






python2.7中实现中文分词,是引入了jieba中文分词库。再进行简单的词频统计。
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import jieba
import jieba.analyse
import xlwt #写入Excel表的库
if __name__=="__main__":
wbk = xlwt.Workbook(encoding = 'ascii')
sheet = wbk.add_sheet("wordCount")#Excel单元格名字
word_lst = []
key_list=[]
for line in open('test.txt'):#test.txt是需要分词统计的文档
item = line.strip('\n\r').split('\t') #制表格切分
# print item
tags = jieba.analyse.extract_tags(item[0]) #jieba分词
for t in tags:
word_lst.append(t)
word_dict= {}
with open("wordCount.txt",'w') as wf2: #打开文件
for item in word_lst:
if item not in word_dict: #统计数量
word_dict[item] = 1
else:
word_dict[item] += 1
orderList=list(word_dict.values())
orderList.sort(reverse=True)
# print orderList
for i in range(len(orderList)):
for key in word_dict:
if word_dict[key]==orderList[i]:
wf2.write(key+' '+str(word_dict[key])+'\n') #写入txt文档
key_list.append(key)
word_dict[key]=0
for i in range(len(key_list)):
sheet.write(i, 1, label = orderList[i])
sheet.write(i, 0, label = key_list[i])
wbk.save('wordCount.xls') #保存为 wordCount.xls文件 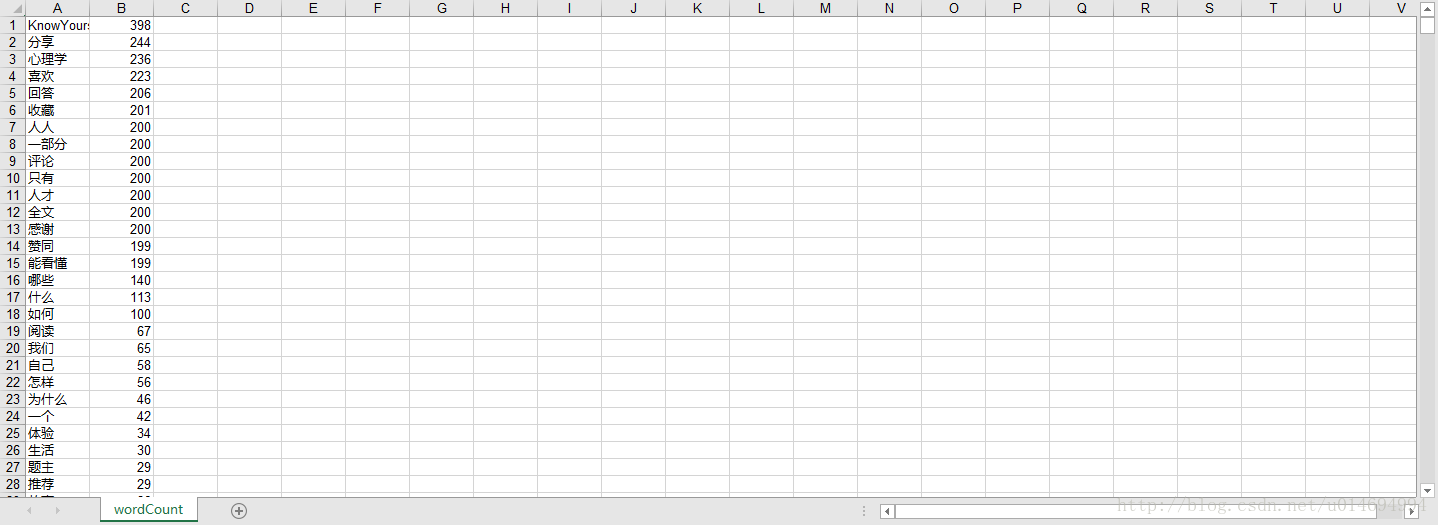
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









