







背景
关于字符编码问题,印象深刻的有两次:
- JNI层获取JVM中Emoji表情出错,上层看到4个字节,到JNI层拿出来成了6个字节
- 面试中一道笔试题
byte[] a = new byte[]{(byte) 0xc6, (byte) 0xd0};
String s = new String(a);
byte[] b = s.getBytes();
问:最后a和b的内容是否相等?这里分析下笔试中的题目。
过程
直接敲代码调试:

从图中看到a数组2个字节,b数组6个字节,内容不同。
但是,为什么不同?这些数字是怎么计算出来的?
首先,我知道JVM内部是以UTF-16形式存储字符,那看下内部存了什么数:
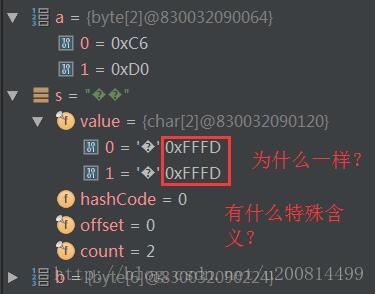
找Stack Overflow问:

在尝试解析输入流时碰到了畸形的数据,被替换为Unicode U+FFFD
去Unicode官网验证:
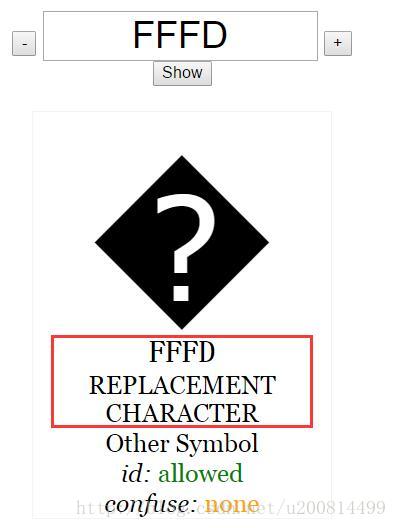
确实没骗人。
再看默认解码方式:

Unicode使用UTF-8解码
Unicode 使用UTF-16编码

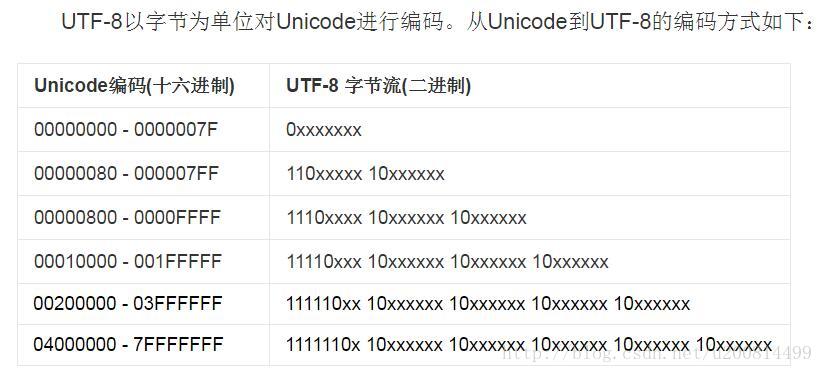
现在看下UTF-8的输入流数据:
byte[] a = new byte[]{(byte) 0xc6, (byte) 0xd0};在看下内存:

底层在从前往后解析数据时,发现0b11000110, 0b11010000不符合UTF-8的规范:

也就是第二个字节应该是10开头,但是我们的输入第二个字节是110开头,故只能解码成0xFFFD这个Unicode,然后这个需要用UTF-16编码存放在内存中,最后我们看到了两个0xFFFD。
接下来b数组里面的数据是两个0xFFFD经过UTF-16解码成Unicode数字,然后用UTF-8编码后的数据。这个转化过程照着上面的转换表格做就可以完成,算一次印象会深刻很多。
总结
//UTF-8字节流
byte[] a = new byte[]{(byte) 0xc6, (byte) 0xd0};
//解码成字符char, JVM内部采用UTF-16编码存储字符
String s = new String(a);
//UTF-16字节流编码成UTF-8字节流输出
byte[] b = s.getBytes();三行代码对数据做了以下事情:
- UTF-8输入流到Unicode数字的解码
- Unicode到UTF-16的编码
- UTF-16输入流到Unicode数字的解码
- Unicode到UTF-8的编码的输出流
综上,Unicode是个数,可以用UTF-8/UTF-16编码传输,占用流量/空间少,需要有输入、输出流的概念,以流的思考方式去处理数据















 577
577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









