







LAS 模型有 encoder , decoder 两部分组成,encoder 部分主要用来听,decoder部分 输出听到的东西。
一,LAS的模型架构
- 0,input
LAS输入的acoustic features 可以采用MFCC,也可以直接 采用 filter bank。
由于语音数据量较大,冗余度较高,为了提高效率,acoustic features在进LAS之前需要先做 down sampling,具体可以采用如下2种做法:
1)直接利用 pyramid RNN 或者 pooling over time 对 语音数据做down sampling,其结构如下:
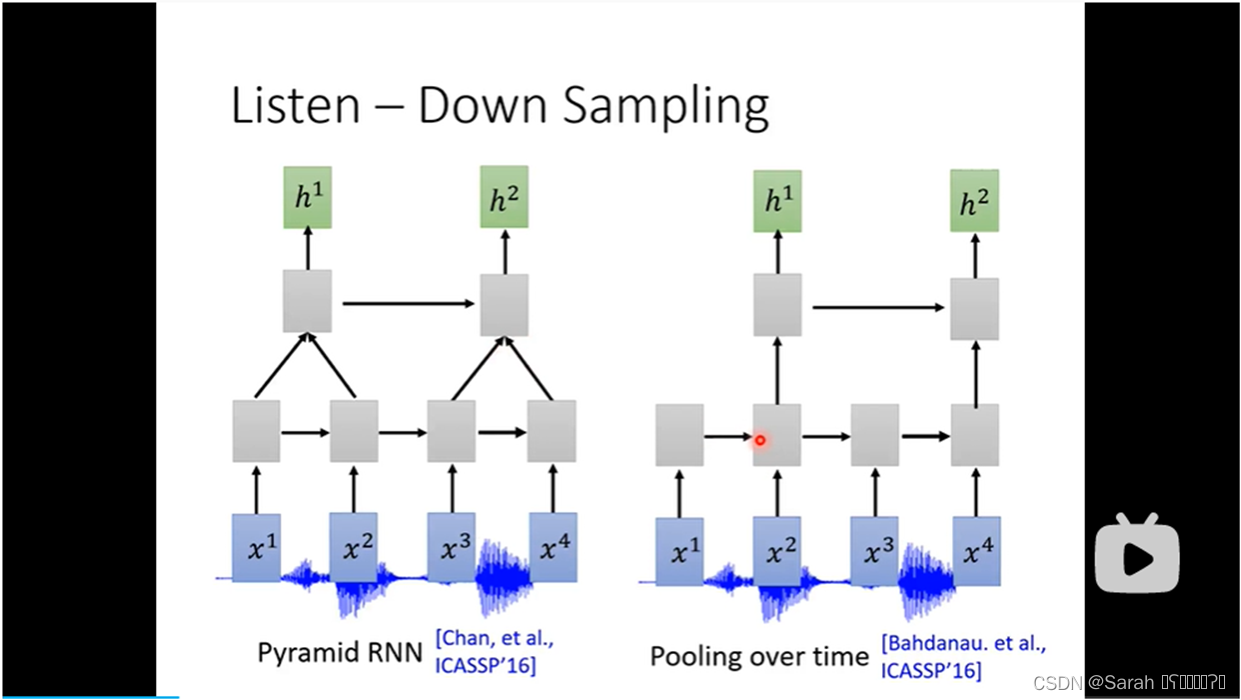
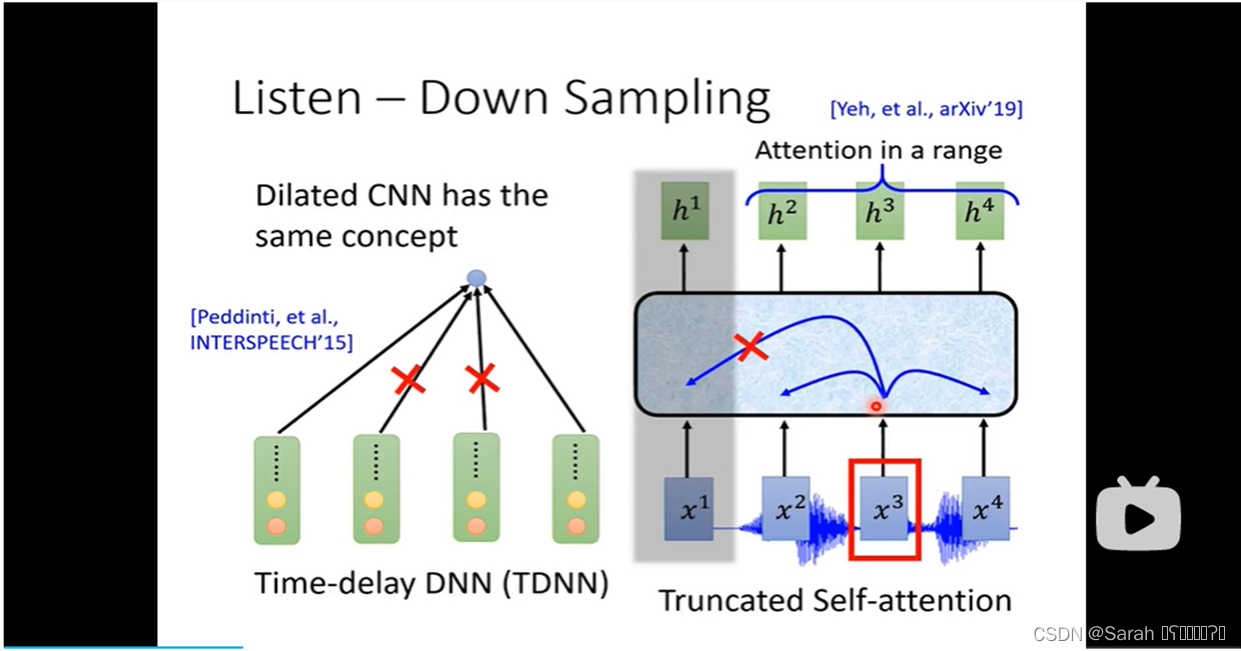
2)用Time-delay DNN(也即: Dilated CNN) 做 down sampling,其具体做法是,用filter计算output时,其input只采用 第一个 和 最后一个 features,而忽略其他 中间的features,以此达到简化计算的效果。
3)用 truncated self-attention 来做 down sampling,其实质是,instead of 用whole sequence做attention,其只采用 local features 做 attention,即 attention in a range。
2),3)结构如下:
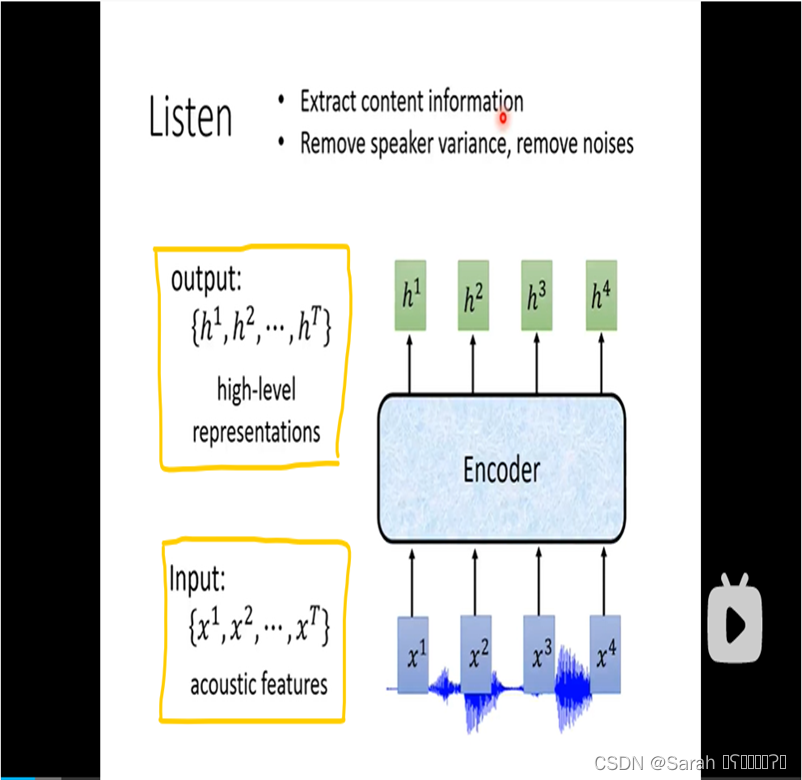
- 1,encoder
encoder使用的模型框架可以是RNN,CNN+RNN,又或者是 self-attention layers。其input为acoustic features,output为 经过 hidden layer的h。
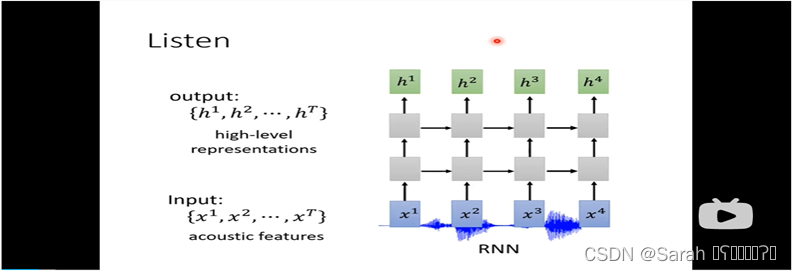
使用多层的RNN作为encoder,其结构如下:
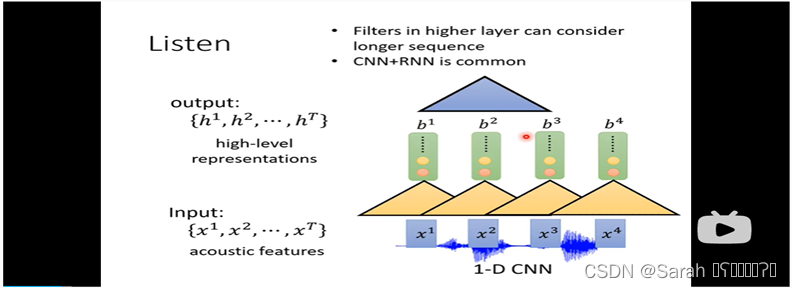
使用 CNN+RNN 作为encoder,其结构如下,首先用1-D CNN 接收 acoustic features,然后,各个timestep 下 CNN的output 作为RNN的input,最后,用 n-D CNN来 输出各个timestep的 h。在最后一步用 n-D CNN,可以将certain time step的context 考虑在内,从而使其输出h更靠谱!
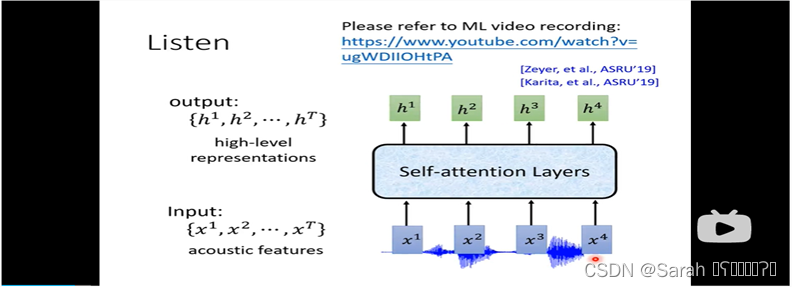
使用self-attention 作为encoder,同样可以将time step的context考虑在内,从而使得输出h更准确!
- 2,decoder
decoder中,每一个timestep的output都会用到encoder的所有output,只不过不同timestep下,encoder中各个output被关注的概率不一样。decoder 中,一个timestep的output 计算方式如下:
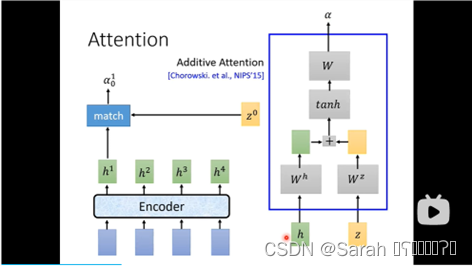
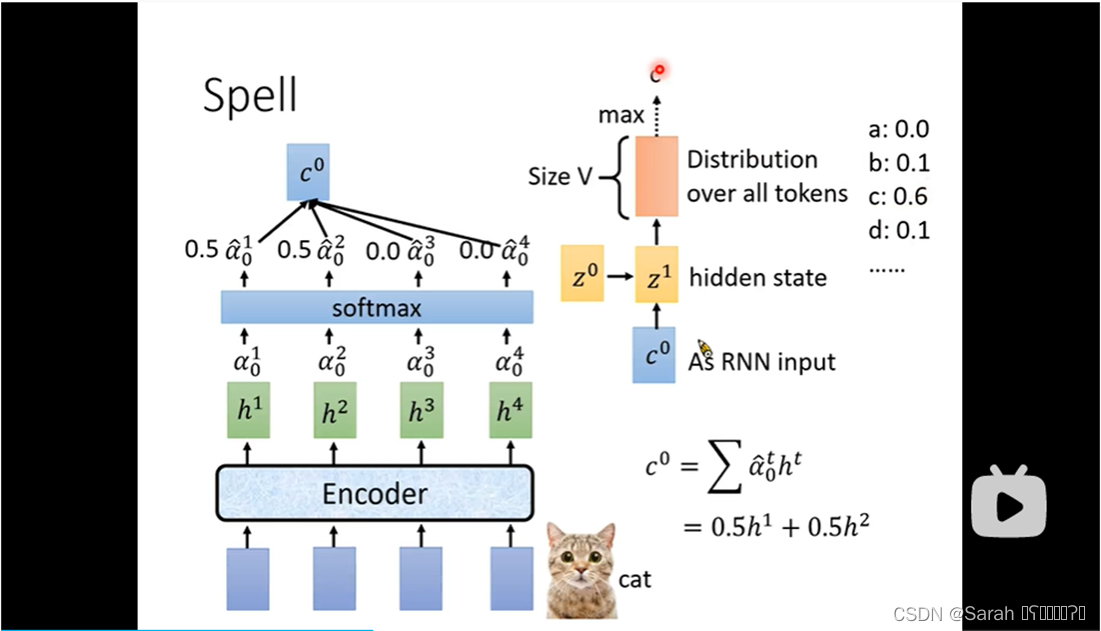
首先,给定一个 query z0,将其分别与encoder 每个timestep的output h 进 match function,得到值alpha。
这里的match function 可以是 dot product attention,也可以是 additive attention。具体如下图所示:

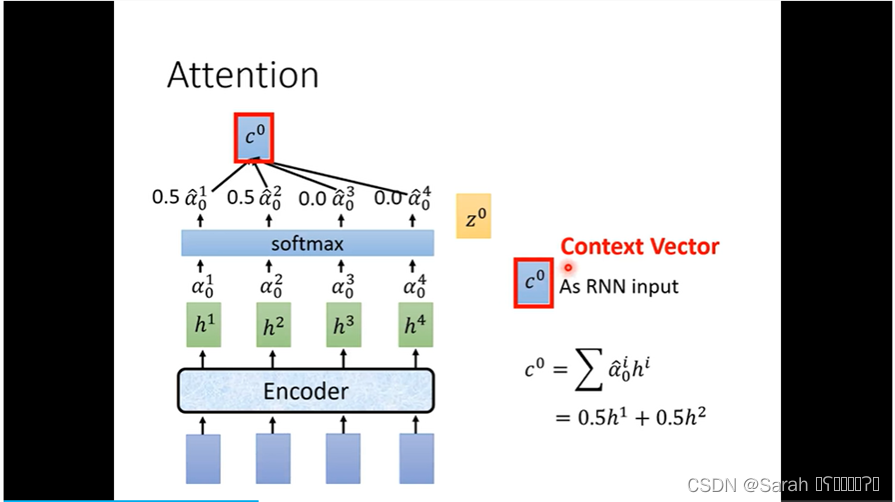
其次,将得到的各个timestep的alpha值进softmax,得到encoder各个timestep的输出h 需要被关注的百分比p。将 各个 timestep 的输出h与百分比p的乘积 进行sum,即得到 decoder的第一个timestep的输入 c0(也被称为context vector)。
第三,将 z0 , c0 作为 decoder 第一个timestep的input,进入hidden layer,其 output为 vocabulary 各个token的概率值。vocabulary可以根据需要进行选择,选项有如下几种:phoneme,grapheme,word,morpheme,bytes。
z0,c0 进 hidden layer 可以得到 z1,而z1则为 第2个timestep的 query,用于与 encoder的各个outputs 做 attention。
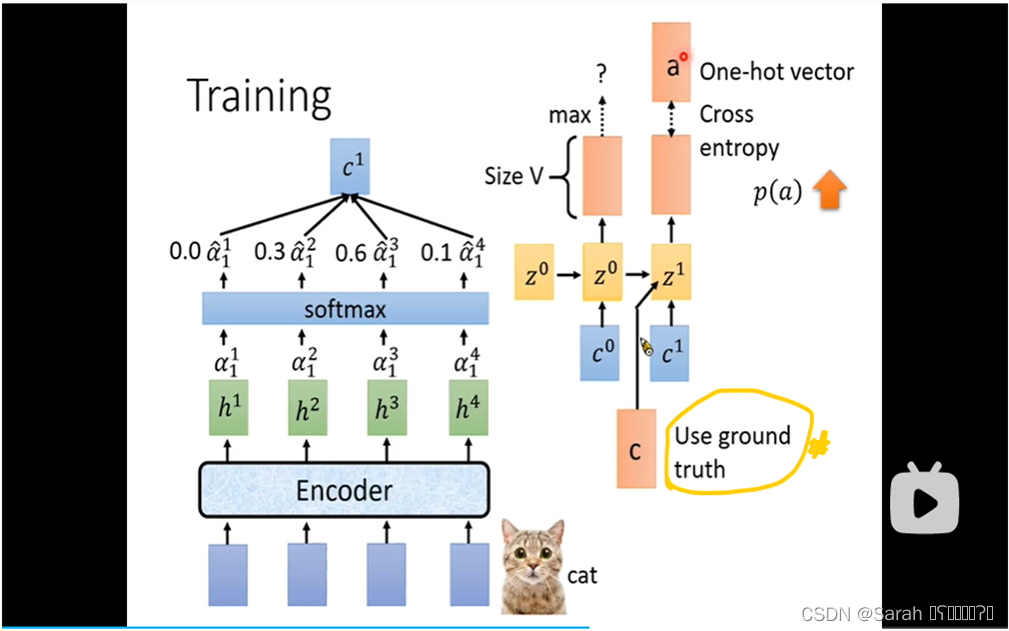
需要注意的是,在训练时,previous time step的output 并不作为 current time step的 input,而是直接采用 previous time step的ground truth,即label作为current time step的input,因为,在刚开始训练时,model辨识力有限,其output也会是随机的,这与我们的预期不符。(这招叫做 teacher forcing)。
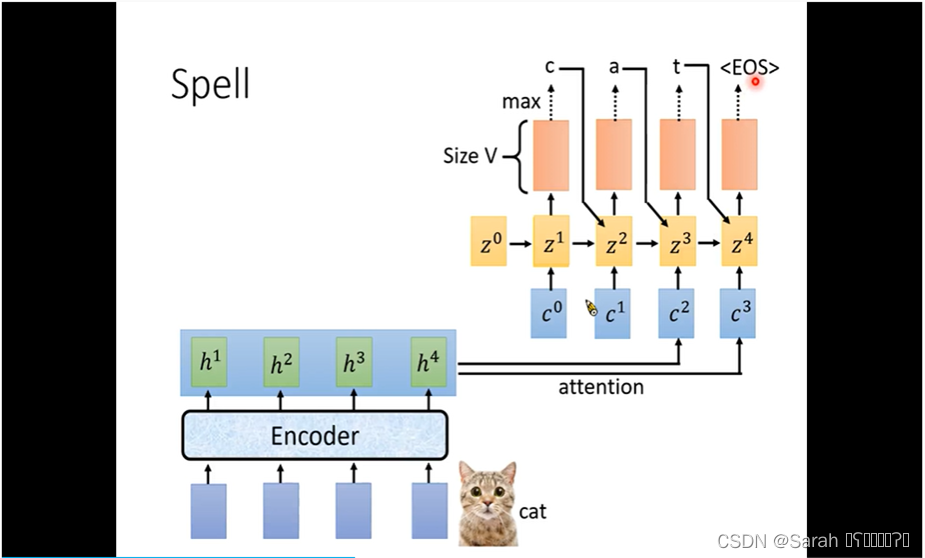
decoder每一个timestep的input都依照上述方法计算得到!
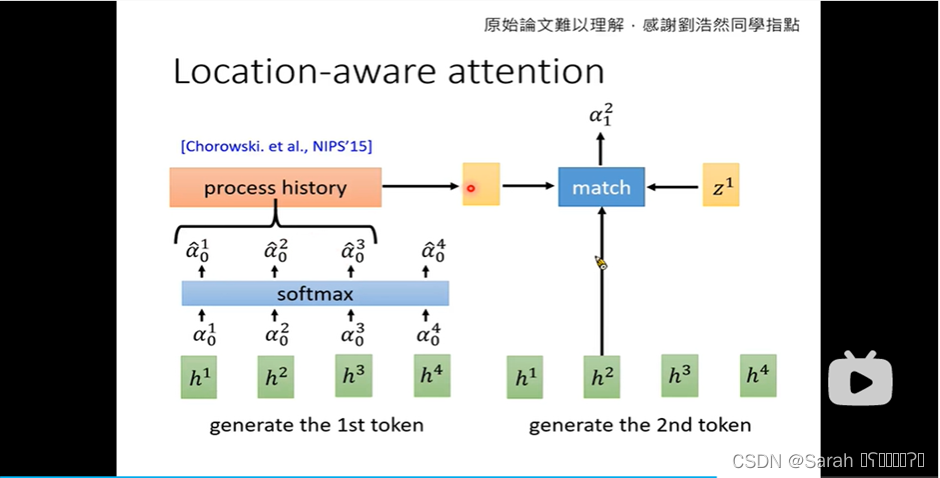
值得一提的是,为了保证decoder中的attention在每个timestep都向右移一点,我们在计算current timestep的match function时,会将previous time step计算出的 百分比 作为 match function的input,与 query 和 encoder的output一并送入 match function 求解。此种attention称为location-aware attention。location-aware attention主要是为了防止 attention乱跳,即并不会每个timestep都会向右移动一点,而生的。
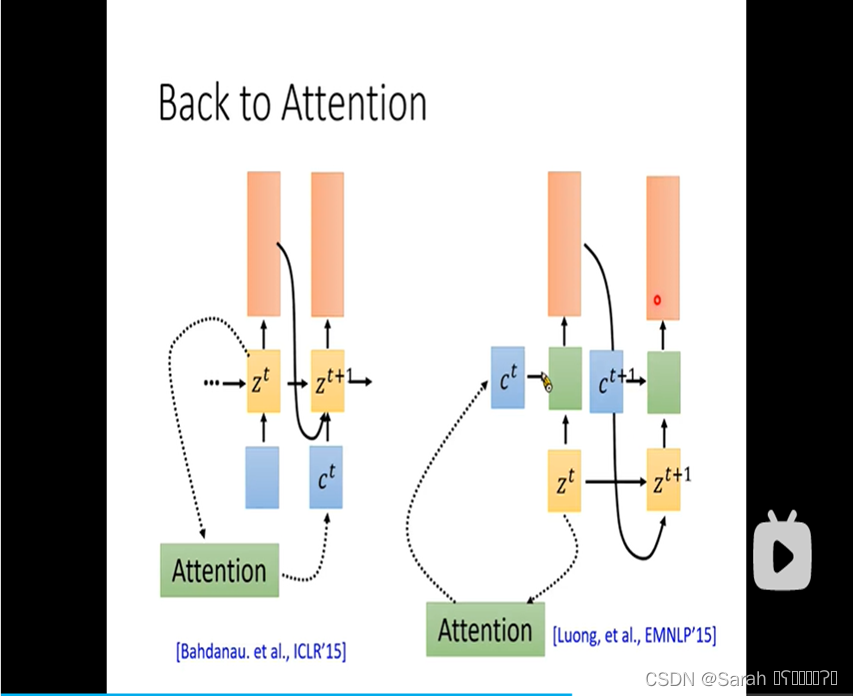
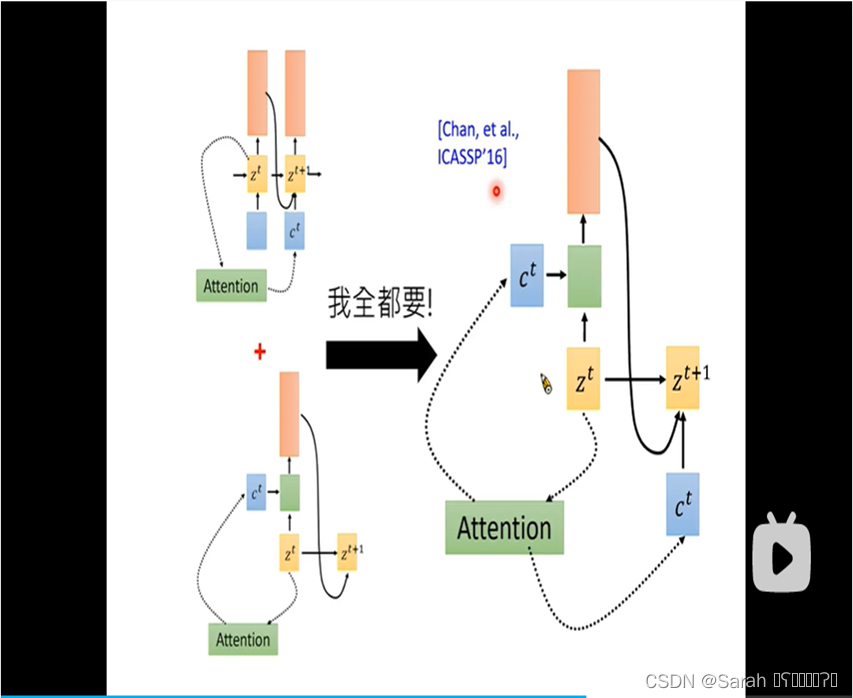
上述提到的attention,由当前step z 计算得出的 c 都是直接用于next time step的,除了这种方式以外,c也可以作为当前timestep的输入 被用于计算 当前timestep的输出,当然,也可以将上述两种方式联合用在模型里,具体如下:
- 3,loss function
LAS采用 cross entropy 来 优化模型参数。
- 4,prediction
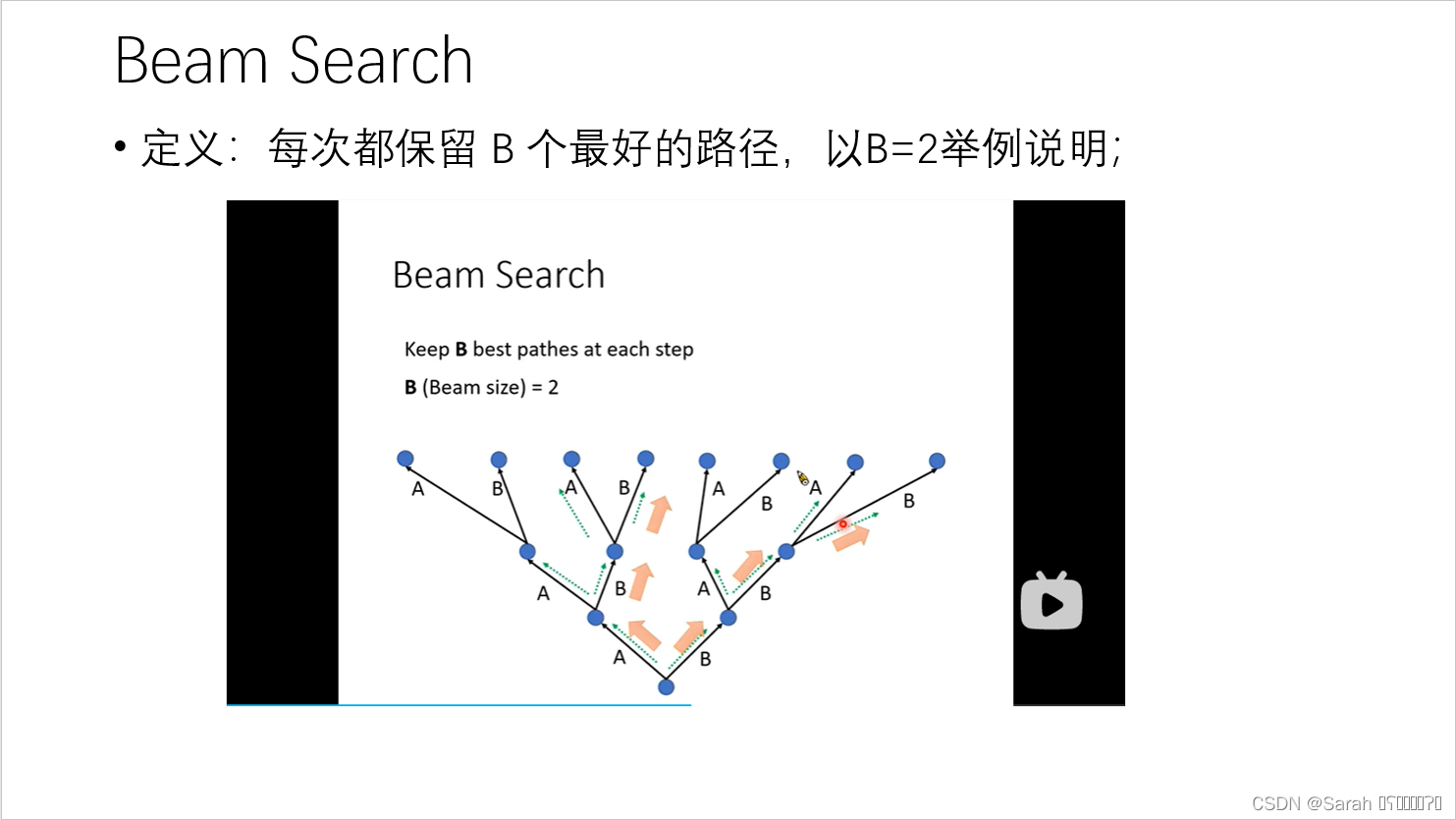
在预测时,Beam Search is usually used!

二,LAS存在的问题
LAS需要先听完所有的语音信息,即 将语音数据全部输入encoder才可以用decoder一个一个的输出文本信息,但是,不能 边听边输出文本信息。
为了解决上述问题,学者提出了新的模型:Connectionist Temporal Classification (CTC)。将在下一节中介绍该模型。
















 1021
1021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











