







注:目前开通个人网站朝思录,之后的博文将在上面更新,CSDN博客会滞后一点
主要介绍经典拉格朗日乘子法的原理,之后讨论该方法中出现的参数 λ \lambda λ的意义
拉格朗日乘子法的数学原理
经典拉格朗日乘子法是下面的优化问题(注:
x
\boldsymbol x
x是一个向量):
(1)
min
x
f
(
x
)
s
.
t
.
g
(
x
)
=
0
\begin{matrix}\min_{\boldsymbol x} f(\boldsymbol x)\\[2ex]s.t. g(\boldsymbol x)=0\end{matrix} \tag{1}
minxf(x)s.t.g(x)=0(1)
直观上理解,最优解
x
o
p
t
i
m
a
l
\boldsymbol x_{optimal}
xoptimal一定有这样的性质,以
x
\boldsymbol x
x是二维变量为例:(网上下的图。为了符合行文风格,这里的
g
(
x
,
y
)
=
c
g(x,y)=c
g(x,y)=c应为
g
(
x
,
y
)
=
0
g(x,y)=0
g(x,y)=0)
这里采用等高线方式描述
f
(
x
,
y
)
f(x,y)
f(x,y)(对方程
f
(
x
,
y
)
=
d
f(x,y)=d
f(x,y)=d对不同
d
d
d绘图),并绘制约束条件
g
(
x
,
y
)
=
0
g(x,y)=0
g(x,y)=0的曲线。可见,当
g
(
x
,
y
)
=
0
g(x,y)=0
g(x,y)=0与
f
(
x
,
y
)
f(x,y)
f(x,y)的某条等高线相切时,可取得最优解。
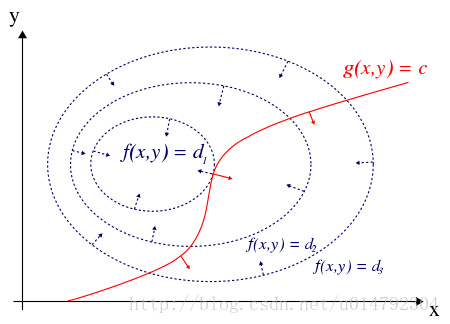
“当 g ( x , y ) = 0 g(x,y)=0 g(x,y)=0与 f ( x , y ) f(x,y) f(x,y)的某条等高线相切”,是取得最优解的充要条件(前提是 f ( x , y ) f(x,y) f(x,y)是凸函数),该条件可拆分成两部分:
- g ( x , y ) g(x,y) g(x,y)与 f ( x , y ) f(x,y) f(x,y)的某条等高线相切
- g ( x , y ) = 0 g(x,y)=0 g(x,y)=0
因为
g
(
x
,
y
)
g(x,y)
g(x,y)与
f
(
x
,
y
)
f(x,y)
f(x,y)的某条等高线相切,可等价于寻找使这两个函数梯度方向共线的点,所以上述条件可用方程组描述如下所示:
(2)
{
∇
f
(
x
)
=
λ
∇
g
(
x
)
g
(
x
)
=
0
\begin{aligned} \begin{cases} \nabla f(\boldsymbol x) = \lambda\nabla g(\boldsymbol x)\\[2ex] g(\boldsymbol x)=0 \end{cases} \end{aligned} \tag{2}
⎩⎨⎧∇f(x)=λ∇g(x)g(x)=0(2)
这时引入拉格朗日函数:
(3)
L
(
x
,
λ
)
=
f
(
x
)
+
λ
g
(
x
)
L(\boldsymbol x,\lambda) = f(\boldsymbol x)+\lambda g(\boldsymbol x) \tag{3}
L(x,λ)=f(x)+λg(x)(3)
该函数有这样的特性:
(4)
{
∇
x
L
(
x
,
λ
)
=
∇
x
f
(
x
)
+
λ
∇
x
g
(
x
)
∇
λ
L
(
x
,
λ
)
=
g
(
x
)
\begin{aligned} \begin{cases} \nabla_\boldsymbol xL(\boldsymbol x,\lambda)=\nabla_\boldsymbol x f(\boldsymbol x)+\lambda\nabla_\boldsymbol x g(\boldsymbol x)\\[2ex] \nabla_\lambda L(\boldsymbol x,\lambda) = g(\boldsymbol x) \end{cases} \end{aligned} \tag{4}
⎩⎨⎧∇xL(x,λ)=∇xf(x)+λ∇xg(x)∇λL(x,λ)=g(x)(4)
即若令拉格朗日函数的梯度为零,即
(
4
)
(4)
(4)式为零,即可得到方程
(
2
)
(2)
(2),虽然
λ
\lambda
λ有所出入但不影响。
系数 λ \lambda λ的作用
另外讨论一下 ( 3 ) (3) (3)式中 λ \lambda λ的意义:
由
(
2
)
(2)
(2)式可以看出,
λ
\lambda
λ在共线的基础上描述了目标函数和约束函数的梯度的长度比值。当然若以
(
4
)
(4)
(4)为基准,
(
2
)
(2)
(2)式第一项应写为
∇
f
(
x
)
=
−
λ
∇
g
(
x
)
\nabla f(\boldsymbol x) = -\lambda\nabla g(\boldsymbol x)
∇f(x)=−λ∇g(x),我们对该等式两边取绝对值如下,以消除正负号可能对读者带来的困扰。
(5)
∣
λ
∣
=
∣
∇
f
(
x
)
∇
g
(
x
)
∣
|\lambda|=|\frac{\nabla f(\boldsymbol x)}{\nabla g(\boldsymbol x)}| \tag{5}
∣λ∣=∣∇g(x)∇f(x)∣(5)
可以发现,当
∣
λ
∣
|\lambda|
∣λ∣越小,
∇
g
(
x
)
\nabla g(\boldsymbol x)
∇g(x)的模就越大于
∇
f
(
x
)
\nabla f(\boldsymbol x)
∇f(x)。极端情况下,
∣
λ
→
0
∣
|\lambda\to0|
∣λ→0∣,此时
∣
∇
g
(
x
)
∣
→
∞
|\nabla g(\boldsymbol x) |\to \infty
∣∇g(x)∣→∞。这意味着在
x
\boldsymbol x
x点,
g
(
x
)
g(\boldsymbol x)
g(x)几乎是垂直的,对增量非常敏感:当最优值不小心变一点点,条件
g
(
x
)
=
0
g(\boldsymbol x)=0
g(x)=0将严重偏离;若
∣
λ
∣
|\lambda|
∣λ∣很大,
g
(
x
)
g(\boldsymbol x)
g(x)几乎是水平的,则其对增量不敏感(若
g
(
x
)
g(\boldsymbol x)
g(x)的轻微偏离不会造成太大的损失,可以适当牺牲约束条件的精确性,来换取更优的解)。
换句话说, ∣ λ ∣ |\lambda| ∣λ∣越小,其求得的结果灵敏度越高,反之越低;可以说 ∣ λ ∣ |\lambda| ∣λ∣是衡量最优解灵敏度的一种方法。(当然也可以直接求 ∇ g ( x ) \nabla g(\boldsymbol x) ∇g(x)来衡量灵敏度,这样更绝对一点)















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









