







 本文演示如何使用Spark Streaming从Kafka中实时消费订单数据,计算订单总数和GMV。通过监听数据库变化并发送到Kafka,Spark Streaming消费并汇总信息,最后在控制台展示实时统计结果。
本文演示如何使用Spark Streaming从Kafka中实时消费订单数据,计算订单总数和GMV。通过监听数据库变化并发送到Kafka,Spark Streaming消费并汇总信息,最后在控制台展示实时统计结果。
前言
在双十一这样的节日,很多电商都会在大屏幕上显示实时的订单总量和GMV总额。由于订单数量巨大,不可能每隔一秒就到数据库里进行一次SQL的数据统计,这时候就需要用到流式计算。本文将介绍一个简单的Demo,讲解如何通过Spark Stream消费来自Kafka中订单信息,然后计算订单的数量和金额。
总体流程
一个完整的流程大概如下图所示。
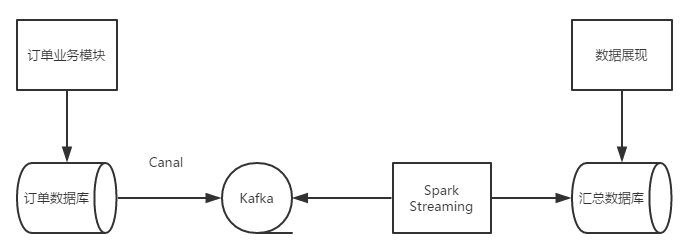
用户下单之后,一笔订单信息会被订单模块写入到关系数据库中,通过监听binlog的变化(可以通过Canal实现),可以解析出数据库的变化,并把刚才刚才新产生的记录写入到kafka的消息队列中。Spark Streaming作为kafka的的一个消费端从卡夫卡中读取订单数据,汇总计算订单的总量和金额的总和,写入到一个特定的汇总数据库中,数据展现层代码从汇总数据库中读取汇总数据进行实施的订单量和GMV总量的展示。
在这个例子中,为了简单起见,会直接写一个Kafka的Producer程序直接往kafka中发送订单信息,同时也把写入汇总数据库的动作用System.out.println来代替(进而也就没有 数据展现层的代码了)
代码实现
首先实现一个Order类来表示一笔订单,在这个Demo中,Order类非常简单,就是两个字段(name,price),分别表示订单中商品的名称和价格。
public class Order {
private String name;
private Float price;
public Order() {
}
public Order(String name, Float price) {
this.name = name;
this.price = price;
}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









