







今日CS.CV 计算机视觉论文速览
Fri, 12 Apr 2019
Totally 50 papers
?上期速览 ✈更多精彩请移步主页

Interesting:
?DBPN基于深度方向传播的图像超分辨,基于前向传播的超分辨模型并不能很好地解决 高低分辨率图像间的相互依存问题,研究人员提出了深度方向网络,采用迭代的上下采样层来提高模型的性能。这种方法为前传单元提供了误差反馈机制。研究中为不同的图像退化过程建立了双向链接的上下采样过程。并并这种思想拓展到了递归网络、稠密网络和残差学习中来提高模型表现。(from 丰田技术研究院 芝加哥 )
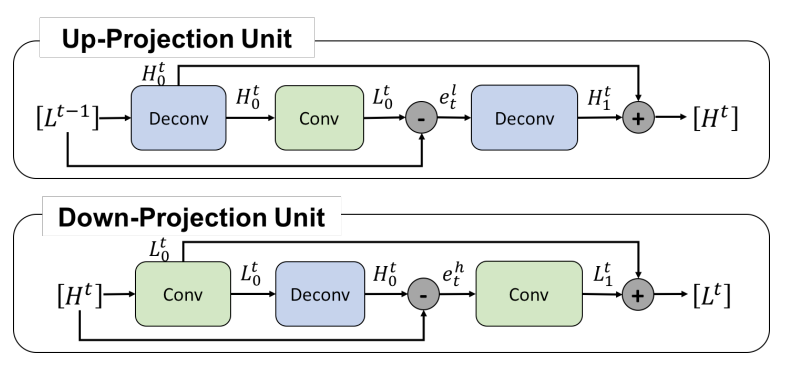
提出的迭代上下采样及上下映射单元:
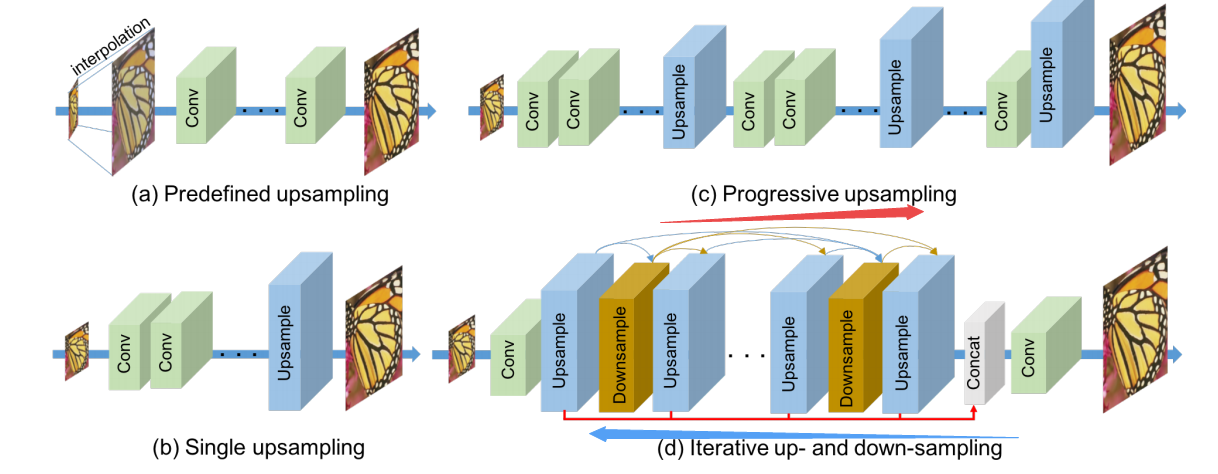
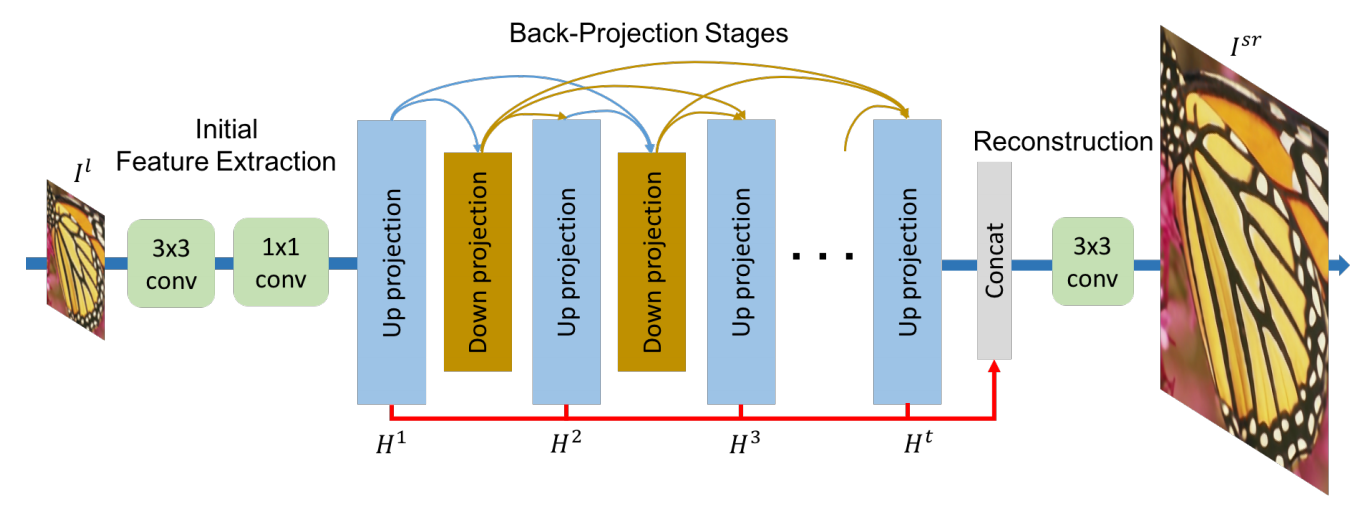
基于稠密连接的架构图,反传使得特征可以复用:
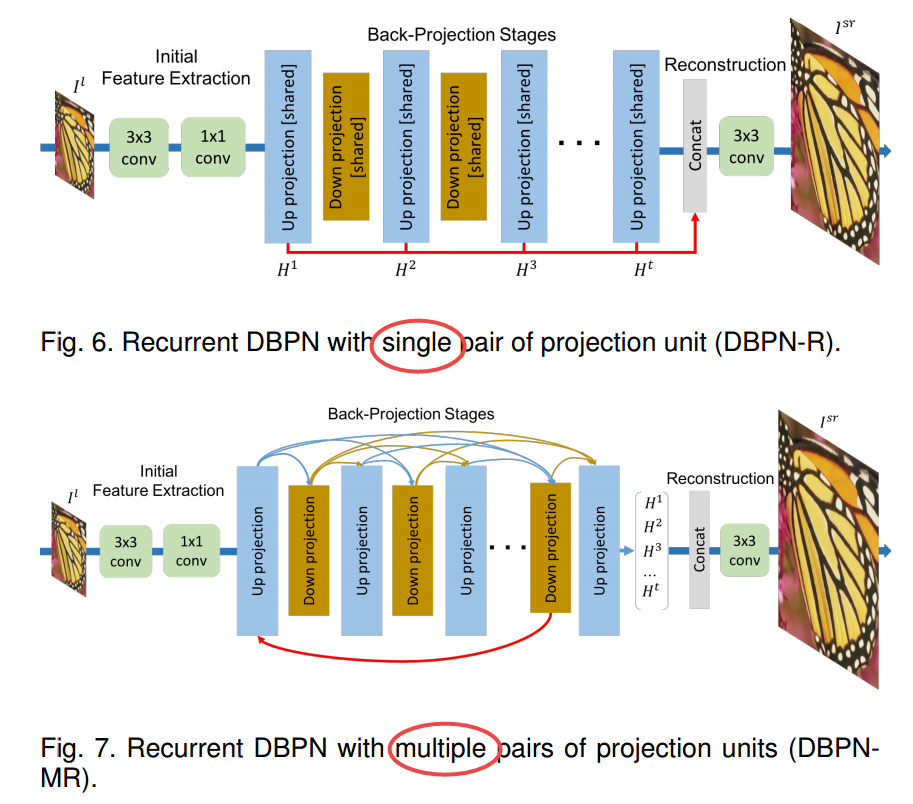
单对和多对映射:
模型的表现和结果:


与一系列其他方法的比较:
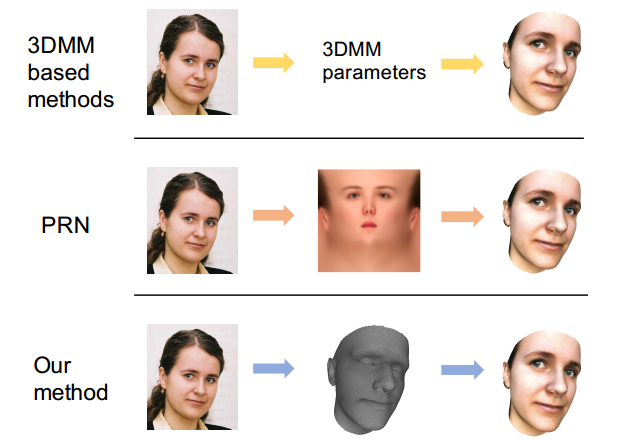
?基于图卷积的稠密人脸对齐, 3D人脸重建和对齐逐渐整合到单一任务中来,这篇文章提出了一种基于图卷积神经网络的人脸坐标回归系统,并直接在3D人脸网格上进行操作,并保持了几何结构和细节信息。(from 华为、旷视 )
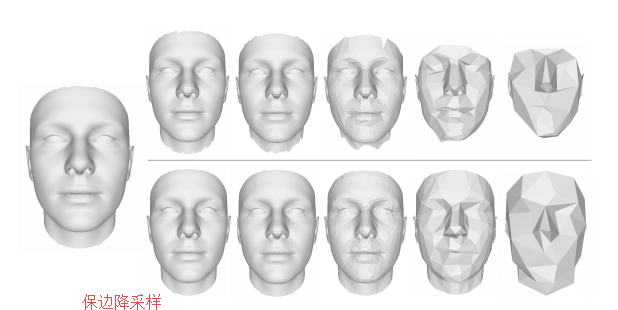
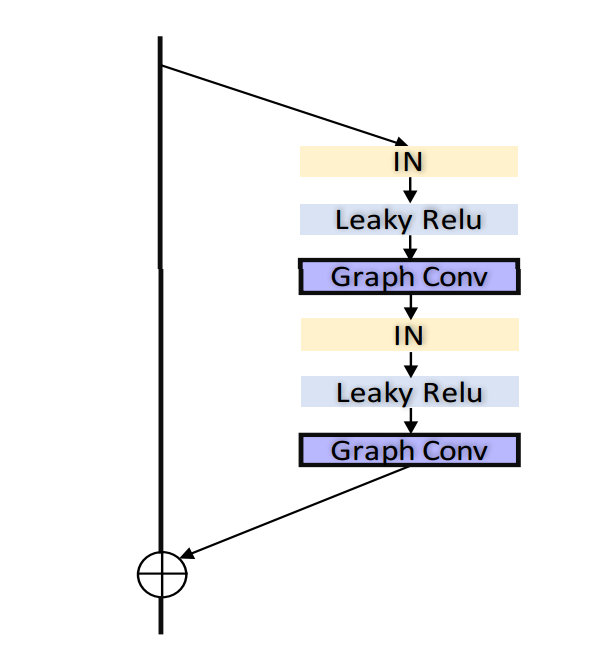
解码器细节和图卷积残差模块:

dataset:AFLW2000-3D AFLW-LFPA Florence
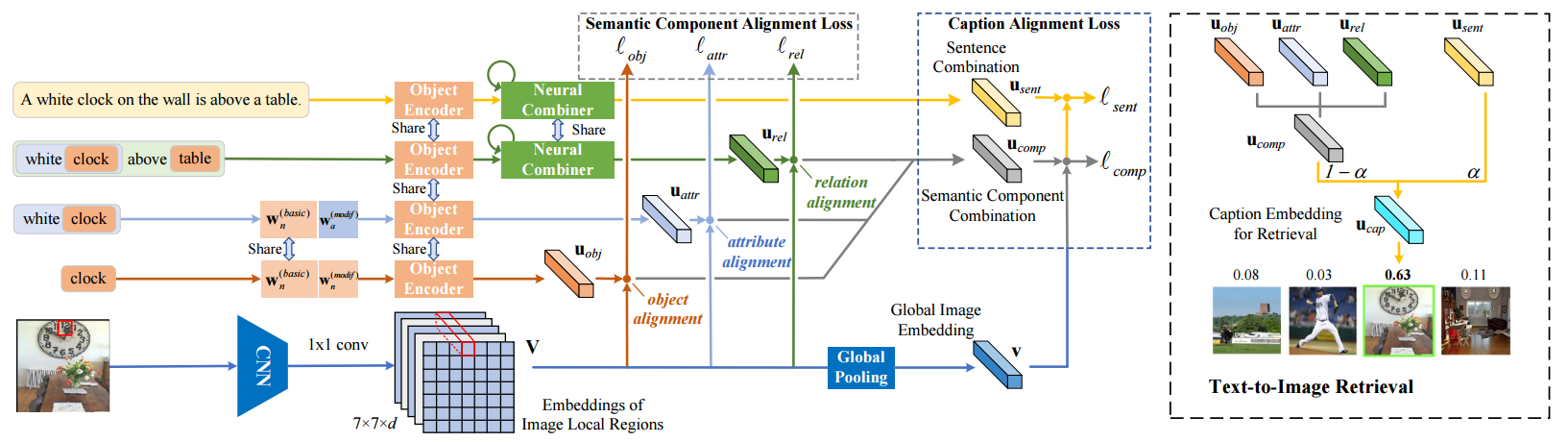
?Unified Visual-Semantic Embeddings, 提出了一个视觉与语义联合的嵌入空间,搭建起了视觉图像和语言沟通的桥梁。从对象、属性、关系和全景等层次展开,并将语义序列视为不同语义元素的结合,并将其匹配到不同的图像区域。(from 复旦大学)
语义与图像的匹配:
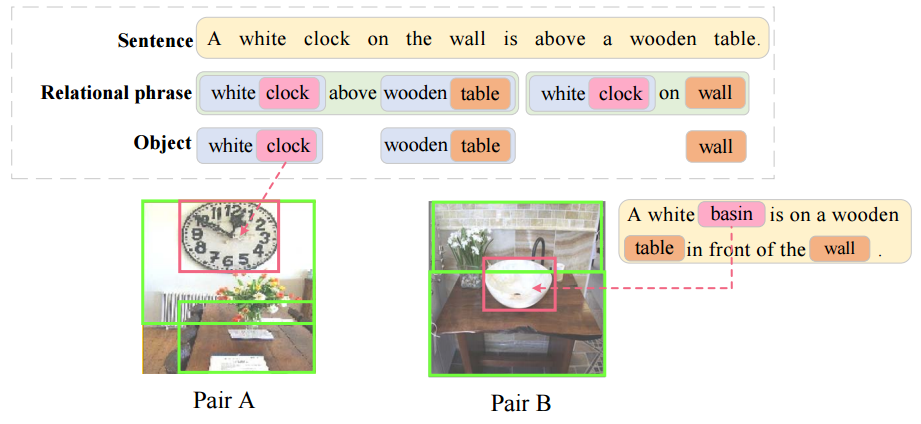
VSE的架构图:
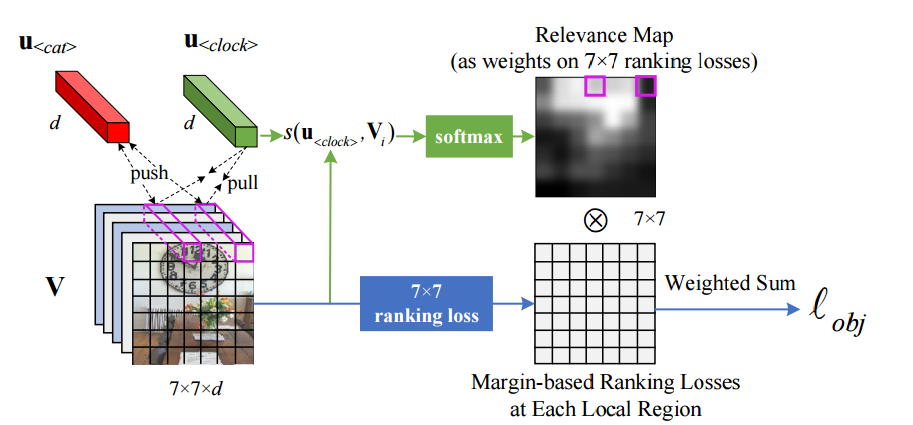
相关权重匹配和一些结果:

Common Crawl dataset
?多标签分类问题的探究, 基于五个数据集(VOC, COCO, NUSWIDE,
ADE20k and Recipe1M)分析了针对多任务分类问题的适用性。研究发现,图像中出现多个共生标签以及预测的标签数十分重要,超参数调参会带来明显的提升,并在3个数据集上得到了最优秀的结果。(from facebook)
不同数据集的预测及结构:

·code:http://anonymous.url/
?BAOD: Budget-Aware Object Detection, (from 洛斯安第斯大学 加州)
Daily Computer Vision Papers
| Factor Graph Attention Authors Idan Schwartz, Seunghak Yu, Tamir Hazan, Alexander Schwing 对话是交换信息的有效方式,但细微的细节和细微差别非常重要。尽管取得了重大进展,但已经为解决算法的视觉对话铺平了道路,但细节和细微差别仍然是一个挑战。注意机制已经证明了在视觉问题回答中提取细节的令人信服的结果,并且由于其可解释性和有效性而为视觉对话提供了令人信服的框架。然而,伴随视觉对话的许多数据工具挑战了现有的注意力技术。我们解决了这个问题,并开发了一个可视对话的一般注意机制,可以在任意数量的数据工具上运行。为此,我们设计了一个基于因子图的注意机制,它结合了任意数量的效用表示。我们说明了所提出的方法对具有挑战性和最近引入的VisDial数据集的适用性,在VisDial0.9上优于1.1的最新技术方法,在MRR上优于VisDial1.0的2。我们的集合模型将VisDial1.0的MRR得分提高了6个以上。 |
| Two Body Problem: Collaborative Visual Task Completion Authors Unnat Jain, Luca Weihs, Eric Kolve, Mohammad Rastegari, Svetlana Lazebnik, Ali Farhadi, Alexander Schwing, Aniruddha Kembhavi 协作是执行超出一个代理功能的任务的必要技能。广泛应用于传统和现代AI,多代理协作通常在简单的网格世界中进行研究。我们认为合作存在固有的视觉方面,应该在视觉丰富的环境中进行研究。协作中的一个关键要素是通过显示,通过消息或隐式,通过对其他代理和视觉世界的感知来进行通信。学习在视觉环境中进行协作需要学习1来执行任务,2何时和什么进行交流,以及3如何基于这些通信和视觉世界的感知来行动。在本文中,我们研究了直接从AI2 THOR中的像素进行协作的问题,并展示了显式和隐式通信模式执行视觉任务的好处。有关详细信息,请参阅我们的项目页面 |
| A Simple Baseline for Audio-Visual Scene-Aware Dialog Authors Idan Schwartz, Alexander Schwing, Tamir Hazan 最近提出的视听场景感知对话任务为学习虚拟助手,智能扬声器和汽车导航系统的更加数据驱动的方式铺平了道路。然而,迄今为止,关于如何从过多的传感器中有效地提取有意义的信息以及这些设备的计算引擎的知识,我们知之甚少。因此,在本文中,我们提供并仔细分析了一个端到端训练的视听场景感知对话的简单基线。我们的方法使用注意机制以数据驱动的方式区分来自分散注意力的信号的有用信号。我们在最近推出的具有挑战性的视听场景知识数据集上评估了所提出的方法,并展示了在CIDEr上超过现有技术水平超过20的关键特性。 |
| An Empirical Study of Spatial Attention Mechanisms in Deep Networks Authors Xizhou Zhu, Dazhi Cheng, Zheng Zhang, Stephen Lin, Jifeng Dai 注意机制已成为深度神经网络中的一个流行组件,但很少有人研究不同的影响因素和计算这些因素影响性能的方法如何影响性能。为了更好地理解注意力机制,我们提出了一个实证研究,该研究消除了广义注意力公式中的各种空间注意力元素,包括主要的变压器注意以及普遍的可变形卷积和动态卷积模块。该研究针对各种应用进行了研究,得出了深层网络空间关注的重要发现,其中一些与传统理解背道而驰。例如,我们发现Transformer关注中的查询和关键内容比较对于自我关注是微不足道的,但对编码器解码器的关注至关重要。可变形卷积与关键内容的适当组合仅显着性实现了自我关注中的最佳准确性效率权衡。我们的研究结果表明,注意机制的设计存在很大的改进空间。 |
| An Analysis of Pre-Training on Object Detection Authors Hengduo Li, Bharat Singh, Mahyar Najibi, Zuxuan Wu, Larry S. Davis 我们提供了对卷积神经网络的详细分析,这些网络是在对象检测任务上预先训练过的。为此,我们在大型数据集上训练检测器,如OpenImagesV4,ImageNet Localization和COCO。我们分析了它们的特征在PASCAL VOC,Caltech 256,SUN 397,Flowers 102等小数据集上的图像分类,语义分割和对象检测等任务的概括性。我们分析的一些重要结论是1大型检测数据集的预训练是对于小型检测数据集的微调至关重要,尤其是在需要精确定位时。例如,我们在OpenImagesV4预培训后,在0.7 IoU的PASCAL VOC数据集上获得81.1 mAP,比最近提出的使用ImageNet预训练的DeformableConvNetsV2好7.6。 2检测预训练也有利于其他定位任务,如语义分割,但会 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









