










AI视野·今日CS.CV 计算机视觉论文速览
Tue, 6 Aug 2019
Totally 63 papers
👉上期速览✈更多精彩请移步主页

Interesting:
📚CRNet基于卷积稀疏编码的图像超分辨技术,卷积稀疏编码(CSC)技术由于可以利用图像全局的相关性改进算法表现,受到越来越多的关注。这篇文章探索了卷积稀疏编码与常规卷积的关系,并研究了卷积迭代软阈值(Iterative Soft Thresholding Algorithm (ISTA) [5] ,CISTA)的方法来解决稀疏编码问题,并利用CNN架构实现,同时引入了前处理和后处理上采样架构来解决图像超分辨问题。(from 武汉大学)
CISTA的架构如下:
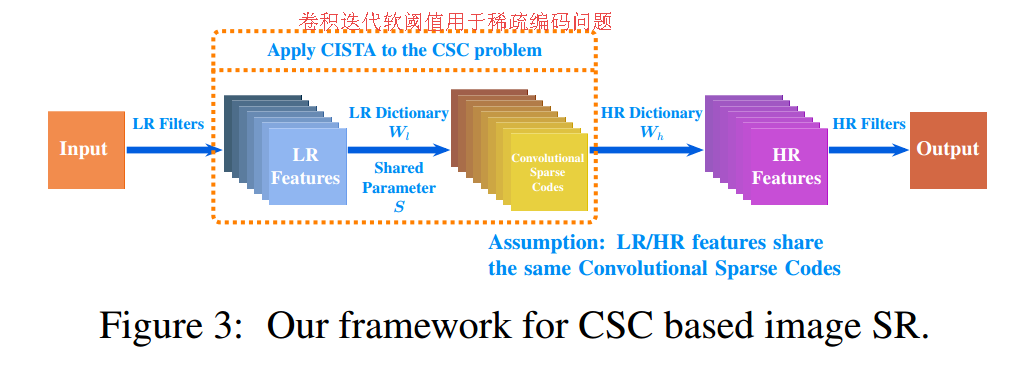
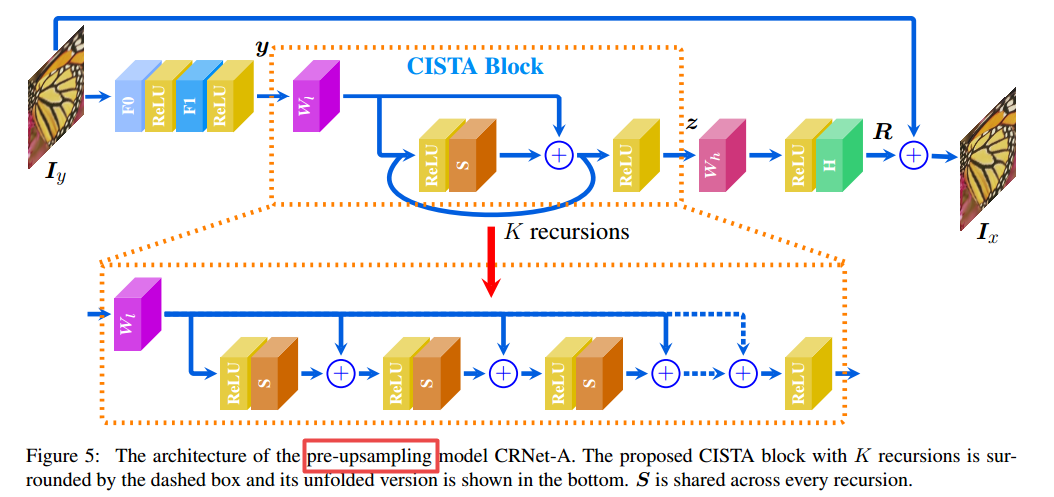
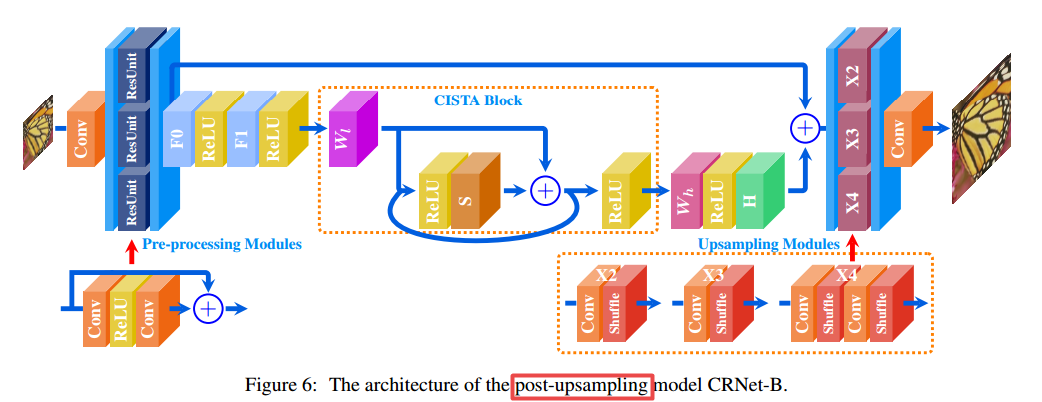
基于这种稀疏编码方法研究人员分别提出了上采样的前处理和后处理架构,其中CISTA模块在模型中对低分辨特征按照迭代的方式进行稀疏编码:
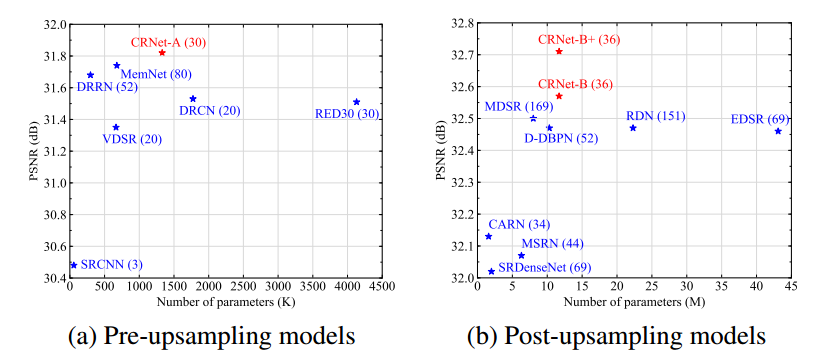
最终在x4图像超分辨上的表现如下图所示:

与其他模型在结构上的区别:
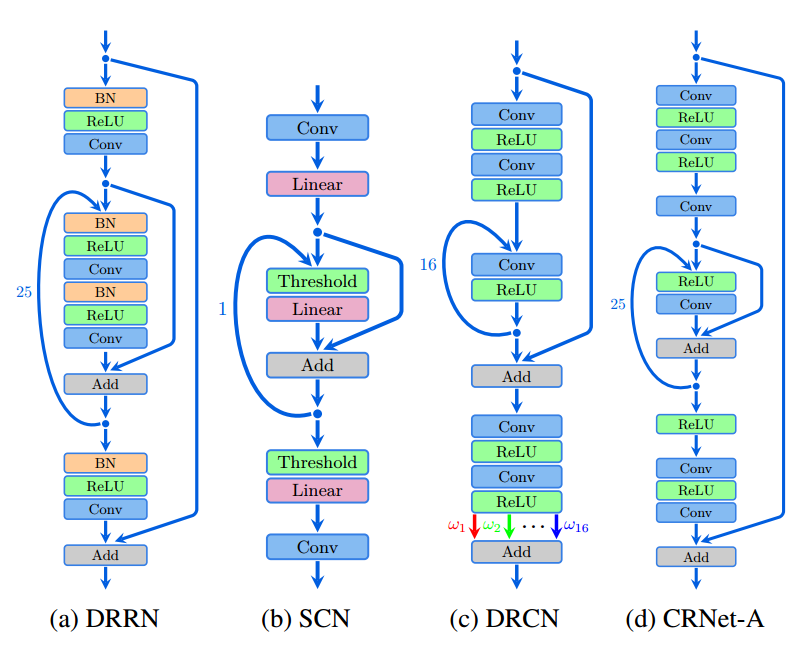
📚SESF-Fuse多景深图像的融合技术, 研究人员提出了一种非监督的深度学习模型用于融合多焦段的图像。由于在景深中的物体才有锐利清晰的显示,而其他离焦物体则会变得模糊。研究人员通过估计决策图的方式来融合不同焦段的图像,充分利用了深度特征来代替原始图像进行融合。(from 北京科技大学)
方法的框架如下图所示,首先训练编码器用于从输入图像中获取深度特征、随后利用这些特征和频率来测量活跃度和决策图,最后利用连续性验证方法来调整决策图并得到融合的结果。
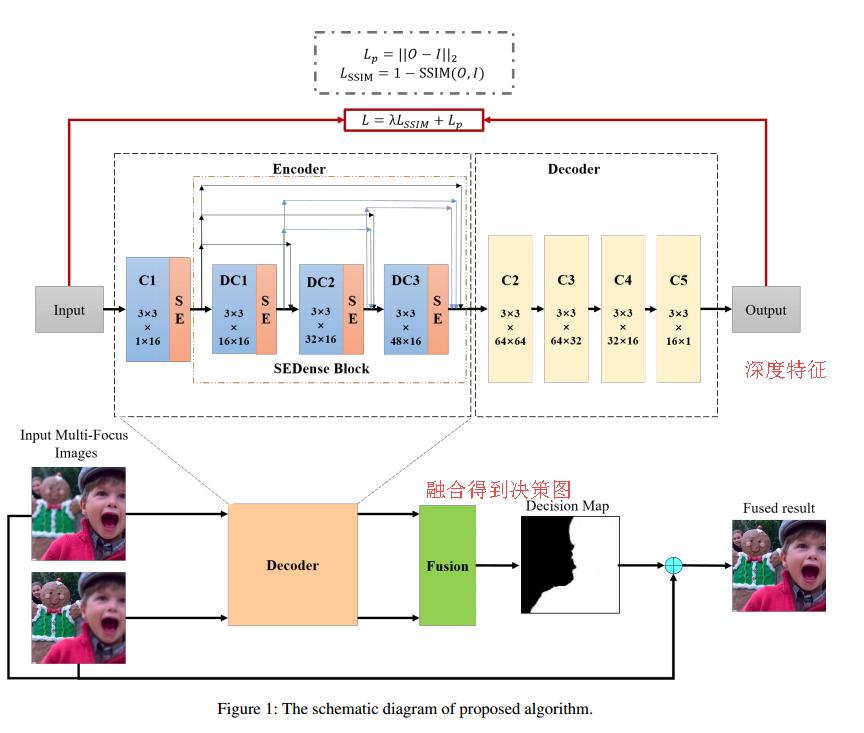
特征融合获取决策图的方法,其中利用特征梯度(空间频率)代替特征强度来计算活跃级别(activity level):
基于这种方法得到的结果及比较:

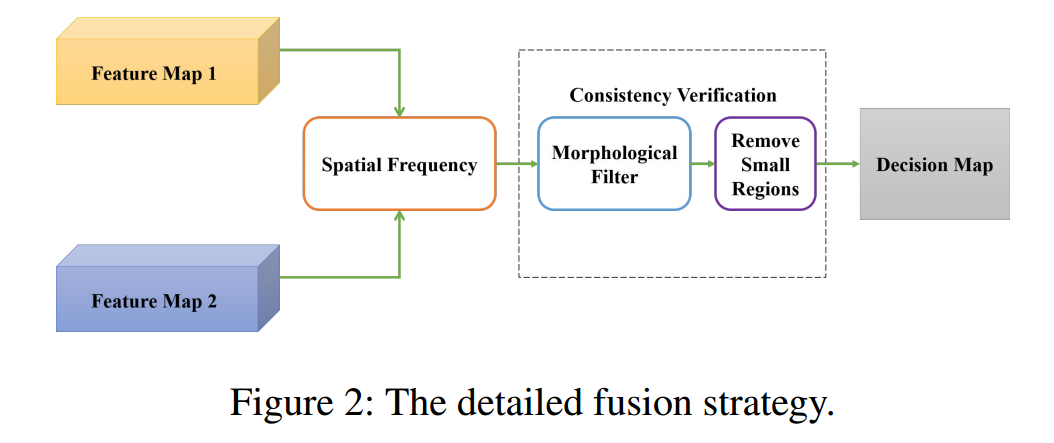
📚CameraNet图像原始信号处理的网络模型,将卷积神经网络用于相机的原始信号处理以获取高质量的RGB图像,模型包含了修复部分和提升部分,利用分离训练的方法并合成构成工作流。(from 香港理工)
用于图像修复和提升的基本Unet架构,整个CameraNet系统包含了两个修复网络和两个颜色空间线性变换:
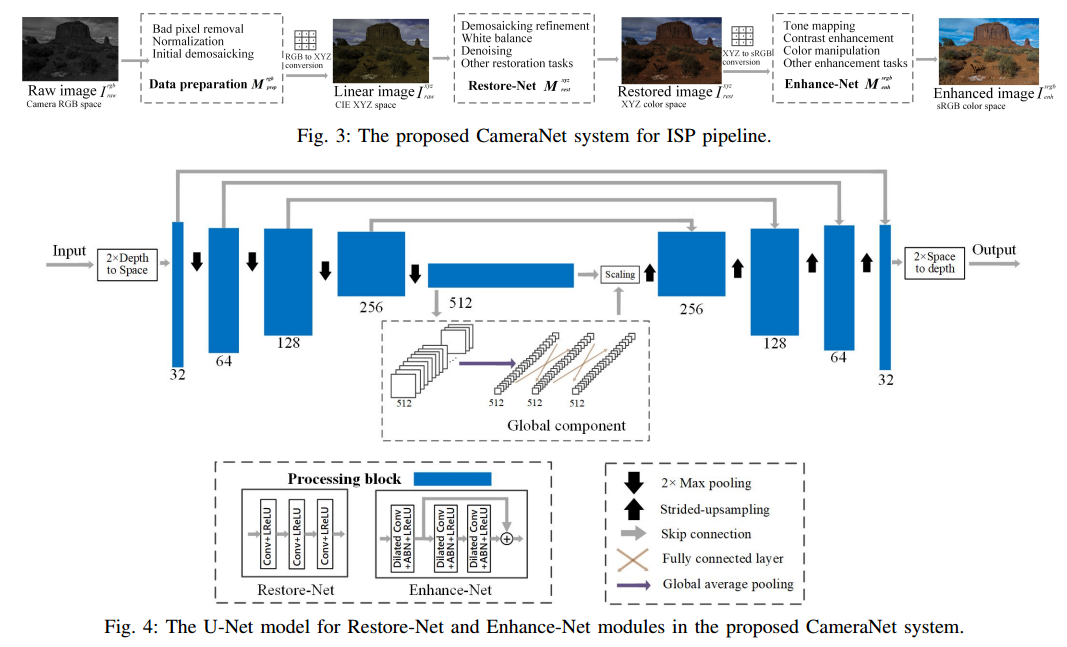
网络的具体架构如下图所示,其中修复图像训练的raw数据来源于Adobe Camera Raw,提升图像的训练数据来源于LightRoom。(数据用adobe 软件构建)研究人员将ISP的任务归结为图像修复(mainly including demosaicking,denoising and white balance.)和提升(exposure adjustment, tone mapping and color enhancement)两个部分,from part 3.B
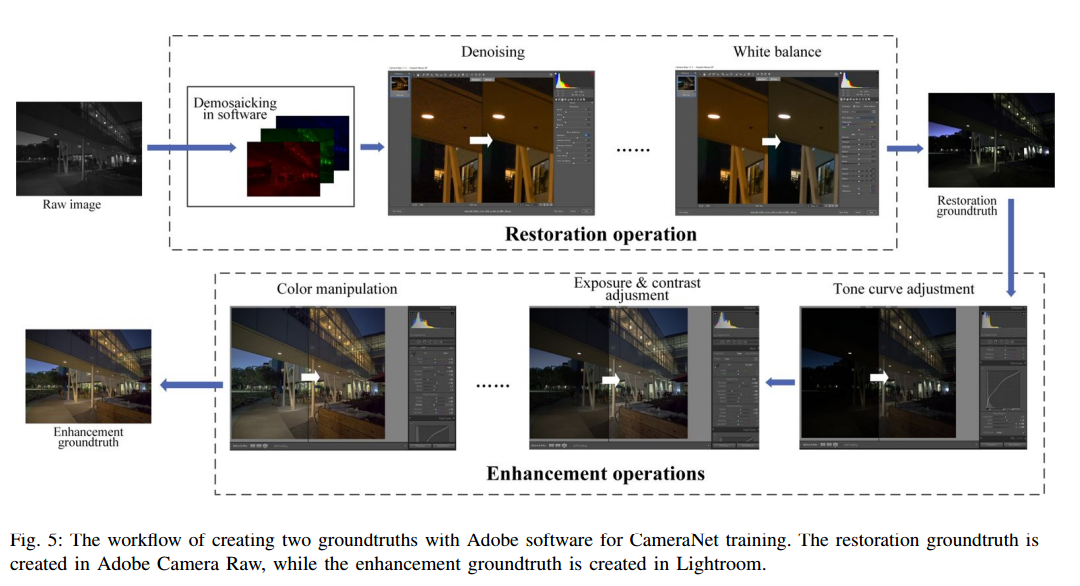
一些实现的结果:


以及与相关方法的指标比较:

Dataset: The simplest creation method is to use Adobe software or DCRaw to process the input raw image and sequentially obtain a restored image and an enhanced image as groundtruths.
Benchmark:HDR+(details), SID and FiveK+(color style) datasets
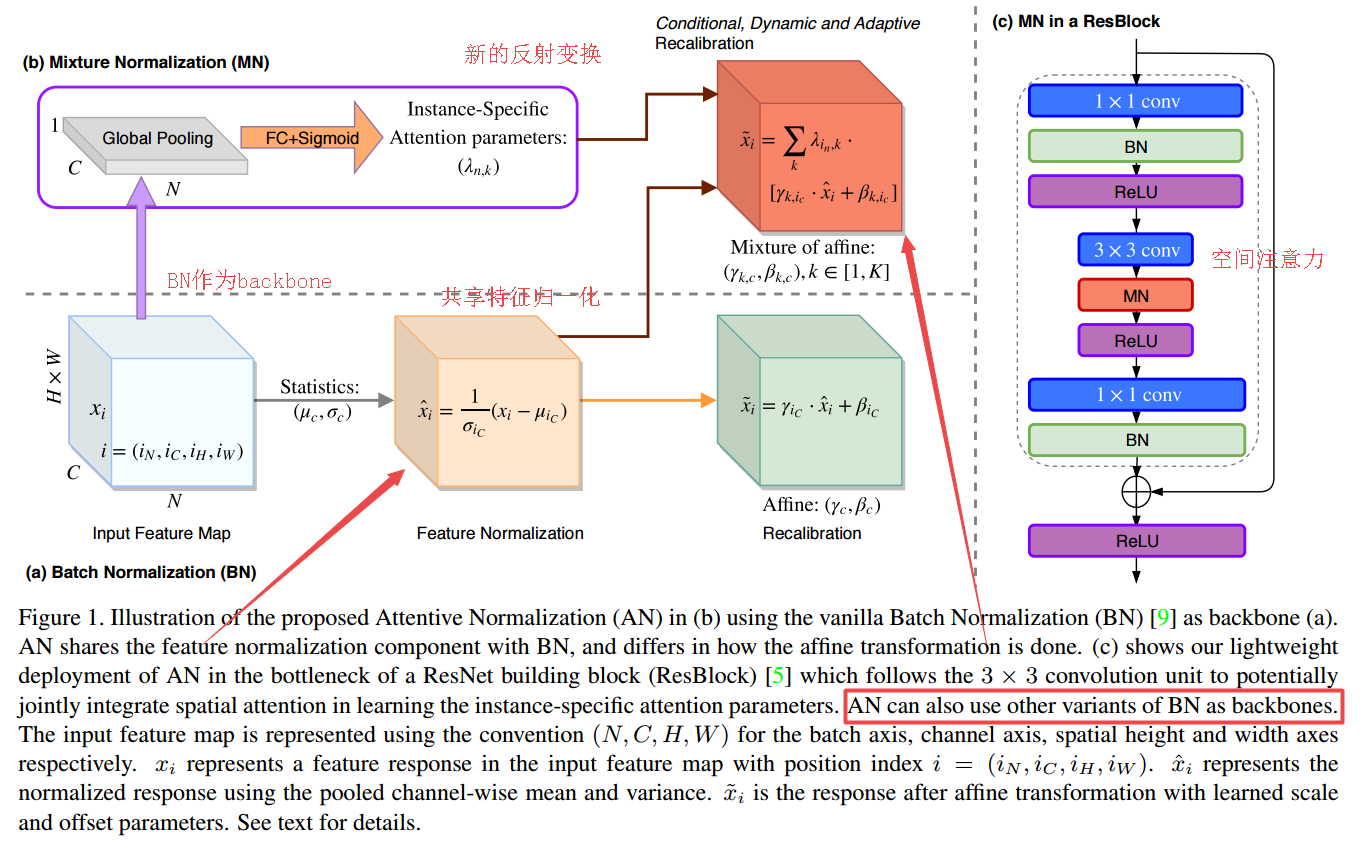
📚Attentive Normalization 新的归一化方法注意力归一化,基于batchnormal研究人员们开发出了GroupNormal和SwitchableNormal等方法来从不同的角度考虑minibatch内的均值和方差以及特征归一化,随后进行可学习的逐通道的仿射变换。而局域序列-激活(SE)的逐通道特征注意力方法则着重校准逐通道的特征。在这篇文章中,研究人员提出了一种联合特征归一化和特种通道注意力的方法AttentiveNoramal,将序列激活的优点集成到BN中。AN为每个通道学习小规模的尺度和偏置参数,并将权重的和用于最终的仿射变换。这些权重浴室里相关,并基于逐通道的注意力来学习,基于SE的思想补充了BN的不足。(from 北卡大学)
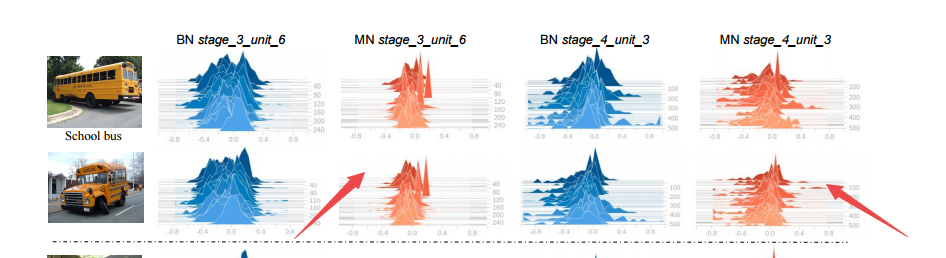
可以看到新的归一化方法权重方差更小,特征更为相似:
# pytorch中AN的代码实现
class AttenNorm(nn.BatchNorm2d):
def _init_( self , C, K, eps, momentum, running):
super(AttenNorm, self )._init_(C, eps=eps, momentum=momentum, affine=False, track_running_)stats=running)
self.gamma = nn.Parameter(torch.Tensor(K, C))
self.beta = nn.Parameter( torch .Tensor(K, C))
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear (C, K)
self.sigmoid = nn.Sigmoid()
def forward( self , x):
output = super(AttenNorm, self ) . forward(x)
size = output . size ()
b, c,_,_= x. size ()
y = self.avgpool(x) . view(b, c)
y = self.fc (y)
y = self.sigmoid(y)
gamma = y @ self.gamma
beta = y @ self . beta
gamma = weight.unsqueeze(−1).unsqueeze(−1).expand(size)
beta = bias . unsqueeze(−1).unsqueeze(−1).expand(size)
return gamma ∗ output + beta
#ref super():https://zhuanlan.zhihu.com/p/34317467
# https://www.runoob.com/python/python-func-super.html
code:http://github.com/ivMCL/AttentiveNorm
ref:swithchnormal:https://github.com/switchablenorms/SwitchNorm_Detection/blob/master/lib/nn/modules/normalization.py
Daily Computer Vision Papers
| +++快速语义分割架构搜索方法SqueezeNAS: Fast neural architecture search for faster semantic segmentation Authors Albert Shaw, Daniel Hunter, Forrest Iandola, Sammy Sidhu 对于利用深度神经网络DNN的实时应用,模型在目标任务上实现高精度并在目标计算平台上实现低延迟推断至关重要。虽然神经架构搜索NAS已被有效地用于开发用于图像分类的低延迟网络,但是使用NAS来优化用于其他视觉任务的DNN架构的努力相对较少。在这项工作中,我们展示了我们认为是第一个针对密集语义分段的无代理硬件感知搜索。通过这种方法,我们提高了Cityscapes语义分割数据集上延迟优化网络的最先进精度。我们的延迟优化小型SqueezeNAS网络实现了68.02验证级别mIOU,NVIDIA AGX Xavier的推理时间少于35 ms。我们的延迟优化大型SqueezeNAS网络实现了73.62级mIOU,推理时间少于100毫秒。我们通过利用NAS查找针对特定任务和推理硬件优化的网络,证明可以获得显着的性能提升。我们还提供了详细的分析,将我们的网络与最新的架构进行了比较。 |
| Visual-Relation Conscious Image Generation from Structured-Text Authors Duc Minh Vo, Akihiro Sugimoto 从文本描述生成逼真的图像是一个具有挑战性的问题,并且具有许多应用,例如图像编辑或计算机辅助设计。尽管该文本最近在基于GAN的图像生成方面取得了进展,但是在文献中尚未实现从一般场景中的许多实体的复杂描述生成逼真图像。在存在多个实体的情况下,实体之间的关系变得重要,因为它们调节每个实体的位置。我们提出了一个基于GAN的端到端网络,它从给定的文本中学习实体之间的视觉关系布局,并在生成图像时调整布局。我们提出的网络包括视觉关系布局模块和堆叠GAN。视觉关系布局模块预测输入文本中给出的所有实体的边界框,使得它们中的每一个唯一地对应于每个实体,同时保持其涉及的关系。通过聚合所有边界框来获得视觉关系布局,反映文本中给出的场景结构。堆叠GAN是以先前GAN的输出和视觉关系布局为条件的三个GAN的堆叠,一致地捕获场景结构。我们的网络在保持场景结构的同时,以高分辨率逼真地呈现实体细节。两个公共数据集的实验结果表明我们的方法优于现有技术方法。 |
| ++语义视觉嵌入学习 Learning a Unified Embedding for Visual Search at Pinterest Authors Andrew Zhai, Hao Yu Wu, Eric Tzeng, Dong Huk Park, Charles Rosenberg 在Pinterest,我们在整个搜索和推荐系统中利用图像嵌入,通过浏览相关内容和搜索确切的购物产品等体验,帮助用户浏览可视内容。在这项工作中,我们描述了一个多任务深度量学习系统,以学习单个统一图像嵌入,可用于为我们的多个视觉搜索产品提供动力。我们提出的解决方案不仅允许我们在单个深度神经网络架构中训练多个应用目标,而且利用来自每个应用的所有训练数据组合的相关信息来生成统一嵌入,其优于先前部署的所有专用嵌入对于每个产品。我们讨论了处理来自不同领域的图像的挑战,例如相机照片,高质量的Web图像和清洁的产品目录图像。我们还详细介绍了如何联合培训多个产品目标以及如何利用参与数据和人工标记数据。此外,我们训练有素的嵌入也可以进行二值化,以实现高效的存储和检索,同时不会影响精度和召回率。通过对离线指标,用户研究和在线A B实验的全面评估,我们证明了与现有的专用嵌入相比,我们提出的统一嵌入提高了我们的视觉搜索产品的相关性和参与度,无论是浏览还是搜索目的。最后,在Pinterest上部署统一嵌入,大大降低了维护多个嵌入的操作和工程成本,同时提高了质量。 |
| SESF-Fuse: An Unsupervised Deep Model for Multi-Focus Image Fusion Authors Boyuan Ma, Xiaojuan Ban, Haiyou Huang, Yu Zhu 在这项工作中,我们提出了一种新的无监督深度学习模型来解决多焦点图像融合问题。首先,我们以无人监督的方式训练编码器解码器网络以获取输入图像的深度特征。然后我们利用这些特征和空间频率来测量活动水平和决策图。最后,我们应用一些一致性验证方法来调整决策图并绘制融合结果。所提出的方法的关键点在于,只有景深DOF内的物体在照片中具有锐利的外观,而其他物体可能被模糊。与以前的作品相比,我们的方法分析了深度特征而不是原始图像的锐利外观。实验结果表明,与现有的16种融合方法相比,该方法在客观和主观评价方面达到了现有的融合性能。 |
| Spatially and Temporally Efficient Non-local Attention Network for Video-based Person Re-Identification Authors Chih Ting Liu, Chih Wei Wu, Yu Chiang Frank Wang, Shao Yi Chien 基于视频的人物识别Re ID旨在匹配非重叠相机的行人的视频序列。如何将视频的空间和时间信息嵌入其特征表示中是一项实际但具有挑战性的任务。虽然大多数现有方法通过聚合图像智能特征和设计神经网络中的注意机制来学习视频特性,但它们仅探索高级特征的帧之间的相关性。在这项工作中,我们的目标是通过非本地注意力操作来完善中间特征以及高级特征,并做出两点贡献。 i我们建议使用非本地视频注意网络NVAN将视频特性合并到多个功能级别的表示中。 ii我们进一步介绍了一种空间和时间效率非本地视频注意网络STE NVAN,通过探索行人视频中呈现的空间和时间冗余来降低计算复杂性。大量实验表明,我们的NVAN在MARS数据集上的等级1精度优于3.8,并证实我们的STE NVAN与现有方法相比具有更优越的计算足迹。 |
| Model Decay in Long-Term Tracking Authors Efstratios Gavves, Ran Tao, Deepak K. Gupta, Arnold W. M. Smeulders 使用不利的边界框预测更新跟踪器模型会为学习添加不可避免的偏差项。这个偏差项,我们称之为模型衰减,抵消了学习并导致跟踪漂移。虽然在短期跟踪中可能看不到其不利影响,但长期累积这种偏差最终会导致目标的永久性损失。在本文中,我们从数学角度研究模型偏差的问题。此外,我们使用相关滤波器ECO和Siamese SINT跟踪器简要检查各种跟踪误差源对模型衰减的影响。基于观察和见解,我们提出了简单的补充,有助于减少长期跟踪中的模型衰减。建议的跟踪器在四个长期和一个短期跟踪基准上进行评估,表明即使在30分钟长的视频中也具有出色的准确性和稳健性。 |
| Revisiting Feature Alignment for One-stage Object Detection Authors Yuntao Chen, Chenxia Han, Naiyan Wang, Zhaoxiang Zhang 最近,由于在实践中的简单性,一级物体检测器获得了很多关注。与需要NMS和提案阶段分类的两级探测器相比,其完全卷积性质大大降低了训练和部署的难度。然而,一个基本问题在于所有一级探测器是锚箱和卷积特征之间的不对准,这显着地阻碍了一级探测器的性能。在这项工作中,我们首先揭示了广泛使用的im2col运算符和RoIAlign运算符之间的深层联系。在这个有启发性的观察指导下,我们提出了一个RoIConv算子,它以一种有原则的方式在一级检测中对齐特征及其相应的锚点。然后,我们设计了一个完全卷积的AlignDet架构,它结合了学习锚点的灵活性和对齐特征的精确性。具体来说,我们的AlignDet在具有ResNeXt 101主干的COCO测试开发站上实现了44.1的最新mAP。 |
| ++制陶工艺中去除手部遮挡的三维重建3D Reconstruction of Deformable Revolving Object under Heavy Hand Interaction Authors Raoul de Charette, Sotiris Manitsaris 我们通过时间重建3D可变形物体,在现场陶器制作过程中,工匠将物体塑造成模具。因为对象遭受重手交互并且正在变形,所以不能应用经典技术。我们使用粒子能量优化来估计物体轮廓和物体径向对称的益处,以增加重建对遮挡和噪声的鲁棒性。我们的方法适用于具有一个或多个深度传感器的无约束可扩展设置。我们评估我们在每帧和时间基础上发布的数据库,并显示它明显优于达到7.60mm平均对象重建误差的现有技术。进一步的消融研究证明了我们的方法的有效性。 |
| Adversarial Self-Defense for Cycle-Consistent GANs Authors Dina Bashkirova, Ben Usman, Kate Saenko 无监督图像到图像转换的目的是将图像从一个域映射到另一个域,而没有两个域之间的地面真实对应。现有技术方法使用来自两个域的大量未配对示例来学习对应,并且基于生成对抗网络。为了保留输入图像的语义,对抗性目标通常与循环一致性损失相结合,该循环一致性损失惩罚来自翻译的输入图像的不正确重建。但是,如果目标映射是多对一的,例如,对于地图的航空照片,这种限制迫使发生器将信息隐藏在人眼或鉴别器无法察觉的低幅度结构噪声中。在本文中,我们展示了无监督翻译方法的这种自我攻击行为如何影响其性能并提供两种防御技术。我们对所提出的技术进行定量评估,并表明使翻译模型对自我对抗性攻击更加稳健,提高了其生成质量和重建可靠性,并使模型对低幅度扰动不太敏感。 |
| A Fast Content-Based Image Retrieval Method Using Deep Visual Features Authors Hiroki Tanioka 使用视觉特征的快速且可扩展的基于内容的图像检索是当前时期的文档分析,医学图像分析等所必需的。卷积神经网络CNN激活功能在这一领域取得了突出的成就。在输出层中使用softmax函数的深度卷积表示也是视觉特征之一。然而,几乎所有图像检索系统都在主存储器上保持其视觉特征的索引,以便具有高响应性,从而限制了它们对大数据应用的适用性。在本文中,我们提出了一种在Elasticsearch上预先索引的L2范数的余弦相似度的快速计算方法。我们使用ImageNet Dataset和VGG 16预训练模型评估我们的方法。评估结果表明了我们提出的方法的有效性和有效性。 |
| Part Segmentation for Highly Accurate Deformable Tracking in Occlusions via Fully Convolutional Neural Networks Authors Weilin Wan, Aaron Walsman, Dieter Fox 成功跟踪人体对于必须围绕人们工作的机器人来说是一个重要的感知挑战。现有方法分为两大类几何跟踪和使用机器学习的直接姿态估计。虽然最近的工作已经表明直接估计技术可以非常强大,但使用点云的几何跟踪方法可以提供非常高水平的3D精度,这对于许多机器人应用来说是必需的。然而,当对象的大部分被遮挡时,这些方法可能难以混乱。为了克服这个限制,我们提出了一种基于完全卷积神经网络FCN的解决方案。我们为我们的应用开发了优化的Fast FCN网络架构,使我们能够过滤观测点云并提高跟踪精度,同时保持交互式帧速率。我们还表明,通过使用现有的几何跟踪器和数据增强来自动生成分割图,可以使用有限数量的示例训练该模型,并且几乎不需要手动标记。我们通过将其与现有几何跟踪器进行比较来证明我们的完整系统的准确性,并在这些具有挑战性的情况下显示出显着的改进 |
| ++++多视图的场景生成Pixel2Mesh++: Multi-View 3D Mesh Generation via Deformation Authors Chao Wen, Yinda Zhang, Zhuwen Li, Yanwei Fu 我们从具有已知相机姿势的几个彩色图像研究3D网格表示中的形状生成问题。虽然许多以前的作品都是学会直接从先验中产生幻觉,但我们通过利用图形卷积网络利用交叉视图信息来进一步提高形状质量。我们的模型不是建立从图像到3D形状的直接映射函数,而是学习预测一系列变形以迭代地改善粗糙形状。受传统多视图几何方法的启发,我们的网络对初始网格顶点位置周围的邻近区域进行采样,并使用从多个输入图像构建的感知特征统计来推导最佳变形。大量实验表明,我们的模型可以生成精确的3D形状,不仅可以从输入视角看起来合理,而且可以很好地与任意视点对齐。在物理驱动架构的帮助下,我们的模型还展示了跨不同语义类别,输入图像数量和网格初始化质量的泛化能力。 |
| Walking with MIND: Mental Imagery eNhanceD Embodied QA Authors Juncheng Li, Siliang Tang, Fei Wu, Yueting Zhuang EmbodiedQA的任务是通过智能地在模拟环境中导航并收集视觉信息来回答问题来训练具体代理。现有方法未能明确地模拟代理人的心理意象功能,而心理意象对于具体认知至关重要,并且与诸如泛化和解释等许多高级元技能密切相关。在本文中,我们为具体的代理人提出了一个新的Mental Imagery eNhanceD MIND模块,以及一个相关的深度加固训练框架。 MIND模块不仅可以模拟环境的动态,例如如果代理人通过门可能会发生什么,但也可以帮助代理人更好地理解环境,例如冰箱通常在厨房里。这样的知识使代理人在仅用少量路径定位可行策略时更快更好地学习。此外,MIND模块可以生成由我们提出的深层加固框架作为短期子目标处理的心理图像。这些心理图像有助于政策学习,因为短期子目标很容易实现和重复使用。与其他直接从原始操作学习策略的算法相比,这可以产生更好的规划效率。最后,心理图像以人类可以理解的方式可视化代理人的意图,这使我们的代理人的行为具有更多的可解释性。实验结果和进一步分析证明,具有MIND模块的代理不仅在EQA性能方面优于其对应方,而且在许多其他方面(例如路线规划,行为解释和从一些示例推广的能力)优于其对应物。 |
| GDRQ: Group-based Distribution Reshaping for Quantization Authors Haibao Yu, Tuopu Wen, Guangliang Cheng, Jiankai Sun, Qi Han, Jianping Shi 低比特量化对于维持具有有限模型容量的高性能是挑战性的,例如,对于权重和激活都是4比特。当然,深度神经网络中权重和激活的分布都是高斯分布的。然而,由于低位模型的有限位宽,已经证明统一的分布权重和激活对量化更友好,同时保持准确性引用Han2015Learning。受此启发,我们提出了Scale Clip,一种分布整形技术,可以动态地将权重或激活重塑为统一的分布。此外,为了增加低位模型的模型能力,提出了一种新的基于组的量化算法,以将滤波器分成若干组。不同的组可以学习不同的量化参数,这些参数可以优雅地合并到批量归一化层中,而在推理阶段没有额外的计算成本。最后,我们将Scale Clip技术与基于组的量化算法相结合,并提出基于组的分布整形量化GDQR框架,以进一步提高量化性能。在各种网络上的实验,例如VGGNet和ResNet以及愿景任务,例如分类,检测和分割表明我们的框架实现了良好的性能。 |
| Automated Detection System for Adversarial Examples with High-Frequency Noises Sieve Authors Dang Duy Thang, Toshihiro Matsui 深度神经网络正在许多任务中应用,结果令人鼓舞,并且经常达到人类水平的表现。然而,深度神经网络容易受到设计良好的输入样本的影响,称为对抗性示例。特别是,神经网络倾向于错误分类人类难以察觉的对抗性例子。本文介绍了一种新的检测系统,可以自动检测深度神经网络上的对抗实例。我们提出的系统主要可以在没有人为干预的情况下以端到端的方式区分对抗样本和良性图像。我们利用频域在对抗样本中的重要作用,并提出一种在观察中检测恶意样本的方法。当在两个标准基准数据集MNIST和ImageNet上进行评估时,我们的方法在许多设置中实现了99.7 100的输出检测率。 |
| TopoTag: A Robust and Scalable Topological Fiducial Marker System Authors Guoxing Yu, Yongtao Hu, Jingwen Dai 基准标记在增强现实AR,机器人导航以及需要相机和物体之间的相对姿势的一般应用中起着重要作用。我们介绍了TopoTag,这是一个强大且可扩展的拓扑基准标记系统,可以从单个图像中支持可靠和准确的姿态估计。 TopoTag在标记检测中使用拓扑和几何信息来实现更高的稳健性。与以前的系统一样,TopoTag不会牺牲比特以获得更高的调用和精度,可以使用全比特进行ID编码,并支持数万个唯一ID,并通过添加更多比特轻松扩展到数百万甚至更多,从而实现完美的可扩展性。我们收集了一个大型数据集,包括总共169,713个图像用于评估,涉及平面和平面外旋转,图像模糊,不同距离和各种背景等。实验表明,TopoTag在各种指标方面明显优于以前的基准标记系统,包括检测精度,顶点抖动,姿态抖动和精度等。此外,TopoTag支持遮挡,只要保持主标签拓扑结构和灵活的形状设计,用户可以自定义外部和外部标记形状。我们的数据集,标记设计和检测算法对社区是公开的。 |
| Image to Video Domain Adaptation Using Web Supervision Authors Andrew Kae, Yale Song 训练深度神经网络通常需要大量标记数据,这对于特定目标域而言可能是稀缺或昂贵的。作为替代方案,我们可以利用网络监督数据,即来自公共搜索引擎的结果,其相对丰富但可能包含噪声结果。在这项工作中,我们提出了一种新的两阶段方法来学习使用网络监督数据的视频分类器。我们认为,顺序而不是同时学习外观特征和时间特征是这项任务的一种更容易的优化。我们通过首先从网络图像学习图像模型来展示这一点,该模型用于初始化和训练视频模型。我们的模型应用域适应来解释源域webly监督数据和目标域之间存在的潜在域移位,并且还通过添加新的注意组件来解释噪声。我们报告了与UCF 101上的网络监督方法相比具有最新技术水平的结果,同时简化了培训过程并且还评估了动力学以进行比较。 |
| Learning Compact Target-Oriented Feature Representations for Visual Tracking Authors Chenglong Li, Yan Huang, Liang Wang, Jin Tang, Liang Lin 许多现有技术的跟踪器通常采用预训练的卷积神经网络CNN模型进行相关滤波,其中深度特征通常对于某些特定情况通常是冗余的,噪声的并且较少辨别,因此跟踪性能可能受到影响。为了解决这个问题,我们提出了一种新方法,它既具有生成模型的良好推广优势,又具有辨别模型的优异辨别力,可用于视觉跟踪。特别地,我们使用拉普拉斯编码算法学习紧凑,判别和面向目标的特征表示,该算法利用判别相关滤波器框架中的输入局部特征之间的依赖性。共同学习特征表示和相关滤波器以通过快速求解器彼此增强,该快速求解器仅对跟踪速度具有非常小的计算负担。对三个基准数据集的大量实验表明,该提议的框架明显优于基线跟踪器,对帧速率产生适度影响,并且与现有技术方法的性能相当。 |
| Inference of visual field test performance from OCT volumes using deep learning Authors Stefan Maetschke, Bhavna Antony, Hiroshi Ishikawa, Gadi Wollstein, Joel Schuman, Rahil Garnav 视野检查VFT是青光眼诊断的关键,并定期进行以监测疾病进展。在这里,我们解决了可以从光学神经头ONH或黄斑的光学相干断层扫描OCT扫描推断出诸如视野指数VFI和平均偏差MD的聚合VFT测量的程度的问题。从OCT准确推断VFT测量可以减少检查时间和成本。 |
| Deep Neural Network for Semantic-based Text Recognition in Images Authors Yi Zheng, Qitong Wang, Margrit Betke 现有技术的文本定位系统通常旨在在自然场景的图像中检测孤立的单词或逐字文本,并忽略文本区域内的语义相干性。然而,当一起解释时,看似孤立的单词可能更容易识别。在此基础上,我们提出了一种新的基于语义的文本识别STR深度学习模型,该模型借助于理解上下文来读取图像中的文本。 STR由几个模块组成。我们引入文本分组和排列TGA算法来连接和排序隔离的文本区域。文本识别网络解释孤立的单词。受益于语义信息,序列到序列网络模型有效地纠正了早先在STR管道中产生的不准确和不确定短语。我们在两个新的不同数据集上展示实验,这些数据集分别包含室内设计的扫描目录图像和带有手写标志的抗议者的照片。我们的结果表明,我们的STR模型优于在两个数据集上使用最先进的单一词识别技术的基线方法。 STR在目录图像上产生高准确率90,在更难以抗议的图像上产生71,这表明它在识别文本方面具有普遍性。 |
| +++Image-Guided Depth Sampling and Reconstruction Authors Adam Wolff, Shachar Praisler, Ilya Tcenov, Guy Gilboa 基于主动照明的深度采集对于自主和机器人导航至关重要。 LiDARs光检测和带有机械,固定,采样模板的测距通常用于当今的自动驾驶汽车。基于固态深度传感器的新兴技术,无机械部件,可实现快速,自适应,可编程扫描。 |
| Unsupervised Learning of Depth and Deep Representation for Visual Odometry from Monocular Videos in a Metric Space Authors Xiaochuan Yin, Chengju Liu 对于自我运动估计,场景的特征表示是至关重要的。以前的方法表明基于低级和基于语义特征的方法都可以获得有希望的结果。因此,分层特征表示的结合可以受益于两种方法。从这个角度来看,我们提出了一种新颖的直接特征测距框架,命名为DFO,用于深度估计和单眼视频的层次特征表示学习。通过利用度量距离,我们的框架能够在没有监督的情况下学习分层特征表示。在放大的特征图中,从高级到低级特征的粗到精方法获得姿势。像素级注意掩码可以自学习以提供先验信息。与之前的方法相比,我们提出的方法使用直接方法计算相机运动,而不是从姿势网络回归自我运动。通过这种方法,可以限制翻译比例因子的一致性。另外,所提出的方法因此与传统的SLAM流水线兼容。 KITTI数据集上的实验证明了我们方法的有效性。 |
| SF-Net: Structured Feature Network for Continuous Sign Language Recognition Authors Zhaoyang Yang, Zhenmei Shi, Xiaoyong Shen, Yu Wing Tai 连续手语识别SLR旨在将签名序列翻译成句子。这是非常具有挑战性的,因为手语具有丰富的词汇量,而其中许多包含相似的手势和动作。此外,由于签名光标的对齐不可用,因此它受到弱监督。在本文中,我们提出结构化特征网络SF Net,通过有效地学习数据中的多个级别的语义信息来解决这些挑战。所提出的SF Net以结构化的方式提取特征,并逐渐将帧级,光泽级和句子级的信息编码到特征表示中。建议的SF网络可以在没有其他模型或预训练的帮助下进行端到端的训练。我们在从不同的连续SLR情景中收集的两个大规模公共SLR数据集上测试了所提出的SF Net。结果表明,所提出的SF Net在准确性和适应性方面明显优于以前的序列级监督方法。 |
| ARGAN: Attentive Recurrent Generative Adversarial Network for Shadow Detection and Removal Authors Bin Ding, Chengjiang Long, Ling Zhang, Chunxia Xiao 在本文中,我们提出了一种细心的复发性生成对抗网络ARGAN来检测和去除图像中的阴影。发电机由多个渐进步骤组成。在每个步骤中,首先利用阴影注意检测器来生成注意图,该注意图指定输入图像中的阴影区域。给予注意力图,阴影去除器编码器的负残差将恢复阴影更亮或甚至无阴影图像。设计鉴别器以分类最后一个渐进步骤中的输出图像是真实的还是假的。此外,ARGAN适合用半监督策略进行训练,以充分利用足够的无监督数据。对四个公共数据集的实验表明,我们的ARGAN可以很好地检测简单和复杂的阴影,并产生更逼真的阴影去除效果。它优于最先进的方法,特别是在恢复阴影区域方面。 |
| Low-Rank Pairwise Alignment Bilinear Network For Few-Shot Fine-Grained Image Classification Authors Huaxi Huang, Junjie Zhang, Jian Zhang, Jingsong Xu, Qiang Wu 深度神经网络已经证明了各种视觉分类任务的先进能力,这些任务严重依赖于带有注释事实的大规模训练样本。然而,在现实世界的应用中要求这样的注释总是不现实的。最近,为了解决训练样本不足的问题,Few Shot学习FS在通用分类任务方面取得了重大进展。尽管如此,鉴于有限的训练数据,目前的FS模型仍然难以区分细粒度类别之间的细微差别。为了填补分类空白,在本文中,我们讨论了少数镜头细粒度FSFG分类问题,该问题侧重于在具有挑战性的少数镜头学习设置下处理细粒度分类。提出了一种新颖的低秩成对双线性池化操作来捕获支持和查询图像之间的细微差别,以学习有效距离度量。此外,特征对齐层被设计为在比较之前将支持图像特征与查询图像特征匹配。我们将所提出的模型命名为Low Rank Pairwise Alignment Bilinear Network LRPABN,它以端到端的方式进行训练。四种广泛使用的细粒度分类数据集的综合实验结果表明,与现有技术方法相比,我们的LRPABN模型实现了优越的性能。 |
| Fully Automatic Video Colorization with Self-Regularization and Diversity Authors Chenyang Lei, Qifeng Chen 我们提出了一种全自动的视频着色方法,具有自我正规化和多样性。我们的模型包含用于视频帧着色的着色网络和用于时空颜色细化的细化网络。在没有任何标记数据的情况下,可以使用在双边和时间空间中定义的自正规化损失来训练两个网络。双边损失强制双边空间中的相邻像素之间的颜色一致性,并且时间损失在两个附近帧中的相应像素之间施加约束。虽然视频着色是一种多模态问题,但我们的方法使用具有多样性的感知损失来区分解空间中的各种模式。感知实验表明,我们的方法优于全自动视频着色的最先进方法。结果显示在补充视频中 |
| Theme Aware Aesthetic Distribution Prediction with Full Resolution Photos Authors Gengyun Jia, Peipei Li, Ran He 审美质量评估由于人类评估过程中的主观和多样化因素,照片的AQA是一项具有挑战性的任务。如今,通过深度神经网络DNN解决AQA是常见的,因为它们在建模这种复杂关系方面具有卓越的性能。然而,传统的DNN需要固定尺寸的输入,并且将各种输入调整为均匀尺寸可能会显着改变其美学特征。这种转变导致照片与其美学评价之间的不匹配。现有方法通常采用两种解决方案。一些方法直接从输入中修剪大小的补丁。其他人通过插入自适应池或移除完全连接的层来交替地从预定义的多尺寸输入捕获美学特征。然而,前者破坏了全球结构和布局信息,这在大多数情况下都是至关重要的。后者必须将图像调整为几个预定义的尺寸,这不足以反映图像尺寸的多样性,并且美学特征仍然被破坏。为了解决这个问题,我们提出了一种简单有效的方法,通过将图像填充与ROI感兴趣区域相结合,可以处理任意大小的批量输入以在全分辨率图像上实现AQA。填充保持相同大小的输入,而ROI池化切断了填充区域上的特征的向前传播,从而消除了填充的副作用。此外,我们观察到相同的图像可能在不同的主题下得到不同的分数,我们称之为主题标准偏差。然而,以前的作品只关注图像的美学特征,忽略了主题带来的标准偏见。在本文中,我们介绍主题信息并提出一个主题意识模型。广泛的实验证明了所提出的方法相对于现有技术的有效性。 |
| Adversarial View-Consistent Learning for Monocular Depth Estimation Authors Yixuan Liu, Yuwang Wang, Shengjin Wang 本文讨论了单眼深度估计MDE的问题。 MDE上的现有方法通常将其建模为像素级回归问题,忽略基础几何属性。我们凭经验发现这可能导致次优解,而预测深度图在一个特定视图中呈现小损失值,如果在不同方向上观察,则可能表现出大的损失。在本文的启发下,多视图立体声MVS,我们提出了一个对抗视图一致性学习AVCL框架,以强制从多个视图观察所有合理的深度图。为此,我们首先设计可区分的深度图变形操作,该端对端可训练,然后提出姿势生成器以对抗方式生成给定图像的新颖视图。通过与可微分深度图变形操作协作,姿势生成器鼓励深度估计网络从硬视图中学习,从而产生视图一致的深度图。我们在NYU Depth V2数据集上评估我们的方法,并且实验结果显示了在现有技术MDE方法上有希望的性能增益。 |
| ++To Learn or Not to Learn: Visual Localization from Essential Matrices Authors Qunjie Zhou, Torsten Sattler, Marc Pollefeys, Laura Leal Taixe 视觉定位是估计场景中的摄像机的问题,也是计算机视觉应用中的关键部件,例如自驾车和混合现实。用于精确视觉定位的现有技术方法使用场景特定表示,导致在将技术应用于新场景时构建这些模型的开销。最近,已经提出了基于相对姿态估计的基于深度学习的方法,其承载容易适应新场景。然而,已经表明这种方法目前明显不如现有技术方法准确。在本文中,我们有兴趣分析这种行为。为此,我们提出了一种新的相对姿态视觉定位框架。在此框架中使用基于经典特征的方法,我们展示了最先进的性能。将经典方法替换为不同层次的学习方法,然后我们确定深度学习方法不能很好地运行的原因。根据我们的分析,我们为未来的工作提出建议。 |
| Softmax Dissection: Towards Understanding Intra- and Inter-clas Objective for Embedding Learning Authors Lanqing He, Zhongdao Wang, Yali Li, Shengjin Wang softmax损失及其变体被广泛用作嵌入学习的目标,特别是在人脸识别等应用中。然而,softmax损失中的内部和类间目标是纠缠的,因此良好优化的类间目标导致内部目标的放松,反之亦然。在本文中,我们建议将softmax损失分解为独立的内部和类间目标D Softmax。以D Softmax为目标,我们可以清楚地理解内部和类间目标,因此可以直接将每个部分调整到最佳状态。此外,我们发现类间目标的计算是冗余的,并提出了两个基于采样的D Softmax变体以降低计算成本。使用常规比例数据进行训练,面部验证实验显示,D Softmax与现有的损失(如SphereFace和ArcFace)相当。通过大规模数据训练,实验表明D Softmax的快速变体显着加速了训练过程,例如64x,只有轻微的性能牺牲,在性能和效率方面优于softmax的现有加速方法。 |
| Attentive Normalization Authors Xilai Li, Wei Sun, Tianfu Wu 批量标准化BN是深度学习发展的重要支柱,具有许多最近的变化,例如Group Normalization GN和Switchable Normalization。通道明智的特征注意方法,如挤压和激励SE单元也显示出令人印象深刻的性能改进。 BN及其变体考虑了在特征标准化的最小批量内计算均值和方差的不同方式,随后是可学习的通道明智仿射变换。 SE明确地学习如何自适应地重新校准通道明智的特征响应。然而,他们已经分开研究。在本文中,我们提出了一种新颖,轻量级的特征规范化和特征渠道注意力集成。我们将Attentive Normalization AN作为一种简单而统一的替代方案。 AN将SE吸收到BN的仿射变换中。 AN学习每个信道的少量缩放和偏移参数,即不同的仿射变换。它们的加权和即混合物用于最终的仿射变换。权重是特定于实例的并且以考虑渠道方式注意的方式学习,在精神上类似于SE单元中的挤压模块。 AN是互补的,适用于现有的BN变体。在实验中,我们在ImageNet 1K分类数据集和MS COCO对象检测和实例分割数据集中测试AN,其获得的性能明显优于香草BN。我们的AN也优于BN,GN和SN两种最先进的变体。源代码将在url上发布 |
| Kannada-MNIST: A new handwritten digits dataset for the Kannada language Authors Vinay Uday Prabhu 在本文中,我们为Kannada脚本传播了一个新的手写数字数据集,称为Kannada MNIST,可以直接替代原始MNIST数据集。除了这个数据集之外,我们还传播了一个带有10k图像的附加真实世界手写数据集,我们将其称为Dig MNIST数据集,它可以作为域外测试数据集。我们还适当地开源所有代码以及原始扫描图像以及扫描仪设置,以便想要尝试不同信号处理流水线的研究人员可以执行端到端比较。我们提供与MNIST数据集的高级形态学比较,并为传播的数据集提供基线准确性。使用经常使用的CNN架构96.8用于主要测试集和76.1用于Dig MNIST测试集获得的初始基线表明这些数据集确实提供了与MNIST或KMNIST数据集相关的普遍性挑战。我们也希望这种传播能够刺激为数字数字使用不同符号的所有语言创建类似的数据集。 |
| +++Learning Guided Convolutional Network for Depth Completion Authors Jie Tang, Fei Peng Tian, Wei Feng, Jian Li, Ping Tan 密集的深度感知对于自动驾驶和其他机器人应用至关重要。然而,现代LiDAR传感器仅提供稀疏深度测量。因此有必要完成稀疏的LiDAR数据,其中经常使用同步的引导RGB图像来促进这种完成。已经为此任务设计了许多神经网络。然而,它们通常通过执行特征级联或元素添加来完美地融合LiDAR数据和RGB图像信息。受引导图像滤波的启发,我们设计了一种新的引导网络,用于从引导图像中预测核权重。然后应用这些预测的内核来提取深度图像特征。通过这种方式,我们的网络为多模态特征融合生成内容相关和空间变体内核。动态生成的空间变体内核可能导致令人望而却步的GPU内存消耗和计算开销。我们进一步设计了卷积分解,以减少计算和内存消耗。 GPU内存减少使得特征融合可以在多阶段方案中工作。我们进行了全面的实验,以验证我们在真实世界室外,室内和合成数据集上的方法。我们的方法产生强大的结果它在NYUv2数据集上优于最先进的方法,在提交时在KITTI深度完成基准测试中排名第一。它还在不同的3D点密度,各种照明和天气条件以及交叉数据集评估下呈现出强大的泛化能力。该代码将被发布以供复制。 |
| Smooth Grad-CAM++: An Enhanced Inference Level Visualization Technique for Deep Convolutional Neural Network Models Authors Daniel Omeiza, Skyler Speakman, Celia Cintas, Komminist Weldermariam 深入了解卷积神经网络模型如何执行图像分类以及如何解释其输出一直是计算机视觉研究人员和决策者关注的问题。这些深层模型通常被称为黑盒子,因为它们对内部工作的理解不足。作为开发可解释的深度学习模型的努力,已经提出了几种方法,例如相对于输入图像灵敏度图,类激活图CAM和基于梯度的类激活图Grad CAM找到类输出的梯度。当本地化同一类的多次出现并且不适用于所有CNN时,这些方法正在执行。此外,当在单个对象图像上使用时,Grad CAM不会完整地捕获整个对象,这会影响识别任务的性能。为了在视觉清晰度,对象定位和解释单个图像中多次出现的对象方面创建增强的视觉解释,我们提出了Smooth Grad CAM脚注简单演示 |
| Learning to Predict 3D Objects with an Interpolation-based Differentiable Renderer Authors Wenzheng Chen, Jun Gao, Huan Ling, Edward J. Smith, Jaakko Lehtinen, Alec Jacobson, Sanja Fidler 许多机器学习模型对图像进行操作,但忽略了图像是由3D几何与光交互形成的2D投影的事实,在称为渲染的过程中。启用ML模型来理解图像形成可能是推广的关键。然而,由于涉及离散分配操作的基本光栅化步骤,渲染管线是不可微分的,因此基于梯度的ML技术基本上不可访问。在本文中,我们提出了DIB R,一种可微分的渲染框架,允许对图像中的所有像素进行分析计算。我们的方法的关键是将前景光栅化视为局部属性的加权插值,将背景光栅化视为基于距离的全局几何体聚合。我们的方法允许通过各种照明模型对顶点位置,颜色,法线,光线方向和纹理坐标进行精确优化。我们在两个ML应用程序中展示我们的方法单个图像3D对象预测和3D纹理对象生成,两者都使用专门使用2D监督进行训练。我们的项目网站是 |
| Searching for Ambiguous Objects in Videos using Relational Referring Expressions Authors Hazan Anayurt, Sezai Artun Ozyegin, Ulfet Cetin, Utku Aktas, Sinan Kalkan 人类经常使用引用识别表达来引用对象。特别是在模糊的环境中,人们更喜欢称为关系引用表达式的表达,其描述关于区别的唯一对象的对象。与使用引用表达式进行视频对象搜索的研究不同,在本文中,我们的重点是在高度模糊的设置中的关系引用表达式,以及可以生成和理解引用表达式的方法。为此目的,我们首先引入一个用于视频对象搜索的新数据集,其中包含引用表达式,其中包含大量对象副本,因此很难使用非关系表达式。此外,我们在该数据集上训练了两个基线深度网络,显示了有希望的结果。最后,我们提出了一个深度关注网络,它明显优于我们数据集的基线。数据集和代码可在以下位置获得 |
| Learning Local Feature Descriptor with Motion Attribute for Vision-based Localization Authors Yafei Song, Di Zhu, Jia Li, Yonghong Tian, Mingyang Li 近年来,基于摄像机的定位已广泛用于机器人应用,并且大多数提出的算法依赖于从记录图像中提取的局部特征。为了获得更好的性能,用于开环定位的特征需要是短期全局静态的,用于重新定位或循环闭合检测的特征需要是长期静态的。因此,可以利用局部特征点的运动属性来改善定位性能,例如,由于它们的不稳定性,可以从这些系统中排除从移动的人或车辆中提取的特征点。在本文中,我们设计了一个完全卷积网络FCN,名为MD Net,以同时执行运动属性估计和特征描述。 MD Net有一个共享骨干网络,用于从输入映像和两个网络分支中提取功能,以完成每个子任务。使用MD Net,我们可以获得运动属性,同时避免增加更多的计算。实验结果表明,该方法可以通过大幅度优于竞争方法,仅使用FCN学习不同的局部特征描述符和运动属性。我们还表明,所提出的算法可以集成到基于视觉的定位算法中,以显着提高估计精度。 |
| Permutation-invariant Feature Restructuring for Correlation-aware Image Set-based Recognition Authors Xiaofeng Liu, Zhenhua Guo, Site Li, Lingsheng Kong, Ping Jia, Jane You, B.V.K. Kumar 我们考虑将图像集的相似性与可变数量,质量和无序异构图像进行比较的问题。我们使用特征重构来利用内部集合图像的相关性。具体地,剩余自我关注可以使用集合内的其他特征有效地重构特征,以强调辨别图像并消除冗余。然后,基于稀疏协作学习的依赖性引导表示方案以画廊特征为条件重建探测特征,以便自适应地对齐两组。这使我们的框架能够与验证和开放集识别兼容。我们证明了参数自注意网络和非参数字典学习可以通过统一的替代优化方案进行端到端的训练,并且完整的框架是排列不变的。在我们进行的数值实验中,我们的方法在基于竞争图像集视频的人脸识别和人格识别基准上实现了最佳性能。 |
| ABD-Net: Attentive but Diverse Person Re-Identification Authors Tianlong Chen, Shaojin Ding, Jingyi Xie, Ye Yuan, Wuyang Chen, Yang Yang, Zhou Ren, Zhangyang Wang 注意机制已被证明对人员识别Re ID有效。然而,所学习的注意特征嵌入通常不是自然多样的或不相关的,将基于欧几里德距离来损害检索性能。我们主张强制执行多样性可以极大地补充注意力。为此,我们提出了一个关注但多样化的网络ABD网络,它将注意力模块和多样性正规化无缝集成到整个网络中,以学习具有代表性,强大和更具辨别力的功能。具体来说,我们介绍了一对互补的注意力模块,分别关注信道聚合和位置感知。此外,导出了一种新的有效形式的正交性约束,以对隐藏的激活和权重实施正交性。通过仔细的消融研究,我们验证了所提出的细致和多样化的术语各自有助于ABD Net的性能提升。在三个流行的基准测试中,ABD Net始终优于现有的最新技术方法。 |
| Simultaneous Semantic Segmentation and Outlier Detection in Presence of Domain Shift Authors Petra Bevandi , Ivan Kre o, Marin Or i , Sini a egvi 最近在现实道路驾驶数据集上的成功增加了对在现实世界应用中探索稳健性能的兴趣。未解决的主要问题之一是识别用给定推理引擎无法可靠识别的图像内容。因此,我们研究了通过依赖共享卷积特征,通过单个前向传递来恢复密集异常值映射以及主要任务的方法。我们将语义分割视为主要任务,并对WildDash val inlier,LSUN val异常值和Pascal VOC 2007异常值的粘贴对象进行广泛验证。我们通过培训来实现最佳验证性能,即使ImageNet 1k包含许多道路行驶像素,并且至少在名义上无法解释视觉世界的完全多样性,因此可以区分内容与粘贴的ImageNet 1k内容。所提出的双头模型与训练的C路多类模型相比,可以预测异常值的均匀分布,同时优于其他几种经过验证的方法。我们在WildDash测试数据集上评估我们最好的两个模型,并在WildDash基准测试中设置新的最新技术水平。 |
| Adaloss: Adaptive Loss Function for Landmark Localization Authors Brian Teixeira, Birgi Tamersoy, Vivek Singh, Ankur Kapoor 具有多种应用的计算机视觉中的地标定位是一个具有挑战性的问题。最近基于深度学习的方法通过回归似然图而不是直接回归坐标来显示改进的结果。然而,在训练期间设置这些回归目标的精确度是一个麻烦的过程,因为它在可训练性与定位精度之间产生折衷。使用精确目标会引入显着的采样偏差,从而使训练更加困难,而使用不精确的目标会导致不准确的地标探测器。在本文中,我们介绍了Adaloss,这是一种在训练期间通过基于训练统计更新目标精度来适应自身的目标函数。该方法不需要设置问题特定参数,并且在推理期间显示出改进的训练稳定性和更好的定位精度。我们证明了我们提出的方法在地标定位的三种不同应用中的有效性1:在医学X射线图像中精确检测导管尖端的挑战性任务,2在内窥镜图像中定位手术器械,以及在野外图像中定位3个面部特征显示300 W基准数据集的最新结果。 |
| Cycle In Cycle Generative Adversarial Networks for Keypoint-Guided Image Generation Authors Hao Tang, Dan Xu, Gaowen Liu, Wei Wang, Nicu Sebe, Yan Yan 在这项工作中,我们提出了一种新的循环周期生成对抗网络C 2 GAN,用于关键点引导图像生成的任务。拟议的C 2 GAN是一个交叉模式框架,探索以交互方式联合利用关键点和图像数据。 C 2 GAN包含两种不同类型的发生器,即面向关键点的发生器和面向图像的发生器。它们都以端对端可学习的方式相互连接,并明确地形成三个循环的子网络,即一个图像生成周期和两个关键点生成周期。每个循环不仅旨在重建输入域,还产生涉及另一个循环的生成的有用输出。通过这样做,周期隐含地相互约束,这提供来自两种不同模态的补充信息,并且跨周期带来额外的监督,从而促进整个网络的更稳健的优化。两个公开可用的数据集(即Radboud Faces和Market 1501)的广泛实验结果表明,与现有技术模型相比,我们的方法可以有效地生成更逼真的图像。 |
| A principled approach for generating adversarial images under non-smooth dissimilarity metrics Authors Aram Alexandre Pooladian, Chris Finlay, Tim Hoheisel, Adam Oberman 深度神经网络容易受到对抗性扰动,输入中的微小变化容易导致错误分类。在这项工作中,我们提出了一种攻击方法,不仅适用于通过椭圆规范测量扰动的情况,而且实际上是任何具有封闭近端形式的对抗性差异度量度量。这包括但不限于ell 1,ell 2,ell infty扰动和ell 0计数范数,即真正的稀疏性。我们产生扰动的方法是我们最近的工作LogBarrier攻击的自然延伸,LogBarrier攻击之前要求度量是可微分的。我们在MNIST,CIFAR10和ImageNet 1k数据集上演示了我们的新算法ProxLogBarrier。我们攻击不设防和防御的模型,并显示我们的算法转移到各种数据集,几乎没有参数调整。特别地,在ell 0的情况下,与多个现有方法相比,我们的算法发现明显更小的扰动 |
| +++Review of Algorithms for Compressive Sensing of Images Authors Yoni Sher 我们提供了对图像压缩感知的经典算法的全面回顾,重点是总变差方法,以便在LiDAR系统中应用。我们的主要重点是为该领域的初学者提供全面的评估,以及模拟真实LiDAR系统中的噪声类型。为此,我们提供了理论背景的概述,对压缩传感中出现的各种考虑因素的简要讨论,以及现成方法的标准化比较,旨在作为选择压缩传感算法的快速入门指南应用。 |
| Knee menisci segmentation and relaxometry of 3D ultrashort echo time (UTE) cones MR imaging using attention U-Net with transfer learning Authors Michal Byra, Mei Wu, Xiaodong Zhang, Hyungseok Jang, Ya Jun Ma, Eric Y Chang, Sameer Shah, Jiang Du 这项工作的目的是开发一种基于深度学习的膝关节半月板分割方法,用于3D超短回波时间UTE锥体磁共振磁共振成像,并自动确定MR弛豫时间,即T1,T1 rho和T2参数,用于评估膝关节骨性关节炎OA。使用3D UTE锥体序列进行全膝关节成像以收集来自61个人类受试者的数据。基于减去的T1 rho加权MR图像,由两位经验丰富的放射科医师概述感兴趣区域ROI。转移学习应用于开发2D注意U网络卷积神经网络,用于分别基于每个放射科医师的ROI进行半月板分割。计算骰子分数以评估分割性能。接下来,确定手动和自动分割的T1,T1 rho,T2松弛和ROI区域,然后进行比较。使用由两名放射科医师提供的ROI开发的模型获得0.860和0.833的高Dice分数,同时实现放射科医师手动分割骰子得分为0.820。使用自动和手动分割计算的T1,T1 rho和T2松弛的线性相关系数介于0.90和0.97之间,并且估计的平均半月板松弛参数之间没有相关差异。深度学习模型实现了与两位放射科医师的观察者间变异性相当的分割性能。所提出的基于深度学习的方法可用于有效地生成自动分割并确定半月板松弛时间。该方法有可能帮助放射科医师评估半月板疾病,如OA。 |
| High Accuracy Tumor Diagnoses and Benchmarking of Hematoxylin and Eosin Stained Prostate Core Biopsy Images Generated by Explainable Deep Neural Networks Authors Aman Rana, Alarice Lowe, Marie Lithgow, Katharine Horback, Tyler Janovitz, Annacarolina Da Silva, Harrison Tsai, Vignesh Shanmugam, Hyung Jin Yoon, Pratik Shah 苏木精和伊红H染色后组织活检中肿瘤的组织病理学诊断是肿瘤治疗的金标准。 H E染色很慢并且使用不能重复使用的染料,试剂和珍贵的组织样品。成千上万的原生未染色RGB全幻灯片RWSI贴片的前列腺核心组织活组织检查用他们的H E染色版本注册。然后训练条件生成性对抗神经网络cGAN,其自动将原始非染色RWSI转换为计算H E染色图像。计算结构相似性指数SSIM 0.902,Pearsons Correlation Coefficient CC 0.962和峰值信噪比PSNR 22.821 dB的计算和H E染料染色图像之间的高度相似性。第二个cGAN使用SSIM 0.9,CC 0.963和PSNR 25.646 dB对H E染料染色图像进行准确的计算脱色,使其恢复到其原生非染色形式。单盲研究计算了由五名经过委员会认证的MD病理学家提供的计算机染色图像上的前列腺肿瘤注释之间的95个像素重叠,以及H E染料染色对应物上的那些。我们报告了在H E染色期间神经网络核激活图的第一次可视化和解释以及cGAN对RGB图像的脱色。计算和H E染色图像的核激活图之间的高相似性均方误差0.0005提供染色系统的额外数学和机械验证。因此,我们的神经网络框架是自动化的,可解释的并且执行高精度H E染色和低成本原生RGB图像的脱色,并且是计算机视觉和医师认证的快速和准确的肿瘤诊断。 |
| Knowledge Isomorphism between Neural Networks Authors Ruofan Liang, Tianlin Li, Longfei Li, Quanshi Zhang 本文旨在分析预训练深度神经网络之间的知识同构。我们提出了不同模糊水平下神经网络之间知识同构的通用定义,并设计了一个任务不可知和模型不可知方法,以解开和量化神经网络中间层的同构特征。作为通用工具,我们的方法可以广泛用于不同的应用程序。在初步实验中,我们使用知识同构作为诊断神经网络特征表示的工具。知识同构提供了新的见解来解释现有深度学习技术的成功,例如知识蒸馏和网络压缩。更重要的是,已经表明知识同构也可以用于改进预先训练的网络并提高性能。 |
| ++肾脏血管精确估计Precise Estimation of Renal Vascular Dominant Regions Using Spatially Aware Fully Convolutional Networks, Tensor-Cut and Voronoi Diagrams Authors Chenglong Wang, Holger R. Roth, Takayuki Kitasaka, Masahiro Oda, Yuichiro Hayashi, Yasushi Yoshino, Tokunori Yamamoto, Naoto Sassa, Momokazu Goto, Kensaku Mori 本文提出了一种使用Voronoi图精确估计肾血管主导区域的新方法。为了为部分肾切除手术的术前模拟提供计算机辅助诊断,我们必须获得关于肾动脉和肾血管显性区域的信息。我们提出了一种全自动分割方法,该方法结合了神经网络和基于张量的图切割方法来精确提取肾动脉和肾动脉。首先,我们使用卷积神经网络来定位肾脏区域并使用基于张量的图切割方法提取微小的肾动脉。然后我们生成Voronoi图以基于分段的肾和肾动脉估计肾血管显性区域。经过8次交叉验证的27例肾脏分割的准确性达到了95的Dice评分。 8例肾动脉分割的准确性得到中心线重叠率为80。每个分区区域对应于肾血管显性区域。最终的主导区域估计精度达到80的Dice系数。临床应用显示了我们提出的估计方法在真实临床手术环境中的潜力。使用大规模数据库进一步验证是我们未来的工作。 |
| Discriminating Spatial and Temporal Relevance in Deep Taylor Decompositions for Explainable Activity Recognition Authors Liam Hiley, Alun Preece, Yulia Hicks, David Marshall 用于可解释AI的当前技术已经应用于图像处理。最近视频处理研究的兴起呼吁进行类似的工作,解构和解释时空模型。虽然许多技术是针对2D卷积模型设计的,但其他技术本身适用于任何输入域。一个这样的工作体,深泰勒分解,将模型输出的相关性分布式地传播到其输入上,因此不限于图像处理模型。然而,通过利用去除运动信息的简单技术,我们表明这种技术不是用于表示非图像任务中的相关性的情况。我们提出了一种判别方法,该方法产生帧的空间和时间相关性的两个表示,作为两个单独的对象。这种新的判别相关性模型暴露了归因于运动的框架中的相关性,这在先前的解释中是模糊的。我们观察了该技术对来自UCF 101动作识别数据集的一系列样本的有效性,其中两个在本文中进行了演示。 |
| CameraNet: A Two-Stage Framework for Effective Camera ISP Learning Authors Zhetong Liang, Jianrui Cai, Zisheng Cao, Lei Zhang 传统的图像信号处理ISP流水线由相机上的一组单独的图像处理组件组成,以从传感器原始数据重建高质量的sRGB图像。由于ISP组件的手工制作特性,传统的ISP管道在具有挑战性的场景下具有有限的重建质量。最近,卷积神经网络CNN已经证明了它们在解决许多单独的图像处理问题方面的竞争力,例如图像去噪,去马赛克,白平衡和对比度增强。但是,CNN模型是否可以同时解决ISP管道中的多个任务仍然是一个问题。我们沿着这条线做了一个很好的尝试,并提出了一个新的框架,我们称之为CameraNet,用于有效和通用的ISP管道学习。 CameraNet由两个CNN模块组成,用于在ISP流水线恢复和增强中考虑两组相对不相关的子任务。为了训练两阶段的CameraNet模型,我们指定了两个可以在摄影的常见工作流程中轻松创建的底图。 CameraNet经过培训,可以通过其两个模块逐步解决恢复和增强子任务问题。实验表明,所提出的CameraNet在三个基准数据集上实现了始终如一的引人注目的重建质量,并且优于传统的ISP管道。 |
| Restricted Linearized Augmented Lagrangian Method for Euler's Elastica Model Authors Yinghui Zhang, Xiaojuan Deng, Jun Zhang, Hongwei Li 欧拉弹性模型已被广泛研究并应用于图像处理任务。然而,由于所涉及的曲率项的高非线性和非凸性,传统算法遭受慢收敛和高计算成本。已经提出了各种快速算法,其中,基于增强拉格朗日的算法在社区中非常流行。但是,参数调整对于这些方法可能非常具有挑战性。在本文中,一个简单的切断策略被引入到基于拉格朗日增强的算法中,以最小化欧拉弹性能量,从而简化参数调整和快速收敛。切断策略基于对基于增广拉格朗日算法内部的不一致性的观察。当曲率项的加权参数变为零时,能量函数归结为ROF模型。因此,一个自然的要求是它的增强拉格朗日算法也应该接近直接用于从一开始就解决ROF模型的增强拉格朗日算法。不幸的是,对于某些现有的基于增强拉格朗日算法,情况并非如此。所提出的切断策略有助于解耦辅助分裂变量之间的棘手依赖性,从而消除观察到的不一致性。数值实验表明,该算法更容易参数调整,收敛速度更快,图像修复质量更高。 |
| Simultaneous Clustering and Optimization for Evolving Datasets Authors Yawei Zhao, En Zhu, Xinwang Liu, Chang Tang, Deke Guo, Jianping Yin 同时聚类和优化SCO最近因其广泛的实际应用而备受关注。先前已提出许多方法来解决该问题并获得最佳模型。然而,当数据集随时间演变时,那些现有方法必须经常更新模型以保证准确性,这种更新在计算上是不可行的。在本文中,我们提出了一种新的SCO公式来处理不断发展的数据集。具体而言,我们提出了乘法器ADMM的交替方向方法的新变体,以有效地解决该问题。从理论上分析了岭回归和凸聚类这两个特定任务的模型精度保证。广泛的实证研究证实了我们方法的有效性。 |
| Unsupervised Microvascular Image Segmentation Using an Active Contours Mimicking Neural Network Authors Shir Gur, Lior Wolf, Lior Golgher, Pablo Blinder 显微镜图像中血管分割的任务对于许多诊断和研究应用是至关重要的。然而,根据瞬态成像条件,血管可能看起来大不相同,并且收集监督训练的数据是费力的。我们提出了一种新的深度学习方法,用于无监督的血管分割。该方法的灵感来自活动轮廓领域,我们引入了一个新的损失项,它基于形态学活动轮廓无边缘ACWE优化方法。形态运算符的作用是通过新的汇集层来实现,这些汇集层被整合到网络架构中。我们展示了当成像条件发生变化时,先前监督学习解决方案所面临的挑战。我们的无监督方法能够在标记数据集中以及应用于相似但不同的数据集时优于此前的方法。 GitHub上提供了我们的代码,以及基线方法VesselNN和DeepVess的高效PyTorch重新实现 |
| Improving IT Support by Enhancing Incident Management Process with Multi-modal Analysis Authors Atri Mandal, Shivali Agarwal, Nikhil Malhotra, Giriprasad Sridhara, Anupama Ray, Daivik Swarup 随着人工智能变得司空见惯,IT支持服务行业正在经历一场重大变革。在IT支持流程中,每个人类接触点的自动化方向都付出了很多努力。事件管理就是这样一个过程,它一直是基于AI的自动化的信标过程。目标是从事故罚单到达解决和关闭之前自动执行流程。虽然文本是传达事件的主要模式,但是使用像图像这样的替代模式来传达问题的趋势越来越明显。今天,很大一部分IT支持票据都以屏幕截图,日志消息,发票等形式包含附加的图像数据。这些附件有助于更好地解释有助于更快解决问题的问题。任何渴望提供基于AI的IT支持的人,都必须构建能够处理多模态内容的系统。在本文中,我们将介绍如何使用多模态分析使IT支持域中的事件管理更加有效。从不同模态提取的信息是相关的,以丰富票证中的信息并用于更好的票证路由和解决方案。我们使用包含来自选定问题区域的附件的大约25000张真实票证来评估我们的系统。我们的结果表明,与仅基于文本的分析相比,使用多模态票证分析可以显着改善路由和分辨率。 |
| ++搜索超过mobilenetv3的网络模型 小米 MoGA: Searching Beyond MobileNetV3 Authors Xiangxiang Chu, Bo Zhang, Ruijun Xu MobileNets的发展为移动端的神经网络应用奠定了坚实的基础。借助最新的MobileNetV3,神经架构搜索再次声称其在网络设计方面具有至高无上的地位。直到今天,所有移动方法主要关注CPU延迟而不是GPU,后者虽然具有较低的开销和干扰,但在业界更受青睐。为了缓解这一差距,我们提出了第一个移动GPU感知MoGA神经架构搜索,以便为现实世界的应用程序精确定制。此外,设计移动网络的最终目标在于通过最大限度地利用有限资源来实现更好的性能。在敦促更高的能力和抑制时间消耗的同时,我们非常规地鼓励增加参数的数量以获得更高的代表性能力。毫无疑问,这三种力量是不可调和的,我们必须通过加权进化技术来缓解紧张局势。最后,我们以相似的延迟限制在移动规模上提供优于MobileNetV3的搜索网络,即MoGA A在ImageNet上达到75.9的前1精度,MoGA B达到75.5,移动GPU上的成本仅比MobileNetV3高0.5ms。 75.2。 MoGA C最好通过达到75.3来证明GPU意识,并且在CPU上速度较慢但在GPU上速度更快。模型和测试代码可在此处获得 |
| Building Deep, Equivariant Capsule Networks Authors Sairaam Venkatraman, S. Balasubramanian, R. Raghunatha Sarma 胶囊网络受到它们的相对性,不能以参数便宜的方式更深地限制,并且还受到通常缺乏等效性保证的限制。作为弥合这两个差距的一步,我们提出了一种称为变异空间SOVNET的胶囊网络的新变种。 SOVNET中的每个层都学习使用每个胶囊类型的可学习神经网络来射影地表示一组胶囊的合法姿势变化的多种形式。因此,来自局部池的较浅的囊通过输入与更深的囊的类型相关联的神经网络来预测更深的囊。为了更好地捕获局部对象结构,从增加的参数共享中受益,并且具有等效性保证在预测机制中使用组等变卷积。此外,提出了一种基于图节点度中心性的新路由算法。仿真转换版本的MNIST和FashionMNIST的实验展示了SOVNET优于某些胶囊网络基线的优势。 |
| BCD-Net for Low-dose CT Reconstruction: Acceleration, Convergence, and Generalization Authors Il Yong Chun, Xuehang Zheng, Yong Long, Jeffrey A. Fessler 从低剂量计算机断层扫描CT获得准确可靠的图像具有挑战性。从训练数据中学习的回归卷积神经网络CNN模型在低剂量CT重建中越来越受到关注。本文修改了迭代回归CNN,BCD Net的体系结构,用于快速,稳定,准确的低剂量CT重建,并提出了改进BCD网络的收敛性。使用幻像数据的数值结果表明,将更快的数值求解器应用于基于模型的BCD网络图像重建MBIR模块导致更快更准确的BCD Net BCD Net与使用学习变换BCD的现有MBIR方法相比显着提高了重建精度与最先进的迭代NN架构ADMM Net相比,Net实现了更好的图像质量。临床数据的数值结果表明,BCD Net比缺乏MBIR模块的现有技术深度非迭代回归NN FBPConvNet明显更好。 |
| ++自动分割肝肾肿瘤 Automatic segmentation of kidney and liver tumors in CT images Authors Dina B. Efremova, Dmitry A. Konovalov, Thanongchai Siriapisith, Worapan Kusakunniran, Peter Haddawy 由于肿瘤的异质,扩散形状和复杂背景,计算机断层扫描CT图像中肝脏病变的自动分割是一项具有挑战性的任务。为了解决这个问题,越来越多的研究人员依赖于深度卷积神经网络的辅助,这种神经网络已经被证明在包括医学图像处理在内的各种计算机视觉任务中都具有二维或三维结构。在本技术报告中,我们开展的研究侧重于更加谨慎的学习过程,而不是CNN的复杂架构。我们选择了用于培训过程的MICCAI 2017 LiTS数据集和用于验证我们方法的公共3DIRCADb数据集。所提出的算法在3DIRCADb数据集上达到DICE得分78.8。然后将所述方法应用于2019年肾脏肿瘤分割KiTS 2019攻击,其中我们的单次提交对于肾脏达到96.38并且对于肿瘤Dice得分达到67.38。 |
| CRNet: Image Super-Resolution Using A Convolutional Sparse Coding Inspired Network Authors Menglei Zhang, Zhou Liu, Lei Yu 卷积稀疏编码CSC近年来吸引了越来越多的关注,因为它充分利用了图像全局相关性来提高各种计算机视觉应用的性能。然而,很少有研究关注于解决基于CSC的图像超分辨率SR问题。因此,在一段时间内该领域没有重大进展。在本文中,我们利用CSC和卷积神经网络CNN之间的自然联系来解决基于CSC的图像SR。具体地,引入卷积迭代软阈值算法CISTA来解决CSC问题,并且可以使用CNN架构来实现。然后,我们开发了一种新的基于CSC的SR框架,类似于传统的基于SC的SR方法。受此框架启发的两个模型分别被提议用于前后上采样SR。与最新的现有SR方法相比,我们提出的两种模型在定量和定性测量方面都表现出优异的性能。 |
| ++去除CT中金属工件影响 ADN: Artifact Disentanglement Network for Unsupervised Metal Artifact Reduction Authors Haofu Liao, Wei An Lin, S. Kevin Zhou, Jiebo Luo 当前基于深度神经网络的计算机断层扫描CT金属伪影减少方法是依赖于合成金属伪影进行训练的监督方法。然而,由于合成数据可能无法准确模拟CT成像的潜在物理机制,因此监督方法通常对临床应用的概括性较差。为了解决这个问题,我们建议,就我们所知,第一个无监督的MAR学习方法。具体来说,我们引入了一种新颖的人工解构网络,它可以解开潜在空间中CT图像的金属伪影。它支持具有专门的损失函数的不同形式的世代伪影减少,伪像转移和自我重建等,以消除对合成数据的监督的需要。大量实验表明,当应用于合成数据集时,我们的方法明显优于现有的无监督模型,用于自然图像到图像转换问题,并且实现了与现有的MAR监督模型相当的性能。当应用于临床数据集时,我们的方法表现出比监督模型更好的泛化能力。本文的源代码可在以下网站公开获取 |
| Toward Understanding Catastrophic Forgetting in Continual Learning Authors Cuong V. Nguyen, Alessandro Achille, Michael Lam, Tal Hassner, Vijay Mahadevan, Stefano Soatto 我们研究了灾难性遗忘与任务序列属性之间的关系。特别地,给定一系列任务,我们想要了解该序列的哪些属性影响在序列上训练的连续学习算法的错误率。为此,我们提出了一个新的程序,利用任务空间建模的最新发展以及相关性分析来指定和分析我们感兴趣的属性。作为一个应用程序,我们应用我们的程序来研究任务的两个属性序列1总复杂度和2连续异质性。我们表明,对于某些最先进的算法,错误率与任务序列的总复杂度强烈且正相关。我们还惊讶地发现,错误率在某些情况下与顺序异质性没有甚至是负相关。我们的研究结果提出了改进持续学习基准和方法的方向。 |
| ++自动融合重建声光图像 Y-Net: A Hybrid Deep Learning Reconstruction Framework for Photoacoustic Imaging in vivo Authors Hengrong Lan, Daohuai Jiang, Changchun Yang, Fei Gao 光声成像PAI是一种新兴的非侵入性成像模式,结合了深度超声穿透和高光学对比度的优点。图像重建是PAI中的一个重要主题,遗憾的是,由于组织中复杂且未知的光学声学参数,这是一个不适当的问题。 PAI中使用的常规算法(例如,延迟和求和)提供快速解决方案,同时保留许多伪像,尤其是对于具有有限视图问题的线性阵列探测器。卷积神经网络CNN已经在计算机视觉中显示出最先进的结果,并且近来在医学图像处理中已经研究了越来越多基于CNN的工作。在本文中,我们提出了一种填补现有直接处理和后处理方法之间差距的非迭代方案,并提出了一种新的框架Y Net CNN架构,通过优化原始数据和波束形成图像一次来重建PA图像。网络连接两个编码器和一个解码器路径,最佳地利用来自原始数据和波束成形图像的更多信息。与传统的重建算法和其他深度学习方法相比,测试集的结果表现出良好的性能。我们的方法也通过体外和体内实验验证,其仍然比其他现有方法表现更好。所提出的Y Net架构在医学图像重建方面也具有很高的潜力,可用于PAI以外的其他成像模式。 |
| Chinese Abs From Machine Translation |

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









