










AI视野·今日CS.CV 计算机视觉论文速览
Tue, 24 Oct 2023
Totally 138 papers
👉上期速览✈更多精彩请移步主页

Interesting:
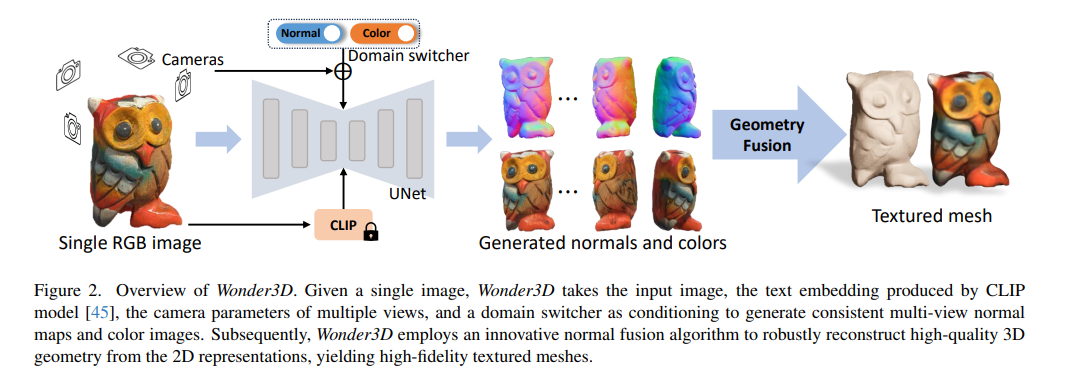
📚Wonder3D, 基于交叉扩散模型的单图像三维形状生成。(from 香港大学)

website:https://www.xxlong.site/Wonder3D/
Daily Computer Vision Papers
| RoboDepth: Robust Out-of-Distribution Depth Estimation under Corruptions Authors Lingdong Kong, Shaoyuan Xie, Hanjiang Hu, Lai Xing Ng, Benoit R. Cottereau, Wei Tsang Ooi 单目图像的深度估计对于现实世界的视觉感知系统至关重要。虽然当前基于学习的深度估计模型在精心策划的数据上进行训练和测试,但它们经常忽略分布外的 OoD 情况。然而,在实际环境中,尤其是像自动驾驶这样对安全至关重要的环境中,可能会出现常见的腐败现象。为了解决这一疏忽问题,我们引入了全面的稳健性测试套件 RoboDepth,其中包含 18 个损坏,涵盖三个类别:i 天气和照明条件;ii 传感器故障和移动;iii 数据处理异常。随后,我们对室内和室外场景的 42 个深度估计模型进行了基准测试,以评估它们对这些损坏的恢复能力。我们的研究结果强调,在缺乏专门的稳健性评估框架的情况下,许多领先的深度估计模型可能容易受到典型损坏的影响。我们深入研究了设计更强大的深度估计模型的考虑因素,涉及预训练、增强、模态、模型容量和学习范例。 |
| FreeNoise: Tuning-Free Longer Video Diffusion Via Noise Rescheduling Authors Haonan Qiu, Menghan Xia, Yong Zhang, Yingqing He, Xintao Wang, Ying Shan, Ziwei Liu 随着大规模视频数据集的可用性和扩散模型的进步,文本驱动的视频生成取得了实质性进展。然而,现有的视频生成模型通常是在有限数量的帧上进行训练,导致在推理过程中无法生成高保真长视频。此外,这些模型仅支持单个文本条件,而现实生活场景通常需要多个文本条件,因为视频内容随着时间的推移而变化。为了应对这些挑战,本研究探讨了扩展文本驱动功能以生成基于多个文本的更长视频的潜力。 1 我们首先分析视频扩散模型中初始噪声的影响。然后,基于对噪声的观察,我们提出了 FreeNoise,这是一种免调整且省时的范例,可增强预训练视频扩散模型的生成能力,同时保持内容一致性。具体来说,我们不是初始化所有帧的噪声,而是重新安排一系列噪声以进行长程相关,并通过基于窗口的函数对它们执行时间关注。 2 此外,我们设计了一种新颖的运动注入方法来支持根据多个文本提示生成视频。大量的实验验证了我们的范例在扩展视频扩散模型的生成能力方面的优越性。值得注意的是,与之前性能最佳的方法带来的 255 额外时间成本相比,我们的方法仅产生约 17 的时间成本,可以忽略不计。 |
| Ghost on the Shell: An Expressive Representation of General 3D Shapes Authors Zhen Liu, Yao Feng, Yuliang Xiu, Weiyang Liu, Liam Paull, Michael J. Black, Bernhard Sch lkopf 创建逼真的虚拟世界需要对各种物体进行 3D 表面几何的精确建模。为此,网格很有吸引力,因为它们 1 支持使用真实材质和光照进行基于物理的快速渲染,2 支持物理模拟,3 对于现代图形管道来说具有内存效率。然而,最近关于 3D 形状重建和统计建模的工作批评网格在拓扑上不灵活。为了捕捉各种物体形状,任何 3D 表示都必须能够对实体、防水形状以及薄的、开放的表面进行建模。最近的工作主要集中在前者上,并且重建开放表面的方法不支持使用材质和照明或无条件生成建模进行快速重建。受到开放表面可以被视为漂浮在水密表面上的岛屿这一观察的启发,我们通过在水密模板上定义流形有符号距离场来参数化开放表面。通过这种参数化,我们进一步开发了一种基于网格的可微分表示,可以参数化任意拓扑的水密和非水密网格。我们的新表示形式称为“Ghost on the Shell G Shell”,它支持两个重要的应用:基于多视图图像的可微光栅化重建和非水密网格的生成建模。 |
| Large Language Models are Visual Reasoning Coordinators Authors Liangyu Chen, Bo Li, Sheng Shen, Jingkang Yang, Chunyuan Li, Kurt Keutzer, Trevor Darrell, Ziwei Liu 视觉推理需要多模态感知和对世界的常识认知。最近,多种视觉语言模型VLM被提出,在各个领域都具有出色的常识推理能力。然而,如何利用这些互补的 VLM 的集体力量却很少被探讨。诸如集成之类的现有方法仍然难以将这些模型与所需的高阶通信聚合起来。在这项工作中,我们提出了 Cola,这是一种协调多个 VLM 进行视觉推理的新颖范式。我们的主要见解是,大型语言模型 LLM 可以通过促进利用其独特且互补的功能的自然语言通信来有效地协调多个 VLM。大量实验表明,我们的指令调整变体 Cola FT 在视觉问答 VQA、外部知识 VQA、视觉蕴涵和视觉空间推理任务上实现了最先进的性能。此外,我们还表明,我们的上下文学习变体“可乐零”在零和少量镜头设置中表现出竞争性能,无需进行微调。 |
| Handling Data Heterogeneity via Architectural Design for Federated Visual Recognition Authors Sara Pieri, Jose Renato Restom, Samuel Horvath, Hisham Cholakkal 联邦学习 FL 是一种很有前途的研究范式,它能够在各方之间协作训练机器学习模型,而无需敏感信息交换。尽管如此,将数据保留在单个客户端中会给实现与集中训练的模型相当的性能带来根本性的挑战。我们的研究对应用于视觉识别的联邦学习进行了广泛的回顾。它强调了深思熟虑的架构设计选择在实现最佳性能方面的关键作用,这是 FL 文献中经常被忽视的一个因素。许多现有的 FL 解决方案都是在浅层或简单网络上进行测试的,这可能无法准确反映现实世界的应用。这种做法限制了研究成果向大规模视觉识别模型的转移。通过对卷积神经网络、变压器和 MLP 混合器等多种尖端架构的深入分析,我们通过实验证明架构选择可以显着提高 FL 系统性能,特别是在处理异构数据时。我们在四个具有挑战性的 FL 数据集上研究了来自 5 个不同架构系列的 19 个视觉识别模型。我们还重新研究了基于卷积的架构在 FL 设置中的较差性能,并分析了归一化层对 FL 性能的影响。我们的研究结果强调了实际场景中计算机视觉任务的架构设计的重要性,有效缩小了联邦学习和集中学习之间的性能差距。 |
| SAM-Med3D Authors Haoyu Wang, Sizheng Guo, Jin Ye, Zhongying Deng, Junlong Cheng, Tianbin Li, Jianpin Chen, Yanzhou Su, Ziyan Huang, Yiqing Shen, Bin Fu, Shaoting Zhang, Junjun He, Yu Qiao 尽管 Segment Anything Model SAM 在 2D 自然图像分割中表现出了令人印象深刻的性能,但其在 3D 立体医学图像中的应用却暴露出显着的缺点,即性能次优和预测不稳定,需要过多的提示点才能获得所需的结果。这些问题很难通过在医学数据上微调 SAM 来解决,因为 SAM 的原始 2D 结构忽略了 3D 空间信息。在本文中,我们介绍了 SAM Med3D,这是针对 3D 医学图像修改 SAM 的最全面的研究。我们的方法的特点在于其在两个主要方面的全面性,首先,通过将 SAM 全面重新表述为在全面处理的大规模体医学数据集上训练的彻底的 3D 架构,其次,通过提供对其性能的全面评估。具体来说,我们使用超过 131K 3D 掩模和 247 个类别来训练 SAM Med3D。我们的 SAM Med3D 擅长捕获 3D 空间信息,与医疗领域中性能最佳的微调 SAM 相比,其提示点明显更少,从而展现出具有竞争力的性能。然后,我们在 15 个数据集上评估其功能,并从多个角度进行分析,包括解剖结构、模式、目标和泛化能力。与 SAM 相比,我们的方法展示了 3D 立体医学图像的显着提高的效率和广泛的分割能力。 |
| FreeMask: Synthetic Images with Dense Annotations Make Stronger Segmentation Models Authors Lihe Yang, Xiaogang Xu, Bingyi Kang, Yinghuan Shi, Hengshuang Zhao 由于各种先进网络架构的提出,语义分割取得了巨大的进步。然而,他们非常渴望训练精细的注释,而且获取起来既费力又负担不起。因此,我们在这项工作中提出了 FreeMask,它利用生成模型的合成图像来减轻数据收集和注释程序的负担。具体来说,我们首先根据现实数据集提供的语义掩模合成丰富的训练图像。这将为语义分割模型产生额外良好对齐的图像掩模训练对。我们惊讶地发现,仅使用合成图像进行训练,我们已经实现了与真实图像相当的性能,例如,ADE20K 上的 mIoU 为 48.3 vs. 48.5,COCO Stuff 上的 mIoU 为 49.3 vs. 50.5。然后,我们通过与真实图像联合训练或对真实图像进行预训练来研究合成图像的作用。同时,我们设计了一种强大的过滤原理来抑制错误合成的区域。此外,我们建议不平等地对待不同的语义掩模,以优先考虑那些较难的语义掩模,并为它们采样更多相应的合成图像。因此,无论是使用我们的过滤和重新采样的合成图像进行联合训练还是预训练,分割模型都可以得到极大的增强,例如,在 ADE20K 上从 48.7 到 52.0。 |
| Online Detection of AI-Generated Images Authors David C. Epstein, Ishan Jain, Oliver Wang, Richard Zhang 随着人工智能生成图像的不断进步,区分传统来源的图像(例如照片、艺术品)与人工智能生成的图像变得越来越困难。以前的检测方法独立地研究从单个生成器到另一个生成器的泛化。然而,实际上,新的生成器是在流媒体的基础上发布的。我们在这种情况下研究泛化,按照众所周知的生成方法的历史发布日期,对 N 个模型进行训练并在下一个 N k 上进行测试。此外,图像越来越多地由真实的和生成的组件组成,例如通过图像修复。因此,我们将这种方法扩展到像素预测,使用自动生成的修复数据展示了强大的性能。 |
| DEsignBench: Exploring and Benchmarking DALL-E 3 for Imagining Visual Design Authors Kevin Lin, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Lijuan Wang 我们推出 DEsignBench,这是一个为视觉设计场景量身定制的文本到图像 T2I 生成基准。最近的 T2I 模型(例如 DALL E 3 等)在生成与文本输入紧密结合的逼真图像方面表现出了卓越的能力。虽然创造视觉上迷人的图像的吸引力是不可否认的,但我们的重点不仅仅是审美愉悦。我们的目标是研究在真实的设计环境中使用这些强大模型的潜力。为了实现这一目标,我们开发了DEsignBench,其中包含旨在评估T2I模型的设计技术能力和设计应用场景的测试样本。这两个维度中的每一个都由一组不同的特定设计类别支持。我们在 DEsignBench 上探索 DALL E 3 与其他领先的 T2I 模型,从而形成一个全面的视觉图库,用于并排比较。对于 DEsignBench 基准测试,我们根据图像文本对齐、视觉美感和设计创意的标准,对 DEsignBench 库中生成的图像进行人工评估。我们的评估还考虑了其他专业设计能力,包括文本渲染、布局构图、色彩和谐、3D设计和媒介风格。除了人工评估之外,我们还推出了第一个由 GPT 4V 提供支持的自动图像生成评估器。该评估器提供的评级与人类判断非常一致,同时易于复制且具有成本效益。 |
| SpVOS: Efficient Video Object Segmentation with Triple Sparse Convolution Authors Weihao Lin, Tao Chen, Chong Yu 半监督视频对象分割 Semi VOS 只需要注释视频的第一帧即可分割未来的帧,最近受到了越来越多的关注。在现有的管道中,基于内存匹配的管道正在成为主要的研究方向,因为它可以充分利用时间序列信息来获得高质量的分割结果。尽管这种方法已经取得了可喜的性能,但整体框架仍然承受着沉重的计算开销,这主要是由高分辨率特征图和每个内核滤波器之间的每帧密集卷积操作引起的。因此,我们在这项工作中提出了一个名为 SpVOS 的 VOS 稀疏基线,它开发了一种新颖的三重稀疏卷积来降低整个 VOS 框架的计算成本。设计的三重门充分考虑了相邻视频帧之间的空间和时间冗余,自适应地做出三重决策来决定如何在每个像素上应用稀疏卷积来控制每层的计算开销,同时保持足够的辨别能力区分相似的物体,避免错误积累。还开发了混合稀疏训练策略,加上考虑稀疏性约束的设计目标,以平衡 VOS 分割性能和计算成本。在 DAVIS 和 Youtube VOS 两个主流 VOS 数据集上进行了实验。结果表明,所提出的 SpVOS 比其他最先进的稀疏方法实现了优越的性能,甚至保持了可比的性能,例如,DAVIS 2017 Youtube VOS 验证集的总体得分为 83.04 79.29,典型的非稀疏 VOS 基线为 82.88 |
| Matryoshka Diffusion Models Authors Jiatao Gu, Shuangfei Zhai, Yizhe Zhang, Josh Susskind, Navdeep Jaitly 扩散模型是生成高质量图像和视频的事实上的方法,但由于计算和优化挑战,学习高维模型仍然是一项艰巨的任务。现有方法通常采用在像素空间中训练级联模型或使用单独训练的自动编码器的下采样潜在空间。在本文中,我们介绍了 Matryoshka 扩散模型 MDM,这是一种用于高分辨率图像和视频合成的端到端框架。我们提出了一种扩散过程,该过程联合对多个分辨率的输入进行去噪,并使用 NestedUNet 架构,其中小规模输入的特征和参数嵌套在大规模输入的特征和参数中。此外,MDM 还支持从低分辨率到高分辨率的渐进训练计划,从而显着改进高分辨率生成的优化。我们在各种基准上展示了我们的方法的有效性,包括类条件图像生成、高分辨率文本到图像以及文本到视频应用程序。 |
| Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model Authors Ruoxi Shi, Hansheng Chen, Zhuoyang Zhang, Minghua Liu, Chao Xu, Xinyue Wei, Linghao Chen, Chong Zeng, Hao Su 我们报告了 Zero123,这是一种图像条件扩散模型,用于从单个输入视图生成 3D 一致的多视图图像。为了充分利用预训练的 2D 生成先验,我们开发了各种条件和训练方案,以最大限度地减少现成图像扩散模型(例如稳定扩散)的微调工作。 Zero123 擅长从单个图像生成高质量、一致的多视图图像,克服纹理退化和几何错位等常见问题。此外,我们还展示了在 Zero123 上训练 ControlNet 以增强对生成过程的控制的可行性。 |
| FD-Align: Feature Discrimination Alignment for Fine-tuning Pre-Trained Models in Few-Shot Learning Authors Kun Song, Huimin Ma, Bochao Zou, HuiShuai Zhang, Weiran Huang 由于数据有限,现有的几种从头开始训练的镜头学习方法未能达到令人满意的性能。相比之下,大规模预训练模型(例如 CLIP)表现出出色的少样本和零样本能力。为了增强下游任务的预训练模型的性能,经常需要对下游数据的模型进行微调。然而,对预训练模型进行微调会导致其在存在分布偏移的情况下泛化能力下降,而少数镜头学习中样本数量有限使得模型极易出现过拟合。因此,现有的微调少数镜头学习的方法主要集中在微调模型的分类头或引入额外的结构。在本文中,我们介绍了一种称为特征区分对齐 FD Align 的微调方法。我们的方法旨在通过在微调过程中保持虚假特征的一致性来增强模型的通用性。大量的实验结果验证了我们的方法对于 ID 和 OOD 任务的有效性。经过微调,该模型可以与现有方法无缝集成,从而提高性能。 |
| Acquiring Weak Annotations for Tumor Localization in Temporal and Volumetric Data Authors Yu Cheng Chou, Bowen Li, Deng Ping Fan, Alan Yuille, Zongwei Zhou 创建大规模且注释良好的数据集来训练人工智能算法对于自动化肿瘤检测和定位至关重要。然而,由于资源有限,在注释大量未标记数据时确定最佳注释类型具有挑战性。为了解决这个问题,我们重点关注结肠镜检查视频中的息肉和腹部 CT 扫描中的胰腺肿瘤,由于数据的高维性质(涉及临时维度或空间维度),这两种应用都需要大量的精力和时间进行像素级注释。在本文中,我们开发了一种新的注释策略,称为“拖放”,该策略将注释过程简化为拖放。这种注释策略比其他类型的弱注释(例如每像素、边界框、涂鸦、椭圆和点)更有效,特别是对于时间和体积成像。此外,为了利用我们的拖放注释,我们开发了一种基于分水岭算法的新颖的弱监督学习方法。实验结果表明,我们的方法比其他弱注释实现了更好的检测和定位性能,更重要的是,实现了与详细的每像素注释训练相似的性能。有趣的是,我们发现,在资源有限的情况下,与为一小组图像分配每像素注释相比,从不同的患者群体中分配弱注释可以培养对未见过的图像更稳健的模型。 |
| Localizing Active Objects from Egocentric Vision with Symbolic World Knowledge Authors Te Lin Wu, Yu Zhou, Nanyun Peng 从自我中心的角度主动执行任务指令的能力对于人工智能代理完成任务或虚拟协助人类至关重要。实现这一目标的一个重要步骤是定位和跟踪由于人类行为与环境交互而经历重大状态变化的关键活动对象,而无需准确告知在哪里接地,例如,定位和跟踪指令 Dip 视频中的海绵将海绵放入桶中。 。虽然现有的作品从纯粹的视觉角度来解决这个问题,但我们研究了文本模态(即任务指令及其与视觉模态的交互)在多大程度上是有益的。具体来说,我们建议通过以下方式提高短语基础模型定位活动对象的能力:1学习正在发生变化的对象的角色并从指令中准确地提取它们,2在动作过程中利用对象的前后条件,3更多地识别对象具有强大的描述性知识。我们利用大型语言模型LLM来提取上述动作对象知识,并设计一种每个对象聚合屏蔽技术来有效地对对象短语和符号知识进行联合推理。我们在 Ego4D 和 Epic Kitchens 数据集上评估我们的框架。大量实验证明了我们提出的框架的有效性,这使得 TREK 150 OPE Det 定位跟踪任务的所有标准指标有了 54 项改进,TREK 150 OPE 跟踪任务的所有标准指标有了 7 项改进,平均精度 AP 有了 3 项改进 |
| A Universal Anti-Spoofing Approach for Contactless Fingerprint Biometric Systems Authors Banafsheh Adami, Sara Tehranipoor, Nasser Nasrabadi, Nima Karimian 随着智能手机越来越融入我们的日常生活,指纹照片正在成为一种潜在的非接触式身份验证方法。虽然它提供了便利,但它也更容易受到各种演示攻击工具 PAI 的欺骗。非接触式指纹是一种新兴的生物特征认证,但尚未针对反欺骗进行深入研究。虽然现有的反欺骗方法表现出了不错的结果,但它们在检测任何看不见的未知欺骗样本的普遍性和可扩展性方面遇到了挑战。为了解决这个问题,我们提出了一种用于非接触式指纹的通用呈现攻击检测方法,尽管对呈现攻击样本的了解有限。我们使用 StyleGAN 从活体手指照片生成合成非接触式指纹,并将它们集成以训练半监督 ResNet 18 模型。引入了一种新颖的联合损失函数,结合了 Arcface 和 Center 损失,并进行了正则化,以平衡两个损失函数之间的平衡,并最小化实时样本内的变化,同时增强 Deepfake 和实时样本之间的类间变化。我们还全面比较了不同正则化对呈现攻击检测 PAD 的联合损失函数的影响,并探索了具有不同激活函数(即泄漏 ReLU 和 RelU 以及 Arcface 和中心损失)的改进 ResNet 18 架构的性能。最后,我们使用看不见的欺骗攻击类型和实时数据来评估模型的性能。 |
| Manipulation Mask Generator: High-Quality Image Manipulation Mask Generation Method Based on Modified Total Variation Noise Reduction Authors Xinyu Yang, Jizhe Zhou 在人工智能中,任何模型想要取得好的结果,都离不开大量高质量的数据。在篡改检测领域尤其如此。本文提出了一种改进的全变分降噪方法来获取高质量的篡改图像。我们自动从百度PS吧抓取原始图片和篡改图片。百度PS吧是一个网友发布无数被篡改图片的网站。用篡改图像减去原始图像可以突出显示篡改区域。然而,最终打印也存在大量噪声,因此这些图像不能直接用于深度学习模型。我们改进的全变分降噪方法就是为了解决这个问题。由于很多文字比较细长,在打开和关闭操作后很容易丢失文字信息。我们使用MSER极大稳定极值区域和NMS非极大抑制技术来提取文本信息。然后利用改进的全变分降噪技术对减影图像进行处理。最后,通过将图像和文本信息相加,我们就可以得到一张噪声很小的图像。而且这个想法也很大程度上保留了文本信息。 |
| UWB Based Static Gesture Classification Authors Abhishek Sebastian 我们的论文利用专有的 UWB 雷达传感器技术,提出了一个基于 UWB 的静态手势识别的强大框架。我们进行了大量的数据收集工作,以编译包含五种常用手势的数据集。我们的方法涉及全面的数据预处理管道,其中包括异常值处理、保持纵横比的大小调整和伪彩色图像转换。 CNN 和 MobileNet 模型都是在处理后的图像上进行训练的。值得注意的是,我们表现最好的模型达到了 96.78 的准确率。此外,我们开发了一个用户友好的 GUI 框架来评估模型的系统资源使用情况和处理时间,结果显示内存利用率较低,并且实时任务在一秒内完成。 |
| P2AT: Pyramid Pooling Axial Transformer for Real-time Semantic Segmentation Authors Mohammed A. M. Elhassan, Changjun Zhou, Amina Benabid, Abuzar B. M. Adam 最近,基于 Transformer 的模型由于能够对长范围依赖关系进行建模,因此在各种视觉任务中取得了有希望的结果。然而,变压器的计算成本很高,这限制了它们在自动驾驶等实时任务中的应用。此外,高效的局部和全局特征选择和融合对于准确的密集预测至关重要,尤其是驱动场景理解任务。在本文中,我们提出了一种名为 Pyramid Pooling Axial Transformer P2AT 的实时语义分割架构。所提出的 P2AT 采用来自 CNN 编码器的粗略特征来生成尺度感知上下文特征,然后将其与多级特征聚合方案相结合以生成增强的上下文特征。具体来说,我们引入了金字塔池轴向变换器来捕获复杂的空间和通道依赖性,从而提高语义分割的性能。然后,我们设计了一个双向融合模块BiF来组合不同级别的语义信息。同时,引入了全局上下文增强器来弥补连接不同语义级别的不足。最后,提出了一个解码器块来帮助维持更大的感受野。我们在三个具有挑战性的场景理解数据集上评估 P2AT 变体。特别是,我们的 P2AT 变体在 P2AT S、P2ATM 和 P2AT L 的 Camvid 数据集上分别达到了 80.5、81.0、81.1 的最先进结果。此外,我们在 Cityscapes 和 Pascal VOC 2012 上的实验证明了所提出架构的效率,结果表明 P2AT M 在 Cityscapes 上达到了 78.7。 |
| SONIC: Sonar Image Correspondence using Pose Supervised Learning for Imaging Sonars Authors Samiran Gode, Akshay Hinduja, Michael Kaess 在本文中,我们通过一种使用学习特征进行声纳图像对应的新颖方法来解决水下 SLAM 数据关联的挑战性问题。我们引入了 SONIC SONar Image Correspondence,这是一种姿态监督网络,旨在产生能够承受视点变化的鲁棒特征对应。水下环境固有的复杂性源于动态且经常受限的能见度条件,将视野限制在几米通常毫无特征的区域。这使得基于摄像头的系统在大多数开放水域应用场景中都不是最佳的。因此,多波束成像声纳成为感知传感器的首选。然而,它们也并非没有局限性。虽然与相机相比,成像声纳提供了卓越的远距离可视性,但从不同的角度来看,它们的测量结果可能会有所不同。这种固有的可变性给数据关联带来了巨大的挑战,特别是对于基于特征的方法。我们的方法在生成声纳图像对应关系方面表现出明显更好的性能,这将为更准确的闭环约束和基于声纳的位置识别铺平道路。 |
| Wonder3D: Single Image to 3D using Cross-Domain Diffusion Authors Xiaoxiao Long, Yuan Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song Hai Zhang, Marc Habermann, Christian Theobalt, Wenping Wang 在这项工作中,我们介绍了 Wonder3D,这是一种从单视图图像高效生成高保真纹理网格的新颖方法。基于分数蒸馏采样 SDS 的最新方法已显示出从 2D 扩散先验恢复 3D 几何形状的潜力,但它们通常会受到时间的影响消耗每个形状的优化和不一致的几何形状。 |
| Domain Watermark: Effective and Harmless Dataset Copyright Protection is Closed at Hand Authors Junfeng Guo, Yiming Li, Lixu Wang, Shu Tao Xia, Heng Huang, Cong Liu, Bo Li 深度神经网络 DNN 的繁荣很大程度上得益于开源数据集,用户可以根据这些数据集评估和改进其方法。在本文中,我们重新审视基于后门的数据集所有权验证 DOV,这是目前保护开源数据集版权的唯一可行方法。我们发现,这些方法从根本上来说是有害的,因为它们可能会被对手引入带有水印的 DNN 的恶意错误分类行为。在本文中,我们从另一个角度设计了DOV,通过使在受保护数据集上训练的水印模型正确地分类一些会被良性模型错误分类的硬样本。我们的方法受到 DNN 泛化特性的启发,我们发现原始数据集的 emph 很难泛化域作为其 emph 域水印。使用包含修改样本的受保护数据集可以轻松学习它。具体来说,我们将域生成制定为双层优化,并建议优化一组视觉上无法区分的干净标签修改数据,其与来自难以广义域的域水印样本具有相似的效果,以确保水印的隐秘性。我们还通过域水印设计了一个假设检验引导的所有权验证,并提供了我们方法的理论分析。在三个基准数据集上进行了广泛的实验,验证了我们的方法的有效性及其对潜在自适应方法的抵抗力。 |
| Reference-based Restoration of Digitized Analog Videotapes Authors Lorenzo Agnolucci, Leonardo Galteri, Marco Bertini, Alberto Del Bimbo 几十年来,模拟磁带一直是主要的视频数据存储设备。存储在模拟录像带上的视频表现出由磁带老化和读取器设备故障引起的独特退化模式,这与在电影和数字视频恢复任务中观察到的情况不同。在这项工作中,我们提出了一种基于参考的方法来恢复数字化模拟录像带。我们利用 CLIP 进行零镜头伪影检测,通过描述不同伪影的文本提示来识别每个视频中最干净的帧。然后,我们选择与输入帧最相似的干净帧并将其用作参考。我们设计了一个基于变压器的 Swin UNet 网络,该网络通过我们的多参考空间特征融合 MRSFF 块利用相邻帧和参考帧。 MRSFF 块依靠交叉注意力和注意力池来利用每个参考帧中最有用的部分。为了解决现实世界视频中缺乏真实情况的问题,我们创建了一个视频合成数据集,其中展示的伪影与模拟录像带中常见的伪影非常相似。与其他最先进的方法相比,定量和定性实验都表明了我们的方法的有效性。 |
| Converting Depth Images and Point Clouds for Feature-based Pose Estimation Authors Robert L sch 1 , Mark Sastuba 2 , Jonas Toth 1 , Bernhard Jung 1 1 Technical University Bergakademie Freiberg, Germany, 2 German Centre for Rail Traffic Research at the Federal Railway Authority, Germany 近年来,深度传感器变得越来越便宜,并且已进入越来越多的机器人系统中。然而,单模态或多模态传感器配准通常是进一步处理的必要步骤,在原始深度图像或点云上面临着许多挑战。本文提出了一种将深度数据转换为能够可视化基本上隐藏在传统深度图像中的空间细节的图像的方法。去除噪声后,点的邻域形成两个法向量,其差异被编码到这个新的转换中。与方位角图像相比,我们的方法产生更明亮、对比度更高的图像,具有更明显的轮廓和更多细节。我们测试了视觉里程计任务和 RGB D SLAM 中基于特征的姿态估计转换。对于所有测试的特征,AKAZE、ORB、SIFT 和 SURF,我们的新 Flexion 图像比方位角图像产生更好的结果,并显示出弥合深度数据和经典计算机视觉之间差距的巨大潜力。 |
| GRLib: An Open-Source Hand Gesture Detection and Recognition Python Library Authors Jan Warchocki, Mikhail Vlasenko, Yke Bauke Eisma 手势识别系统为人类与计算机系统交互提供了一种自然的方式。尽管针对此任务设计了各种算法,但许多外部条件(例如光线不足或距相机的距离)使得创建在各种环境中表现良好的算法变得困难。在这项工作中,我们提出了 GRLib 一个开源 Python 库,能够检测和分类静态和动态手势。此外,该库可以根据现有数据进行训练,以提高分类的鲁棒性。所提出的解决方案利用 RGB 相机的反馈。然后,检索到的帧经过数据增强并传递到 MediaPipe Hands 以执行手部标志检测。然后将这些地标分类到它们各自的手势类别中。该库通过轨迹和关键帧提取支持动态手势。结果发现,该库在三个不同的现实世界数据集上优于另一个公开的 HGR 系统 MediaPipe Solutions。 |
| ARNIQA: Learning Distortion Manifold for Image Quality Assessment Authors Lorenzo Agnolucci, Leonardo Galteri, Marco Bertini, Alberto Del Bimbo 无参考图像质量评估 NR IQA 旨在开发无需高质量参考图像即可测量与人类感知一致的图像质量的方法。在这项工作中,我们提出了一种名为 ARNIQA 学习失真流形的图像质量评估自监督方法,用于对图像失真流形进行建模,以内在的方式获得质量表示。首先,我们引入一种图像退化模型,该模型随机组成连续应用的失真的有序序列。通过这种方式,我们可以对具有多种降级模式的图像进行综合降级。其次,我们建议通过最大化不同图像块的表示之间的相似性来训练我们的模型,尽管内容不同,但相同地扭曲的不同图像的块的表示之间的相似性。因此,以相同方式劣化的图像对应于失真流形内的相邻位置。最后,我们使用简单的线性回归器将图像表示映射到质量分数,因此无需微调编码器权重。实验表明,我们的方法在多个数据集上实现了最先进的性能。此外,与竞争方法相比,ARNIQA 展示了更高的数据效率、泛化能力和鲁棒性。 |
| Object Pose Estimation Annotation Pipeline for Multi-view Monocular Camera Systems in Industrial Settings Authors Hazem Youssef, Frederik Polachowski, J r me Rutinowski, Moritz Roidl, Christopher Reining 在仓库和生产设施等大型工业空间中,对象定位,更具体地说是对象姿态估计,对于物料流操作至关重要。传统方法依赖于安装在环境中的人工制品或过于昂贵的设备,这不适合大规模使用。一种更实用的方法是利用此类空间中的现有摄像机来解决潜在的姿态估计问题并定位感兴趣的对象。为了利用深度学习中最先进的方法进行物体姿态估计,需要收集和注释大量数据。在这项工作中,我们提供了一种无需手工劳动即可注释大型单目图像数据集的方法。我们的方法将摄像机定位在空间中,将其位置与运动捕捉系统统一,并使用一组线性映射将感兴趣对象的 3D 模型投影到其地面实况 6D 姿势位置。我们在模仿预期操作区域的工业环境中的八个摄像头系统收集的自定义数据集上测试我们的管道。 |
| Orientation-Aware Leg Movement Learning for Action-Driven Human Motion Prediction Authors Chunzhi Gu, Chao Zhang, Shigeru Kuriyama 动作驱动的人体运动预测的任务旨在根据观察到的序列预测未来的人体运动,同时尊重给定的动作标签。它不仅需要对人体运动的随机性进行建模,还需要对多个动作标签之间的平滑而现实的过渡进行建模。然而,大多数数据集不包含此类转换数据这一事实使这项任务变得复杂。现有的工作通过在简单地促进平滑过渡之前学习平滑度来解决这个问题,但这样做可能会导致不自然的过渡,特别是当历史运动和预测运动在方向上显着不同时。在本文中,我们认为有效的人体运动转换应该结合现实的腿部运动来处理方向变化,并将其作为 ACB 学习任务之间的条件动作,以鼓励转换的自然性。由于对所有可能的转换进行建模实际上是不合理的,因此我们的 ACB 仅在极少数具有主动步态运动的选定动作类上执行,例如步行或跑步。具体来说,我们遵循两阶段预测策略,首先采用运动扩散模型生成具有指定未来动作的目标运动,然后产生中间层以平滑连接观察和预测,最终解决运动预测问题。我们的方法在训练期间完全不受标记的运动转换数据的影响。为了展示我们方法的稳健性,我们将在一个数据集上训练的学习模型推广到两个看不见的大规模运动数据集以产生自然过渡。 |
| 3M-TRANSFORMER: A Multi-Stage Multi-Stream Multimodal Transformer for Embodied Turn-Taking Prediction Authors Mehdi Fatan, Emanuele Mincato, Dimitra Pintzou, Mariella Dimiccoli 预测多方对话中的轮流在人机机器人交互中具有许多实际应用。然而,人类沟通的复杂性使其成为一项具有挑战性的任务。最近的进展表明,与异步、单视角转录相比,同步多视角自我中心数据可以显着改善轮流预测。基于这项研究,我们提出了一种新的基于多模态变压器的架构,用于预测具体的、同步的多视角数据中的轮流。我们在最近引入的 EgoCom 数据集上的实验结果显示,与现有基线和基于 Transformer 的替代方法相比,平均性能大幅提高,高达 14.01。 |
| ESVAE: An Efficient Spiking Variational Autoencoder with Reparameterizable Poisson Spiking Sampling Authors Qiugang Zhan, Xiurui Xie, Guisong Liu, Malu Zhang 近年来,尖峰神经网络SNN的图像生成模型的研究引起了许多研究人员的关注。变分自编码器 VAE 作为最流行的图像生成模型之一,吸引了大量研究其 SNN 实现的工作。由于 SNN 中的二进制表示受到限制,现有的 SNN VAE 方法通过精心设计的自回归网络隐式构造潜在空间,并使用网络输出作为采样变量。然而,这种未指定的潜在空间隐式表示会增加生成高质量图像的难度,并引入额外的网络参数。在本文中,我们提出了一种高效的尖峰变分自动编码器ESVAE,它构造了一个可解释的潜在空间分布,并设计了一种可重新参数化的尖峰采样方法。具体来说,我们使用尖峰神经元的放电率将潜在空间的先验和后验构造为泊松分布。随后,我们提出了一种可重新参数化的泊松尖峰采样方法,该方法无需额外的网络。进行了全面的实验,实验结果表明,所提出的 EVAE 在重建生成图像质量方面优于先前的 SNN VAE 方法。此外,实验表明ESVAE的编码器能够更有效地保留原始图像信息,并且解码器更鲁棒。 |
| Deep learning denoiser assisted roughness measurements extraction from thin resists with low Signal-to-Noise Ratio(SNR) SEM images: analysis with SMILE Authors Sara Sacchi, Bappaditya Dey, Iacopo Mochi, Sandip Halder, Philippe Leray 高数值孔径极紫外光刻高NA EUVL技术的进步为30nm以下更薄光刻胶的广泛研究打开了大门,这对于高NA EUVL的工业实施是必要的。因此,扫描电子显微镜 SEM 的图像会受到成像对比度降低和信噪比 SNR 较低的影响,影响无偏线边缘粗糙度 uLER 和线宽粗糙度 uLWR 的测量。因此,这项工作的目的是通过使用深度学习降噪器来增强 SEM 图像的信噪比,并实现薄抗蚀剂的稳健粗糙度提取。在本研究中,我们使用不同厚度 15nm、20nm、25nm、30nm、底层旋涂玻璃 SOG、有机底层 OUL 以及平均 4、8、16、32 的框架,使用化学放大抗蚀剂 CAR 获取了线间距 L S 图案的 SEM 图像。和 64 Fr 。去噪后,使用开源计量软件 SMILE 2.3.2 对噪声和去噪图像进行了系统分析,以研究平均 CD、SNR 改进因子、有偏和无偏 LWR LER 功率谱密度 PSD。具有较低帧数的去噪图像呈现出未改变的关键尺寸 CD、增强的 SNR(特别是对于低数量的集成帧)以及 uLER 和 uLWR 的精确测量,其精度与具有一致较高帧数的噪声图像相同。 |
| Large Language Models can Share Images, Too! Authors Young Jun Lee, Jonghwan Hyeon, Ho Jin Choi 本文探讨了大型语言模型 LLM(例如 InstructGPT、ChatGPT 和 GPT 4)在零镜头设置下的图像共享功能,无需视觉基础模型的帮助。受人类对话中图像共享的两阶段过程的启发,我们提出了一个两阶段框架,允许法学硕士预测潜在的图像共享回合,并使用我们基于有效限制的提示模板生成相关的图像描述。通过大量实验,我们在零镜头提示中解锁了 LLM 的 textit 图像共享功能,其中 GPT 4 实现了最佳性能。此外,我们还发现了零镜头提示中的新兴文本图像共享功能,证明了基于限制的提示在我们框架的两个阶段中的有效性。基于这个框架,我们用稳定扩散在预测转弯时生成的图像来增强 PhotoChat 数据集,即 PhotoChat 。据我们所知,这是第一项在没有视觉基础模型的情况下评估法学硕士在零镜头设置下的图像共享能力的研究。 |
| Vision-Enhanced Semantic Entity Recognition in Document Images via Visually-Asymmetric Consistency Learning Authors Hao Wang, Xiahua Chen, Rui Wang, Chenhui Chu 从文档 VFD 等视觉丰富的表单中提取属于预定义类别的有意义的实体是一项具有挑战性的任务。视觉和布局特征(例如字体、背景、颜色以及边界框位置和大小)为识别相同类型的实体提供了重要线索。然而,现有模型通常使用弱跨模式监督信号来训练视觉编码器,导致捕获这些非文本特征的能力有限且性能不佳。在本文中,我们提出了一种新颖的 textbf V isually textbf A 对称 co textbf N sisten textbf C y textbf L 赚钱 textsc Vancl 方法,该方法通过结合以下内容来增强模型捕获细粒度视觉和布局特征的能力,从而解决上述限制:颜色先验。基准数据集上的实验结果表明,我们的方法大大优于强大的 LayoutLM 系列基线,证明了我们方法的有效性。此外,我们还研究了不同配色方案对我们方法的影响,为优化模型性能提供了见解。 |
| Dance Your Latents: Consistent Dance Generation through Spatial-temporal Subspace Attention Guided by Motion Flow Authors Haipeng Fang, Zhihao Sun, Ziyao Huang, Fan Tang, Juan Cao, Sheng Tang 生成式人工智能的进步已经扩展到人类舞蹈生成领域,展示了卓越的生成能力。然而,当前的方法在实现时空一致性方面仍然存在缺陷,导致重影、闪烁和不连贯运动等伪影。在本文中,我们提出了 Dance Your Latents,这是一个框架,可以使潜在对象按照运动流连贯地跳舞,以生成一致的舞蹈视频。首先,考虑到每个组成元素在有限的空间内移动,我们引入时空子空间注意块,将全局空间分解为规则子空间的组合,并有效地建模这些子空间内的时空一致性。该模块使每个补丁能够关注相邻区域,从而减轻远距离注意力的过度分散。此外,观察到身体部位的运动是由姿势控制引导的,我们设计了运动流引导的子空间对齐恢复。该方法使得能够在沿着运动流的不规则子空间上计算注意力。 |
| SAMCLR: Contrastive pre-training on complex scenes using SAM for view sampling Authors Benjamin Missaoui, Chongbin Yuan 在计算机视觉中,自监督对比学习在同一图像的不同视图之间强制执行相似的表示。预训练最常在图像分类数据集上执行,例如 ImageNet,其中图像主要包含单一类别的对象。然而,当处理具有多个项目的复杂场景时,同一图像的多个视图不太可能代表相同的对象类别。在这种情况下,我们提出了 SAMCLR,它是 SimCLR 的一个附加组件,它使用 SAM 将图像分割成语义区域,然后从同一区域对两个视图进行采样。 |
| MAS: Multi-view Ancestral Sampling for 3D motion generation using 2D diffusion Authors Roy Kapon, Guy Tevet, Daniel Cohen Or, Amit H. Bermano 我们引入了多视图祖先采样 MAS,这是一种生成运动序列的一致多视图 2D 样本的方法,从而能够创建其 3D 对应项。 MAS 利用仅在 2D 数据上训练的扩散模型,为之前由于 3D 数据稀缺且难以收集而被探索的令人兴奋和多样化的运动领域提供了机会。 MAS 的工作原理是同时对表示不同角度相同运动的多个 2D 运动序列进行去噪。我们的一致性块通过将各个代组合成统一的 3D 序列,并将其投影回原始视图以进行下一次迭代,确保每个扩散步骤中所有视图的一致性。我们在 2D 姿态数据上演示了 MAS,这些数据是从描述专业篮球动作、以球类器械为特色的艺术体操表演以及马匹障碍赛的视频中获取的。在这些领域中的每一个领域,3D 动作捕捉都是艰巨的,然而,MAS 无需文本调节即可生成多样化且逼真的 3D 序列。 |
| Rethinking Scale Imbalance in Semi-supervised Object Detection for Aerial Images Authors Ruixiang Zhang, Chang Xu, Fang Xu, Wen Yang, Guangjun He, Huai Yu, Gui Song Xia 本文主要研究航空图像中半监督目标检测SSOD的尺度不平衡问题。与自然图像相比,航拍图像中的物体尺寸更小,每幅图像的数量更大,增加了手动标注的难度。同时,先进的SSOD技术可以利用有限的标记数据和大量未标记数据来训练高级检测器,从而节省注释成本。然而,作为航空图像中一项未被充分研究的任务,SSOD 在面对大量小物体时会出现性能急剧下降的问题。通过分析小目标和大目标之间的预测,我们发现了由尺度偏差引起的三个不平衡问题,即伪标签不平衡、标签分配不平衡和负学习不平衡。为了解决这些问题,我们提出了一种新颖的航空图像尺度判别半监督对象检测 S 3OD 学习流程。在我们的 S 3OD 中,提出了三个关键组件,即大小感知自适应阈值 SAT、大小重新平衡的标签分配 SLA 和教师引导的负向学习 TNL,以保证规模无偏学习。具体来说,SAT 自适应地选择适当的阈值来过滤不同尺度对象的伪标签。 SLA通过重采样和重新加权来平衡不同尺度对象的正样本。 TNL 通过利用教师模型生成的信息来缓解负样本的不平衡。在 DOTA v1.5 基准上进行的大量实验证明了我们提出的方法相对于最先进的竞争对手的优越性。 |
| BM2CP: Efficient Collaborative Perception with LiDAR-Camera Modalities Authors Binyu Zhao, Wei Zhang, Zhaonian Zou 协作感知使代理能够与附近的代理共享互补的感知信息。这将提高感知性能并缓解单视图感知的问题,例如遮挡和稀疏。大多数现有方法主要集中于单一模态尤其是激光雷达,并没有充分发挥多模态感知的优势。我们提出了一种协作感知范式 BM2CP,它采用 LiDAR 和摄像头来实现高效的多模态感知。它利用激光雷达引导模态融合、协作深度生成和模态引导中间融合来获取不同智能体模态之间的深度交互,此外,它能够应对任何智能体的相同或不同类型的传感器之一的特殊情况不见了。大量实验验证了我们的方法优于最先进的方法,在模拟和现实世界的自动驾驶场景中通信量降低了 50 倍。 |
| Interaction-Driven Active 3D Reconstruction with Object Interiors Authors Zihao Yan, Fubao Su, Mingyang Wang, Ruizhen Hu, Hao Zhang, Hui Huang 我们引入了一种主动 3D 重建方法,该方法集成了视觉感知、机器人对象交互和 3D 扫描,以恢复目标 3D 对象的外部和内部(即未暴露的几何形状)。与主动视觉领域的其他工作不同,这些工作侧重于优化相机视角以更好地研究环境,我们重建的主要特点是分析目标物体各个部分的交互性以及机器人随后进行的部分操作,以扫描被遮挡的物体。地区。因此,在完整的几何采集的基础上,可以获得对目标对象的部分关节的理解。我们的方法由带有内置 RGBD 传感器的 Fetch 机器人全自动运行。它在交互分析和交互驱动重建之间进行迭代,一次扫描和重建检测到的可移动部件,其中铰接部件检测和网格重建都是由神经网络执行的。在最后一步中,重建所有剩余的非铰接部件,包括通过先前部件操作暴露并随后扫描的所有内部结构,以完成采集。 |
| CAwa-NeRF: Instant Learning of Compression-Aware NeRF Features Authors Omnia Mahmoud, Th o Ladune, Matthieu Gendrin 通过体积特征网格对 3D 场景进行建模是神经近似改善神经辐射场 NeRF 的有前途的方向之一。即时 NGP IGP 从可训练特征网格的查找表中引入了多分辨率哈希编码,从而可以在几秒钟内学习高质量的神经图形基元。然而,这种改进是以更大的存储大小为代价的。在本文中,我们通过引入压缩感知 NeRF 特征 CAwa NeRF 的即时学习来解决这一挑战,它允许在模型训练结束时导出 zip 压缩特征网格,额外时间开销可以忽略不计,而无需更改存储架构和参数用于原始INGP论文中。尽管如此,所提出的方法并不限于INGP,还可以适用于任何模型。通过广泛的模拟,我们提出的即时学习管道可以在不同类型的静态场景上取得令人印象深刻的结果,例如单个对象蒙版背景场景和在我们工作室捕获的现实生活场景。 |
| On Partial Shape Correspondence and Functional Maps Authors Amit Bracha, Thomas Dag s, Ron Kimmel 在处理形状与零件的匹配时,我们经常使用一种称为功能图的工具。这个想法是将形状匹配问题转化为方便的空间,通过求解最小二乘问题以代数方式执行匹配。在这里,我们认为这种表述虽然在该领域很流行,但在调用偏倚时会在估计匹配中引入错误。即使考虑先进的特征提取网络,此类错误也是不可避免的,并且它们会随着形状偏爱程度的增加而升级,从而对此类系统的学习能力产生不利影响。 |
| Online Out-of-Domain Detection for Automated Driving Authors Timo S mann, Horst Michael Gro 确保自动驾驶的安全是汽车行业面临的重大挑战。特别关注人工智能,特别是深度神经网络DNN,它被认为是实现高度自动驾驶的关键技术。 DNN 从训练数据中学习,这意味着它们只能在训练数据的基础数据分布内实现良好的准确性。当离开训练域时,会引起分布变化,这可能导致准确性急剧下降。在这项工作中,我们提出了一种安全机制的概念证明,该机制可以在线(即在运行时)检测域的离开。在我们使用 Synthia 数据集进行的实验中,我们可以证明可以正确检测输入数据是在域内还是在域外。 |
| Invariant Feature Regularization for Fair Face Recognition Authors Jiali Ma, Zhongqi Yue, Kagaya Tomoyuki, Suzuki Tomoki, Karlekar Jayashree, Sugiri Pranata, Hanwang Zhang 公平的人脸识别就是学习不变的特征,该特征可以推广到任何人口群体中看不见的面孔。不幸的是,人脸数据集不可避免地会捕获现实世界观察中普遍存在的不平衡人口统计属性,并且该模型学习到的有偏见的特征在少数群体中概括性较差。我们指出,偏差是由于混杂的人口统计属性而产生的,这会误导模型捕捉虚假的人口统计特定特征。混杂效应只能通过因果干预来消除,这需要混杂注释。然而,由于人口统计属性的多样性,此类注释可能非常昂贵。为了解决这个问题,我们建议以无监督的方式迭代生成不同的数据分区。每个数据分区都充当自注释混杂因素,使我们的不变特征正则化 INV REG 能够解混杂。 INV REG 与现有方法正交,并将 INV REG 与两个强大的基线 Arcface 和 CIFP 相结合,带来了新的技术水平,可改善各种人口群体的人脸识别。 |
| Relit-NeuLF: Efficient Relighting and Novel View Synthesis via Neural 4D Light Field Authors Zhong Li, Liangchen Song, Zhang Chen, Xiangyu Du, Lele Chen, Junsong Yuan, Yi Xu 在本文中,我们解决了使用有限数量的光源从多视图图像中同时重新照明和新颖的视图合成复杂场景的问题。我们提出了一种称为 Relit NeuLF 的分析综合方法。继最近的神经 4D 光场网络 NeuLF 之后,Relit NeuLF 首先利用两个平面光场表示来参数化 4D 坐标系中的每条光线,从而实现高效的学习和推理。然后,我们以自监督的方式恢复 3D 场景的空间变化双向反射率分布函数 SVBRDF。 DecomposeNet 学习将每条光线映射到其 SVBRDF 组件反照率、法线和粗糙度。基于分解的 BRDF 组件和调节光线方向,RenderNet 学习合成光线的颜色。为了自我监督 SVBRDF 分解,我们鼓励使用微面模型预测的光线颜色接近基于物理的渲染结果。综合实验表明,所提出的方法在合成数据和现实世界人脸数据上都是高效且有效的,并且优于最先进的结果。我们在 GitHub 上公开发布了我们的代码。 |
| Semantic-Aware Adversarial Training for Reliable Deep Hashing Retrieval Authors Xu Yuan, Zheng Zhang, Xunguang Wang, Lin Wu 深度哈希由于其效率和有效性而被深入研究并成功应用于大规模图像检索系统。最近的研究认识到,对抗性样本的存在对深度哈希模型构成了安全威胁,即对抗性漏洞。值得注意的是,有效地提取深度哈希的可靠语义代表来指导对抗性学习具有挑战性,从而阻碍了基于深度哈希的检索模型的对抗鲁棒性的增强。此外,当前针对深度哈希的对抗训练的研究很难形式化为统一的极小极大结构。在本文中,我们探索语义感知对抗训练 SAAT,以提高深度哈希模型的对抗鲁棒性。具体来说,我们构想了一种判别性的主要特征学习 DMFL 方案来构建语义代表,以指导深度哈希中的对抗性学习。特别是,我们的 DMFL 具有严格的理论保证,以判别学习方式自适应优化,同时考虑判别属性和语义属性。此外,通过最大化对抗样本的哈希码与主要特征之间的汉明距离来制造对抗样本,其有效性在对抗攻击试验中得到了验证。此外,我们首次在生成的主要代码的指导下将深度哈希的形式化对抗训练制定为统一的极小极大优化。对基准数据集的大量实验显示了针对最先进算法的卓越攻击性能,同时,所提出的对抗性训练可以有效消除对抗性扰动,从而实现基于可信深度哈希的检索。 |
| Pre-Training LiDAR-Based 3D Object Detectors Through Colorization Authors Tai Yu Pan, Chenyang Ma, Tianle Chen, Cheng Perng Phoo, Katie Z Luo, Yurong You, Mark Campbell, Kilian Q. Weinberger, Bharath Hariharan, Wei Lun Chao 自动驾驶汽车的准确 3D 物体检测和理解在很大程度上依赖于 LiDAR 点云,需要大量标记数据进行训练。在这项工作中,我们引入了一种创新的预训练方法,即接地点着色 GPC,通过教导模型对 LiDAR 点云进行着色,为其配备有价值的语义线索,从而弥合数据和标签之间的差距。为了解决颜色变化和选择偏差带来的挑战,我们通过在着色过程中提供地面真实颜色作为提示,将颜色作为上下文。在 KITTI 和 Waymo 数据集上的实验结果证明了 GPC 的显着有效性。即使标记数据有限,GPC 也能显着提高微调性能,尤其是在 20 个 KITTI 数据集上,GPC 的性能优于从头开始使用整个数据集进行的训练。 |
| Leveraging Image-Text Similarity and Caption Modification for the DataComp Challenge: Filtering Track and BYOD Track Authors Shuhei Yokoo, Peifei Zhu, Yuchi Ishikawa, Mikihiro Tanaka, Masayoshi Kondo, Hirokatsu Kataoka 大型网络爬取数据集已经在学习具有高泛化能力的多模态特征方面发挥了重要作用。然而,调查数据设计细节或改进的研究仍然非常有限。最近,DataComp 挑战赛旨在通过固定模型提出最佳训练数据。本文介绍了我们针对 DataComp 挑战的过滤跟踪和 BYOD 跟踪的解决方案。我们的解决方案采用大型多模态模型 CLIP 和 BLIP 2 来过滤和修改网络爬行数据,并利用外部数据集和一系列技巧来提高数据质量。 |
| DICE: Diverse Diffusion Model with Scoring for Trajectory Prediction Authors Younwoo Choi, Ray Coden Mercurius, Soheil Mohamad Alizadeh Shabestary, Amir Rasouli 对于自动驾驶等各种应用来说,动态环境中的道路用户轨迹预测是一项具有挑战性但至关重要的任务。该领域的主要挑战之一是未来轨迹的多模态性质,这源于代理未知但不同的意图。扩散模型已被证明在捕捉预测任务中的这种随机性方面非常有效。然而,这些模型涉及许多计算成本高昂的降噪步骤和采样操作,这使得它们成为实时安全关键应用不太理想的选择。为此,我们提出了一个新颖的框架,利用扩散模型以计算有效的方式预测未来的轨迹。为了最大限度地减少迭代采样中的计算瓶颈,我们采用了一种高效的采样机制,使我们能够最大限度地增加采样轨迹的数量,以提高准确性,同时保持实时推理时间。此外,我们提出了一种评分机制,通过分配相对排名来选择最合理的轨迹。 |
| HallusionBench: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V(ision), LLaVA-1.5, and Other Multi-modality Models Authors Fuxiao Liu, Tianrui Guan, Zongxia Li, Lichang Chen, Yaser Yacoob, Dinesh Manocha, Tianyi Zhou 大型语言模型 LLM 在与视觉模型对齐并集成到视觉语言模型 VLM 中后,可以为图像推理任务带来令人印象深刻的改进。最近发布的 GPT 4V ison 、LLaVA 1.5 等都证明了这一点。然而,这些 SOTA LVLM 中的强语言先验可能是一把双刃剑,它们可能会忽略图像上下文,而仅依赖甚至矛盾的语言先验进行推理。相比之下,VLM 中的视觉模块比 LLM 弱,可能会导致误导性的视觉表示,然后由 LLM 转化为自信的错误。为了研究这两类 VLM 错误,即语言幻觉和视觉幻觉,我们策划了 HallusionBench,这是一个图像上下文推理基准,即使对 GPT 4V 和 LLaVA 1.5 来说仍然具有挑战性。我们对 HallusionBench 中的示例进行了详细分析,为 VLM 的幻觉或幻觉以及未来如何改进它们提供了新颖的见解。 |
| F$^2$AT: Feature-Focusing Adversarial Training via Disentanglement of Natural and Perturbed Patterns Authors Yaguan Qian, Chenyu Zhao, Zhaoquan Gu, Bin Wang, Shouling Ji, Wei Wang, Boyang Zhou, Pan Zhou 深度神经网络 DNN 很容易受到精心设计的扰动精心设计的对抗性示例的影响。这可能会给自动驾驶汽车、监控安全和医疗诊断等关键应用带来灾难性的结果。目前,对抗性训练是对抗对抗性例子最有效的防御之一。然而,传统的对抗性训练很难在准确率和鲁棒性之间取得良好的平衡,因为 DNN 仍然会学习虚假特征。其内在原因是,当对抗性噪音和干净的例子无法分离时,传统的对抗性训练很难从对抗性例子中充分学习核心特征。在本文中,我们通过位平面切片将对抗性示例分解为自然模式和扰动模式。我们假设较高位平面代表自然模式,较低位平面代表扰动模式。我们提出了一种特征聚焦对抗训练 F 2 AT ,它与之前的工作不同,它强制模型关注自然模式的核心特征,并减少扰动模式的虚假特征的影响。 |
| Polyhedral Surface: Self-supervised Point Cloud Reconstruction Based on Polyhedral Surface Authors Hui Tian, Kai Xu 几十年来,从原始点云重建点云一直是计算机图形学的一个重要主题,特别是由于其在建模和渲染应用程序中的高需求。解决这个问题的一个重要方法是建立局部几何形状来拟合局部曲线。然而,以前的方法要么构建局部平面,要么构建多项式曲线。局部平面带来了开放表面上锐利特征和边界伪影的损失。多项式曲线由于局部坐标一致问题,很难与神经网络结合。为了解决这个问题,我们提出了一种新颖的多面体表面来表示局部表面。该方法可以更灵活地表示开放表面上的尖锐特征和表面边界。它不需要任何局部坐标系,这在引入神经网络时很重要。具体来说,我们使用法线来构造多面体表面,包括分别使用 2 个和 3 个法线的二面体和三面体表面。我们的方法在三个常用数据集 ShapeNetCore、ABC 和 ScanNet 上取得了最先进的结果。 |
| S3Aug: Segmentation, Sampling, and Shift for Action Recognition Authors Taiki Sugiura, Toru Tamaki 动作识别是计算机视觉中一个成熟的研究领域。在本文中,我们提出了 S3Aug,一种用于动作识别的视频数据增强。与涉及从两个视频剪切和粘贴区域的传统视频数据增强方法不同,所提出的方法通过分割和标签到图像转换从单个训练视频生成新视频。此外,所提出的方法通过采样修改某些类别的标签图像以生成各种视频,并移动中间特征以增强生成视频的帧之间的时间一致性。 |
| Practical Deep Dispersed Watermarking with Synchronization and Fusion Authors Hengchang Guo, Qilong Zhang, Junwei Luo, Feng Guo, Wenbin Zhang, Xiaodong Su, Minglei Li 基于深度学习的盲水印作品逐渐涌现并取得了骄人的成绩。然而,以往的深度水印研究主要集中在固定的低分辨率图像,而对任意分辨率图像的关注较少,尤其是当今广泛使用的高分辨率图像。此外,大多数作品通常都表现出针对典型非几何攻击的鲁棒性,例如文本攻击。 ,JPEG 压缩但忽略常见的几何攻击 textit 例如、旋转以及更具挑战性的组合攻击。为了克服上述限制,我们提出了一种实用的深度textbf分散textbf水印,具有textbf同步和textbf融合,称为textbf提议。具体来说,给定任意分辨率的覆盖图像,我们采用分散嵌入方案,该方案稀疏且随机地选择几个固定的小尺寸覆盖块,以通过训练有素的编码器嵌入一致的水印消息。在提取阶段,我们首先设计一个水印同步模块来定位和校正噪声水印图像中的编码块。然后,我们利用解码器获取嵌入在这些块中的消息,并提出基于相似性的消息融合策略,以充分利用消息之间的一致性,从而确定可靠的消息。在不同数据集上进行的广泛实验令人信服地证明了我们提出的建议的有效性。与最先进的方法相比,我们的盲水印可以实现更好的性能,针对单一攻击和组合攻击,比特精度平均分别提高 5.28 和 5.93,并且显示出更少的文件大小增量和更好的视觉质量。 |
| Poster: Real-Time Object Substitution for Mobile Diminished Reality with Edge Computing Authors Hongyu Ke, Haoxin Wang 缩小现实 DR 被认为是增强现实 AR 的概念对应物,最近受到工业界和学术界越来越多的关注。与 AR 将虚拟对象添加到现实世界不同,DR 允许用户从现实世界中删除物理内容。当与对象替换技术相结合时,它为元宇宙中的探索提供了更令人兴奋的途径。尽管已经对对象替换和灾难恢复的交叉进行了一些研究,但还没有高质量的移动减现实架构的实时对象替换。 |
| ADoPT: LiDAR Spoofing Attack Detection Based on Point-Level Temporal Consistency Authors Minkyoung Cho, Yulong Cao, Zixiang Zhou, Z. Morley Mao 深度神经网络 DNN 越来越多地集成到自动驾驶汽车 AV 的基于 LiDAR 光检测和测距的感知系统中,需要在对抗条件下具有强大的性能。我们的目标是解决 LiDAR 欺骗攻击的挑战,即攻击者将虚假物体注入 LiDAR 数据中,并欺骗自动驾驶汽车误解其环境并做出错误的决策。然而,当前的防御算法主要依赖于感知输出,即边界框,因此在检测攻击者时面临局限性,因为边界框是由不完善的感知模型处理有限点生成的,这些有限点是基于自我车辆的视点获取的。为了克服这些限制,我们提出了一种新颖的框架,名为基于点级时间一致性的 ADoPT 异常检测,它定量测量连续帧之间的时间一致性,并根据点簇的一致性识别异常对象。在我们使用 nuScenes 数据集的评估中,我们的算法有效地抵御了各种 LiDAR 欺骗攻击,实现了低 10 的误报率 FPR 和高 85 的真报率 TPR,优于现有最先进的防御方法 CARLO 和 3D TC2。 |
| MSFormer: A Skeleton-multiview Fusion Method For Tooth Instance Segmentation Authors Yuan Li, Huan Liu, Yubo Tao, Xiangyang He, Haifeng Li, Xiaohu Guo, Hai Lin 最近,基于深度学习的牙齿分割方法受到昂贵且耗时的数据收集和标记过程的限制。用有限的数据集实现高精度分割至关重要。对此的可行解决方案需要微调基于预训练的多视图模型,从而提高有限数据的性能。然而,仅仅依靠二维 2D 图像进行三维 3D 牙齿分割可能会因为咬合和变形(即形状感知不完整和扭曲)而产生次优结果。为了改进这种基于微调的解决方案,本文提倡 2D 3D 联合感知。在有限数据下采用 2D 3D 联合感知的根本挑战是 3D 相关输入和模块必须遵循轻量级策略,而不是使用需要大量训练数据的庞大 3D 数据和参数丰富的模块。遵循这种轻量级策略,本文选择骨骼作为 3D 输入,并引入 MSFormer,这是一种新颖的牙齿分割方法。 MSFormer 将两个轻量级模块合并到现有的基于多视图的模型中:一个 3D 骨骼感知模块,用于从骨骼中提取 3D 感知;一个骨骼图像对比学习模块,通过融合多视图和骨骼感知来获得 2D 3D 联合感知。实验结果表明,MSFormer 与大型预训练多视图模型相结合即可实现最先进的性能,仅需要 100 个训练网格。 |
| VQ-NeRF: Vector Quantization Enhances Implicit Neural Representations Authors Yiying Yang, Wen Liu, Fukun Yin, Xin Chen, Gang Yu, Jiayuan Fan, Tao Chen 隐式神经表征的最新进展有助于高保真表面重建和逼真的新颖视图合成。然而,这些方法固有的计算复杂性构成了很大的障碍,限制了实际应用中可达到的帧速率和分辨率。为了应对这种困境,我们提出了 VQ NeRF,这是一种通过矢量量化增强隐式神经表示的有效且高效的管道。我们方法的本质是将 NeRF 的采样空间降低到较低的分辨率,然后利用预先训练的 VAE 解码器将其恢复到原始大小,从而有效缓解渲染过程中遇到的采样时间瓶颈。尽管码本提供了代表性特征,但由于高压缩率,重建场景的精细纹理细节仍然具有挑战性。为了克服这一限制,我们设计了一种创新的多尺度 NeRF 采样方案,该方案同时在压缩和原始尺度上优化 NeRF 模型,以增强网络保留精细细节的能力。此外,我们结合了语义损失函数来提高 3D 重建的几何保真度和语义连贯性。大量的实验证明了我们的模型在实现渲染质量和效率之间的最佳权衡方面的有效性。 |
| Player Re-Identification Using Body Part Appearences Authors Mahesh Bhosale, Abhishek Kumar, David Doermann 我们提出了一种神经网络架构,可以学习身体部位的外观以进行足球运动员的重新识别。我们的模型由两个流网络组成,一个流用于外观图提取,另一个用于身体部位图提取,以及一个生成和空间池化身体部位图的双线性池层。身体部位图的每个局部特征是通过相应的局部外观和身体部位描述符的双线性映射获得的。我们的新颖表示产生了鲁棒的图像匹配特征图,这是通过将相关身体部位的局部相似性与加权外观相似性相结合而产生的。我们的模型不需要在 SoccerNet V3 重新识别数据集上进行任何部分注释来训练网络。相反,我们使用现有姿态估计网络 OpenPose 的子网络来初始化部分子流,然后训练整个网络以最小化三元组损失。外观流在 ImageNet 数据集上进行预训练,部分流在 SoccerNet V3 数据集上从头开始训练。 |
| Skipped Feature Pyramid Network with Grid Anchor for Object Detection Authors Li Pengfei, Wei Wei, Yan Yu, Zhu Rong, Zhou Liguo 近年来,基于 CNN 的目标检测方法取得了重大进展。由于池化或其他重新缩放操作,CNN 的经典结构会产生类似金字塔的特征图。特征金字塔不同级别的特征图用于检测不同尺度的目标。为了更准确的目标检测,具有最低分辨率并包含最强语义的最高级别特征被放大并与较低级别特征连接以增强较低级别特征中的语义。然而,经典的特征连接模式将较低级别的特征与其之上的所有特征结合起来,这可能会导致语义退化。在本文中,我们提出了一种跳过连接,以在特征金字塔的每个级别获得更强的语义。在我们的方法中,较低级别的特征仅与最高级别的特征连接,使得每个级别负责检测具有固定尺度的对象更加合理。此外,我们简化了边界框回归的anchor的生成,这可以进一步提高目标检测的准确性。 |
| Mobile AR Depth Estimation: Challenges & Prospects -- Extended Version Authors Ashkan Ganj, Yiqin Zhao, Hang Su, Tian Guo 度量深度估计在移动增强现实 AR 中发挥着重要作用。通过准确的度量深度,我们可以实现更真实的用户交互,例如对象放置和遮挡检测。虽然激光雷达等专用硬件展现了其前景,但其可用性有限(即仅在选定的高端移动设备上),并且范围和环境敏感性等性能限制使其不太理想。 |
| ConViViT -- A Deep Neural Network Combining Convolutions and Factorized Self-Attention for Human Activity Recognition Authors Rachid Reda Dokkar, Faten Chaieb, Hassen Drira, Arezki Aberkane Transformer 架构由于其泛化和捕获长范围依赖关系的能力而在计算机视觉任务中获得了广泛的欢迎。这一特性使其非常适合从视频生成时空标记。另一方面,卷积是处理图像和视频的基本支柱,因为它们有效地聚合小型局部邻域内的信息,以创建描述视频空间维度的空间标记。虽然基于 CNN 的架构和纯 Transformer 架构都被研究人员广泛研究和利用,但这两种主干的有效组合在活动识别领域还没有受到同等的关注。在这项研究中,我们提出了一种新颖的方法,该方法在混合架构中利用 CNN 和 Transformer 的优势,使用 RGB 视频执行活动识别。具体来说,我们建议使用 CNN 网络通过生成 128 通道视频来增强视频表示,从而有效地将执行活动的人类与背景分开。随后,CNN 模块的输出被输入到变压器中以提取时空标记,然后将其用于分类目的。 |
| Vision Language Models in Autonomous Driving and Intelligent Transportation Systems Authors Xingcheng Zhou, Mingyu Liu, Bare Luka Zagar, Ekim Yurtsever, Alois C. Knoll 视觉语言模型VLM在自动驾驶AD和智能交通系统ITS领域的应用因其出色的性能和利用大语言模型LLM的能力而受到广泛关注。通过集成语言数据,车辆和交通系统能够深入了解现实世界环境,提高驾驶安全性和效率。在这项工作中,我们对该领域的语言模型的进展进行了全面的调查,包括当前的模型和数据集。此外,我们还探索潜在的应用和新兴的研究方向。最后,我们深入讨论了挑战和研究差距。 |
| A Pytorch Reproduction of Masked Generative Image Transformer Authors Victor Besnier, Mickael Chen 在本技术报告中,我们展示了使用 PyTorch 的 MaskGIT Masked Generative Image Transformer 的复制品。该方法涉及利用屏蔽双向变压器架构,只需 8 至 16 步即可生成 512 x 512 分辨率图像的图像,即比自回归方法快 64 倍。通过严格的实验和优化,我们取得了与原始论文中提出的结果紧密一致的结果。我们将报告的 FID 7.32 与我们的复制相匹配,并在分辨率 512 x 512 的 ImageNet 上获得具有类似超参数的 7.59。此外,我们通过一些小的超参数调整改进了官方实现,实现了 7.26 的 FID。在 256 x 256 像素的较低分辨率下,我们的重新实现得分为 6.80,而原始论文的得分为 6.18。 |
| Cross-Domain HAR: Few Shot Transfer Learning for Human Activity Recognition Authors Megha Thukral, Harish Haresamudram, Thomas Ploetz 带有集成惯性测量单元 IMU 的智能手机和智能手表随处可见,可以直接捕获人类活动。然而,对于基于传感器的人类活动识别 HAR 的特定应用,后勤挑战和迅速增长的成本尤其使得此类数据的地面实况注释变得困难,导致数据集的规模和多样性有限。迁移学习,即利用公开可用的标记数据集首先学习有用的表示,然后使用来自目标域的有限数量的标记数据进行微调,可以缓解当代 HAR 系统的一些性能问题。然而,当源条件和目标条件之间的差异太大或者目标应用领域中只有很少的样本可用时,它们可能会失败,这些都是现实世界人类活动识别场景中的典型挑战。在本文中,我们提出了一种经济地利用公开的标记 HAR 数据集进行有效迁移学习的方法。我们引入了一种新颖的迁移学习框架——跨域 HAR,它遵循师生自我训练范式,可以更有效地识别标签信息非常有限的活动。它弥合了源域和目标域之间的概念差距,包括传感器位置和活动类型。通过对一系列基准数据集进行广泛的实验评估,我们证明了我们的方法对于实际相关的少数镜头活动识别场景的有效性。 |
| OV-VG: A Benchmark for Open-Vocabulary Visual Grounding Authors Chunlei Wang, Wenquan Feng, Xiangtai Li, Guangliang Cheng, Shuchang Lyu, Binghao Liu, Lijiang Chen, Qi Zhao 开放词汇学习已成为一个前沿研究领域,特别是考虑到基于视觉的基础模型的广泛采用。其主要目标是理解未包含在预定义词汇中的新概念。这项工作的一个关键方面是视觉基础,它需要根据相应的语言描述来定位图像中的特定区域。虽然当前的基础模型在各种视觉语言任务上表现出色,但明显缺乏专门为开放词汇视觉基础量身定制的模型。这项研究工作引入了新颖且具有挑战性的 OV 任务,即开放词汇视觉基础和开放词汇短语本地化。总体目标是在语言描述和新物体的本地化之间建立联系。为了实现这一目标,我们策划了一个全面的带注释的基准测试,包含 7,272 个 OV VG 图像和 1,000 个 OV PL 图像。为了解决这些挑战,我们深入研究了植根于现有开放词汇对象检测、VG 和短语本地化框架的各种基线方法。令人惊讶的是,我们发现最先进的方法在不同的场景中往往会失效。因此,我们开发了一个新颖的框架,集成了两个关键组件:文本图像查询选择和语言引导特征注意。这些模块旨在增强对新类别的识别并增强视觉和语言信息之间的一致性。大量实验证明了我们提出的框架的有效性,该框架在 OV VG 任务中始终保持 SOTA 性能。此外,消融研究进一步证明了我们创新模型的有效性。 |
| A Quantitative Evaluation of Dense 3D Reconstruction of Sinus Anatomy from Monocular Endoscopic Video Authors Jan Emily Mangulabnan, Roger D. Soberanis Mukul, Timo Teufel, Isabela Hern ndez, Jonas Winter, Manish Sahu, Jose L. Porras, S. Swaroop Vedula, Masaru Ishii, Gregory Hager, Russell H. Taylor, Mathias Unberath 从内窥镜视频生成准确的 3D 重建是对鼻窦解剖和手术结果进行纵向无辐射分析的一种有前途的途径。已经提出了几种单眼重建方法,通过从运动类型算法和单眼深度估计融合中检索相对相机姿势和结构,产生视觉上令人愉悦的 3D 解剖结构。然而,由于底层算法和内窥镜场景的复杂特性,重建管道可能表现不佳或意外失败。此外,获取医疗数据带来了额外的挑战,在对这些模型进行定量基准测试、理解故障案例以及识别有助于其精度的关键组件方面遇到了困难。在这项工作中,我们使用内窥镜序列与从九个离体标本获取的光学跟踪和高分辨率计算机断层扫描相结合,对鼻窦重建的自监督方法进行了定量分析。我们的结果表明,生成的重建与解剖结构高度一致,重建和 CT 分割之间的平均点到网格误差为 0.91 毫米。然而,在与内窥镜跟踪和导航相关的点对点匹配场景中,我们发现平均目标配准误差为 6.58 毫米。我们发现,姿态和深度估计的不准确性同样会导致此错误,并且具有较短轨迹的局部一致序列会生成更准确的重建。这些结果表明,在相对相机姿势和估计深度与解剖结构之间实现全局一致性至关重要。 |
| Cultural and Linguistic Diversity Improves Visual Representations Authors Andre Ye, Sebastin Santy, Jena D. Hwang, Amy X. Zhang, Ranjay Krishna 计算机视觉通常将感知视为客观的,这种假设反映在数据集收集和模型训练的方式中。例如,不同语言的图像描述通常被假设为相同语义内容的翻译。然而,跨文化心理学和语言学的研究表明,个体的视觉感知因文化背景和所使用的语言而异。在本文中,我们证明了数据集和模型生成的字幕中跨语言语义内容的显着差异。当数据是多语言而不是单语言时,根据场景图、嵌入和语言复杂性来衡量,字幕平均具有更高的语义覆盖率。例如,多语言字幕比一组单语言字幕平均多出 21.8 个对象、24.5 个关系和 27.1 个属性。此外,针对不同语言内容训练的模型针对这些语言的测试数据表现最佳,而针对多语言内容训练的模型在所有评估数据组合中始终表现良好。 |
| What's in a Prior? Learned Proximal Networks for Inverse Problems Authors Zhenghan Fang, Sam Buchanan, Jeremias Sulam 近端算子在逆问题中无处不在,通常作为算法策略的一部分出现,以规范否则不适定的问题。现代深度学习模型也已用于这些任务,例如在即插即用或深度展开的框架中,它们大致类似于近端运算符。然而,在采用这些纯数据驱动的方法时,一些重要的东西丢失了,不能保证一般的深度网络代表任何函数的近端算子,也不能保证网络可以提供一些近似近端的函数的任何特征。这不仅使得保证迭代方案的收敛具有挑战性,而且更根本的是,使对这些网络所学到的训练数据的分析变得复杂。在这里,我们提供了一个框架来开发学习的近端网络 LPN ,证明它们为数据驱动的非凸正则化器提供了精确的近端算子,并展示了一种称为近端匹配的新训练策略如何有效地促进真实数据的对数先验的恢复分配。这种 LPN 提供了通用的、无监督的、富有表现力的近端算子,可用于具有收敛保证的一般逆问题。 |
| Research on Key Technologies of Infrastructure Digitalization based on Multimodal Spatial Data Authors Zhanyuan Tian, Tianrui Zhu, Zerui Tian, Zhen Dong 自2010年NASA提出数字孪生概念以来,许多行业都提出了数字化发展的动态目标,交通运输行业也在其中。随着越来越多的企业布局这片处女地,数字孪生交通产业迅速成长,并逐渐形成了完整的科研体系。然而,在基本成熟的框架下,仍然存在许多漏洞问题需要解决。在利用点云信息构建路网的过程中,我们总结了激光扫描仪采集的点云的几大特征,并分析了构建路网的潜在问题,例如误判特征点为地面点和网格空隙等。在此基础上,我们回顾了相关文献并提出了针对性的解决方案,例如仿照图像金字塔构建点云金字塔、扩展虚拟网格等、应用CSF进行地面点云提取、利用CSF构建路网模型等。基于 PTD 渐进密度的过滤算法。针对道路标志检测问题,我们优化了地面点云中的遥感数据,通过边缘检测增强信息密度,通过去除低强度点提高数据质量,并使用PaddleOCR和密集网。针对实时数字孪生流量,我们设计了P2PRN网络,使用MPR GAN的骨干进行2D特征生成,使用SuperGlue进行2D特征匹配,根据匹配优化点渲染视点,经过多次迭代完成多模态匹配任务, |
| Deep MDP: A Modular Framework for Multi-Object Tracking Authors Abhineet Singh 本文提出了一种基于马尔可夫决策过程 MDP 检测范式跟踪的快速模块化多目标跟踪 MOT 框架。它的设计目的是允许其各种功能组件被定制设计的替代品所取代,以适应给定的应用。还提供了集成了对象检测、分割、MOT 和半自动标记的交互式 GUI,以帮助您更轻松地开始使用此框架。尽管在性能方面没有突破,Deep MDP 拥有庞大的代码库,对于社区尝试新想法或只是为任何 MOT 应用程序拥有一个易于使用和易于调整的系统应该很有用。 |
| A Survey on Continual Semantic Segmentation: Theory, Challenge, Method and Application Authors Bo Yuan, Danpei Zhao 持续学习,也称为增量学习或终身学习,处于深度学习和人工智能系统的最前沿。它突破了封闭集上单向训练的障碍,并能够在开放集条件下进行连续自适应学习。近十年来,持续学习在多个领域得到了探索和应用,特别是在计算机视觉领域,涵盖分类、检测和分割任务。连续语义分割 CSS ,其密集预测特性使其成为一项具有挑战性、复杂且新兴的任务。在本文中,我们对 CSS 进行了回顾,致力于对问题表述、主要挑战、通用数据集、近代理论和多样化应用进行全面调查。具体来说,我们首先阐明问题定义和主要挑战。在深入研究相关方法的基础上,我们对当前的 CSS 模型进行了梳理和分类,分为两个主要分支:textit 数据重放和 textit 数据自由集。在每个分支中,相应的方法都是基于相似性的聚类和彻底分析,并对相关数据集进行定性比较和定量再现。此外,我们还介绍了四个CSS专业,它们具有不同的应用场景和发展趋势。 |
| Guidance system for Visually Impaired Persons using Deep Learning and Optical flow Authors Shwetang Dubey, Alok Ranjan Sahoo, Pavan Chakraborty 视障人士在路上行走时很难了解周围环境。他们使用的手杖只能为他们提供有关手杖附近障碍物的信息。此外,它在静态或节奏非常慢的环境中最有效。因此,本文介绍了一种在繁忙街道上引导他们的方法。要创建这样的系统,了解正在接近的物体及其接近方向非常重要。为了实现这一目标,我们创建了一种方法,将从视频接收到的图像帧分为三个部分,即中心、左侧和右侧,以了解接近物体的接近方向。物体检测是使用 YOLOv3 完成的。光流估计采用Lucas Kanade的光流估计方法,深度估计采用Depth net。该模型利用深度信息、物体运动轨迹和物体类别信息,向人员提供必要的信息警告。 |
| High-Quality 3D Face Reconstruction with Affine Convolutional Networks Authors Zhiqian Lin, Jiangke Lin, Lincheng Li, Yi Yuan, Zhengxia Zou 最近基于卷积编码器解码器架构和 3DMM 参数化的工作已经显示出从单个输入图像重建规范视图的巨大潜力。传统的 CNN 架构受益于利用输入和输出像素之间的空间对应关系。然而,在 3D 人脸重建中,输入图像之间的空间失准,例如人脸和规范的 UV 输出使得特征编码解码过程相当具有挑战性。在本文中,为了解决这个问题,我们提出了一种新的网络架构,即仿射卷积网络,它使基于 CNN 的方法能够处理空间上不对应的输入和输出图像,同时保持高保真质量输出。在我们的方法中,从特征图的每个空间位置的仿射卷积层学习仿射变换矩阵。此外,我们使用多个组件在 UV 空间中表示 3D 人体头部,包括用于纹理表示的漫反射贴图、用于几何表示的位置图以及用于恢复现实世界中更复杂的光照条件的光照图。所有组件都可以在没有任何手动注释的情况下进行训练。我们的方法是无参数的,可以生成分辨率为 512 x 512 像素的高质量 UV 贴图,而以前的方法通常生成 256 x 256 像素或更小。 |
| A comprehensive survey on deep active learning and its applications in medical image analysis Authors Haoran Wanga, Qiuye Jin, Shiman Li, Siyu Liu, Manning Wang, Zhijian Song 深度学习在医学图像分析方面取得了广泛的成功,导致对大规模专家注释医学图像数据集的需求不断增加。然而,医学图像注释的高昂成本严重阻碍了深度学习在该领域的发展。为了降低标注成本,主动学习的目标是选择信息量最大的样本进行标注,并用尽可能少的标记样本训练高性能模型。在本次调查中,我们回顾了主动学习的核心方法,包括信息量评估和抽样策略。我们首次详细总结了主动学习与其他标签高效技术的集成,例如半监督、自监督学习等。此外,我们还重点介绍专门针对医学图像分析定制的主动学习作品。 |
| Hierarchical Vector Quantized Transformer for Multi-class Unsupervised Anomaly Detection Authors Ruiying Lu, YuJie Wu, Long Tian, Dongsheng Wang, Bo Chen, Xiyang Liu, Ruimin Hu 无监督图像异常检测 UAD 旨在学习正常样本的鲁棒性和判别性表示。虽然每个类的单独解决方案会带来昂贵的计算和有限的通用性,但本文重点关注为多个类构建统一的框架。在这种具有挑战性的环境下,具有连续潜在表示假设的流行的基于重建的网络总是遭受相同的捷径问题,其中正常和异常样本都可以很好地恢复但难以区分。为了解决这个关键问题,我们在概率框架下提出了一种面向分层矢量量化原型的 Transformer。首先,我们不学习连续表示,而是将典型的正常模式保留为离散的图标原型,并确认矢量量化在防止模型陷入捷径方面的重要性。将矢量量化的图标原型集成到Transformer中进行重建,从而将异常数据点翻转为正常数据点。其次,我们研究了一种精致的分层框架来缓解码本崩溃问题并补充脆弱的正常模式。第三,提出了一种面向原型的最优传输方法,以更好地规范原型并分层评估异常分数。通过对 MVTec AD 和 VisA 数据集进行评估,我们的模型超越了最先进的替代方案,并具有良好的可解释性。 |
| Multi-stream Cell Segmentation with Low-level Cues for Multi-modality Images Authors Wei Lou, Xinyi Yu, Chenyu Liu, Xiang Wan, Guanbin Li, Siqi Liu, Haofeng Li 由于这些图像中复杂的纹理、图案和细胞形状,多模态显微镜图像的细胞分割仍然是一个挑战。为了解决这个问题,我们首先开发一个自动细胞分类管道,根据低级图像特征来标记显微镜图像,然后根据类别标签训练分类模型。之后,我们使用相应类别中的图像为每个类别训练单独的分割模型。此外,我们进一步部署两种类型的分割模型来分别分割圆形和不规则形状的细胞。此外,利用高效且强大的骨干模型来提高分割模型的效率。 |
| One-for-All: Towards Universal Domain Translation with a Single StyleGAN Authors Yong Du, Jiahui Zhan, Shengfeng He, Xinzhe Li, Junyu Dong, Sheng Chen, Ming Hsuan Yang 在本文中,我们提出了一种新颖的翻译模型 UniTranslator,用于在训练数据有限和视觉差异显着的条件下在视觉上不同的域之间转换表示。我们方法背后的主要思想是利用 CLIP 的领域中立功能作为桥接机制,同时利用单独的模块从源领域和目标领域的嵌入中提取抽象的、与领域无关的语义。将这些抽象语义与目标特定语义融合会导致 CLIP 空间内的嵌入发生转换。为了弥合 CLIP 和 StyleGAN 不同世界之间的差距,我们引入了一种新的非线性映射器,即 CLIP2P 映射器。利用 CLIP 嵌入,该模块经过定制以近似 P 空间中的潜在分布,有效地充当这两个空间之间的连接器。所提出的 UniTranslator 具有多功能性,能够执行各种任务,包括风格混合、风格化和翻译,甚至在不同视觉领域的视觉挑战性场景中也是如此。值得注意的是,UniTranslator 生成高质量的翻译,展示领域相关性、多样性和改进的图像质量。 UniTranslator 超越了现有通用模型的性能,并且在代表性任务中比专用模型表现良好。 |
| The Importance of Anti-Aliasing in Tiny Object Detection Authors Jinlai Ning, Michael Spratling 由于微小物体在许多关键的现实世界场景中频繁出现,微小物体检测在研究界引起了相当大的关注。然而,用作目标检测架构骨干的卷积神经网络 CNN 通常在下采样操作期间忽略奈奎斯特采样定理,从而导致混叠和性能下降。对于占用很少像素并因此具有高空间频率特征的微小物体来说,这可能是一个特殊问题。本文应用了现有的 WaveCNet 抗锯齿方法来检测微小物体。 WaveCNet 通过使用小波池 WaveletPool 层替换 CNN 中的标准下采样过程来解决混叠问题,从而有效地抑制混叠。我们修改了原始的 WaveCNet,以在 ResNet 中残差块的两个路径中以一致的方式应用 WaveletPool。此外,我们还提出了主干的底层重版本,它进一步提高了微小物体检测的性能,同时还将所需的参数数量减少了近一半。 TinyPerson、WiderFace 和 DOTA 数据集上的实验结果证明了抗锯齿在微小物体检测中的重要性以及所提出方法的有效性,该方法在所有三个数据集上都取得了最新的结果。 |
| TransY-Net:Learning Fully Transformer Networks for Change Detection of Remote Sensing Images Authors Tianyu Yan, Zifu Wan, Pingping Zhang, Gong Cheng, Huchuan Lu 在遥感领域,变化检测CD旨在从同一地点的双相图像中识别和定位变化区域。近年来,随着深度学习的进步,它取得了长足的进步。然而,由于提取的视觉特征的表示能力有限,当前的方法通常提供不完整的 CD 区域和不规则的 CD 边界。为了缓解这些问题,在这项工作中,我们提出了一种新颖的基于 Transformer 的遥感图像 CD 学习框架,名为 TransY Net,它改进了全局视图的特征提取,并以金字塔方式组合了多级视觉特征。更具体地说,所提出的框架首先利用 Transformer 在远程依赖建模中的优势。它可以帮助学习更具辨别力的全局级别特征并获得完整的CD区域。然后,我们引入了一种新颖的金字塔结构来聚合来自 Transformers 的多级视觉特征以进行特征增强。嫁接有渐进式注意力模块 PAM 的金字塔结构可以通过空间和通道注意力来提高特征表示能力,并具有额外的相互依赖性。最后,为了更好地训练整个框架,我们利用具有多个边界感知损失函数的深度监督学习。大量实验表明,我们提出的方法在四个光学基准和两个 SAR 图像 CD 基准上实现了最先进的性能。 |
| Distractor-aware Event-based Tracking Authors Yingkai Fu, Meng Li, Wenxi Liu, Yuanchen Wang, Jiqing Zhang, Baocai Yin, Xiaopeng Wei, Xin Yang 事件相机或动态视觉传感器最近在从基本视觉任务到高级视觉研究方面取得了成功。由于能够异步捕捉光强变化,事件相机具有固有的优势,可以在具有挑战性的场景中捕捉移动物体,包括弱光、高动态范围或快速移动的物体。因此,事件相机对于视觉对象跟踪来说是很自然的。然而,当前源自 RGB 跟踪器的基于事件的跟踪器只是将输入图像修改为事件帧,并且仍然遵循主要关注对象纹理以进行目标区分的传统跟踪管道。因此,跟踪器在处理具有挑战性的场景(例如移动摄像机和杂乱的前景)时可能不够稳健。在本文中,我们提出了一种基于干扰感知事件的跟踪器,它将变压器模块引入名为 DANet 的 Siamese 网络架构中。具体来说,我们的模型主要由运动感知网络和目标感知网络组成,它同时利用事件数据中的运动线索和对象轮廓,从而发现运动对象并通过去除动态干扰来识别目标对象。我们的 DANet 可以以端到端的方式进行训练,无需任何后处理,并且可以在单个 V100 上以超过 80 FPS 的速度运行。我们对两个大型事件跟踪数据集进行了全面的实验,以验证所提出的模型。 |
| Partition Speeds Up Learning Implicit Neural Representations Based on Exponential-Increase Hypothesis Authors Ke Liu, Feng Liu, Haishuai Wang, Ning Ma, Jiajun Bu, Bo Han textit 隐式神经表示 INR 旨在学习 textit 连续函数,即表示图像的神经网络,其中函数的输入和输出分别是像素坐标和 RGB 灰度值。然而,图像往往由许多颜色不完全一致的对象组成,这导致图像实际上是一个不连续分段函数并且不能通过连续函数很好地估计的挑战。在本文中,我们根据经验研究了如果强制神经网络拟合不连续分段函数以达到固定的小误差,则时间成本将相对于目标信号空间域的边界呈指数增加。我们将这种现象命名为文本指数增长假说。在 textit 指数增长假设下,学习具有许多对象的图像的 INR 收敛速度会非常慢。为了解决这个问题,我们首先证明将复杂信号划分为多个子区域并利用分段 INR 来拟合该信号可以显着加快收敛速度。基于这一事实,我们引入了一种简单的划分机制来提高两种 INR 图像重建方法的性能,一种用于学习 INR,另一种用于学习 INR。在这两种情况下,我们将图像划分为不同的子区域,并为每个部分分配更小的网络。此外,我们还分别提出了两种基于规则网格和语义分割图的划分规则。 |
| Prompt-based Grouping Transformer for Nucleus Detection and Classification Authors Junjia Huang, Haofeng Li, Weijun Sun, Xiang Wan, Guanbin Li 自动细胞核检测和分类可以为疾病诊断提供有效的信息。大多数现有方法对核进行独立分类,或者没有充分利用核之间的语义相似性及其分组特征。在本文中,我们提出了一种基于分组变压器分类器的新型端到端核检测和分类框架。核分类器通过对核嵌入进行分层分组来学习和更新核组和类别的表示。然后利用分类嵌入和细胞核特征之间的成对相关性来预测细胞类型。为了提高完全基于 Transformer 的框架的效率,我们将核心组嵌入作为主干的输入提示,这有助于通过仅调整提示而不是整个主干来收获分组引导特征。 |
| Augmenting End-to-End Steering Angle Prediction with CAN Bus Data Authors Rohan Gupta 近年来,自动驾驶汽车的端到端转向预测已成为一个主要研究领域。实现端到端转向的主要方法是在实时视频数据上使用计算机视觉模型。然而,为了进一步提高准确性,许多公司通过传感器融合添加了光检测和测距激光雷达和/或雷达传感器的数据。然而,添加激光器和传感器的财务成本很高。在本文中,我通过提高计算机视觉模型的准确性来解决这两个问题,而无需增加使用激光雷达和/或传感器的成本。我通过传感器将 CAN 总线数据(一种车辆协议)与视频数据融合来提高计算机视觉模型的准确性,从而实现了这一目标。 CAN 总线数据是有关车辆状态的丰富信息源,包括速度、转向角和加速度。通过将该数据与视频数据融合,可以提高计算机视觉模型预测的准确性。当我在没有 CAN 总线数据的情况下训练模型时,得到的 RMSE 为 0.02492,而使用 CAN 总线数据训练的模型得到的 RMSE 为 0.01970。 |
| Visual-Attribute Prompt Learning for Progressive Mild Cognitive Impairment Prediction Authors Luoyao Kang, Haifan Gong, Xiang Wan, Haofeng Li 深度学习 DL 已用于通过脑成像数据自动诊断轻度认知障碍 MCI 和阿尔茨海默氏病 AD。然而,以前的方法并没有充分利用专家在实践中广泛采用的大脑图像与临床信息之间的关系。为了同时利用来自成像和表格数据的异构特征,我们提出了基于视觉属性提示学习的 Transformer VAP Former,这是一种基于变压器的网络,可以通过快速微调有效地提取和融合多模态特征。此外,我们提出了一种提示微调 PT 方案,将 AD 预测任务中的知识转移到渐进式 MCI pMCI 诊断中。具体来说,我们首先在 AD 诊断任务上在没有提示的情况下预训练 VAP Former,然后使用 PT 在 pMCI 检测任务上对模型进行微调,只需优化少量参数,同时保持骨干网冻结。接下来,我们为视觉提示提出了一种新颖的全局提示标记,为多模态表示提供全局指导。大量的实验不仅表明了我们的方法在 pMCI 预测方面与最先进的方法相比的优越性,而且还证明了全局提示可以使提示学习过程更加有效和稳定。 |
| Affine-Consistent Transformer for Multi-Class Cell Nuclei Detection Authors Junjia Huang, Haofeng Li, Xiang Wan, Guanbin Li 多类细胞核检测是组织病理学诊断的基本前提。在数字病理图像中有效定位和识别具有不同形态和分布的细胞至关重要。大多数现有方法以复杂的中间表示作为学习目标,并依赖于不灵活的后期细化,而较少关注各种细胞密度和视野。在本文中,我们提出了一种新颖的仿射一致变换器 AC 前体,它直接产生一系列核位置,并通过两个子网络(全局网络和局部网络)进行协作训练。本地分支学习推断较小尺度的失真输入图像,而全局网络输出大规模预测作为额外的监督信号。我们进一步引入了自适应仿射变换器 AAT 模块,它可以自动学习关键的空间变换来扭曲原始图像以进行本地网络训练。 AAT 模块的工作原理是学习捕获对训练模型更有价值的变换图像区域。 |
| MMTF-DES: A Fusion of Multimodal Transformer Models for Desire, Emotion, and Sentiment Analysis of Social Media Data Authors Abdul Aziz, Nihad Karim Chowdhury, Muhammad Ashad Kabir, Abu Nowshed Chy, Md. Jawad Siddique 欲望是人类的一系列愿望和愿望,包括驱动人类情感和行为的言语和认知方面,将人类与其他动物区分开来。了解人类欲望有可能成为最迷人和最具挑战性的研究领域之一。它与情感分析和情感识别任务紧密结合。它有利于增加人机交互、识别人类情商、理解人际关系、做出决策。然而,理解人类的欲望是具有挑战性的,而且还没有得到探索,因为人类引发欲望的方式可能不同。由于文化、国家和语言的多样性,这项任务变得更加困难。先前的研究忽视了图像文本成对特征表示的使用,这对于人类欲望理解的任务至关重要。在这项研究中,我们提出了一个基于统一多模态转换器的框架,具有图像文本对设置来识别人类的欲望、情绪和情绪。我们提出的方法的核心在于编码器模块,它是使用两种最先进的多模态变压器模型构建的。这些模型使我们能够提取不同的特征。为了有效地从社交媒体图像和文本对中提取视觉和上下文嵌入特征,我们对两个预训练的多模态转换器模型 Vision and Language Transformer ViLT 和 Vision and Augmented Language Transformer VAuLT 进行了联合微调。随后,我们对这些嵌入特征使用早期融合策略,以获得图像文本对的组合不同特征表示。 |
| Zero-shot Learning of Individualized Task Contrast Prediction from Resting-state Functional Connectomes Authors Minh Nguyen, Gia H. Ngo, Mert R. Sabuncu 给定足够对的受试者静息状态和任务诱发的 fMRI 扫描,可以训练 ML 模型以使用静息状态功能 MRI rsfMRI 扫描来预测受试者特定任务诱发的活动。然而,虽然 rsfMRI 扫描相对容易收集,但获得足够的任务 fMRI 扫描却要困难得多,因为它涉及更复杂的实验设计和程序。因此,对稀缺配对数据的依赖限制了当前技术仅应用于训练期间看到的任务。我们证明,可以通过利用组平均对比度来减少这种依赖,从而实现新任务的零样本预测。我们的方法名为 OPIC(个人对比度 Omni Task Prediction 的缩写),将受试者 rsfMRI 衍生的连接组和组平均对比度作为输入,以生成受试者特定对比度的预测。类似于大型语言模型中使用特殊输入来获取新的自然语言处理任务的答案的零样本学习,输入组平均对比度引导 OPIC 模型泛化到训练中未见过的新任务。 |
| Convolutional Bidirectional Variational Autoencoder for Image Domain Translation of Dotted Arabic Expiration Authors Ahmed Zidane, Ghada Soliman 本文提出了一种用于编码器和解码器的梯形自下而上卷积双向变分自编码器 LCBVAE 架构的方法,通过将阿拉伯点式到期日期重建为填充的到期日期,对点式阿拉伯到期日期的图像翻译进行训练。我们采用了定制和改编版本的卷积循环神经网络 CRNN 模型来满足我们的特定要求并增强其在我们的上下文中的性能,然后使用 2019 年至 2027 年的填充图像来训练定制 CRNN 模型以提取过期时间日期并评估 LCBVAE 在到期日识别方面的模型表现。然后,LCBVAE CRNN 的管道可以集成到自动分拣系统中,用于提取有效期并在制造阶段对产品进行相应的分类。此外,它还可以克服商家手动输入有效期的问题,这既耗时又低效。由于缺乏点阵阿拉伯过期日期图像,我们创建了阿拉伯点阵 True Type Font TTF 来生成合成图像。我们使用 59902 张图像的不切实际合成日期来训练模型,并在 2019 年至 2027 年的 3287 张图像的真实合成日期(表示为 yyyy mm dd)上进行测试。在我们的研究中,我们证明了在图像翻译的下游迁移学习任务中,当尺寸增加到 1024 时,潜在瓶颈层对于提高泛化能力具有重要意义。 |
| You Only Condense Once: Two Rules for Pruning Condensed Datasets Authors Yang He, Lingao Xiao, Joey Tianyi Zhou 数据集压缩是通过减小训练数据集的大小来提高训练效率的重要工具,特别是在设备场景中。然而,这些场景有两个重大挑战:1 设备上可用的不同计算资源需要与预定义的压缩数据集不同的数据集大小;2 有限的计算资源通常无法进行额外的压缩过程。我们推出 You Only Condense Once YOCO 来克服这些限制。在一个压缩数据集之上,YOCO 使用两个极其简单的数据集修剪规则(低 LBPE 分数和平衡构造)生成更小的压缩数据集。 YOCO 具有两个关键优势:1 它可以灵活地调整数据集大小以适应不同的计算约束;2 它消除了额外的压缩过程的需要,而额外的压缩过程在计算上可能会令人望而却步。实验验证了我们在 ConvNet、ResNet 和 DenseNet 等网络以及 CIFAR 10、CIFAR 100 和 ImageNet 等数据集上的发现。例如,我们的 YOCO 在 CIFAR 10 上以每类 IPC 十张图像超越了各种数据集压缩和数据集修剪方法,分别实现了 6.98 8.89 和 6.31 23.92 的精度增益。 |
| Bi-discriminator Domain Adversarial Neural Networks with Class-Level Gradient Alignment Authors Chuang Zhao, Hongke Zhao, Hengshu Zhu, Zhenya Huang, Nan Feng, Enhong Chen, Hui Xiong 无监督域适应旨在将丰富的知识从带注释的源域转移到具有相同标签空间的未标记的目标域。一种流行的解决方案是双鉴别器域对抗网络,它致力于识别源域分布支持之外的目标域样本,并强制其分类在两个鉴别器上保持一致。尽管有效,但不可知的准确性和对分布样本的过度自信估计阻碍了其进一步的性能改进。为了解决上述挑战,我们提出了一种具有类级梯度对齐的新型双判别器域对抗神经网络,即 BACG。 BACG 利用梯度信号和二阶概率估计来更好地对齐域分布。具体来说,为了准确度意识,我们首先设计一种可优化的最近邻算法来获取目标域中样本的伪标签,然后在类级别强制执行两个判别器的后向梯度近似。此外,根据证据学习理论,我们将传统的基于softmax的优化方法转化为多项式狄利克雷分层模型,以推断类概率分布以及样本不确定性,从而减少对分布外样本的错误估计并保证高质量的类对齐。此外,受对比学习的启发,我们开发了一种基于记忆库的变体,即Fast BACG,它可以大大缩短训练过程,但准确性略有下降。 |
| Competitive Ensembling Teacher-Student Framework for Semi-Supervised Left Atrium MRI Segmentation Authors Yuyan Shi, Yichi Zhang, Shasha Wang 半监督学习极大地先进了医学图像分割,因为它有效地减轻了从专家那里获取大量注释的需要,并且利用了更容易获取的未标记数据。在现有的扰动一致性学习方法中,平均教师模型充当半监督医学图像分割的标准基线。在本文中,我们提出了一种简单而有效的竞争性集成教师学生框架,用于半监督 3D MR 图像的左心房分割,其中引入具有不同任务级别干扰的两个学生模型来相互学习,同时执行竞争性集成策略将更可靠的信息集成到教师模型中。与教师和学生模型之间的单向迁移不同,我们的框架在教师模型的指导下促进了不同学生模型的协作学习过程,并激励不同的训练网络进行竞争性学习和集成过程,以取得更好的性能。 |
| Fuzzy-NMS: Improving 3D Object Detection with Fuzzy Classification in NMS Authors Li Wang, Xinyu Zhang, Fachuan Zhao, Chuze Wu, Yichen Wang, Ziying Song, Lei Yang, Jun Li, Huaping Liu 非最大抑制 NMS 是许多 3D 对象检测框架中使用的重要后处理模块,用于删除重叠的候选边界框。然而,过度依赖分类分数以及确定适当阈值的困难可能会直接影响结果的准确性。为了解决这些问题,我们将模糊学习引入 NMS 中,并提出一种新颖的广义模糊 NMS 模块来实现更精细的候选边界框过滤。所提出的模糊 NMS 模块结合了候选边界框的体积和聚类密度,用模糊分类方法对其进行细化,并优化适当的抑制阈值,以减少 NMS 过程中的不确定性。使用主流的 KITTI 和大规模 Waymo 3D 物体检测基准进行了充分的验证实验。这些测试结果表明,所提出的 Fuzzy NMS 模块可以显着提高许多最近基于 NMS 的检测器的准确性,包括 PointPillars、PV RCNN 和 IA SSD 等。这种效果对于行人和自行车等小物体尤其明显。 |
| Adversarial Image Generation by Spatial Transformation in Perceptual Colorspaces Authors Ayberk Aydin, Alptekin Temizel 众所周知,深度神经网络容易受到对抗性扰动的影响。这些扰动的量通常使用L p 度量来量化,例如L 0 、L 2 和L infty 。然而,即使测量到的扰动很小,它们也往往会被人类观察者注意到,因为 L p 距离度量不能代表人类的感知。另一方面,人类对色彩空间的变化不太敏感。此外,受限邻域中的像素偏移很难被注意到。受这些观察的启发,我们提出了一种通过应用空间变换来创建对抗性示例的方法,该方法通过独立地将像素位置更改为感知色彩空间(例如 YC b C r 和 CIELAB )的色度通道来创建对抗性示例,而不是进行加性扰动或直接操作像素值。在有针对性的白盒攻击设置中,所提出的方法能够以非常高的置信度获得有竞争力的愚弄率。实验评估表明,所提出的方法在良性和对抗性生成图像之间的近似感知距离方面具有良好的结果。 |
| Learning Motion Refinement for Unsupervised Face Animation Authors Jiale Tao, Shuhang Gu, Wen Li, Lixin Duan 无监督面部动画旨在根据源图像的外观生成人脸视频,模仿驾驶视频中的运动。现有方法通常采用基于先验的运动模型,例如局部仿射运动模型或局部薄板样条运动模型。虽然它能够捕捉粗略的面部运动,但由于这些方法模拟更精细的面部运动的能力有限,因此经常可以在局部区域(例如嘴唇和眼睛)的微小运动周围观察到伪影。在这项工作中,我们设计了一种新的无监督面部动画方法来同时学习粗略和精细的运动。特别是,在利用局部仿射运动模型学习全局粗略面部运动的同时,我们设计了一种新颖的运动细化模块来补偿局部仿射运动模型,以在局部区域建模更精细的面部运动。运动细化是从源图像和驾驶图像之间的密集相关性中学习的。具体来说,我们首先根据源图像和驱动图像的关键点特征构建结构相关量。然后,我们训练一个模型以从低分辨率到高分辨率迭代地生成微小的面部运动。学习到的运动细化与粗略运动相结合以生成新图像。 |
| Exploring Driving Behavior for Autonomous Vehicles Based on Gramian Angular Field Vision Transformer Authors Junwei You, Ying Chen, Zhuoyu Jiang, Zhangchi Liu, Zilin Huang, Yifeng Ding, Bin Ran 自动驾驶汽车自动驾驶行为的有效分类已成为诊断自动驾驶操作故障、增强自动驾驶算法和降低事故率的关键领域。本文提出了 Gramian Angular Field Vision Transformer GAF ViT 模型,旨在分析 AV 驾驶行为。所提出的 GAF ViT 模型由三个关键组件组成:GAF Transformer Module、Channel Attention Module 和 Multi Channel ViT Module。这些模块共同将多元行为的代表性序列转换为多通道图像,并采用图像识别技术进行行为分类。将通道注意机制应用于多通道图像以辨别各种驾驶行为特征的影响。对 Waymo 轨迹开放数据集的实验评估表明,所提出的模型实现了最先进的性能。 |
| Multimodal Transformer Using Cross-Channel attention for Object Detection in Remote Sensing Images Authors Bissmella Bahaduri, Zuheng Ming, Fangchen Feng, Anissa Mokraou 遥感图像中的目标检测 RSI 是地球观测 EO 中众多应用的一项关键任务。与一般的物体检测不同,RSI 中的物体检测面临着特定的挑战:1 与一般物体检测数据集相比,RSI 中标记数据的稀缺性;2 在具有广阔背景的高分辨率图像中呈现的小物体。为了解决这些挑战,我们提出了一种多模态转换器,探索用于对象检测的多源遥感数据。我们提出了一个跨通道注意模块,而不是通过通道明智的串联直接组合多模态输入,这忽略了不同模态的异质性。该模块学习不同通道之间的关系,通过在早期阶段调整不同的模态来构建连贯的多模态输入。我们还引入了一种基于 Swin 转换器的新架构,该架构在非移位块中合并了卷积层,同时保持固定尺寸,允许生成精细到粗略的表示,并具有有利的精度计算权衡。 |
| A Dual-Stream Neural Network Explains the Functional Segregation of Dorsal and Ventral Visual Pathways in Human Brains Authors Minkyu Choi, Kuan Han, Xiaokai Wang, Yizhen Zhang, Zhongming Liu 人类视觉系统使用两条并行路径进行空间处理和物体识别。相比之下,计算机视觉系统倾向于使用单一的前馈路径,这使得它们的鲁棒性、适应性或效率不如人类视觉。为了弥补这一差距,我们受人眼和大脑的启发,开发了一种双流视觉模型。在输入级别,该模型对两种互补的视觉模式进行采样,以模仿人眼如何使用大细胞和小细胞视网膜神经节细胞来分离大脑的视网膜输入。在后端,该模型通过卷积神经网络 CNN 的两个分支处理单独的输入模式,以模仿人脑如何使用背侧和腹侧皮质通路进行并行视觉处理。第一个分支WhereCNN对全局视图进行采样以学习空间注意力并控制眼球运动。第二个分支 WhatCNN 对局部视图进行采样以表示注视点周围的对象。随着时间的推移,这两个分支反复交互,从移动的注视点构建场景表示。我们将该模型与处理同一部电影的人脑进行了比较,并通过线性变换评估了它们的功能对齐。发现WhereCNN和WhatCNN分支分别与视觉皮层的背侧和腹侧通路有差异地匹配,这主要是由于它们不同的学习目标。这些基于模型的结果使我们推测,腹侧和背侧流的不同反应和表征更多地受到它们在视觉注意和物体识别方面的不同目标的影响,而不是受到它们在视网膜输入中的特定偏差或选择性的影响。 |
| Data-Free Knowledge Distillation Using Adversarially Perturbed OpenGL Shader Images Authors Logan Frank, Jim Davis 知识蒸馏KD一直是一种流行且有效的模型压缩方法。 KD 的一个重要假设是原始训练数据集始终可用。然而,由于隐私问题等原因,情况并非总是如此。近年来,无数据 KD 已成为一个日益增长的研究主题,其重点是在不提供数据的情况下执行 KD 的场景。许多方法依赖生成器网络来合成蒸馏示例,这可能很难训练,并且经常会生成在视觉上与原始数据集相似的图像,这引发了有关隐私是否得到完全保护的问题。在这项工作中,我们提出了一种新的无数据 KD 方法,该方法利用非自然的 OpenGL 图像,结合大量数据增强和对抗性攻击来训练学生网络。我们证明,我们的方法可以为各种数据集网络实现最先进的结果,并且比现有的基于生成器的无数据 KD 方法更稳定。 |
| TexFusion: Synthesizing 3D Textures with Text-Guided Image Diffusion Models Authors Tianshi Cao, Karsten Kreis, Sanja Fidler, Nicholas Sharp, Kangxue Yin 我们提出了 TexFusion 纹理扩散,这是一种使用大规模文本引导图像扩散模型来合成给定 3D 几何形状纹理的新方法。与最近利用 2D 文本到图像扩散模型来使用缓慢且脆弱的优化过程提取 3D 对象的工作相比,TexFusion 引入了一种新的 3D 一致生成技术,专门为纹理合成而设计,该技术在不同的 2D 渲染视图上采用常规扩散模型采样。具体来说,我们利用潜在扩散模型,将扩散模型的降噪器应用于 3D 对象的一组 2D 渲染,并将不同的降噪预测聚合到共享的潜在纹理图上。最终输出 RGB 纹理是通过优化潜在纹理 2D 渲染解码的中间神经色域来生成的。我们彻底验证了 TexFusion,并表明我们可以有效地生成多样化、高质量和全局一致的纹理。我们仅使用图像扩散模型实现了最先进的文本引导纹理合成性能,同时避免了以前基于蒸馏的方法的缺陷。文本调节提供了详细的控制,并且我们也不依赖任何地面实况 3D 纹理进行训练。这使得我们的方法具有通用性,适用于广泛的几何形状和纹理类型。 |
| PACE: Human and Camera Motion Estimation from in-the-wild Videos Authors Muhammed Kocabas, Ye Yuan, Pavlo Molchanov, Yunrong Guo, Michael J. Black, Otmar Hilliges, Jan Kautz, Umar Iqbal 我们提出了一种通过移动摄像机估计全局场景中人体运动的方法。由于视频中人和摄像机运动的耦合,这是一项极具挑战性的任务。为了解决这个问题,我们提出了一种联合优化框架,该框架使用前景人体运动先验和背景场景特征来分离人体和相机运动。与使用 SLAM 作为初始化的现有方法不同,我们建议将 SLAM 和人体运动先验紧密集成到受捆绑调整启发的优化中。具体来说,我们优化人体和相机运动,以匹配观察到的人体姿势和场景特征。该设计结合了 SLAM 和运动先验的优点,从而显着改进了人体和相机运动估计。我们还引入了适合批量优化的运动先验,使我们的方法比现有方法更加有效。最后,我们提出了一种新颖的合成数据集,除了动态视频中的人体运动之外,还可以评估相机运动。 |
| U-BEV: Height-aware Bird's-Eye-View Segmentation and Neural Map-based Relocalization Authors Andrea Boscolo Camiletto, Alfredo Bochicchio, Alexander Liniger, Dengxin Dai, Abel Gawel 当 GPS 接收不足或基于传感器的定位失败时,高效的重新定位对于智能车辆至关重要。鸟瞰 BEV 分割的最新进展允许准确估计局部场景外观,进而有利于车辆的重新定位。然而,BEV 方法的一个缺点是利用几何约束需要大量计算。本文介绍了 U BEV,这是一种受 U Net 启发的架构,它允许 BEV 在展平 BEV 特征之前在多个高度层上推理场景,从而扩展了当前的技术水平。我们表明,这种扩展将 U BEV 的性能提升了高达 4.11 IoU。此外,我们将编码的神经 BEV 与可微模板匹配器相结合,对神经 SD 地图数据执行重定位。 |
| Evaluating sleep-stage classification: how age and early-late sleep affects classification performance Authors Eugenia Moris, Ignacio Larrabide 睡眠阶段分类是专家用来监测人类睡眠数量和质量的常用方法,但这是一项耗时且费力的任务,观察者之间和内部的变异性很高。使用小波进行特征提取和随机森林进行分类,寻找并评估了自动睡眠阶段分类方法。受试者的年龄,以及早睡和深夜的睡眠时间,都会影响分类器的性能。 |
| Localizing and Editing Knowledge in Text-to-Image Generative Models Authors Samyadeep Basu, Nanxuan Zhao, Vlad Morariu, Soheil Feizi, Varun Manjunatha 文本到图像扩散模型(例如 Stable Diffusion 和 Imagen)已经实现了前所未有的照片级真实感质量,在 MS COCO 和其他生成基准上具有最先进的 FID 分数。给定标题,图像生成需要有关对象结构、风格和视角等属性的细粒度知识。这些信息驻留在文本到图像生成模型中的哪里在我们的论文中,我们解决了这个问题并了解与不同视觉属性相对应的知识如何存储在大规模文本到图像扩散模型中。我们对文本到图像模型采用因果中介分析,并将有关不同视觉属性的知识追踪到扩散模型的 i UNet 和 ii 文本编码器中的各种因果组件。特别是,我们表明,与生成性大语言模型不同,有关不同属性的知识并不局限于孤立的组件中,而是分布在条件 UNet 中的一组组件中。这些组件集对于不同的视觉属性通常是不同的。值得注意的是,我们发现公共文本到图像模型(例如稳定扩散)中的 CLIP 文本编码器仅包含跨不同视觉属性的一个因果状态,这是与标题中属性的最后一个主题标记相对应的第一个自注意力层。这与其他语言模型中的因果状态形成鲜明对比,这些模型通常是 MLP 中间层。基于对文本编码器中仅一个因果状态的观察,我们引入了一种快速、无数据的模型编辑方法 Diff QuickFix,它可以有效地将文本中的概念编辑为图像模型。 |
| Fusion-Driven Tree Reconstruction and Fruit Localization: Advancing Precision in Agriculture Authors Kaiming Fu, Peng Wei, Juan Villacres, Zhaodan Kong, Stavros G. Vougioukas, Brian N. Bailey 水果配送对于塑造农业和农业机器人的未来至关重要,为简化供应链铺平道路。这项研究引入了一种创新方法,利用 RGB 图像、LiDAR 和 IMU 数据的协同作用,实现复杂的树木重建和水果的精确定位。这种集成不仅提供了对水果分布的洞察,从而提高了农业机器人和自动化系统的指导精度,而且还为模拟不同树木结构的合成水果模式奠定了基础。为了验证这种方法,在受控环境和实际桃园中进行了实验。 |
| Novel-View Acoustic Synthesis from 3D Reconstructed Rooms Authors Byeongjoo Ahn, Karren Yang, Brian Hamilton, Jonathan Sheaffer, Anurag Ranjan, Miguel Sarabia, Oncel Tuzel, Jen Hao Rick Chang 我们研究了将盲录音与 3D 场景信息相结合以实现新颖的视图声学合成的好处。给定 2×4 个麦克风的录音以及包含多个未知声源的场景的 3D 几何结构和材质,我们可以估计场景中任何位置的声音。我们将新视角声学合成的主要挑战确定为声源定位、分离和去混响。虽然单纯地训练端到端网络无法产生高质量的结果,但我们表明,结合从 3D 重建房间导出的房间脉冲响应 RIR 可以使同一网络共同处理这些任务。我们的方法优于为单个任务设计的现有方法,证明了其在利用 3D 视觉信息方面的有效性。在 Matterport3D NVAS 数据集的模拟研究中,我们的模型在源定位方面实现了近乎完美的精度,源分离和去混响的 PSNR 为 26.44 dB,SDR 为 14.23 dB,结果 PSNR 为 25.55 dB,SDR 为 14.20 dB关于新颖的观点声学合成。 |
| Dual-path convolutional neural network using micro-FTIR imaging to predict breast cancer subtypes and biomarkers levels: estrogen receptor, progesterone receptor, HER2 and Ki67 Authors Matheus del Valle, Emerson Soares Bernardes, Denise Maria Zezell 乳腺癌分子亚型分类对于对预后不同的患者进行分类具有重要作用。使用的生物标志物是雌激素受体 ER 、孕激素受体 PR 、HER2 和 Ki67。根据这些生物标志物表达水平,亚型分为 Luminal A LA、Luminal B LB、HER2 亚型和三阴性乳腺癌 TNBC。免疫组织化学用于对亚型进行分类,尽管实验室间和观察者间的差异可能会影响其准确性,而且是一项耗时的技术。傅里叶变换红外显微光谱可与深度学习结合用于癌症评估,目前仍缺乏对亚型和生物标志物水平预测的研究。这项研究提出了一种新颖的二维深度学习方法来实现这些预测。从人类乳腺活检微阵列中收集了 60 张 320x320 像素的微 FTIR 图像。数据通过 K 均值进行聚类、预处理,并使用全自动方法生成 32x32 补丁。 CaReNet V2 是一种新型卷积神经网络,旨在对乳腺癌 CA 与邻近组织 AT 和分子亚型进行分类,并预测生物标志物水平。聚类方法能够去除非组织像素。 CA 与 AT 和亚型的测试准确度均高于 0.84。该模型能够预测 ER、PR 和 HER2 水平,其中边界值显示较低的性能最小精度为 0.54。 Ki67 百分比回归显示平均误差为 3.6。 |
| On the Detection of Image-Scaling Attacks in Machine Learning Authors Erwin Quiring, Andreas M ller, Konrad Rieck 图像缩放是机器学习和计算机视觉系统不可或缺的一部分。不幸的是,这个预处理步骤很容易受到所谓的图像缩放攻击,其中攻击者对图像进行不明显的更改,使其在缩放后变成新图像。这为攻击者控制预测或改进中毒和后门攻击开辟了新的途径。虽然存在防止扩展攻击的有效技术,但尚未对其检测进行严格研究。 |
| RD-VIO: Robust Visual-Inertial Odometry for Mobile Augmented Reality in Dynamic Environments Authors Jinyu Li, Xiaokun Pan, Gan Huang, Ziyang Zhang, Nan Wang, Hujun Bao, Guofeng Zhang 对于视觉或视觉惯性里程计系统来说,处理动态场景和纯旋转的问题通常具有挑战性。在这项工作中,我们设计了一种新颖的视觉惯性里程计 VIO 系统(称为 RD VIO)来处理这两个问题。首先,我们提出了一种 IMU PARSAC 算法,该算法可以在两阶段过程中稳健地检测和匹配关键点。在第一种状态下,使用视觉和 IMU 测量将地标与新的关键点进行匹配。我们从匹配中收集统计信息,然后指导第二阶段的内部关键点匹配。其次,为了处理纯旋转问题,我们在数据关联过程中检测运动类型并采用延迟三角测量技术。我们将纯旋转框架制成特殊的副框架。在求解视觉惯性束平差时,它们为纯旋转运动提供了额外的约束。我们在公共数据集上评估拟议的 VIO 系统。 |
| The BLA Benchmark: Investigating Basic Language Abilities of Pre-Trained Multimodal Models Authors Xinyi Chen, Raquel Fern ndez, Sandro Pezzelle 尽管预先训练的语言和视觉模型在下游任务中取得了令人印象深刻的性能,但这是否反映了对图像文本交互的正确理解仍然是一个悬而未决的问题。在这项工作中,我们探讨了他们在多大程度上处理基本语言结构主动被动语态、协调和关系从句,即使是学龄前儿童通常也能掌握这些语言结构。我们提出了 BLA,这是一种新颖的、自动构建的基准,用于评估这些基本语言能力的多模态模型。我们表明,不同类型的基于 Transformer 的系统,例如 CLIP、ViLBERT 和 BLIP2,通常在零样本设置下与 BLA 作斗争,这与之前的发现一致。我们的实验特别表明,大多数测试模型在微调或使用特定构建样本提示时只会略微受益。然而,生成式 BLIP2 显示出有希望的趋势,尤其是在情境学习环境中。 |
| Robot Skill Generalization via Keypoint Integrated Soft Actor-Critic Gaussian Mixture Models Authors Iman Nematollahi, Kirill Yankov, Wolfram Burgard, Tim Welschehold 在现实世界场景中运行的机器人操纵系统面临的一个长期挑战是如何适应和推广其获得的运动技能以适应看不见的环境。我们采用整合模仿和强化范式的混合技能模型来应对这一挑战,探索技能的学习和适应,以及通过学习的关键点在场景中的核心基础,如何促进这种泛化。为此,我们开发了关键点集成软演员评论家高斯混合模型 KIS GMM 方法,该方法学习将场景内动态系统的参考预测为 3D 关键点,利用机器人在技能学习期间的物理交互获得的视觉观察结果。通过在模拟和现实环境中进行综合评估,我们表明,我们的方法使机器人能够对新环境获得显着的零样本泛化,并比从头开始学习更快地改进目标环境中的技能。重要的是,这是在不需要新的地面实况数据的情况下实现的。 |
| CalibrationPhys: Self-supervised Video-based Heart and Respiratory Rate Measurements by Calibrating Between Multiple Cameras Authors Yusuke Akamatsu, Terumi Umematsu, Hitoshi Imaoka 使用面部视频进行基于视频的心率和呼吸率测量比传统的基于接触的传感器更有用且用户友好。然而,当前大多数深度学习方法都需要地面实况脉冲和呼吸波来进行模型训练,而收集这些数据的成本很高。在本文中,我们提出了 CalibrationPhys,这是一种基于自监督视频的心率和呼吸率测量方法,可在多个摄像机之间进行校准。 CalibrationPhys 通过使用多个摄像头同时捕获的面部视频来训练没有监督标签的深度学习模型。进行对比学习,使得使用多个摄像机的同步视频预测的脉搏波和呼吸波为正,而来自不同视频的脉搏波和呼吸波为负。 CalibrationPhys 还通过数据增强技术提高了模型的稳健性,并成功利用了针对特定相机的预训练模型。利用两个数据集的实验结果表明,CalibrationPhys 的性能优于最先进的心脏和呼吸频率测量方法。 |
| Invariance is Key to Generalization: Examining the Role of Representation in Sim-to-Real Transfer for Visual Navigation Authors Bo Ai, Zhanxin Wu, David Hsu 数据驱动的机器人控制方法一直在迅速加快步伐,但对未知任务领域的泛化仍然是一个严峻的挑战。我们认为泛化的关键是表征足够丰富以捕获所有任务相关信息并且对训练域和测试域之间多余的可变性保持不变。我们通过实验研究了这种包含用于视觉导航的深度和语义信息的表示,并表明它使得完全在模拟室内场景中训练的控制策略能够推广到室内和室外的不同现实世界环境。此外,我们表明我们的表示减少了训练域和测试域之间的 A 距离,从而改善了泛化误差范围。 |
| StenUNet: Automatic Stenosis Detection from X-ray Coronary Angiography Authors Hui Lin, Tom Liu, Aggelos Katsaggelos, Adrienne Kline 冠状动脉造影仍然是诊断冠状动脉疾病 CAD 的主要方法,而 CAD 是全球主要的死亡原因。 CAD 的严重程度通过狭窄的位置、狭窄程度和所涉及的动脉数量来量化。在目前的实践中,这种量化是使用目视检查手动执行的,因此评分者之间和内部的可靠性较差。 MICCAI 重大挑战基于自动区域的冠状动脉疾病诊断使用 X 射线血管造影图像 ARCADE 策划了一个带有狭窄注释的数据集,目的是创建自动狭窄检测算法。结合机器学习和其他计算机视觉技术,我们提出了 StenUNet 架构和算法,可以准确检测 X 射线冠状动脉造影的狭窄情况。我们提交的 ARCADE 挑战赛在所有团队中排名第三。 |
| Robust Depth Linear Error Decomposition with Double Total Variation and Nuclear Norm for Dynamic MRI Reconstruction Authors Junpeng Tan, Chunmei Qing, Xiangmin Xu 压缩感知 CS 显着加快了磁共振图像 MRI 处理速度,并根据采样的 k 空间数据实现了准确的 MRI 重建。根据目前的研究,基于CS的动态MRI k空间重建还存在一些问题。 1 傅里叶域和图像域存在差异,需要考虑不同域MRI处理的差异。 2 动态MRI作为三维数据,具有其时空特性,需要计算表面纹理的差异性和一致性,同时保持结构的完整性和唯一性。 3 动态 MRI 重建非常耗时且依赖于计算资源。在本文中,我们通过高度欠采样和离散傅立叶变换 DFT 提出了一种新颖的鲁棒低阶动态 MRI 重建优化模型,称为鲁棒深度线性误差分解模型 RDLEDM 。我们的方法主要包括线性分解、双全变分TV和双核范数NN正则化。通过加入线性图像域误差分析,经过欠采样和DFT处理后降低了噪声,增强了算法的抗干扰能力。双TV和NN正则化可以利用时空特征并探索动态MRI序列中不同维度之间的互补关系。此外,由于TV和NN项的非平滑性和非凸性,导致统一目标模型的优化困难。为了解决这个问题,我们利用快速算法来解决原始问题的原始对偶形式。 |
| DocTrack: A Visually-Rich Document Dataset Really Aligned with Human Eye Movement for Machine Reading Authors Hao Wang, Qingxuan Wang, Yue Li, Changqing Wang, Chenhui Chu, Rui Wang 视觉丰富的文档 VRD 在各个领域的使用催生了对能够像人类一样阅读和理解文档的文档 AI 模型的需求,这需要克服技术、语言和认知障碍。不幸的是,缺乏适当的数据集极大地阻碍了该领域的进步。为了解决这个问题,我们引入了textsc DocTrack,这是一个使用眼动追踪技术与人眼运动信息真正对齐的VRD数据集。该数据集可用于研究上述挑战。此外,我们还探讨了人类阅读顺序对文档理解任务的影响,并研究了如果机器按照与人类相同的顺序阅读会发生什么。我们的结果表明,尽管文档 AI 模型已经取得了重大进展,但要像人类一样准确、连续、灵活地读取 VRD,它们还有很长的路要走。这些发现对文档人工智能模型的未来研究和开发具有潜在影响。 |
| Data Pruning via Moving-one-Sample-out Authors Haoru Tan, Sitong Wu, Fei Du, Yukang Chen, Zhibin Wang, Fan Wang, Xiaojuan Qi 在本文中,我们提出了一种新颖的数据修剪方法,称为将一个样本移出 MoSo,其目的是从训练集中识别并删除信息量最少的样本。 MoSo 背后的核心见解是通过评估每个样本对最佳经验风险的影响来确定其重要性。这是通过测量当特定样本被排除在训练集中时经验风险变化的程度来实现的。我们提出了一种高效的一阶逼近器,它只需要来自不同训练阶段的梯度信息,而不是使用计算成本昂贵的留一再训练过程。我们的近似背后的关键思想是,梯度与训练集的平均梯度一致的样本信息更丰富,应该获得更高的分数,如果特定样本的梯度与训练集的平均梯度一致,则可以直观地理解如下平均梯度向量,这意味着使用样本优化网络将对所有剩余样本产生类似的效果。 |
| Multilevel Perception Boundary-guided Network for Breast Lesion Segmentation in Ultrasound Images Authors Xing Yang, Jian Zhang, Qijian Chen, Li Wang, Lihui Wang 从超声图像中自动分割乳腺肿瘤对于后续的临床诊断和治疗计划至关重要。尽管现有的基于深度学习的方法在乳腺肿瘤的自动分割方面取得了显着的进展,但它们在与正常组织强度相似的肿瘤上的表现仍然不尽如人意,特别是对于肿瘤边界。为了解决这个问题,我们提出了一个由多级全局感知模块 MGPM 和边界引导模块 BGM 组成的 PBNet,用于从超声图像中分割乳腺肿瘤。具体来说,在MGPM中,对单级特征图中体素之间的长距离空间依赖性进行建模,然后融合多级语义信息以提高模型对非增强肿瘤的识别能力。在BGM中,使用最大池化的膨胀和侵蚀效应从高级语义图中提取肿瘤边界,然后使用这些边界来指导低级和高级特征的融合。此外,为了提高肿瘤边界的分割性能,提出了多级边界增强分割BS损失。对公开数据集和内部数据集进行的广泛比较实验表明,所提出的 PBNet 在定性可视化结果和定量评估指标方面均优于最先进的方法,Dice 得分、Jaccard 系数、特异性和 HD95 提高了分别为 0.70、1.1、0.1 和 2.5。 |
| Tensor Decomposition Based Attention Module for Spiking Neural Networks Authors Haoyu Deng, Ruijie Zhu, Xuerui Qiu, Yule Duan, Malu Zhang, Liangjian Deng 注意力机制已被证明是改进尖峰神经网络SNN的有效方法。然而,基于当前SNN输入数据流被分割成张量在GPU上处理的事实,之前的工作都没有考虑张量的属性来实现注意力模块。这启发我们从张量相关理论的角度重新思考当前的SNN。使用张量分解,我们设计了 textit 投影全注意力 PFA 模块,该模块在线性增长的参数下展示了出色的结果。具体来说,PFA由尖峰张量LPST模块的textit线性投影和构成AMC模块的textit注意力图组成。在 LPST 中,我们首先使用单个属性保留策略将原始尖峰张量压缩为三个投影张量,每个维度都有可学习的参数。然后,在 AMC 中,我们利用张量分解过程的逆过程,使用所谓的连接因子将三个张量组合到注意力图中。为了验证所提出的 PFA 模块的有效性,我们将其集成到广泛使用的 VGG 和 ResNet 架构中以进行分类任务。 |
| Learning Generalizable Manipulation Policies with Object-Centric 3D Representations Authors Yifeng Zhu, Zhenyu Jiang, Peter Stone, Yuke Zhu 我们引入了 GROOT,一种模仿学习方法,用于学习具有以对象为中心和 3D 先验的稳健策略。 GROOT 制定的政策超越了基于视觉的操作的初始训练条件。它构建了以对象为中心的 3D 表示,这些表示对背景变化和摄像机视图具有鲁棒性,并使用基于转换器的策略对这些表示进行推理。此外,我们引入了分段对应模型,允许策略在测试时泛化到新对象。通过全面的实验,我们验证了 GROOT 策略针对模拟和现实环境中感知变化的稳健性。 GROOT 的性能在背景变化、相机视点移动和新对象实例的存在方面表现出色,而最先进的端到端学习方法和基于对象提议的方法都存在不足。我们还广泛评估了真实机器人上的 GROOT 策略,并展示了在设置发生非常大的变化下的有效性。 |
| Toward Flare-Free Images: A Survey Authors Yousef Kotp, Marwan Torki 镜头眩光是一种常见的图像伪影,由于强光源指向相机,它会显着降低图像质量并影响计算机视觉系统的性能。这项调查全面概述了镜头眩光的多方面领域,包括其基础物理、影响因素、类型和特征。它深入研究了由相机镜头系统内的内反射、散射、衍射和色散等因素引起的耀斑形成的复杂光学。探讨了耀斑的不同类别,包括散射、反射、眩光、球体和星爆类型。分析形状、颜色和定位等关键属性。讨论了影响耀斑外观的众多因素,涵盖光源属性、镜头特征、相机设置和场景内容。该调查广泛涵盖了提出的各种耀斑去除方法,包括硬件优化策略、经典图像处理技术和使用深度学习的基于学习的方法。它不仅描述了为培训和评估目的而创建的开创性耀斑数据集,还描述了它们的创建方式。探讨了常用的性能指标,例如 PSNR、SSIM 和 LPIPS。耀斑的复杂性和数据依赖性特征带来的挑战得到了强调。该调查提供了有关耀斑去除研究的最佳实践、局限性和有希望的未来方向的见解。回顾现有技术可以深入了解耀斑现象的固有复杂性和现有解决方案的功能。 |
| Diffusion-based Data Augmentation for Nuclei Image Segmentation Authors Xinyi Yu, Guanbin Li, Wei Lou, Siqi Liu, Xiang Wan, Yan Chen, Haofeng Li 细胞核分割是组织病理学图像定量分析中的一项基本但具有挑战性的任务。尽管基于完全监督的深度学习的方法已经取得了重大进展,但需要大量标记图像才能实现出色的分割性能。考虑到手动标记数据集的所有核实例效率低下,获取大规模人工注释数据集既耗时又费力。因此,仅用少量标记图像来增强数据集以提高分割性能具有重要的研究和应用价值。在本文中,我们介绍了第一种用于核分割的基于扩散的增强方法。其想法是合成大量标记图像以方便训练分割模型。为了实现这一目标,我们提出了一个两步走的策略。第一步,我们训练一个无条件扩散模型来合成被定义为像素级语义和距离变换表示的核结构。每个合成核结构将作为组织病理学图像合成的约束,并进一步后处理为实例图。第二步,我们训练条件扩散模型来合成基于细胞核结构的组织病理学图像。与合成实例图配对的合成组织病理学图像将被添加到真实数据集中用于训练分割模型。 |
| ASC: Appearance and Structure Consistency for Unsupervised Domain Adaptation in Fetal Brain MRI Segmentation Authors Zihang Xu, Haifan Gong, Xiang Wan, Haofeng Li 胎儿脑图像的自动组织分割对于产前神经发育的定量分析至关重要。然而,生成胎儿大脑成像的体素水平注释既耗时又昂贵。为了降低标记成本,我们提出了一种实用的无监督域适应 UDA 设置,该设置将高质量胎儿大脑图谱的分割标签适应来自另一个域的未标记胎儿大脑 MRI 数据。为了解决这个任务,我们提出了一个基于外观和结构一致性的新 UDA 框架,名为 ASC。我们通过限制基于频率的图像变换前后的一致性,使分割模型适应不同域的外观,即交换脑 MRI 数据和图集之间的外观。考虑到即使在同一区域,不同胎龄的胎儿大脑图像在解剖结构上也可能存在显着差异。为了使模型适应目标域的结构变化,我们进一步鼓励不同结构扰动下的预测一致性。 |
| Can Language Models Laugh at YouTube Short-form Videos? Authors Dayoon Ko, Sangho Lee, Gunhee Kim 随着社交网络上的搞笑短视频越来越受欢迎,人工智能模型需要理解它们,以便更好地与人类交流。不幸的是,以前的视频幽默数据集针对特定领域,例如演讲或情景喜剧,并且主要关注言语线索。我们策划了一个用户生成的数据集,其中包含来自 YouTube 的 10K 多模式有趣视频,称为 ExFunTube。使用 GPT 3.5 的视频过滤管道,我们验证了有助于幽默的语言和视觉元素。过滤后,我们为每个视频添加时间戳和有趣时刻的文字解释。我们的 ExFunTube 与现有数据集相比是独一无二的,因为我们的视频涵盖了广泛的领域,具有各种类型的幽默,需要对内容进行多模式理解。此外,我们还开发了零镜头视频到文本提示,以最大限度地提高法学硕士对大型语言模型的视频幽默理解。 |
| CLIP meets Model Zoo Experts: Pseudo-Supervision for Visual Enhancement Authors Mohammadreza Salehi, Mehrdad Farajtabar, Maxwell Horton, Fartash Faghri, Hadi Pouransari, Raviteja Vemulapalli, Oncel Tuzel, Ali Farhadi, Mohammad Rastegari, Sachin Mehta 对比语言图像预训练 CLIP 是训练视觉语言模型的标准方法。虽然 CLIP 具有可扩展性、可及时性并且对图像分类任务的分布变化具有鲁棒性,但它缺乏对象定位功能。本文研究了以下问题:我们能否使用模型动物园中的任务特定视觉模型来增强 CLIP 训练,以改善其视觉表示。为此,我们利用开源任务特定视觉模型来为未经整理的噪声图像文本数据集生成伪标签。随后,除了图像和文本对的对比训练之外,我们还在这些伪标签上训练 CLIP 模型。这个简单的设置在不同的视觉任务中显示出高达 16.3 的显着改进,包括分割、检测、深度估计和表面法线估计。 |
| Unleashing Modified Deep Learning Models in Efficient COVID19 Detection Authors Md Aminul Islam 1 , Shabbir Ahmed Shuvo 2 , Mohammad Abu Tareq Rony 3 , M Raihan 4 , Md Abu Sufian 5 1 Oxford Brookes University, UK, 2 Offenburg University of Applied Sciences, Germany, Noakhali Science and Technology University, Bangladesh 3 , 4 Khulna University, Bangladesh 5 University of Leicester, UK 新冠肺炎大流行是一种独特且毁灭性的呼吸道疾病暴发,随着疾病的迅速传播,已经影响到了全球人口。最近的深度学习突破可能会提高对新冠肺炎的预测和预报,作为精确和快速检测的工具,但是,目前的方法仍在检验中,以实现更高的准确度和精确度。这项研究分析了包含 8055 个 CT 图像样本的集合,其中 5427 个是新冠病例,2628 个非新冠病例。 9544 个 X 射线样本包括 4044 名新冠病毒患者和 5500 名非新冠病毒病例。最准确的模型是 MobileNet V3 97.872%、DenseNet201 97.567% 和 GoogleNet Inception V1 97.643%。高准确率表明这些模型可以做出许多准确的预测,其他的对于 MobileNetV3 和 DenseNet201 来说也很高。在本研究中,使用准确度、精确度和召回率进行广泛的评估,通过将损失优化与可扩展的批量归一化相结合,可以进行全面的比较,以改进预测模型。我们的分析表明,这些策略提高了模型性能和弹性,以推进 COVID19 预测和检测,并展示了深度学习如何改善疾病处理。 |
| Concept-based Anomaly Detection in Retail Stores for Automatic Correction using Mobile Robots Authors Aditya Kapoor, Vartika Sengar, Nijil George, Vighnesh Vatsal, Jayavardhana Gubbi, Balamuralidhar P, Arpan Pal 跟踪库存和重新排列放错地方的物品是零售环境中劳动力最密集的任务。虽然已经尝试使用基于视觉的技术来完成这些任务,但他们大多使用货架图合规性来检测任何异常,但人们发现这种技术缺乏稳健性和可扩展性。此外,现有系统依赖人工干预在检测后执行纠正措施。在本文中,我们提出了 Co AD,这是一种基于概念的异常检测方法,使用 Vision Transformer ViT,能够在不使用货架图等先验知识库的情况下标记放错位置的对象。它使用自动编码器架构,然后在潜在空间中进行异常值检测。 Co AD 在从 RP2K 数据集提取的零售对象的异常检测图像集上的峰值成功率为 89.90,而标准 ViT 自动编码器的最佳性能基线为 80.81。为了展示其实用性,我们描述了一个机器人移动操纵管道,用于自动纠正 Co AD 标记的异常情况。 |
| Training Image Derivatives: Increased Accuracy and Universal Robustness Authors Vsevolod I. Avrutskiy 导数训练是一种众所周知的提高神经网络准确性的方法。在前向传递中,不仅计算输出值,还计算它们的导数,以及它们与目标导数的偏差都包含在成本函数中,通过基于梯度的算法相对于权重最小化成本函数。到目前为止,该方法已针对相对低维的任务实现。在本研究中,我们将该方法应用于图像分析问题。我们考虑基于立方体图像重建立方体顶点的任务。通过训练关于立方体 6 个自由度的导数,我们获得了比无噪声输入准确 25 倍的结果。这些导数还为鲁棒性问题提供了重要的见解,目前鲁棒性问题被理解为两种类型的网络漏洞。第一种类型是显着改变输出的小扰动,第二种类型是网络错误地忽略的实质性图像变化。目前,它们被认为是相互冲突的目标,因为传统的训练方法会产生权衡。第一种类型可以通过网络的梯度进行分析,但第二种类型需要人类对输入进行评估,这是预言机的替代品。对于手头的任务,可以定义最近邻预言,并且导数的知识允许将其扩展到泰勒级数。 |
| Ophthalmic Biomarker Detection Using Ensembled Vision Transformers -- Winning Solution to IEEE SPS VIP Cup 2023 Authors H.A.Z. Sameen Shahgir, Khondker Salman Sayeed, Tanjeem Azwad Zaman, Md. Asif Haider, Sheikh Saifur Rahman Jony, M. Sohel Rahman 本报告概述了我们在 IEEE SPS VIP Cup 2023 眼科生物标志物检测竞赛中的方法。我们在本次比赛中的主要目标是从不同患者的光学相干断层扫描 OCT 图像中识别生物标志物。使用强大的增强和 5 倍交叉验证,我们训练了两个基于视觉转换器的模型 MaxViT 和 EVA 02,并在推理时将它们集成。我们发现 MaxViT 使用卷积层和跨步注意力更适合检测局部特征,而 EVA 02 使用普通注意力机制和知识蒸馏更适合检测全局特征。 |
| Linguistically Motivated Sign Language Segmentation Authors Amit Moryossef, Zifan Jiang, Mathias M ller, Sarah Ebling, Yoav Goldberg 手语分割是手语处理系统中的一项关键任务。它支持下游任务,例如符号识别、转录和机器翻译。在这项工作中,我们考虑两种分割:分割成单个符号和分割成文本短语(包含多个符号的较大单元)。 |
| Not all Fake News is Written: A Dataset and Analysis of Misleading Video Headlines Authors Yoo Yeon Sung, Jordan Boyd Graber, Naeemul Hassan 两极分化和印象市场共同导致用户难以在线浏览信息,尽管人们在检测虚假或误导性文本方面付出了巨大努力,但多模态数据集受到的关注却少得多。为了补充现有资源,我们提出了多模态视频误导性标题 VMH,这是一个由视频以及注释者是否认为标题代表视频内容组成的数据集。收集并注释该数据集后,我们分析多模式基线以检测误导性标题。 |
| Normalizing flow-based deep variational Bayesian network for seismic multi-hazards and impacts estimation from InSAR imagery Authors Xuechun Li, Paula M. Burgi, Wei Ma, Hae Young Noh, David J. Wald, Susu Xu 地震等现场灾害可能引发山体滑坡和基础设施损坏等级联灾害和影响,从而导致灾难性损失,因此,快速、准确的估计对于及时有效的灾后应对至关重要。干涉合成孔径雷达 InSAR 数据对于提供高分辨率现场信息以进行快速危险评估非常重要。最近使用 InSAR 图像信号的方法预测单一类型的灾害,因此由于共处的灾害、影响和不相关的环境变化(例如植被变化、人类活动)引起的噪声和复杂信号,通常精度较低。 |
| Inter-Scale Dependency Modeling for Skin Lesion Segmentation with Transformer-based Networks Authors Sania Eskandari, Janet Lumpp 黑色素瘤是一种危险的皮肤癌,由皮肤细胞异常生长引起。全卷积网络 FCN 方法(包括 U Net 架构)可以自动分割皮肤病变以帮助诊断。对称 U Net 模型已显示出出色的结果,但其使用卷积运算限制了其捕获长范围依赖性的能力,而这对于精确的医学图像分割至关重要。此外,U 形结构还受到编码器和解码器之间语义差距的影响。在本研究中,我们开发并评估了一种基于 U 形分层 Transformer 的皮肤病变分割结构,同时我们提出了一种尺度间上下文融合 ISCF,利用编码器每个阶段的注意力相关性来自适应地组合来自每个阶段的上下文,以阻碍语义差距。 |
| Habitat 3.0: A Co-Habitat for Humans, Avatars and Robots Authors Xavier Puig, Eric Undersander, Andrew Szot, Mikael Dallaire Cote, Tsung Yen Yang, Ruslan Partsey, Ruta Desai, Alexander William Clegg, Michal Hlavac, So Yeon Min, Vladim r Vondru , Theophile Gervet, Vincent Pierre Berges, John M. Turner, Oleksandr Maksymets, Zsolt Kira, Mrinal Kalakrishnan, Jitendra Malik, Devendra Singh Chaplot, Unnat Jain, Dhruv Batra, Akshara Rai, Roozbeh Mottaghi 我们推出了 Habitat 3.0 一个模拟平台,用于研究家庭环境中的协作人类机器人任务。 Habitat 3.0 在三个维度上做出了贡献 1 精确的人形模拟解决了复杂可变形体建模以及外观和运动多样性方面的挑战,同时确保了高模拟速度。 2 人机交互基础设施可通过鼠标键盘或 VR 界面与模拟机器人进行真实的人类交互,从而促进通过人类输入评估机器人策略。 3 协作任务 研究两个协作任务:社交导航和社交重排。社交导航研究机器人在看不见的环境中定位和跟随人形化身的能力,而社交重排则解决人形机器人和机器人在重新布置场景时的协作问题。这些贡献使我们能够深入研究人类机器人协作的端到端学习和启发式基线,并与人类一起评估它们。我们的实验表明,当与看不见的人形代理和人类伙伴合作时,学习的机器人策略可以有效地完成任务,而这些代理和人类伙伴可能表现出机器人以前从未见过的行为。此外,我们还观察到协作任务执行期间的紧急行为,例如机器人在阻碍类人智能体时让出空间,从而使人形智能体能够有效完成任务。此外,我们使用人机循环工具进行的实验表明,当与真实的人类协作者进行评估时,我们对人形机器人的自动评估可以提供不同策略的相对顺序的指示。 |
| Chinese Abs From Machine Translation |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









