







今日CS.CV 计算机视觉论文速览
Tue, 9 Apr 2019 (showing first 100 of 124 entries)
Totally 100 papers
?上期速览 ✈更多精彩请移步主页

Interesting:
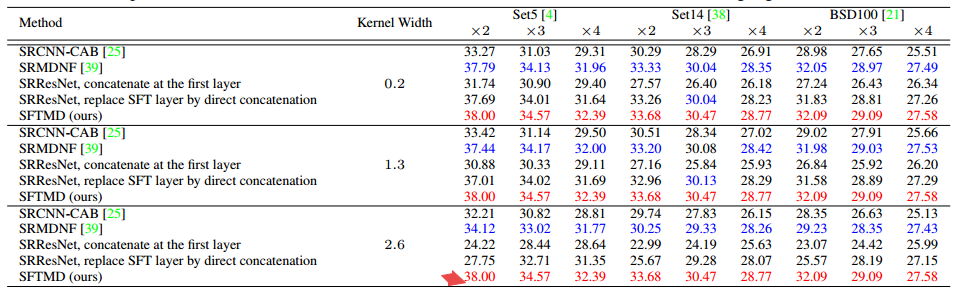
?基于核纠正迭代的盲超分辨, 提出了一种迭代核纠正的方法来处理退化核未知的盲超分辨过程。效果比直接估计退化核好,并提出了基于空间特征变换层来处理多个模糊核。 (from 香港中文)
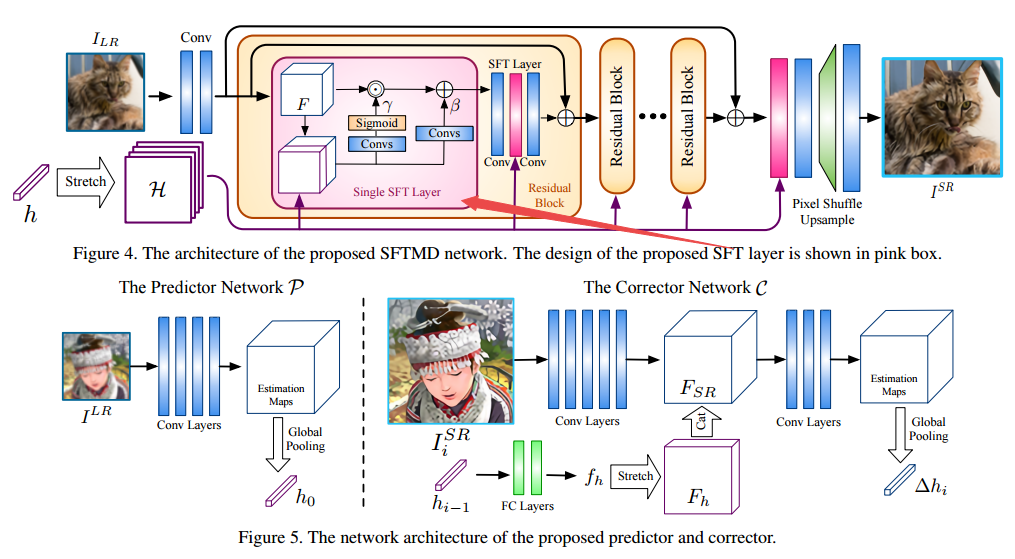
与现有个方法的比较:
一些效果:

?CameraSR, 调节内参从相机镜头的角度来平衡分辨率和视角的关系,并构建分辨率和视角的超分辨隐模型,用于逆问题的研究。在单反Digital Single Lens ReflexDSLR和手机相机中进行了实验。利用了高分辨相纸打印并采集了City100数据集。(from 中科大)
基于双三次降采样和分辨率-视角模型的降采样:


dataset:https://github.com/ngchc/CameraSR
?Point Attention Transformers,PATs, 可以处理大小变换的输入,并实现了与类别无关的采样方法Gumbel Subset Sampling(GSS),选出点云中最具代表性的点。(from 上海交大 )
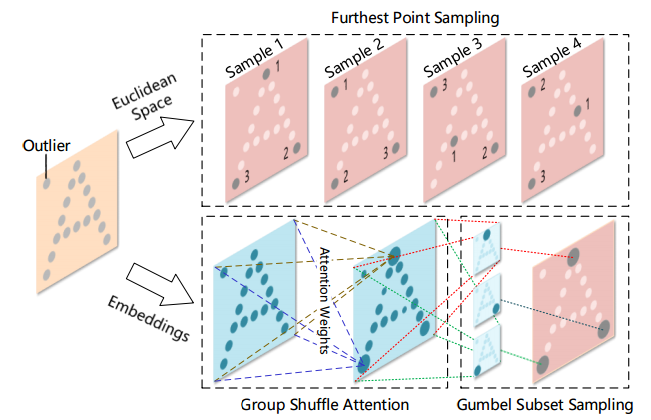
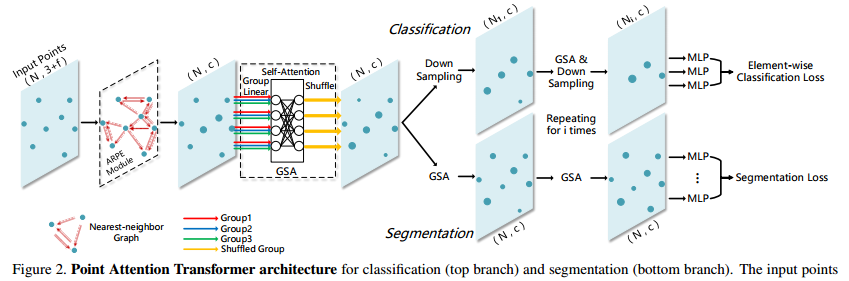
应用: DVS128 Gesture Dataset
ref:Gumbel:https://blog.csdn.net/a358463121/article/details/80820878
?用于处理样本不平衡的加权点云增强系统, (from 伦敦大学学院)
基于点云增强后得到的结果,分别来自于Semantic3D和ScanNet在pointnet++下的结果:

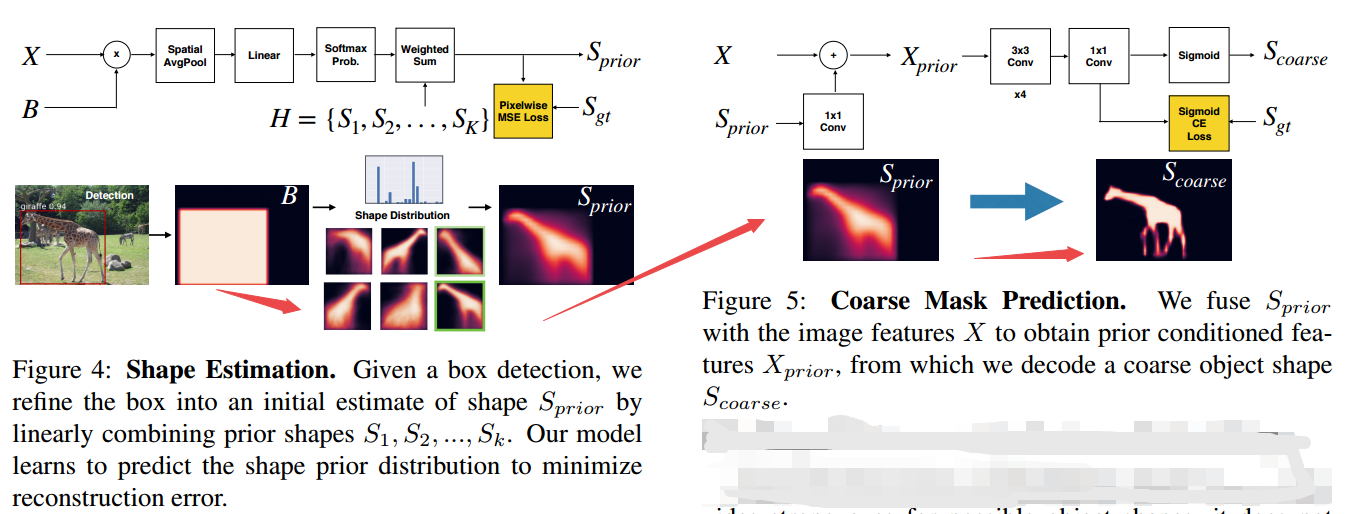
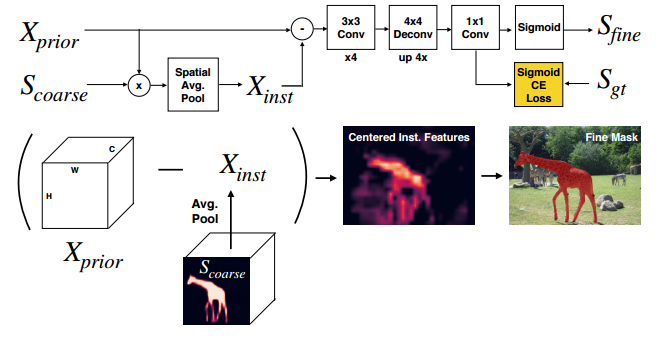
?ShapeMask, 通过提炼形状先验来实现新颖物体的分割。首先利用bbox来估计目标的形状先验,随后利用目标特征优化得到粗糙的mask,最后特征先验、精炼得到精细的mask分割。(from Google Brain Berkeley)
一些结果:

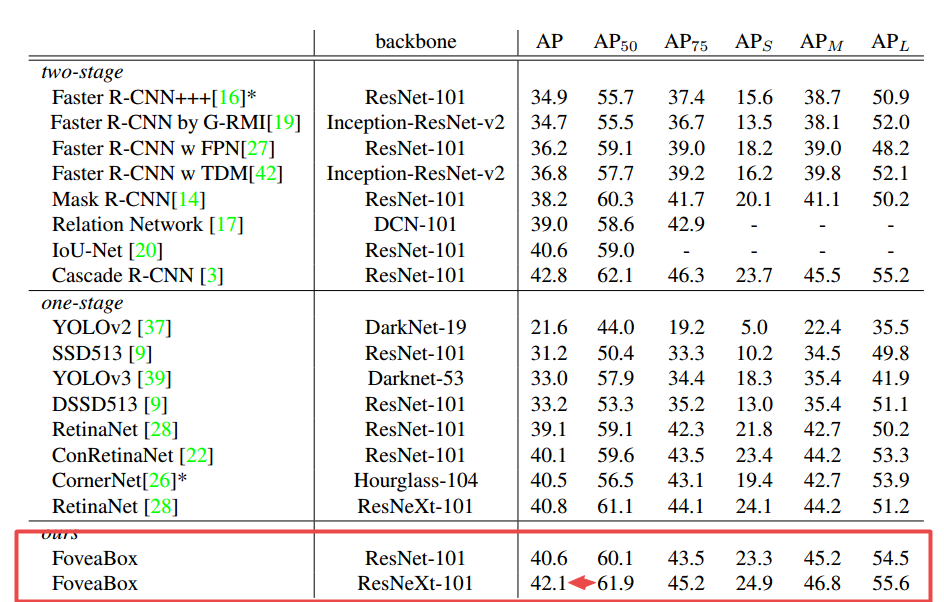
?FoveaBox一种不基于锚点的目标检测方法, 在不需要锚的情况下直接学习物体存在的可能性和框的位置。主要通过预测类别敏感的目标存在可能性语义图,以及为潜在目标位置生成与类别无关的框。框的尺度与金字塔特征相关。这一方法在COCO上实现了42.1的高mAP。(from 清华)
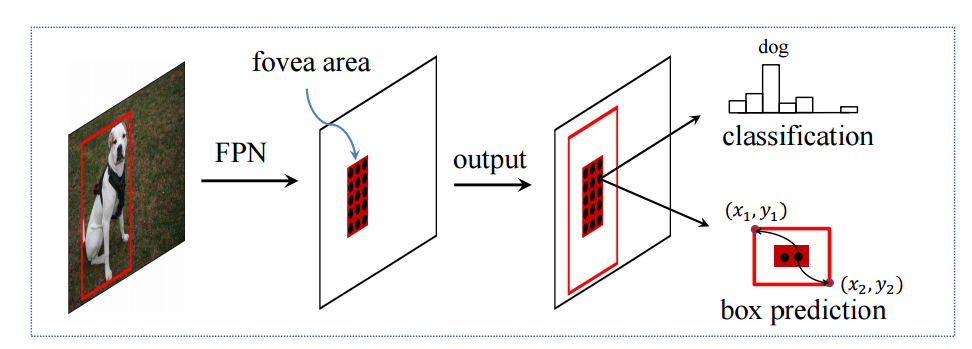
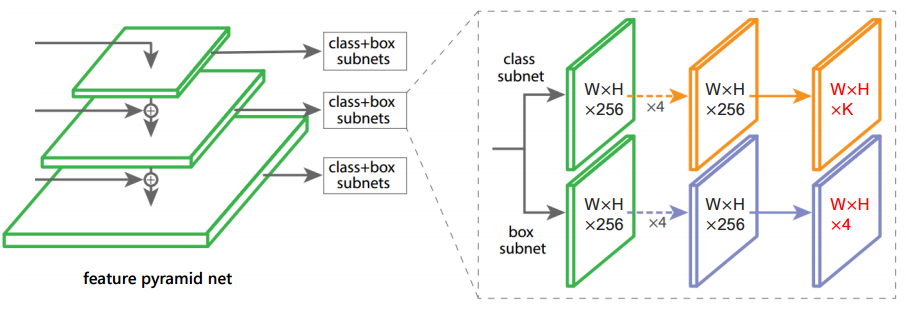
馈入NMS前得到输出存在可能性图和相应的框。

与各种丰富的比较:
?Kervolutional Neural Networks, 提出了一种 基于和的卷积(kernel convolution)来研究卷积中操作中的非线性过程,使卷积操作更加通用、提高模型表达能和抽取特征的能力。(from 南洋理工)
基于核函数来实现KNN计算:

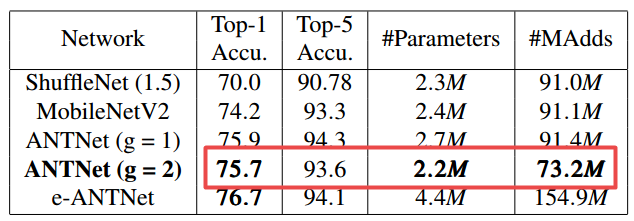
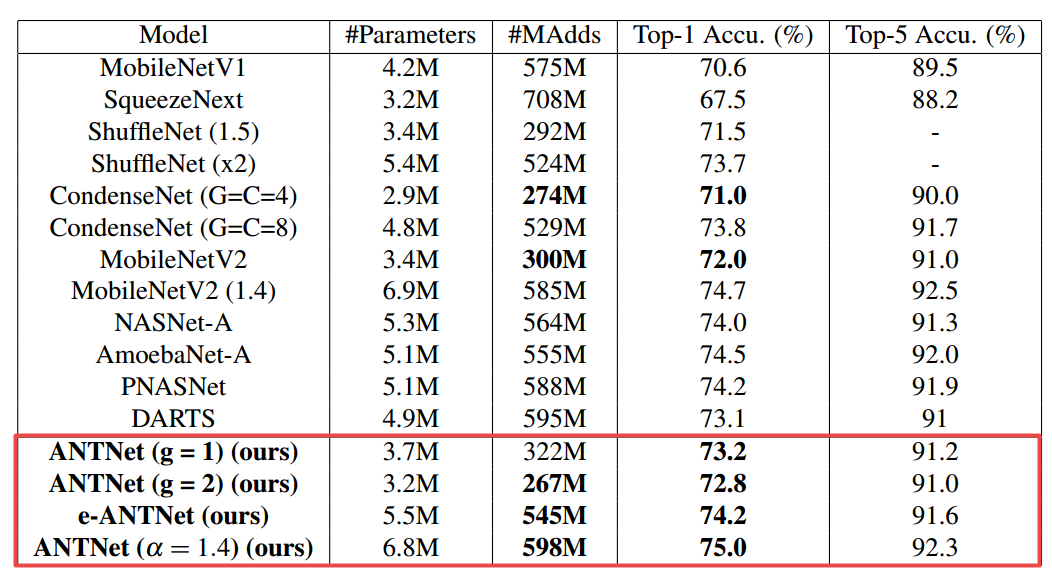
?ANTNets, 为了解决深度可分离网络表达能力下降的问题,研究人员提出了一种参数和计算量(MAdds)更少的架构模块ANTBlock,Attention NesTed Network,在高维空间中用更少的参数保持模型的表达能力,在CIFAR100上实现了75.7%的top1精度,比MobileV2高75.7%,而参数和计算FLOPS更少、(from 威斯康辛·麦迪逊大学)
实验结果和对比如下:
?深度图卷积网络, 图卷积对于非欧空间数据有着较好的效果,但由于梯度消失问题使网络深度很浅。研究人员利用类似卷积中的残差和稠密连接概念实现了56层的GCN,并在点云分割任务中提升了3.7%的mIOU(from KAUST)
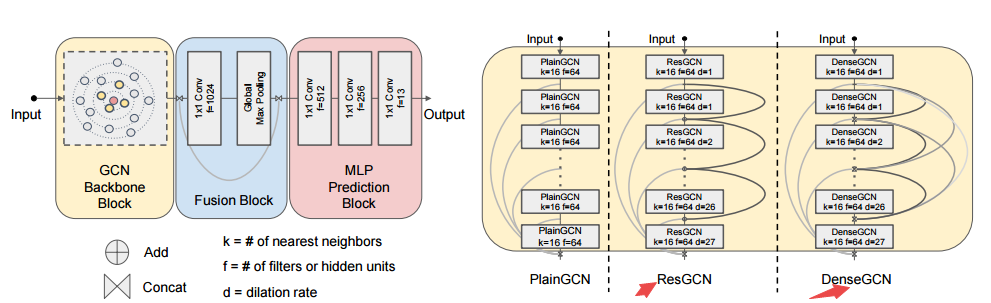

project:https://sites.google.com/view/deep-gcns
?基于RGBD估计表面法向量, 利用了基于自适应特征赋权方法的分层融合网络实现表面法向量估计。彩色和深度图像在多尺度进行操作保证了图像的连续性和图中物体的显著性,同时深度图和置信图的结合实现重新赋权缓解了人工痕迹。(from 商汤 北理工 )
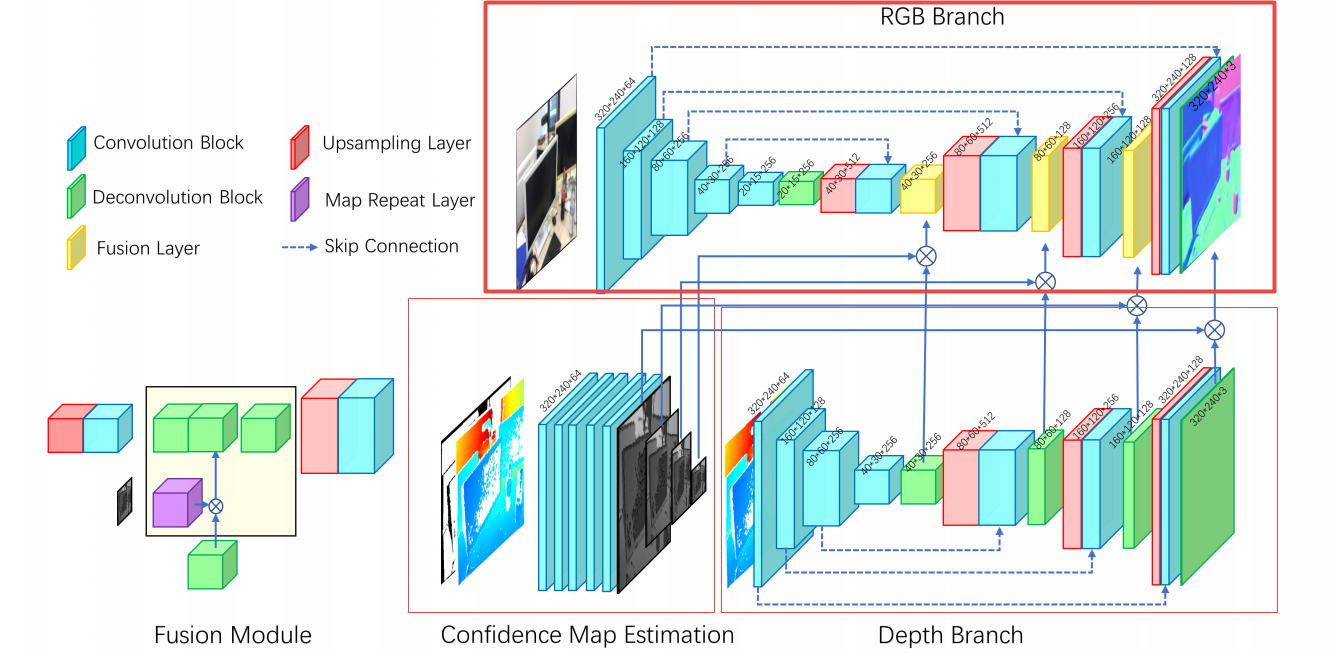
一些结果和比较:

数据集:Matterport3D and ScanNet dataset
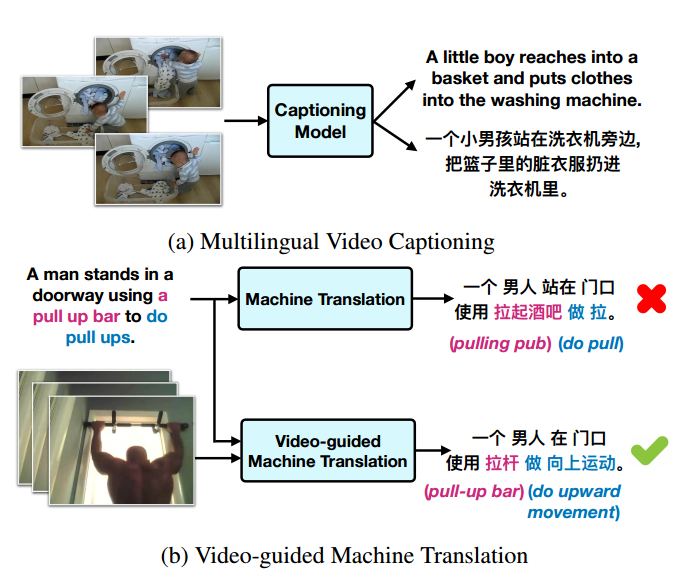
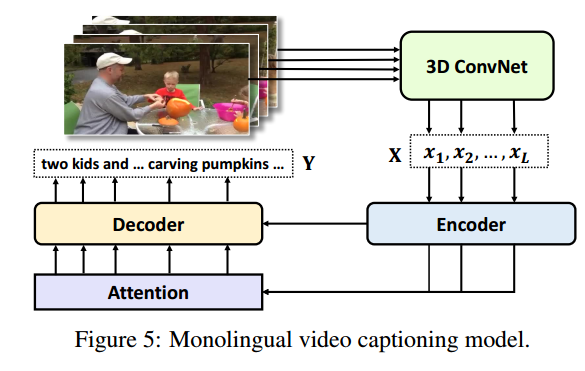
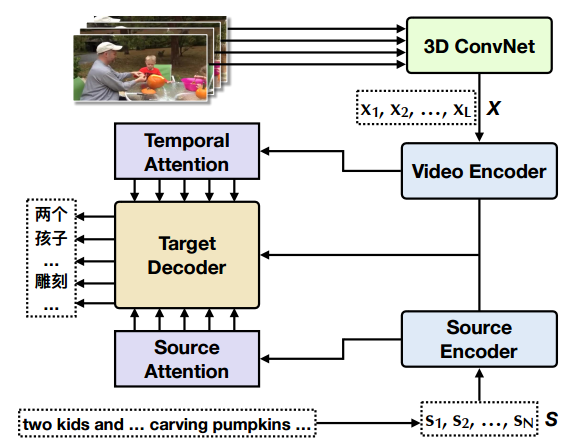
?VATEX, 大规模高质量多语言视觉语言数据集(from UCSB)
其中包含了多语言视频标注和基于视频的机器翻译任务:
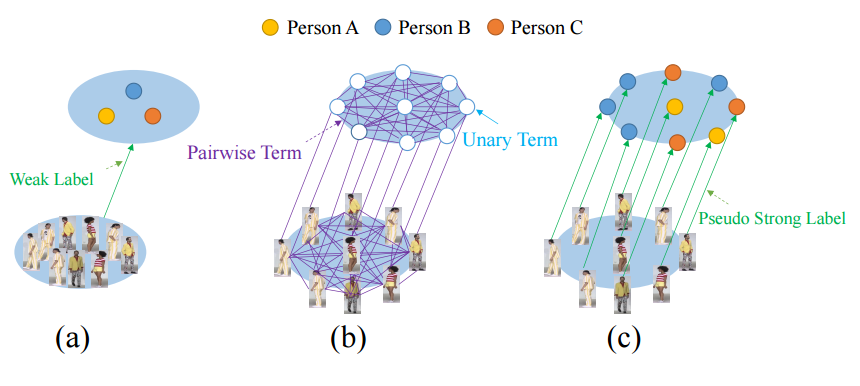
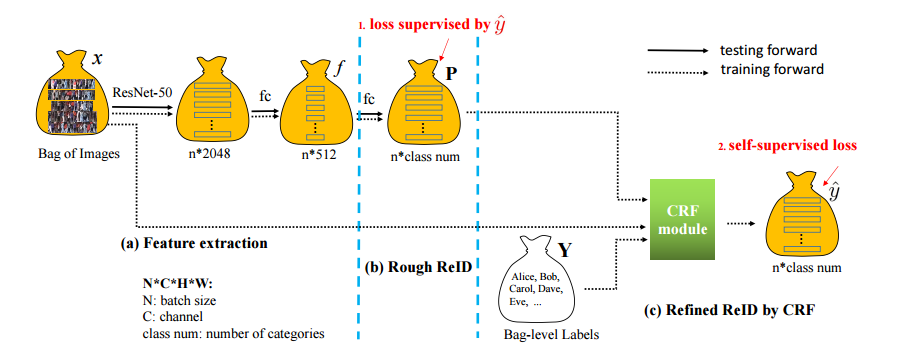
? SYSU-30k,弱监督行人重识别的新基准 (from 中山大学)
基于弱监督ReID的重识别方法:
相关数据集:

Daily Computer Vision Papers
| A Closer Look at Few-shot Classification Authors Wei Yu Chen, Yen Cheng Liu, Zsolt Kira, Yu Chiang Frank Wang, Jia Bin Huang 几个镜头分类的目的是学习一个分类器,用有限的标签示例在训练期间识别看不见的课程。虽然已经取得了重大进展,但网络设计,元学习算法的日益复杂以及实施细节的差异使得公平比较变得困难。在本文中,我们提出了几个代表性的几个镜头分类算法的一致比较分析,结果表明,更深的主干显着降低了具有有限域差异的数据集的方法之间的性能差异,2一个改进的基线方法,令人惊讶地实现了竞争性能与miniI和CUB数据集上的现有技术进行了比较,3是用于评估少数镜头分类算法的跨域泛化能力的新实验设置。我们的结果表明,当特征骨干较浅时,减少类内变异是一个重要因素,但在使用更深的骨干时则不那么重要。在真实的跨域评估设置中,我们表明,使用标准微调实践的基线方法与其他现有技术的少数镜头学习算法相比是有利的。 |
| Relational Action Forecasting Authors Chen Sun, Abhinav Shrivastava, Carl Vondrick, Rahul Sukthankar, Kevin Murphy, Cordelia Schmid 本文重点关注视频中的多人动作预测。更确切地说,给定H先前帧的历史,目标是检测演员并预测他们未来对下一个T帧的动作。我们的方法通过构建循环图来联合模拟不同参与者之间的时间和空间相互作用,使用以更快的R CNN获得的行动者提议作为节点。我们的方法学会选择一个判别关系的子集,而不需要明确的监督,从而使我们能够处理具有挑战性的视觉数据。我们将我们的模型称为判别关系循环网络DRRN。对AVA的动作预测的评估证明了我们提出的方法与更简单的基线相比的有效性。此外,我们显着提高了J HMDB早期行动分类任务的性能,从之前的SOTA 48到60。 |
| Least-squares registration of point sets over SE (d) using closed-form projections Authors Sk. Miraj Ahmed, Niladri Ranjan Das, Kunal Narayan Chaudhury 考虑使用旋转和平移在一些d维空间中注册多个点集的问题。假设存在具有共同点的集合,而且对于这样的集合,已知成对对应关系。我们考虑这个问题的最小二乘公式,其中变量是与点集相关联的变换。目前的新颖性是我们将这个非凸问题简化为优于半正半圆的优化,其中目标是线性的,但约束仍然是非凸的。我们建议使用变量分裂和乘法器ADMM的交替方向方法来解决这个问题。由于目标的线性和约束的结构,ADMM子问题由具有闭合形式解的投影给出。特别地,对于m个点集,每次迭代的主要成本是md乘以md矩阵的部分特征分解,以及d乘以d矩阵的m 1奇异值分解。我们根据经验表明,对于适当的参数设置,所提出的求解器具有较大的收敛流域并且在扰动下是稳定的。作为应用程序,我们使用我们的方法进行2D形状匹配和3D多视图注册。在任一应用中,我们将形状扫描建模为点集,并使用ICP确定成对对应关系。特别地,我们的算法在时间和精度方面与用于多视图重建的现有方法相比是有利的。 |
| Log-barrier constrained CNNs Authors Hoel Kervadec, Jose Dolz, Jing Yuan, Christian Desrosiers, Eric Granger, Ismail Ben Ayed 本研究调查了对CNN的输出施加不等式约束以进行弱监督分割。在深度网络的一般环境中,约束通常用惩罚方法处理,因为它们简单,并且尽管它们具有众所周知的限制。拉格朗日优化在惩罚方法方面具有良好的理论和实践优势,但在很大程度上避免了深度CNN,这主要是由于交替随机优化和双重更新引起的计算复杂性和稳定性收敛问题。最近的几项研究表明,在深度CNN的背景下,拉格朗日优化优于简单惩罚的理论优势在实践中并未实现,其表现令人惊讶地更糟。 |
| Pushing the Envelope for RGB-based Dense 3D Hand Pose Estimation via Neural Rendering Authors Seungryul Baek, Kwang In Kim, Tae Kyun Kim 由于固有的2D 3D映射模糊和有限的训练数据,估计来自单个RGB图像的3D手网是具有挑战性的。我们采用紧凑的参数化3D手模型,代表可变形和铰接式手形网格。为了实现适合RGB图像的模型,我们以三种方式进行研究和贡献1神经渲染受到最近人体工作的启发,我们的手网格估计器HME由神经网络和可微分渲染器实现,由2D分割掩模和3D监督骷髅。 HME表现出良好的性能,可用于估计不同的手形并提高姿势估计的准确性。 2迭代测试改进我们的拟合功能是可微分的。我们在迭代模型拟合方法(如ICP)的精神中,使用梯度迭代地细化初始估计。这一想法得到了人体最新研究的支持。 3自我数据增强收集大小的RGB网格或分割掩模骨架三联体用于训练是一个很大的障碍。一旦模型成功地适合输入RGB图像,其网格即形状和关节是逼真的,并且我们在估计的密集手部姿势之上增加视点。使用三个基于RGB的基准测试的实验表明,我们的框架提供了超出3D姿态估计的最先进精度,以及恢复密集的3D手形状。上述每个技术组件都有意义地提高了消融研究的准确性。 |
| Unsupervised learning of action classes with continuous temporal embedding Authors Anna Kukleva, Hilde Kuehne, Fadime Sener, Juergen Gall 最近,人们越来越关注在未修剪的视频中临时检测和分割动作的任务。在这种情况下的一个问题源于需要定义和标记动作边界以创建用于训练的注释,这是非常耗费时间和成本的。为了解决这个问题,我们提出了一种无监督的方法,用于从未修剪的视频序列中学习动作类。为此,我们使用框架特征的连续时间嵌入来受益于活动的顺序性。基于嵌入创建的潜在空间,我们在所有视频中识别对应于语义有意义的动作类的时间片段的集群。该方法在三个具有挑战性的数据集上进行评估,即早餐数据集,YouTube说明和50Salads数据集。虽然之前的作品假设视频包含相同的高级活动,但我们进一步表明,所提出的方法也可以应用于视频内容未知的更一般的设置。 |
| Revisiting EmbodiedQA: A Simple Baseline and Beyond Authors Yu Wu, Lu Jiang, Yi Yang 在Embodied Question Answering EmbodiedQA中,代理与环境交互以收集回答用户问题所需的信息。现有的工作为解决这个有趣的问题奠定了坚实的基础。但目前的表现,尤其是导航表现,表明EmbodiedQA可能对目前的方法来说太具挑战性。在本文中,我们通过实证研究了这个问题并引入了一个简单而有效的基线,可以通过SGD 2进行端到端优化,为EmbodiedQA提供了一个更简单实用的设置,其中代理有机会将训练过的模型适应新环境它实际上回答用户的问题。在新设置中,我们在新环境中随机放置一些对象,并通过蒸馏网络升级代理策略,以保留训练模型的泛化能力。在EmbodiedQA v1基准测试中,在标准设置下,我们的简单基线在新设置中获得了与现有技术水平相当的非常有竞争力的结果,我们发现设置中引入的微小变化会在导航中产生显着的增益。 |
| Robust Alignment for Panoramic Stitching via an Exact Rank Constraint Authors Yuelong Li, Mohammad Tofighi, Vishal Monga 我们研究了全景拼接的图像对齐问题。与大多数基于特征的现有方法不同,我们的算法直接对像素进行处理,并在全局范围内解决整个图像的错误。从技术上讲,我们将对齐问题表示为秩1,并对变换图像进行稀疏矩阵分解,并开发出一种有效的算法来解决这一具有挑战性的非凸优化问题。该算法简化为求解一系列子问题,我们在分析中建立精确的恢复条件,收敛性和最优性,以及收敛速度和复杂度。我们将其概括为同时对齐多个图像并恢复多个单应性,将其应用范围扩展到绝大多数实际场景。实验结果表明,与现有技术相比,所提出的算法能够更精确地对准图像并生成更高质量的拼接图像。 |
| Learning monocular depth estimation infusing traditional stereo knowledge Authors Fabio Tosi, Filippo Aleotti, Matteo Poggi, Stefano Mattoccia 单个图像的深度估计代表了无数应用中令人着迷但具有挑战性的问题。最近的工作证明,这项任务可以在没有直接监督地面真实标签的情况下学习,利用序列或立体对上的图像合成。着眼于第二种情况,在本文中,我们利用立体匹配来改进单眼深度估计。为此,我们提出了monoResMatch,这是一种新颖的深度架构,旨在通过从不同的视角合成特征,与输入图像水平对齐,在单个输入图像中推断深度,在两个线索之间执行立体匹配。与以前分享这一理论基础的作品相比,我们的网络是第一个从头开始结束的训练端。此外,我们展示了如何通过传统的立体算法(例如半全局匹配)获得代理地面实况注释,通过保持自我监督的方法,能够实现更准确的单眼深度估计,从而抵消对昂贵的深度标签的需求。详尽的实验结果证明了所提出的monoResMatch架构和ii代理监督之间的协同作用如何获得自监督单眼深度估计的现有技术。该代码可在以下网站公开获取 |
| Weighted Point Cloud Augmentation for Neural Network Training Data Class-Imblance Authors David Griffiths, Jan Boehm 最近在3D数据深度学习领域的发展已经证明了直接从点云进行端到端学习的巨大潜力。然而,由于在自然界中观察到的自然类im平衡,许多现实世界点云包含大类im平衡。例如,城市环境的3D扫描将主要由道路和立面组成,而其他对象如杆将不足。在本文中,我们通过使用加权扩充来增加包含较少点的类来解决此问题。通过减少数据中存在的类im平衡,我们证明了标准PointNet深度神经网络可以在验证数据的推断上实现更高的性能。这被观察到两个测试基准数据集ScanNet和Semantic3D的F1得分分别增加19和25,其中没有执行类别im余额预处理。我们的网络在高代表性和低代表性类别上表现更好,这表明当损失函数不过度暴露于少数类时,网络正在学习更强大和有意义的特征。 |
| Leveraging the Invariant Side of Generative Zero-Shot Learning Authors Jingjing Li, Mengmeng Jin, Ke Lu, Zhengming Ding, Lei Zhu, Zi Huang 传统的零射击学习ZSL方法通常学习嵌入(例如,视觉语义映射)以通过间接方式处理看不见的视觉样本。在本文中,我们利用生成对抗网络GAN的优势,提出了一种新的方法,称为利用不变边GAN LisGAN,它可以直接生成由语义描述条件限制的随机噪声中看不见的特征。具体来说,我们训练一个条件Wasserstein GAN,其中发生器合成来自噪声的假看不见的特征,鉴别器通过minimax游戏区分假和真实。考虑到一种语义描述可以对应于各种合成的视觉样本,并且语义描述(比喻性地)是生成特征的灵魂,我们将灵魂样本作为生成零射击学习的不变侧进行介绍。灵魂样本是一个类的元表示。它可视化同一类别中每个样本的最具语义意义的方面。我们规定每个生成的样本生成ZSL的变化侧应该接近至少一个灵魂样本,其中不变侧与其具有相同的类标签。在零射击识别阶段,我们建议使用两个分级器,它们以级联方式部署,以实现粗略到精细的结果。对五个流行基准测试的实验证实,我们提出的方法可以在显着改进的情况下优于最先进的方法。 |
| ContextDesc: Local Descriptor Augmentation with Cross-Modality Context Authors Zixin Luo, Tianwei Shen, Lei Zhou, Jiahui Zhang, Yao Yao, Shiwei Li, Tian Fang, Long Quan 大多数关于学习局部特征的研究都集中在基于补丁的个体关键点描述上,而忽略了从关键点位置建立的空间关系。在本文中,我们通过引入上下文感知来扩展本地特征描述符,从而超越了本地细节表示。具体来说,我们提出了一个统一的学习框架,它利用和聚合交叉模态上下文信息,包括来自高级图像表示的i视觉上下文,以及来自2D关键点分布的ii几何上下文。此外,我们提出了一种有效的N对损失,它避开了经验超参数搜索并改善了收敛性。与原始局部特征描述相比,所提出的增强方案是轻量级的,同时在几个具有多样化场景的大规模基准上得到显着改善,这在几何匹配应用中表现出强大的实用性和泛化能力。 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









