






本文分析了安泰杯 —— 跨境电商智能算法大赛的解题代码 —— rain.的跨境电商智能算法大赛-数据探索与可视化
一、转化每列数据类型为可存储的最小值,减少内存消耗
memory = df.memory_usage().sum() / 1024**2
print('Before memory usage of properties dataframe is :', memory, " MB")
dtype_dict = {'buyer_admin_id' : 'int32',
'item_id' : 'int32',
'store_id' : pd.Int32Dtype(),
'irank' : 'int16',
'item_price' : pd.Int16Dtype(),
'cate_id' : pd.Int16Dtype(),
'is_train' : 'int8',
'day' : 'int8',
'hour' : 'int8',
}
df = df.astype(dtype_dict)
memory = df.memory_usage().sum() / 1024**2
print('After memory usage of properties dataframe is :', memory, " MB")
del train,test; gc.collect()-
这行代码计算了DataFramememory = df.memory_usage().sum() / 1024**2df的内存使用量,单位是MB。df.memory_usage().sum()返回一个Series,表示DataFrame中每个元素占用的内存大小。然后,将这个Series中的所有值相加得到总内存使用量。最后,将总内存使用量除以1024**2(即1MB的平方),以便以MB为单位显示。 -
这行代码指定DataFrame中各个列的数据类型。Pandas在创建DataFrame时会根据这个字典指定的数据类型来创建数据类型。dtype_dict = {…………} -
这行代码首先删除了变量del train,test; gc.collect()train和test,这可能是在之前的代码中定义的变量。gc.collect()函数用于回收垃圾,即删除不再使用的内存块。这有助于清理内存,避免内存泄漏。
具体效果为:
Before memory usage of properties dataframe is : 1292.8728713989258 MB After memory usage of properties dataframe is : 696.1623153686523 MB
二、将数据存储到h5文件中
for col in ['store_id', 'item_price', 'cate_id']:
df[col] = df[col].fillna(0).astype(np.int32).replace(0, np.nan)
df.to_hdf('../data/train_test.h5', '1.0')具体效果为:
previous : CPU times: user 13.3 s, sys: 1.29 s, total: 14.6 s Wall time: 14.6 s
now : CPU times: user 3.55 s, sys: 2.91 s, total: 6.46 s Wall time: 6.46 s
三、赛题要求及Baseline
要求选手提交的数据
关于yy国的B部分用户每个用户的最后一条购买数据的预测Top30
代码中的Baseline部分
test = pd.read_csv('../data/Antai_AE_round1_test_20190626.csv')
tmp = test[test['irank']<=31].sort_values(by=['buyer_country_id', 'buyer_admin_id', 'irank'])[['buyer_admin_id','item_id','irank']]
sub = tmp.set_index(['buyer_admin_id', 'irank']).unstack(-1)
sub.fillna(5595070).astype(int).reset_index().to_csv('../submit/sub.csv', index=False, header=None)选取用户近30次购买记录作为预测值,越近购买的商品放在越靠前的列,不够30次购买记录的用热销商品5595070填充
首先使用条件'irank'<=31来筛选test DataFrame中irank列的值小于或等于31的行。然后,使用sort_values方法按buyer_country_id、buyer_admin_id和irank列的值进行排序,并将排序后的结果存储在变量tmp中。
这行代码将tmp DataFrame的buyer_admin_id和irank列设置为索引,并使用unstack方法将最后一列转换为一个单独的层级(即将一列转换为多列,通常用于透视表操作),结果存储在变量sub中。
1. sort_values目的
根据赛题要求,我们需要yy国(buyer_country_id)中的用户(buyer_admin_id),那进行排序后,数据结构变为(随机数据为例)
| 国家 | 用户 | irank | …… |
| xx | 1574 | 1 | |
| 1575 | 1 | ||
| yy | 7458 | 1 | |
| 7458 | 2 |
那就可以取yy国的用户数据。对于每个用户,其按照购买时间 (irank) 排序购买的商品,然后再取其购买的商品 (item_id) 也就是最近购买的30个商品
2. 为什么使用5595070填充
根据数据分析,得出5595070为最热销的产品
item_cnt = groupby_cnt_ratio(df, 'item_id')
item_cnt.columns=['销量', '总销量占比']
item_cnt.reset_index(inplace=True)
top_item_plot = item_cnt.groupby(['is_train','buyer_country_id']).head(10)
fig, ax = plt.subplots(2, 1, figsize=(16,12))
sns.barplot(x='item_id', y='销量', data=top_item_plot[top_item_plot['buyer_country_id']=='xx'],
order=top_item_plot['item_id'][top_item_plot['buyer_country_id']=='xx'], ax=ax[0], estimator=np.mean).set_title('xx国-TOP热销商品')
sns.barplot(x='item_id', y='销量', hue='is_train', data=top_item_plot[top_item_plot['buyer_country_id']=='yy'],
order=top_item_plot['item_id'][top_item_plot['buyer_country_id']=='yy'], ax=ax[1], estimator=np.mean).set_title('yy国-TOP热销商品');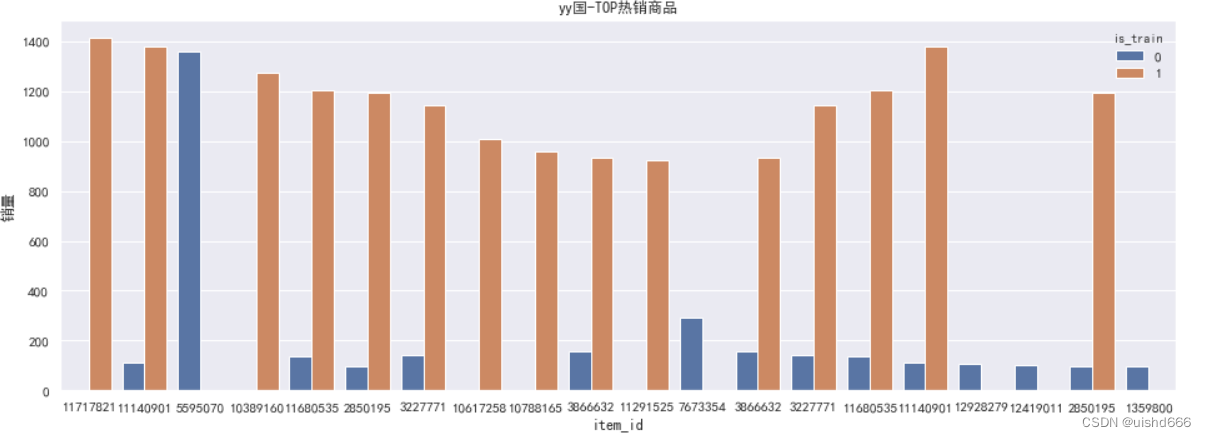
乍一看,Baseline挺简单。代码重点放在了数据可视化和数据处理上面,比如是否有刷单情况等















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









