









Regular Expressions 搜索也即正则搜索是非常耗时的。正则表达式是一种使用 placeholder(称为运算符)匹配数据中的模式的方法。 有关regexp查询支持的运算符的列表,请参阅 Regular expression syntax。
在今天的文章中,我们来简单介绍如何正确使用 regexp 搜索。
正则表达式语法中使用了许多符号和运算符来表示通配符和字符范围:
- 句号 “.” 用于代表任何字符。
- 用括号括起来的一系列字符,例如 [a-z],是一个字符类。 字符类表示字符范围; 在此示例中,它充当任何字母的替代。
- 加号 “+” 用于表示重复的字符; 例如,“Mississippi” 中的 “pp”。
我们来看一个 “regexp”,其中包含我们刚刚讨论的所有正则表达式语法。 以下示例中显示的 regexp 将与单词 “Mississippi” 匹配:
GET states/_search
{
"query": {
"regexp": {
"name": "[a-z]*ip+i"
}
}
}
# RETURNS --->
"name" : "Mississippi"
GET states/_search
{
"query": {
"regexp": {
"name": "mis+[a-z]*"
}
}
}
# RETURNS --->
"name" : "Missouri"
# ..and
"name" : "Mississippi"
GET states/_search
{
"query": {
"regexp": {
"name": "[a-z]*ska"
}
}
}
# RETURNS -->
"name" : "Alaska"
# and..
"name" : "Nebraska"我们首先创建一个 my_example 的索引:
PUT my_example/_doc/1
{
"content": "This is a good network"
}假如我们想搜索以 net 为开头的文档,那么我们可以使用 regexp 来进行如下写的搜索:
GET my_example/_search
{
"query": {
"regexp": {
"content": "net.*"
}
}
}根据 Regular expression syntax 里的描述,它匹配任何以 net 为开头的所有的文档:
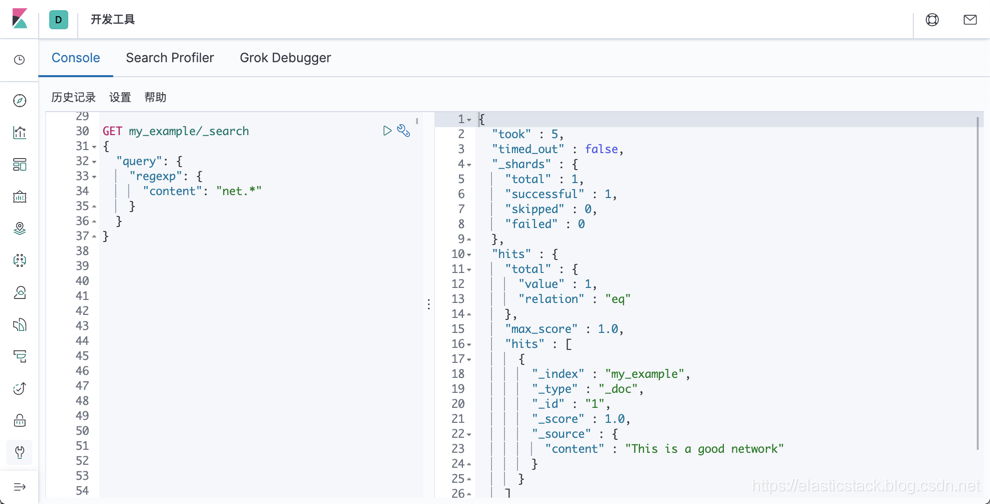
可能有人想搜索以 work 结束的术语的所有文档,那么我们应该怎么做呢?我们可以通过如下的方法:
GET my_example/_search
{
"query": {
"regexp": {
"content": ".*work"
}
}
}显示的结果为:
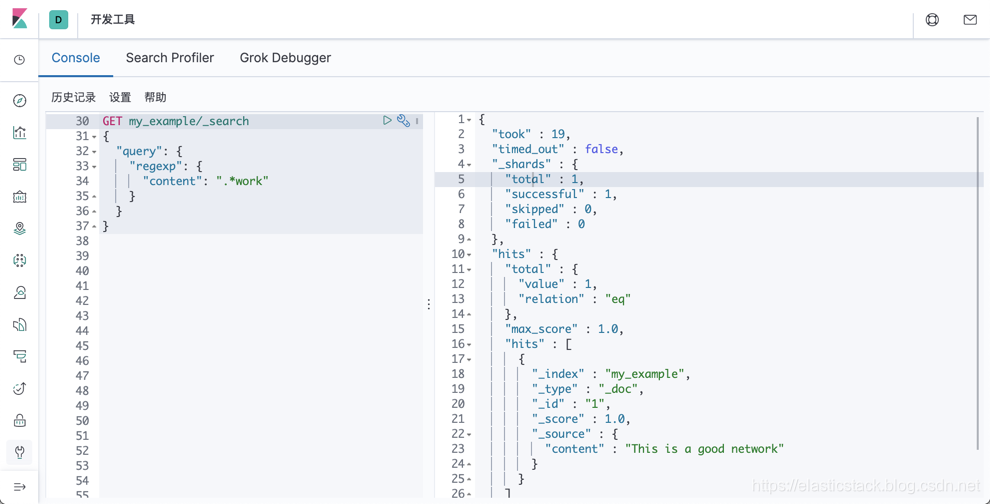
我们得到了我们希望的结果。
虽然在上面我们得到我们想要的结果,但是在实际使用 regexp 搜索时,我们必须记住如下的事项:
- 避免通配符在前面,比如上面的 .*work。可能以避免使用前导通配符的方式对数据建立索引
- 通常,正则表达式可能会很昂贵
那么什么是正确的解决方案呢?
如果您确实需要匹配 token 的末尾,只需使用 reverse 过滤器为它们建立索引。下面,我们用一个具体的例子来实现。
首先,我们为 reverse_example 建立一个 mapping:
PUT reverse_example
{
"settings": {
"analysis": {
"analyzer": {
"whitespace_reverse": {
"tokenizer": "whitespace",
"filter": [
"reverse"
]
}
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text",
"fields": {
"reversed": {
"type": "text",
"analyzer": "whitespace_reverse"
}
}
}
}
}
}在这里 content 是一个 multi-field 的字段。content.reversed 将使用 whitespace_reverse 分析器来对我们的字段进行分词。这个分析器将会对术语进行倒序处理。比如:
GET reverse_example/_analyze
{
"tokenizer": "standard",
"filter": [
"reverse"
],
"text": "quick fox jumps"
}它将返回:
{
"tokens" : [
{
"token" : "kciuq",
"start_offset" : 0,
"end_offset" : 5,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "xof",
"start_offset" : 6,
"end_offset" : 9,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "spmuj",
"start_offset" : 10,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 2
}
]
}现在,我们对我们的索引添加一个文档:
PUT reverse_example/_doc/1
{
"content": "This is a good network"
}那么我们对我们的文档重新使用 regexp 进行搜索:
GET reverse_example/_search
{
"query": {
"regexp": {
"content.reversed": "krow.*"
}
}
}显示的结果为:
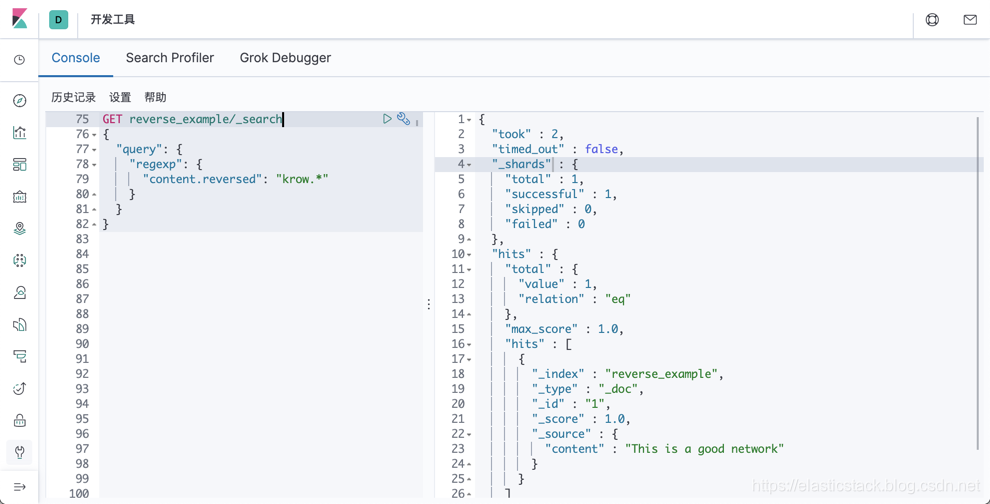
我们通过上面的方法把通配符在前面的搜索修改成为通配符在后面的 regexp 搜索。
参考:
【1】https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-reverse-tokenfilter.html


















 852
852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









