







机器学习中常见算法都会用到参数估计以及损失函数,下面资料仅是个人学习所得,有错误欢迎讨论。
常见的参数估计方法有:梯度下降、牛顿法、拟牛顿法。
常见的损失函数有:
1.0-1损失函数 (0-1 loss function)
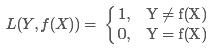
2.平方损失函数(quadratic loss function)
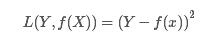
3.绝对值损失函数(absolute loss function)
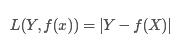
4.对数损失函数(logarithmic loss function) 或对数似然损失函数(log-likehood loss function)
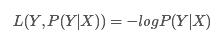
5.合页损失函数
L(y(wx+b)) = [1-y(wx+b)]下取整
下面的表格中反斜杠\表示|,因为博客编辑表格时需要用“|”来划分表格的列和行。
| 算法 | 目标函数 | 问题优化 | 损失函数 |
|---|---|---|---|
| 感知机 | f(x)= sign(w*x+b) | 采用梯度下降法优化参数w | 误分类点到分类超平面的最小距离 |
| KNN | y=argmaxsum(I(yi=cj)) | 交叉验证选择最好的k,采用投票表决方法判定样本所属的类 | 误分类率P(Y!=f(X))最小化,采用0-1损失函数 |
| Navie Bayes | y=P(Y=ci)[P(Xj=xi\Y=ck)],j=1,2,..n | 极大似然估计相应的先验概率和条件概率,为避免出现概率为0的情况,采用贝叶斯估计,在随机变量各个取值的频数上赋予一个正数r>0。r=1时为拉普拉斯平滑 | 求后验概率最大化等价于0-1损失函数时的期望风险最小化 |
| 决策树 | ID3:g(D,A)=H(D)-H(D\A) C4.5:gr(D,A)=g(D,A)/Ha(D) CART:miniGini(D,A) | 决策树剪枝 | |
| 逻辑回归 | P(Y=k\x)=1/1+exp(-wx), k=1,…,K-1, P(Y=K\x)=1/1+exp(wx) | 参数选优方法一般采用迭代尺度法、梯度下降法、拟牛顿法 | 采用对数损失函数 |
| 线性回归 | f(xi)=wxi+b,使得f(xi)~=yi | 采用最小二乘估计参数 | 平方和最小损失函数 |
| Adaboost | 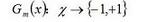 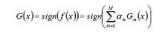 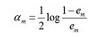 | 采用指数损失函数 | |
| SVM | min (w*w)/2,y=sign(wx+b) | SMO解决对偶问题 | 采用合页损失函数 |















 296
296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









