







Feasibility of Learning
直观来讲机器学习其实是用采样估计整体。
When Can Machines Learn?
No Free Lunch (必须有归纳偏好才可以学习)

假如没有明确要学习的问题,对于样本,所有的模型假设
f
f
f同等重要,那么从
D
\mathcal{D}
D中学习去推断
D
\mathcal{D}
D以外的是注定失败的。在西瓜书中,把NFL定理认为是归纳偏好。也就是学习必须要偏好某种假设
f
f
f,例如使用“奥卡姆剃刀”,偏好简单的模型假设。当然这个假设要跟问题相匹配。
Hoeffding不等式(从概率上理解可学习)
这个不等式可以提供用采样估计整体的PAC上界(PAC指的是Probably approximately correct)。

这个不等式中
ν
\nu
ν是采样的统计量,
μ
\mu
μ是整体的估计量,二者相差
ϵ
\epsilon
ϵ的概率上界为
2
e
x
p
(
−
2
ϵ
2
N
)
2exp(-2\epsilon^2N)
2exp(−2ϵ2N),其中
N
N
N是采样的数量,注意各次采样之间满足独立同分布。这是直观解读,更详细的Hoeffding不等式参见维基百科。
Connect to Learning
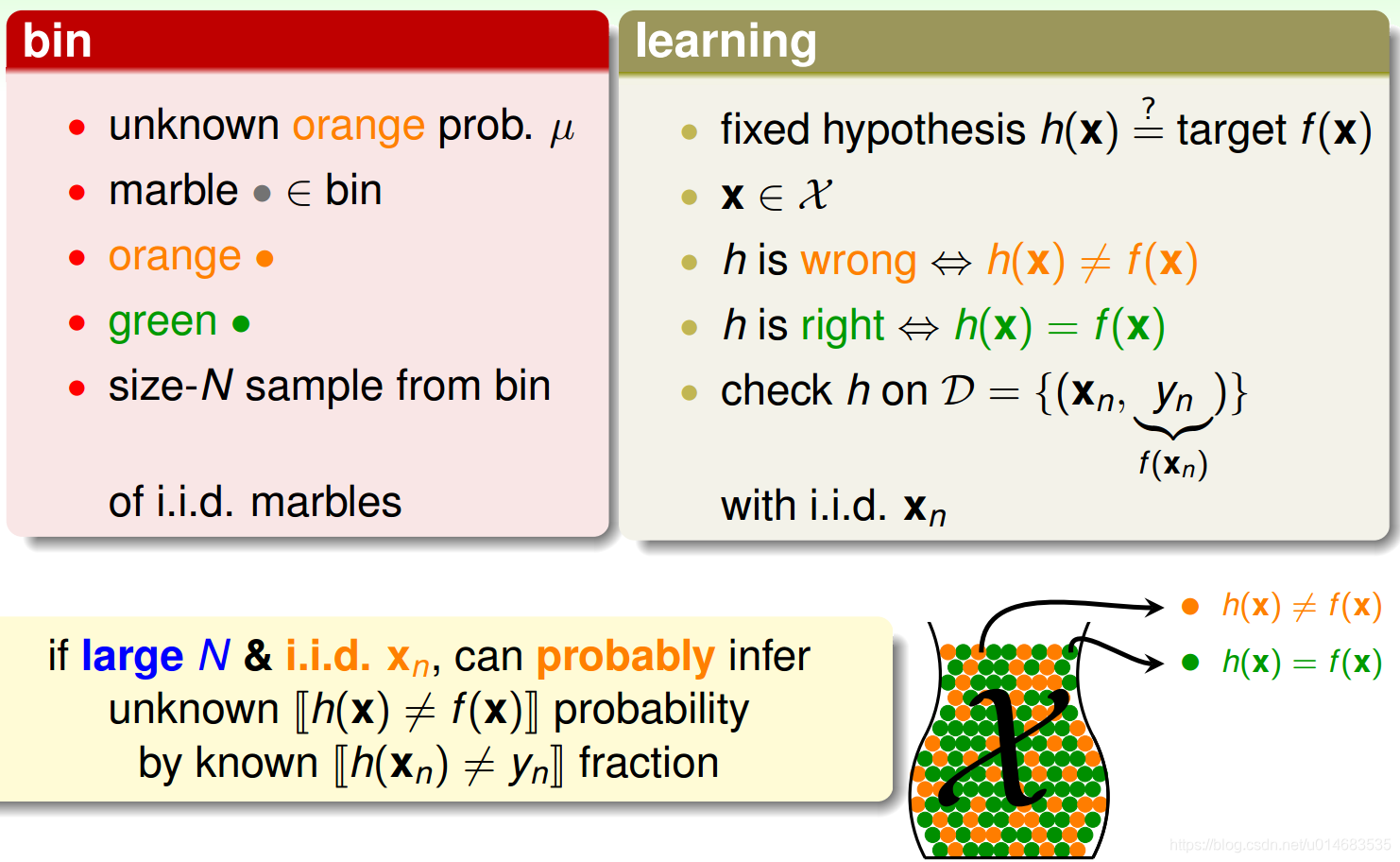
对于假设
h
h
h,我们把
h
(
x
i
)
h(x_i)
h(xi)是错的当成是黄色小球,
h
(
x
i
)
h(x_i)
h(xi)是对的当成是绿色小球,而
x
i
∈
X
x_i \in \mathcal{X}
xi∈X是采样。那么黄色小球的比例
ν
=
E
(
h
(
x
)
≠
f
(
x
)
)
\nu=E(h(x)\neq f(x))
ν=E(h(x)̸=f(x))即
E
i
n
E_{in}
Ein,而整体中黄色小球的比例就是
E
o
u
t
E_{out}
Eout。所以根据Hoeffding不等式,
∣
E
i
n
−
E
o
u
t
∣
>
ϵ
|E_{in}-E_{out}|>\epsilon
∣Ein−Eout∣>ϵ的概率有个上界。
实际的学习是从多个
h
h
h中找到能使得
E
i
n
E_{in}
Ein最小的
h
∗
h^*
h∗作为学习的结果
g
g
g, 使得
g
=
f
g=f
g=f, PAC. 但是当可选择的
h
h
h较多的时候,就必然存在使
E
i
n
=
0
E_{in}=0
Ein=0的
h
′
h'
h′,但是却使得
E
o
u
t
E_{out}
Eout很大,称这种
h
′
h'
h′叫"Bad Sample"。同理,对于一个
h
h
h,存在让
∣
E
i
n
−
E
o
u
t
∣
>
ϵ
|E_{in}-E_{out}|>\epsilon
∣Ein−Eout∣>ϵ的采样数据集
D
\mathcal{D}
D,这种
D
\mathcal{D}
D叫作"Bad Data"。

所以推出假设空间
H
\mathcal{H}
H为有限集的时候的Hoeffding不等式。(注意每个
h
h
h相当于一个装满球的bin,而从采样集
D
\mathcal{D}
D中得到
∣
ν
−
μ
∣
>
ϵ
|\nu-\mu| > \epsilon
∣ν−μ∣>ϵ等于
D
\mathcal{D}
D是
h
h
h的"Bad Data". 那么当前的训练集是某个
h
h
h的"Bad Data"的概率有个上界。然后可以得到对于
H
\mathcal{H}
H, 能够学到的“most resonable”的
h
h
h令
∣
E
i
n
−
E
o
u
t
∣
>
ϵ
|E_{in}-E_{out}|>\epsilon
∣Ein−Eout∣>ϵ有个概率上界,说明这个问题还是PAC可学习的。)
Why Can Machines Learn?
Effective Number of Hypothesis (上面的Hoeffding不等式里的M可以减小)
上面提到针对有限假设空间
H
\mathcal{H}
H的PAC可学习的不等式,那个概率上界中提到的
M
M
M可能是无穷大的。例如假设空间
H
\mathcal{H}
H是二维平面的直线集合。但是实际上从训练集
D
\mathcal{D}
D的角度来看,这些直线的种类是有限的。例如两条不一样的直线将训练集分成的两部分是相同的,那就认为这些直线是同一类,因为它们的
E
i
n
E_{in}
Ein相同,
E
o
u
t
E_{out}
Eout接近。用Growth Function来表示总共有多少类不同的假设,用
m
H
m_{\mathcal{H}}
mH来表示
H
\mathcal{H}
H的增长函数。

对二分类问题来说,
H
\mathcal{H}
H中的假设对
D
\mathcal{D}
D中示例赋予标记的每种可能结果称为对
D
\mathcal{D}
D的一种“对分”。若假设空间
H
\mathcal{H}
H能实现数据集
D
\mathcal{D}
D的所有对分,即
m
H
=
2
N
m_{\mathcal{H}}=2^{N}
mH=2N,则称
H
\mathcal{H}
H可以把
D
\mathcal{D}
D打散。

Break Point

使用break point可以降低增长函数到poly(N)

引入bounding function的概念,为了解决
m
H
(
N
)
m_{\mathcal{H}}(N)
mH(N)是多项式复杂度的问题。

证明省略

VC bound (Bad Data发生的概率更紧的上界):
将
E
o
u
t
E_{out}
Eout替换成
E
i
n
′
E'_{in}
Ein′,一系列放缩之后得到,再使用Hoeffding without Replacement:

VC维

d
d
d维的Perceptron的VC维是
d
+
1
d+1
d+1.
改写VC bound:

变换形式:将
ϵ
\epsilon
ϵ用
δ
\delta
δ表示

最终得到:

模型不一定越复杂越好!
计算sample complexity:

为什么sample complexity理论结果比实际经验大这么多?原因就是:















 730
730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









