







今日CS.CV 计算机视觉论文速览
Mon, 10 Jun 2019
Totally 38 papers
?上期速览 ✈更多精彩请移步主页

Interesting:
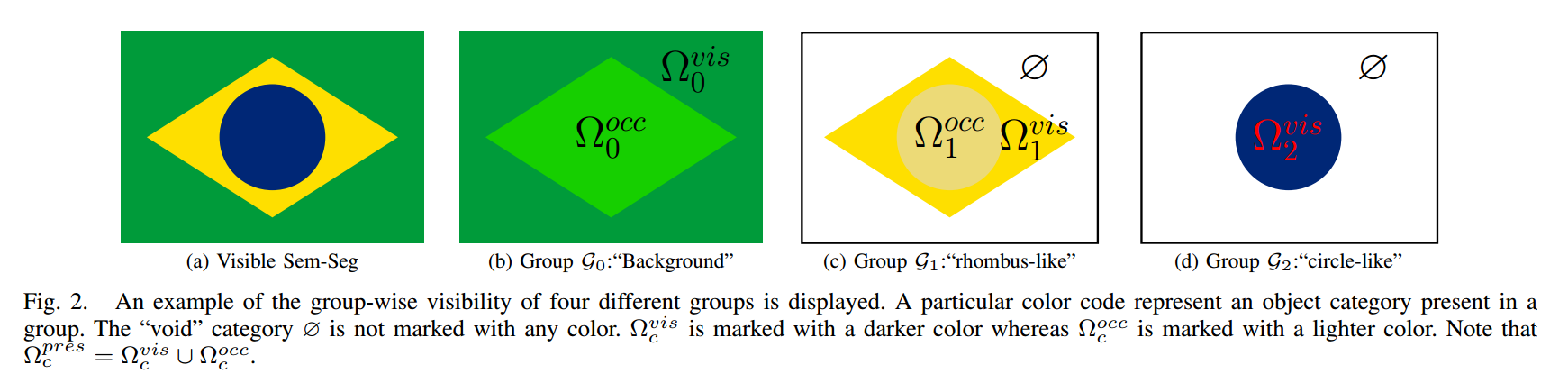
?遮挡区域语义分割, 研究人员将语义分割模型拓展到了看不见的区域上,为遮挡物体也提出了有效的语义分割。将前景和背景分开, 按照分组的方式进行分割,在不增加网络尺寸的情况下可以通过改造的交叉熵来实现有效分割。(from 阿德莱德大学 澳大利亚)
一般语义分割与分组语义分割,可以将遮挡的部分背景有效分解出来:
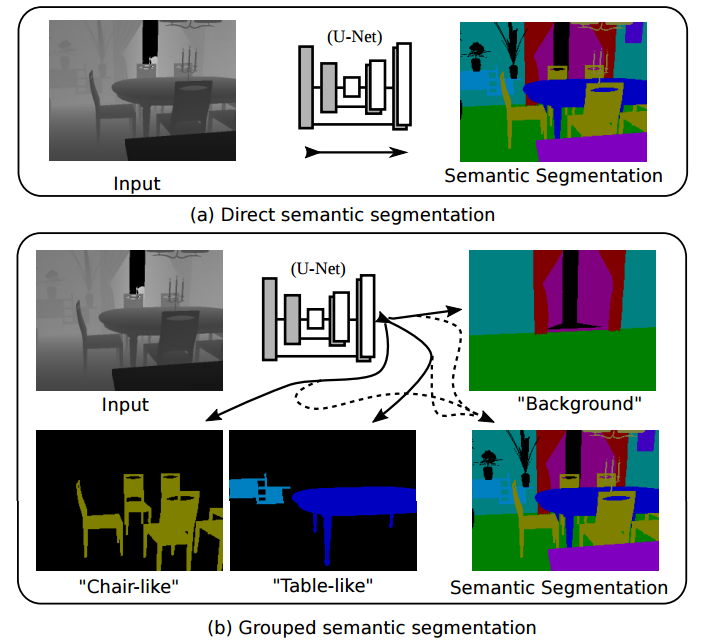
分组语义分割的例子:
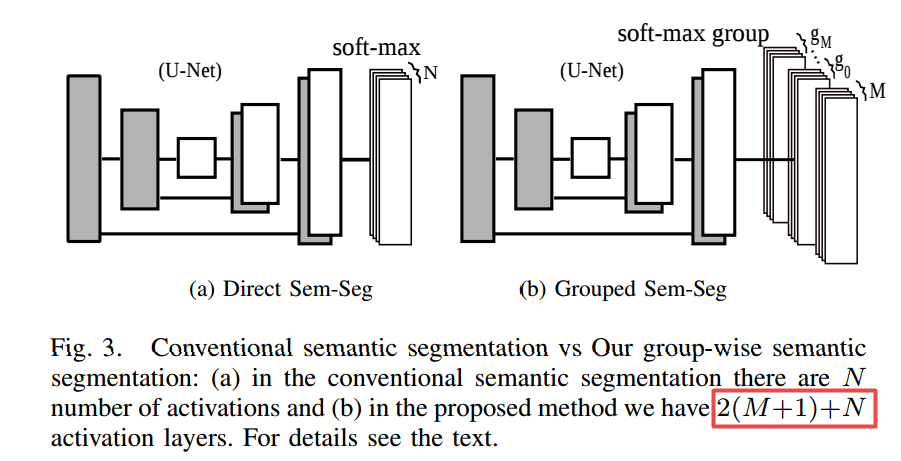
在标准语义分割的基础上增加了2(M+1)个分组(M 为分组数,N为类别数):
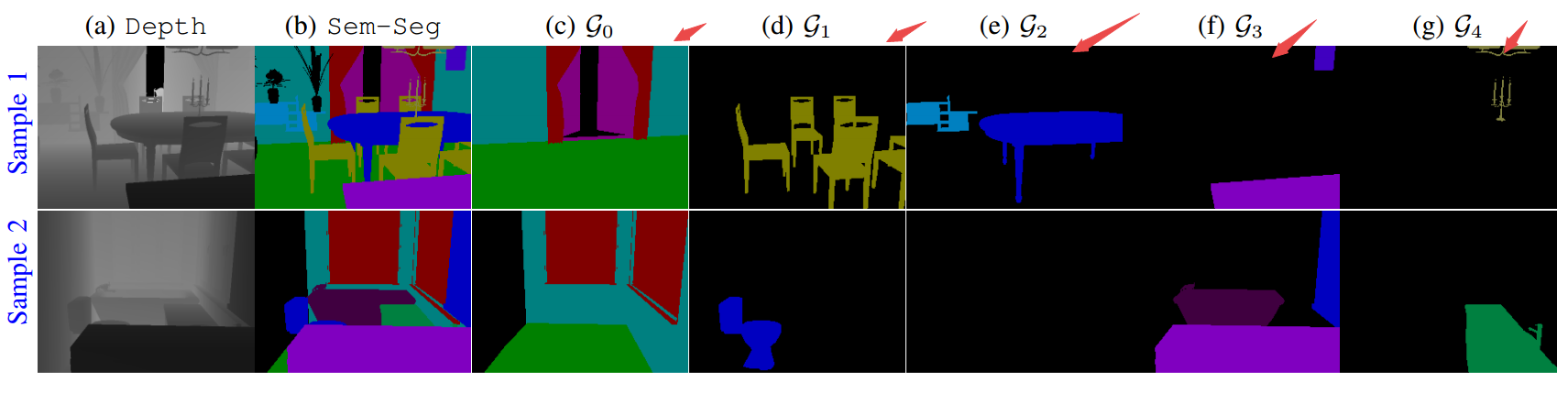
结果如下所示,可以看到不同组别的分类和每一组内各自的分类:
ref:https://github.com/shurans/SUNCGtoolbox
https://shurans.github.io/
dataset:SUNCG
?无人机用于环境和场景检测, UAV和多种相机结合实现对于不同作物的检测可以实现分类、计数、检测、产量预测、病虫害防治等,这篇文章总结了无人机在各个方面的应用和研究,将为智能农场提供新的思路。(from Kingston University, UK)
基于UAV的作物分类:

基于UAV的生产预测:

种植面积和害虫检测:
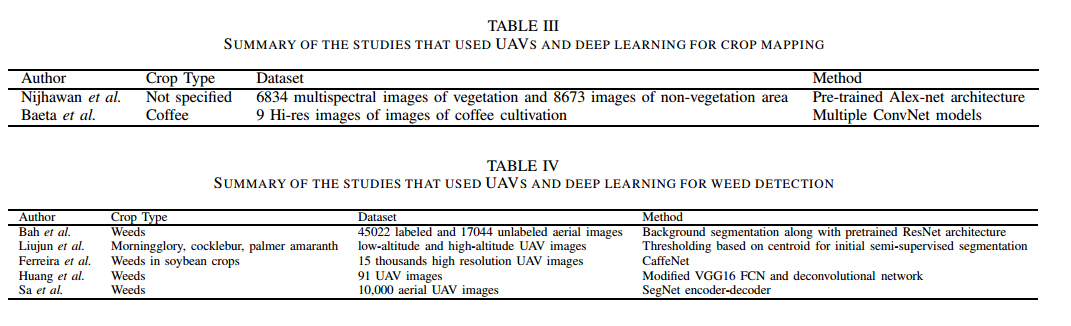
营养和病害检测:

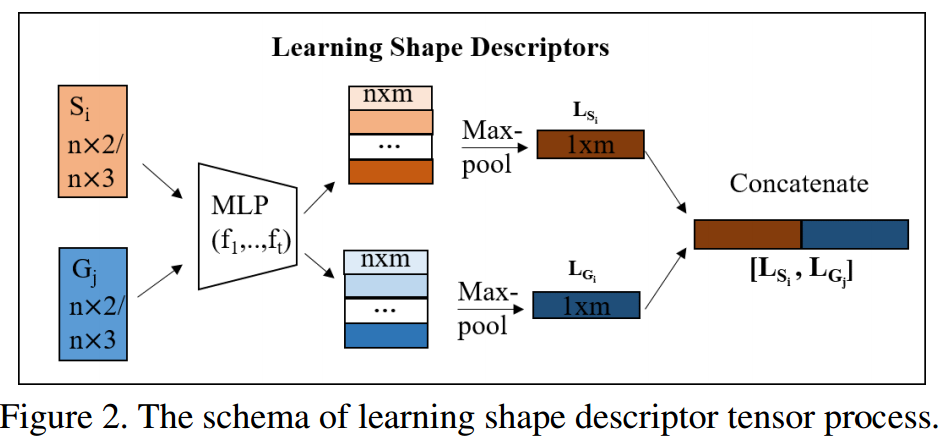
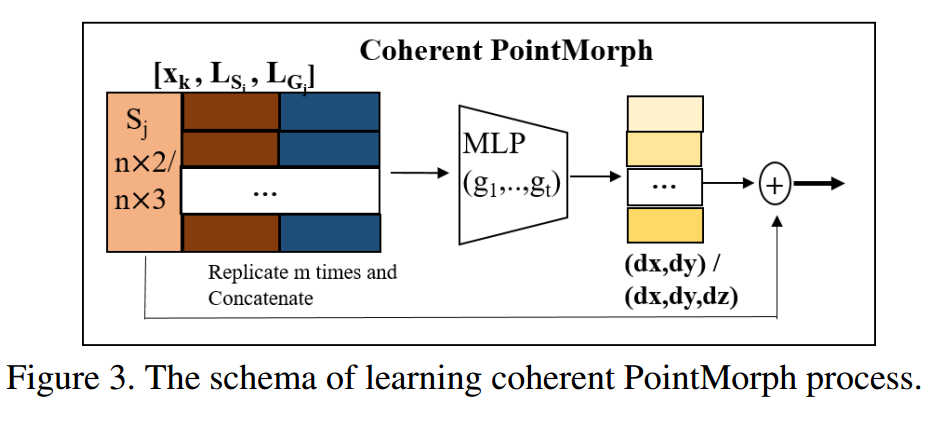
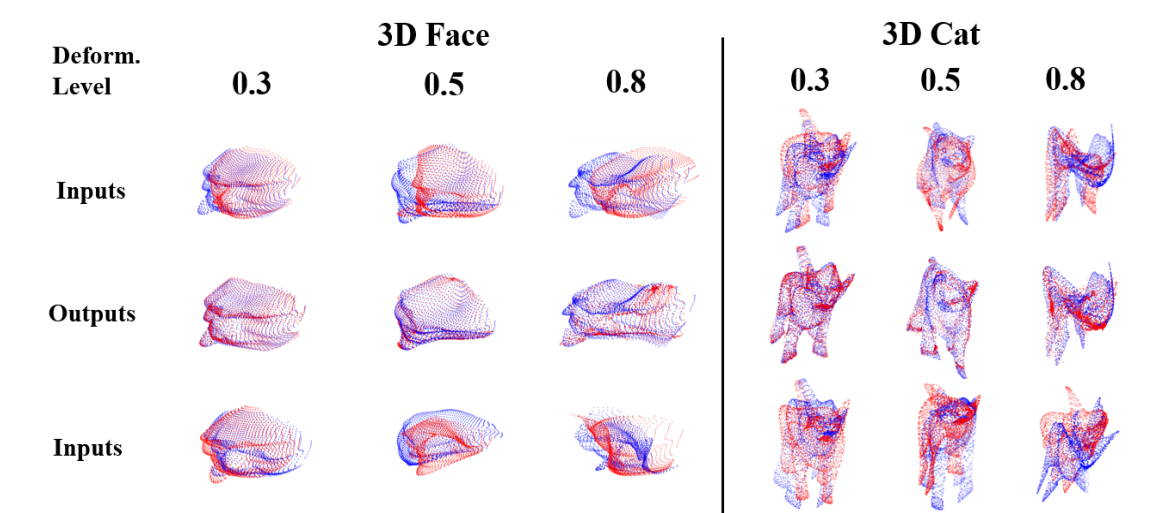
? coherent point drift networks,CPD-Net用于非刚体的配准网络, 传统的点云配准方法需要搜索一个集合变换来将源于目标配准,但十分耗时。这篇论文提出乐意一种非监督学习的方法可以将实现非刚体点集的实时变换配准,它可以从训练数据中学习到一个位移场函数来估计几何变换,并能够预测位置物体间配准的几何变换。并能够适用于任意函数来对不同复杂度的物体进行几何变换与配准,并可以保证连续位移矢量函数来进行配准。(from 纽约大学)

学习描述子 & 学习位移量:
一些实验结果:
code:https://github.com/Lingjing324/CPD-Net
dataset:4.1. Experimental Dataset
?AutoGrow, 自动深度探索拓展的网络,从浅层架构开始不断根据模型表现拓展架构,通过通用增长和停止策略来最小化人类的介入,可以发现发现有效的网络深度并实现最优的效果。可以有效减少计算和搜索时间,局小于深度发现效率,可以拓展到大规模数据集上。(from 杜克大学)
随着训练不断增长的网络模型:
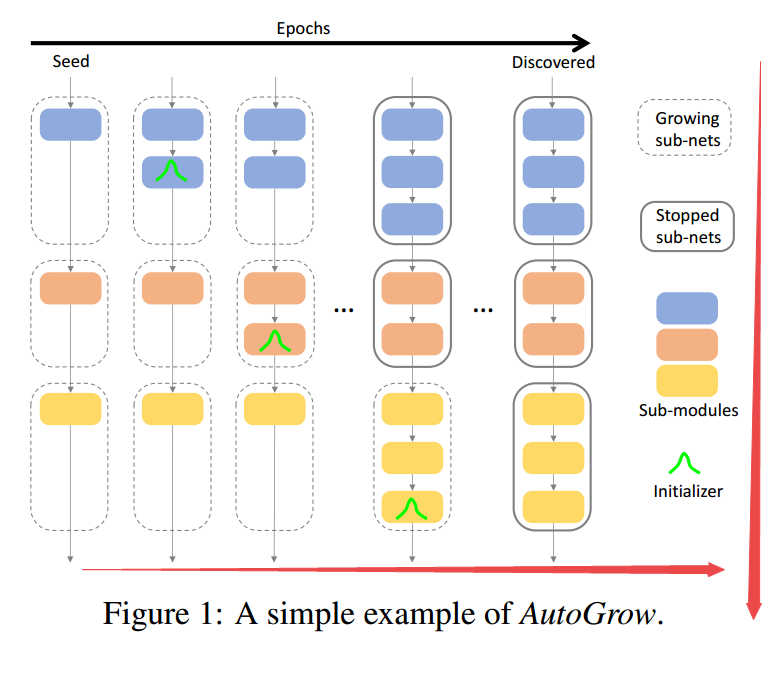
code:https://github.com/wenwei202/autogrow
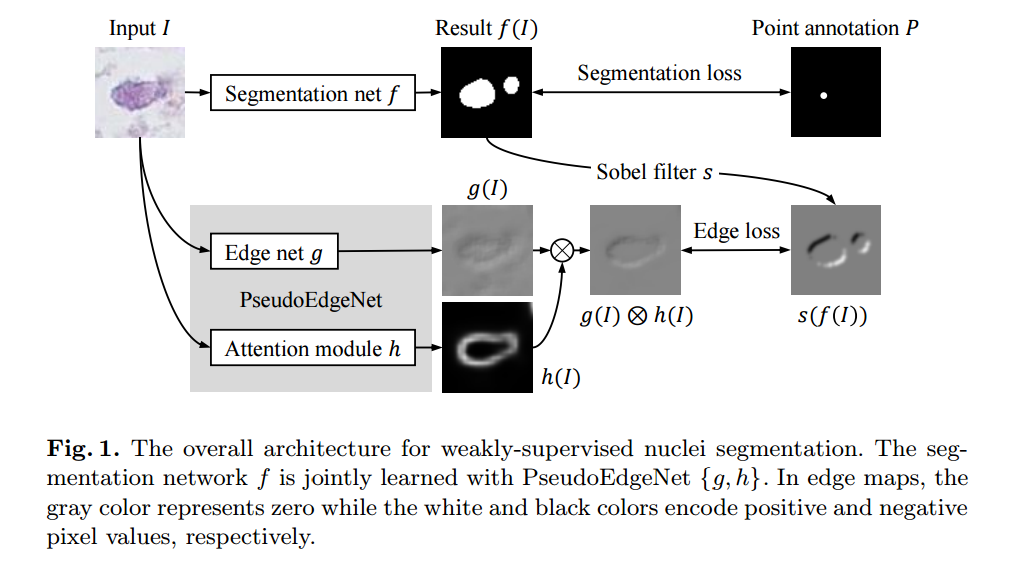
?基于点标记的细胞分割方法,弱监督方法, (from Lunit Inc., Seoul, South Korea)
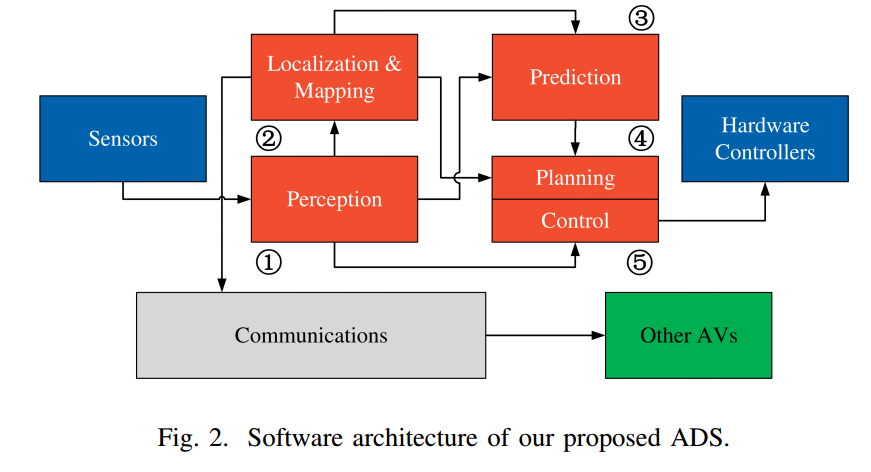
?自动驾驶汽车重点技术综述, (from https://www.webofknowledge.com)
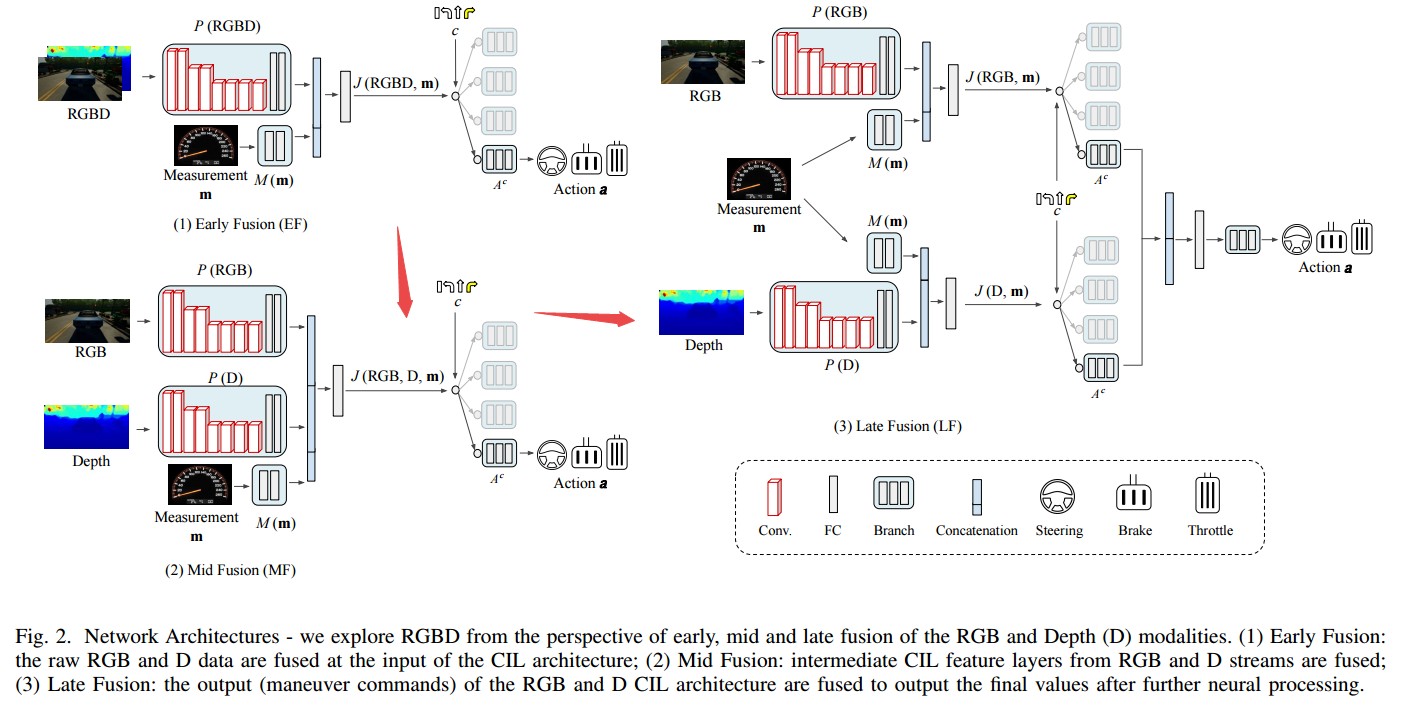
?多模态端到端自动驾驶, (from Univ. Autonoma de Barcelona (UAB).)
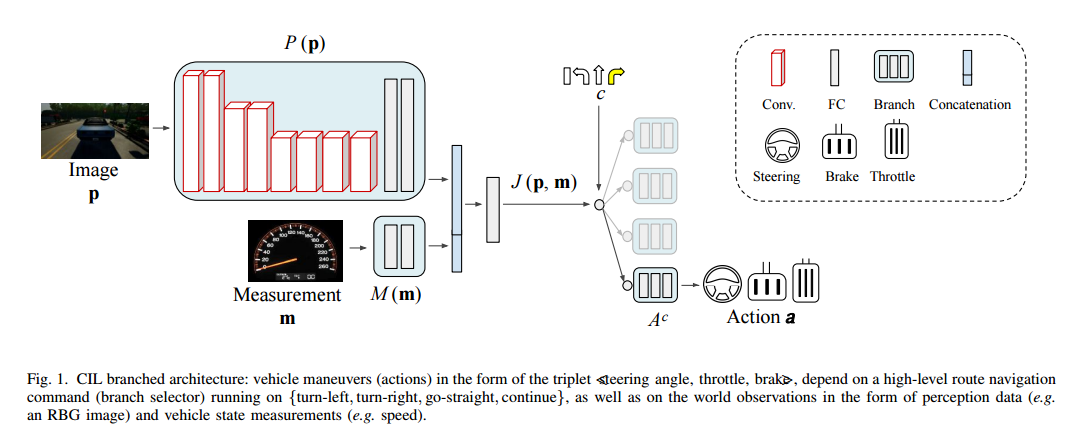
网络架构:
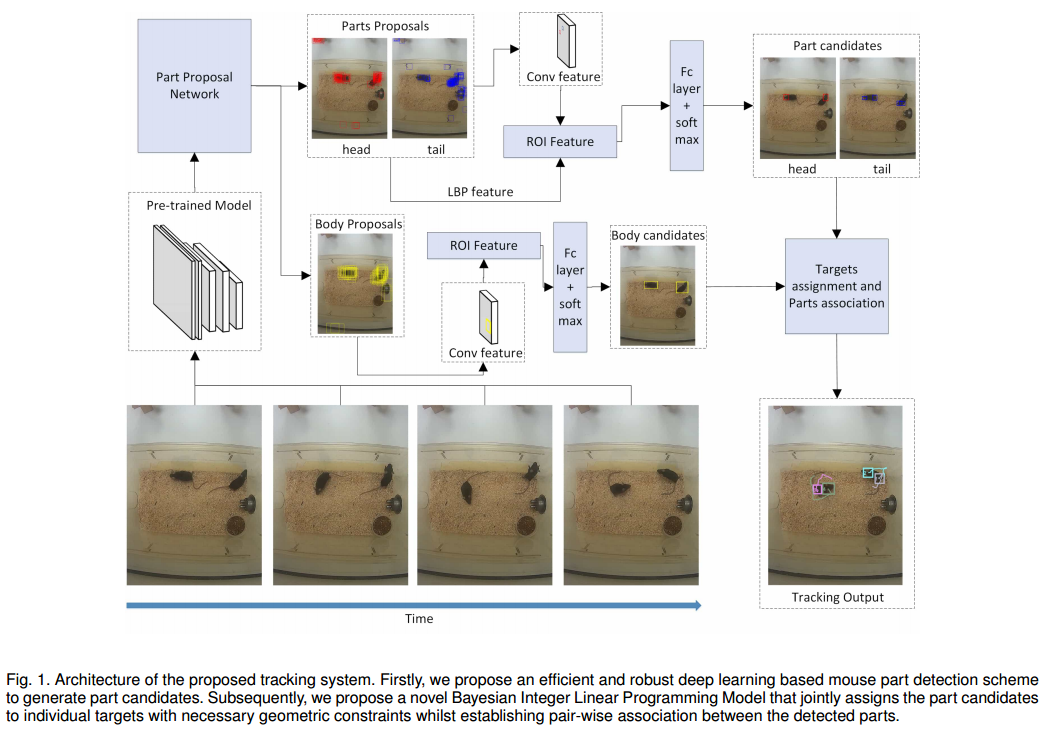
?多主体检测与跟踪方法, (from University of Leicester, United Kingdom)
Daily Computer Vision Papers
| Evolving Losses for Unlabeled Video Representation Learning Authors AJ Piergiovanni, Anelia Angelova, Michael S. Ryoo 我们提出了一种从未标记数据中学习视频表示的新方法。给定大规模未标记的视频数据,目标是通过学习可以直接用于新任务(例如零次射击学习)的通用且可转移的表示空间来从这样的数据中受益。我们将无监督表示学习表示为多模态,多任务学习问题,其中表示也通过蒸馏在不同模态中共享。此外,我们还介绍了使用进化算法找到更好的损失函数来训练这样的多任务多模态表示空间的概念,我们的方法自动搜索捕获多个自监督任务和模态的损失函数的不同组合。我们的公式允许将音频,光流和时间信息提升到单个基于RGB的卷积神经网络中。我们还比较了使用其他未标记视频数据的效果,并评估了我们在标准公共视频数据集上的表示学习。 |
| **Extracting Visual Knowledge from the Internet: Making Sense of Image Data Authors Yazhou Yao, Jian Zhang, Xiansheng Hua, Fumin Shen, Zhenmin Tang 最近在视觉识别方面的成功主要归功于特征表示,学习算法以及标记的训练数据的不断增加的大小。对前两个问题进行了广泛的研究,但对第三个问题的关注却少得多。由于手动标签的高成本,ImageNet等近期工作的规模在日常应用方面仍然相对较小。在这项工作中,我们主要关注如何大规模自动生成给定视觉概念的识别图像数据。利用生成的图像数据,我们可以为给定的概念训练强大的识别模型。我们在基准Pascal VOC 2007数据集上评估了提议的webly监督方法,结果证明了我们提出的方法在图像数据收集中的优越性。 |
| ****Multimodal End-to-End Autonomous Driving |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









