







DOM解析XML文件:
1.javax.xml.parsers 包中的DocumentBuilderFactory用于创建DOM模式的解析器对象 , DocumentBuilderFactory是一个抽象工厂类,它不能直接实例化,但该类提供了一个newInstance方法 ,这个方法会根据本地平台默认安装的解析器,自动创建一个工厂的对象并返回
2.调用 DocumentBuilderFactory.newInstance() 方法得到创建 DOM 解析器的工厂。
3.调用工厂对象的 newDocumentBuilder方法得到 DOM 解析器对象。
4.调用 DOM 解析器对象的 parse() 方法解析 XML 文档,得到代表整个文档的 Document 对象,进行可以利用DOM特性对整个XML文档进行操作了。
案例1.遍历xml文件中跟节点下面的所有子节点.
1.xml的约束文件java.dtd
- <!ELEMENT classes (java班,net班,php班,ios班)>
- <!ELEMENT java班 (teachers?,students?)>
- <!ELEMENT net班 (teachers?,students?)>
- <!ELEMENT php班 (teachers?,students?)>
- <!ELEMENT ios班 (teachers?,students?)>
- <!ELEMENT teachers (teacher*)>
- <!ELEMENT teacher EMPTY>
- <!ELEMENT students (student*)>
- <!ELEMENT student (name,sex,age)>
- <!ATTLIST java班 name CDATA #IMPLIED>
- <!ATTLIST net班 name CDATA #IMPLIED>
- <!ATTLIST php班 name CDATA #IMPLIED>
- <!ATTLIST ios班 name CDATA #IMPLIED>
- <!ATTLIST teacher name CDATA #IMPLIED>
- <!ATTLIST teacher sex CDATA #IMPLIED>
- <!ATTLIST teacher age CDATA #IMPLIED>
- <!ELEMENT name (#PCDATA)>
- <!ELEMENT sex (#PCDATA)>
- <!ELEMENT age (#PCDATA)>
- <!ATTLIST student id ID #IMPLIED>
2.xml文件内容如下java.xml
- <?xml version="1.0" encoding="UTF-8" ?>
- <!DOCTYPE classes SYSTEM "bin//parsers//java.dtd">
- <classes>
- <java班 name="CSDNJava01班">
- <teachers>
- <teacher name="军哥" sex="男" age="28" />
- <teacher name="刘丽华" sex="女" age="28" />
- </teachers>
- <students>
- <student id="x121">
- <name>王亮</name>
- <sex>女</sex>
- <age>28</age>
- </student>
- </students>
- </java班>
- <!-- 注释0 -->
- <net班 name="CSDNNet01班">xxx</net班>
- <php班 name="CSDNPhp01班"></php班>
- <ios班 name="CSDNIos01班"></ios班>
- </classes>
- <!-- 对java.xml文件进行CRUD的操作 -->
- <!-- 节点
- nodeName nodeValue nodeType
- element 标签名 null 1
- Attr 属性名 属性值 2
- text #text 文本的值 3
- -->
//1.获取XML的根节点对象
- @Test
- public void test() throws ParserConfigurationException, SAXException, IOException{
- //调用 DocumentBuilderFactory.newInstance() 方法得到创建 DOM 解析器的工厂
- DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
- //调用工厂对象的 newDocumentBuilder方法得到 DOM 解析器对象
- DocumentBuilder builder = builderFactory.newDocumentBuilder();
- //通过文件的方式获取Document对象
- /*File file = new File("src//parsers//java.xml");
- System.out.println(file+"----");
- Document document = builder.parse(file);*/
- //解析指定的文件
- InputStream is= this.getClass().getClassLoader()
- .getResourceAsStream("parsers//java.xml");
- Document document = builder.parse(is);
- //document.getDocumentElement()获取根节点的元素对象
- Element root = document.getDocumentElement();
- //遍历根节点下面的所有子节点
- listNodes(root);
- }
//2.遍历节点对象的方法
- /**
- * 遍历根据节点对象下面的所有的节点对象
- * @param node
- */
- public void listNodes(Node node) {
- // 节点是什么类型的节点
- if (node.getNodeType() == Node.ELEMENT_NODE) {// 判断是否是元素节点
- Element element = (Element) node;
- //判断此元素节点是否有属性
- if(element.hasAttributes()){
- //获取属性节点的集合
- NamedNodeMap namenm = element.getAttributes();//Node
- //遍历属性节点的集合
- for(int k=0;k<namenm.getLength();k++){
- //获取具体的某个属性节点
- Attr attr = (Attr) namenm.item(k);
- System.out.println("name:::"+attr.getNodeName()+" value::"
- +attr.getNodeValue()+" type::"+attr.getNodeType());
- }
- }
- //获取元素节点的所有孩子节点
- NodeList listnode = element.getChildNodes();
- //遍历
- for (int j = 0; j < listnode.getLength(); j++) {
- //得到某个具体的节点对象
- Node nd = listnode.item(j);
- System.out.println("name::" + nd.getNodeName() + " value:::"
- + nd.getNodeValue() + " type:::" + nd.getNodeType());
- //重新调用遍历节点的操作的方法
- listNodes(nd);
- }
- }
- }
4.查询某个节点对象(简单列举一些案例)
- /**
- * 根据标签的名称查找所有该名称的节点对象
- */
- public void findNode(Document document) {
- //根据标签名称获取该名称的所有节点对象
- NodeList nodelist = document.getElementsByTagName("teacher");
- //遍历
- for (int i = 0; i < nodelist.getLength(); i++) {
- //得到具体的某个节点对象
- Node node = nodelist.item(i);
- System.out.println(node.getNodeName());
- }
- }
- /**
- * 根据属性的值 查询某个节点对象
- * 属性值是唯一(假设)
- * @param document
- * @param value
- * @return
- */
- public Node findNodeByAttrValue(Document document, String value) {
- //根据标签名称获取该名称的节点对象集合
- NodeList nodelist = document.getElementsByTagName("teacher");
- //遍历
- for (int i = 0; i < nodelist.getLength(); i++) {
- //获取某个具体的元素节点对象
- Element node = (Element) nodelist.item(i);
- //根据属性名称获取该节点的属性节点对象
- Attr attr = node.getAttributeNode("name");
- //获取属性节点的值是否给指定的节点属性值相同
- if (attr.getNodeValue().equals(value)) {
- //返回此节点
- return node;
- }
- }
- return null;
- }
- /**
- * 根据id获取某个节点对象
- *
- * @param document
- * @param id
- * @return
- */
- public Node findNodeById(Document document, String id) {
- return document.getElementById(id);
- }
5.删除指定的节点对象
- /**
- * 删除某个节点对象
- *
- * @param document
- * @param id
- * @throws TransformerException
- */
- public void deleteNodeById(Document document, String id)
- throws TransformerException {
- //获取删除的节点对象
- Node node = document.getElementById(id);
- // 是通过父节点调用removeChild(node)把子节点给删除掉
- Node node1 = node.getParentNode().removeChild(node);
- //创建TransformerFactory对象
- TransformerFactory transformerFactory = TransformerFactory
- .newInstance();
- //Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出
- //Transformer对象通过TransformerFactory获得
- Transformer transformer = transformerFactory.newTransformer();
- // 把Document对象又重新写入到一个XML文件中。
- transformer.transform(new DOMSource(document), new StreamResult(
- new File("src//a.xml")));
- }
6.更新某个节点对象
- /**
- * 更新某个节点
- *
- * @param document
- * @param id
- * @throws TransformerException
- */
- public void updateNodeById(Document document, String id)
- throws TransformerException {
- //根据id获取元素指定的元素节点对象
- Element node = document.getElementById(id);
- //获取元素节点的id属性节点对象
- Attr attr = node.getAttributeNode("id");
- //修改元素节点的属性值
- attr.setValue("x122");
- //获取该节点对象的所有孩子节点对象name、age、sex节点
- NodeList nodelist = node.getChildNodes();
- //遍历
- for (int i = 0; i < nodelist.getLength(); i++) {
- //得到具体的节点对象
- Node n = nodelist.item(i);
- //判断是否是元素节点对象
- if (n.getNodeType() == Node.ELEMENT_NODE) {
- //看是否是name节点
- if (n.getNodeName().equals("name")) {
- n.setTextContent("君君");//修改其值
- } else if (n.getNodeName().equals("age")) {//看看是否是age节点
- n.setTextContent("80");//修改其值
- } else if (n.getNodeName().equals("sex")) {//看看是否是sex节点
- n.setTextContent("男");//修改其值
- } else {
- System.out.println("不做处理");
- }
- }
- }
- //创建TransformerFactory对象
- TransformerFactory transformerFactory = TransformerFactory
- .newInstance();
- //Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出
- //Transformer对象通过TransformerFactory获得
- Transformer transformer = transformerFactory.newTransformer();
- //把Document对象又重新写入到一个XML文件中。
- transformer.transform(new DOMSource(document), new StreamResult(
- new File("src//b.xml")));
- }
7.在某个节点的下方添加新的节点
- /**
- * 在指定的节点下方添加新得某个节点
- *
- * @param document
- * @param id
- * @throws TransformerException
- */
- public void addNodeById(Document document, String id)
- throws TransformerException {
- //获取要添加位置节点的兄弟节点对象
- Element node = document.getElementById(id);
- //获取其父节点对象
- Node parentNode = node.getParentNode();
- //创建元素节点
- Element nd = document.createElement("student");
- //设置元素节点的属性值
- nd.setAttribute("id", "x123");
- //创建name元素节点
- Node name = document.createElement("name");
- //设置name节点的文本值
- name.appendChild(document.createTextNode("陈红军"));
- //创建age元素节点
- Node age = document.createElement("age");
- //设置age节点的文本值
- age.appendChild(document.createTextNode("20"));
- //创建sex元素节点
- Node sex = document.createElement("sex");
- //设置sex节点的文本值
- sex.appendChild(document.createTextNode("男"));
- //在nd节点中添加3个子节点
- nd.appendChild(name);
- nd.appendChild(age);
- nd.appendChild(sex);
- //在父节点中添加nd节点
- parentNode.appendChild(nd);
- //创建TransformerFactory对象
- TransformerFactory transformerFactory = TransformerFactory
- .newInstance();
- //Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出
- //Transformer对象通过TransformerFactory获得
- Transformer transformer = transformerFactory.newTransformer();
- //把Document对象又重新写入到一个XML文件中。
- transformer.transform(new DOMSource(document), new StreamResult(
- new File("src//c.xml")));
- }
SAX解析XML文件:
SAX解析XML文件采用事件驱动的方式进行,也就是说,SAX是逐行扫描文件,遇到符合条件的设定条件后就会触发特定的事件,回调你写好的事件处理程序。使用SAX的优势在于其解析速度较快,相对于DOM而言占用内存较少。而且SAX在解析文件的过程中得到自己需要的信息后可以随时终止解析,并不一定要等文件全部解析完毕。凡事有利必有弊,其劣势在于SAX采用的是流式处理方式,当遇到某个标签的时候,它并不会记录下以前所遇到的标签,也就是说,在处理某个标签的时候,比如在startElement方法中,所能够得到的信息就是标签的名字和属性,至于标签内部的嵌套结构,上层标签、下层标签以及其兄弟节点的名称等等与其结构相关的信息都是不得而知的。实际上就是把XML文件的结构信息丢掉了,如果需要得到这些信息的话,只能你自己在程序里进行处理了。所以相对DOM而言,SAX处理XML文档没有DOM方便,SAX处理的过程相对DOM而言也比较复杂。
SAX采用事件处理的方式解析XML文件,利用 SAX 解析 XML 文档,涉及两个部分:解析器和事件处理器:
解析器可以使用JAXP的API创建,创建出SAX解析器后,就可以指定解析器去解析某个XML文档。
解析器采用SAX方式在解析某个XML文档时,它只要解析到XML文档的一个组成部分,都会去调用事件处理器的一个方法,解析器在调用事件处理器的方法时,会把当前解析到的xml文件内容作为方法的参数传递给事件处理器。
事件处理器由程序员编写,程序员通过事件处理器中方法的参数,就可以很轻松地得到sax解析器解析到的数据,从而可以决定如何对数据进行处理。
备注说明:SAX API中主要有四种处理事件的接口,它们分别是ContentHandler,DTDHandler, EntityResolver 和 ErrorHandler
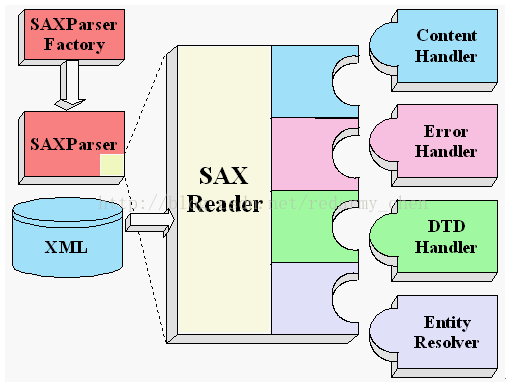
这里使用最多的就是ContentHandler,仔细阅读 API文档,了解常用方法:startElement、endElement、characters等
1.startElement方法说明
- void startElement(String uri,
- String localName,
- String qName,
- Attributes atts)
- throws SAXException
- 方法说明:
- 解析器在 XML 文档中的每个元素的开始调用此方法;对于每个 startElement 事件都将有相应的 endElement 事件(即使该元素为空时)。所有元素的内容都将在相应的 endElement 事件之前顺序地报告。
- 参数说明:
- uri - 名称空间 URI,如果元素没有名称空间 URI,或者未执行名称空间处理,则为空字符串
- localName - 本地名称(不带前缀),如果未执行名称空间处理,则为空字符串
- qName - 限定名(带有前缀),如果限定名不可用,则为空字符串
- atts - 连接到元素上的属性。如果没有属性,则它将是空 Attributes 对象。在 startElement 返回后,此对象的值是未定义的
- void endElement(String uri,
- String localName,
- String qName)
- throws SAXException接收元素结束的通知。
- SAX 解析器会在 XML 文档中每个元素的末尾调用此方法;对于每个 endElement 事件都将有相应的 startElement 事件(即使该元素为空时)。
- 参数:
- uri - 名称空间 URI,如果元素没有名称空间 URI,或者未执行名称空间处理,则为空字符串
- localName - 本地名称(不带前缀),如果未执行名称空间处理,则为空字符串
- qName - 限定的 XML 名称(带前缀),如果限定名不可用,则为空字符串
3.characters方法
- void characters(char[] ch,
- int start,
- int length)
- throws SAXException
- 接收字符数据的通知,可以通过new String(ch,start,length)构造器,创建解析出来的字符串文本.
- 参数:
- ch - 来自 XML 文档的字符
- start - 数组中的开始位置
- length - 从数组中读取的字符的个数
其它方法请参考api数据
下面我们就具体讲解sax解析的操作.
一.我们通过XMLReaderFactory、XMLReader完成,步骤如下
- 1.通过XMLReaderFactory创建XMLReader对象
- XMLReader reader = XMLReaderFactory.createXMLReader();
- 2. 设置事件处理器对象
- reader.setContentHandler(new MyDefaultHandler());
- 3.读取要解析的xml文件
- FileReader fileReader =new FileReader(new File("src\\sax\\startelement\\web.xml"));
- 4.指定解析的xml文件
- reader.parse(new InputSource(fileReader));
案例:通过案例对uri、localName、qName和attribute参数有更加深入的了解
1.首先创建要解析的web.xml文件,内容如下
- <?xml version="1.0" encoding="UTF-8"?>
- <web-app version="2.5"
- xmlns:csdn="http://java.sun.com/xml/ns/javaee"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
- http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd">
- <csdn:display-name></csdn:display-name>
- </web-app>
- <!--
- uri - 名称空间 URI,如果元素没有任何名称空间 URI,或者没有正在执行名称空间处理,则为空字符串。
- xml namespace-xmlns
- localName - 本地名称(不带前缀),如果没有正在执行名称空间处理,则为空字符串。
- qName - 限定的名称(带有前缀),如果限定的名称不可用,则为空字符串。
- attributes - 附加到元素的属性。如果没有属性,则它将是空的 Attributes 对象。
- -->
2.创建解析测试类及事件处理的内部类代码如下
- package sax.startelement;
- import java.io.File;
- import java.io.FileReader;
- import org.junit.Test;
- import org.xml.sax.Attributes;
- import org.xml.sax.InputSource;
- import org.xml.sax.SAXException;
- import org.xml.sax.XMLReader;
- import org.xml.sax.helpers.DefaultHandler;
- import org.xml.sax.helpers.XMLReaderFactory;
- public class Demo3 {
- @Test
- public void test() throws Exception {
- // 通过XMLReaderFactory创建XMLReader对象
- XMLReader reader = XMLReaderFactory.createXMLReader();
- // 设置事件处理器对象
- reader.setContentHandler(new MyDefaultHandler());
- // 读取要解析的xml文件
- FileReader fileReader = new FileReader(new File(
- "src\\sax\\startelement\\web.xml"));
- // 指定解析的xml文件
- reader.parse(new InputSource(fileReader));
- }
- // 自定义的解析类,通过此类中的startElement了解uri,localName,qName,Attributes的含义
- class MyDefaultHandler extends DefaultHandler {
- @Override
- public void startElement(String uri, String localName, String qName,
- Attributes attributes) throws SAXException {
- super.startElement(uri, localName, qName, attributes);
- System.out
- .println("--------------startElement开始执行--------------------------");
- System.out.println("uri:::" + uri);
- System.out.println("localName:::" + localName);
- System.out.println("qName:::" + qName);
- for (int i = 0; i < attributes.getLength(); i++) {
- String value = attributes.getValue(i);// 获取属性的value值
- System.out.println(attributes.getQName(i) + "-----" + value);
- }
- System.out
- .println("------------------startElement执行完毕---------------------------");
- }
- }
- }
3.程序运行的结果如下:
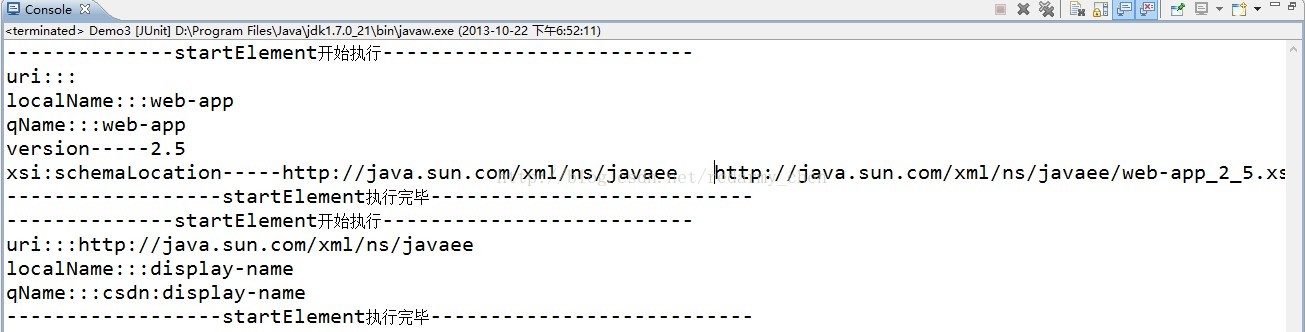
通过运行结果,希望你对uri,localName,qName有更加深入的了解.
二.我们通过SAXParserFactory、SAXParser、XMLReader完成,步骤如下
1.使用SAXParserFactory创建SAX解析工厂
SAXParserFactory spf = SAXParserFactory.newInstance();
2.通过SAX解析工厂得到解析器对象
SAXParser sp = spf.newSAXParser();
3.通过解析器对象得到一个XML的读取器
XMLReader xmlReader = sp.getXMLReader();
4.设置读取器的事件处理器
xmlReader.setContentHandler(new BookParserHandler());
5.解析xml文件
xmlReader.parse("book.xml");
说明:如果只是使用SAXParserFactory、SAXParser他们完成只需要如下3步骤
1.获取sax解析器的工厂对象
SAXParserFactory factory = SAXParserFactory.newInstance();
2.通过工厂对象 SAXParser创建解析器对象
SAXParser saxParser = factory.newSAXParser();
3.通过解析saxParser的parse()方法设定解析的文件和自己定义的事件处理器对象
saxParser.parse(new File("src//sax//sida.xml"), new MyDefaultHandler());
案例:解析出"作者"元素标签中的文本内容
1.需要解析的sida.xml文件
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE 四大名著[
- <!ELEMENT 四大名著 (西游记,红楼梦)>
- <!ATTLIST 西游记 id ID #IMPLIED>
- ]>
- <四大名著>
- <西游记 id="x001">
- <作者>吴承恩</作者>
- </西游记>
- <红楼梦 id="x002">
- <作者>曹雪芹</作者>
- </红楼梦>
- </四大名著>
2.解析测试类和事件处理器类的实现代码
- package sax;
- import java.io.File;
- import javax.xml.parsers.SAXParser;
- import javax.xml.parsers.SAXParserFactory;
- import org.junit.Test;
- import org.xml.sax.Attributes;
- import org.xml.sax.SAXException;
- import org.xml.sax.helpers.DefaultHandler;
- public class SaxTest {
- @Test
- public void test() throws Exception {
- // 1.获取sax解析器的工厂对象
- SAXParserFactory factory = SAXParserFactory.newInstance();
- // 2.通过工厂对象 SAXParser创建解析器对象
- SAXParser saxParser = factory.newSAXParser();
- // 3.通过解析saxParser的parse()方法设定解析的文件和自己定义的事件处理器对象
- saxParser.parse(new File("src//sax//sida.xml"), new MyDefaultHandler());
- }
- // 自己定义的事件处理器
- class MyDefaultHandler extends DefaultHandler {
- // 解析标签开始及结束的的标识符
- boolean isOk = false;
- @Override
- public void startElement(String uri, String localName, String qName,
- Attributes attributes) throws SAXException {
- super.startElement(uri, localName, qName, attributes);
- // 当解析作者元素开始的时候,设置isOK为true
- if ("作者".equals(qName)) {
- isOk = true;
- }
- }
- @Override
- public void characters(char[] ch, int start, int length)
- throws SAXException {
- // TODO Auto-generated method stub
- super.characters(ch, start, length);
- // 当解析的标识符为true时,打印元素的内容
- if (isOk) {
- System.out.println(new String(ch, start, length));
- }
- }
- @Override
- public void endElement(String uri, String localName, String qName)
- throws SAXException {
- super.endElement(uri, localName, qName);
- // 当解析作者元素的结束的时候,设置isOK为false
- if ("作者".equals(qName)) {
- isOk = false;
- }
- }
- }
- }
3.程序运行结果如下:

1.sax与Dom解析的区别
dom是w3c指定的一套规范标准,核心是按树形结构处理数据,dom解析器读入xml文件并在内存中建立一个结构一模一样的“树”,这树各节点和xml各标记对应,通过操纵此“树”来处理xml中的文件。xml文件很大时,建立的“树”也会大,所以会大量占用内存。sax解析器占内存少,效率高。sax解析器核心是事件处理机制。例如解析器发现一个标记的开始标记时,将所发现的数据会封装为一个标记开始事件,并把这个报告给事件处理器,事件处理器再调用方法(startElement)处理发现的数据。事件处理器可以自己编写也可以从父类继承。

上图中描述了SAX和DOM的不同。
SAX适于处理下面的问题:
1、对大型文件进行处理;
2、只需要文件夹的部分内容,或者只需从文件中得到特定信息。
3、想建立自己的对象模型的时候。
DOM适于处理下面的问题:
1、需要对文件进行修改;
2、需要随机对文件进行存取
2.如果用(二的解析方式解析web.xml)会有什么样的输出结果?















 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









