






Java基础(下)
书接上文 Java基础(上)
本文采用全新注释和排版、更清晰
声明:集合当中有关于源码和数据结构的内容,因为概念抽象,画图不便。临时称其为指针更好理解。但是Java当中是没有指针的!
文中所谓指向前后的指针皆为引用对象
Java基础
一、枚举和注解
1.枚举(enum)
说明:枚举(enum)是一组常量的集合,属于一种特殊的类,里面只包含一组有限的特定的对象。
1.枚举的两种实现方式:
(1):自定义类实现枚举:
①:将构造器私有化(private),防止直接new赋值
②:去掉setXXX方法,可以保留getXXX因为枚举对象值通常为只读,防止属性被修改
③:在类的内部,直接创建固定对象,通过[ public final static ]修饰符暴露对象

在main函数中调用:System.out.println(Season.AUTUMN);//可在类中重写toString方便输出。
自定义类实现枚举要点:
1.枚举对象名通常全部使用大写,常量的命名规范。
2.原先说 final + static 修饰能够避免类的加载实现底层优化。本人使用静态静态代码块测试,同样还是会进行类的加载。
3.枚举对象根据需要,可以有多个属性。
(2):使用enum关键字实现枚举**
①:使用关键字 enum 替代 class
②:将自定义类枚举中public final static 定义句 换成 SPRING("春天","温暖")常量名(实参列表)
③:如果有多个常量(对象),使用逗号间隔即可
例:SPRING(“春天”,“温暖”),WINTER(“冬天”,“寒冷”); 语句之间使用逗号而非分号
④:使用 enum 实现枚举,要求定义常量必须写在第一句(行首),私有变量可以放在后面
2.enum 注意事项
1.当我们使用enum 关键字开发一个枚举类时,默认会继承Enum类
javap:将编译好的 class文件 重新变回 java文件 的dos命令
2.传统的 public static final Season SPRING = new Season("春天”"温暖”); 简化成 SPRING(“春天”,"温暖"), 这里必须知道,它调用的是哪个构造器.
3.如果使用无参构造器创建枚举对象,则实参列表和小括号都可以省略
例:从 SPRING("春天","温暖") 编程 SPRING; 此时它调用的是无参构造器
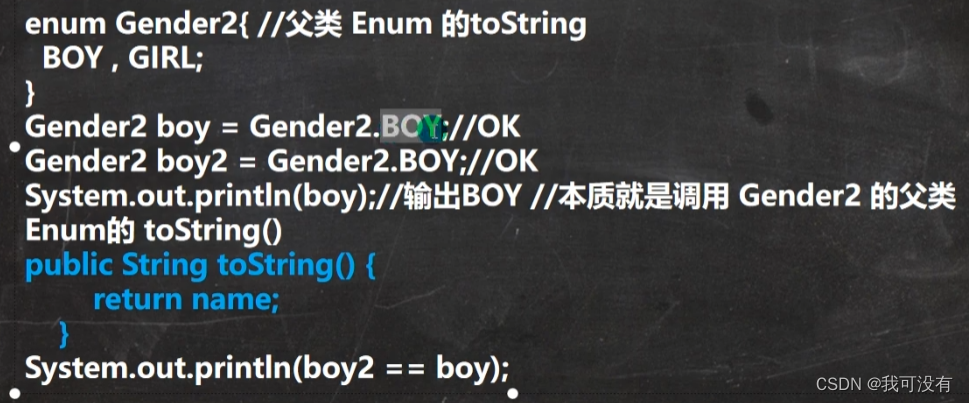
💢当你创建枚举类型实例并且输出实例的时候,它所输出的内容就是你在枚举类型当中定义的常量名。比如 BOY、GIRL,当你输出实例的时候理论上是调用子类的 toString 来替你输出。但是子类没有重写,于是找到了父类 Enum,父类重写了 toString 来 return name。而这个 name 就是你声明Enum 的常量名(大写的)!
3.enum 常用方法说明
1.toString:Enum类已经重写,返回的是当前对象名。子类可以重写该方法,返回对象的属性信息。
2.name:返回当前常量名,子类中不能重写
3.ordinal:返回当前对象的位置号,默认从0开始,有点类似于它的位置的下标
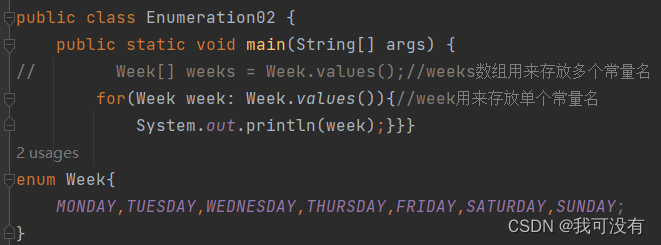
4.values:返回当前枚举类中所有的常量 运用增强for 来查看
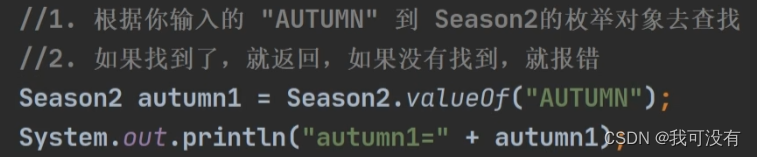
5.valueOf:输入字符串,它会到该枚举中查找同名对象并返回,未找到则报异常!
6.compareTo:比较两个枚举常量,用 前面调用方法名的位置号减后面 的位置号

增强for循环
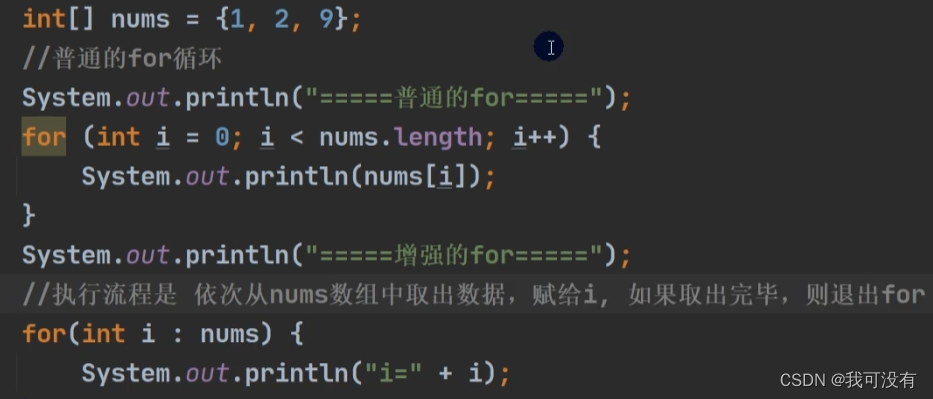
普通for循环当中:i 充当的是下标来找到数组
增强for循环当中:i 是直接存储nums数组的数据,每一次都将nums的数据传送一个给 i 。
4.enum 常用方法说明
1.使用enum关键字后,就不能再继承其他类了,因为enum会隐式继承Enum,而Java是但继承机制
2.枚举类和普通类一样可以实现接口,形式如下:
enum 类名 Implements 接口1,接口2{ }
interface IPlaying{public void playing();}//接口和抽象方法
enum Music implements IPlaying{
CLASSICMUSIC;
public void playing(){//方法重写
System.out.println("播放音乐...");}
}
public static void main[String[] args]{
Music.CLASSICMUSIC.playing();}//main中调用
5.注解(Annotation)
1.注解(Annotation)也被称为元数据(Metadata),用于修饰解释 包类、方法、属性、构造器、局部变量等数据信息。
2.和注释一样,注解不影响程序逻辑,但注解可以被编译或运行,相当于嵌入在代码中的补充信息。
3.在JavaSE中,注解的使用目的比较简单,例如标记过时的功能,忽略警告等。在JavaEE中注解占据了更重要的角色,例如用来配置应用程序的任何切面,代替java EE旧版中所遗留的繁元代码和XML配置等。
说明:使用 Annotation 时要在其前面增加 @ 符号,并把该(Annotation)当成一个修饰符是用。用于修饰它支持的程序元素
三个基本的 Annotation:
1.@Override:限定某个方法,时重写父类方法,该注解只能用于方法
①:即便不写@Override,也能够执行子类重写父类的方法。但如果写了@Override,编译器则会检查该方法是否真的重写,重写了则通过编译,没有重写则编译错误
若出现:@interface 表示一个注解类 与 接口无关
②:@Override 只能修饰方法,不能修饰其他类、包、属性等等
③:@Override注解源码为 @Target(ElementType.METHOD),说明只能修饰方法
④:@Target 是修饰注解的注解,称为 元注解
2.@Deprecated:用于表示某个程序元素(类,方法等)已过时
例:@Deprecated class A{ public int n1 = 10; public void hi(){ }}
①:@Deprecated 修饰某个元素,表示该元素已过时。
即不再推荐使用,但是仍可以使用。当你再次调用这个元素或方法时,会出现一道划线
②:可以修饰方法、类、字段、包、参数等等
③:@Target(value = {CONSTRUCTOR, FIELD, LOCAL_VARIABLE, METHOD, PACKAGE, PARAMETER, TYPE})// 翻译出来就是能够修饰的内容
④:@Deprecated 的作用可以做到新旧版本的兼容和过渡
3.@SuppressWarnings:抑制编译器警告
说明:在代码编写过程中经常容易出现警告,当你不想看到这些警告的时候便可以使用,@SuppressWarnings({" "})此格式来抑制警告。
@SuppressWarnings的使用:
在出现警告的时候,将鼠标放置在代码右方的黄色线条,能够看出警告内容。
根据警告内容来输入你希望抑制 ( 不显示 )的警告信息,或者直接填入 "all" 掩耳盗铃,一劳永逸
例:@SuppressWarnings({“rawtypes”,“uncheked”})
具体抑制内容可参考:https://blog.csdn.net/qq_40437152/article/details/86577194
①:@SuppressWarnings 作用范围与你放置的位置相关
你放在main方法上面就是main方法,或者放在语句、类之前也可以
②:@Target({TYPE,FIELD,METHOD,PARAMETER,CONSTRUCTOR,LOCAL_VARIABLE})
③:该注解类有数组 String[ ] values( ) 设置一个数组{“rawtypes”,“uncheked”}
6.元注解(了解即可)
学习元注解目的是方便各位解读源码,可以在查看源码时来翻看。
1.Retention:指定注解的作用范围,三种: SOURCE,CLASSRUNTIME
说明:只能用于修饰一个Annotation 定义,用于指定该Annotation可以保留多长时间,@Rentention 包含一个 RetentionPolicy 类型的成员变量,使用 @Rentention时必须为该 value 成员变量指定值。
①:RetentionPolicy.SOURCE: 编译器使用后,直接丢弃这种策略的注释
②:RetentionPolicy.CLASS: 编译器将把注释记录在 class 文件中当运行 Java 程序时,JVM 不会保留注解。 这是默认值
③:RetentionPolicy.RUNTIME:编译器将把注解记录在 class 文件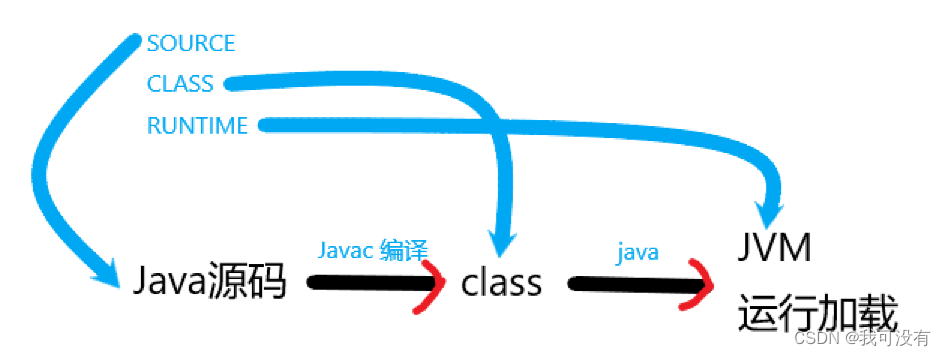
中。当运行Java 程序时,JVM 会保留注解。程序可以通过反射获取该注释
2.Target:指定注解可以在哪些地方使用
用于修饰 Annotation 定义,用于指定被修饰的 Annotation 能用于修饰哪 些程序元素. @Target 也包含一个名为 value 的成员变量
3. Documented:指定该注解是否会在javadoc体现
用于指定被该元 Annotation 修饰的 Annotation 类将被javadoc 工具提取成文档,即在生成文档时,可以看到该注解。
说明:定义为Documented的注解必须设置Retention值为RUNTIME
例:JDK API 当中有一些过时的方法,在文档中就标记了 @Deprecated
能出现在文档中是因为它的源码标注了:@Documented
4. Inherited:子类会继承父类注解
被它修饰的 Annotation 将具有继承性.如果某个类使用了被 @Inherited 修饰
的 Annotation,则其子类将自动具有该注解
二、异常(Exception)
1.异常概念
说明:不使用异常处理机制的情况下在项目运行过程中出现了一个不算致命的错误,就会导致系统崩溃。当我们在处理一个很大的项目的时候,为了避免一个小错误导致系统的崩溃。我们就会采用异常处理机制来解决问题,这样即使某段代码出现了错误,也不会影响程序运行完成!
注意:开发过程中的语法错误和逻辑错误不是异常
当你认为一段代码可能出现 异常 / 报错 可以使用 try - catch 异常处理机制来解决
从而保证程序的健壮性
只需:选中可能异常的代码块 快捷键 ctrl + alt + t 选中 try - catch
执行过程中所发生的异常事件可分为两类:
1.Error(错误):Java虚拟机无法解决的严重问题
例:JVM系统内部错误、资源耗尽等严重情况。
StackOverflowError[栈溢出]、OOM(out of memory)、 Error 都是严重错误,程序会崩溃
2.Exception:其他因编程错误或偶然的外在因素导致的一般性问题,可以使用针对性的代码进行处理。例如空指针访问,试图读取不存在的文件,网络连接中断等等,
异常(Exception)分为两大类: 运行时异常[ 程序运行时发生的异常] 和 编译时异常[ 编译时 编译器检查出的异常]
异常体系图一览:
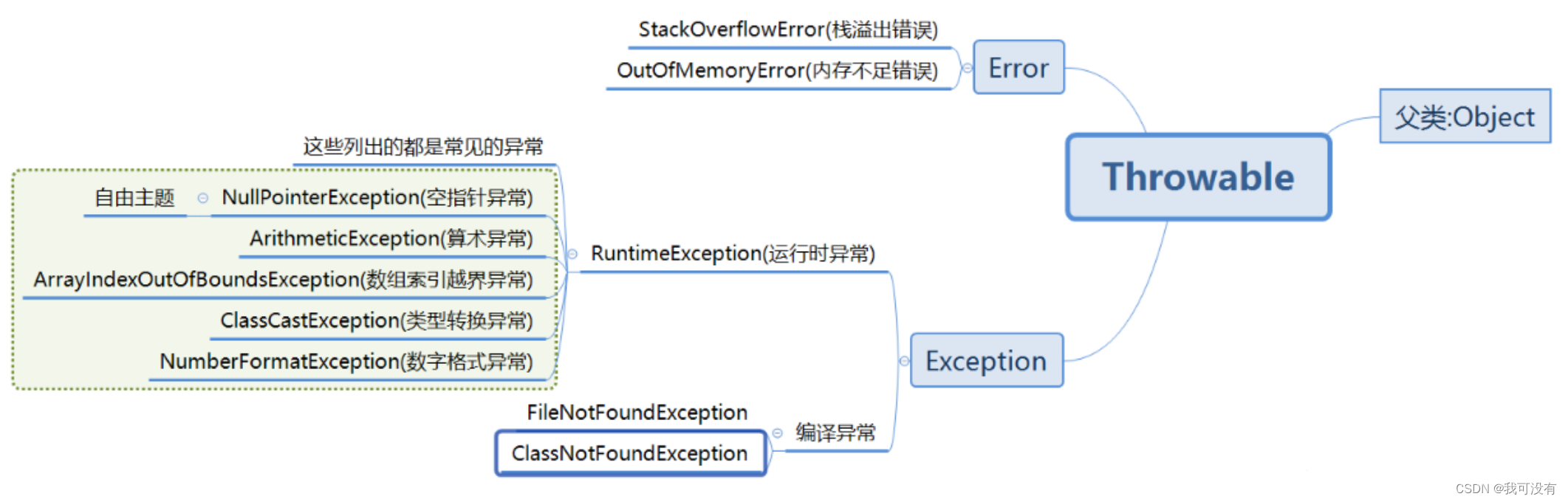
1.运行时异常,编译器检测不出来,一般指编程时的逻辑错误,时程序员应该避免其出现的异常。java.lang.RuntimeException类及它的子类都是运行时异常
2.对于运行时异常,可以不做处理,因为这类异常很普遍,若全处理可能会对程序的可读性和运行效率产生影响
3.编译时异常,是编译器要求必须处置的异常`
2.常见的运行时异常
1.NullPointerException空指针异常
说明:当应用程序示图在需要对象的地方使用 null 时,抛出异常
例:String name = null; System.out.println(name.length( ));
2.ArithmeticException数学运算异常
说明:当出现异常的运算条件时,抛出异常
例:int res = 10 / 0;
3.ArraylndexOutOfBoundsException数组下标越界异常
说明:用非法索引访问数组时抛出异常,如果索引为负或大于等于数组大小,则该索引为非法索引( index )
例:int[] arr = {1,2,4}; System.out.println(arr[5]);
4.ClassCastException类型转换异常
说明:当试图将对象强制转换为不是实力的子类时,抛出异常

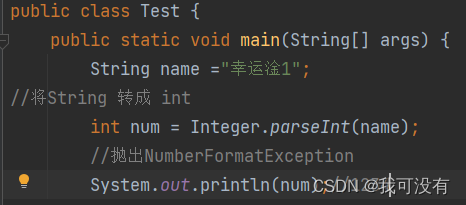
5.NumberFormatException数字格式不正确异常
说明:当应用程序试图将字符串转换成一种数值类型,但该字符串不能转换为适当格式时,抛出异常。 使用异常我们可以确保输入时满足条件的数组
3.编译异常
说明:编译异常是指在编译期间,就必须处理的异常,否则代码不能通过编译
常见的编译异常:
- SQLException //操作数据库时,查询表可能发生异常
- IOException //操作文件时,发生的异常
- FileNotFoundException //当操作一个不存在的文件时,发生异常
- ClassNotFoundException //加载类,而该类不存在时,异常
- EOFException // 操作文件,到文件未尾,发生异常
- IllegalArguementException //参数异常
异常处理的方式:
异常处理就是当异常发生时,对异常处理的方式
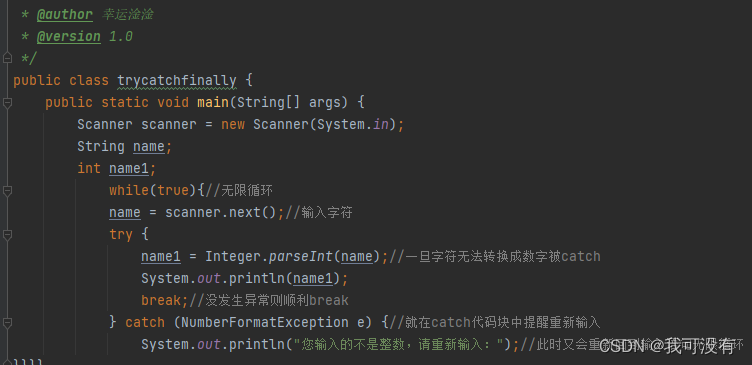
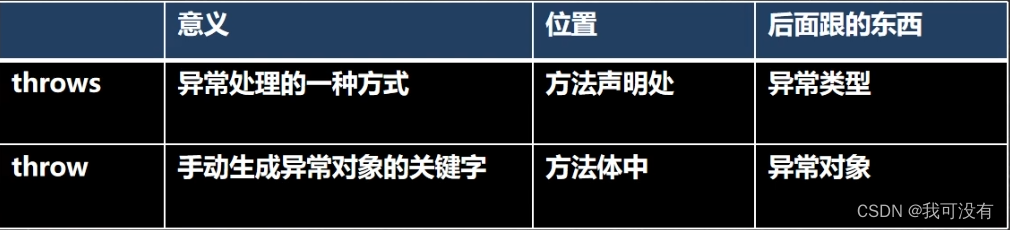
1.try - catch - finally
程序员在代码中捕获发生的异常,自行处理

2.throws
将发生的异常抛出,交给调用者(方法)来处理,最顶级的处理者就是JVM
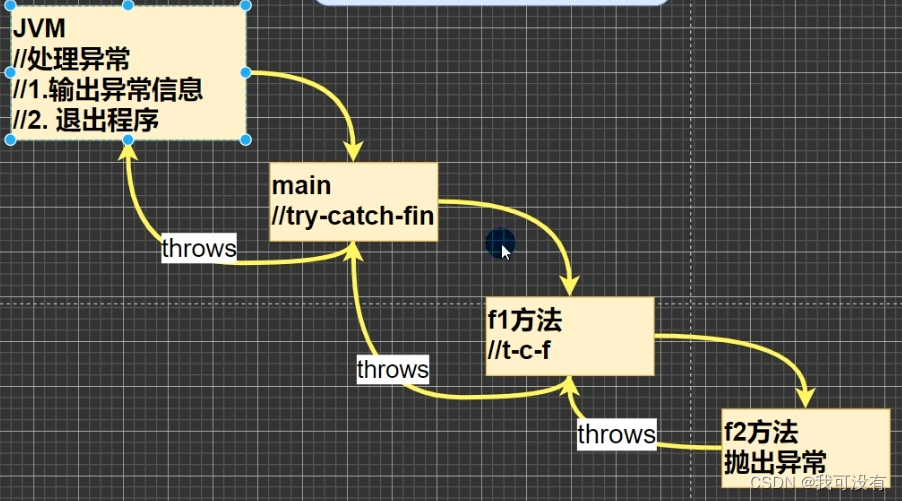
1.try - catch - finally 和 throws 二选一
要么就在当前位置try - catch - finally,要么就throws丢给上一级。
当每一层调用都没有解决异常问题,则交给JVM处理。
JVM处理机制十分暴力,它会直接报错之后中断程序。也就是以往大家看到的程序报错
2.如果程序员,没有显示是异常处理,默认是在方法前throws丢给上一层。知道丢给JVM,发生报错
4.try - catch - finally异常处理
1.Java提供try和catch块来处理异常。try块用于包含可能出错的代码。catch块用于处理try块中发生的异常。可以根据需要在程序中有多个数量的try…catch块
2.基本语法:
try{
//可疑代码
//将异常生成对应的异常对象,传递给catch块
}catch(异常){
//对异常的处理
}
finally并不是一定要写的,但它一定会执行
try - catch方式处理异常 - 注意事项:
1.如果异常发生了,则异常发生后面的代码不会执行,直接进入到catch块
2.如果异常没有发生,则顺序执行try的代码块,不会进入到catch
3.如果希望不管是否发生异常都执行某段代码(比如关闭连接,释放资源等)则使用如下代码 - finally { }
4.可以有多个catch语句,捕获不同的异常(进行不同的业务处理),要求父类异常在后,子类异常在前,比如(Exception 在后,NullPointerException 在前),如果发生异常,只会匹配一个catch
分开捕获异常:
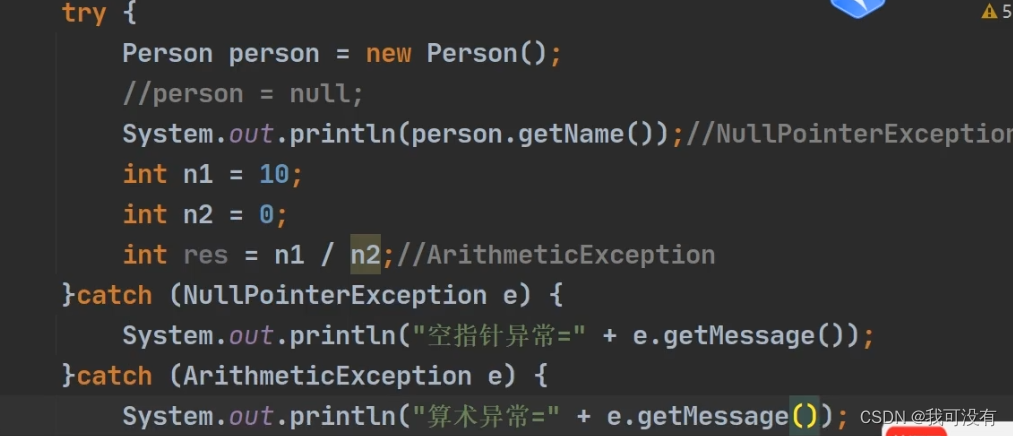
如果父类异常写在前面,比如Exception 它就足够捕获所有异常。就没有办法针对某个异常去写处理方法。
5.可以进行 try - finally 配合使用,这种用法相当于没有捕获异常,如果try当中程序出错因此程序会直接崩掉/退出。它的应用场景是,执行一段代码,不管是否发生异常,都必须执行某个业务逻辑。
语法:
try{
//代码…
}finally{
//总是执行}
- 不论发生什么、都必须执行finally中代码块。但这个方法并
不是用来捕获异常
6.try - catch - finally执行顺序小结:
1.如果没有出现异常,则执行try块中所有语句,不执行catch块中语句,如果有finally,最后还需要执行finally里面的语句
2.如果出现异常,则try块中异常发生后,剩下的语句不再执行。将执行catch块中的语句,如果有finally,最后还需要执行finally里面的语句
5.throws异常处理
1.如果一个方法(中的语句执行时)可能生成某种异常但是并不能确定如何处理这种异常则此方法应显示地声明抛出异常,表明该方法将不对这些异常进行处理,而由该方法的调用者负责处理
2.在方法声明中用throws语句可以声明抛出异常的列表,throws后面的异常类型可以是方法中产生的异常类型,也可以是它的父类。当你觉得写某个异常很麻烦也可以直接写 throws Exception 更加方便。
3.throws关键字后也可以是 异常列表,即可以抛出多个异常。用逗号间隔
throws异常处理 :
1.对于运行时异常,程序中如果没有处理,默认就是throws的方式处理。就直接丢给调用它的方法去处理,如果丢到了main当中。那就是JVM处理,直接报错。
2.子类重写父类的方法时,对抛出异常的规定:子类重写的方法,所抛出的异常类型要么和父类抛出的异常一致,要么为父类抛出的异常类型的子类型
自定义异常
1.定义类:自定义异常类名(程序员自己写) 继承Exception或RuntimeException
2.如果继承Exception,属于编译异常
3.如果继承RuntimeException,属于运行异常(一般来说,继承RuntimeException)
即把自定义异常做成 运行时异常, 好处是我们可以使用默认的处理机制
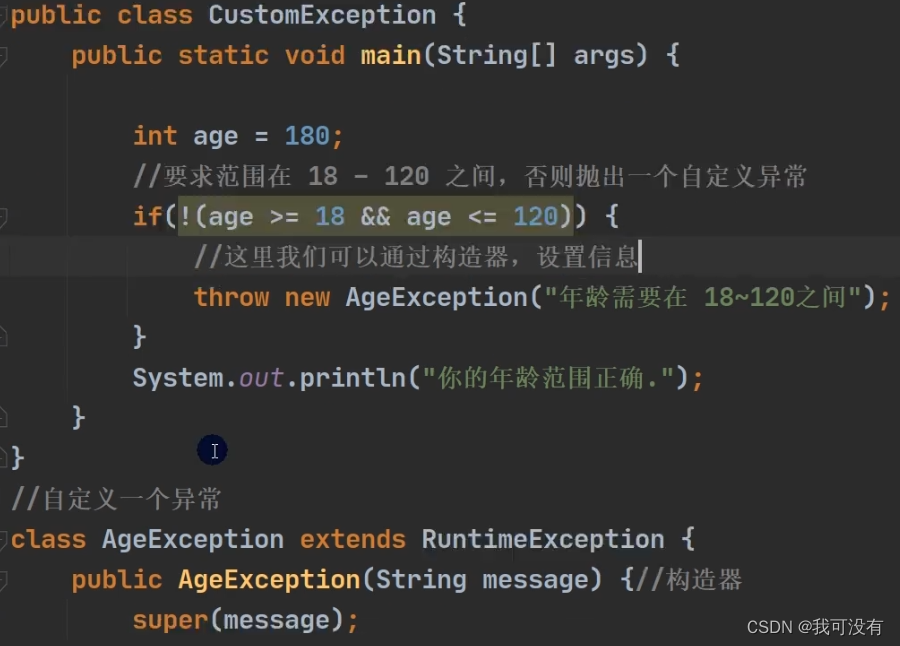
throw 和 throws 的区别:
三、八大包装类(Wrapper)
1.包装类的分类
1.针对八种基本数据类型相应的引用类型 - 包装类
2.有了类的特点,就可以调用类中的方法
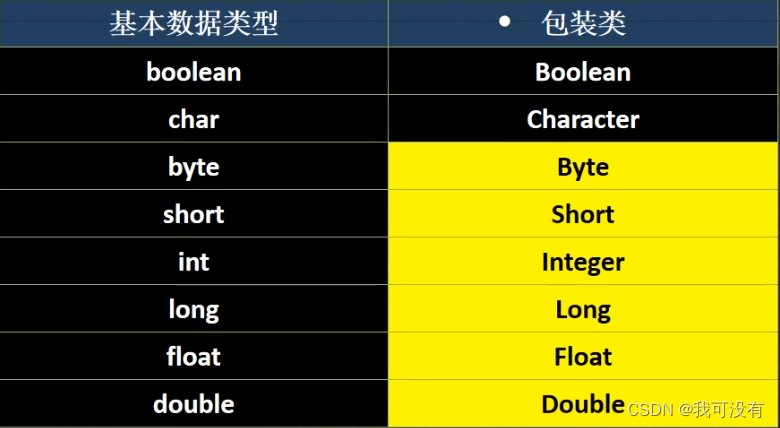
黄色部分包装类的父类:Number
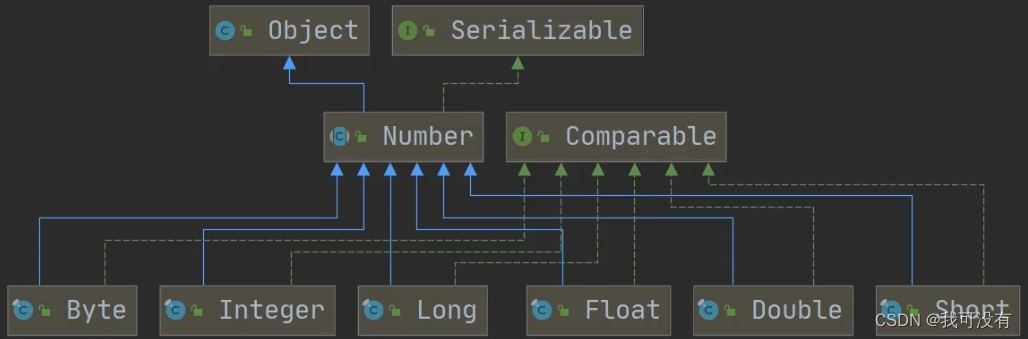
包装类和基本数据的转换:
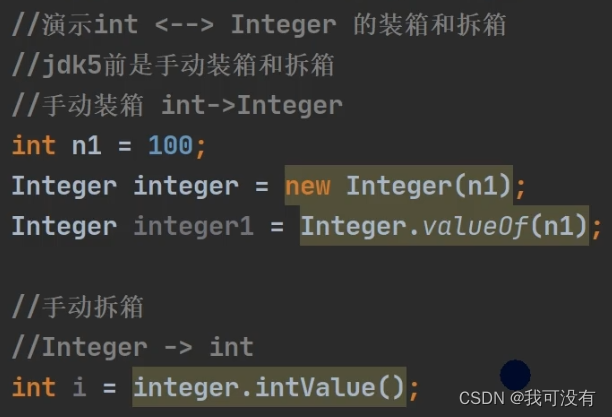
1.JDK5 以前的手动装箱和拆箱方式 装箱:基本类型 → 包装类 反之,拆箱/
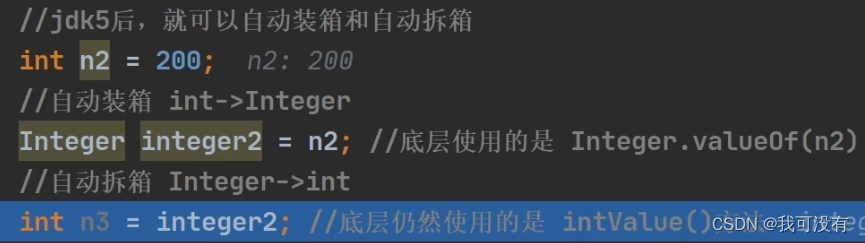
2.JDK5 以后(含JDK5)的自动装箱和拆箱方法
3.自动装箱底层调用的是valueOf方法,比如Integer.valueOf( )
手动装箱、拆箱图解:
自动装箱、拆箱图解:
练习:

Integer x = 128;//在底层中实际时调用了 Integer.valueOf(128);
当你赋值在 -128 ~ 127之间时,实际上并没有 new Integer 、是给你存放进他的数组之中
当你超出了这个范围时,才会真正给你 new Integer
但是,当你 Integer x = new Integer(128); 时。 此时并不会存入源码数组,是直接新建==================================
关于包装类的接口解释:
右键 包装类(如:String) 选择 show Diagram 则可以看到 包装类所接入的所有接口
Serializable:接入该接口表示 String可以串行化、能够进行网络传输
Comparable:接入该接口说明该对象可以比较大小、然后自然排序
2.String(面试常考)💢
1.String对象用于保存字符串,也就是一组字符序列
2.字符串常量对象是用双引号括起来的字符序列。例如:“你好”、“12.97”、"boy"等等
3.字符串的字符使用Unicode字符编码,一个字符(不区分字母还是汉字)占两个字节
4.String类较常用构造方法(其他看手册):
String实现了构造器重载、有非常多方法
String s1 = new String();
String s2 = new String(String original);
String s3 = new String(char[] a);
String s4 = new String(char[] a,int startIndex, int count);
String s5 = new String(byte[] b);
5.String 是 final 类不能被继承
6.String 有属性 private final char value[];用于存放字符串内容
7.value 是一个 final类型, 其地址不可以修改:即value不能指向
你无法修改 vlaue 的地址、但你可以修改 value 里面的字符内容
当你更改了String对象的内容之后,其实都是新建了一个,指向新的value,新的value指向你在 常量区 新开辟空间存放的 字符内容
创建String对象的两种方式:
方式一:直接赋值 String s = “幸运淦”;
方式二:调用构造器String s = new String(“幸运淦”);
1.方式一:先从常量池查看是否有 “幸运淦” 数据空间,如果有,直接指向;
如果没有则重新创建,然后指向。main方法中的 s 最终指向的是常量池的空间地址
2.方式二:先从堆中创建空间,里面维护了value属性,指向常量池的"幸运淦"空间。
如果常量池没有"幸运淦",重新创建,如果有,直接通过value指向。最终指向的是堆中的空间地址
3.两种方式的内存分布图:
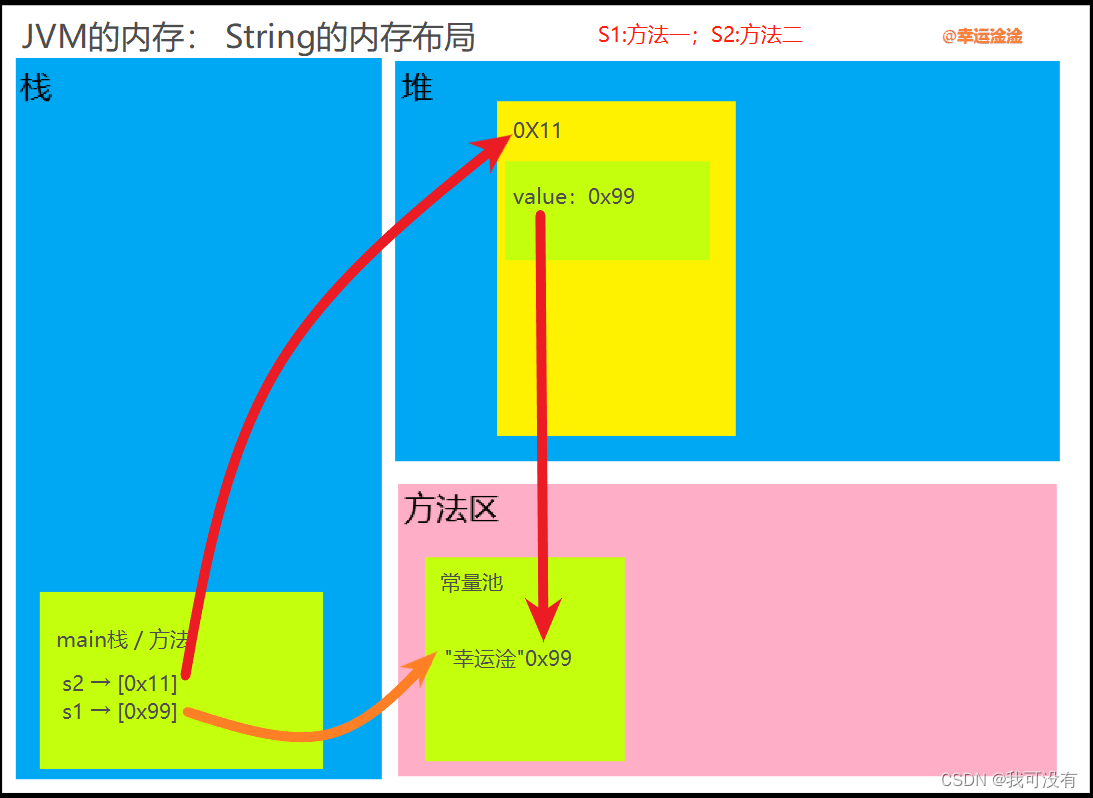
方式一[橙色箭头]:s1 会直接进入常量池找、找到就直接指向,找不到就重新建一个指向它。
方式二[红色箭头]:s2在堆里面创建一个空间,value 会直接进入常量池找、找到就直接指向,找不到重建再指向它,也正是因此 String才会每次更新值 都是在更改地址
当调用 intern 方法时,如果池已经包含一个等于此 String 对象的字符串 (用equals(Object) 方法确定),则返回池中的字符串。否则,将此 String 对象添加到池中,并返回此 String 对象的引用
intern() :方法最终返回的是常量池的地址
字符串的特性:
1.String 是一个 final类,代表不可变的字符序列
2.字符串是不可变的。一个字符串对象一旦被分配,其内容是不可变的
面试题:
String a = "hello" + "abc";//一共创建了几个对象?
// 1个,编译器会自动优化 String a = "helloabc";
//第二题
String a = "hello";
String b = "abc";
String c = a + b;//一共创建了三个对象
//c 会指向 在堆当中创建的value,value再指向常量池中的 "helloabc";
第二题是底层中 StringBuilder sb = new StringBuilder(); sb.append(a); sb.append(b);
sb在堆中,并且append是在原来字符串的基础上追加
重要规则:String c1 = “ab” + “cd”; 常量相加,看的是常量池!
String c1 = a + b; 变量相加,看的是堆!
String类的常见方法:
String类是保存字符串常量的。每次更新都需要重新开辟空间,效率较低。因此java设计者还提供了StringBuilder 和 StringBuffer 来增强String的功能并提高效率
equals:区分大小写,判断内容是否相等
equalslgnoreCase:忽略大小写的判断内容是否相等
length:获取字符的个数,字符串的长度
indexof(x):获取字符/字符串 x 在字符串中第1次出现的索引,索引从0开始,如果找不到,返回-1
lastIndexof(‘x’):获取字符/字符串 x 在字符串中最后1次出现的索引,索引从0开始,如找不到,返回-1
substring:截取指定范围的子串
substring(6):截取6以后的所有字符; substring(0,5):截取0~4的所有字符
trim:去前后空格
charAt:获取某索引处的字符,注意不能使用Strindex] 这种方式
toUpperCase:转大写
toLowerCase:转小写
concat:拼接
replace(a,b):将字符串当中所有的 a 都替换成b
注:比如 s1.replace(“1”,“2”); 当你运行完这句代码,s1本身的内容并不会受影响
split:分割字符串,对于某些分割字符。若出现转义字符,则需要多加 \
String peom = "锄禾日当午,汗滴禾下土,谁之盘中餐,粒粒皆辛苦";
String[] split = poem.split(",");//这样每当遇到 , 逗号 都会自动分割 存进数组split
compareTo:比较两个字符串的大小
toCharArray:把字符串转换成字符数组,前者大返回正数,后者大返回负数。相同返回0
注:源码中将 前str 与 后str 比较字符,一旦比到不同的地方就直接相减。
format:格式字符串,%s 字符串 %c 字符 %d 整型 %.2f 浮点型
注:当你用上 String.format("…") 的时候,双引号中间的写法跟c语言printf 一毛一样
%.2f 会四舍五入
3.StringBuffer类
说明:java.lang.StringBuffer代表可变的字符序列,可以对字符串内容进行增删
很多方法与 String 相同,但 StringBuffer 是可变长度的
StringBuffer 是一个容器
1.StringBuffer 的直接父类是 AbstractStringBuilder
2.StringBuffer 实现了 Serializable, 即 StringBuffer 的对象可以串行化
3.在父类中 AbstractStringBuilder 有属性 char[ ] value,它并不是 final
该 value 数组存放 字符串内容,引出存放在队中的
4.StringBuffer 是一个 final 类,不能被继承
String与StringBuffer的区别:
1.String保存的是字符串常量,里面的值不能更改,每次String类的更新实际上就是更改地址,效率较低 // private final char valuell;
2.StringBuffer保存的是字符串变量,里面的值可以更改,每次StringBuffer的更新实际上可以更新内容,不用每次 更新地址,效率较高//char[ ] value;// 这个放在堆
StringBuffer构造器:
StringBuffer()
构造一个其中不带字符的字符串缓冲区,其初始容量为16个字符
StringBuffer(ChaerSecuence sq)
public java.lang.StringBuilder(ChaerSecuence sq) 构造一个字符串缓冲区,它包含与指定的 ChaerSecuence 相同的字符 // 直接把形参内容放到里面去了,比较少用
StringBuffer(int capacity) //capacity[容量]
构造一个不带字符,但具有指定初始容量的字符串缓冲区。即对 char[ ] 大小进行指定
StringBuffer(String str)
构造一个字符串缓冲区,并将其内容初始化为指定的字符串内容
String 和 StringBuffer 相互转换:
String → StringBuffer
String s = "hello";
//方式1:
StringBuffer b1 = new StringBuffer(s);
//方式2:
StringBuffer b2 = new StringBuffer();
b2.append(s);
StringBuffer → String
//方式1:
String s2 = b1.toString();
//方式2:
String s3 = new String(b1);
StringBuffer类常见方法:
1.增 append
2.删 delete(start, end) :删除 索引>= start && <end 的字符(不包含end) [start,end)
3.改 replace(start,end,string) [start,end) 替换成 string
将 start — end 之间的内容替换掉,不含end
4.查 indexOf 查找子串在字符串第1次出现的索引,如果找不到返回 -1
5.插 insert
6.获取长度 length
4.StringBuilder类
1.一个可变的字符序列。此类提供一个与 StringBuffer 兼容的 AP 但不保证同步(StringBuilder 不是线程安全)。该类被设计用作 StringBuffer 的一个简易替换,用在字符串缓冲区被单个线程使用的时候。如果可能,建议优先采用该类,因为在大多数实现中,它比StringBuffer 要快
2.在 StringBuilder 上的主要操作是 append 和 insert 方法,可重载这些方法以接受任意类型的数据。
StringBuilder 和 StringBuffer 均代表可变的字符序列,方法是一样的,所以使用和StringBuffer一样
StringBuilder常用方法:
1.StringBuilder 继承 AbstractStringBuilder 类
2.实现了 Serializable, 说明 StringBuilder 对象是可以串行化(对象可以网络传输,可以保存文件)
3.StringBuilder 是 final类,不能被继承
4.StringBuilder 对象字符序列仍是存放在其父类 AbstractStringBuilder 的 char[ ] value
5.StringBuilder 的方法,没有做互斥处理,既没有synchronized 关键字,因此在单线程的情况下使用
5.String与StringBuffer、StringBuilder的比较
1.StringBuffer 和 StringBuilder 非常类似,均代表可变的字符序列,而且方法也一样
2.String:不可变字符序列,效率低,但是复用率高(创建之后常量池会一直保留、一需要这个字符串内容、大家都会指向它)
3.StringBuffer:可变字符序列、效率较高(增删)、线程安全(当有一个线程在操作的时候,其他线程不能操作)
4.StringBuilder:可变字符序列、效率最高、线程不安全
5.String使用说明:
String s = “a”;//创建了一个字符串
s += “b”;//实际上原来的"a"字符串对象已经丢弃了、现在又产生了一个字符串s+“b”(也就是"ab")。如果多次执行这些改变串内容的操作,会导致大量副本字符串对象保留在内存中,降低运行效率。如果这样的操作放到循环中,会极大的影响程序性能 → 结论:如果我们对String做大量修改,不要使用String
效率:StringBuilder > StringBuffer > String
6.Math类
常见方法:
1.abs:绝对值
2. pow:求幂
3.ceil:向上取整
4. floor:向下取整
5. round:四舍五入
6. sqrt:求开方
7.random 求随机数
7.Arrays类
1.toString:返回数组的字符串形式 Arrays.toString(arr)
2.sort:排序(自然排序和定制排序) Integer arr[] = {1,-1,7,0,89};
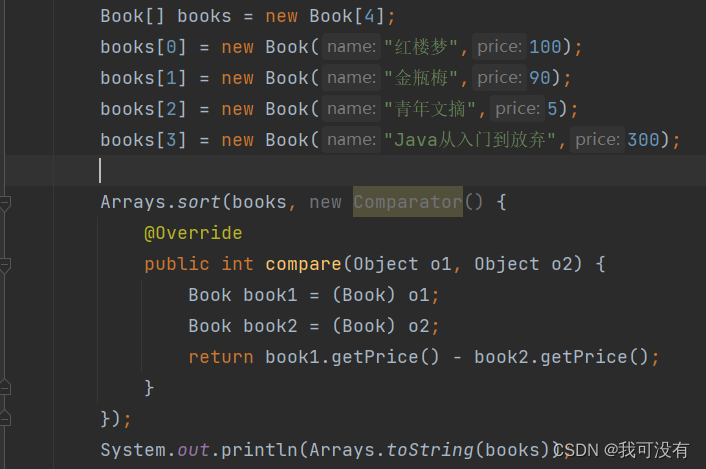
返回值决定排序顺序、可以调换减数和被减数位置调整顺序
3.binarySearch:通过二分搜索法进行查找,要求必须排好序
int index = Arrays.binarySearch(arr,3);
4.copyOf:数组元素的赋值
Integer[] newArr = Arrays.copyOf(arr,arr.length);
5.fill:数组元素的填充
Integer[] num = new Integer[]{9,3,2};
Arrays.fill(num,99);
6.equals:比较两个数组是否完全一致
boolean equals = Arrays,equals(arr,arr2);
7.asList:将一组值,转换成list
ListasList = Arrays.asList(2,3,4,5,6,1);
System.out.println("asList= " + asList);
8.System类
1.exit:退出当前程序
2.arraycopy:复制数组元素,比较适合底层调用,一般使用Arrays.copyOf完成数组赋值
int[] src = {1,2,3,};
int[] dest = new int[3];
System.arraycopy(src,0,dest,0,3);
将 src数组里从索引为0的元素开始,复制到数组dest 索引为5的位置,复制元素为3个
3.currentTimeMillens:返回当前时间距离1970-1-1的毫秒数
4.gc:运行垃圾回收机制 System.gc();
8.BigInteger和BigDecimal
长数值: 导入 java.util.math.* (BigInteger/BigDecimal)
在java中有两个类BigInteger和BigDecimal分别表示大整数类、大浮点数类
BigInteger的计算
9.日期类
第一代日期类
1.Date:精确到毫秒,代表特定的瞬间
2.SimpleDateFormat:格式和解析日期的类
SimpleDateFormat 格式化和解析日期的具体类。它允许进行格式化(日期→文本)、
解析(文本 → 日期) 和规范化
Date d1 = new Date();//读取系统当前时间
`SimpleDateFormat s = new SimpleDateFormat("yyyy年MM月dd日 hh:mm:ss E");`
//初始化你的中文时间格式
String format = s.format(d1);//使用字符串接收,直接输出format字符串
/
String s1 = "1966年1月1日 10:20:30 星期一"
Date parse = s1.parse(s);
输出 s.format(parse);
第二代日期类
Calendar类
Calender存在的问题:
1.可变性::像日期和时间这样的类应该是不可变的。
2.偏移性::Date中的年份是从1900开始的,而月份都从0开始
3.格式化:格式化只对Date有用,Calendar则不行。
4.此外,它们也不是线程安全的; 不能处理闺秒等 (每隔2天,多出1s)
第三代日期类
LocalDate
四、集合、泛型(源码)
这块部分为本人自己记载
集合终极笔记(涵盖了泛型!)
看上面这篇就够了!看上面这篇就够了!看上面这篇就够了!****看上面这篇就够了!
集合的理解和好处:
数组
1.长度开始时必须指定,而且一旦指定,不能更改
2.保存的必须为同一类型的元素
3.使用数组进行增加元素的示意代码 - 比较麻烦
集合:
1.可以动态保存任意多个对象,使用比较方便!
2.提供了一系列方便的操作对象的方法: add、remove、set、get等
3.使用集合添加,删除新元素的示意代码- 简洁了
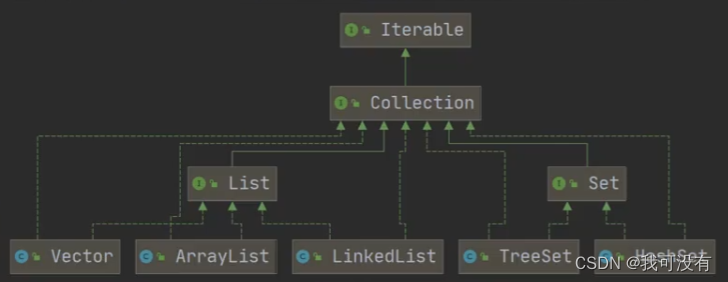
集合主要是两组:单列集合、双列集合
Collection 接口有两个重要的子接口 List set,他们的实现子类都是单列集合
Map 接口的实现子类 是双列集合,存放的 K-V
集合体系框架图
**单列集合:**添加数据每次只能添加一个元素
**双列集合:**添加数据每次添加两个元素
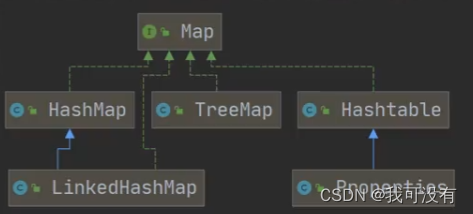
1.Collection接口和常用方法
1.collection实现子类可以存放多个元素,每个元素可以是Obiect
2.有些Collection的实现类,可以存放重复的元素,有些不可以
3.有些Collection的实现类,有些是有序的(List),有些不是有序(Set)
4.Collection接口没有直接的实现子类,是通过它的子接口Set 和 List 来实现的
常用方法:
1.add:添加单个元素
2.remove:删除指定元素
3.contains:查找元素是否存在
4.size:获取元素个数
5.isEmpty:判断是否为空
6. clear:清空集合中所有元素
7.addAll:添加多个元素
8.containsAll:查找多个元素是否都存在
9.removeAll: 删除多个元素
10.说明:Collection接口不能实例化 通常以子类ArrayList实现来写
Collection接口遍历元素方式1 - 使用Iterator(迭代器)
1.Iterator对象称为迭代器,主要用于遍历 Collection 集合中的元素
2.所有实现了Collection接口的集合类都有一个iterator0方法,用以返回一个实现了lterator接口的对象,即可以返回一个迭代器
3.lterator 的结构:
4.Iterator 仅用于遍历集合,lterator 本身并不存放对象
ctrl + j 显示所有快捷键的快捷键
迭代器的使用:
Collection col = new ArrayList();//向下转型
col.add(new Book("三国演义","罗贯中",10.1));
col.add(new Book("4399","小王",18.1));
col.add(new Book("7k7k","小陈",9.5));//增加数据内容
Iterator iterator = col.iterator();//得到 col 对应的迭代器
while(iterator.hasNext()){//快捷键 itit回车
//hasNext会自动检测下一个元素,如果下一个位置为空返回false。停止循环
Object obj = iterator.next();//返回一个元素,类型是Object
//编译类型是Object 但是运行类型取决于你添加内容的时候的类 此处为Book
System.out.println(obj);}
当你退出while循环后,此时iterator迭代器,指向最后的元素
如果你还想再次遍历,需要重置迭代器,iterator = col.iterator();
for循环增强:
增强for循环的底层仍然是迭代器,快捷键:大写 I 回车
增强for循环,可以代替iterator迭代器,特点: 增强for就是简化版的iterator本质一样。只能用于遍历集合或数组。
语法:
for(元素类型 元素名: 集合名或数组名){
访问元素}
2.List接口和常用方法
List 接口是 Collection 接口的子接口 List .java
1.List集合类中元素有序(即添加顺序和取出顺序一致)、且可重复添加相同元素、有索引
2.List集合中的每个元素都有其对应的顺序索引,即支持索引,跟数组差不多意思
3.List容器中的元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素。
4.JDK API中List接口的实现类常用的有: ArrayList、LinkedList 和 Vector
常用方法:
1. void add(int index, Object ele):在index位置插入ele元素
2.boolean addAll(int index, Collection eles):从index位置开始将eles中的所有元素添加进来,不加索引默认加最后
3.Object get(int index):获取指定index位置的元素
4.int indexof(Object obj):返回obj在集合中首次出现的位置
5.int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置
6.Object remove(int index):移除指定index位置的元素,并返回此元素
7.Object set(int index, Object ele):设置指定index位置的元素为ele相当于是替换
8.List subList(int fromIndex, int tolndex):返四从fromIndex到8)tolndex位置的子集合
List的三种遍历方式:
1.方式一: 使用iterator
2.方式二: 增强for
3.方式三: 普通for
3.ArrayList底层结构和源码:
1.permits all elements, including null , ArrayList 可以加入null,并且多个
2.ArrayList 是由数组来实现数据存储的
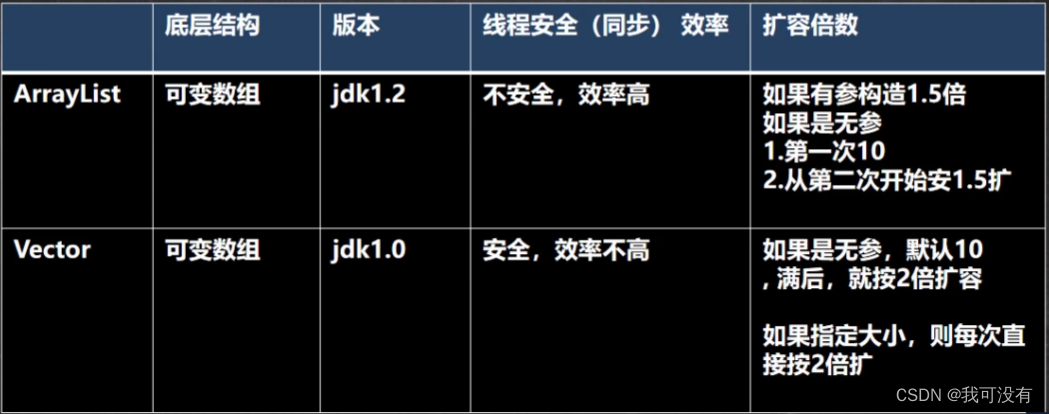
3.ArrayList 基本等同于Vector,除了 ArrayList是线程不安全(执行效率高)看源码在多线程情况下,不建议使用ArrayList
ArrayList扩容机制:
1.ArrayList中维护了一个Object类型的数组elementData[] 由于是Object所以什么类型都能放.
transient Object[] elementDate::transient 表示瞬间、短暂的,表示属性不会被序列化
2.当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0,第1次添加,则扩容elementData为10,如需要再次扩容,则扩容elementData为1.5倍。
3.如果使用的是指定大小的构造器,则初始elementData容量为指定大小,如果需要扩容则直接扩容elementData为1.5倍
注:
底层源码当中,将旧容量加上就容量右移 1 位。比如10的二进制 1010 右移变成 0101 也就是5 此时,数组等于扩容了1.5倍但并不是第一次就采用扩容机制
可以追溯到ArrayList 的 grow 方法当中查看扩容源码
在源码中最后使用了 Arrays.copyOf 来达成赋值,这个方法会保留原来数组中存在的元素

Debug测试源码过程可以到设置当中,Java 把 Enable alternative view... 选线取消打勾 Hide null elements 是看隐藏的空数组也取消
4.Vector基本介绍和源码
1.Vector底层也是一个对象数组,protected Object[] elementDate;
2.Vector是线程同步的,即线程安全,Vector类的操作方法带有 synchronized 它代表支持线程同步
3.在开发中,需要线程同步安全时,考虑使用Vector
Vector和ArrayList的比较
源码中实现扩容的语句

5.LinkedList底层结构
1.LinkedList底层实现了双向链表和双端队列特点
2.可以添加任意元素(元素可以重复),包括null
3.线程不安全,没有实现同步
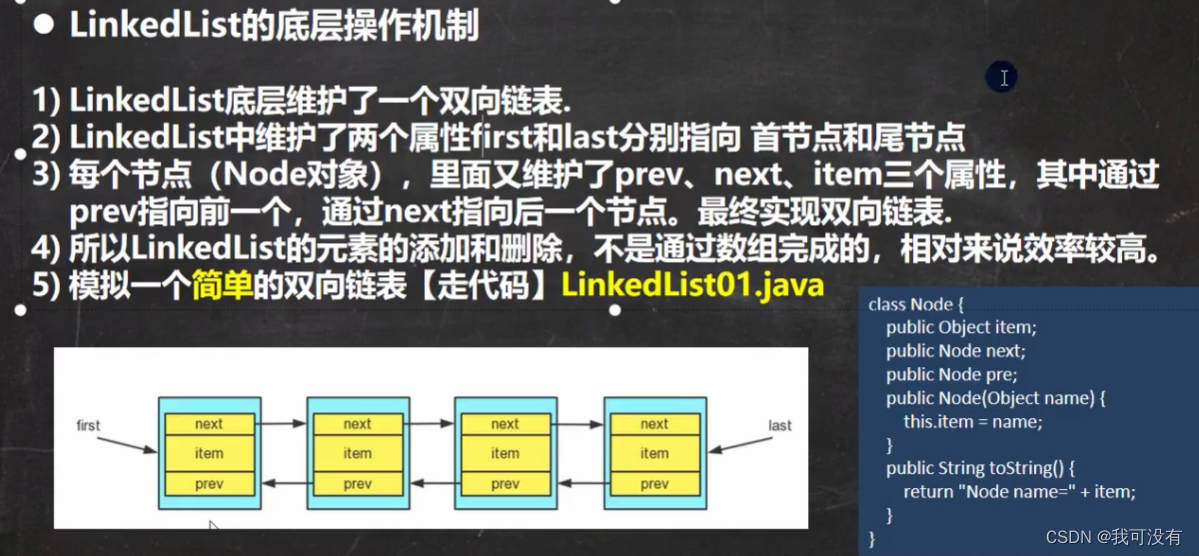
源码当中的逻辑就是一个双向链表、可以看源码或者去学习一下数据结构
ArrayList和ArrayList的比较
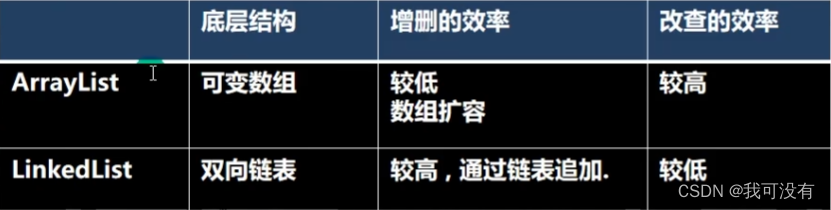
如何选择ArrayList和LinkedList:
1.如果我们改查的操作多,选择ArrayList
2.如果我们增删的操作多,选择LinkedList
3.一般来说,在程序中,80%-90%都是查询,因此大部分情况下会选择ArrayList
4.在一个项目中,根据业务灵活选择,也可能这样,一个模块使用的是ArrayList,另外一个模块是LinkedList.
5.set接口
接口实现类:HashSet
1.无序(添加和取出的顺序不一致),不重复,没有索引。实际上它是按照哈希值来排序存放位置的
排完之后位置就确定下来了
2.不允许重复元素,所以最多包含一个null
遍历方式:
同Collection的遍历方式一样,因为Set接口是Collection接口的子接口
1.可以使用迭代器
2.增强for
3.不能使用索引的方式来获取
6.HashSet的全面说明💢
1.HashSet实现了Set接口
2.HashSet实际上是HashMap 源码:
public HashSet(){
map = new HashMap<>();}
3.可以存放null值,但是只能有一个null
4.HashSet不保证元素是有序的(添加和取出的顺序不一致),取决于hash后,再确定索引的结果
5.不能有重复元素/对象在前面Set 接口使用已经讲过
Hashset可以存放null、但是只能有一个null、即元素不能重复
HashMap的底层机制说明:
HashSet的添加元素底层实现:(hash() + equals())
 解析:当你添加元素、会先得到hash值将其转换成索引。之后到表中存放,看看
解析:当你添加元素、会先得到hash值将其转换成索引。之后到表中存放,看看表中这个位置有没有一样的元素。如果有一样的元素、那就使用equals比较。至于是比较地址还是比较值、那是取决于程序员有没有重写。假如元素equals相同那就放弃添加,如果不相同、但是索引值相同,那就添加然后放到原先元素的后面,就是一张邻接表的样子。
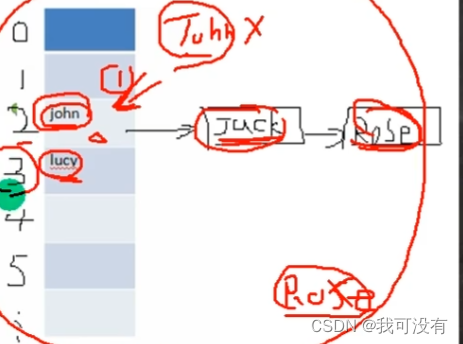
当你每一个链表的元素到达了8个、同时你整张表的元素也到达了64个。此时表会扩容
实际写代码的时候,如果你想触发内容相同就不给存放的话。在信息类里面右键 Generate equals() and hashCode();
这个选项表明:
第一次选:当XXX属性(你选择的属性)值相同,在使用equals的时候返回true
第二次选:当XXX属性(你选择的属性)值相同,在计算hashCode()时返回相同结果
直接new三个对象放进HashSet 由于hashcode不同、所以一定都能存放进去的!当你重写equals和hashcode之后,那只要相同就放不进去了。只有值不同但是hashcode相同的时候才能放进去
HashMap源码当中 putVal()方法当中的💢:

其中 (n - 1) & hash等于 hash % n 它所产生的值就是指示你的key放在table的哪个位置的。hashCode()方法里面只是给你一个hashcode值
整个代码是将链表当中这个下标位置内是否等于空、如果是空的那就可以直接放入,如果不是空的,那么就需要去对比 key 和 hash值 是否相同了,如果相同的话
7.LinkedHashSet
1.LinkedHashSet 是 HashSet 的子类
2.LinkedHashSet 底层是一个LinkedHashMap,底层维护了一个数组 + 双向链表
3. LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,同时使用链表维护元素的次序,这使得元素看起来是以插入顺序保存的.
4. LinkedHashSet 不允许添重复元素
说明:
1.在LinkedHastSet 中维护了一个hash表和双向链表( LinkedHashSet 有 head 和 tail )
2.每一个节点有 pre 和 next 属性,这样可以形成双向链表
3.在添加一个元素时,先求hash值,在求索引,确定该元素在hashtable的位置,然后将添加的元素加入到双向链表(如果已经存在,不添加
[原则和hashset一样])
tail.next = newElement // 简单指定
newElement.pre = tail
tail = newEelment; (tail是尾节点指针,画图比较复杂所以就叫它指针吧)
4.这样的话,我们遍历LinkedHashSet 也能确保插入顺序和遍历顺序一致 (还得是双向链表)
5.第一次添加数据,会直接把数组table 扩容到 16,存放的节点类型还是LinkedHashiMap$Entry。但是你debug的时候就会发现数组table实际上是HashMap $Entry类型。那究竟凭什么呢?因为他们两是继承关系
你在源码当中可以看到 这个 Entry 继承了 Node。方法当中还有两个变量before,after 这两个就是指向前后的两个指针。
8.Map接口
Map map = new HashMap();
map.put("","");传入 map.get("key");根据key搜索value
注:此处指的是JDK8(市面上最多的版本)的Map接口特点
1.Map用于保存具有映射关系的数据:Key-(Value)指的是HashMap里面方法需要的第二个参数,也可以看map.put() 这个put方法的源码
2.Map 中的 key 和 value 可以是任何引用类型的数据,会封装到HashMap$Node
map这个数组本身也就是 HashMap $Node类型
对象中
3.Map 中的 key 不允许重复,原因和HashSet 一样,去看源码
4.Map 中的 value 可以重复,本身这个值的存在就没什么意义
5.Map 的key 可以为 null,value 也可以为null ,注意 key只能有一个为null。value可以有多个为null
6.常用String类作为Map的 key
7.key 和 value 之间存在单向一对一关系,即通过指定的 key 总能找到对应的 value
8.用相同的key 不同的value添加到map当中,value是会被替换的、
可以理解为value只是一个附加的数据内容、它有一个配套的key
key 和 value 都是Object类型、你也不是非要字符串才行
Map接口的特点:
Map存放数据的 key - value 示意图, 一堆K-V是放在一个HashMap$Node中的,又因为Node实现了 Entry接口,有些书上也说,一个对K-V就是一个Entry
五、项目界面的设计
由于Java主要针对于服务器、后端开发。很少会用到窗口设计和用户直接接触。
所以直接引入同站链接提供学习
程序窗口设计
六、File
难点在于学会灵活运用集合、File方法来达成你的需求、包括一些引用类型的方法。建议多找一些题目来写
File对象就表示一个路径、可以是文件的路径、也可以是文件夹的路径
这个路径可以是存在的、也允许是不存在的
常见方法:

//1.根据字符串表示的路径,变成File对象
String str = "C:\\Users\\alienware\\Desktop\\a.txt";
File fl = new File(str);
System.out.println(f1);//C: Users alienware Desktopla.txt
//2.父级路径: C: Users\alienware\Desktop
//子级路径: a.txt
String parent ="C:\\Users\\alienware\\Desktop":String child = "a.txt";
File f2 = new File(parent,child);
System.out.println(f2);//C: Users alienware Desktop a.txt
File f3 = new File( pathname: parent + "\\" + child);
System.out.println(f3);//C: Users alienware Desktopla.txt
//3.把一个File表示的路径和string表示路径进行拼接
File parent2 = new File(pathname:"C:\\Users\\alienware\\Desktop");
String child2 = "a.txt";
File f4 = new File(parent2,child2);
System,out.println(f4);//C: Users alienware Desktopla.txt
七、IO流(随用随创建、用完即关)
File 表示系统中的文件或者文件夹的路径
File类只能对文件本身进行操作,不能读写文件里面存储的数据
IO流 用于读写文件中的数据(可以读写文件、或网络中的数据…)
I: input ; O: output
流: 像水流一样传输数据
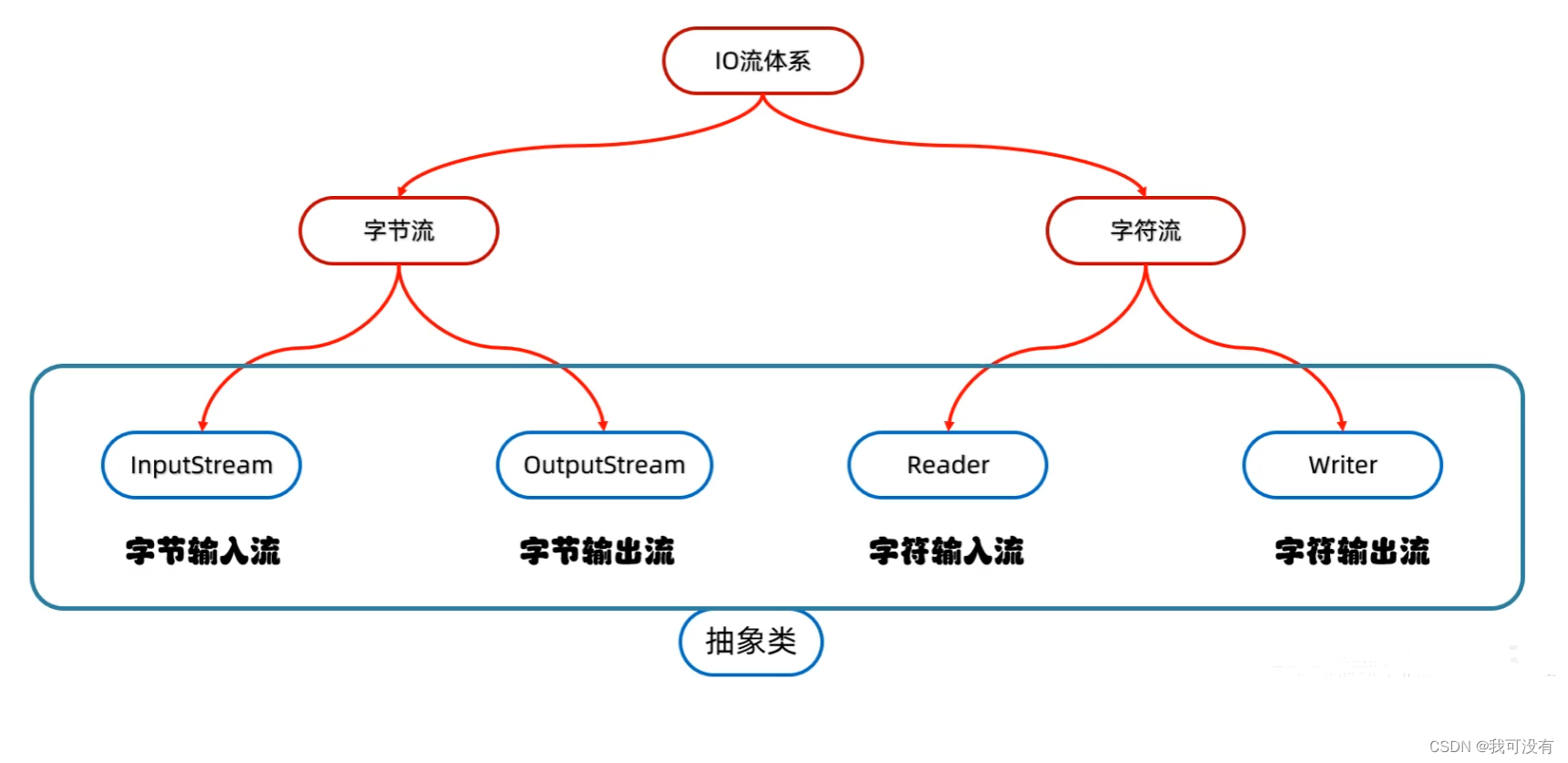
IO流分类:
IO流按照流向有两种:
输出流: 程序 → 文件
输入流: 文件 → 程序
IO流按照操作文件类型有两种:
字节流:可以操作所有类型的文件
字符流:可以操作纯文本类型的文件
注: 纯文本文件指Windows自带记事本打开能够读懂的文件!
如:txt 、md 、xml 、lrc
1.FileOutputStream
可以右键文件、split and move right
操作本地文件的字节输出流、可以把程序中的数据写到本地文件中
步骤:
①: 创建字节输出流对象
参数是字符串表示的路径或File对象都可以!
如果文件不存在会创建一个新的文件、但是要保证父级路径是存在的!
如果文件已经存在、则会清空文件!
②: 写数据
write方法的参数是整数,但实际上写到文件当中的是ASCII上对应的字符
③: 释放资源
每次使用完流之后都要释放资源! 不释放会被程序占用,导致你无法操作该文件
FileOutputStream常用方法:
创建String对象 写入内容,传输到byte[ ]数组里面,然后调用write
换行:windows \r\n ; Linux \n ; Mac \r
只需要在你想要换行的语句后面写就行、即使你只写入\r或者\n 系统都会自动补全
续写:
在底层源码中由一个变量来决定是否续写,
默认是 false 关闭状态,此时创建对象会清空文件
可以在创建文件输出流的时候第二个参数写上 true ,不会清空,这样就能够继续续写!
2.FileInputStream
操作本地文件的字节输入流、可以把本地文件中的数据读取到程序中来
书写步骤:
①: 创建字节输入流对象
文件不存在就直接报错
②: 读数据
read():读到文件末尾了、返回-1(如果最后一个数字是-1,它会先读取符号,再读取1) 、这个方法读取完一次数据会移动一次指针到下一个字符
一次都一个字节、读出来的数据在ASCII上对应的数字
③: 释放资源
常用方法:

循环读取
//一次读取一个字符的 循环读取代码
FileInputStream fip = new FileInputStream("D:\\Java\\project\\day2\\a.txt") ;
int b;
while((b = fip.read()) != -1){
System.out.print((char)b);
}
fip.close();
//一次读取多个字符的 循环读取代码
FileInputStream fip = new FileInputStream("D:\\Java\\project\\day2\\a.txt") ;
byte[] bytes = new byte[2];
int len = fis.read(bytes);//返回打印了多少个字符
String str = new String(bytes);
System.out.println(str);//用String读取字符输出
fis.close;
重复使用这段代码,指针会继续向后读写,并不会重置
使用数组一次读取多个字节数据、具体读取多少跟数组长度有关!
fis.read(bytes)的返回值:本次读取到了多少个字节数据
3.文件的拷贝
通常先开的资源最后关闭!
小文件拷贝:
FileInputStream fip = new FileInputStream("D:\\Java\\project\\day2\\a.txt") ;
FileOutputStream fop = new FileOutputStream("D:\\Java\\project\\day2\\b.txt");
int b;
while((b = fip.read()) != -1){
fop.write(b);
}
fop.close();
fip.close();
大文件拷贝:
FileInputStream fip = new FileInputStream("D:\\Java\\project\\day2\\a.txt") ;
FileOutputStream fop = new FileOutputStream("D:\\Java\\project\\day2\\b.txt");
int len;
byte[] bytes = new byte[1024 * 1024 * 5];//5M每秒传输
while((len = fip.read(bytes)) != -1){
fop.write(bytes,0,len);//从0开始到传进来给的长度结束
//是避免到末尾的时候传进来多余的内容
}
fop.close();
fip.close();
4.字符集详解
欧美ASCII码规则

中国GBK

1.在计算机中,任意数据都是以二进制的形式来存储的
2.计算机中最小的存储单元是一个字节
3.ASCII字符集中,一个英文占一个字节
4.简体中文版windows,默认使用GBK字符集
5.GBK字符集完全兼容ASCII字符集
①: 一个英文占一个字节,二进制第一位是0
②: 一个中文占两个字节,二进制高位字节的第一位是1
Unicode: 万国码
unicode编码规则: 中文在unicode当中占三个字节 即三个2进制8位数
UTF-8 不是字符集、只是一种编码方式!

1.Unicode字符集的UTF-8编码格式
一个英文占一个字节,二进制第一位是0,转成十进制是正数
一个中文占三个字节,二进制第一位是1,第一个字节转成十进制是负数
产生乱码的原因:
1:读取数据时未读完整个汉字(不要用字节流读取文本文件,它一次只获取一个字节!)
2: 编码和解码的方式不同意(编码解码时使用同一个码表,同一个编码方式)
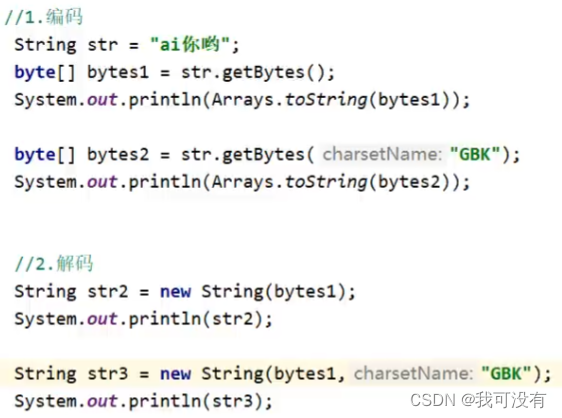
Java中编码的方法:

Java中解码的方法:

GBK 和 UTF-8的区别:
IDEA默认: UTF-8中的中文是三个字节
eclipse默认: GBK中的中文是两个字节
5.字符流
字符流的底层就是字节流
字符流 = 字节流 + 字符集
特点:
输入流: 一次读一个字节,遇到中文时,一次读多个字节
输出流: 底层会把数据按照指定的编码方式进行编码,变成字节再写到文件中
6.FileReader
①: 创建字符输入流对象
②: 读取数据

1: 按字节进行读取,遇到中文,一次读多个字节,读取后解码,返回一个整数
2: 读到文件末尾了,read方法返回-1。
③: 释放资源
read () 细节:
1.read():默认也是一个字节一个字节的读取的,如果遇到中文就会一次读取多个
2.在读取之后,方法的底层还会进行解码并转成十进制。
最终把这个十进制作为返回值
这个十进制的数据也表示在字符集上的数字
英文:文件里面二进制数据 01100001
read方法进行读取,解码并转成十进制97
中文: 文件里面的二进制数据 11100110 10110001 10001001
read方法进行读取,解码并转成十进制27721
包括回车换行也能自动读取
如果想看到中文汉字,就必须把这些十进制强转成 char类型
7.FileWriter
常用方法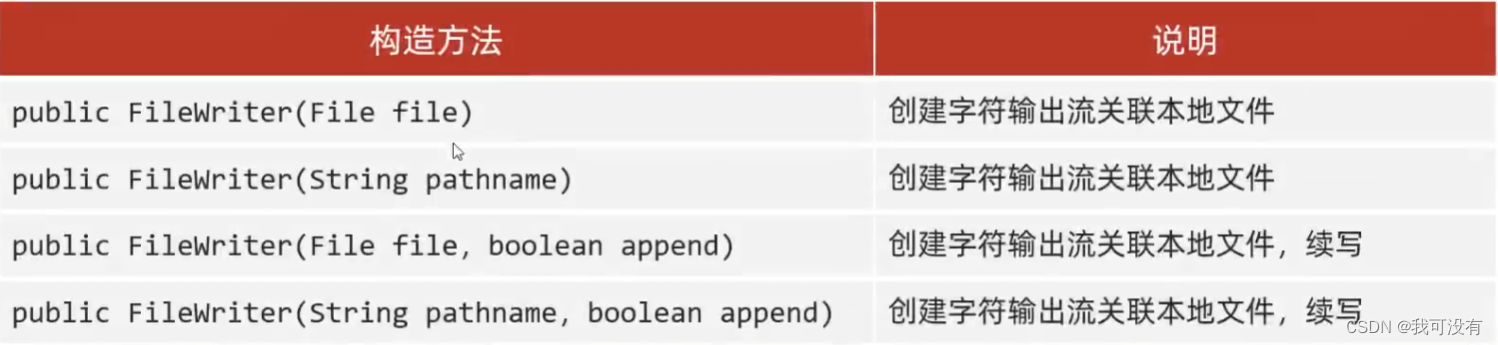
与FileOutputStream一样、会自动清空, 也可以靠第二个参数输入true来打开续写
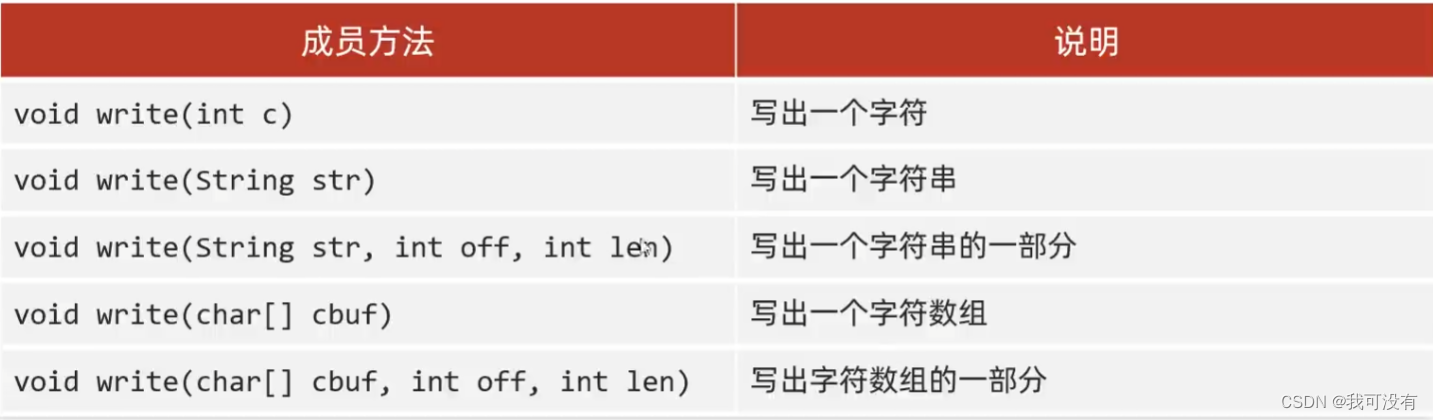
步骤:
①: 创建字节输出流对象
参数是字符串表示的路径或File对象都可以!
如果文件不存在会创建一个新的文件、但是要保证父级路径是存在的!
如果文件已经存在、则会清空文件!不想清空可以打开续写开关
②: 写数据
write方法的参数是整数,但实际上写到文件当中的是字符集上对应的字符
③: 释放资源
每次使用完流之后都要释放资源! 不释放会被程序占用,导致你无法操作该文件
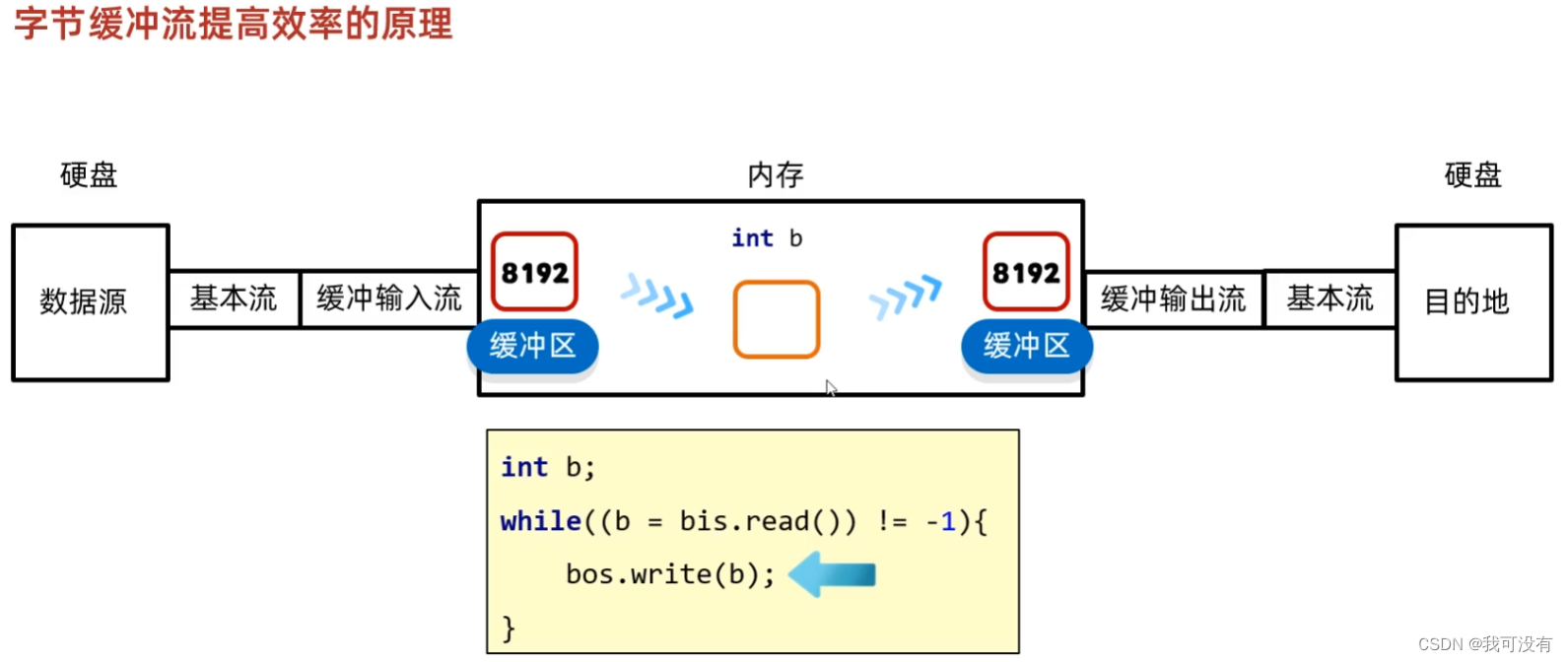
8.BufferedInputStream

常用方法:

原理:底层自带了长度为8192的缓冲区提高性能
//1.创建缓冲流的对象
BufferedInputStream bis = new BufferedInputStream(new FileInputStream( name: "myiola,txt"));BufferedoutputStream bos = new BufferedoutputStream(new,Fileoutputstream( name: "myiollcopy,txt"));//2.循环读取并写到目的地
int b;
while ((b = bis.read()) != -1) [bos.write(b);
//3.释放资源
bos.close();
bis.close();
字节缓冲流提高效率的原理
9.BufferedReader
字符缓冲流的构造方法:

readline()方法在读取的时候、一次读一整行,遇到回车换行结束,但他不会把回车换行读到内存当中

xx.newLine() 任何平台使用都可以换行
缓冲流四种:

缓冲流提高性能主要是因为它拥有8192的字符缓冲区,
在创建FileWriter对象时如果有数据会先清空数据
字节缓冲流是用来拷贝文件的!它每次都只能读取一个字节,没有办法高效处理文本当中的中文。只能用数组来高效拷贝文件。想要在IDEA控制台当中输出中文,必须将字节流转换为字符流并指定正确的输出编码!
10.转换流
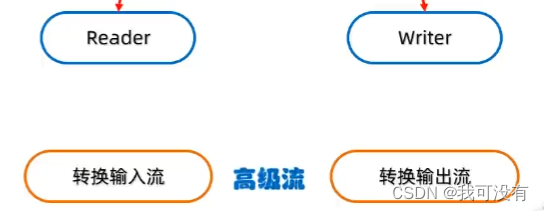
是字符流和字节流之间的桥梁
在IDEA当中调用不同编码的文本:(JDK11以后)
FileReader fr = new FileReader("a.txt",Charset.forName("GBK"));
字符转换输入流:InputStreamReader
字符转换输出流: OutputStreamWriter
字符缓冲流的作用比较:
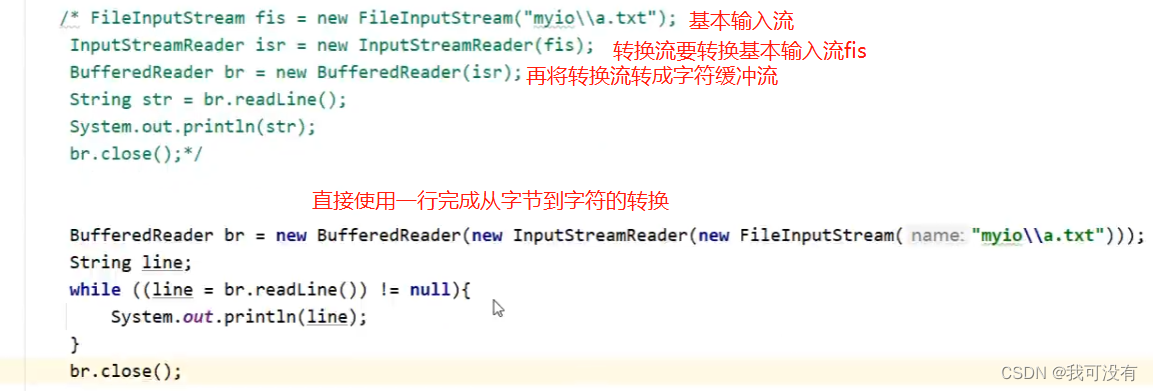
作用是:当你的字节流想要使用字符流中的方法,比如字符流当中的读取readLine();
11.序列化流与反序列化流
ObjectInputStream:
ObjectOutputStream:
可以把Java中的对象写道本地文件中
序列化流:


注:
对象在序列化前,需要将类接入 Serializable接口。此接口没有抽象方法,称之为标记型接口一旦实现了这个接口就表示当前的Student类可以被序列化
反序列化流:


序列化流的注意细节:
当你序列化一个类的时候,底层会根据类当中的构造方法、静态方法、成员去计算出一个long类型的序列号
当你创建对象的时候,也会带着这个序列号。当你把它序列化,序列号也会跟着一起到文本当中。但是!当你在这个时候对类当中的内容作出修改的时候,序列号就会更变。此时你想要进行反序列化就会报错!
因此: 我们可以在定义类的时候就定义好序列号: serialVersionUID是不可改变的!
private static final long serialVersionUID = 1L;
1.使用序列化流将对象写到文件时,需要让Javabean类实现Serializable接口。否则,会出现NotSerializableException异常
2.序列化流写到文件中的数据是不能修改的,一旦修改就无法再次读回来了
3.序列化对象后,修改了Javabean类,再次反序列化,会不会有问题?
会出问题,会抛出InvalidclassException异常解决方案:给Javabean类添加 serialVersionUID(序列号、版本号)
4.如果一个对象中的某个成员变量的值不想被序列化,又该如何实现呢?
解决方案:给该成员变量加transient关键字修饰,该关键字标记的成员变量不参与序列化过程
当你不知道你的序列化文件当中创建了几个对象的时候。该如何去反序列化呢?
可以创建 ArrayList 数组,把你所有的对象都add进去,然后直接序列化数组。当你反序列化的时候,也是直接反序列化数组,然后用增强for循环打印出来!
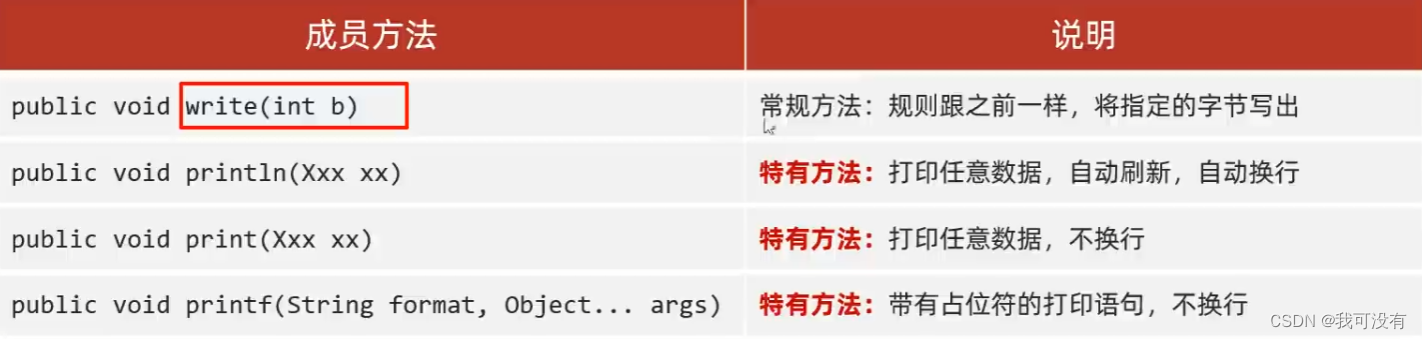
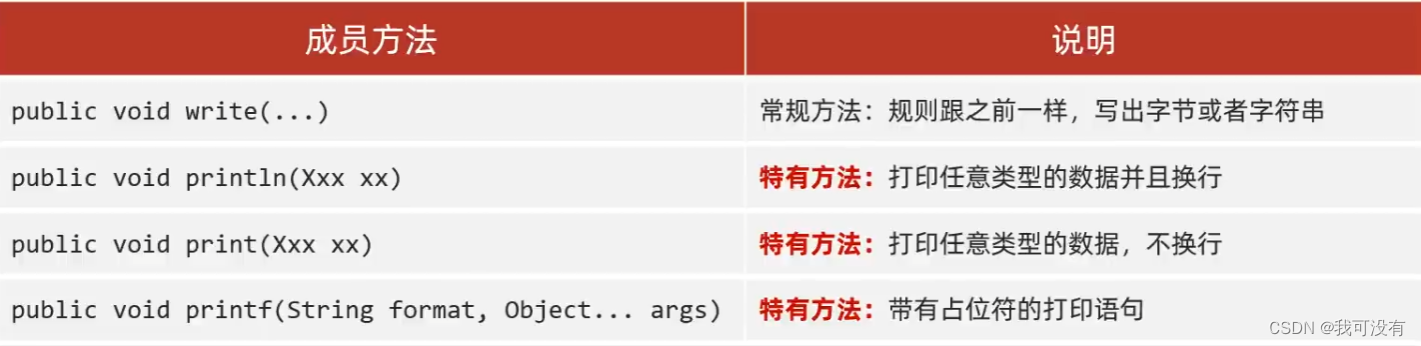
13.打印流

分类: 打印流一般指的是:PrintStream,PrintWriter(只有输出)
特点:
①: 打印流只操作文件目的地,不操作数据源
②: 特有的写出方法可以实现,数据原样写出
如: 打印:97 文件中:97 ; 打印:true 文件中:true
③: 特有的写出方法,可以实现自动刷新,自动换行
打印一次数据 = 写出 + 换行 + 刷新
字节打印流方法:

字节流底层没有缓冲区,开不开自动刷新都一样
占位符那条方法,写法跟C语言的输出一样
关于println()形参autoflush自动刷新的意义,贴一条GPT的回复
字符打印流方法:

打印流最简单的例子:
System.out.println(); 这是一条链式编程,System是系统定义好的类,out是定义好的静态变量。println就是打印流方法!
14.解压缩流和压缩流
Java只能识别 zip 格式压缩包

解压缩流
File src = new File("E:\\aaa.zip");//要解压的压缩包
File dest = new File("E:\\");//解压目的地
//获取要压缩的对象
ZipInputStream zip = new ZipInputStream(new FileInputStream(src));
ZipEntry entry;
while((entry = zip.getNextEntry())!=null){
System.out.println(entry);//打印压缩包中所有文件名
if(entry.isDirectory()){//是否是文件夹
File file = new File(dest,entry.toString());//第一个:父目录;第二:子目录
file.mkdirs();//它会同时创建该文件所在路径的所有缺失的父目录
}else{
FileOutputStream fos = new FileOutputStream(new File(dest,entry.toString()));
int b;
while((b = zip.read())!=-1){
fos.write(b);
}fos.close();
zip.closeEntry();
}
} zip.close();
压缩流
File src = new File("E:\\aaa\\a.txt");//要压缩的文件
File dest = new File("E:\\");//压缩目的地
ZipOutputStream zop = new ZipOutputStream(new FileOutputStream(new File(dest,"a.zip")));//第一个:父目录;第二:子目录
ZipEntry entry = new ZipEntry("a.txt");//参数:压缩包里面的路径
zop.putNextEntry(entry);//输入条目
FileInputStream fis = new FileInputStream(src);//读取文件内容
int b;
while ((b = fis.read())!=-1){
zop.write(b);
}
zop.closeEntry();
zop.close();
15.Commons-io
开源工具包,提高IO流开发贷率。
使用步骤:

学完前面的基础逻辑来看工具包很容易、工具包都是静态方法,类名直接调用就好。
Hutool工具包~
八、多线程
这块部分为本人自己记载
多线程详解
九、网络编程
这块部分为本人自己记载
网络编程
















 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









