









 本文详细解析了Transformer模型的原理与实现过程,包括向量点乘的物理意义、各组件如Encoder、Decoder的设计与代码实现,以及Attention机制的理解。
本文详细解析了Transformer模型的原理与实现过程,包括向量点乘的物理意义、各组件如Encoder、Decoder的设计与代码实现,以及Attention机制的理解。
目录
1.torch.view(shape)与torch.contiguous().view(shape)函数:
一、向量点乘的物理意义
1.问题:
为什么能表示Q和K向量的相似性,再分配到V上的权重?
2.解决
两个向量的点积的物理意义是向量A在向量B上的投影,当AB高度相似时,其夹角就小,点积就越大。这里K是等于V的。
二、代码总结
1.从大结构到小结构写逻辑树。
2.所有网络的结构都用类来封装—— def __init__ 下定义结构,大类通常是调用小类来实现forward方法,所以在定义结构的时候,也要给出构建子类的参数,以及子类forward函数的参数。
并重写def forward()方法,forward方法参数是输入变量
3.写网络时一定要先规划好网络的结构与输入参数,这样才不会乱。
1.模型结构(将一个类一个类进行说明)
最大的结构:EncoderDecoder类
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, src_mask, tgt, tgt_mask):
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, src_mask, memory, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)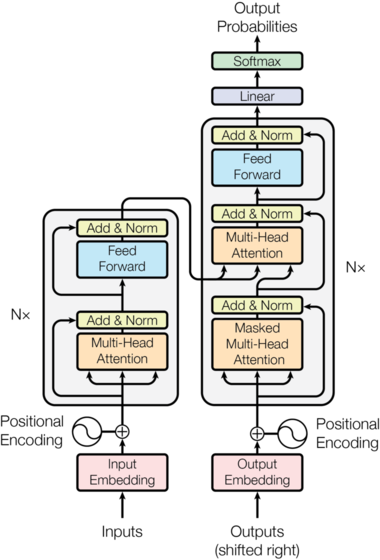
1.EncoderDecoder由:encoder, decoder, src_embed, tgt_embed, 以及generator 五个大模块构成(分模块的依据是,是否对输入进行了处理),所以在初始化部分定义了5个属性。
2.为了重写forward方法,就需要知道数据流——即输入输出的关系:
其中:encoder结构的输入是src, src_mask
decoder的输入是memory, tgt, tgt_mask, src_mask
又因为memory是中间变量,所以EncoderDecoder的输入只有4个src_embed, src_mask, tgt_embed, tgt_mask
这样就完成了网络最大结构的定义。
3.tips: 定义参数的时候,顺序是src -> memory -> tgt
2.实现Encoder类
因为在transformer is all you need论文里, encoder和decoder都被重复使用了六次, 所以我们需要一个复制函数来进行批量复制(这里涉及深拷贝、nn.ModuleList([])的知识。
这里提示一句:继承nn.Module的类,会自动调用forward函数。
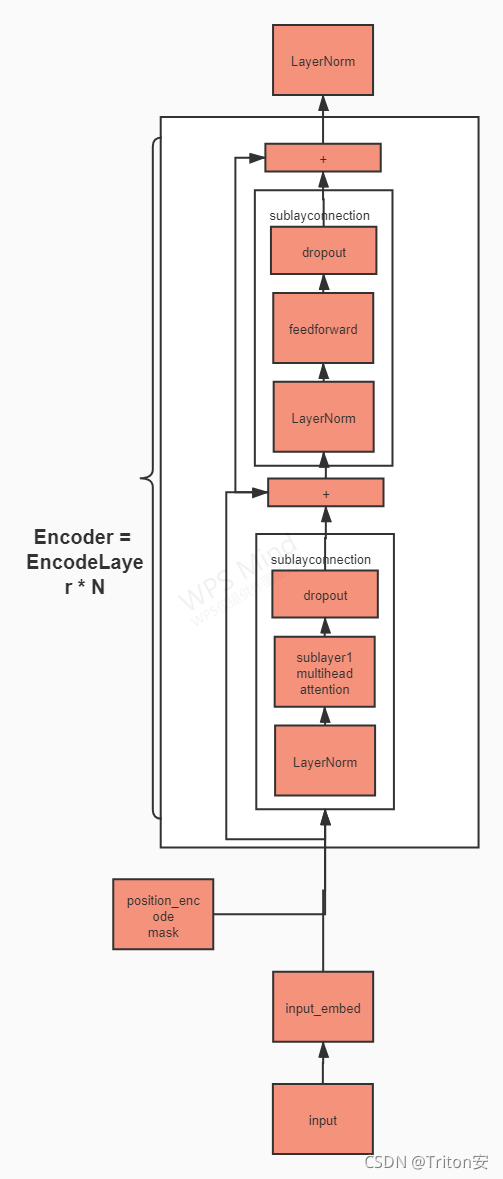
def clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])接着,根据上面的流程图,从大类到小类依次写代码:
Encoder = EncodeLayer * N
他的输入是input_embed 与 input_mask
class Encoder(nn.Module):
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
for layer in self.layers
x = layer(x, mask)
return self.norm(x)
EncoderLayer的结构是两层SubLayerConnection,SubLayerConnection的参数是要给出layernorm用的size, dropout的dropout_rate, 两个子层self_attn, feed_forward
他的输入是nput_embed 与 input_mask
class EncoderLayer(nn.Module):
def __init__(self, size, dropout_rate, self_attn, feed_forward):
super(EncoderLayer, self).()
self.size = size
self.sublayer = clones(SubLayerConnection(size, dropout_rate), 2)
self.self_attn = self_attn
self.feed_forward = feed_forward
def forward(self,x, mask):
x = self.sublayer[0](x, lambda x : self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
SubLayerConnection的结构就是一个layernorm和dropout
输入是x与sublayer(这里的x指得应该是input_embed)事实上,src_mask只是decoder的输入。
class SubLayerConnection(nn.Module):
def __init__(self, size, dropout_rate):
super(SubLayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout_rate)
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))再补充上LayerNorm
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
# features=layer.size=512
self.a_2 = nn.Parameter(t.ones(features))
self.b_2 = nn.Parameter(t.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2这样就实现了Encoder类
3.实现Decoder类
Decoder的代码思路和Encoder类似,只不过Decoder相比于Encoder多了一个子层,所以只要在Encoder的代码上稍做修改即可。
请根据Encoder类的思路,写出Decoder类的流程图,与代码~
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout_rate):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SubLayerConnection(size, dropout_rate), 3)
def forward(self, src_mask, memory, x, tgt_mask):
x = self.sublayer[0](x, lambda x : self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x : self.src_attn(x, memory, memory, src_mask))
return self.sublayer[2](x, self.feed_forward)所有网络的结构都用类来封装—— def __init__ 下定义结构,大类通常是调用小类来实现forward方法,所以在定义结构的时候,也要给出构建子类的参数:
DecoderLayer子类的构建需要:三个SubLayerConnection中的sublayer, SubLayerConnection类的两个参数, size和dropout_rate
forward方法的参数接收模型外的输入参数,即:src_mask, memory, x, tgt_mask
class Decoder(nn.Module):
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, src_mask, memory, x, tgt_mask): #每一个DecoderLayer有四个输入参数
for layer in self.layers:
x = layer(src_mask, memory, x, tgt_mask)
return self.norm(x)Decoder子类是DecoderLayer, 我们只需要将DecoderLayer放进来clones,再在输出进行一个LayerNorm操作就可以了。
这样Decoder的模型结构就非常清晰了:
底层是SubLayerConnection类,它需要两个参数来构建——size, dropout_rate,它的forward方法需要两个参数——输入x,定义的sublayer;
中间层是DecoderLayer,它需要5个参数来构建,其中两个参数——size,dropout_rate是为了在DecoderLayer类中定义SubLayerConnection结构,另外三个参数self_attn, src_attn, feed_forward是为了使用SubLayerConnection的forward方法。
最后一层是Decoder,它需要2个参数来构建,layer实际上就是DecoderLayer,N是复制的次数,最后记住输出要过一遍LayerNorm即可。
4.attention的实现
(1)如何理解attention?
首先,如果一个横向量与一个竖向量进行矩阵乘法,那实际上是进行了向量的点乘,而点乘的物理意义在开头提及过,是确定两个向量的相似性,因此可以得到一个score。
而这里,将多个向量合并起来放在矩阵里面进行矩阵乘法可以更快速的得到多个向量之间的关联性。例如:若
,
表示Q的第i行向量,与
的第j列的相似性,就得到了一个score matrix。
再通过softmax就得到0-1的score matrix,除以sqrt(d_k)的目的是为了让分数不要非1即0; 由于K与V一一对应,再与V矩阵相乘.
这里着重说明一下与矩阵V相乘的物理意义:
,假设A和V都是3x3的矩阵,以A矩阵的第一行为例,a11,a12,a13分别表示Q的第一行与V的第一行的关联性,Q的第一行与V的第二行的关联性,Q的第三行与V的第三行的关联性(注意K与V是一一对应的,所以和K的关联性即对V的关联性),这样在矩阵相乘的时候,由于矩阵乘法的定义是线性组合,所以实际上是把这些关联的score作为权值乘在了V矩阵的行向量上,并求和。
def attention(query, key, value, mask=None, dropout=None): """Compute 'Scaled Dot Product Attention ' """ d_k = query.size(-1) scores = t.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k) # matmul矩阵相乘 if mask is not None: scores = scores.masked_fill(mask == 0, -1e9) p_attn = F.softmax(scores, dim = -1) if dropout is not None: p_attn = dropout(p_attn) return t.matmul(p_attn, value), p_attn
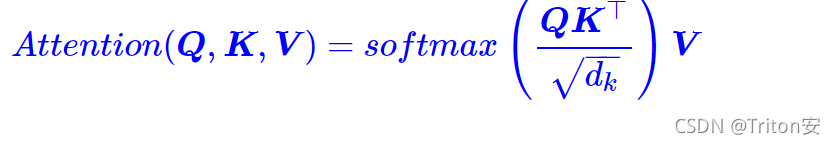

(2)理解Multi-Head Attention
这一段《Attention is All You Need》浅读(简介+代码) - 科学空间|Scientific Spaces (kexue.fm)
讲得很好,直接截图。concat就是恢复之前的维度。
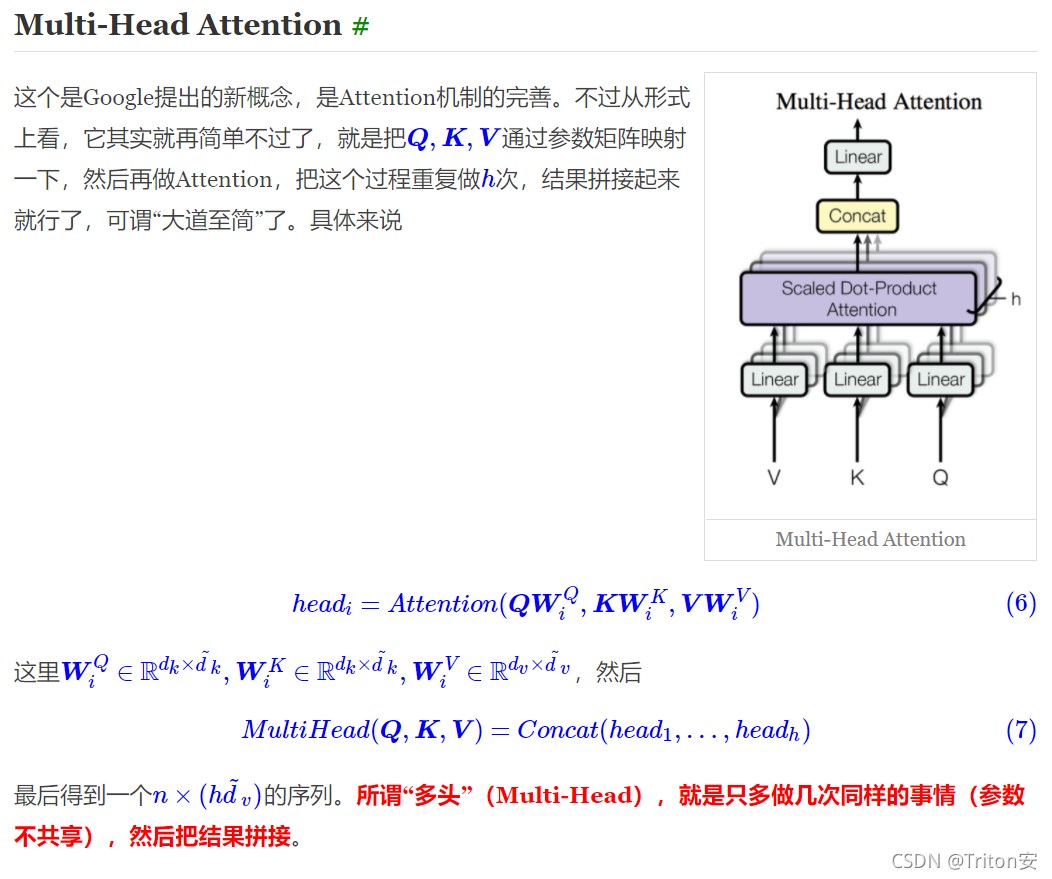
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
""" Take in model size and numbe of heads """
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"""图片ModalNet-20的实现"""
if mask is not None:
# 同样的mask应用到所有heads
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1. 批量做linear投影 => h x d_k
query, key, value = [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2. 批量应用attention机制在所有的投影向量上
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# 3. 使用view进行“Concat”并且进行最后一层的linear
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)5.feed-forward network
这一部分就是很基本的神经网络层
class PositionwiseFeedForward(nn.Module):
"""
FFN实现
d_model = 512
d_ff = 2048
"""
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
6.Embedding
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
这里和传统的seq2seq区别不大。
7.Position Embedding
这里理解不是很深,引用:《Attention is All You Need》浅读(简介+代码) - 科学空间|Scientific Spaces (kexue.fm)的说明。
(28条消息) pytorch求索(4): 跟着论文《 Attention is All You Need》一步一步实现Attention和Transformer_腾云-CSDN博客
class PositionalEncoding(nn.Module): """PE函数实现""" def __init__(self, d_model, dropout, max_len=5000): super(PositionalEncoding, self).__init__() self.dropout = nn.Dropout(p=dropout) pe = torch.zeros(max_len, d_model) position = torch.arange(0, max_len).unsqueeze(1) div_term = torch.exp(torch.arange(0, d_model, 2) * (-(math.log(10000.0) / d_model))) pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) pe = pe.unsqueeze(0) self.register_buffer('pe', pe) def forward(self, x): x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False) return self.dropout(x)


8.构造模型
def make_model(src_vacab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
""" 构建模型"""
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vacab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab)
)
# !!!import for the work
# 使用Glorot/ fan_avg初始化参数
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
这里就是朴实无华的构造出模型,for语句是对模型的参数进行xavier_uniform的初始化。
9.补充:FLOPs和参数量的测试
from torchvision.models import resnet18
from thop import profile
model = resnet18()
input = torch.randn(1, 3, 224, 224) #模型输入的形状,batch_size=1
flops, params = profile(model, inputs=(input, ))
print(flops/1e9,params/1e6) #flops单位G,para单位M
FLOPs的意义是模型的浮点数计算次数,即等于模型进行一次forward所进行的乘法与加法的次数。
这里会发现一件很有意思的事情,由于transformer在训练时会需要src 和 tgt的输入,但是在预测时只需要输入src, 这两种不同的模式导致模型的forward只用来进行训练, 而预测是采用的贪心算法进行的预测。
三、编程时遇到的问题
1.torch.view(shape)与torch.contiguous().view(shape)函数:
关于contiguous的问题参考这篇博客:
PyTorch中的contiguous - 知乎 (zhihu.com)
https://zhuanlan.zhihu.com/p/64551412总之,torch.view是要作用与连续对象上的。
2.assert语句
语法格式如下:
assert expression等价于:
if not expression: raise AssertionError
3.torch.register_buffer( )
例如,本次代码中positional_encoding中的:self.register_buffer('pe', pe) 就保存了位置编码的参数。
4.Layer Normalization
注意LN是对一个词向量做的


5.torch.masked_fill
masked_fill方法有两个参数,mask和value,mask是一个pytorch张量(Tensor),元素是布尔值,value是要填充的值,填充规则是mask中取值为True位置对应于self的相应位置用value填充。
>>> t = torch.randn(3,2)
>>> t
tensor([[-0.9180, -0.4654],
[ 0.9866, -1.3063],
[ 1.8359, 1.1607]])
>>> m = torch.randint(0,2,(3,2))
>>> m
tensor([[0, 1],
[1, 1],
[1, 0]])
>>> m == 0
tensor([[ True, False],
[False, False],
[False, True]])
>>> t.masked_fill(m == 0, -1e9)
tensor([[-1.0000e+09, -4.6544e-01],
[ 9.8660e-01, -1.3063e+00],
[ 1.8359e+00, -1.0000e+09]])


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









