






3 Method
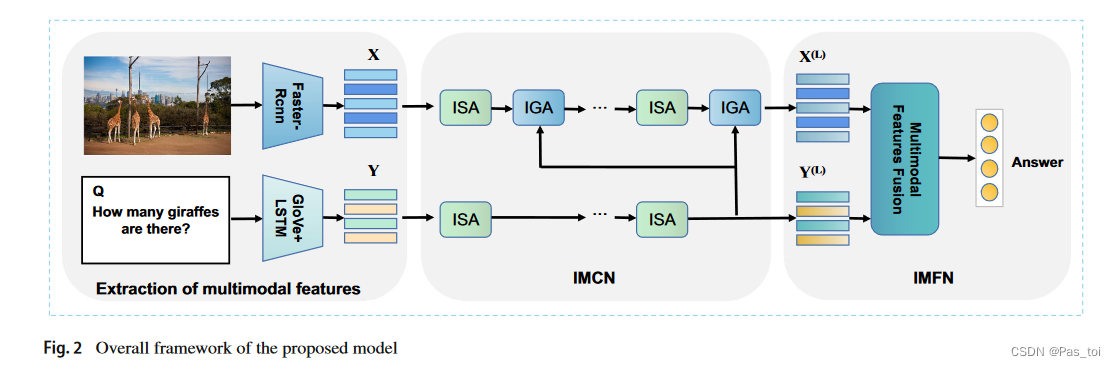
这一部分详细介绍了IMCN和IMFN。方法的整体框架如图2所示,由多个改进的模块化协同注意力( IMC )层堆叠而成。在接下来的部分中,首先介绍了图像特征和问题特征的提取方法,然后对IMCN的各个组成部分进行了说明。最后,在得到关注的视觉特征和文本特征后,引入IMFN对它们进行融合,最终得到预测答案。
3.1 Notations
在描述我们的方法之前,我们给出了本文的关键数学符号及其描述,列于表1。
3.2 Extraction of image features and question features
IMCN使用在Visual Genome数据集上预训练的Fast - RCNN提取的一组区域视觉特征来表示输入图像。为了保证视觉特征的质量,我们设置了一个置信度阈值,只选择检测概率超过该阈值的图像区域。这样,我们得到了一个动态的区域图像特征数,它可以用一个矩阵X∈来表示,其中m∈[ 10、100 ]是选定的图像区域的数目。xi∈
表示第i个图像区域。
在问题特征表示方面,我们沿用了之前BAN的研究成果,首先将输入的问题标记为一组单词,并将单词数限制在 14 个以内。为了与其他问题保持一致,超过 14 个字的问题的多余字会被丢弃。然后,使用在大规模语料库中预先训练好的 300 维 GloVe 词嵌入,将每个词进一步转换成一个向量。因此,我们可以得到 n × 300 的词嵌入序列,其中 n∈[1, 14] 表示输入问题的词数。当图像区域数或问题单词数小于最大值时(即 m=100, n=14),我们利用零填充法将其对应的特征矩阵填充到最大值。
3.3 Improved modular co-attention networks
IMCN 由一组 IMC 层堆叠而成,其中包括两个基本注意力单元,即改进的自我注意力单元(ISA)和改进的引导注意力单元(IGA)。通过不同方式的组合,我们进一步开发出三种 IMC 变体。我们选择其中最好的一种作为模型的组成部分。
3.3.1 ISA and IGA units
ISA和IGA可以看作是MCAN中提出的自注意力和引导注意力的两种扩展,使用"尺度点积注意力" 。尺度化的点积注意力使用Q,K和V作为输入和输出值的加权组合。具体来说,它首先计算Q和K的点积并除以√d,其中d是K的维数。结果用softmax函数归一化,以获得V的注意力权重。然后对注意力权重和V进行加权求和,得到关注特征F:
多头注意力:
当没有任何东西满足给定的查询时,多头注意力模块仍然会生成一个与查询无关的向量,从而导致为 VQA 任务生成一个错误的答案。因此,利用 Attention on Attention for Image Captioning中提出的 AoA 来改进传统的多头注意力模块,即在得到多头注意力结果后使用另一个注意力函数。第二个注意力函数的过程可描述如下:
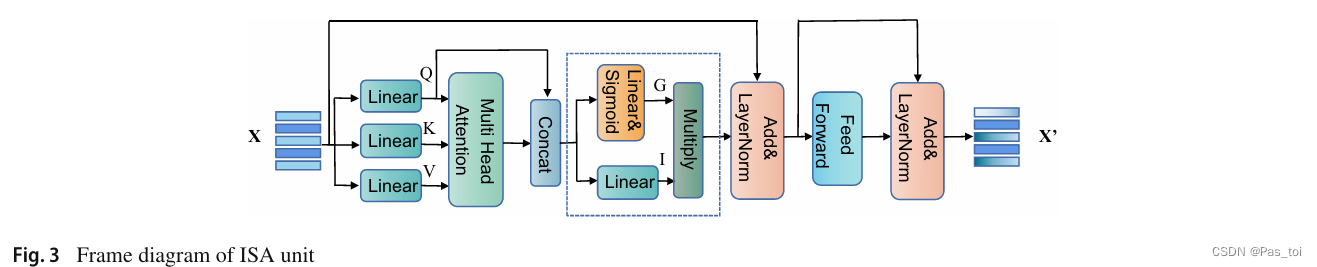
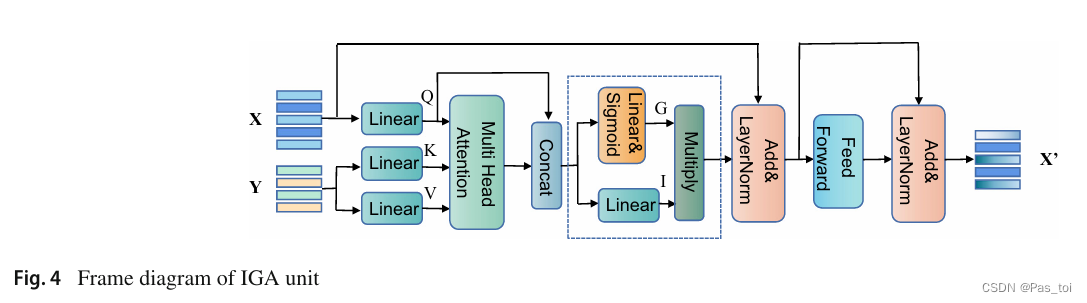
ISA还应用了一个前馈层,它使用两个全连接层来执行ReLU激活和Dropout。为了促进优化,在AoA和前馈层之后使用残差连接和层归一化。ISA单元的结构如图3所示。IGA与ISA类似,不同之处在于IGA以视觉特征X和文本特征Y作为输入,其中X由Y引导,而ISA则以X或Y作为输入。IGA单元的结构如图4所示。
在ISA和IGA单元的基础上,我们开发了三种可以级联(见图5)的IMC层。
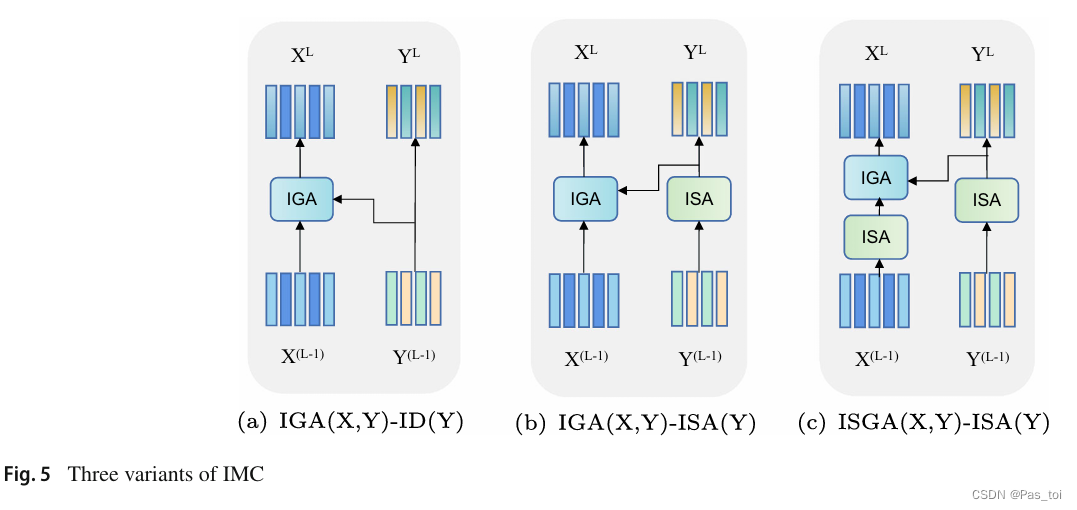
同MCAN一样,上一个IMC层的输出直接输入到下一个IMC层,并且特征的数量和每个特征的维度保持不变。需要说明的是,上述3种IMC层并不能涵盖所有情况。我们还对其他IMC变体如ISGA( X , Y) - ID ( Y ),IGA( X , Y) - IGA( Y , X)和ISGA( X , Y) - ISGA( Y , X)进行了实验。
3.3.2 Cascade of IMC layers
通过级联,上述三种IMC变体被用于构成深度协同注意力学习模块。我们将第l个IMC层记为IMC ( l ),其中l∈[ 1 , L],L表示IMC层的总数。最后一个IMC层输出的视觉特征和文本特征直接输入到下一个IMC层,可以看作是一个递归的过程。设X ( l-1 ),Y ( l-1 )和X ( l ),Y ( l )分别表示第l个IMC层的输入特征和输出特征。这个过程可以形式化为:
对于IMC ( 1 ),输入特征设置为:X ( 0 ) = X,Y ( 0 ) = Y,其中X,Y来自3.2节。我们以ISGA( X , Y) - ISA ( Y )层为例,构建了与[ 11 ]相同的两种协同注意力模型(图6 )。堆叠模型(图6 ( a ) )只是简单地将L个IMC层堆叠在一起,而编码器-解码器模型(图6 ( b ) )则将每个IMC ( l )的IGA单元的输入文本特征Y ( l )替换为最终IMC层的文本特征Y ( L )。有一种特殊情况,当L = 1时,两个模型是等价的。
3.4 Improved multimodal fusion networks
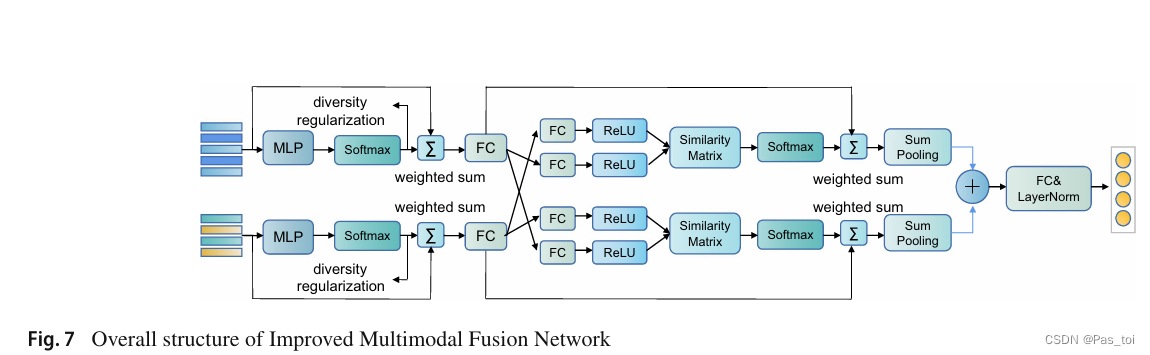
在获得图像特征X ( L )∈和问题特征Y ( L )∈Rn × d后,引入一种改进的多模态融合网络( IMFN ) (图7 )对它们进行融合[ 2 ]。
具体来说,首先将图像和问题特征通过多层感知器( MLP )计算多个头上不同的注意力权重。令hm表示头数,此过程可描述如下:
其中α∈,β∈
.然后采用加权求和的方法得到注意图像特征
和问题特征
:
式中:,
∈
,α i为α中的每个列向量,β i为β中的每个列向量。此外,为了获得视觉模态和文本模态之间的互补信息,使用交叉注意力机制,(1)计算两个模态的相似度矩阵。(2)通过softmax函数获取注意力权重。(3)通过加权求和和池化,得到了两个向量( x,( y ),分别代表最终的视觉特征和文本特征。(4)它们被组合在一起,紧接着是LayerNorm层。(5)我们使用全连接层来预测答案。
其中∈
,N是训练集中最常见答案的个数。我们使用与[ 29 ]相同的二元交叉熵作为损失函数( LossBCE ):
其中M,N表示训练问题和候选答案的个数,,
表示真实答案和预测答案。为了解决注意力可能集中在相似区域的冗余问题,受...的启发,我们加入了多样性正则化损失( LossDR ):
其中α,β表示注意力权重矩阵来自本文公式(8)和( 9 )。I∈为单位矩阵。并且' | | . | | F '表示平方Frobenius范数.最后,总损失描述如下:
4 Experiments
我们在VQA - v2 和GQA 上进行了一系列的实验来验证模型的有效性。首先描述了实验中使用的数据集以及具体的实验设置。然后,进行了一些消融研究,以比较我们的模型与MCAN的不同变体的性能。最后,提供了一个可视化的模型,并将模型与其他现有的VQA方法的性能进行了比较。
4.1 Dataset
......
4.2 Experimental settings
......
















 440
440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









