同区域的嵌入空间明显分开,而GSSIC则重叠。微调过程中位置模式会保留,并且嵌入距离越大,通常会导致不熟悉区域出现更高的错误。 |
| An evaluation of pre-trained models for feature extraction in image classification Authors Erick da Silva Puls, Matheus V. Todescato, Joel L. Carbonera 近年来,我们见证了图像分类任务性能的显着提高。这种性能的提升主要归功于深度学习技术的采用。一般来说,深度学习技术需要大量带注释的数据,这使得将其应用于小型数据集时成为一个挑战。在这种情况下,迁移学习策略已成为克服这些问题的有希望的替代方案。这项工作旨在比较不同预训练神经网络在图像分类任务中进行特征提取的性能。我们评估了四个图像数据集中的 16 个不同的预训练模型。我们的结果表明,CLIP ViT B 和 ViT H 14 实现了数据集的最佳总体性能,其中 CLIP ResNet50 模型具有相似的性能,但变异性较小。 |
| Decoding Human Activities: Analyzing Wearable Accelerometer and Gyroscope Data for Activity Recognition Authors Utsab Saha, Sawradip Saha, Tahmid Kabir, Shaikh Anowarul Fattah, Mohammad Saquib 人的运动或相对定位有效地生成原始电信号,计算机可以读取这些信号,以应用各种操纵技术对不同的人类活动进行分类。本文提出了一种基于残差网络与残差MobileNet集成的分层多结构方法,称为FusionActNet。所提出的方法涉及使用精心设计的残差块来分别对静态和动态活动进行分类,因为它们具有将它们分开的清晰且独特的特征。这些网络经过独立训练,产生了两个专门且高度准确的模型。这些模型擅长利用架构调整的独特算法优势来识别特定超类中的活动。然后,这两个 ResNet 通过基于加权集成的 Residual MobileNet。随后,该集成能够熟练地区分特定的静态活动和特定的动态活动,这些活动是在早期阶段根据其独特的特征特征进行识别的。使用两个可公开访问的数据集(即 UCI HAR 和 Motion Sense)对所提出的模型进行评估。其中,它成功地处理了高度混乱的数据重叠情况。 |
| MUSCLE: Multi-task Self-supervised Continual Learning to Pre-train Deep Models for X-ray Images of Multiple Body Parts Authors Weibin Liao, Haoyi Xiong, Qingzhong Wang, Yan Mo, Xuhong Li, Yi Liu, Zeyu Chen, Siyu Huang, Dejing Dou 虽然自监督学习 SSL 算法已广泛用于预训练深度模型,但在使用 SSL 预训练模型改进 X 射线图像分析的表示学习方面却很少做出努力11。在这项工作中,我们研究了一种新颖的自监督预训练流程,即多任务自监督持续学习肌肉,用于多种医学成像任务,例如分类和分割,使用从多个身体部位(包括头部、肺部)收集的 X 射线图像和骨头。具体来说,MUSCLE将从多个身体部位收集的X射线聚合起来进行基于MoCo的表示学习,并采用精心设计的持续学习CL程序来进一步联合预训练骨干主体的各种X射线分析任务。图像预处理、学习计划和正则化的某些策略已用于解决 MUSCLE 中多任务数据集学习的数据异质性、过度拟合和灾难性遗忘问题。我们使用 9 个具有各种任务(包括肺炎)的真实世界 X 射线数据集来评估 MUSCLE分类、骨骼异常分类、肺分割和结核病结核病检测。 |
| Development of Machine Vision Approach for Mechanical Component Identification based on its Dimension and Pitch Authors Toshit Jain, Faisel Mushtaq, K Ramesh, Sandip Deshmukh, Tathagata Ray, Chandu Parimi, Praveen Tandon, Pramod Kumar Jha 在这项工作中,描述了一种用于机械装配线自动化的高度可定制和可扩展的基于视觉的系统。所提出的系统计算对装配线中使用的不同类型的螺栓进行分类和识别所需的特征。除了螺栓识别和计算螺栓尺寸之外,该系统还描述了一种计算螺栓螺距的新颖方法。该识别和分类系统非常轻量级,可以在最低限度的硬件上运行。该系统的速度非常快,约为毫秒,因此即使组件在传送带上稳定移动,该系统也可以成功使用。 |
| Understanding Masked Autoencoders From a Local Contrastive Perspective Authors Xiaoyu Yue, Lei Bai, Meng Wei, Jiangmiao Pang, Xihui Liu, Luping Zhou, Wanli Ouyang Masked AutoEncoder MAE 以其简单而有效的屏蔽和重建策略彻底改变了自监督学习领域。然而,尽管在各种下游视觉任务中实现了最先进的性能,但与典型的对比学习范式相比,驱动 MAE 功效的潜在机制还没有得到很好的探索。在本文中,我们探索了一个新的视角来解释什么真正有助于 MAE 内部丰富的隐藏表示。首先,关于 MAE 的生成预训练路径,利用独特的编码器解码器架构从积极的掩蔽中重建图像,我们对解码器的行为进行了深入分析。我们根据经验发现,MAE 的解码器主要学习具有有限感受野的局部特征,遵循众所周知的局部性原则。基于这种局部性假设,我们提出了一个理论框架,将基于重建的 MAE 重新表述为局部区域级别的对比学习形式,以提高理解。 |
| CoralVOS: Dataset and Benchmark for Coral Video Segmentation Authors Zheng Ziqiang, Xie Yaofeng, Liang Haixin, Yu Zhibin, Sai Kit Yeung 珊瑚礁构成了最有价值和生产力最高的海洋生态系统,为许多海洋物种提供了栖息地。珊瑚礁调查和分析目前仅限于珊瑚专家,他们投入大量精力来生成全面且可靠的报告,例如: 、珊瑚覆盖率、种群、空间分布、文本等,来自收集的调查数据。然而,基于手动工作执行密集珊瑚分析非常耗时,现有的珊瑚分析算法妥协并选择执行下采样并仅在选定的帧内进行基于稀疏点的珊瑚分析。然而,这种下采样不可避免地会引入估计偏差甚至导致错误的结果。为了解决这个问题,我们建议执行textbf密集珊瑚视频分割,不涉及下采样。通过视频对象分割,我们可以生成比现有珊瑚礁分析算法更可靠、更深入的珊瑚分析文本。为了促进这种密集珊瑚分析,我们提出了一个大规模珊瑚视频分割数据集 textbf CoralVOS,如图 1 所示。据我们所知,我们的 CoralVOS 是第一个支持密集珊瑚视频分割的数据集和基准。我们在 CoralVOS 数据集上进行了实验,其中包括 6 种最新的视频对象分割 VOS 算法。我们在 CoralVOS 数据集上对这些 VOS 算法进行了微调,并实现了可观察到的性能改进。结果表明,进一步提升分割精度仍有很大潜力。 |
| Constructing Image-Text Pair Dataset from Books Authors Yamato Okamoto, Haruto Toyonaga, Yoshihisa Ijiri, Hirokatsu Kataoka 数字归档因其在保护有价值的书籍和以电子方式向许多人提供知识方面的有效性而变得越来越普遍。在本文中,我们提出了一种利用数字档案进行机器学习的新颖方法。如果我们能够充分利用这些数字化数据,机器学习就有可能发现未知的见解并最终自主获取知识,就像人类读书一样。第一步,我们设计一个数据集构建管道,包括光学字符读取器 OCR、对象检测器和布局分析器,用于自主提取图像文本对。 |
| MarineDet: Towards Open-Marine Object Detection Authors Liang Haixin, Zheng Ziqiang, Ma Zeyu, Sai Kit Yeung 由于迫切需要解开海洋之谜并增强我们对宝贵的海洋生态系统的了解,海洋物体检测在海洋研究中占据了重要地位。迫切需要有效、准确地识别和定位水下图像中各种看不见的海洋实体。开放式海洋物体检测 OMOD(简称 OMOD)需要检测各种不可见的海洋物体,同时进行分类和定位。为了实现 OMOD,我们提出了 textbf MarineDet 。我们通过预训练制定联合视觉文本语义空间,然后进行海洋特定训练,以实现空中到海洋的知识转移。考虑到没有为 OMOD 设计的特定数据集,我们构建了一个包含 821 个海洋相关对象类别的 textbf MarineDet 数据集,以提升和衡量 OMOD 性能。实验结果证明了 MarineDet 比现有的通用和专业对象检测算法具有优越的性能。据我们所知,我们是第一个推出 OMOD 的公司,它为海洋生态系统监测和管理提供了更有价值和更实用的环境。 |
| DARTH: Holistic Test-time Adaptation for Multiple Object Tracking Authors Mattia Segu, Bernt Schiele, Fisher Yu 多目标跟踪 MOT 是自动驾驶感知系统的基本组成部分,其对未见条件的鲁棒性是避免生命攸关的故障的必要条件。尽管迫切需要驾驶系统的安全性,但尚未提出针对测试时间条件下域转移的 MOT 适应问题的解决方案。然而,MOT 系统的本质是多方面的,需要对象检测和实例关联,并且调整其所有组件并非易事。在本文中,我们分析了域转移对基于外观的跟踪器的影响,并介绍了 DARTH,一种用于 MOT 的整体测试时间适应框架。我们提出了一种检测一致性公式,以自我监督的方式适应对象检测,同时通过我们新颖的补丁对比损失来调整实例外观表示。我们在各种域转换上评估我们的方法,包括模拟到真实、室外到室内、室内到室外,并显着提高源模型在所有指标上的性能。 |
| RoFormer for Position Aware Multiple Instance Learning in Whole Slide Image Classification Authors Etienne Pochet, Rami Maroun, Roger Trullo 整个幻灯片图像 WSI 分类是计算病理学中的一项关键任务。然而,此类图像的十亿像素大小仍然是深度学习当前状态的主要挑战。当前的方法依赖于具有冻结特征提取器的多实例学习 MIL 模型。鉴于每幅图像中的实例数量较多,MIL 方法长期以来一直假设斑块的独立性和排列不变性,而忽略斑块之间的组织结构和相关性。最近的工作开始研究实例之间的这种相关性,但如此大量令牌的计算工作量仍然是一个限制因素。特别是,补丁的相对位置仍未得到解决。我们建议应用一个简单的编码模块,即 RoFormer 层,依赖于内存高效的精确自注意力和相对位置编码。该模块可以通过对大型且任意形状的 WSI 块进行相对位置编码来执行完全自注意力,解决实例与组织空间建模之间的相关性需求。我们证明,在弱监督分类任务上,我们的方法在三个常用公共数据集 TCGA NSCLC、BRACS 和 Camelyon16 上的性能优于最先进的 MIL 模型。 |
| Beyond the Benchmark: Detecting Diverse Anomalies in Videos Authors Yoav Arad, Michael Werman 视频异常检测 VAD 在现代监控系统中发挥着至关重要的作用,旨在识别现实世界中的各种异常情况。然而,当前的基准数据集主要强调简单的单帧异常,例如新物体检测。这种狭隘的关注限制了 VAD 模型的进步。在这项研究中,我们主张扩大 VAD 调查范围,以涵盖超出传统基准边界的复杂异常情况。为了促进这一点,我们引入了两个数据集:HMDB AD 和 HMDB Violence,以挑战具有不同基于动作的异常的模型。这些数据集源自 HMDB51 动作识别数据集。我们进一步提出了多帧异常检测 MFAD,这是一种基于 AI VAD 框架的新颖方法。 AI VAD 利用姿态估计和深度图像编码等单帧特征,以及物体速度等两帧特征。然后,他们应用密度估计算法来计算异常分数。为了解决复杂的多帧异常,我们添加了捕获长范围时间依赖性的深度视频编码功能,以及逻辑回归来增强最终分数计算。实验结果证实了我们的假设,强调了现有模型对新异常类型的局限性。 |
| MFOS: Model-Free & One-Shot Object Pose Estimation Authors JongMin Lee, Yohann Cabon, Romain Br gier, Sungjoo Yoo, Jerome Revaud 现有的基于学习的 RGB 图像中物体姿态估计方法大多是特定于模型或基于类别的。它们缺乏在测试时泛化到新对象类别的能力,因此严重阻碍了它们的实用性和可扩展性。值得注意的是,最近已经尝试解决这个问题,但它们仍然需要训练和测试时物体表面的准确 3D 数据。在本文中,我们介绍了一种新颖的方法,可以在给定最小输入的情况下,在一次前向传递中估计训练期间从未见过的物体的姿势。与依赖于任务特定模块的现有最先进方法相比,我们提出的模型完全基于 Transformer 架构,该架构可以受益于最近提出的 3D 几何通用预训练。我们进行了大量的实验,并在具有挑战性的 LINEMOD 基准测试中报告了最先进的一次性性能。 |
| Adaptive Multi-NeRF: Exploit Efficient Parallelism in Adaptive Multiple Scale Neural Radiance Field Rendering Authors Tong Wang, Shuichi Kurabayashi 神经辐射场 NeRF 的最新进展已经证明了将 3D 场景外观表示为隐式神经网络的巨大潜力,从而能够合成高保真新颖的视图。然而,冗长的训练和渲染过程阻碍了这种有前景的技术在实时渲染应用中的广泛采用。 |
| A Dual Attentive Generative Adversarial Network for Remote Sensing Image Change Detection Authors Luyi Qiu, Xiaofeng Zhang, ChaoChen Gu, and ShanYing Zhu 双时态图像之间的遥感变化检测越来越受到研究人员的关注。然而,比较两个双时图像来检测变化是具有挑战性的,因为它们表现出不同的外观。在本文中,我们提出了一种用于实现超高分辨率遥感图像变化检测任务的双注意力生成对抗网络,该网络将检测模型视为生成器,并通过以下方式在不增加检测模型参数的情况下获得检测模型的最优权重:生成对抗策略,提高预测的空间连续性。此外,我们设计了一种有效融合多级特征的多级特征提取器,它采用预先训练的模型从双向图像中提取多级特征,并引入聚合连接来融合它们。为了加强对多尺度对象的识别,我们提出了一种多尺度自适应融合模块,通过各种感受野自适应地融合多尺度特征,并设计了一个上下文细化模块来探索上下文依赖性。此外,DAGAN框架利用4层卷积网络作为鉴别器来识别合成图像是假的还是真实的。 |
| LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment Authors Bin Zhu, Bin Lin, Munan Ning, Yang Yan, Jiaxi Cui, Wang HongFa, Yatian Pang, Wenhao Jiang, Junwu Zhang, Zongwei Li, Cai Wan Zhang, Zhifeng Li, Wei Liu, Li Yuan 视频语言VL预训练在多个下游任务中取得了显着的改进。然而,当前的 VL 预训练框架很难扩展到视觉和语言之外的多种模态 N 模态、N 3 。因此,我们提出LanguageBind,将语言作为不同模态之间的绑定,因为语言模态已经得到很好的探索并且包含丰富的语义。具体来说,我们冻结通过 VL 预训练获得的语言编码器,然后通过对比学习来训练其他模式的编码器。因此,所有模态都映射到共享特征空间,实现多模态语义对齐。虽然 LanguageBind 确保我们可以将 VL 模态扩展到 N 模态,但我们还需要一个高质量的数据集,其中包含以语言为中心的对齐数据对。因此我们提出VIDAL 10M,带有Video、Infrared、Depth、Audio及其相应的Language,命名为VIDAL 10M。在我们的VIDAL 10M中,所有视频都来自具有完整语义的短视频平台,而不是长视频的截断片段,并且所有视频、深度、红外和音频模态都与其文本描述一致。在 VIDAL 10M 上进行预训练后,我们在 MSR VTT 数据集上的性能优于 ImageBind 1.2 R 1,在零镜头视频文本检索中仅使用 15 个参数,验证了我们数据集的高质量。除此之外,我们的 LanguageBind 在零镜头视频、音频、深度和红外理解任务上取得了巨大的进步。 |
| Zero-Shot Refinement of Buildings' Segmentation Models using SAM Authors Ali Mayladan, Hasan Nasrallah, Hasan Moughnieh, Mustafa Shukor, Ali J. Ghandour 基础模型在各种任务中表现出色,但通常根据一般基准进行评估。这些模型针对特定领域(例如遥感图像)的适应仍然是一个尚未充分探索的领域。在遥感中,精确的建筑实例分割对于城市规划等应用至关重要。虽然卷积神经网络 CNN 表现良好,但其泛化能力可能有限。为此,我们提出了一种新颖的方法来调整基础模型,以解决现有模型泛化下降的问题。在多个模型中,我们的重点是 Segment Anything Model SAM,这是一个强大的基础模型,以其在类无关图像分割功能方面的实力而闻名。我们首先确定 SAM 的局限性,揭示其应用于遥感图像时的次优性能。此外,SAM 不提供识别能力,因此无法对本地对象进行分类和标记。为了解决这些限制,我们引入了不同的提示策略,包括集成预先训练的 CNN 作为提示生成器。这种新颖的方法增强了 SAM 的识别能力,这在同类方法中尚属首次。我们在三个遥感数据集上评估了我们的方法,包括 WHU 建筑数据集、马萨诸塞州建筑数据集和 AICrowd 测绘挑战赛。对于 WHU 数据集上的分布性能,我们的 IoU 提高了 5.47,F1 分数提高了 4.81。对于 WHU 数据集的分布性能,我们观察到 True Positive IoU 和 True Positive F1 分数分别增加了 2.72 和 1.58。 |
| Selective Feature Adapter for Dense Vision Transformers Authors Xueqing Deng, Qi Fan, Xiaojie Jin, Linjie Yang, Peng Wang 微调预训练的 Transformer 模型(例如 Swin Transformer)在众多下游密集预测视觉任务中取得了成功。然而,一个主要问题是大量参数的存储成本,随着视觉任务数量的不断增加,处理这一问题变得越来越具有挑战性。在本文中,我们提出了一种有效的方法来缓解该问题,即选择性特征适配器 SFA 。它在任何给定的可训练参数预算下实现了最先进的 SoTA 性能,并且在各种密集任务中表现出与完全微调的模型相当或更好的性能。具体来说,SFA 由外部适配器和内部适配器组成,它们在变压器模型上顺序运行。对于外部适配器,我们适当选择附加多层感知 MLP 的位置和数量。对于内部适配器,我们在变压器内部转换一些任务重要参数,这些参数是通过简单而有效的彩票算法自动发现的。 |
| SelfGraphVQA: A Self-Supervised Graph Neural Network for Scene-based Question Answering Authors Bruno Souza, Marius Aasan, Helio Pedrini, Ad n Ram rez Rivera 由于人们越来越关注识别和推理之间的无缝集成,视觉和语言的交叉引起了人们的极大兴趣。场景图 SG 已成为多模态图像分析的有用工具,在视觉问答 VQA 等任务中显示出令人印象深刻的性能。在这项工作中,我们证明了尽管场景图在 VQA 任务中很有效,但当前使用理想化注释场景图的方法在使用从图像中提取的预测场景图时很难泛化。为了解决这个问题,我们引入了 SelfGraphVQA 框架。我们的方法使用预先训练的场景图生成器从输入图像中提取场景图,并通过自监督技术采用语义保留增强。该方法避免了对昂贵且可能有偏见的注释数据的需求,从而提高了 VQA 任务中图形表示的利用率。通过图像增强创建提取图的替代视图,我们可以使用非标准化对比方法优化其表示中的信息内容来学习联合嵌入。当我们使用 SG 时,我们尝试了三种不同的最大化策略:节点方式、图方式和排列等变正则化。我们凭经验展示了提取的 VQA 场景图的有效性,并证明这些方法通过突出视觉信息的重要性来提高整体性能。 |
| Self-Supervised High Dynamic Range Imaging with Multi-Exposure Images in Dynamic Scenes Authors Zhilu Zhang, Haoyu Wang, Shuai Liu, Xiaotao Wang, Lei Lei, Wangmeng Zuo 合并多重曝光图像是获得高动态范围 HDR 图像的常用方法,主要挑战是避免动态场景中的重影伪影。最近的方法提出使用深度神经网络来消除重影。然而,这些方法通常依赖于具有 HDR 基本事实的足够数据,而收集这些数据既困难又昂贵。在这项工作中,为了消除对标记数据的需求,我们提出了 SelfHDR,一种自监督 HDR 重建方法,在训练过程中只需要动态多曝光图像。具体来说,SelfHDR 在两个互补组件的监督下学习重建网络,这两个组件可以根据多曝光图像构建,并分别关注 HDR 颜色和结构。颜色分量是根据对齐的多曝光图像估计的,而结构分量是通过结构聚焦网络生成的,该网络由颜色分量和输入参考(例如中等曝光图像)监督。在测试过程中,直接部署学习到的重建网络来预测 HDR 图像。对现实世界图像的实验表明,我们的 SelfHDR 相对于最先进的自监督方法取得了优异的结果,并且性能与监督方法相当。 |
| Extending CAM-based XAI methods for Remote Sensing Imagery Segmentation Authors Abdul Karim Gizzini, Mustafa Shukor, Ali J. Ghandour 当前基于人工智能的方法无法对所使用的数据、提取的特征和预测推理操作提供可理解的物理解释。因此,使用高分辨率卫星图像训练的深度学习模型缺乏透明度和可解释性,只能被视为黑匣子,这限制了其广泛采用。专家需要帮助理解人工智能模型的复杂行为和底层决策过程。可解释的人工智能XAI领域是一个新兴领域,为人工智能模型的稳健、实用和值得信赖的部署提供了手段。已经提出了几种用于图像分类任务的 XAI 技术,而图像分割的解释在很大程度上仍未得到探索。本文通过采用最新的 XAI 分类算法并使它们可用于多类图像分割来弥补这一差距,其中我们主要关注高分辨率卫星图像的建筑物分割。为了对所提出的方法的性能进行基准测试和比较,我们引入了一种新的 XAI 评估方法和基于熵的指标来测量模型的不确定性。传统的XAI评估方法主要依赖于将图像中感兴趣区域的面积反馈给预先训练的效用模型,然后计算目标类别概率的平均变化。这些评估指标缺乏所需的鲁棒性,我们表明使用熵来监控目标类内像素分割的模型不确定性更合适。 |
| Skin the sheep not only once: Reusing Various Depth Datasets to Drive the Learning of Optical Flow Authors Sheng Chi Huang, Wei Chen Chiu 光流估计对于视觉和机器人领域的各种应用至关重要。由于在现实场景中收集真实光流的困难,大多数现有的学习光流的方法仍然采用合成数据集进行监督训练或利用时间相邻视频帧之间的光度一致性来驱动无监督学习,其中前者通常具有普遍性问题,而后者通常比受监督的表现更差。为了应对这些挑战,我们建议利用光流估计和立体匹配之间的几何联系,基于发现图像之间像素对应关系的相似性,以统一各种现实世界深度估计数据集,从而根据光流生成监督训练数据。具体来说,我们通过合成虚拟视差将单目深度数据集转换为立体数据集,从而产生沿水平方向的流,此外,我们将虚拟相机运动引入立体数据中以产生沿垂直方向的附加流。此外,我们建议对光流对的一张图像应用几何增强,鼓励光流估计器从更具挑战性的情况中学习。最后,由于不同几何增强下的光流图实际上表现出不同的特征,因此利用辅助分类器来训练以根据流图的外观识别增强类型,以进一步增强光流估计器的学习。 |
| AI-Generated Images as Data Source: The Dawn of Synthetic Era Authors Zuhao Yang, Fangneng Zhan, Kunhao Liu, Muyu Xu, Shijian Lu 视觉智能的进步本质上与数据的可用性有关。与此同时,生成人工智能 AI 释放了创建与现实世界照片非常相似的合成图像的潜力,这引发了人们对视觉智能如何从生成人工智能的进步中受益的令人信服的探究本文探讨了利用这些人工智能生成的图像的创新概念一个新的数据源,重塑视觉智能中的传统模型范式。与真实数据相比,人工智能生成的数据源表现出显着的优势,包括无与伦比的丰富性和可扩展性、快速生成海量数据集以及轻松模拟边缘情况。基于生成式人工智能模型的成功,我们研究了生成的数据在一系列应用中的潜力,从训练机器学习模型到模拟计算建模、测试和验证的场景。我们探讨了支持生成式人工智能这一突破性应用的技术基础,并对伴随这一变革性范式转变的伦理、法律和实践考虑因素进行了深入讨论。通过对当前技术和应用的详尽调查,本文对视觉智能的合成时代提出了全面的看法。 |
| Trainable Noise Model as an XAI evaluation method: application on Sobol for remote sensing image segmentation Authors Hossein Shreim, Abdul Karim Gizzini, Ali J. Ghandour eXplainable 人工智能 XAI 已成为处理关键任务应用程序时的基本要求,确保所使用的黑盒 AI 模型的透明度和可解释性。 XAI 的重要性涵盖从医疗保健到金融的各个领域,了解深度学习算法的决策过程至关重要。大多数基于人工智能的计算机视觉模型通常都是黑匣子,因此,在图像处理中提供深度神经网络的可解释性对于其在医学图像分析、自动驾驶和遥感应用中的广泛采用和部署至关重要。最近,已经推出了几种用于图像分类任务的 XAI 方法。相反,图像分割在可解释性方面受到的关注相对较少,尽管它是计算机视觉应用(尤其是遥感)中的一项基本任务。只有一些研究提出了基于梯度的 XAI 算法用于图像分割。本文采用最新的无梯度 Sobol XAI 方法进行语义分割。为了衡量 Sobol 分割方法的性能,我们提出了一种基于可学习噪声模型的定量 XAI 评估方法。该模型的主要目标是在解释图上引入噪声,其中较高的引入噪声意味着较低的精度,反之亦然。使用所提出的基于噪声的评估技术进行基准分析来评估和比较三种 XAI 方法的性能,包括 Seg Grad CAM、Seg Grad CAM 和 Seg Sobol。 |
| Empirical Study of PEFT techniques for Winter Wheat Segmentation Authors Mohamad Hasan Zahweh, Hasan Nasrallah, Mustafa Shukor, Ghaleb Faour, Ali J. Ghandour 参数高效微调 PEFT 技术最近经历了显着增长,并已被广泛应用于使大型视觉和语言模型适应各个领域,以最少的计算需求实现令人满意的模型性能。尽管取得了这些进展,但更多的研究尚未深入探讨 PEFT 在现实生活场景中的潜在应用,特别是在遥感和作物监测的关键领域。不同地区气候的多样性以及对全面的大规模数据集的需求,为准确识别不同地理位置和不断变化的生长季节的作物类型带来了重大障碍。本研究旨在通过使用最先进的 SOTA 小麦作物监测模型全面探索跨地区和跨年份分布概括的可行性来弥补这一差距。这项工作的目的是探索作物监测的 PEFT 方法。具体来说,我们专注于采用 SOTA TSViT 模型来解决冬小麦田分割问题,这是作物监测和粮食安全的一项关键任务。此适应过程涉及集成不同的 PEFT 技术,包括 BigFit、LoRA、Adaptformer 和提示调整。使用 PEFT 技术,我们取得了与使用完全微调方法所取得的结果相当的显着结果,同时仅训练整个 TSViT 架构的 0.7 个参数。内部标记数据集(称为 Beqaa Lebanon 数据集)包含连续五年的小麦和非小麦类别的高质量注释多边形,总面积为 170 平方公里。使用 Sentinel 2 图像,我们的模型获得了 84 F1 分数。 |
| MIMO-NeRF: Fast Neural Rendering with Multi-input Multi-output Neural Radiance Fields Authors Takuhiro Kaneko 神经辐射场 NeRF 在新颖的视图合成方面显示出了令人印象深刻的结果。然而,它们依赖于重复使用单输入单输出多层感知器 SISO MLP,该感知器以样本方式将 3D 坐标和视图方向映射到颜色和体积密度,这会减慢渲染速度。我们提出了一种多输入多输出 NeRF MIMO NeRF,它通过用 MIMO MLP 替换 SISO MLP 并以分组方式进行映射来减少运行的 MLP 数量。这种方法的一个显着挑战是,每个点的颜色和体积密度可能会根据组中输入坐标的选择而有所不同,这可能会导致一些明显的模糊性。我们还提出了一种自监督学习方法,该方法使用多个快速重构的 MLP 来规范 MIMO MLP,以在不使用预训练模型的情况下减轻这种模糊性。包括比较和消融研究在内的综合实验评估结果表明,MIMO NeRF 在合理的训练时间下在速度和质量之间取得了良好的平衡。 |
| Amazing Combinatorial Creation: Acceptable Swap-Sampling for Text-to-Image Generation Authors Jun Li, Zedong Zhang, Jian Yang 探索机器学习系统从多个文本描述生成有意义的组合对象图像,模拟人类创造力,是一项重大挑战,因为人类能够构建令人惊叹的组合对象,但机器努力模拟数据分布。在本文中,我们开发了一种简单而高效的技术,称为可接受的交换采样,利用不同对象的文本概念来生成表现出新颖性和惊喜的组合对象图像。最初,我们提出了一种交换机制,通过交换两个文本嵌入的列向量来构造新颖的嵌入,从而通过前沿扩散模型生成新的组合图像。此外,我们通过管理新图像和原始概念生成之间合适的 CLIP 距离来设计可接受的区域,从而增加接受具有高质量组合的新图像的可能性。该区域允许我们从使用随机交换列向量生成的新图像池中有效地采样一小部分。最后,我们采用分割方法来比较分割组件之间的 CLIP 距离,最终从采样子集中选择最有希望的目标图像。我们的实验集中于 ImageNet 中的对象文本对,我们的结果表明,我们的方法在生成新颖且令人惊讶的对象图像方面优于最新的方法,例如 Stable Diffusion2、DALLE2、ERNIE ViLG2 和 Bing,即使相关概念似乎难以置信,例如狮子鱼算盘。 |
| PPT: Token Pruning and Pooling for Efficient Vision Transformers Authors Xinjian Wu, Fanhu Zeng, Xiudong Wang, Yunhe Wang, Xinghao Chen Vision Transformers ViT 已成为计算机视觉领域的强大模型,在各种视觉任务中提供卓越的性能。然而,高计算复杂度对其在现实世界场景中的实际应用构成了重大障碍。由于并非所有令牌对最终预测的贡献均等,并且较少的令牌带来的计算成本较低,因此减少冗余令牌已成为加速视觉变换器的流行范例。然而,我们认为仅通过令牌修剪来减少疏忽冗余或仅通过令牌合并来减少重复冗余并不是最佳选择。为此,在本文中,我们提出了一种新颖的加速框架,即 token Pruning Pooling Transformers PPT ,以自适应地解决不同层中的这两类冗余。通过在 ViT 中启发式地集成令牌剪枝和令牌池技术,无需额外的可训练参数,PPT 有效降低了模型复杂性,同时保持了其预测准确性。 |
| Improvement and Enhancement of YOLOv5 Small Target Recognition Based on Multi-module Optimization Authors Qingyang Li, Yuchen Li, Hongyi Duan, JiaLiang Kang, Jianan Zhang, Xueqian Gan, Ruotong Xu 本文对YOLOv5s模型在小目标检测任务上的局限性进行了深入研究和改进。通过引入基于 GhostNet 的卷积模块、基于 RepGFPN 的 Neck 模块优化、CA 和 Transformer 的注意力机制以及使用 NWD 的损失函数改进,成功增强了模型的性能。实验结果验证了这些改进策略对模型精度、召回率和 mAP 的积极影响。特别是,改进后的模型在现实应用测试中处理复杂背景和微小目标时表现出显着的优越性。 |
| HallE-Switch: Rethinking and Controlling Object Existence Hallucinations in Large Vision Language Models for Detailed Caption Authors Bohan Zhai, Shijia Yang, Xiangchen Zhao, Chenfeng Xu, Sheng Shen, Dongdi Zhao, Kurt Keutzer, Manling Li, Tan Yan, Xiangjun Fan 当前的大型视觉语言模型 LVLM 取得了显着的进步,但其准确理解视觉细节(即执行详细字幕)的能力仍然存在很大的不确定性。为了解决这个问题,我们引入了 textit CCEval,这是一种专为详细字幕定制的 GPT 4 辅助评估方法。有趣的是,虽然 LVLM 在现有 VQA 基准中表现出最小的物体存在幻觉,但我们提出的评估揭示了对此类幻觉的持续敏感性。在本文中,我们首次尝试调查和归因此类幻觉,包括图像分辨率、语言解码器大小以及指令数据量、质量、粒度。我们的研究结果强调了当语言描述包含比视觉模块可以接地或验证的更精细的对象粒度的细节时,会出现无根据的推断,从而引发幻觉。为了控制这种幻觉,我们进一步将字幕的可靠性归因于仅涉及上下文基础对象的上下文知识和包含模型推断对象的参数知识。因此,我们引入了 textit HallE Switch ,这是一种根据对象 textbf 存在中的 textbf Hall ucination 的可控 LVLM。 HallE Switch 可以调节字幕在专门描述接地对象的上下文知识和将其与参数知识混合以想象推断对象之间切换。 |
| ImageNet-OOD: Deciphering Modern Out-of-Distribution Detection Algorithms Authors William Yang, Byron Zhang, Olga Russakovsky 众所周知,分布外 OOD 检测的任务定义不明确。早期的工作侧重于新类别检测,旨在识别改变标签的数据分布变化,也称为语义变化。然而,最近的工作主张关注故障检测,扩展 OOD 评估框架以考虑标签保留数据分布变化(也称为协变量变化)。有趣的是,在这个新框架下,以前被认为是最先进的复杂 OOD 检测器现在的表现与简单的最大 softmax 概率基线相似,甚至更差。这就提出了一个问题:最新的 OOD 检测器实际检测的是什么?破译 OOD 检测算法的行为需要能够解耦语义转移和协变量转移的评估数据集。为了帮助我们的研究,我们提出了 ImageNet OOD,这是一个干净的语义偏移数据集,可以最大限度地减少协变量偏移的干扰。通过综合实验,我们表明 OOD 检测器对协变量移位比语义移位更敏感,并且最近的 OOD 检测算法在语义移位检测上的好处微乎其微。 |
| Learning Expected Appearances for Intraoperative Registration during Neurosurgery Authors Nazim Haouchine, Reuben Dorent, Parikshit Juvekar, Erickson Torio, William M. Wells III, Tina Kapur, Alexandra J. Golby, Sarah Frisken 我们提出了一种术中患者通过学习预期外观进行图像配准的新方法。我们的方法使用术前成像通过手术显微镜合成患者特定的预期视图,以预测转换范围。我们的方法通过最小化通过光学显微镜的术中 2D 视图与合成的预期纹理之间的差异来估计相机姿态。与传统方法相比,我们的方法将处理任务转移到术前阶段,从而减少了低分辨率、扭曲和噪声的术中图像的影响,这些图像通常会降低配准精度。我们将我们的方法应用于脑部手术期间的神经导航。我们根据 6 个临床病例的综合数据和回顾性数据评估了我们的方法。 |
| Transcending Domains through Text-to-Image Diffusion: A Source-Free Approach to Domain Adaptation Authors Shivang Chopra, Suraj Kothawade, Houda Aynaou, Aman Chadha 域适应 DA 是一种通过应用模型从具有足够标记数据的相关源域获取的信息来增强模型在注释数据不足的目标域上的性能的方法。 HIPAA、COPPA、FERPA 等数据隐私法规的不断加强,引发了人们对使模型适应新领域、同时避免直接访问源数据的需求的浓厚兴趣,这一问题被称为“无源域适应 SFDA”。在本文中,我们为 SFDA 提出了一种新颖的框架,该框架使用在目标域样本上训练的文本到图像扩散模型来生成源数据。我们的方法首先在标记的目标域样本上训练文本到图像扩散模型,然后使用预先训练的源模型进行微调以生成接近源数据的样本。最后,我们使用域适应技术将人工生成的源数据与目标域数据对齐,从而显着提高模型在目标域上的性能。 |
| Keypoint-Augmented Self-Supervised Learning for Medical Image Segmentation with Limited Annotation Authors Zhangsihao Yang, Mengwei Ren, Kaize Ding, Guido Gerig, Yalin Wang 通过自我监督预训练 CNN 模型(即 UNet)已成为在低注释条件下促进医学图像分割的强大方法。最近的对比学习方法在同一图像经历不同的变换时鼓励相似的全局表示,或者在本质上相关的不同图像块特征之间强制不变性。然而,CNN 提取的全局和局部特征在捕获生物解剖学中至关重要的长距离空间依赖性方面受到限制。为此,我们提出了一个关键点增强融合层,它提取保留短期和长期自注意力的表示。特别是,我们通过合并额外的输入来在多个尺度上增强 CNN 特征图,该输入可以学习局部关键点特征之间的远程空间自注意力。此外,我们为该框架引入了全局和本地自我监督预训练。在全局尺度上,我们从 UNet 的瓶颈中获取全局表示,并通过聚合多尺度关键点特征来获得全局表示。随后通过图像级对比目标对这些全局特征进行正则化。在局部尺度上,我们定义了一个基于距离的标准,首先建立关键点之间的对应关系并鼓励它们的特征之间的相似性。通过对 MRI 和 CT 分割任务的大量实验,当所有架构都使用随机初始化的权重进行训练时,我们展示了我们提出的方法与基于 CNN 和 Transformer 的 UNet 相比的架构优势。通过我们提出的预训练策略,我们的方法通过产生更强大的自注意力并实现最先进的分割结果,进一步优于现有的 SSL 方法。 |
| STARS: Zero-shot Sim-to-Real Transfer for Segmentation of Shipwrecks in Sonar Imagery Authors Advaith Venkatramanan Sethuraman, Katherine A. Skinner 在本文中,我们解决了当训练期间无法访问感兴趣对象的真实示例时用于对象分割的模拟到真实迁移的问题,即用于分割的零样本模拟到真实迁移。我们重点关注沉船分割在侧扫声纳图像中的应用。我们新颖的分割网络 STARS 通过融合预测的变形场和异常体积来解决这一挑战,使其能够更好地推广到真实的声纳图像,并实现更有效的零样本模拟到真实图像分割的传输。我们在真实的、专家标记的沉船侧扫声纳数据集上评估了我们的方法的模拟到真实的传输能力,该数据集是通过自主水下航行器 AUV 的现场工作调查收集的。 STARS 完全在模拟中进行训练,并执行零样本沉船分割,无需对实际数据进行额外的微调。 |
| Task-guided Domain Gap Reduction for Monocular Depth Prediction in Endoscopy Authors Anita Rau, Binod Bhattarai, Lourdes Agapito, Danail Stoyanov 结直肠癌仍然是世界上最致命的癌症之一。近年来,计算机辅助方法旨在通过自动化子任务来加强癌症筛查并提高结肠镜检查的质量和可用性。其中一项任务是从单目视频帧预测深度,这可以帮助内窥镜导航。由于硬件限制,标准体内结肠镜检查的地面真实深度仍然无法获得,因此有两种方法旨在规避对在标记合成数据上训练的真实训练数据监督方法和在未标记真实数据上训练的自监督模型的需求。然而,自监督方法依赖于不可靠的损失函数,这些函数会与边缘、自遮挡和照明不一致等问题作斗争。在合成数据上训练的方法可以为合成几何提供准确的深度,但不使用来自真实数据的任何几何监控信号,并且对合成解剖结构和属性过度拟合。这项工作提出了一种利用标记合成数据和未标记真实数据的新方法。虽然以前的域适应方法不加区别地强制两个输入数据模态的分布一致,但我们专注于最终任务,深度预测,并仅转换输入域之间的基本信息。 |
| SYRAC: Synthesize, Rank, and Count Authors Adriano D Alessandro, Ali Mahdavi Amiri, Ghassan Hamarneh 人群计数是计算机视觉中的一项关键任务,有几个重要的应用。然而,现有的计数方法依赖于劳动密集型的密度图注释,需要手动定位每个行人。虽然最近的努力试图通过弱监督或半监督学习来减轻注释负担,但这些方法无法显着减少工作量。我们提出了一种新方法,通过利用潜在扩散模型生成合成数据来消除注释负担。然而,这些模型很难可靠地理解对象数量,当提示生成具有特定数量对象的图像时,会导致噪声注释。为了解决这个问题,我们使用潜在扩散模型来创建两种类型的合成数据,一种是通过从真实图像中删除行人,生成具有微弱但可靠的对象数量信号的排名图像对,另一种是通过生成具有预定数量的合成图像。物体,提供强烈但嘈杂的计数信号。我们的方法利用排名图像对进行预训练,然后使用这些人群数量特征将线性层拟合到噪声合成图像。 |
| It's all about you: Personalized in-Vehicle Gesture Recognition with a Time-of-Flight Camera Authors Amr Gomaa, Guillermo Reyes, Michael Feld 尽管手势识别技术取得了显着进步,但由于数据有限且昂贵,而且其动态、不断变化的性质,在驾驶环境中识别手势仍然具有挑战性。在这项工作中,我们提出了一种模型适应方法来个性化 CNNLSTM 模型的训练并提高识别准确性,同时减少数据需求。我们的方法通过提供一种可以为个人用户定制的更高效、更准确的方法,为驾驶时动态手势识别领域做出贡献,最终增强车辆交互的安全性和便利性,以及驾驶员的体验和系统信任。我们将使用飞行时间相机的硬件增强和通过数据增强、个性化适应和增量学习技术的算法增强结合起来。 |
| You Only Look at Once for Real-time and Generic Multi-Task Authors Jiayuan Wang, Q. M. Jonathan Wu, Ning Zhang 高精度、轻量化、实时响应是实现自动驾驶的三个基本要求。同时考虑所有这些是一个挑战。在本研究中,我们提出了一种自适应、实时、轻量级的多任务模型,旨在同时处理对象检测、可行驶区域分割和车道检测任务。为了实现这一研究目标,我们开发了一种具有统一且精简的分割结构的端到端多任务模型。我们的模型无需任何特定的定制结构或损失函数即可运行。我们在 BDD100k 数据集上取得了有竞争力的结果,特别是在可视化结果方面。性能结果显示,目标检测的 mAP50 为 81.1,可行驶区域分割的 mIoU 为 91.0,车道线分割的 IoU 为 28.8。此外,我们引入了真实道路数据集来评估我们的模型在真实场景中的性能,其性能显着优于竞争对手。这表明我们的模型不仅表现出有竞争力的性能,而且比现有的多任务模型更灵活、更快。 |
| Adaptive Visual Scene Understanding: Incremental Scene Graph Generation Authors Naitik Khandelwal, Xiao Liu, Mengmi Zhang 场景图生成 SGG 涉及分析图像以提取有关对象及其关系的有意义的信息。鉴于视觉世界的动态本质,人工智能系统检测新对象并与现有对象建立新关系变得至关重要。为了解决 SGG 缺乏持续学习方法的问题,我们引入了全面的持续场景图生成 CSEGG 数据集以及 3 个学习场景和 8 个评估指标。我们的研究调查了现有 SGG 方法在学习新对象实体和关系时保留先前对象实体和关系的持续学习性能。此外,我们还探讨了连续对象检测如何增强对未知对象的已知关系进行分类的泛化能力。我们在持续学习环境中对经典的两阶段 SGG 方法和最新的基于 Transformer 的 SGG 方法进行了广泛的基准测试和分析实验,并获得了对 CSEGG 问题的宝贵见解。 |
| Dynamic Spatio-Temporal Summarization using Information Based Fusion Authors Humayra Tasnim, Soumya Dutta, Melanie Moses 在数据生成蓬勃发展的时代,管理和存储大规模时变数据集提出了重大挑战。随着超级计算能力的崛起,产生的数据量猛增,导致存储和 I O 开销加剧。为了解决这个问题,我们提出了一种动态时空数据摘要技术,该技术可以识别关键时间步长中的信息丰富的特征并融合信息较少的特征。这种方法最大限度地减少了存储需求,同时保留了数据动态。与现有方法不同,我们的方法保留了原始时间步长和汇总时间步长,确保全面了解信息随时间的变化。我们利用信息论方法来指导融合过程,从而产生捕获基本数据模式的视觉表示。我们展示了我们的技术在不同数据集上的多功能性,包括基于粒子的流动模拟、安全和监视应用以及免疫系统内的生物细胞相互作用。我们的研究为数据管理领域做出了重大贡献,在不同的多学科领域引入了更高的效率和更深入的见解。我们提供了一种处理大量数据集的简化方法,可应用于现场分析和事后分析。这不仅解决了数据存储和 I O 开销不断升级的挑战,而且还释放了做出明智决策的潜力。 |
| ImagenHub: Standardizing the evaluation of conditional image generation models Authors Max Ku, Tianle Li, Kai Zhang, Yujie Lu, Xingyu Fu, Wenwen Zhuang, Wenhu Chen 最近,已经开发了无数的条件图像生成和编辑模型来服务不同的下游任务,包括文本到图像生成、文本引导图像编辑、主题驱动图像生成、控制引导图像生成等。然而,我们观察到巨大的不一致实验条件、数据集、推理和评估指标使得公平比较变得困难。本文提出了 ImagenHub,它是一个一站式库,用于标准化所有条件图像生成模型的推理和评估。首先,我们定义了七个突出任务并为它们策划了高质量的评估数据集。其次,我们建立了统一的推理管道以确保公平比较。第三,我们设计了两个人类评估分数,即语义一致性和感知质量,以及评估生成图像的综合指南。我们培训专家评估者根据建议的指标评估模型输出。我们的人工评估在 76 个模型上实现了较高的 Krippendorff s alpha 工作人员间一致性,其值高于 0.4。我们对总共约 30 个模型进行了全面评估,并观察到三个关键要点 1:除了文本引导图像生成和主题驱动图像生成之外,现有模型的性能普遍不令人满意,有 74 个模型的总体得分低于 0.5。 2 我们检查了已发表论文中的主张,发现其中 83 条主张成立,只有少数例外。 3 除了主题驱动的图像生成之外,现有的自动指标均没有高于 0.2 的 Spearman 相关性。 |
| Progressive DeepSSM: Training Methodology for Image-To-Shape Deep Models Authors Abu Zahid Bin Aziz, Jadie Adams, Shireen Elhabian 统计形状建模 SSM 是一种定量工具,可用于研究各种医疗应用中的解剖形状。然而,在这些应用中直接使用 3D 图像还有很长的路要走。最近的深度学习方法为减少直接从未分割图像构建 SSM 的大量预处理步骤铺平了道路。然而,这些模型的性能并没有达到标准。受多尺度多分辨率学习的启发,我们提出了一种新的训练策略——渐进式 DeepSSM,来训练图像来塑造深度学习模型。训练以多个尺度进行,每个尺度都利用前一个尺度的输出。该策略使模型能够在第一个尺度中学习粗略的形状特征,并在后面的尺度中逐渐学习详细的精细形状特征。我们通过分割引导的多任务学习利用形状先验,并采用深度监督损失来确保每个规模的学习。实验从定量和定性的角度证明了所提出的策略训练的模型的优越性。 |
| Direct Inversion: Boosting Diffusion-based Editing with 3 Lines of Code Authors Xuan Ju, Ailing Zeng, Yuxuan Bian, Shaoteng Liu, Qiang Xu 文本引导扩散模型彻底改变了图像生成和编辑,提供了卓越的真实感和多样性。具体地,在基于扩散的编辑的背景下,其中根据目标提示来编辑源图像,该过程通过经由扩散模型获取与源图像相对应的噪声潜在向量来开始。随后将该矢量输入到单独的源扩散分支和目标扩散分支中进行编辑。该反转过程的准确性显着影响最终的编辑结果,影响源图像的基本内容保留和根据目标提示的编辑保真度。先前的反演技术旨在在源扩散分支和目标扩散分支中找到统一的解决方案。然而,我们的理论和实证分析表明,解开这些分支会导致保留基本内容和确保编辑保真度的责任明显分离。基于这一见解,我们引入了直接反转,这是一种只需三行代码即可实现两个分支的最佳性能的新技术。为了评估图像编辑性能,我们推出了 PIE Bench,这是一个编辑基准,包含 700 张图像,展示了不同的场景和编辑类型,并附有多功能注释和综合评估指标。 |
| Elastic Interaction Energy Loss for Traffic Image Segmentation Authors Yaxin Feng, Yuan Lan, Luchan Zhang, Yang Xiang 分割是图像的像素级分类。图像分割的准确性和快速推理速度对于自动驾驶安全至关重要。精细复杂的几何物体是交通场景中最难但又最重要的识别目标,如行人、交通标志、车道等。本文提出了一种简单高效的基于几何敏感能量的损失函数,用于卷积神经网络 CNN,用于实时交通场景理解的多类分割。具体来说,两个边界之间的弹性相互作用能 EIE 将驱动预测向真实值移动,直到完全重叠。 EIE 损失函数被纳入 CNN,以提高精细尺度结构分割的准确性。特别是,可以更准确地识别小型或不规则形状的物体,并且可以改善细长物体上的不连续问题。我们的方法可以应用于不同的基于分割的问题,例如城市场景分割和车道检测。我们在三个交通数据集上对我们的方法进行了定量和定性分析,包括城市场景数据 Cityscapes、车道数据 TuSimple 和 CULane。 |
| Generalizable Long-Horizon Manipulations with Large Language Models Authors Haoyu Zhou, Mingyu Ding, Weikun Peng, Masayoshi Tomizuka, Lin Shao, Chuang Gan 这项工作介绍了一个框架,该框架利用大型语言模型法学硕士的功能来生成原始任务条件,以便对新颖的对象和看不见的任务进行可概括的长期操作。这些任务条件可作为生成和调整动态运动基元 DMP 轨迹的指南,以实现长期任务执行。我们进一步创建了一个基于 Pybullet 的具有挑战性的机器人操作任务套件,用于长期任务评估。在模拟和现实环境中进行的大量实验证明了我们的框架在涉及新对象的熟悉任务和新颖但相关的任务上的有效性,凸显了法学硕士在增强机器人系统多功能性和适应性方面的潜力。 |
| What do we learn from a large-scale study of pre-trained visual representations in sim and real environments? Authors Sneha Silwal, Karmesh Yadav, Tingfan Wu, Jay Vakil, Arjun Majumdar, Sergio Arnaud, Claire Chen, Vincent Pierre Berges, Dhruv Batra, Aravind Rajeswaran, Mrinal Kalakrishnan, Franziska Meier, Oleksandr Maksymets 我们对使用预先训练的视觉表示 PVR 来训练执行现实世界任务的下游策略进行了大规模的实证研究。我们的研究涵盖五种不同的 PVR、两种不同的策略学习范式模仿和强化学习,以及用于 5 种不同操作和室内导航任务的三种不同机器人。通过这项工作,我们可以得出三点见解:1 PVR 在模拟中的性能趋势通常反映了它们在现实世界中的趋势,2 PVR 的使用实现了首个此类结果,即室内 ImageNav 零镜头传输到保留了现实世界中的场景,3 PVR 变化带来的好处(主要是数据增强和微调)也转移到了现实世界的性能。 |
| Unveiling the Pitfalls of Knowledge Editing for Large Language Models Authors Zhoubo Li, Ningyu Zhang, Yunzhi Yao, Mengru Wang, Xi Chen, Huajun Chen 随着微调大型语言模型法学硕士相关的成本持续上升,最近的研究工作已转向开发方法来编辑法学硕士中嵌入的隐性知识。然而,知识编辑是否会引发蝴蝶效应仍是一个乌云,因为目前尚不清楚知识编辑是否会带来潜在风险的副作用。本文开创了对法学硕士知识编辑相关潜在陷阱的调查。为了实现这一目标,我们引入了新的基准数据集并提出了创新的评估指标。我们的结果强调了两个关键问题: 1 知识冲突 编辑逻辑上冲突的事实组可能会放大法学硕士固有的不一致之处,这是以前的方法所忽视的一个方面。 2 知识扭曲 以编辑事实知识为目的而改变参数可能会不可挽回地扭曲法学硕士固有的知识结构。实验结果生动地表明,知识编辑可能会无意中给法学硕士带来意想不到的后果,值得未来工作的关注和努力。 |
| Towards End-to-End Embodied Decision Making via Multi-modal Large Language Model: Explorations with GPT4-Vision and Beyond Authors Liang Chen, Yichi Zhang, Shuhuai Ren, Haozhe Zhao, Zefan Cai, Yuchi Wang, Tianyu Liu, Baobao Chang 在这项研究中,我们探索了多模态大型语言模型 MLLM 在改进代理的具体决策过程中的潜力。虽然大型语言模型法学硕士因其先进的推理技能和广泛的世界知识而被广泛使用,但像 GPT4 Vision 这样的 MLLM 提供了增强的视觉理解和推理能力。我们研究最先进的 MLLM 是否可以以端到端的方式处理具体决策,以及 LLM 和 MLLM 之间的合作是否可以增强决策。为了解决这些问题,我们引入了一个名为 PCA EVAL 的新基准,它从感知、认知和行动的角度评估具体决策。此外,我们提出了 HOLMES,这是一个多代理合作框架,允许法学硕士利用 MLLM 和 API 来收集多模式信息以做出明智的决策。我们在基准上比较端到端体现决策和 HOLMES,发现 GPT4 Vision 模型表现出强大的端到端体现决策能力,在平均决策准确性方面优于 GPT4 HOLMES 3 。然而,这种性能是最新 GPT4 Vision 模型独有的,比开源最先进的 MLLM 高出 26 。 |
| Tuning Large language model for End-to-end Speech Translation Authors Hao Zhang, Nianwen Si, Yaqi Chen, Wenlin Zhang, Xukui Yang, Dan Qu, Xiaolin Jiao 随着大型语言模型LLM的出现,基于LLM的多模态模型展现出了巨大的潜力。 LLaSM、X LLM 和 SpeechGPT 等模型表现出令人印象深刻的理解和生成人类指令的能力。然而,当面对诸如端到端语音翻译 E2E ST(跨语言和跨模式翻译任务)等复杂任务时,它们的性能往往会出现问题。与单模态模型相比,多模态模型在这些场景中落后。本文介绍了 LST,这是一种大型多模态模型,旨在出色地完成 E2E ST 任务。 LST 由语音前端、适配器和 LLM 后端组成。 LST 的训练由两个阶段组成:1 模态调整,其中适配器被调整为将语音表示与文本嵌入空间对齐;2 下游任务微调,其中适配器和 LLM 模型都被训练以优化 E2EST 任务的性能。 MuST C 语音翻译基准测试的实验结果表明,LST 13B 在 En De En Fr En Es 语言对上取得了 30.39 41.55 35.33 的 BLEU 分数,超越了之前的模型并建立了新的最先进水平。此外,我们对单模态模型选择和训练策略的影响进行了深入分析,为未来的研究奠定了基础。 |
| Video Transformers under Occlusion: How Physics and Background Attributes Impact Large Models for Robotic Manipulation Authors Shutong Jin, Ruiyu Wang, Muhammad Zahid, Florian T. Pokorny 随着变压器架构和数据集大小的不断扩展,了解影响模型性能的特定数据集因素的需求变得越来越紧迫。本文研究了物体物理属性颜色、摩擦系数、形状和背景特征静态、动态、背景复杂性如何影响视频变换器在遮挡下的轨迹预测任务中的性能。除了单纯的遮挡挑战之外,本研究还旨在研究三个问题:对象物理属性和背景特征如何影响模型性能?哪些属性对模型泛化影响最大?单个任务中大型变压器模型性能是否存在数据饱和点?为了促进这项研究,我们提出了 OccluManip,一个基于现实世界视频的机器人推送数据集,包含 460,000 个具有不同物理特性和不同背景的物体的一致记录。收集了 1.4 TB、总计 1278 小时的灵活时间长度和目标物体轨迹的高质量视频,以适应不同时间要求的任务。此外,我们提出了 Video Occlusion Transformer VOT ,这是一种基于通用视频转换器的网络,在 OccluManip 中提供的所有 18 个子数据集上实现了平均 96 的准确度。 |
| Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving Authors Long Chen, Oleg Sinavski, Jan H nermann, Alice Karnsund, Andrew James Willmott, Danny Birch, Daniel Maund, Jamie Shotton 大型语言模型法学硕士在自动驾驶领域显示出了前景,特别是在泛化性和可解释性方面。我们引入了一种独特的对象级多模态 LLM 架构,该架构将矢量化数字模态与预先训练的 LLM 相结合,以提高对驾驶情况的上下文理解。我们还提出了一个新的数据集,其中包含源自 10k 驾驶场景的 160k QA 对,并配有 RL 代理收集的高质量控制命令以及由教师 LLM GPT 3.5 生成的问题答案对。设计了一种独特的预训练策略,使用矢量字幕语言数据将数字矢量模态与静态 LLM 表示对齐。我们还引入了驾驶质量检查的评估指标,并展示了我们的法学硕士驾驶员在解释驾驶场景、回答问题和决策方面的熟练程度。与传统的行为克隆相比,我们的研究结果凸显了基于法学硕士的驾驶行为生成的潜力。 |
| OOD Aware Supervised Contrastive Learning Authors Soroush Seifi, Daniel Olmeda Reino, Nikolay Chumerin, Rahaf Aljundi 分布外 OOD 检测是安全部署机器学习模型的一个关键问题,用于识别训练分布之外(即分布数据 ID 中的样本)。大多数 OOD 工作重点关注使用 Cross Entropy CE 训练的分类模型,并尝试解决其固有问题。在这项工作中,我们利用通过监督对比 SupCon 训练学习到的强大表示,并提出一种整体方法来学习对 OOD 数据具有鲁棒性的分类器。我们用两个额外的对比项来扩展 SupCon 损失。第一项将辅助 OOD 表示推离 ID 表示,而不对辅助数据之间的相似性施加任何限制。第二项使 OOD 功能远离现有的类原型,同时使 ID 表示更接近其相应的类原型。当辅助 OOD 数据不可用时,我们提出特征混合技术来有效生成伪 OOD 特征。我们的解决方案简单高效,是闭集监督对比表示学习的自然延伸。 |
| Robust deformable image registration using cycle-consistent implicit representations Authors Louis D. van Harten, Jaap Stoker, Ivana I gum 最近的医学图像配准工作提出了使用隐式神经表示,展示了可与最先进的基于学习的方法相媲美的性能。然而,这些隐式表示需要针对每个新图像对进行优化,这是一个随机过程,可能无法收敛到全局最小值。为了提高鲁棒性,我们提出了一种使用循环一致隐式神经表示对的可变形配准方法,每个隐式表示都链接到估计相反变换的第二隐式表示,使每个网络充当其配对相反的正则化器。在推理过程中,我们通过对成对后向变换进行数值反转并评估优化对的一致性来生成多个变形估计。与使用单一表示相比,这种共识提高了配准准确性,并产生了可用于自动质量控制的强大的不确定性度量。我们使用 4D 肺部 CT 数据集评估我们的方法。与现有技术相比,所提出的循环一致优化方法将优化失败率从 2.4 降低到 0.0。所提出的推理方法将地标精度提高了 4.5,并且所提出的不确定性度量可检测配准方法无法收敛到正确解决方案的所有实例。 |
| Improved Automatic Diabetic Retinopathy Severity Classification Using Deep Multimodal Fusion of UWF-CFP and OCTA Images Authors Mostafa El Habib Daho, Yihao Li, Rachid Zeghlache, Yapo Cedric Atse, Hugo Le Boit , Sophie Bonnin, Deborah Cosette, Pierre Deman, Laurent Borderie, Capucine Lepicard, Ramin Tadayoni, B atrice Cochener, Pierre Henri Conze, Mathieu Lamard, Gwenol Quellec 糖尿病视网膜病变 DR 是一种普遍且严重的糖尿病并发症,影响着全球数百万人,凸显了准确、及时诊断的必要性。成像技术的最新进展,例如超广角彩色眼底摄影 UWF CFP 成像和光学相干断层扫描血管造影 OCTA,为早期检测 DR 提供了机会,但鉴于它们产生的数据性质不同,也带来了重大挑战。本研究引入了一种新颖的多模式方法,利用这些成像模式显着增强 DR 分类。我们的方法使用 ResNet50 和 3D ResNet50 模型的融合,将 2D UWF CFP 图像和 3D 高分辨率 6x6 mm 3 OCTA 结构图像和流图像集成在一起,并使用 Squeeze 和 Exitation SE 块来放大相关特征。此外,为了提高模型的泛化能力,实现了 Manifold Mixup 的多模态扩展,应用于级联多模态特征。实验结果表明,与仅依赖于单一模态的方法相比,所提出的多模态方法的 DR 分类性能显着增强。 |
| Improving style transfer in dynamic contrast enhanced MRI using a spatio-temporal approach Authors Adam G. Tattersall, Keith A. Goatman, Lucy E. Kershaw, Scott I. K. Semple, Sonia Dahdouh DCE MRI 中的风格转移是一项具有挑战性的任务,因为不同组织和时间之间的对比度增强存在很大差异。由于系列图像之间的对比度增强和运动多种多样,当前的无监督方法会失败。我们提出了一种新方法,它将自动编码器与卷积 LSTM 结合起来,以解开内容和风格,以对预测的潜在空间随时间和自适应卷积进行建模,以解决对比度增强的局部性质。为了评估我们的方法,我们提出了一个考虑对比度增强的新指标。 |
| Effective and Parameter-Efficient Reusing Fine-Tuned Models Authors Weisen Jiang, Baijiong Lin, Han Shi, Yu Zhang, and Zhenguo Li, James T. Kwok 在线提供的许多预先训练的大型模型在转移到下游任务方面已经变得非常有效。同时,在这些预训练模型上进行微调的各种特定于任务的模型可在线供公众使用。在实践中,由于收集特定于任务的数据是劳动密集型的,并且微调大型预训练模型的计算成本很高,因此可以重用特定于任务的微调模型来处理下游任务。然而,每个任务使用一个模型会给存储和服务带来沉重的负担。最近,已经提出了许多免训练和参数有效的方法,用于将多个微调的任务特定模型重用为单个多任务模型。然而,与每个任务使用微调模型相比,这些方法表现出很大的准确度差距。在本文中,我们提出了重新使用 PERU 微调模型的参数有效方法。为了重用完全微调的 FFT 模型,我们提出了 PERU FFT,通过幅度剪枝将稀疏任务向量注入到合并模型中。为了重用 LoRA 微调模型,我们建议秘鲁 LoRA 使用较低秩矩阵通过奇异值分解来近似 LoRA 矩阵。 PERUFFT 和 PERU LoRA 都是免费培训的。在计算机视觉和自然语言处理任务上进行的大量实验证明了所提出方法的有效性和参数效率。 |
| Shifting More Attention to Breast Lesion Segmentation in Ultrasound Videos Authors Junhao Lin, Qian Dai, Lei Zhu, Huazhu Fu, Qiong Wang, Weibin Li, Wenhao Rao, Xiaoyang Huang, Liansheng Wang 超声超声视频中的乳腺病灶分割对于诊断和治疗腋窝淋巴结转移至关重要。然而,缺乏具有高质量注释的完善的大规模超声视频数据集给研究界带来了持续的挑战。为了克服这个问题,我们精心策划了一个美国视频乳腺病变分割数据集,其中包含 572 个视频和 34,300 个带注释的帧,涵盖了广泛的现实临床场景。此外,我们提出了一种新颖的频率和定位特征聚合网络 FLA Net,它从频域学习时间特征并预测额外的病变位置以协助乳腺病变分割。我们还设计了一种基于定位的对比损失,以减少同一视频中相邻视频帧之间的病变位置距离,并扩大不同超声视频帧之间的位置距离。我们对带注释的数据集和两个公共视频息肉分割数据集的实验表明,我们提出的 FLA Net 在美国视频中的乳腺病变分割和视频息肉分割方面实现了最先进的性能,同时显着降低了时间和空间复杂度。 |
| SMRD: SURE-based Robust MRI Reconstruction with Diffusion Models Authors Batu Ozturkler, Chao Liu, Benjamin Eckart, Morteza Mardani, Jiaming Song, Jan Kautz 由于样本质量高,扩散模型最近在加速 MRI 重建中受到欢迎。它们可以有效地充当丰富的数据先验,同时在推理时灵活地合并前向模型,并且它们已被证明比分布变化下的展开方法更稳健。然而,扩散模型需要在验证集上仔细调整推理超参数,并且仍然对测试期间的分布变化敏感。为了应对这些挑战,我们引入了基于 SURE 的 MRI 重建与扩散模型 SMRD,这是一种执行测试时超参数调整以增强测试期间鲁棒性的方法。 SMRD 使用 Stein 的无偏风险估计器 SURE 来估计测试期间重建的均方误差。然后,SURE 用于自动调整推理超参数并设置早期停止标准,而无需进行验证调整。据我们所知,SMRD 是第一个将 SURE 纳入扩散模型采样阶段以进行自动超参数选择的公司。 SMRD 在各种测量噪声水平、加速因子和解剖结构上均优于扩散模型基线,在测量噪声下实现了高达 6 dB 的 PSNR 改进。 |
| Generative Autoencoding of Dropout Patterns Authors Shunta Maeda 我们提出了一种称为解密自动编码器的生成模型。在此模型中,我们为训练数据集中的每个数据点分配一个唯一的随机丢失模式,然后训练自动编码器以使用该模式作为要编码的信息来重建相应的数据点。由于解密自动编码器的训练仅依赖于重建误差,因此它比其他生成模型提供更稳定的训练。 |
| RF-ULM: Deep Learning for Radio-Frequency Ultrasound Localization Microscopy Authors Christopher Hahne, Georges Chabouh, Arthur Chavignon, Olivier Couture, Raphael Sznitman 在超声定位显微镜 ULM 中,获得高分辨率图像依赖于造影剂粒子在连续波束形成帧上的精确定位。然而,我们的研究揭示了巨大的潜力。延迟和求和波束成形的过程会导致射频 RF 数据不可逆地减少,而其对定位的影响在很大程度上仍未被探索。 RF 波前中嵌入的丰富上下文信息(包括其双曲形状和相位)为指导深度神经网络 DNN 应对具有挑战性的定位场景提供了巨大的希望。为了充分利用这些数据,我们建议直接定位射频信号中的散射体。我们的方法涉及使用学习的特征通道改组的自定义超分辨率 DNN 和专为 RF 输入数据中可靠且准确的定位而定制的新颖的半全局卷积采样块。此外,我们引入了几何点变换,有助于 B 模式和 RF 空间之间的无缝映射。为了验证我们方法的有效性并了解波束成形的影响,我们与 ULM 中最先进的 SOTA 技术进行了广泛的比较。我们展示了经过 RF 训练的 DNN 的首次体内结果,强调了其在现实世界中的实用性。我们的研究结果表明,RF ULM 弥合了合成数据集和真实数据集之间的领域差距,在精度和复杂性方面提供了相当大的优势。 |
| Fetal-BET: Brain Extraction Tool for Fetal MRI Authors Razieh Faghihpirayesh, Davood Karimi, Deniz Erdo mu , Ali Gholipour 胎儿大脑提取是大多数计算胎儿大脑 MRI 流程中必要的第一步。然而,由于不标准的胎儿头部姿势、检查期间的胎儿运动以及发育中的胎儿大脑以及邻近的胎儿和母体解剖结构在不同序列和扫描条件下的巨大异质性外观,这是一项非常具有挑战性的任务。开发有效解决此任务的机器学习方法需要大量且丰富的标记数据集,而这是以前无法获得的。因此,目前还没有根据各种胎儿 MRI 序列准确提取胎儿大脑的方法。在这项工作中,我们首先构建了一个包含大约 72,000 个 2D 胎儿大脑 MRI 图像的大型带注释数据集。我们的数据集涵盖了三种常见的 MRI 序列,包括 T2 加权、扩散加权和使用不同扫描仪采集的功能 MRI。此外,它还包括正常和病理的大脑。使用该数据集,我们开发并验证了深度学习方法,利用 U Net 风格架构、注意力机制、多重对比特征学习和数据增强的强大功能,实现快速、准确和通用的自动胎儿大脑提取。我们的方法利用多对比多序列胎儿 MRI 数据的丰富信息,能够精确描绘胎儿大脑结构。对独立测试数据的评估表明,我们的方法可以对不同扫描仪、病理大脑和不同妊娠阶段获取的异构测试数据实现准确的大脑提取。 |
| Chinese Abs From Machine Translation |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









