







一、背景
1.Transformer 架构早已在自然语言处理任务中得到广泛应用
2.在计算机视觉领域,注意力要么与卷积网络结合使用,要么用来代替卷积网络的某些组件,同时保持其整体架构不变。
3.基于自注意力的架构,尤其 Transformer,已经成为 NLP 领域的首选模型。该主流方法基于大型文本语料库进行预训练,然后针对较小的任务特定数据集进行微调。由于 Transformer 的计算效率和可扩展性,基于它甚至可以训练出参数超过 100B 的模型。随着模型和数据集的增长,性能仍然没有饱和的迹象。
然而,在计算机视觉中,卷积架构仍然占主导地位。受 NLP 成功的启发,多项计算机视觉研究尝试将类 CNN 架构与自注意力相结合,有的甚至完全代替了卷积。后者虽然在理论上有效,但由于其使用了专门的注意力模式,因此尚未在现代硬件加速器上有效地扩展。因此,在大规模图像识别任务中,经典的类 ResNet 架构仍然是最先进的。
二、本文采取的方法
1.做法概述
受到 NLP 领域中 Transformer 缩放成功的启发,这项研究尝试将标准 Transformer 直接应用于图像,并尽可能减少修改。为此,该研究将图像分割成多个图像块(patch),并将这些图像块的线性嵌入序列作为 Transformer 的输入。然后用 NLP 领域中处理 token 的方式处理图像块,并以监督的方式训练图像分类模型。
在中等规模的数据集(如 ImageNet)上训练时,这样的模型产生的结果并不理想,准确率比同等大小的 ResNet 低几个百分点。这个看似令人沮丧的结果是可以预料的:Transformer 缺少一些 CNN 固有的归纳偏置,例如平移同变性和局部性,因此在数据量不足的情况下进行训练后,Transformer 不能很好地泛化。
但是,如果在大型数据集(14M-300M 张图像)上训练模型,则情况大为不同。该研究发现大规模训练胜过归纳偏置。在足够大的数据规模上进行预训练并迁移到数据点较少的任务时,Transformer 可以获得出色的结果。
该研究提出的 Vision Transformer 在 JFT-300M 数据集上进行预训练,在多个图像识别基准上接近或超过了 SOTA 水平,在 ImageNet 上达到了 88.36% 的准确率,在 ImageNet ReaL 上达到了 90.77% 的准确率,在 CIFAR-100 上达到了 94.55% 的准确率,在 VTAB 基准 19 个任务中达到了 77.16% 的准确率。
2、具体实现
尽可能的保存transformer的结构,只在框架的两端做改变
该研究提出的 Vision Transformer 架构遵循原版 Transformer 架构。下图 1 为模型架构图。
标准 Transformer 接收 1D 序列的 token 嵌入为输入。为了处理 2D 图像,研究者将图像
x ∈
变形为一系列的扁平化 2D patch x_p ∈
,其中 (H, W) 表示原始图像的分辨率,(P, P) 表示每个图像 patch 的分辨率。然后,
成为 Vision Transformer 的有效序列长度。
Vision Transformer 在所有层使用相同的宽度,所以一个可训练的线性投影将每个向量化 patch 映射到模型维度 D 上(公式 1),相应的输出被称为 patch 嵌入。
与 BERT 的 [class] token 类似,研究者在一系列嵌入 patch (z_0^0 = x_class)之前预先添加了一个可学习嵌入,它在 Transformer 编码器(z_0^L )输出中的状态可以作为图像表示 y(公式 4)。在预训练和微调阶段,分类头(head)依附于 z_L^0。
位置嵌入被添加到 patch 嵌入中以保留位置信息。研究者尝试了位置嵌入的不同 2D 感知变体,但与标准 1D 位置嵌入相比并没有显著的增益。所以,编码器以联合嵌入为输入。
Transformer 编码器由多个交互层的多头自注意力(MSA)和 MLP 块组成(公式 2、3)。每个块之前应用 Layernorm(LN),而残差连接在每个块之后应用。MLP 包含两个呈现 GELU 非线性的层。
作为将图像分割成 patch 的一种替代方案,输出序列可以通过 ResNet 的中间特征图来形成。在这个混合模型中,patch 嵌入投影(公式 1)被早期阶段的 ResNet 取代。ResNet 的其中一个中间 2D 特征图被扁平化处理成一个序列,映射到 Transformer 维度,然后馈入并作为 Transformer 的输入序列。最后,如上文所述,将分类输入嵌入和位置嵌入添加到 Transformer 输入中。
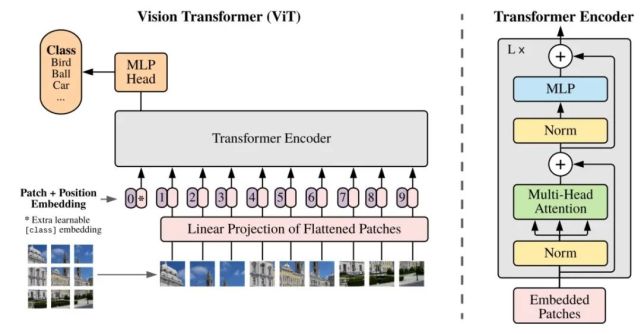
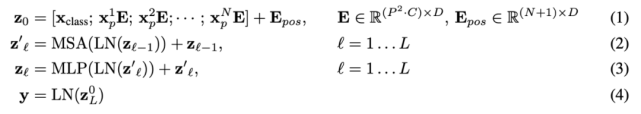
简单来说:
1.patch 16 * 16展平成 1*256
2.将1*256 映射到 我想要的 1 * d
3.图中 那个0*是一个全局的token -> CLS
4.粉色的是token embeding ; 带数字的是position embeding 两个相加(不是拼接,是相加)过transformer encoder以后,由CLS token输出
(这里有个问题:为什么这里要用BERT中的CLS token, 在BERT中有两个任务:NSP(预测下一句,相当于多分类),MLM(预测当前单词),这两个任务在某些token上计算loss是会有重叠的,而用CLS可以保持独立性)

三、代码中的问题
源码中层的顺序:
1.patch embed & position embed
2.encoder layer
3.representation layer(论文中用的是tanh函数)
4. classifier layer
| patch_size | embed_dim | depth | num_heads | FLOPs(GFLOPs) | Latency (ms) | |
| vit_tiny_patch16_224 | 16 | 192 | 12 | 3 | >16.85 | 712.19 |
| vit_tiny_patch16_384 | 16 | 192 | 12 | 3 | >49.35 | 2463.74 |
| vit_small_patch32_224 | 32 | 384 | 12 | 6 | >16.85 | 678.35 |
| vit_small_patch32_384 | 32 | 384 | 12 | 6 | >49.35 | |
| vit_small_patch16_224 | 16 | 384 | 12 | 6 | >16.85 | 691.28 |
| vit_small_patch16_384 | 16 | 384 | 12 | 6 | >49.35 | |
| vit_base_patch32_224 | 32 | 768 | 12 | 12 | >16.85 | |
| vit_base_patch32_384 | 32 | 768 | 12 | 12 | >49.35 | |
| vit_base_patch16_224 | 16 | 768 | 12 | 12 | >16.85 | |
| vit_base_patch16_384 | 16 | 768 | 12 | 12 | >49.35 |
A/libc: Fatal signal 6 (SIGABRT), code -1















 2078
2078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









