







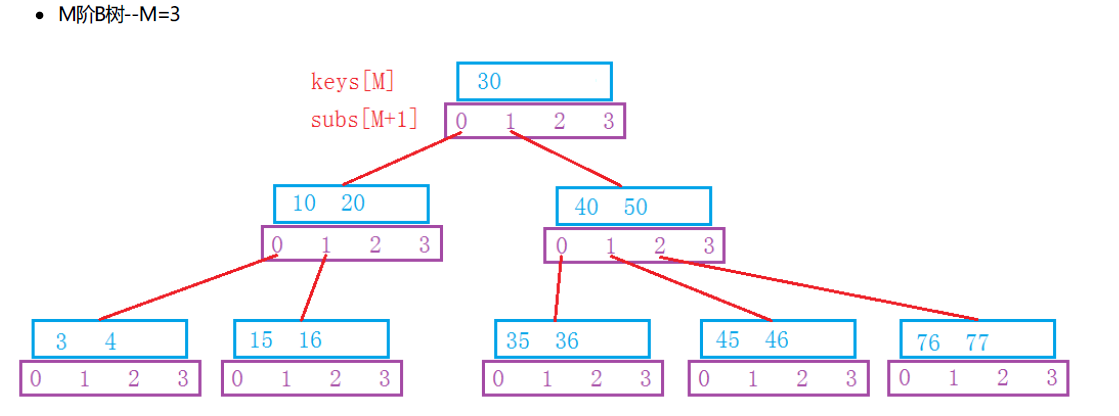
1970年,R.Bayer和E.mccreight提出了一种适合外查找的树,它是一种平衡的多叉树,称为B树。(有些地方写的是B-树,注意不要误读
成”B减树”)
一棵M阶(M>2)的B树,是一棵平衡的M路平衡搜索树,可以是空树或者满足一下性质:
1. 根节点至少有两个孩子
2. 每个非根节点有[M/2 ,M]个孩子
3. 每个非根节点有[ M/2-1,M-1]个关键字,并且以升序排列
4. key[i]和key[i+1]之间的孩子节点的值介于key[i]、key[i+1]之间
5. 所有的叶子节点都在同一层
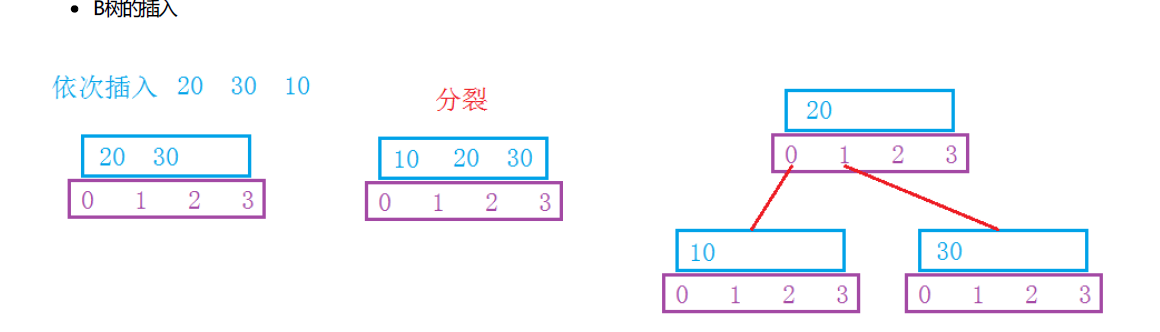
ps: 是向上取整:当一个节点的key个数满足M-1时,就会分裂,然后中间key作为父节点,从mid+1 至M-1的范围内所有的key组成的节点作为父节点的右孩子,左孩子则为0至mid-1;
*/
#pragma once
#include<iostream>
using namespace std;
> /*
1. 根节点至少有两个孩子
:那是因为每次添加key的时候,都是先从叶子结点进行添加,当key的个数等于M的时候,分裂。不断地往上分裂,最后就会出现根节点的孩子至少有两个
2. 每个非根节点有[M/2 ,M]个孩子
:每个节点的key的个数最多为M个,有你自己确定
3. 每个非根节点有[M/2 -1,M-1]个关键字,并且以升序排列
:每个节点的关键字的个数比其孩子少一个。
4. key[i]和key[i+1]之间的孩子节点的值介于key[i]、key[i+1]之间
:子节点的所有key的值介于父节点之间
5. 所有的叶子节点都在同一层
*/
template<class K ,int M>
struct BTreeNode
{
/*本来key[M-1],代表刚好插入这些元素,但为了好分裂,就成了keys[M],但是每一个节点插入的key最多是M-1个
/子节点指针数组 , 这两个数组的坐标也是一一对应,只不过subs的多一个数*/
K _keys[M]; //关键字数组;
BTreeNode<K,M>* _subs[M+1]; //子节点指针数组
size_t _sz; //记录key的个数
BTreeNode<K, M>* _parent;
BTreeNode()
: _sz(0)
, _parent(NULL)
{
for (int i = 0; i < M; i++)
{
_keys[i] = K();
}
for (int i = 0; i < M + 1;i++)
{
_subs[i] = NULL;
}
}
};
template<class K,int M>
class BTree
{
typedef BTreeNode<K,M> Node;
public:
BTree()
:_root(NULL)
{}
pair<Node*, int> Find(const K& key)
{
if (_root == NULL)
return pair<Node*, int>(NULL,-1);
else
{
Node* cur = _root;
Node* parent = NULL;
while (cur)
{
int i = 0; /*每一个节点的key最多有M个,但是你插入的key不一定等于M个,最多为M-1个,*/
while (i < cur->_sz) /*i<cur->_sz :此处的while代表我将要遍历该节点的所有key,为了判断key的位置 */
{
if (key > cur->_keys[i]) /*i:代表上一个节点的key节点的位置,key的位置i实际上可以看作是在sub中的i+1位置*/
{
i++;
}
else if (key < cur->_keys[i])
{
parent = cur;
cur = cur->_subs[i];
// cur 有可能为NULL
if (!cur)
return pair<Node*, int>(parent, -1);
}
//返回查找到的节点,以及位置 ,此时i 是上一个节点的sub[i] : 指向cur这个节点.
else
return pair<Node*, int>(cur, -1);
}
parent = cur; //:key大于_keys[sz-1]的情况
cur = cur->_subs[i];
}
return pair<Node*, int>(parent, -1); //没有找到 返回叶子节点
}
}
bool Insert(const K& key)
{
if (_root == NULL)
{
_root = new Node();
_root->_keys[0] = key;
_root->_sz++;
return true;
}
else
{
pair<Node*,int> ret = Find(key);
//找到key,则返回false
if (ret.second != -1)
return false;
/*Find 中的cur = NULL, 返回的是cur的父节点,即叶子结点,毕竟每次插入数据
都会在叶子节点插入,只有当分裂的时候新的key才会在非叶节点处插入,但此时需
要注意的是:孩子的个数始终bikey的个数多1 。
cur 为叶子节点 */
Node* cur = ret.first;
Node *sub = NULL;
K newkey = key;
while (1)
{
/*
1. 往cur节点插入key/sub
2.如果cur没满,则停止
3.如果满了,则继续向上分裂
*/
/*_Insert(cur, key);//只考虑了插入key的情况,没有考虑到每插入一个key,都对应多一个孩子节点,*/
_Insert(cur, newkey, sub);
if (cur->_sz < M)
{
return true;
}
else //分裂 :此时插入的key的个数为 M个
{
size_t mid = M / 2;
Node* tmp = new Node();
size_t j = 0;
for (int i = mid + 1; i < M; i++) // = M
{
tmp->_keys[j] = cur->_keys[i];
/*转移mid 之后的key的两边的孩子节点最开始忘了将孩子节点移动到tmp下*/
tmp->_subs[j] = cur->_subs[i];
cur->_subs[i] = NULL;
if (cur->_subs[i] != NULL)
{
cur->_subs[i]->_parent = tmp;
}
cur->_keys[i] = K();
tmp->_sz++ ;
cur->_sz--;
j++;
}
tmp->_subs[j] = cur->_subs[M];
cur->_subs[M] = NULL;
if (cur->_subs[M] != NULL)
{
cur->_subs[M]->_parent = tmp;
}
//上面将cur分为两部分,接下来。。。
if (cur->_parent == NULL)
{
_root = new Node();
_root->_keys[0] = cur->_keys[mid];
_root->_sz++;
_root->_subs[0] = cur;
cur->_parent = _root;
_root->_subs[_root->_sz] = tmp;
tmp->_parent = _root;
cur->_keys[mid] = K();
cur->_sz--;
return true;
}
else
{
newkey = cur->_keys[mid];
cur->_keys[mid] = K();
cur->_sz--;
sub = tmp;
cur = cur->_parent;
}
}
}
}
}
void InOrder()
{
_InOrder(_root);
}
protected:
//循环递归模式
void _InOrder(Node* root)
{
if (root == NULL)
return;
Node* cur = root;
int i = 0;
while (i <= cur->_sz)
{
//递归
_InOrder(cur->_subs[i]);
if (i < cur->_sz)
{
cout << cur->_keys[i] << " ";
}
i++;
}
}
//始终记得,最开始的插入一定在叶子节点上
void _Insert(Node* node, K key, Node* sub)
{
for (int i = 0; i < node->_sz; i++)
{
if (key > node->_keys[i])
{
i++;
}
else
{
int j = node->_sz;
while (j - i)
{
node->_keys[j] = node->_keys[j-1];
node->_subs[j+1] = node->_subs[j]; //bug
j--;
}
node->_keys[i] = key;
//以i = 0进行分析,可知道每一次插入sub的时候,都是在i的右边,即在sub【i+1】处。
node->_subs[i + 1] = sub;
if (sub != NULL)
{
sub->_parent = node;
}
node->_sz++;
return;
}
}
node->_keys[node->_sz] = key;
node->_subs[node->_sz + 1] = sub;
if (sub != NULL)
{
sub->_parent = node;
}
node->_sz++;
}
//void _Insert(Node* node ,K key)
//{
// //直接插进去,只在当前节点插入,因为结构体定义的数组大小比应该插入的个数大1,当等于M的时候,进行分裂就行
// for (int i = 0; i < node->_sz; i++)
// {
// if (key < node->_keys[i])//当插入位置为0的时候,sz个key进行挪动, 当插入的位置为1 的时候,sz-1个key进行挪动,===》查找插入位置
// { //i就是插入位置
// int j = node->_sz;
// while (j - i) //必须明确数组的下标和key的实际坐标
// {
// node->_keys[j] = node->_keys[j - 1];
// j--;
// }
// node->_keys[i] = key;
// node->_sz++;
// return ;
// }
// else
// {
// i++;
// }
// }
// node->_keys[node->_sz] = key;
// node->_sz++;
//
//}
protected:
Node* _root;
};
void BTreeTest()
{
BTree<int, 3> bt;
bt.Insert(53);
bt.Insert(75);
bt.Insert(139);
bt.Insert(49);
bt.Insert(145);
bt.Insert(36);
bt.Insert(101);
bt.InOrder();
}














 4926
4926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









