







MySQL学习笔记
搭配MySQL官方文档,风味更佳~
放一位老哥的笔记:MySQL整理
1、索引包含的内容:

1.1、为什么建表尽量要有自增主键?
1)主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
2)自增主键的插入数据模式,每次插入一条新纪录,都是追加操作,不涉及挪动其他记录,不会触发叶子节点的分裂。
2、/索引和实际的数据都是存储在磁盘的,只不过在进行数据读取的时候会优先把索引加载到内存中。/(存储引擎是MEMORY的时候是这样处理)
3、存储引擎:不同的数据文件在磁盘的不同组织形式。

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mz0iKM8h-1625449926475)(/Users/mac/Library/Application Support/typora-user-images/image-20210704093342919.png)]](https://img-blog.csdnimg.cn/2021070509543913.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTQ4MDA5NzU=,size_16,color_FFFFFF,t_70)
4、操作系统与MySQL

5、MySQL使用B+树的原因:
5.1、不使用Hash表的原因:需要比较好的Hash算法,如果算法不好的话,会导致Hash碰撞,Hash冲突,导致数据分裂不均匀。当需要进行范围查找的时候需要挨个遍历,效率比较低。MEMORY存储引擎支持的是Hash索引,同时注意InnoDB支持自适应Hash。
InnoDB引擎的四大特性:https://www.cnblogs.com/zhs0/p/10528520.html
为什么Mysql用B+树做索引而不用B-树或红黑树:https://www.cnblogs.com/will-xz/p/14381154.html
5.2、不使用二叉树、二叉排序树、平衡二叉树、红黑树的原因:当需要向这些树中插入更多数据的时候,会导致当前树的高度非常高,加大读取次数,影响查询效率。
5.3、不使用B-树的原因:

6、聚簇索引与非聚簇索引

7、MySQL回表
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Un1TMKye-1625449926478)(/Users/mac/Desktop/study/bilibili_MySQL/MySQL回表.png)]](https://img-blog.csdnimg.cn/20210705095825390.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTQ4MDA5NzU=,size_16,color_FFFFFF,t_70)
8、MySQL索引覆盖

9、MySQL最左匹配

10、MySQL索引下推

11、如何回答面试中问到的MySQL优化问题?

12、MVCC当前读与快照读
MVCC多版本并发控制:https://www.jianshu.com/p/8845ddca3b23

13、MySQL隐藏字段

14、undolog
事务是否提交?事务开始的时机


15、readview读视图隐藏字段

16、事务可见性判断规则

17、事务隔离级别RC和RR的区别——readview生成时机

18、MySQL事务的四个特征

19、redolog使用两阶段提交的原因
执行流程:
1)、执行器先从引擎中找到数据,如果在内存中直接返回,如果不在内存中,查询后返回。
2)、执行器拿到数据之后会先修改数据,然后调用引擎接口重新写入数据。
3)、引擎将数据更新到内存,同时写数据到redo中,此时处于prepare阶段,并通知执行器执行完成,随时可以操作。
4)、执行器生成这个操作的binlog。
5)、执行器调用引擎的事务提交接口,引擎把刚刚写完的redo改成commit状态,更新完成。


20、MySQL查看当前锁的情况:
show engine innodb status \G;
Select * from information_schema.INNODB_LOCKS\G;
修改MySQL事务隔离级别:
set session transaction isolation level read committed;
set session transaction isolation level repeatable read;
21、MySQL中锁的分类

22、数据库调优问题怎么回答

23、临键锁(Next-key lock)
唯一索引 等值判断只会产生记录锁,范围查询会产生间隙锁,
普通索引等值 会产生间隙锁。

如果把事务的隔离级别设置为RC,Next-key lock临键锁会失效。
24、MDL锁

MDL锁开启事务之后获得意向锁,会锁住表结构。
25、锁等待和死锁

死锁发生必要条件:
互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
不剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
循环等待条件:在发生死锁时,必然存在一个进程–资源的环形链。
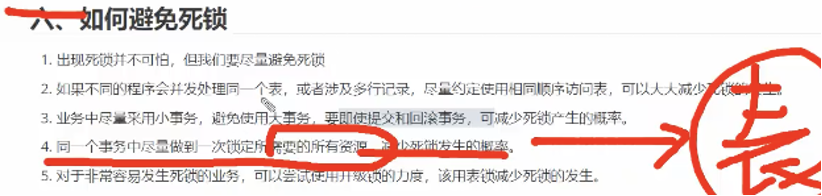
26、如何避免死锁
27、InnoDB引擎SQL执行的BufferPool缓存机制
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









